一种高效简便纯化蛋白的方法与流程
本发明涉及一种表达包涵体蛋白cipa,一种自裂解的内含肽和目标蛋白egfp的质粒pet-28a-cipa-dnab-egfp。本发明还涉及该质粒的构建方法及目标蛋白的纯化方法,属于生物工程技术领域。
背景技术:
随着分子生物学、细胞工程和发酵工程的发展,重组蛋白的表达效率显著提高。尽管取得了这样的成功,开发一种大规模、简便且高效的蛋白纯化方法仍然是一项巨大的挑战。在酶催化过程中,酶纯度是降低生产所需产物成本的一个必要环节。许多研究提到使用不同的方法纯化靶蛋白,例如亲和纯化[1,2],使用自聚集纯化标签[3-5]和自我裂解标签(内含肽)[6,7]等。在这些方法中,亲和纯化在纯化过程中占主导地位,并以其操作简单和纯化效率高仍作为蛋白质纯化的首选。常用的亲和标签包括mbp,his和gst[8,9]。但亲和纯化具有许多缺点。例如,亲和标签会降低目标酶的催化效率[9]。另外,亲和标签的切除操作复杂且造价高。尽管相应的亲和树脂可以通过公司购买,并且能达到很高的纯度,但在利用这些方法处理大量的样品时,不得不考虑其高昂的树脂成本和缓慢的纯化速度。
多年来,生物聚合物已被应用于开发低成本且高效的非色谱纯化方法,经实践证实其具有良好的选择性和较高的产率。在大多数情况下,利用生物聚合物作为纯化标签,可以诱导被标记的融合蛋白在特定的化学或物理条件下形成具有高度选择性的聚集体。报道的标签包括弹性蛋白样多肽(elp)、毒素重复(rtx)结构域和elk16[10-13]。其中尤其是elp标签,它可诱导蛋白聚集。与其他纯化标签一样,这些标签在纯化过程中有时需要被除去,对于可能影响靶蛋白性质的大标签来说,这一步骤尤其重要。常用的标签去除方法包括使用蛋白酶如xa因子、tev蛋白酶和鼻病毒3c蛋白酶[14–16],但蛋白酶需要额外的纯化步骤来去除,这些纯化步骤会对靶蛋白造成一定的损害,如解离反应可能导致靶蛋白的非特异性裂解或在靶蛋白上留下少量的“残基”氨基酸。使用大量酶去除蛋白标记所带来的高成本严重地限制了它们的应用。据报道,具有自我剪切功能的内含肽已被用于标签去除。内含肽可通过编码基因插入到标记的靶蛋白序列中,其位点特异性自我切割的功能可实现将标签从靶蛋白质上去除的效果。因此,与蛋白酶相比,内含肽在时间成本和生产成本方面具有更高的效益。
为了简化蛋白质纯化操作步骤并降低亲和标签对靶蛋白的影响,本发明提出了一种由cipa蛋白和内含肽介导的纯化方法。cipa是一种含有104个氨基酸的小蛋白质,存在于发光杆菌photorhabdusluminescens(p.luminescens)中,可以在菌体中自发组装成包涵体(pcis)。此外,将目标蛋白融合在cipa的c端,融合的蛋白仍可保持其活性。本发明将cipa与靶蛋白p融合,为了从重组蛋白中除去cipa并获得没有任何标签的靶蛋白,在cipa和靶蛋白p之间插入了小内含肽(synechocystissp.pcc6803dnab,sspdnab)以产生cipa-dnab-ppcis。dnab可以在低ph条件下通过其c端裂解与融合的靶蛋白分离。此外,为了提高dnab自裂解的效率并在上清液中获得更多的靶蛋白,本发明在cipa和dnab之间插入不同的连接肽。本发明提出了一种新颖简单的蛋白质纯化方法,可以降低所需蛋白质的工业化生产成本。
本发明利用此方法纯化了六种目标蛋白,包括增强型绿色荧光蛋白(egfp)、β-半乳糖苷酶(β-gal)、乙酰乳酸合酶(alss)、乙酮醇酸还原异构酶(ilvc)、二羟酸脱水酶(ilvd)及丙酮酸脱羧酶(kivd),并成功利用纯化的酶在体外实现了异丁醇的生产。
参考文献:
[1]j.j.lichty,j.l.malecki,h.d.agnew,d.j.michelson-horowitz,s.tan,proteinexpres.purif.2005,41,98.
[2]c.l.young,z.t.britton,a.s.robinson,biotech.j.2012,7,620.
[3]m.r.banki,l.feng,d.w.wood,nat.methods2005,2,659.
[4]d.lan,g.huang,h.shao,l.zhang,etal.,anal.biochem.2011,415,200.
