一种短须裂腹鱼热应激蛋白HSP70基因、检测方法及其应用与流程
本发明属于生物技术领域,尤其涉及一种短须裂腹鱼热应激蛋白hsp70基因、检测方法及其应用。
背景技术:
热应激蛋白作为分子伴侣,是进化上高度保守、功能上至关重要的蛋白,广泛存在于从低等原核生物到高等哺乳动物的整个生物界。hsp70是hsps家族中的重要成员之一,它在正常情况呈低水平的本底表达,在应激条件下(温度、渗透压、炎症、微生物感染、重金属、饥饿和缺氧等)可诱导上调表达,它作为分子伴侣参与蛋白质合成、折叠、装配和运输,可以修复和降解部分变性或已损坏的蛋白,从而增强机体的抗应激能力。hsp70作为生物体抗逆的重要分子,其表达水平的高低可以作为评价机体应激程度和应激能力的重要指标。
短须裂腹鱼(schizothoraxwangchiachii)隶属于鲤形目、鲤科、裂腹鱼亚科、裂腹鱼属,主要分布于金沙江、乌江和雅砻江;因过度捕捞、环境污染、水电开发等原因,野生短须裂腹鱼资源越来越少,目前已经开展人工养殖。
但是,目前,有关于短须裂腹鱼的热应激蛋白hsp70基因还没有相关的报道,其序列也未知,阻碍了对短须裂腹鱼应激能力检测的研究的发展。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种短须裂腹鱼热应激蛋白hsp70基因、检测方法及其应用。
本发明是这样实现的,一种短须裂腹鱼热应激蛋白hsp70基因,所述热应激蛋白hsp70基因的核苷酸序列见seqidno.13。
进一步,所述热应激蛋白hsp70基因编码的蛋白的氨基酸序列见seqidno.14。
一种如上所述的短须裂腹鱼热应激蛋白hsp70基因的全序列检测方法,包括以下步骤:
步骤1:提取短须裂腹鱼rna;
步骤2:以步骤1中提取的rna为模板,合成cdna;
步骤3:根据已知的hsp70基因的保守区序列设计引物,以步骤2中获取的cdna为模板,克隆hsp70的中间部分序列;
步骤4:获取目标基因5’端序列;
步骤5:获取目标基因3’端序列;
步骤6:将步骤3、步骤4和步骤5获得的序列进行全长拼接,获得完整的短须裂腹鱼热应激蛋白hsp70基因的全序列。
进一步,步骤3中根据已知的hsp70基因的保守区序列设计引物的序列见seqidno.1和seqidno.2。
进一步,步骤4和步骤5中分别采用5′race试剂盒和3′race试剂盒获取目标序列。
一种如上所述的短须裂腹鱼热应激蛋白hsp70基因在短须裂腹鱼应激能力检测中的应用。
进一步,检测方法包括针对所述短须裂腹鱼热应激蛋白hsp70基因设计的引物序列,分别见seqidno.15和seqidno.16。
综上所述,本发明的优点及积极效果为:
本发明从短须裂腹鱼的肝脏提取总rna,反转录得到cdna第一条链,采用race扩增法进行hsp70基因5'-和3'-序列的克隆,利用软件对克隆得到的hsp70cdna部分序列、5'-和3'-序列进行拼接成为hsp70cdna全长序列。2348个碱基,开放阅读框(orf)1950个碱基,编码649个氨基酸。采用荧光实时定量pcr技术检测肝、肾、脾组织中hsp70的表达量。为研究短须裂腹鱼hsp70表达调控机理奠定基础。
目前,短须裂腹鱼的热应激蛋白hsp70基因的检测方法和组织表达的检测方法还没有相关的报道,本发明则可填补这一技术空白,对于深入研究其应激调节中的生物学功能提供理论依据。
附图说明
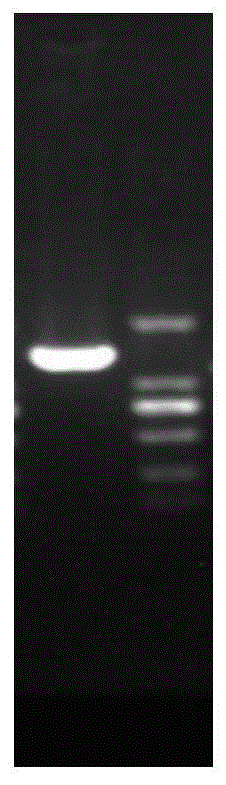
图1是获取中间片段产物的电泳结果;
图2是获取5’端序列产物的电泳结果;
图3是获取3’端序列产物的电泳结果;
图4是hsp70基因全长序列及氨基酸结果图;
图5是短须裂腹鱼不同组织中hsp70基因mrna水平的相对表达量;
图6是实施例3中肝脏中hsp70基因mrna水平的相对表达量;
图7是实施例3中脾中hsp70基因mrna水平的相对表达量;
图8是实施例3中肾中hsp70基因mrna水平的相对表达量。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例对本发明进行进一步详细说明,各实施例及试验例中所用的设备和试剂如无特殊说明,均可从商业途径得到。此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
本发明披露了一种短须裂腹鱼热应激蛋白hsp70基因、检测方法及其应用,具体如下各实施例所示。
实施例1目标基因克隆
步骤1:提取rna
1)短须裂腹鱼经过ms-222麻醉后解剖,快速分离肝胰脏组织置于冻存管,于液氮中速冻后转移-80℃保存备用。从液氮中取出肝脏组织约80mg,置于预冷的研钵中,趁液氮尚未挥发光时,将组织磨成粉末,并迅速加入1mltrizol。匀浆后,trizol/组织混合物室温放置5min,以便样本被trizol充分裂解。
2)每1mltrizol裂解的样本加入200μl氯仿即三氯甲烷。
3)盖严管盖,上下剧烈摇晃15秒。
4)室温放置3min。
5)在4℃下12000g离心15min。
6)离心后,管中液体将分层,转移最上层的无色液体(约总体积50%左右)至一个新的无rna酶的ep管中。注意:千万不能吸到下层的液体及悬浮在中间的白色沉淀物。吸取的时候,将ep管倾斜成45°角。
7)向新的上层液体中加500μl100%异丙醇。
