抗CD47的单克隆抗体及其用途的制作方法
抗cd47的单克隆抗体及其用途
技术领域
[0001]
本发明涉及自身免疫性疾病治疗和分子免疫学领域。涉及一种抗cd47的抗体、包含其的药物组合物及其用途。具体地,本发明涉及一种抗cd47的单克隆抗体。
背景技术:
[0002]
cd47又称为整合素相关蛋白(integrin associated protein,iap)。cd47为5次跨膜蛋白,分子量在50kda左右,属于免疫球蛋白超家族。其胞外n端为igv结构域,与αvβ3(cd51/cd61)和αiibβ3(cd41/cd61)整合素相连。cd47涉及多种生理功能,例如细胞转移,t细胞和树突细胞(dendritic cell,dc)激活,轴突发育等功能。
[0003]
cd47在包括红细胞在内的所有细胞类型上表达,同时在肿瘤细胞上cd47呈高表达。cd47有两种配体分别为信号调节蛋白α(signal regulatory proteinα,sirpα)和凝血酶敏感蛋白-1(thrombospondin-1,tsp1)。sirpα是一类含有免疫球蛋白结构域的受体型穿膜糖蛋白,属于sirp家族,主要在巨噬细胞和神经细胞上表达。在cd47-sirpα通路中,cd47蛋白与sirpα结合磷酸化其免疫受体酪氨酸抑制基序itim,随后细胞内招募shp-1蛋白,产生一系列的级联反应抑制巨噬细胞的吞噬作用(matozaki t,murata y,okazawa h,et al.functions and molecular mechanisms of the cd47-sirpα signalling pathway.trends in cell biology,2009,19(2):72-80.)。而正常红细胞由于细胞膜表面的cd47和巨噬细胞的siprα结合产生抑制性信号,从而不被吞噬。(oldenborg p a,zheleznyak a,fangy f,et al.role of cd47 as amarker of self on red blood cells.science,2000,288(5473):2051-2054.)。tsp1是由3条肽链组成的同源三聚体,与其它细胞表面受体、基质成分和生长因子相互作用参与细胞增殖、凋亡、粘附、迁移、血管生成等过程(jiang p,lagenaur cf,narayanan v.integrin-associated protein is a ligand for the p84 neural adhesion molecule.journal ofbiological chemistry 1999.274∶559-62)。
[0004]
巨噬细胞(macrophages)源自单核细胞,而单核细胞又来源于骨髓中的前体细胞。主要功能是以固定细胞或游离细胞的形式对细胞残片及病原体进行吞噬作用并激活淋巴细胞或其他免疫细胞,令其对病原体做出反应。目前研究认为肿瘤细胞具有逃逸巨噬细胞吞噬的机制,在肿瘤细胞生长过程中表面会形成特异性蛋白比如钙网蛋白,暴露肿瘤身份吸引巨噬细胞吞噬,但与此同时具有sirpα的巨噬细胞与高表达cd47的肿瘤细胞由于cd47-sirpα通路激活抑制巨噬细胞的吞噬作用,巨噬细胞误判为正常细胞致使肿瘤细胞逃逸巨噬细胞的吞噬(cd47 is upregulated on circulating hematopoietic stem cells and leukemia cells to avoid phagocytosis.jaiswal s,jamieson c h m,pang w w,et al.cell,2009,138(3)271-285)。
[0005]
目前研究发现认为,抗cd47抗体主要通过两种机理杀伤肿瘤细胞。1、抗cd47抗体与cd47结合阻断cd47-sirpα通路使巨噬细胞发挥吞噬作用。2、抗cd47抗体通过dc细胞和cd8+t细胞发挥肿瘤杀伤效应。dc细胞通过抗cd47抗体和亲吞噬分子如钙网蛋白协同作用,
吞噬肿瘤细胞,并提呈肿瘤相关抗原给cd8+t细胞,进而发挥cd8+t细胞对肿瘤的特异性杀伤作用(cd47 blockade as another immune checkpoint therapy for cancer.vonderheide r h.nature medicine,2015,21(10):1122)。结合这两个机理表明抗cd47抗体极有可能具有同时激活非特异性免疫以及特异性免疫的能力。
[0006]
目前,抗cd47单克隆抗体药物具有广泛的应用前景和良好的治疗肿瘤的效果,可用于多种肿瘤的治疗。抗cd47单克隆抗体药物hu5f9-g4,在临床前的实验中可以有效抑制恶性血液病和实体瘤的生长和转移(abstract pr13:the anti-cd47 antibody hu5f9-g4 is a novel immune checkpoint inhibitor with synergistic efficacy in combination with clinically active cancer targeting antibodies[j]chao m p,mckenna k m,cha a,et al.,2016)。
[0007]
因此,开发与cd47具有高亲和力的抗体药物,用于肿瘤的治疗,使其具有更好的治疗效果、更低的毒副作用,具有非常重要的意义。
技术实现要素:
[0008]
本发明人利用哺乳动物细胞表达系统表达出重组的人cd47,作为抗原免疫小鼠,经小鼠脾脏细胞与骨髓瘤细胞融合获得杂交瘤细胞。通过对大量样本的筛选,得到了如下的杂交瘤细胞株。
[0009]
本发明人发现:
[0010]
杂交瘤细胞株lt012能够分泌和cd47特异性结合的单克隆抗体(命名为6f7),并且该单克隆抗体能够与受体sirpα ecd-hfc-biotin竞争结合cd47,有效阻断sirpα与cd47的结合,进而促进巨噬细胞对肿瘤细胞的吞噬作用。
[0011]
进一步地,本发明人制得了单克隆抗体6f7的人源化抗体(命名为6f7h1l1、6f7h2l2和6f7h3l3)。
[0012]
本发明由此提供了下述发明:
[0013]
本发明的一个方面涉及抗体或其抗原结合片段,其中:
[0014]
所述抗体包含选自以下重链可变区和轻链可变区中包含的cdr序列
[0015]
(1)seq id no:2所示的重链可变区包含的hcdr1,hcdr2和hcdr3,和
[0016]
seq id no:4所示的轻链可变区包含的lcdr1,lcdr2和lcdr3;或
[0017]
(2)seq id no:12所示的重链可变区包含的hcdr1,hcdr2和hcdr3,和
[0018]
seq id no:14所示的轻链可变区包含的lcdr1,lcdr2和lcdr3;或
[0019]
(3)seq id no:16所示的重链可变区包含的hcdr1,hcdr2和hcdr3,和
[0020]
seq id no:18所示的轻链可变区包含的lcdr1,lcdr2和lcdr3;或
[0021]