[5]w.y.wu,c.mee,f.califano,r.banki,d.w.wood,nat.protoc.2006,1,2257.
[6]c.cui,w.zhao,j.chen,j.wang,q.li,proteinexpres.purif.2006,50,74.
[7]s.s.sharma,s.chong,s.w.harcum,j.biotechnol.2006,125,48.
[8]z.chen,y.li,q.yuan,int.j.biol.macromol.2015,72,6.
[9]z.chen,y.li,q.yuan,int.j.biol.macromol.2015,78,96.
[10]m.r.banki,feng,l.a.;wood,d.w.nat.methods2005,2,659.
[11]b.a.fong,w.y.wu,d.w.wood,proteinexpr.purif.2009,66,198.
[13]w.wu,l.xing,b.zhou,z.lin,cellfact.2011,10,9.
[13]o.shur,k.dooley,m.blenner,m.baltimore,s.banta,biotechniques.2013,54,197.
[14]s.raran-kurussi,s.cherry,d.zhang,d.s.waugh,methodsmol.biol.2017,1586,221.
[15]a.alexandrov,k.dutta,s.m.pascal,biotechniques.2001,30,1194.
[16]h.block,b.maertens,a.spriestersbach,j.kubicek,f.schafer,methodsenzymol.2015,559,71.
技术实现要素:
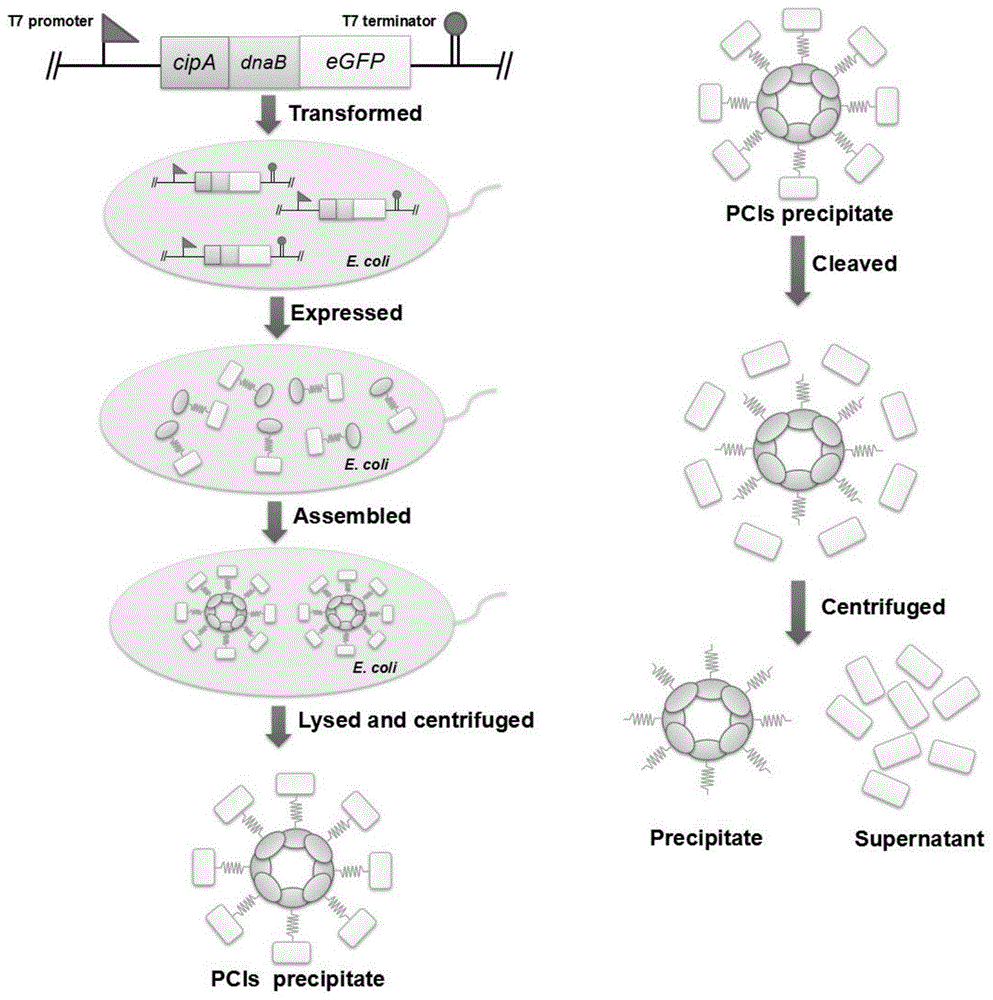
本发明的目的在于提供一种简单高效的纯化靶蛋白的方法,该方法中使用到质粒pet-28a-cipa-dnab-egfp,其表达产物cipa-dnab-egfppcis,改变ph后,可通过内含肽dnab的自裂解将靶蛋白与包涵体蛋白分离,从而达到纯化的效果。
本发明的另一个目的是提供上述质粒的构建方法和蛋白纯化方法,其包括下述步骤:
(1)构建质粒pet-28a-cipa-dnab-egfp,采用oe-pcr法合成了基因cipa(ncbi:cae138691)、dnab(pdb:1mi8_a)和egfp(ncbi:ahk23750.1),通过oe-pcr分别将cipa和egfp连接到dnab的5’端和3’端。通过gibson组装将cipa-dnab-egfp克隆到pet-28a载体上。随后,将pcr产物转化至大肠杆菌xl10-gold,并通过dna测序验证质粒。
(2)表达蛋白cipa-dnab-egfp,将质粒pet-28a-cipa-dnab-egfp导入大肠杆菌bl21(de3)中,挑取单菌落接种于5mllb培养基中,加入50μg/ml卡那霉素,37℃过夜培养获得种子液。次日,将种子液接种于200ml新鲜tb培养基中,37℃培养2h左右,使od600达到0.5-0.8,在培养液中加入0.5mm异丙基-β-d-硫半乳糖苷(iptg),30℃培养10h。为防止代谢产物使培养基ph下降,在0h、2h、4h和6h分别向培养液中加入25mmhepes(ph=8.5)。
(3)获得重组蛋白,将(2)中表达完蛋白的发酵液,离心(4000×g,4℃,20min),弃上清,获得菌体,加入50ml缓冲液(50mmtris-hcl,ph7.5)重悬,超声破碎后离心(10000×g,4℃,20min),弃上清,最终获得cipa-dnab-egfppcis。
(4)通过dnab裂解纯化egfp,用50ml缓冲液(50mmtris-hcl,ph=6.5)洗涤cipa-dnab-egfppcis两次后重悬,23℃放置18h,使内含肽自裂解,将裂解混合物离心(10000×g,4℃,20min)。其中cipa-dnab为沉淀,egfp为上清液中的纯蛋白,整个纯化过程如图1所示。通过sds-page验证egfp的含量和纯度。sds-page浓缩胶和分离胶配方为:5%浓缩胶(3.4mlddh2o,830μl30%丙烯酰胺,630μl1mtris-hcl(ph6.8),50μl10%sds,50μl10%过硫酸铵,5μltemed)和10%分离胶(4mlddh2o,3.3ml30%丙烯酰胺,2.5ml1.5mtris-hcl),100μl10%sds,100μl10%过硫酸铵,5μltemed。