8)室温放置10min。
9)在4℃下12000g离心10min。
10)小心吸去上清,加入75%乙醇,75%乙醇要用depc水配置。
11)上、下颠倒八次,7500g,4℃离心5min。
12)除去乙醇后,开盖室温放置5-10min,即得到纯化的rna。
13)depc水溶解后,琼脂糖电泳检测分子的完整情况,分光光度法检测其浓度。
步骤2:cdna的合成
该步骤使用fermentas公司的revertaidfirststrandcdnasynthesiskit试剂盒完成,具体如下:
1)在无rna酶的pcr管中加入1μg的总rna,和1μl的100μm的oligo(dt)引物,并用depc处理过的灭菌水加至体积12μl。
2)将上述混合液于65℃处理5分钟,然后在冰上立即冷却1分钟。
3)然后再在反应液中依次加入4μl5xreactionbuffer、1μlribolockrnaseinhibitor(20μ/μl)、2μl10mmdntpmix、1μlrevertaidm-mulvreversetranscriptase(200μ/μl)。
4)将其轻轻混匀,并短暂离心。
5)在pcr仪上42℃孵育1个小时。
6)70℃孵育5分钟结束反应。
步骤3:中间片段调取
根据已知的鱼类的hsp70基因的保守区序列设计引物即hsp70f:ctgggcaccacctactcctgtg,见seqidno.1和hsp70r:gtacagcttkgtsatgatkgggtt,见seqidno.2。以步骤2中获得的cdna为模板,进行pcr反应,克隆hsp70的部分序列。
pcr体系(50μl):15μlpcr-gradewater,25.0μl2xextaqbuffer(takara),1.0μldntpmix(10mm),1.0μlextaq(takara),5μlcdna,1.5μlprimerf(10x),1.5μlprimerr(10x)。
pcr程序:94℃变性4min后,94℃30s,55℃30s,72℃2min,35个循环,72℃10min。
pcr电泳结果如图1所示,其中marker为dl2000。pcr产物送至三方公司测序,结果见seqidno.3。
步骤4:获取5’端序列
该步骤采用invitrogen公司的5′racesystemforrapidamplificationofcdnaends,version2.0试剂盒获得目标基因的5’端序列。具体过程如下:
1)设计引物
a202-1(gsp-1):gcttggcatcaaagac,见seqidno.4;
a202-2(gsp-2):tcatggcgacctggtttt,见seqidno.5;
a202-3(gsp-3):gcagcatctccaatcaatct,见seqidno.6。
2)以步骤1中获取的总rna为模板,使用superscriptiirt酶和引物gsp-1对总rna进行目的基因第一链cdna的合成。并使用rnasemix对合成的cdna进行去rna处理。具体如下:
在0.5ml离心管中加入以反应液:
将混合物在70℃下孵育10分钟使rna变性。在冰上冷却1分钟。通过简单离心收集试管内容物,按如下顺序添加:
反应液1和2总体积24μl。轻轻拌匀,瞬时离心收集反应。42℃孵育1分钟;加入1μlofsuperscriptiirt,混合后42℃孵育50分钟;70℃孵育15分钟结束反应;反应在37℃离心10至20秒;加1μlrnase混合完全后,37℃孵化为30分钟;瞬时离心收集反应,并置于冰上。
3)使用dna纯化试剂盒:glassmaxdnaisolationspincartridges对经rnaase处理过的cdna进行纯化。
4)使用tdt酶和dctp对纯化后的cdna进行末端加上多聚c。
在每根试管中加入以下成分,混合均匀。
在94℃下孵育3分钟,在冰上冷却1分钟。瞬时离心收集试管内的物质并置于冰上。加入1μltdt,混合后37℃孵育10分钟。在65℃下加热10分钟使tdt失活。瞬时离心收集反应物置于冰上。
5)使用引物gsp-2和试剂盒里面带的桥连铆钉引物aap对已经加dc尾的cdna进行pcr第一轮扩增。
在0.5ml离心管中加入以下反应液,置于冰上。
之后加入0.5μltaqdna聚合酶(5units/μl)后混匀。直接将冰管转移到热循环器中,预平衡至初始变性温度94℃。pcr反应程序为:94℃预变性1min,94℃变性1min,55℃退火1min,72℃延伸2min,30个循环,循环结束后72℃,再延伸5min,4℃保存。
6)使用引物gsp-3和试剂盒里面带的桥连通用扩增引物auap进行巢式pcr第二轮扩增。
取5μl步骤5)的pcr反应产物加入495μltebuffer[10mmtris-hcl,(ph8.0),1mmedta]。
把下面的反应液加入到0.5ml离心管中。
加入0.5μltaqdna聚合酶(5units/μl)后混匀.
pcr反应程序为:94℃变性2min,1个循环;94℃变性2min;55℃退火30s,72℃延伸1min,30个循环,72℃10min,1个循环,4℃保存。电泳结果见图2,其中,marker为dl2000。将第二轮pcr产物进行电泳并对目的条带进行切胶回收纯化,送三方测序,结果见seqidno.7。
步骤5:获取3’端序列