(4)seq id no:20所示的重链可变区包含的hcdr1,hcdr2和hcdr3,和
[0022]
seq id no:22所示的轻链可变区包含的lcdr1,lcdr2和lcdr3;
[0023]
优选地,所述抗体包含:
[0024]
hcdr1,其包含seq id no:5所示的序列,与所述序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1个、2个或3个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成,
[0025]
hcdr2,其包含seq id no:6所示的序列,与所述序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1个、2个或3个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成,和
[0026]
hcdr3,其包含seq id no:7所示的序列,与所述序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1个、2个或3个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成,并且所述抗体还包含:
[0027]
lcdr1,其包含seq id no:8所示的氨基酸,或与所述序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1个、2个或3个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成,
[0028]
lcdr2,其包含seq id no:9所示的氨基酸序列,与所述序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1个、2个或3个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成,和
[0029]
lcdr3,其包含seq id no:10所示的序列,与所述序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1个、2个或3个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成。
[0030]
在本发明的实施方案中,所述抗体包括:
[0031]
(1)重链可变区,其包含下述序列或由下述序列组成:
[0032]
seq id no:2所示的氨基酸序列,或
[0033]
与seq id no:2所示的序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或
[0034]
与seq id no:2所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,和
[0035]
轻链可变区,其包含下述序列或由下述序列组成:
[0036]
seq id no:4所示的氨基酸序列,或
[0037]
与seq id no:4所示的序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或
[0038]
与seq id no:4所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列;
[0039]
(2)重链可变区,其包含下述序列或由下述序列组成:
[0040]
seq id no:12所示的氨基酸序列,或
[0041]
与seq id no:12所示的序列具有至少85%,优选86%,87%,88%,89%,90%,
91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或
[0042]
与seq id no:12所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,和
[0043]
轻链可变区,其包含下述序列或由下述序列组成:
[0044]
seq id no:14所示的氨基酸序列,或
[0045]
与seq id no:14所示的序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或
[0046]
与seq id no:14所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列;
[0047]
(3)重链可变区,其包含下述序列或由下述序列组成:
[0048]
seq id no:16所示的氨基酸序列,或
[0049]
与seq id no:16所示的序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或
[0050]
与seq id no:16所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,和
[0051]
轻链可变区,其包含下述序列或由下述序列组成:
[0052]
seq id no:18所示的氨基酸序列,或
[0053]
与seq id no:18所示的序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或
[0054]
与seq id no:18所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列;
[0055]
(4)重链可变区,其包含下述序列或由下述序列组成:
[0056]
seq id no:20所示的氨基酸序列,或
[0057]
与seq id no:20所示的序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或
[0058]
与seq id no:20所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,和
[0059]
轻链可变区,其包含下述序列或由下述序列组成:
[0060]
seq id no:22所示的氨基酸序列,或
[0061]
与seq id no:22所示的序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或
[0062]
与seq id no:22所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列。
[0063]
通过本领域技术人员所熟知的技术手段,例如通过vbase2数据库分析上面的(1)-(12)中的抗体序列的cdr区的氨基酸序列:
[0064]
本发明的抗体6f7,6f7 h1l1、6f7 h2l2和6f7 h3l3具有相同的hcdr1-3和lcdr1-3:
[0065]
其重链可变区的3个cdr区的氨基酸序列如下:
[0066]
hcdr1:gytftsyw(seq id no:5),
[0067]