表1:本发明所用到的菌株及质粒
该纯化方法的优化:为了提高dnab断裂的效率并在上清液中获得更多单一的靶蛋白p,本方法在基因cipa和dnab序列之间插入了不同的连接肽。使用pet-28a-cipa-dnab-egfp作为模板,并在靶蛋白基因p的5’端使用具有“gra”三个氨基酸编码序列的引物。随后,将pcr产物转化至大肠杆菌xl10-gold中使其自连接,得到重组质粒pet-28a-cig1,随后通过测序验证重组质粒。另外,质粒pet-28a-cipa-epppl-dnab-gra-egfp(pet-28a-cig2),pet-28a-cipa-eppplppplpppl-dnab-gra-egfp(pet-28a-cig3),pet-28a-cipa-gsgsgs-dnab-gra-egfp(pet-28a-cig4),pet28a-cipa-ggggsggggsggggs-dnab-gra-egfp(pet-28a-cig5),与pet-28a-cig1构建过程相似。实验验证表达质粒pet28a-cipa-ggggsggggsggggs-dnab-gra-egfp(pet-28a-cig5)所得产物的裂解效果最好,得到的纯化的靶蛋白egfp最多。
附图说明:
图1使用该方法纯化蛋白的原理流程图,其中靶蛋白为egfp。
图2使用该方法纯化蛋白的操作流程图,其中靶蛋白为egfp。
图3大肠杆菌bl21(de3)(pet-28a-cipa-dnab-egfp)表达产物cipa-dnab-egfp及cipa-dnab和egfp的sds-page电泳图。泳道1:180kda蛋白marker;泳道2:超声破碎后的全细胞蛋白;泳道3:破碎混合物离心所得沉淀;泳道4:破碎混合物离心所得上清;泳道5:内含肽裂解后离心所得沉淀;泳道6:内含肽裂解后离心所得上清。
图4大肠杆菌bl21(de3)(pet-28a-cipa-dnab-adhp)表达产物cipa-dnab-adhp及cipa-dnab和adhp的sds-page电泳图。泳道1:180kda蛋白marker;泳道2:超声破碎后的全细胞蛋白;泳道3:破碎混合物离心所得沉淀;泳道4:破碎混合物离心所得上清;泳道5:内含肽裂解后离心所得沉淀;泳道6:内含肽裂解后离心所得上清。
图5大肠杆菌bl21(de3)(pet-28a-cipa-dnab-mbp)表达产物cipa-dnab-mbp及cipa-dnab和mbp的sds-page电泳图。泳道1:180kda蛋白marker;泳道2:超声破碎后的全细胞蛋白;泳道3:破碎混合物离心所得沉淀;泳道4:破碎混合物离心所得上清;泳道5:内含肽裂解后离心所得沉淀;泳道6:内含肽裂解后离心所得上清。
序列表:
序列1,包涵体蛋白cipa的氨基酸序列;
序列2,内含肽dnab的氨基酸序列;
序列3,增强型绿色荧光蛋白egfp的氨基酸序列;
序列4,β-半乳糖苷酶(β-gal)的氨基酸序列;
序列5,纤维素结合蛋白(mbp)的氨基酸序列;
序列6,乙酰乳酸合酶(alss)的氨基酸序列;
序列7,乙酮醇酸还原异构酶(ilvc)的氨基酸序列;
序列8,二羟酸脱水酶(ilvd)的氨基酸序列;
序列9,丙酮酸脱羧酶(kivd)的氨基酸序列;
序列10,丙酮酸脱羧酶(adhp)的氨基酸序列。
具体实施方式
以下实例是对本发明的进一步说明,并不构成对本发明实质内容的限制。
实施例1
增强型绿色荧光蛋白egfp的纯化
(1)构建质粒pet-28a-cipa-dnab-egfp,采用oe-pcr法合成了基因cipa(ncbi:cae138691)、dnab(pdb:1mi8_a)和egfp(ncbi:ahk23750.1),通过oe-pcr分别将cipa和egfp连接到dnab的5’端和3’端。通过gibson组装将cipa-dnab-egfp克隆到pet-28a载体上。随后,将pcr产物转化至大肠杆菌xl10-gold,并通过dna测序验证质粒。
(2)表达蛋白cipa-dnab-egfp,将质粒pet-28a-cipa-dnab-egfp导入大肠杆菌bl21(de3)中,挑取单菌落接种于5mllb培养基中,加入50μg/ml卡那霉素,37℃过夜培养获得种子液。次日,将种子液接种于200ml新鲜tb培养基中,37℃培养2h左右,使od600达到0.5-0.8,在培养液中加入0.5mm异丙基-β-d-硫半乳糖苷(iptg),30℃培养10h。为防止代谢产物使培养基ph下降,在0h、2h、4h和6h分别向培养液中加入25mmhepes(ph=8.5)。
