大豆E2泛素结合酶基因GmUBC1的应用的制作方法
本发明属于植物基因工程领域,涉及大豆e2泛素结合酶基因gmubc1的应用。
背景技术:
泛素结合酶e2(ubiquitin-conjugatingenzyme)是一个多基因家族,在动物和人类中的数量涉及100多种。该途径广泛参与植物激素信号转导,在维持细胞功能以及细胞周期运转、抵御环境胁迫、激素响应、胚胎发育和衰老等方面发挥着重要的作用。
植物泛素化研究在拟南芥中最为深入,约1400个基因(占总蛋白质数量的约5%)编码蛋白泛素化系统的组分(王金利等,2010)。其中,e2基因有37个,e2-like基因8个(estellemetal.2004)。e2蛋白由150个氨基酸组成的保守催化结构域组成,内含一个高度保守的半胱氨酸保守位点。植物在生长发育过程中,有时会受到各种非生物胁迫。而相关研究表明泛素蛋白酶体途径在植物非生物胁迫中发挥着重要作用(leehetal.2001)。而泛素结合酶e2基因在泛素蛋白酶体途径充当着重要的角色。同时,某些e2蛋白也有着调节植物生长发育的重要作用(wanxetal.2011)。尽管在许多物种中泛素结合酶的许多基因已被确定,但是泛素e2结合酶ubc基因在大豆中的报道相对较少,因而,大豆e2泛素结合酶基因功能仍需进一步的实验验证。
技术实现要素:
本发明的目的在于提供公开一个e2泛素结合酶基因gmubc1。
本发明的另一目的是提供该基因在种子千粒重以及氨基酸含量的基因工程应用。
本发明的目的可通过如下技术方案实现:
大豆e2泛素结合酶基因gmubc1,核苷酸序列为seqidno.1。
本发明所述的大豆e2泛素结合酶基因gmubc1编码的蛋白质,其氨基酸序列为seqidno.2。
含有本发明所述的大豆e2泛素结合酶基因gmubc1的表达载体。
本发明所述的大豆e2泛素结合酶基因gmubc1在提高植物种子千粒重以及氨基酸含量的基因工程应用。
所述的gmubc1转基因拟南芥种子千粒重增加,氨基酸含量提高。
本发明所述的含大豆e2泛素结合酶基因gmubc1的表达载体在提高植物种子千粒重以及氨基酸含量的基因工程应用。
使用gmubc1构建植物表达载体时,在其转录起始核苷酸前可加上任何一种增强型启动子或诱导型启动子。为了便于对转基因植物细胞或植物进行鉴定及筛选,可对所用植物表达载体进行加工,如加入可在植物中表达的选择性标记基因(gus基因、gfp基因等)或者抗生素标记物(庆大霉素标记物、卡那霉素标记物、潮霉素标记物等)的抗性基因。从转基因植物的安全性考虑,可不加任何选择性标记基因,直接以表型性状筛选转化植株。
携带有本发明gmubc1的植物表达载体可通过使用ti质粒、ri质粒、植物病毒载体、直接dna转化、显微注射、电导、农杆菌介导等常规生物学方法转化植物细胞或组织,并将转化的植物组织培育成植株。被转化的植物宿主既可以是水稻、小麦、玉米等单子叶植物,也可以是烟草、拟南芥、大豆、油菜、黄瓜、番茄、杨树、草坪草、苜蓿等双子叶植物。
有益效果:
本发明中gmubc1属于e2泛素结合酶家族,该家族基因具有一个ubcc结构域。通过组织表达分析发现gmubc1主要在花和种子中表达,亚细胞定位显示gmubc1蛋白定位于整个细胞中。拟南芥中过表达gmubc1,发现与对照野生型拟南芥相比,转基因拟南芥种子的千粒重以及各组分氨基酸含量和总氨基酸含量提高。而且在胁迫处理材料中,基因的表达量在干旱、低温、激素ja、aba处理下表达量都显著下调,在盐处理条件下基因表达量显著上调。本发明公开了该基因促使植株果实千粒重增加,氨基酸含量提高的生物功能,可以通过定向地改造作物的果实重量以及氨基酸含量,为农作物提高品质。
利用植物过表达载体pmdc83-gmubc1,将本发明的gmubc1导入植物体内,可以调控植株果实发育,获得转基因植株。
附图说明
下面结合附图及实施例对本发明做进一步说明。
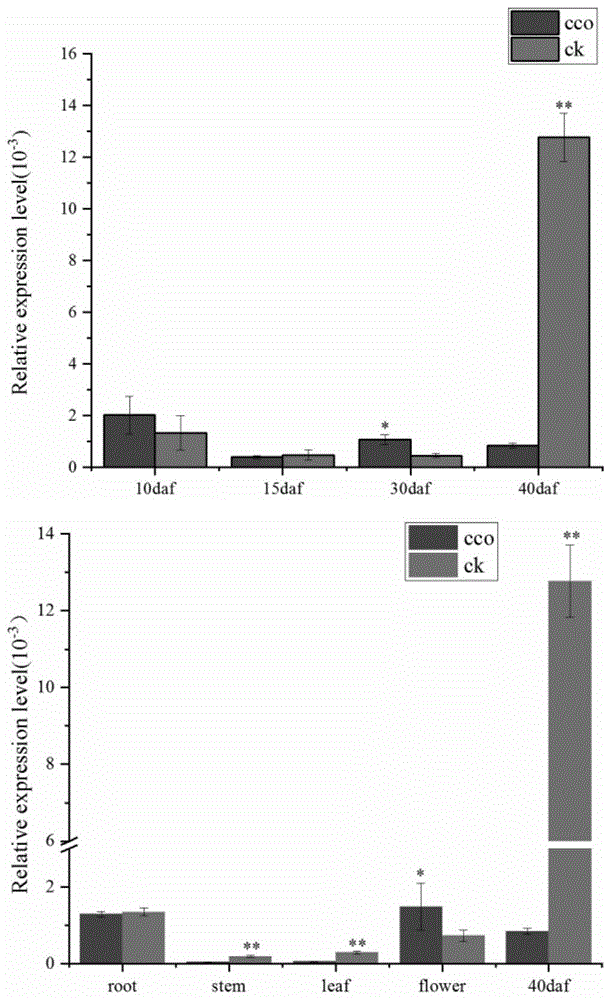
图1gmubc1基因的组织表达分析。
采用实时荧光定量pcr技术对gmubc1在大豆南农94-16以及cco的不同组织表达进行研究,大豆不同组织分别为根、茎、叶、花、7d种子、10d种子、15d种子、30d种子、45d种子。