该步骤采用clontech公司的smartertmracecdnaamplificationkit试剂盒获得目标基因的3’端序列。
1)设计引物
3’792-1:agggtgagcgtgcaatgaccaagga,见seqidno.8;
3’792-2:tcgtggtgttccccagattgaggtc,见seqidno.9。
2)以总rna为模板,使用逆转录酶试剂盒smartscribetmreversetranscriptase和引物3’cdsprimera(5'–aagcagtggtatcaacgcagactac(t)30vn–3')对总rna进行逆转录合成cdna。
在0.5ml的离心管中加入下面的反应液,混匀后离心。
在反应液中继续加入下面的成分。
混合均匀,瞬时离心。72℃孵育3min,然后42℃冷却2min,最后14000rpm离心10min。室温下,混匀下面的试剂:
将上述两种反应液混匀,离心。42℃孵育90min。70℃加热10min终止反应。
3)使用引物3’792-1和upm(5'-ctaatacgactcactatagggc-3',见seqidno.10;5'-:ctaatacgactcactatagggcaagcagtggtaacaacgcagagr-3',见seqidno.11),以上面合成的cdna为模板进行第一轮pcr扩增,实验方案同步骤4。
4)将第一轮pcr扩增产物稀释50倍,然后用引物3’792-2和upm进行第二轮pcr扩增,实验方案同步骤4。将第二轮pcr产物进行电泳,结果见图3,其中marker为dl2000。并对目的条带进行切胶回收纯化。回收产物送三方公司测序,结果见seqidno.12。
步骤6:全长拼接及orf预测
利用软件对所克隆的短须裂腹鱼hsp70基因中间部分序列、3'race和5'race序列进行分析并拼接成为hsp70基因全长序列,见图4,其中灰色为家族签名序列;单层方框内为核定位序列;双层方框内为终止信号序列;单下划线为多聚尾巴;双下划线为细胞质特征基序;糖基化位点为nksi,nvsa;靠近c末端四肽序列为gcmp。dna序列见seqidno.13,氨基酸序列见seqidno.14。
实施例2hsp70基因在短须裂腹鱼肝脏、肾脏、脾组织中的表达量
步骤1:提取肝脏、肾脏、脾组织中的总rna,反转录为cdna,方法同实施例1。
步骤2:根据短须裂腹鱼hsp70基因的全长序列,使用primer5.0软件设计荧光实时定量pcr特异性引物,引物序列如下:
hsp70f’:catgaaccccaccaacacag,见seqidno.15;
hsp70r’:tcacccttgtaatcaacctgga,见seqidno.16。
短须裂腹鱼内参基因序列:
actin-f:cctgttccagccatccttct,见seqidno.17;
actin-r:cagcaatgccagggtacatg,见seqidno.18。
步骤3:使用cfxconnecttm荧光定量pcr仪和power
pcr反应体系:总反应体系为20μl,内含cdna模板1μl,上下游引物各0.5μl(浓度为10μmol/l),sybrgreenpcrmastermix10μl和ddh2o8μl。pcr反应条件为95℃3min;95℃10s,45个循环;55℃20s,72℃30s;75.0℃5s,共40个循环,65~95℃进行熔解曲线分析。每个组织都做3个重复以减少误差。
步骤4:采用2–⊿⊿ct法(k.j.livak,t.d.schmittgen,analysisofrelativegeneexpressiondatausingreal-timequantitativepcrandthe2-δδctmethod,2001)计算肝脏、肾脏、脾组织中hsp70基因在mrna水平的相对表达量,用spss19.0软件进行单因素方差分析,duncan多重比较检验不同组织间差异显著性,p<0.05表示差异显著。
检测结果见图4,结果说明本发明针对克隆出的hsp70基因的全序列开发的检测体系能够顺利检测短须裂腹鱼不同组织中hsp70基因mrna水平的相对表达量。
实施例3周期性饥饿-投喂对短须裂腹鱼幼鱼肝脏、肾脏、脾组织hsp70基因表达影响研究实验设计:本发明设计1个对照组,三个饥饿处理组,每个处理三个重复,实验周期为8周。饥饿处理与投喂时间如下:
s0:对照组,实验期间每天饱食投喂,持续8周;
s1:每周第一天饥饿1天,饱食投喂6天,重复8周;
s2:每周第一、二天连续饥饿2天,饱食投喂5天,重复8周;
s3:每周第一、二、三天连续饥饿3天,饱食投喂4天,重复8周。
实验结束后检测各个处理组肝脏、肾脏、脾组织hsp70表达量,检测方法同实施例2。
结果如图6-8所示:周期性饥饿-投喂这种投喂方法不会影响hsp70在肝脏、脾脏中的表达量,会显著影响hsp70在肾组织中表达量,表明肾脏可以作为研究饥饿应激的靶器官,为深入研究饥饿诱导的应激提供基础数据依据。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
序列表
<110>水利部中国科学院水工程生态研究所
<120>一种短须裂腹鱼热应激蛋白hsp70基因、检测方法及其应用
<160>18
<170>siposequencelisting1.0