(3)获得重组蛋白,将(2)中表达完蛋白的发酵液,离心(4000×g,4℃,20min),弃上清,获得菌体,加入50ml缓冲液(50mmtris-hcl,ph7.5)重悬,超声破碎后离心(10000×g,4℃,20min),弃上清,最终获得cipa-dnab-egfppcis。
(4)通过dnab裂解纯化egfp,用50ml缓冲液(50mmtris-hcl,ph=6.5)洗涤cipa-dnab-egfppcis两次后重悬,23℃放置18h,使内含肽自裂解,将裂解混合物离心(10000×g,4℃,20min)。其中cipa-dnab为沉淀,egfp为上清液中的纯蛋白,整个纯化过程如图1所示。通过sds-page验证egfp的含量和纯度。sds-page浓缩胶和分离胶配方为:5%浓缩胶(3.4mlddh2o,830μl30%丙烯酰胺,630μl1mtris-hcl(ph6.8),50μl10%sds,50μl10%过硫酸铵,5μltemed)和10%分离胶(4mlddh2o,3.3ml30%丙烯酰胺,2.5ml1.5mtris-hcl),100μl10%sds,100μl10%过硫酸铵,5μltemed。
蛋白表达的培养基组成为:酵母提取物24g/l,蛋白胨12g/l,kh2po412.54g/l,k2hpo42.31g/l,甘油4ml/l,高温高压灭菌。
裂解缓冲液组成为:50mmtris,10mmdtt,hcl调至ph=6.5
实施例2
β-半乳糖苷酶(β-gal)的纯化
(1)构建质粒pet-28α-cipa-dnab-lacz(pet-28α-ciz),采用oe-pcr法合成了基因cipa(ncbi:cae138691)、dnab(pdb:1mi8_a)和lacz(ncbi:945006)。然后,通过oe-pcr分别将cipa和lacz连接到dnab的5’端和3’端。然后通过gibson组装将cipa-dnab-lacz片段克隆到pet-28a载体上。随后,将pcr产物转化大肠杆菌xl10-gold,测序验证重组质粒。
(2)表达融合蛋白cipa-dnab-β-gal,将pet-28α-ciz转化至大肠杆菌bl21(de3)中,并将单个菌落接种于5mllb培养基中,加入50μg/ml卡那霉素,在37°с培养过夜后将培养液接种于200ml新鲜tb培养基中。37℃培养2h后使od600达到0.5-0.8,加入0.5mm异丙基-β-d-硫半乳糖苷(iptg),30℃培养10h。为了防止培养基中的介质酸化和培养液ph下降,在培养0h、2h、4h和6h时加入25mmhepes(ph8.5)。
(3)获得重组蛋白,将(2)中表达完蛋白的发酵液,离心(4000×g,4℃,20min),弃上清,获得菌体,加入50ml缓冲液(50mmtris-hcl,ph7.5)重悬,超声破碎后离心(10000×g,4℃,20min),弃上清,最终获得cipa-dnab-β-galpcis。
(4)纯化β-gal,用50mm裂解缓冲液(50mmtris-hcl,ph6.5)洗涤沉淀cipa-dnab-β-galpcis两次,最后用裂解缓冲液重悬,使其浓度达到od600为1,然后在23℃下放置18h,dnab的c端裂解。将裂解混合物离心(10000×g,4℃,20min)。cipa-dnab保留在沉淀中,β-gal则作为上清液中的唯一蛋白被纯化出来。通过sds-page电泳确定β-gal的含量和纯度。
酶活性的测定,参照gil-martín等人的方法略加改进。在总体积为1ml的柠檬酸反应缓冲液(0.1m柠檬酸用naoh调至ph4.5),体系中含0.8μmol的底物onpg和40μmolβ-巯基乙醇(临用前配制),适量纯化后的酶液。在37℃孵育30min后,用0.5m冷碳酸钠1ml终止反应,用紫外分光光度计于405nm波长测定吸光度值,同时设定底物对照和酶液对照。产物邻硝基苯酚(onp)显黄色,在405nm处有最大吸收峰。
酶活性计算公式:u(β-gal)=a/(0.777×30)×m。
式中:a为反应生成的onp吸光度值,a=a(反应液)-a(底物)-a(酶提取液);0.777为1μmol邻硝基苯酚(onp)的吸光度值;m为反应体系中的酶蛋白量,单位是mg。酶活力单位u定义为标准条件下(ph4.5,37℃)每min催化生成1μmol产物邻硝基苯酚(onp)所需的酶量为1个单位。
蛋白表达的培养基组成为:酵母提取物24g/l,蛋白胨12g/l,kh2po412.54g/l,k2hpo42.31g/l,甘油4ml/l,蒸馏水定容至1l,高温高压灭菌。
裂解缓冲液组成为:50mmtris,10mmdtt,hcl调至ph=6.5