hcdr2:idpsdset(seq id no:6),
[0068]
hcdr3:arlyrwyfdv(seq id no:7);
[0069]
其轻链可变区的3个cdr区的氨基酸序列如下:
[0070]
lcdr1:eivgty(seq id no:8),
[0071]
lcdr2:gas(seq id no:9),
[0072]
lcdr3:gqsynfpyt(seq id no:10)。
[0073]
在一些实施方案中,本发明的抗体选自以下各项组成的组:
[0074]
6f7 h1l1(g1m)重链的氨基酸序列(seq id no:59)
[0075]
6f7 h1l1(g1m)轻链的氨基酸序列(seq id no:60)
[0076]
6f7 h2l2(g1m)重链的氨基酸序列(seq id no:61)
[0077]
6f7 h2l2(g1m)轻链的氨基酸序列(seq id no:62)
[0078]
6f7 h3l3(g1m)重链的氨基酸序列(seq id no:63)
[0079]
6f7 h3l3(g1m)轻链的氨基酸序列(seq id no:64)
[0080]
6f7 h1l1(hg4)重链的氨基酸序列(seq id no:65)
[0081]
6f7 h1l1(hg4)轻链的氨基酸序列(seq id no:66)
[0082]
6f7 h2l2(hg4)重链的氨基酸序列(seq id no:67)
[0083]
6f7 h2l2(hg4)轻链的氨基酸序列(seq id no:68)
[0084]
6f7 h3l3(hg4)重链的氨基酸序列(seq id no:69)
[0085]
6f7 h3l3(hg4)轻链的氨基酸序列(seq id no:70)
[0086]
在本发明的实施方案中,所述抗体(优选6f7抗体)还包含重链可变区的框架区fr,优选地,所述框架区fr包含fr-h1,fr-h2,fr-h3和fr-h4,其中fr-h1包含seq id no:23的氨基酸序列或与seq id no:23所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:23所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成;fr-h2包含seq id no:24的氨基酸序列或与seq id no:24所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:24所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成;fr-h3包含seq id no:25的氨基酸序列或与seq id no:25所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:25所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基
no:42的氨基酸序列,或与seq id no:42所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:42所示的氨基酸序列相比具有一个或多个保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成。
[0091]
在本发明的实施方案中,所述抗体(优选6f7 h2l2抗体)还包含轻链可变区的框架区fr,优选地,所述框架区fr包含fr-l1,fr-l2,fr-l3和fr-l4,其中fr-l1包含seq id no:43的氨基酸序列,或与seq id no:43所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:43所示的氨基酸序列相比具有一个或多个保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成;fr-l2包含seq id no:44的氨基酸序列,或与seq id no:44所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:44所示的氨基酸序列相比具有一个或多个保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成;fr-l3包含seq id no:45的氨基酸序列,或与seq id no:45所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:45所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成;fr-l4包含seq id no:46的氨基酸序列,或与seq id no:46所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:46所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成。
[0092]
在本发明的实施方案中,所述抗体(优选6f7 h3l3抗体)还包含重链可变区的框架区fr,优选地,所述框架区fr包含fr-h1,fr-h2,fr-h3和fr-h4,其中fr-h1包含seq id no:47的氨基酸序列,或与seq id no:47所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:47所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成;fr-h2包含seq id no:48的氨基酸序列,或与seq id no:48所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:48所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成;fr-h3包含seq id no:49的氨基酸序列或,或与seq id no:49所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:49所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成;fr-h4包含seq id no:50的氨基酸序列,或与seq id no:50所示的序列具有至少80%,优选81%,
82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:50所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列或由其组成。
[0093]