<210>1
<211>22
<212>dna
<213>人工序列(hsp70f)
<400>1
ctgggcaccacctactcctgtg22
<210>2
<211>24
<212>dna
<213>人工序列(hsp70r)
<400>2
gtacagcttkgtsatgatkgggtt24
<210>3
<211>1415
<212>dna
<213>中间序列(wh061200290hspf2r2hsp70-fzidai_pw_a11)
<400>3
atcatcgctaatgaccaaggaaacaggaccactccaagctatgtagctttcacagacagt60
gagagattgattggagatgctgcaaaaaaccaggtcgccatgaaccccaccaacacagtc120
tttgatgccaagcgtctgattggccgcaggtttgatgacggcgttgttcagtctgatatg180
aagcactggccttttaatgtcatcaatgacaatacccgtcccaaggtccaggttgattac240
aagggtgagaccaagagtttctaccctgaagagatttcctccatggttctcaccaagatg300
aaggaaattgctgaggcctacctgggaaagactgtttccaacgcggtcgtcacagtgcct360
gcctacttcaacgattctcagcgacaggctaccaaggatgctggaaccatctctggcttg420
aatgttctgcgtatcatcaatgaaccaactgctgctgctattgcttacggtctggacaaa480
aaggttggtgctgagaggaatgtcctcatctttgatcttggtggtggcactttcgatgtg540
tctatcctcaccattgaggatggcatcttcgaggtaaaatctactgctggagacactcac600
ttgggtggagaagactttgacaaccgcatggtgaaccactttatcacagagttcaagcgg660
aagcacaagaaggacatcagcgacaacaagagagccgttcgccgtctccgcaccgcctgc720
gagagggccaagcgtaccctatcctccagcactcaggccagtattgagatcgactccctc780
tatgagggtatcgatttctatacctccatcaccagggcccgttttgaggagctcaacgct840
gacctcttccgtggcaccttggacccagtcgaaaagtcacttcgtgacgccaagatggac900
aaggctcagatccatgatattgtcctggttggtggctccactcgcattcccaaaatccag960
aagctgctccaagactacttcaacggcaaggagcttaataagagcatcaaccctgatgag1020
gctgtggcctatggagcagccgttcaggctgccatcctctctggtgacaagtctgagaac1080
gttcaggacttgctgctgctagatgtcactcctctgtcccttggaattgagacagctggt1140
ggagtcatgactgtcctcatcaagcgtaataccactatcccaaccaaacagactcagact1200
ttcaccacctattccgacaaccagccaggtgtgctcattcaggtctatgagggtgagcgt1260
gcaatgaccaaggataacaacttgctgggcaagtttgagcttactggaatcccccctgca1320
cctcgtggtgttccccagattgaggtcacctttgacattgatgccaatggcatcatgaat1380
gtttcagctgttgataaaagcactggcaaggagaa1415
<210>4
<211>16
<212>dna
<213>人工序列(gsp-1)
<400>4
gcttggcatcaaagac16
<210>5
<211>18
<212>dna
<213>人工序列(gsp-2)
<400>5
tcatggcgacctggtttt18
<210>6
<211>20
<212>dna
<213>人工序列(gsp-3)
<400>6
gcagcatctccaatcaatct20
<210>7
<211>382
<212>dna
<213>5’端序列(5’)
<400>7
ccacgcgtcgactagtacgggggggggggcggtttactaacattcgctcttgtccgactg60
tgttaggctgccttttttccaggctcatttgctttactcccgagtcgagcgggcgggctg120
catgctctcttctaactaagcaaggcgaggcagtttgtcgccattccagctttccaaccg180
gcatcttcactcatctcggttatttccagcttgcgacaatgtccaagggaccagctgttg240