实施例3
麦芽糖结合蛋白(mbp)的纯化
(1)构建质粒pet-28α-cipa-dnab-mbp(pet-28α-cim),采用oe-pcr法合成了基因cipa(ncbi:cae138691)、dnab(pdb:1mi8_a)和mbp(geneid:4155)。然后,通过oe-pcr分别将cipa和mbp连接到dnab的5’端和3’端。然后通过gibson组装将cipa-dnab-mbp片段克隆到pet-28a载体上。随后,将pcr产物转化大肠杆菌xl10-gold,测序验证重组质粒。
(2)表达融合蛋白cipa-dnab-mbp,将pet-28α-cim转化至大肠杆菌bl21(de3)中,并将单个菌落接种于5mllb培养基中,加入50μg/ml卡那霉素,在37℃培养过夜后将培养液接种于200ml新鲜tb培养基中。37℃培养2h后使od600达到0.5-0.8,加入0.5mm异丙基-β-d-硫半乳糖苷(iptg),30℃培养10h。为了防止培养基中的介质酸化和培养液ph下降,在培养0h、2h、4h和6h时加入25mmhepes(ph8.5)。
(3)获得重组蛋白,将(2)中表达完蛋白的发酵液,离心(4000×g,4℃,20min),弃上清,获得菌体,加入50ml缓冲液(50mmtris-hcl,ph7.5)重悬,超声破碎后离心(10000×g,4℃,20min),弃上清,最终获得cipa-dnab-mbppcis。
(4)纯化mbp,用50mm裂解缓冲液(50mmtris-hcl,ph6.5)洗涤沉淀cipa-dnab-mbppcis两次,最后用裂解缓冲液重悬,使其浓度达到od600为1,然后在23℃下放置18h,dnab的c端裂解。将裂解混合物离心(10000×g,4℃,20min)。cipa-dnab保留在沉淀中,mbp则作为上清液中的唯一蛋白被纯化出来。通过sds-page电泳确定mbp的含量和纯度。
蛋白表达的培养基组成为:酵母提取物24g/l,蛋白胨12g/l,kh2po412.54g/l,k2hpo42.31g/l,甘油4ml/l,蒸馏水定容至1l,高温高压灭菌。
裂解缓冲液组成为:50mmtris,10mmdtt,hcl调至ph=6.5
实施例4
乙醇脱氢酶(adhp)的纯化
(1)构建质粒pet-28α-cipa-dnab-adhp(pet-28α-cip),采用oe-pcr法合成了基因cipa(ncbi:cae138691)、dnab(pdb:1mi8_a)和adhp(geneid:946036)。然后,通过oe-pcr分别将cipa和adhp连接到dnab的5’端和3’端。然后通过gibson组装将cipa-dnab-adhp片段克隆到pet-28a载体上。随后,将pcr产物转化大肠杆菌xl10-gold,测序验证重组质粒。
(2)表达融合蛋白cipa-dnab-adhp,将pet-28α-cip转化至大肠杆菌bl21(de3)中,并将单个菌落接种于5mllb培养基中,加入50μg/ml卡那霉素,在37℃培养过夜后将培养液接种于200ml新鲜tb培养基中。37℃培养2h后使od600达到0.5-0.8,加入0.5mm异丙基-β-d-硫半乳糖苷(iptg),30℃培养10h。为了防止培养基中的介质酸化和培养液ph下降,在培养0h、2h、4h和6h时加入25mmhepes(ph8.5)。
(3)获得重组蛋白,将(2)中表达完蛋白的发酵液,离心(4000×g,4℃,20min),弃上清,获得菌体,加入50ml缓冲液(50mmtris-hcl,ph7.5)重悬,超声破碎后离心(10000×g,4℃,20min),弃上清,最终获得cipa-dnab-adhppcis。
(4)纯化adhp,用50mm裂解缓冲液(50mmtris-hcl,ph6.5)洗涤沉淀cipa-dnab-adhppcis两次,最后用裂解缓冲液重悬,使其浓度达到od600为1,然后在23℃下放置18h,dnab的c端裂解。将裂解混合物离心(10000×g,4℃,20min)。cipa-dnab保留在沉淀中,adhp则作为上清液中的唯一蛋白被纯化出来。通过sds-page电泳确定adhp的含量和纯度。
蛋白表达的培养基组成为:酵母提取物24g/l,蛋白胨12g/l,kh2po412.54g/l,k2hpo42.31g/l,甘油4ml/l,蒸馏水定容至1l,高温高压灭菌。
裂解缓冲液组成为:50mmtris,10mmdtt,hcl调至ph=6.5
实施例5
乙酰乳酸合酶(alss)、乙酮醇酸还原异构酶(ilvc)、二羟酸脱水酶(ilvd)及丙酮酸脱羧酶(kivd)的纯化及体外反应