图2gmubc1的亚细胞定位
(a)d35s::gfp;(b)d35s::gmubc1-gfp;
图3转基因拟南芥的pcr鉴定。
1-9为不同的转基因株系;11为野生型拟南芥、12为水(阴性对照);10:为pmdc83-gmubc1重组质粒(阳性对照)。
图4转基因拟南芥和野生型拟南芥千粒重比较
*表示0.01<p<0.05水平下显著差异;**表示p<0.01水平下极显著差异;
图5转基因拟南芥和野生型拟南芥氨基酸含量比较
*表示0.01<p<0.05水平下显著差异;**表示p<0.01水平下极显著差异;
具体实施方式
下面结合附图和实施例,并参照数据进一步详细地描述本发明。这些实施例只是为了举例说明本发明,而非以任何方式限制本发明的范围。在以下的实施例中,未详细描述的各种过程和方法是本领域中公知的常规方法。所用到的引物,均在首次出现时标明,其后所用相同引物,均以首次标明的内容相同。
实施例1大豆gmubc1及其编码基因的克隆与鉴定
根据phytozome网站预测的gmubc1序列信息设计引物,以栽培大豆品种“南农94-16”的花cdna为模板pcr扩增。
上游引物gmubc1f1:tttgctgattctctcggcgt;(seqidno.3)
下游引物gmubc1r1:aggtaactggaaactgcgagg。(seqidno.4)
应用rt-pcr方法,从大豆花器官总rna中扩增gmubc1基因。取大豆花组织,用研钵研碎,加入盛有裂解液的1.5mlep管,充分振荡后,再移入玻璃匀浆器内。匀浆后移至1.5mlep管中,采用植物总rna提取试剂盒(tiangendp404)进行总rna提取。用甲醛变性胶电泳鉴定总rna质量,然后在分光光度计上测定rna含量。以获得的总rna为模板,按照takara公司提供的反转录试剂盒的说明书进行反转录,合成cdna第一链。进行pcr扩增反应。pcr反应体系为:2μlcdna(0.05μg)、上、下游引物各2μl(10μm)、25μl2×phantamaxbuffer、1μldntp(10mm)和1uphantamaxsuper-fidelitydna聚合酶(vazyme),用超纯水补足50μl。pcr程序如下:在bio-radptc200型pcr仪上进行,其程序为94℃预变性3min;94℃变性15s,58℃退火15s,72℃延伸45s,共30个循环;然后72℃延伸5min终止反应,4℃保存。pcr产物回收将其克隆至pmd19-t载体,测序后获得具有完整编码区的大豆基因gmubc1的cdna序列seqidno.1,全长462bp,利用ncbi网站预测基因的保守结构域,该基因在8-151位具有一个ubcc结构域。根据phytozome网站下载gmubc1基因的氨基酸序列信息,gmubc1编码153个氨基酸,序列如seqidno.2所示。
实施例2gmubc1在大豆不同器官中的表达特征
提取大豆突变体cco和南农94-16根、茎、叶、花、7d种子、10d种子、15d种子、30d种子、45d种子的rna,反转成cdna进行rt-pcr分析。
总rna的提取同实施例1。以大豆组成型表达基因tubulin为内参基因,其扩增引物为tubulin正向引物序列:ggagttcacagaggcagag(seqidno.5),tubulin反向引物序列:cacttacgcatcacatagca(seqidno.6)。以来自大豆不同组织或器官的cdna为模板,进行实时荧光定量pcr分析。gmubc1的扩增引物为:gmubc1f2:ggcgttgttcatttctgtctca(seqidno.7),gmubc1r2:tcgagttcgattgcaaaacgt(seqidno.8)。结果(图1)分析表明gmubc1在种子发育不同时期的表达量均较高,其中在开花后30天种子中cco表达量显著低于wt,而在开花后40天的种子中,cco表达量极显著高于wt。同时,gmubc1在花和种子中的表达相对较高,表明gmubc1可能与大豆种子发育相关。
实施例3gmubc1的亚细胞定位