gtattgatctcgggaccacctactcctgtgtaggtgttttccaacatggaaaagttgaaa300
tcatcgctaatgaccaaggaaacaggaccactccaagctatgtagctttcacagacagtg360
agagattgattggagatgctgc382
<210>8
<211>25
<212>dna
<213>人工序列(3’792-1)
<400>8
agggtgagcgtgcaatgaccaagga25
<210>9
<211>25
<212>dna
<213>人工序列(3’792-2)
<400>9
tcgtggtgttccccagattgaggtc25
<210>10
<211>22
<212>dna
<213>人工序列(upm-f)
<400>10
ctaatacgactcactatagggc22
<210>11
<211>45
<212>dna
<213>人工序列(upm-r)
<400>11
ctaatacgactcactatagggcaagcagtggtaacaacgcagagr45
<210>12
<211>863
<212>dna
<213>3'端序列(3')
<400>12
tcgtggtgttccccagattgaggtcacctttgacattgatgccaatggcatcatgaatgt60
ttcagctgttgataagagcactggcaaggagaacaaaaccaccatcactaacgataaggg120
tcgtctcagcaaggaggacattgagcgcatggtgcaggaggcagagaagtacaagagtga180
ggatgatgtgcagcgcgacaaggtgtctgccaagaacggtctggaatcctattctttcaa240
catgaagtcaactgttgaggatgagaaactaaagggcaagatcagtgatgaggacaagca300
gaagatccttgacaagtgcaatgaagtcatcagttggcttgacaagaaccagactgctga360
gaaggaagagtttgagcaccagcagaaggagctggagaaggtatgtaaccccatcatcac420
caagctgtaccagggtgctggaggcatgccaggtggaatgcctgatggtatgcccggcgg480
cttcccaggagccggctctgctccaggaggtggatcctctggcccaaccattgaggaggt540
cgactaagcaattccaaagccactgcgctacctccatagcaatgattactgttgccctct600
gtagttggactcctctaaaattgttcttacggtctgtcttaagttttggatgacttcaac660
ttgcagagagattgttgcaattaaaaaaaaaaaagggggattaagggatcacagggaaca720
gattttctacctagattgcacaacctatttatcggcttgtgaaatgtgagtttcataagc780
cttttccaactgcctcaatgcctcaagtaaatgaataaaatggtgacttattccctaaaa840
aaaaaaaaaaaaaaaaaaaaaaa863
<210>13
<211>2348
<212>dna
<213>hsp70基因全长序列(hsp70)
<400>13
taagcaaggcgaggcagtttgtcgccattccagctttccaaccggcatcttcactcatct60
cggttatttccagcttgcgacaatgtccaagggaccagctgttggtattgatctcgggac120
cacctactcctgtgtaggtgttttccaacatggaaaagttgaaatcatcgctaatgacca180
aggaaacaggaccactccaagctatgtagctttcacagacagtgagagattgattggaga240
tgctgcaaaaaaccaggtcgccatgaaccccaccaacacagtctttgatgccaagcgtct300
gattggccgcaggtttgatgacggcgttgttcagtctgatatgaagcactggccttttaa360
tgtcatcaatgacaatacccgtcccaaggtccaggttgattacaagggtgagaccaagag420
tttctaccctgaagagatttcctccatggttctcaccaagatgaaggaaattgctgaggc480
ctacctgggaaagactgtttccaacgcggtcgtcacagtgcctgcctacttcaacgattc540
tcagcgacaggctaccaaggatgctggaaccatctctggcttgaatgttctgcgtatcat600
caatgaaccaactgctgctgctattgcttacggtctggacaaaaaggttggtgctgagag660
gaatgtcctcatctttgatcttggtggtggcactttcgatgtgtctatcctcaccattga720