(1)构建质粒pet-28α-cipa-dnab-gra-alss(pet-28α-cis)、pet-28α-cipa-dnab-gra-ilvc(pet-28α-cic)、pet-28α-cipa-dnab-gra-ilvd(pet-28α-cid)和pet-28α-cipa-dnab-gra-kivd(pet-28α-cik),采用oe-pcr法合成了基因alss、ilvc、ilvd和kivd。以pet-28a-cipa-dnab-egfp为模板,将包含cipa的pet-28a骨架克隆下来,通过gibson组装分别将4个基因克隆到pet-28a-cipa的骨架中,将连接产物转化至大肠杆菌xl10-gold,测序验证。
(2)表达融合蛋白cipa-dnab-alss、cipa-dnab-ilvc、cipa-dnab-ilvd和cipa-dnab-kivd,将质粒pet-28α-cis、pet-28α-cic、pet-28α-cid和pet-28α-cik分别转化大肠杆菌bl21(de3),将单菌落接种于5mllb培养基中,加入50μg/ml卡那霉素,在37℃培养过夜后将培养液接种于200ml新鲜tb培养基中。37℃培养2h后使od600达到0.5-0.8,加入0.5mm异丙基-β-d-硫半乳糖苷(iptg),30℃培养10h。为了防止培养基中的介质酸化和培养液ph下降,在培养0h、2h、4h和6h时加入25mmhepes(ph8.5)。
(3)获得重组蛋白,将(2)中表达完蛋白的发酵液,离心(4000×g,4℃,20min),弃上清,获得菌体,加入50ml缓冲液(50mmtris-hcl,ph7.5)重悬,超声破碎后离心(10000×g,4℃,20min),弃上清,最终获得cipa-dnab-alss、cipa-dnab-ilvc、cipa-dnab-ilvd及cipa-dnab-kivdpcis。通过sds-page电泳确定所得产物的含量和纯度。
(4)纯化alss、ilvc、ilvd和kivd,用50mm裂解缓冲液(50mmtris-hcl,ph6.5)分别洗涤沉淀cipa-dnab-alss、cipa-dnab-ilvc、cipa-dnab-ilvd及cipa-dnab-kivdpcis两次,最后用裂解缓冲液重悬,使其浓度达到od600为1,然后在23℃下放置18h,dnab的c端裂解。将裂解混合物离心(10000×g,4℃,20min)。cipa-dnab保留在沉淀中,alss、ilvc、ilvd及kivd则分别作为上清液中的唯一蛋白被纯化出来。通过sds-page电泳确定alss、ilvc、ilvd和kivd的含量和纯度。
(5)配制异丁醇生成反应体系。异丁醇生成反应体系(2ml):2mm丙酮酸,1mmnad+,4种酶包括实施例4中adhp各50μl,室温反应2h。
异丁醇检测,使用配备火焰离子化检测器的agilent6890气相色谱仪。毛细管柱为db-ffap(30m×0.32mm×0.25μm,安捷伦科技),色谱条件为80℃,3min,利用增加梯度(115℃/min)增加到230℃,并在230℃保持1min,氮气作为载气。进样器和检测器分别维持在250和280℃。取反应后上清液1μl进样,其中进样分流比为1:30,正戊醇为内标。
在1.9min时获得异丁醇的气相色谱峰,且产量为1.2mm,产率为60%。序列表
序列1:cipa
mindmhpslikdkdivddvmlrsckiiamkvmpdkvmqvmvtvlmhdgvceemllkwnlldnrgmaiykvlmealcakkdvkistvgkvgplgcdyincveism
序列2:dnab
aisgdslislastgkrvsikdlldekdfeiwaineqtmklesakvsrvfctgkklvyilktrlgrtikatanhrfltidgwkrldelslkehialprklessslqlspeieklsqsdiywdsivsitetgveevfdltvpgphnfvandiivhn
序列3:egfp
mvskgeelftgvvpilveldgdvnghkfsvsgegegdatygkltlkficttgklpvpwptlvttltygvqcfsrypdhmkqhdffksampegyvqertiffkddgnyktraevkfegdtlvnrielkgidfkedgnilghkleynynshnvyimadkqkngikvnfkirhniedgsvqladhyqqntpigdgpvllpdnhylstqsalskdpnekrdhmvllefvtaagitlgmdelyk