亚细胞定位采用洋葱表皮细胞表达的方法,利用新鲜的洋葱,在打基因枪的前一天在超净台内剥取合适的内表皮,紧密贴合在ms固体培养基平板上,黑暗过夜培养,第二天待用。以测序正确的连接有全长gmubc1cdna的载体为模板,扩增gmubc1基因的开放阅读框,将其与gfp报告基因融合,形成一个gmubc1-gfp的嵌合基因。质粒包裹好金粉之后利用基因枪法打入洋葱表皮细胞中表达,进行基因枪轰击后的洋葱表皮在室温暗环境下培养一天后可进行激光共聚焦显微镜观察。结果如图2所示,转入空载质粒在整个细胞中都有分布,gmubc1:gfp融合蛋白也分布于整个细胞中,表明gmubc1可能在整个细胞中都发挥功能。
实施例4gmubc1的基因工程
以连接到pmd19-t载体上的全长gmubc1cdna质粒为模板,用cds序列引物加载体接头序列gmubc1f2(seqidno.10):ggggacaagtttgtacaaaaaagcaggcttcatggccaacagcaacctccc;gmubc1r2(seqidno.11):ggggaccactttgtacaagaaagctgggtctcagacgccactagcatata用gateway系统的bp反应将其完整的orf通过同源重组构建到入门载体pdornor221上面。测序正确后进行lr反应,将入门克隆产物与表达载体通过重组交换,将目的基因gmubc1转化到pmdc83载体上,即完成pmdc83-gmubc1表达载体构建。转化dh5α大肠杆菌感受态,涂布于具有卡那霉素抗性的lb固体培养基上,37℃培养12-16h后挑单克隆,菌检阳性的送测序,测序正确菌液提质粒,命名为pmdc83-gmubc1(dh5α)。pmdc83-gmubc1(dh5α)转化根癌农杆菌eha105感受态,得到pmdc83-gmubc1农杆菌菌液
用蘸花法侵染拟南芥获得转基因拟南芥株系,提取初步筛选得到具有潮霉素抗性的转基因拟南芥的基因组dna,pcr扩增结果显示1-9号为阳性株系(图3)。结果表明gmubc1可在转基因拟南芥中表达(图3)。
对gmubc1转基因拟南芥进行表型观察。在22℃、长日照的生长条件下,gmubc1转基因拟南芥与对照相比,转基因拟南芥株系种子千粒重极显著增加,氨基酸含量显著提高(图4、图5)。
序列表
<110>南京农业大学
<120>大豆e2泛素结合酶基因gmubc1的应用
<160>10
<170>siposequencelisting1.0
<210>1
<211>462
<212>dna
<213>大豆(glycinemax)
<400>1
atggccaacagcaacctccctcgaagaatcatcaaggaaacgcagcgtttgctcagtgag60
ccagcaccaggaattagtgcctccccttctgaagagaatatgcgatatttcaatgtgatg120
atccttgggccaacccagtcgccttatgaaggaggagttttcaagttagaactatttttg180
ccagaagaatatccaatggctgctccaaaggttaggtttctaacaaaaatatatcatcca240
aacattgataagcttggcaggatttgtcttgatattctgaaagataagtggagtcctgcc300
cttcagatccgcactgttctactaagcattcaagctctattaagtgcaccaaacccagat360
gatccactttctgagaacattgccaagcattggaaatctaatgaggctgaggctgtcgaa420
acagcgaaggaatggacccgattatatgctagtggcgtctga462
<210>2
<211>153
<212>prt
<213>大豆(glycinemax)
<400>2
metalaasnserasnleuproargargileilelysgluthrglnarg
151015
leuleusergluproalaproglyileseralaserprosergluglu
202530
asnmetargtyrpheasnvalmetileleuglyprothrglnserpro
354045
tyrgluglyglyvalphelysleugluleupheleuprogluglutyr