在本发明的实施方案中,所述抗体(优选6f7 h3l3抗体)还包含轻链可变区的框架区fr,优选地,所述框架区fr包含fr-l1,fr-l2,fr-l3和fr-l4,其中fr-l1包含seq id no:51的氨基酸序列,或与seq id no:51所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:51所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成;fr-l2包含seq id no:52的氨基酸序列,或与seq id no:52所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:52所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成;fr-l3包含seq id no:53的氨基酸序列,或与seq id no:53所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:53所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成;fr-l4包含seq id no:54的氨基酸序列,或与seq id no:54所示的序列具有至少80%,优选81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与seq id no:54所示的氨基酸序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9或10个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,或由其组成。
[0094]
在本发明的一个方面,涉及分离的多肽,其包含seq id no:5,6和7所示的序列,其中所述多肽作为抗人cd47的抗体的一部分,特异性结合人cd47,所述抗体还包含seq id no:8,9和10所示的序列。
[0095]
在本发明的一个方面,涉及分离的多肽,其包含seq id no:8,9和10所示的序列,其中所述多肽作为抗人cd47的抗体的一部分,特异性结合人cd47,所述抗体还包含seq id no:5,6和7所示的序列。
[0096]
在本发明的一个方面,涉及分离的多肽,其包含选自seq id no:2,12,16或20所示的序列或与所述序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,其中所述多肽作为抗人cd47的抗体的一部分,特异性结合人cd47,所述抗体还分别对应包含选自seq id no:4,14,18或22所示的序列或与所述序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、
20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列;或者
[0097]
在本发明的一个方面,涉及分离的多肽,其包含选自seq id no:4,14,18或22所示的序列或与所述序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,其中所述多肽作为抗人cd47的抗体的一部分,特异性结合人cd47,所述单克隆抗体还对应包含选seq id no:2,12,16或20所示的序列或与所述序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列。
[0098]
在本发明的实施方案中,所述抗原结合片段选自fab、fab
′
、f(ab
′
)2、fd、fv、dab、fab/c、互补决定区(cdr)片段、单链抗体(例如,scfv)、双价抗体、结构域抗体。
[0099]
在本发明的实施方案中,所述抗体是人源化抗体、嵌合抗体、多特异性抗体(例如双特异性抗体)。
[0100]
在本发明的实施方案中,所述抗体以小于大约10-5
m,例如小于大约10-6
m、10-7
m、10-8
m、10-9
m或10-10
m或更小的kd结合人cd47蛋白。优选地,所述kd通过fortebio分子相互作用仪测得。
[0101]
在本发明的实施方案中,所述抗体以小于大约100nm,例如小于大约10nm、1nm、0.9nm、0.8nm、0.7nm、0.6nm、0.5nm、0.4nm、0.3nm、0.2nm、0.1nm或更小的ec50结合人cd47蛋白。具体地,所述ec50通过间接elisa方法测得。
[0102]
在本发明的实施方案中,所述抗体包括恒定区,且所述恒定区来自不是鼠类的物种,例如来自人抗体,优选来自人igg,更优选igg1或igg4。
[0103]
在本发明的实施方案中,所述抗体的恒定区是人源的,例如,重链恒定区采用ig gamma-1链c区,更优选genbank登记号为accession:p01857的ig gamma-1链c区(seq id no:58),或采用ig gamma-4链c区,更优选genbank登记号为accession:p01861.1的ig gamma-4链c区(seq id no:56);轻链恒定区均采用ig kappa链c区,更优选genbank登记号为accession:p01834的ig kappa链c区(seq id n o:57)。本发明的抗体在6f7h1l1、6f7 h2l2和6f7 h3l3的可变区基础上采用以下恒定区:重链恒定区为ig gamma-1chain c region,accession:p01857(seq id no:58)或重链恒定区ig gamma-4chain c region,accession:p01861.1(seq id no:56);轻链恒定区为ig kappa chain c region,accession:p01834(seq id no:57)。本发明的另一方面涉及编码多肽的分离的多核苷酸,所述多肽包含seq id no:5,6和7所示的序列,其中所述多肽作为抗人cd47的抗体的一部分,特异性结合人cd47,所述抗体还包含seq id no:8,9和10所示的序列。
[0104]
在本发明的一个方面,涉及编码多肽的分离的多核苷酸,所述多肽包含seq id no:8,9和10所示的序列,其中所述多肽作为抗人cd47的抗体的一部分,特异性结合人cd47,所述抗体还包含seq id no:5,6和7所示的序列。
[0105]
在本发明的一个方面,涉及编码多肽的分离的多核苷酸,所述多肽包含选自seq id no:2,12,16或20所示的序列或与所述序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,其中所述多肽作为抗人cd47的抗体的一部分,特异性结合人cd47,所述抗体还分别对应包含选自seq id no:4,14,18或22所示的序列或与所述序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列;或
[0106]