ggatggcatcttcgaggtaaaatctactgctggagacactcacttgggtggagaagactt780
tgacaaccgcatggtgaaccactttatcacagagttcaagcggaagcacaagaaggacat840
cagcgacaacaagagagccgttcgccgtctccgcaccgcctgcgagagggccaagcgtac900
cctatcctccagcactcaggccagtattgagatcgactccctctatgagggtatcgattt960
ctatacctccatcaccagggcccgttttgaggagctcaacgctgacctcttccgtggcac1020
cttggacccagtcgaaaagtcacttcgtgacgccaagatggacaaggctcagatccatga1080
tattgtcctggttggtggctccactcgcattcccaaaatccagaagctgctccaagacta1140
cttcaacggcaaggagcttaataagagcatcaaccctgatgaggctgtggcctatggagc1200
agccgttcaggctgccatcctctctggtgacaagtctgagaacgttcaggacttgctgct1260
gctagatgtcactcctctgtcccttggaattgagacagctggtggagtcatgactgtcct1320
catcaagcgtaataccactatcccaaccaaacagactcagactttcaccacctattccga1380
caaccagccaggtgtgctcattcaggtctatgagggtgagcgtgcaatgaccaaggataa1440
caacttgctgggcaagtttgagcttactggaatcccccctgcacctcgtggtgttcccca1500
gattgaggtcacctttgacattgatgccaatggcatcatgaatgtttcagctgttgataa1560
gagcactggcaaggagaacaaaaccaccatcactaacgataagggtcgtctcagcaagga1620
ggacattgagcgcatggtgcaggaggcagagaagtacaagagtgaggatgatgtgcagcg1680
cgacaaggtgtctgccaagaacggtctggaatcctattctttcaacatgaagtcaactgt1740
tgaggatgagaaactaaagggcaagatcagtgatgaggacaagcagaagatccttgacaa1800
gtgcaatgaagtcatcagttggcttgacaagaaccagactgctgagaaggaagagtttga1860
gcaccagcagaaggagctggagaaggtatgtaaccccatcatcaccaagctgtaccaggg1920
tgctggaggcatgccaggtggaatgcctgatggtatgcccggcggcttcccaggagccgg1980
ctctgctccaggaggtggatcctctggcccaaccattgaggaggtcgactaagcaattcc2040
aaagccactgcgctacctccatagcaatgattactgttgccctctgtagttggactcctc2100
taaaattgttcttacggtctgtcttaagttttggatgacttcaacttgcagagagattgt2160
tgcaattaaaaaaaaaaaagggggattaagggatcacagggaacagattttctacctaga2220
ttgcacaacctatttatcggcttgtgaaatgtgagtttcataagccttttccaactgcct2280
caatgcctcaagtaaatgaataaaatggtgacttattccctaaaaaaaaaaaaaaaaaaa2340
aaaaaaaa2348
<210>14
<211>649
<212>prt
<213>hsp70氨基酸序列(hsp70)
<400>14
metserlysglyproalavalglyileaspleuglythrthrtyrser
151015
cysvalglyvalpheglnhisglylysvalgluileilealaasnasp
202530
glnglyasnargthrthrprosertyrvalalaphethraspserglu
354045
argleuileglyaspalaalalysasnglnvalalametasnprothr
505560
asnthrvalpheaspalalysargleuileglyargargpheaspasp
65707580
glyvalvalglnseraspmetlyshistrppropheasnvalileasn
859095
aspasnthrargprolysvalglnvalasptyrlysglygluthrlys
100105110
serphetyrproglugluilesersermetvalleuthrlysmetlys