序列4:β-gal
mtmitdslavvlqrrdwenpgvtqlnrlaahppfaswrnseeartdrpsqqlrslngewrfawfpapeavpeswlecdlpeadtvvvpsnwqmhgydapiytnvtypitvnppfvptenptgcysltfnvdeswlqegqtriifdgvnsafhlwcngrwvgygqdsrlpsefdlsaflragenrlavmvlrwsdgsyledqdmwrmsgifrdvsllhkpttqisdfhvatrfnddfsravleaevqmcgelrdylrvtvslwqgetqvasgtapfggeiiderggyadrvtlrlnvenpklwsaeipnlyravvelhtadgtlieaeacdvgfrevriengllllngkpllirgvnrhehhplhgqvmdeqtmvqdillmkqnnfnavrcshypnhplwytlcdryglyvvdeaniethgmvpmnrltddprwlpamservtrmvqrdrnhpsviiwslgnesghganhdalyrwiksvdpsrpvqyegggadttatdiicpmyarvdedqpfpavpkwsikkwlslpgetrplilceyahamgnslggfakywqafrqyprlqggfvwdwvdqslikydengnpwsayggdfgdtpndrqfcmnglvfadrtphpalteakhqqqffqfrlsgqtievtseylfrhsdnellhwmvaldgkplasgevpldvapqgkqlielpelpqpesagqlwltvrvvqpnatawseaghisawqqwrlaenlsvtlpaashaiphlttsemdfcielgnkrwqfnrqsgflsqmwigdkkqlltplrdqftrapldndigvseatridpnawverwkaaghyqaeaallqctadtladavlittahawqhqgktlfisrktyridgsgqmaitvdvevasdtphpariglncqlaqvaervnwlglgpqenypdrltaacfdrwdlplsdmytpyvfpsenglrcgtrelnygphqwrgdfqfnisrysqqqlmetshrhllhaeegtwlnidgfhmgiggddswspsvsaefqlsagryhyqlvwcqk
序列5:mbp蛋白序列
mkieegklviwingdkgynglaevgkkfekdtgikvtvehpdkleekfpqvaatgdgpdiifwahdrfggyaqsgllaeitpdkafqdklypftwdavryngkliaypiavealsliynkdllpnppktweeipaldkelkakgksalmfnlqepyftwpliaadggyafkyengkydikdvgvdnagakagltflvdliknkhmnadtdysiaeaafnkgetamtingpwawsnidtskvnygvtvlptfkgqpskpfvgvlsaginaaspnkelakeflenylltdegleavnkdkplgavalksyeeelakdpriaatmenaqkgeimpnipqmsafwyavrtavinaasgrqtvdealkdaqt
序列6:alss
mltkatkeqkslvknrgaelvvdclveqgvthvfgipgakidavfdalqdkgpeiivarheqnaafmaqavgrltgkpgvvlvtsgpgasnlatglltantegdpvvalagnviradrlkrthqsldnaalfqpitkysvevqdvknipeavtnafriasagqagaafvsfpqdvvnevtntknvravaapklgpaaddaisaaiakiqtaklpvvlvgmkggrpeaikavrkllkkvqlpfvetyqaagtlsrdledqyfgriglfrnqpgdllleqadvvltigydpieydpkfwningdrtiihldeiiadidhayqpdleligdipstinhiehdavkvefaereqkilsdlkqymhegeqvpadwksdrahpleivkelrnavddhvtvtcdigshaiwmsryfrsyepltlmisngmqtlgvalpwaigaslvkpgekvvsvsgdggflfsameletavrlkapivhivwndstydmvafqqlkkynrtsavdfgnidivkyaesfgatglrvespdqladvlrqgmnaegpviidvpvdysdninlasdklpkefgelmktkal