在本发明的一个方面,涉及编码多肽的分离的多核苷酸,所述多肽包含选自seq id no:4,14,18或22所示的序列或与所述序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列,其中所述多肽作为抗人cd47的抗体的一部分,特异性结合人cd47,所述抗体还分别对应包含选自seq id no:2,12,16或20所示的序列或与所述序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列,或与所述序列相比具有一个或多个(优选1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个)保守氨基酸突变(优选置换,插入或缺失)的氨基酸序列;
[0107]
具体地,所述多核苷酸分子包含下述序列或由下述序列组成:seq id no:1,seq id no:11,seq id no:15或seq id no:19所示的核苷酸序列,或与所述序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列。
[0108]
具体地,所述多核苷酸分子包含下述序列或由下述序列组成:seq id no:3,seq id no:13,seq id no:17或seq id no:21所示的核苷酸序列或与所述序列具有至少85%,优选86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%或99%以上序列同一性的序列。
[0109]
本发明的再一方面涉及一种载体,其包含本发明中如上所述任一个的多核苷酸分子。
[0110]
本发明的再一方面涉及一种宿主细胞,其包含本发明中如上所述任一个的多核苷酸分子,或者本发明的载体。
[0111]
本发明的再一方面涉及一种制备本发明中如上所述任一个的抗体或其抗原结合片段的方法,其包括在合适的条件下培养本发明的宿主细胞,以及从细胞培养物中回收所述抗体或其抗原结合片段的步骤。
[0112]
在本发明的一个方面,还提供了抗体偶联物,其包括所述抗人cd47的抗体或其抗原结合片段,以及与其偶联的偶联部分,所述偶联部分为纯化标签(如his标签)、细胞毒性
剂,或可检测的标记。优选地,所述偶联部分为放射性同位素、发光物质、有色物质、酶或聚乙二醇。
[0113]
在本发明的一个方面,还提供了多特异性抗体,优选双特异性抗体,其包括所述抗人cd47的抗体或其抗原结合片段,以及针对其他抗原和/或其他抗原表位的抗体或抗原结合片段。
[0114]
在本发明的一个方面,还提供了融合蛋白,其包括如上文任一个所述的抗人cd47的抗体或其抗原结合片段。
[0115]
在本发明的一个方面,还提供了试剂盒,其包括本发明中如上所述任一个的抗体或其抗原结合片段,或者包括本发明的抗体偶联物、多特异性抗体或融合蛋白。
[0116]
优选地,所述试剂盒还包括第二抗体,其特异性识别所述抗体或其抗原结合片段;任选地,所述第二抗体还包括可检测的标记,例如放射性同位素、发光物质、有色物质、酶或聚乙二醇。
[0117]
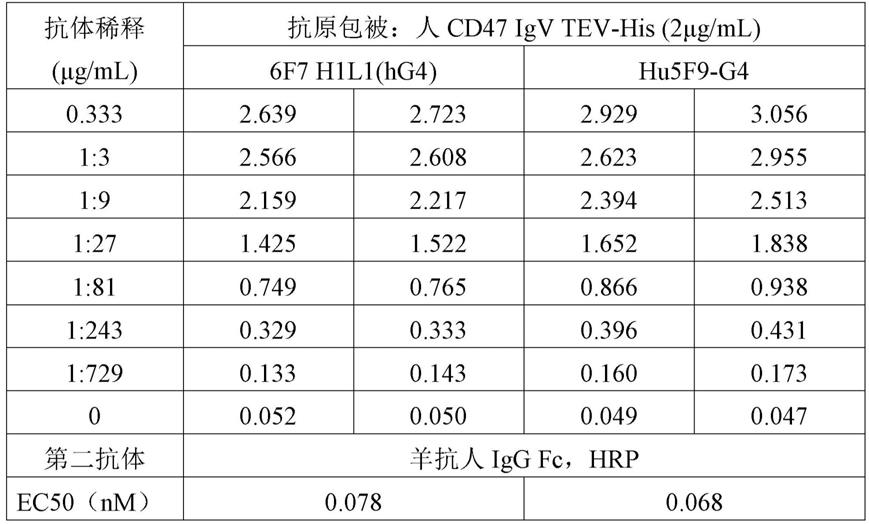
在本发明的一个方面,还提供了选自如下的杂交瘤细胞株以及由其产生的单克隆抗体:杂交瘤细胞株lt012,其保藏编号为cctcc no:2018135。
[0118]
本发明的再一方面,涉及本发明如上所述任一个所述的抗体或其抗原结合片段或者本发明的抗体偶联物或多特异性抗体或融合蛋白在检测人cd47在样品中的存在或其水平,或在制备检测人cd47在样品中的存在或其水平的试剂盒中的用途。
[0119]
本发明的再一方面,涉及一种药物组合物,其包含本发明中如上所述任一个的抗体或其抗原结合片段或者本发明所述的抗体偶联物,多特异性抗体或融合蛋白;可选地,其还包括药学上可接受的载体和/或赋形剂。
[0120]
本发明的再一方面,涉及如上所述任一个的抗体或其抗原结合片段或者本发明的抗体偶联物或多特异性抗体或融合蛋白在制备如下药物中的用途:
[0121]
阻断人cd47与人sirpα结合的药物,
[0122]
阻断人cd47活性或下调其水平的药物,或者
[0123]
阻断人sirpα与cd47结合所介导的细胞学反应的药物;
[0124]
在本发明的一个方面,涉及如上所述任一个的抗体或其抗原结合片段或者本发明的抗体偶联物或多特异性抗体或融合蛋白在治疗肿瘤或在制备治疗肿瘤的药物中的用途。
[0125]
本发明的再一方面涉及一种在体内或体外方法,包括施加含有本发明所述的抗体或其抗原结合片段、本发明的抗体偶联物、多特异性抗体或融合蛋白的细胞的步骤,或给予有需求的受试者以有效量的本发明中如上所述任一个的抗体或其抗原结合片段或者本发明的抗体偶联物或多特异性抗体或融合蛋白的步骤,所述方法选自如下各项:
[0126]
阻断cd47与人sirpα的结合的方法,
[0127]
阻断人cd47活性或下调其水平的方法,或者
[0128]
阻断人sirpα与cd47结合所介导的细胞学反应的方法。
[0129]
在本发明的实施方案中,所述体外方法是非治疗目的的或诊断目的的。
[0130]
本发明的再一方面涉及本发明中如上所述任一个的抗体或其抗原结合片段或者本发明的抗体偶联物或多特异性抗体或融合蛋白在预防和/或治疗和/或辅助治疗和/或诊断有关肿瘤或在制备预防和/或治疗和/或辅助治疗和/或诊断有关肿瘤的药物中的用途。
[0131]
在本发明的一个方面,所述肿瘤优选为表达cd47的肿瘤,优选癌症,例如恶性血液
肿瘤或实体瘤,更优选淋巴瘤、结肠癌或乳腺癌,更优选非霍奇金淋巴瘤,进一步更优选b细胞淋巴瘤细胞。
[0132]
在本发明的实施方案中,所述药物为适于注射的形式,优选是适于通过皮下注射、皮内注射、静脉内注射、肌内注射或病灶内注射施用的形式。
[0133]
在本发明中,除非另有说明,否则本文中使用的科学和技术名词具有本领域技术人员所通常理解的含义。并且,本发明中所用的细胞培养、分子遗传学、核酸化学、免疫学实验室操作步骤均为相应领域内广泛使用的常规步骤。同时,为了更好地理解本发明,下面提供相关术语的定义和解释。
[0134]
如本发明中所使用的,术语“抗原结合区”意指特异性结合指定抗原的蛋白或蛋白的部分。例如,含有与抗原相互作用并对抗体赋予其对于抗原的特异性和亲和力的氨基酸残基的抗体的该部分被称为“抗原结合区”。抗原结合区通常包括一或多个“互补决定区”(complementarity-determining region,“cdr”)。某些抗原结合区还包括一个或多个“框架”区(fragment region,“fr”)。cdr是促成抗原结合特异性和亲和力的氨基酸序列。
[0135]
如本发明中所使用的,术语“抗体”是指任何同种型的完整免疫球蛋白或可与完整抗体竞争对靶抗原的特异性结合的其抗原结合片段,并且包括,例如嵌合抗体、人源化抗体、全人源化抗体和双特异性抗体或其抗原结合片段。这样的“抗体”是抗原结合蛋白的种类。完整抗体通常包含至少两个全长重链和两个全长轻链,但在一些情况下,可包括更少的链,诸如可只包含重链的天然存在于骆驼科动物中的抗体。抗体或其抗原结合片段可只来源于单个来源,或可以是“嵌合的”,即,抗体的不同部分可来源于如下文中进一步描述的两个不同来源。抗体或其抗原结合片段可通过重组dna技术在杂交瘤中产生,或通过完整抗体的酶促或化学切割来产生。除非另外指出,否则术语“抗体”,除了包含两个全长重链和两个全长轻链的抗体外,还包括其衍生物、变体和片段。