115120125
gluilealaglualatyrleuglylysthrvalserasnalavalval
130135140
thrvalproalatyrpheasnaspserglnargglnalathrlysasp
145150155160
alaglythrileserglyleuasnvalleuargileileasnglupro
165170175
thralaalaalailealatyrglyleuasplyslysvalglyalaglu
180185190
argasnvalleuilepheaspleuglyglyglythrpheaspvalser
195200205
ileleuthrilegluaspglyilephegluvallysserthralagly
210215220
aspthrhisleuglyglygluasppheaspasnargmetvalasnhis
225230235240
pheilethrgluphelysarglyshislyslysaspileseraspasn
245250255
lysargalavalargargleuargthralacysgluargalalysarg
260265270
thrleuserserserthrglnalaserilegluileaspserleutyr
275280285
gluglyileaspphetyrthrserilethrargalaargphegluglu
290295300
leuasnalaaspleupheargglythrleuaspprovalglulysser
305310315320
leuargaspalalysmetasplysalaglnilehisaspilevalleu
325330335
valglyglyserthrargileprolysileglnlysleuleuglnasp
340345350
tyrpheasnglylysgluleuasnlysserileasnproaspgluala
355360365
valalatyrglyalaalavalglnalaalaileleuserglyasplys
370375380
sergluasnvalglnaspleuleuleuleuaspvalthrproleuser
385390395400
leuglyilegluthralaglyglyvalmetthrvalleuilelysarg
405410415
asnthrthrileprothrlysglnthrglnthrphethrthrtyrser
420425430
aspasnglnproglyvalleuileglnvaltyrgluglygluargala
435440445
metthrlysaspasnasnleuleuglylysphegluleuthrglyile
450455460
proproalaproargglyvalproglnilegluvalthrpheaspile
465470475480
aspalaasnglyilemetasnvalseralavalasplysserthrgly
485490495
lysgluasnlysthrthrilethrasnasplysglyargleuserlys
500505510
gluaspilegluargmetvalglnglualaglulystyrlysserglu
515520525
aspaspvalglnargasplysvalseralalysasnglyleugluser
530535540
tyrserpheasnmetlysserthrvalgluaspglulysleulysgly
545550555560
lysileseraspgluasplysglnlysileleuasplyscysasnglu
565570575
valilesertrpleuasplysasnglnthralaglulysglugluphe
580585590
gluhisglnglnlysgluleuglulysvalcysasnproileilethr
595600605
lysleutyrglnglyalaglyglymetproglyglymetproaspgly
610615620
metproglyglypheproglyalaglyseralaproglyglyglyser
625630635640
serglyprothrileglugluvalasp
645
<210>15
<211>20
<212>dna
<213>人工序列(hsp70f’)
<400>15
catgaaccccaccaacacag20
<210>16
<211>22
<212>dna
<213>人工序列(hsp70r’)
<400>16
tcacccttgtaatcaacctgga22
<210>17
<211>20
<212>dna
<213>人工序列(actin-f)
<400>17
cctgttccagccatccttct20
<210>18
<211>20
<212>dna
<213>人工序列(actin-r)
<400>18
cagcaatgccagggtacatg20
- 还没有人留言评论。精彩留言会获得点赞!