序列7:ilvc
maiellydadadlsliqgrkvaivgygsqghahsqnlrdsgvevviglregsksaekakeagfevkttaeaaawadvimllapdtsqaeiftndiepnlnagdallfghglnihfdlikpaddiivgmvapkgpghlvrrqfvdgkgvpcliavdqdptgtaqaltlsyaaaiggaragvipttfeaetvtdlfgeqavlcggteelvkvgfevlteagyepemayfevlhelklivdlmfeggisnmnysvsdtaefggylsgprvidadtksrmkdiltdiqdgtftkrlianvengnteleglrasynnhpieetgaklrdlmswvkvdaraeta
序列8:ilvd
miplrskvttvgrnaagaralwratgtkenefgkpivaivnsytqfvpghvhlknvgdivadavrkaggvpkefntiavddgiamghggmlyslpsreiiadsveymvnahtadamvcisncdkitpgmlnaamrlnipvvfvsggpmeagkavvvdgvahaptdlitaisasasdavddaglaaveasacptcgscsgmftansmncltealglslpgngstlathaarralfekagetvvelcrryygeedesvlprgiatkkafenamaldmamggstntilhilaaaqegevdfdladidelsknvpclskvapnsdyhmedvhraggipallgelnrggllnkdvhsvhsndlegwlddwdirsgkttevatelfhaapggirtteafstenrwdeldtdaakgcirdvehaytadgglvvlrgnispdgaviksagieeelwnftgparvvesqeeavsviltktiqagevlvvryegpsggpgmqemlhptaflkgsglgkkcalitdgrfsggssglsighvspeaahggvigliengdivsidvhnrklevqvsdeelqrrrdamnasekpwqpvnrnrvvtkalrayakmatsadkgavrqvd
序列9:kivd
mytvgdylldrlhelgieeifgvpgdynlqfldqiisrkdmkwvgnanelnasymadgyartkkaaaflttfgvgelsavnglagsyaenlpvveivgsptskvqnegkfvhhtladgdfkhfmkmhepvtaartlltaenatveidrvlsallkerkpvyinlpvdvaaakaekpslplkkenstsntsdqeilnkiqeslknakkpivitgheiisfglektvsqfisktklpittlnfgkssvdealpsflgiyngklsepnlkefvesadfilmlgvkltdsstgafthhlnenkmislnidegkifnesiqnfdfeslisslldlseieykgkyidkkqedfvpsnallsqdrlwqavenltqsnetivaeqgtsffgassiflkpkshfigqplwgsigytfpaalgsqiadkesrhllfigdgslqltvqelglairekinpicfiinndgytvereihgpnqsyndipmwnysklpesfgateervvskivrtenefvsvmkeaqadpnrmywielilakedapkvlkkmgklfaeqnks
序列10:adhp蛋白序列
mkaavvtkdhhvdvtyktlrslkhgeallkmeccgvchtdlhvkngdfgdktgvilghegigvvaevgpgvtslkpgdrasvawfyegcghceycnsgnetlcrsvknagysvdggmaeecivvadyavkvpdgldsaaassitcagvttykavklskirpgqwiaiyglgglgnlalqyaknvfnakviaidvndeqlklatemgadlainshtedaakivqektggahaavvtavakaafnsavdavraggrvvavglppesmsldiprlvldgievvgslvgtrqdlteafqfaaegkvvpkvalrpladintiftemeegkirgrmvid
- 还没有人留言评论。精彩留言会获得点赞!