[0136]
如本发明中所使用的,术语“抗体”或“免疫球蛋白链(重链或轻链)”的“抗原结合片段”(或简称“片段”),包含缺乏至少一些存在于抗体全长链中的氨基酸但能够特异性结合抗原的抗体的部分(无论如何获得或合成该部分)。此类片段具有生物活性,因为它们特异性结合靶抗原并且可与其它抗体或其抗原结合片段竞争对给定的表位的特异性结合。在一个方面,此类片段将保留至少一个存在于抗体全长轻链或重链中的cdr,并且在一些实施方案中将包含单个重链和/或轻链或其部分。这些生物活性片段可通过重组dna技术产生,或可以例如通过完整抗体的酶促或化学切割产生。免疫功能性免疫球蛋白片段包括,但不限于fab、fab’、f(ab’)2、fab/c、dab、fv、结构域抗体和单链抗体,并且可来源于任何哺乳动物来源,包括但不限于人、小鼠、大鼠、骆驼科动物或兔。还设想本文中公开的抗体的功能性部分例如一个或多个cdr可被共价地结合于第二蛋白或小分子以生成导向身体中的特定靶标的治疗剂,从而具有双功能治疗性质或具有延长的血清半衰期,例如融合蛋白。
[0137]
如本发明中所使用的,术语“抗体全长链”、“全长抗体”、“完整抗体(intact antibody)”和“全抗体(whole antibody)”在本文中可互换地用来指这样的抗体,所述抗体具有基本上与天然抗体结构相似的结构或具有如本文定义的fc区的重链。
[0138]
术语“轻链”包括全长轻链和其具有充足的可变区序列来赋予结合特异性的片段。全长轻链包括可变区结构域v
l
和恒定区结构域c
l
。轻链的可变区结构域在多肽的氨基末端。轻链包括κ链和λ链。
[0139]
术语“重链”包括全长重链和其具有充足的可变区序列来赋予结合特异性的片段。全长重链包括可变区结构域v
h
和3个恒定区结构域c
h1
、c
h2
和c
h3
。v
h
结构域在多肽的氨基末端,并且c
h
结构域在羧基末端,c
h3
最靠近多肽的羧基末端。重链可具有任何同种型,包括igg(包括igg1、igg2、igg3和igg4亚型)、iga(包括iga1和iga2亚型)、igm和ige。
[0140]
如本发明中所使用的,术语“fab片段”由一条轻链和c
h1
以及一条重链的可变区组成。fab分子的重链不能与另一条重链分子形成二硫键。
[0141]
如本发明中所使用的,术语“fc”区含有两个包含抗体的c
h1
和c
h2
结构域的重链片段。两个重链片段通过两个或更多个二硫键以及通过c
h3
结构域的疏水相互作用保持在一起。
[0142]
如本发明中所使用的,术语“fab’片段”含有一条轻链和一条重链的部分(其含有v
h
结构域和c
h1
结构域以及还有c
h1
与c
h2
结构域之间的区域的部分),以便可在两个fab’片段的两条重链之间形成链间二硫键以形成f(ab’)2分子。
[0143]
如本发明中所使用的,术语“f(ab’)2片段”含有两条轻链和两条含有c
h1
与c
h2
结构域之间的恒定区的部分的重链,以便在两条重链之间形成链间二硫键。f(ab’)2片段从而由通过两条重链之间的二硫键保持在一起的两个fab’片段组成。
[0144]
如本发明中所使用的,术语“fv区”包含来自重链和轻链的可变区,但缺乏恒定区。
[0145]
如本发明中所使用的,术语“fd”片段意指由v
h
和c
h1
结构域组成的抗体片段(ward等人,nature 341:544-546(1989))。
[0146]
如本发明中所使用的,术语“dab”片段(ward等人,nature 341:544-546(1989))由v
h
结构域组成。
[0147]
如本发明中所使用的,术语“fab
’-
sh”是本文对fab’的命名,其中恒定结构域的一个或多个半胱氨酸残基携带游离硫醇基团。
[0148]
如本发明中所使用的,术语“fab/c”片段是免疫球蛋白经胃蛋白酶消化形成的抗体裂解中间产物,其兼有fab和fc区的优点,即具有扩散能力强,体内代谢清除慢的特点,并能保持高度亲和力(刘建军,《细胞与分子免疫学杂志》,1989(4):29-29)。
[0149]
如本发明中所使用的,术语“单链抗体”是其中重链与轻链可变区通过柔性接头连接来形成单条多肽链(其形成抗原结合区)的fv分子(参见,例如,bird等人,science.242:423-426(1988)和huston等人,proc.natl.acad.sci.usa.90:5879-5883(1988))。单链抗体在国际专利申请公开号wo 88/01649和美国专利u.s.patent 4,946,778和u.s.patem 5,260,203(所述国际专利申请公开号和美国专利号的公开内容通过引用并入)中进行了详细描述。
[0150]
如本发明中所使用的,术语“结构域抗体”是只含有重链的可变区或轻链的可变区的免疫功能性免疫球蛋白片段,包括多价结构域抗体或双价结构域抗体。在一些情况下,两个或更多个v
h
区通过肽接头共价地连接,以生成多价结构域抗体(特别是双价结构域抗体)。双价结构域抗体的两个v
h
区可靶向相同或不同的抗原。
[0151]
如本发明中所使用的,术语“双价抗原结合蛋白”或“双价抗体”包含两个抗原结合位点。在一些情况下,两个结合位点具有相同抗原特异性。双价抗体可以是双特异性的。
[0152]
如本发明中所使用的,术语“多特异性抗原结合蛋白”或“多特异性抗体”是靶向不止一种抗原或表位的抗原结合蛋白或抗体。
[0153]
如本发明中所使用的,术语“双特异性”、“双重特异性”或“双功能性”抗原结合蛋白或抗体是分别具有两个不同的抗原结合位点的杂交抗原结合蛋白或抗体。双特异性抗体是一种多特异性抗原结合蛋白或多特异性抗体,并且可通过多种方法产生,包括,但不限于杂交瘤的融合或fab’片段的连接。参见,例如,songsivilai和lachmann,1990,clin.exp.immunol.79:315-321;kostelny等人,1992,j.immunol.148:1547-1553。双特异性抗原结合蛋白或抗体的两个结合位点将结合两个不同的表位,所述表位存在于相同或不同的蛋白质靶标上。
[0154]
如本发明中所使用的,术语“单抗”和“单克隆抗体”是指,来自一群高度同源的抗体分子中的一个抗体或抗体的一个片段,也即除了可能自发出现的自然突变外,一群完全相同的抗体分子。单抗对抗原上的单一表位具有高特异性。多克隆抗体是相对于单克隆抗体而言的,其通常包含至少2种或更多种的不同抗体,这些不同的抗体通常识别抗原上的不同表位。单克隆抗体通常可采用kohler等首次报道的杂交瘤技术获得(nature,256:495,1975),但也可采用重组dna技术获得(如参见u.s.p 4,816,567)。
[0155]