505560
prometalaalaprolysvalargpheleuthrlysiletyrhispro
65707580
asnileasplysleuglyargilecysleuaspileleulysasplys
859095
trpserproalaleuglnileargthrvalleuleuserileglnala
100105110
leuleuseralaproasnproaspaspproleusergluasnileala
115120125
lyshistrplysserasnglualaglualavalgluthralalysglu
130135140
trpthrargleutyralaserglyval
145150
<210>3
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>3
tttgctgattctctcggcgt20
<210>4
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>4
aggtaactggaaactgcgagg21
<210>5
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>5
ggagttcacagaggcagag19
<210>6
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>6
cacttacgcatcacatagca20
<210>7
<211>22
<212>dna
<213>人工序列(artificialsequence)
<400>7
ggcgttgttcatttctgtctca22
<210>8
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>8
tcgagttcgattgcaaaacgt21
<210>9
<211>51
<212>dna
<213>人工序列(artificialsequence)
<400>9
ggggacaagtttgtacaaaaaagcaggcttcatggccaacagcaacctccc51
<210>10
<211>50
<212>dna
<213>人工序列(artificialsequence)
<400>10
ggggaccactttgtacaagaaagctgggtctcagacgccactagcatata50
- 还没有人留言评论。精彩留言会获得点赞!
- 一种新的多肽——人泛素-结合酶9和编码这种多肽的多核苷酸的制作方法
- 调节去泛素化酶和泛素化多肽的方法和材料的制作方法
- 一种新的多肽——人泛素结合酶9.46和编码这种多肽的多核苷酸的制作方法
- 一种新的多肽——人泛素-结合酶48和编码这种多肽的多核苷酸的制作方法
- 一种新的多肽——人泛素-结合酶17和编码这种多肽的多核苷酸的制作方法
- 一种新的多肽——人泛素活化酶37和编码这种多肽的多核苷酸的制作方法
- 用真核表达系统制备泛素结合酶UbcH10的方法
- 一种珠磨破碎结合酶法从脱脂米糠中提取米糠蛋白的方法
- 一种新的多肽-泛素-结合酶10和编码这种多肽的多核苷酸的制作方法
- 一种新的多肽——人泛素活化酶 e1-13.53和编码这种多肽的多核苷酸的制作方法
- 泛素活化酶的吡唑并嘧啶基抑制剂的制作方法
- 一种新的多肽——人泛素-结合酶48和编码这种多肽的多核苷酸的制作方法
- 一种新的多肽——人泛素-结合酶17和编码这种多肽的多核苷酸的制作方法
- 一种新的多肽——人泛素活化酶37和编码这种多肽的多核苷酸的制作方法
- 一种检测待测蛋白是否为泛素连接酶的底物的方法
- 一种新的多肽——泛素-蛋白酶18和编码这种多肽的多核苷酸的制作方法
- 一种新的多肽-泛素-结合酶10和编码这种多肽的多核苷酸的制作方法
- 一种新的多肽——人泛素活化酶 e1-13.53和编码这种多肽的多核苷酸的制作方法
- 一种新的多肽——人泛素特异性蛋白酶47.19和编码这种多肽的多核苷酸的制作方法
- 一种新的多肽——泛素-结合酶10.56和编码这种多肽的多核苷酸的制作方法