如本发明中所使用的,术语“人源化抗体”是指,人源免疫球蛋白(受体抗体)的全部或部分cdr区被一非人源抗体(供体抗体)的cdr区替换后得到的抗体或抗体片段,其中的供体抗体可以是具有预期特异性、亲和性或反应性的非人源(例如,小鼠、大鼠或兔)抗体。此外,受体抗体的框架区(fr)的一些氨基酸残基也可被相应的非人源抗体的氨基酸残基替换,或被其他抗体的氨基酸残基替换,以进一步完善或优化抗体的性能。关于人源化抗体的更多详细内容,可参见例如,jones et al.,nature,321:522 525(1986);reichmann et al.,nature,332:323 329(1988);presta,curr.op.struct.biol.,2:593 596(1992);和clark,immunol.today 21:397 402(2000)。
[0156]
如本发明中所使用的,术语“表位”是指,抗原上被免疫球蛋白或抗体特异性结合的部位。“表位”在本领域内也称为“抗原决定簇”。表位或抗原决定簇通常由分子的化学活性表面基团例如氨基酸或碳水化合物或糖侧链组成并且通常具有特定的三维结构特征以及特定的电荷特征。例如,表位通常以独特的空间构象包括至少3,4,5,6,7,8,9,10,11,12,13,14或15个连续或非连续的氨基酸,其可以是“线性的”或“构象的”。参见,例如,epitope mapping protocols in methods in molecular biology,第66卷,g.e.morris,ed.(1996)。在线性表位中,蛋白质与相互作用分子(例如抗体)之间的所有相互作用的点沿着蛋白质的一级氨基酸序列线性存在。在构象表位中,相互作用的点跨越彼此分开的蛋白质氨基酸残基而存在。
[0157]
术语“多肽”或“蛋白质”在本文中可互换地用于指氨基酸残基的聚合物。术语还用于其中一个或多个氨基酸残基是对应的天然存在的氨基酸的类似物或模拟物的氨基酸聚合物,以及用于天然存在的氨基酸聚合物。术语还可包括已例如通过添加糖类残基以形成糖蛋白而被修饰的或磷酸化的氨基酸聚合物。多肽和蛋白质可由天然存在的细胞和非重组细胞产生;或其由基因工程或重组细胞产生,并且包含具有天然蛋白质的氨基酸序列的分子,或具有天然序列的一个或多个氨基酸的缺失、添加和/或取代的分子。
[0158]
在一些实施方案中,术语“多肽”和“蛋白质”具体地包括抗体,例如抗人cd47抗体(也称为cd47抗体)、cd47结合蛋白、或其变体,例如具有一个或多个氨基酸的缺失、添加和/或取代的抗体或序列。
[0159]
术语“多肽片段”是指相较于全长蛋白质具有氨基末端缺失、羧基末端缺失和/或内部缺失的多肽。此类片段还可相较于全长蛋白质含有经修饰的氨基酸。在某些实施方案中,片段的长度为约5至500个氨基酸。例如,片段的长度可为至少5、6、8、10、14、20、50、70、100、110、150、200、250、300、350、400或450个氨基酸。有用的多肽片段包括抗体的免疫功能片段,包括结合结构域。在人cd47抗体的情况下,有用的片段包括但不限于cdr区、重链或轻链的可变结构域、抗体链的部分或正好其包括2个cdr的可变结构域等。
[0160]
多肽的“衍生物”是以与插入、缺失或取代变体不同的方式,例如通过另一种化学部分的缀合而化学修饰的多肽(例如,抗原结合蛋白或抗体),例如缀合peg的多肽。
[0161]
如本发明中所使用的,术语“分离的”或“被分离的”指的是,从天然状态下经人工手段获得的。如果自然界中出现某一种“分离”的物质或成分,那么可能是其所处的天然环境发生了改变,或从天然环境下分离出该物质,或二者情况均有发生。例如,某一活体动物体内天然存在某种未被分离的多聚核苷酸或多肽,而从这种天然状态下分离出来的高纯度的相同的多聚核苷酸或多肽即称之为分离的。术语“分离的”或“被分离的”不排除混有人工或合成的物质,也不排除存在不影响物质活性的其它不纯物质。
[0162]
如本发明中所使用的,术语“载体(vector)”是指,可将多核苷酸插入其中的一种核酸运载工具。当载体能使插入的多核苷酸编码的蛋白获得表达时,载体称为表达载体。载体可以通过转化,转导或者转染导入宿主细胞,使其携带的遗传物质元件在宿主细胞中获得表达。载体是本领域技术人员公知的,包括但不限于:质粒;噬菌粒;柯斯质粒;人工染色体,例如酵母人工染色体(yac)、细菌人工染色体(bac)或p1来源的人工染色体(pac);噬菌体如λ噬菌体或m13噬菌体及动物病毒等。可用作载体的动物病毒包括但不限于,逆转录酶病毒(包括慢病毒)、腺病毒、腺相关病毒、疱疹病毒(如单纯疱疹病毒)、痘病毒、杆状病毒、乳头瘤病毒、乳头多瘤空泡病毒(如sv40)。一种载体可以含有多种控制表达的元件,包括但不限于,启动子序列、转录起始序列、增强子序列、选择元件及报告基因。另外,载体还可含有复制起始位点。
[0163]
如本发明中所使用的,术语“宿主细胞”是指,可用于导入载体的细胞,其包括但不限于,如大肠杆菌或枯草芽孢杆菌等的原核细胞,如酵母细胞或曲霉菌等的真菌细胞,如s2果蝇细胞或sf9等的昆虫细胞,或者如纤维原细胞,cho细胞,cos细胞,nso细胞,hela细胞,bhk细胞,hek 293细胞或人细胞等的动物细胞。
[0164]
如本发明中使用的,术语“特异性结合”是指,两分子间的非随机的结合反应,如抗体和其所针对的抗原之间的反应。在某些实施方式中,特异性结合某抗原的抗体(或对某抗原具有特异性的抗体)是指,抗体以小于大约10-5
m,例如小于大约10-6
m、10-7
m、10-8
m、10-9
m或10-10
m或更小的亲和力(k
d
)结合该抗原。
[0165]
如本发明中所使用的,术语“k
d”是指特定抗体-抗原相互作用的解离平衡常数,其用于描述抗体与抗原之间的结合亲和力。在分子结合动力学测定的几个参数中,k
d
值为解离平衡常数,在抗体药物研究中,是表征被测抗体与靶抗原分子亲和作用的强弱的参数,计算方法为kd=kdis/kon,解离平衡常数越小,抗体-抗原结合越紧密,抗体与抗原之间的亲和力越高。kon,结合速率常数=抗原抗体复合物形成的速率,kon愈小提示抗体与抗原结合的速度愈快;kdis,解离速率常数=抗体从抗原-抗体复合物中解离的速率,kdis愈小即抗体从抗原上脱离的速度愈慢,抗体与抗原结合越稳固。通常,抗体以小于大约10-5
m,例如小
于大约10-6
m、10-7
m、10-8
m、10-9
m或10-10
m或更小的解离平衡常数(k
d
)结合抗原(例如,l1蛋白),例如,如使用表面等离子体共振术(spr)在biacore仪或fortebio分子相互作用仪中测定的。
[0166]
如本发明中所使用的,术语“单克隆抗体”和“单抗”具有相同的含义且可互换使用;术语“多克隆抗体”和“多抗”具有相同的含义且可互换使用;术语“多肽”和“蛋白质”具有相同的含义且可互换使用。并且在本发明中,氨基酸通常用本领域公知的单字母和三字母缩写来表示。例如,丙氨酸可用a或ala表示。
[0167]
如本发明中所使用的,术语“杂交瘤”和“杂交瘤细胞株”可互换使用,并且当提及术语“杂交瘤”和“杂交瘤细胞株”时,其还包括杂交瘤的亚克隆和后代细胞。
[0168]
如本文中使用的,术语
″
百分比序列同一性
″
与
″
百分比序列同源性
″
可互换使用。
[0169]
如本文中使用的,术语“相似性”或“序列相似性”、“同一性”是指两个或更多个蛋白质或多肽分子的序列之间的关系,如通过比对和比较序列测定的。“百分比同一性”意指被比较的分子中的氨基酸之间的相同残基的百分比,并且可基于待比较的最小的分子的大小来计算。为了进行这些计算,必须通过特定的数学模型或计算机程序(即,“算法”)来解决比对中的缺口(如果有的话)。当用于多肽时,术语
″
大体上的同一性
″
,是指两个肽序列,当例如使用程序gap或bestfit,利用程序提供的缺省缺口权重,进行最佳对齐时,共有至少70%、75%或80%的序列同一性,至少90%或95%的序列同一性,和至少97%、98%或99%的序列同一性。在某些情况下,不相同的残基位点相异在于保守氨基酸置换。”保守氨基酸置换”是这样的置换,即其中氨基酸残基被具有拥有相似化学性质(例如,电荷或正在水性)的侧链r基团的另一个氨基酸残基置换。一般地,保守氨基酸置换将基本上不改变蛋白质的功能性质。在其中两个或更多个氨基酸序列彼此相异在于保守置换的情况下,可上调百分比序列同一性以就置换的保守性质进行修正。用于进行该调整的方法对于本领域技术人员来说是熟知的。参见例如pearson,methods mol.biol.243:307-31(1994)。具有拥有相似化学性质的侧链的氨基酸组的实例包括1)脂肪族羟基侧链:甘氨酸、丙氨酸、缬氨酸、亮氨酸和异亮氨酸:2)脂肪族羟基侧链:丝氨酸和苏氨酸:3)含酰胺侧链:天冬酰胺和谷氨酰胺:4)芳香族侧链:苯丙氨酸、酪氨酸和色氨酸:5)碱性侧链:赖氨酸、精氨酸和组氨酸:6)酸性侧链:天冬氨酸和谷氨酸;和7)含硫侧链:半胱氨酸和甲硫氨酸。例如,保守氨基酸置换组是缬氨酸-亮氨酸-异亮氨酸-甘氨酸-丙氨酸、苯丙氨酸-酪氨酸、苏氨酸-丝氨酸、赖氨酸-精氨酸、谷氨酸-天冬氨酸和天冬酰胺-谷氨酰胺
[0170]
可选择地,保守置换是在gonnet等人,science 256:1443-45(1992)(通过引用合并入本文)中公开的pam250对数似然矩阵(pam250 log-likelihood matrix)中具有正值的任何变化。“中度保守的”置换是在pam250对数似然矩阵中具有非负值的任何变化。
[0171]
通常使用序列分析软件测量多肽的序列同一性。蛋白质分析软件使用分配给不同置换、缺失和其他修饰(包括保守氨基酸置换)的相似性的量度来匹配序列。例如,gcg包括程序例如
″
gap
″
和
″
bestfit
″
,所述程序(使用由程序指定的缺省参数)可用于测定密切相关的多肽(例如来自不同生物物种的同源多肽)之间或野生型蛋白质与其突变蛋白之间的序列同源性或序列同一性。参见,例如,gcg version 6.1(university of wisconsin,wi)。还可使用缺省或推荐的参数利用fasta比较多肽序列,参见gcg version 6.10 fasta(例如,fasta2和fasta3)提供质询序列与搜索序列之间最佳重叠的区域的比对和百分比序列同一
性(pearson,methods enzymol.183:63-98(1990):pearson,methods mo l.biol.132:185-219(2000))。当将序列与含有大量来自不同生物的序列的数据库相比较时,另一个优选算法是计算机程序blast,特别地blastp或tblastn(使用程序提供的缺省参数)。参见,例如,altschul等人,mol.biol.215:403-410(1990):al tschul等人,nucleic acids res.25:3389-402(1997)。
[0172]
相对于现有技术,本发明具有例如如下优点:
[0173]
本发明涉及的抗cd47单克隆抗体能通过特异性结合cd47,有效阻断sirpα与cd47的结合,进而促进巨噬细胞对肿瘤细胞的吞噬作用。本发明中的抗体(例如6f7 h1l1)对肿瘤细胞cd47亲和力与对照抗体hu5f9-g4相当,而对正常人rbc亲和力低于对照抗体hu5f9-g4,所以本发明抗体在尽量避免影响正常人红细胞的基础上,具有更佳的肿瘤治疗潜能。
附图说明
[0174]
图1 6f7 h1l1(hg4)与人cd47 igv tev-his的结合活性检测结果。
[0175]
图2 6f7 h1l1(g1m)与人cd47 igv tev-his的结合活性检测结果。图中6f7 h1l1(hg1dm)即为6f7 h1l1(g1m)。
[0176]
图3 6f7 h1l1(hg4)与人sirpα ecd-hfc-biotin竞争结合人cd47 igv tev-his的活性检测结果。
[0177]
图4 6f7h1l1(g1m)与人sirpα ecd-hfc-biotin竞争结合人cd47 igv tev-his的活性检测结果。图中6f7 h1l1(hgldm)即为6f7 h1l1(g1m)。
[0178]
图5鼠源抗体6f7与人cd47亲和力常数检测结果图。
[0179]
图6 6f7 h1l1(hg4)与人cd47亲和力常数检测结果图。
[0180]
图7 hu5f9-g4与人cd47亲和力常数检测结果图。
[0181]
图8 6f7 h1l1(g1m)与人rbc的结合曲线(facs)。
[0182]
图9 6f7 h1l1(g1m)与肿瘤细胞raji的结合活性(facs)。
[0183]
图10 6f7 h1l1(g1m)与sirp竞争结合lovo的活性检测(facs)。
[0184]
图11 6f7 h1l1(g1m)抗体对人红细胞的凝集作用。
[0185]
图12 6f7 h1l1(hg4)与人rbc的结合曲线(facs)。
[0186]
图13 6f7 h1l1(hg4)与肿瘤细胞raji的结合活性(facs)。
[0187]
图14 6f7 h1l1(hg4)与sirp竞争结合肿瘤细胞raji的竞争结合活性(facs)。
[0188]
图15 6f7 h1 l1(hg4)与肿瘤细胞lovo的结合曲线(facs)。
[0189]
图16 6f7 h1l1(hg4)与sirp竞争结合lovo的活性检测(facs)。
[0190]
图17抗-cd47抗体对人红细胞的凝集作用。
[0191]
图18 6f7 h1l1(hg4)对mda-mb-231皮下移植瘤的治疗作用。
[0192]
图19 6f7 h1l1(hg4)和hu5f9-g4食蟹猴单次给药后血红蛋白浓度变化。
[0193]
图20 6f7 h1l1(hg4)和hu5f9-g4食蟹猴单次给药后红细胞压积变化。
[0194]
关于生物材料保藏的说明:
[0195]
杂交瘤细胞株lt012,其于2018年6月21日保藏于中国典型培养物保藏中心(cctcc),保藏编号为cctcc no:c2018135,保藏地址为中国.武汉.武汉大学,邮编:430072。
具体实施方式:
[0196]
下面将结合实施例对本发明的实施方案进行详细描述。本领域技术人员将会理解,下面的实施例仅用于说明本发明,而不应视为限定本发明的范围。实施例中未注明具体技术或条件者,按照本领域内的文献所描述的技术或条件(例如参考j.萨姆布鲁克等著,黄培堂等译的《分子克隆实验指南》,第三版,科学出版社)或按照产品说明书进行。所用试剂或仪器未注明生产厂商者,为可以通过市场购买获得的常规产品。
[0197]
在本发明的下述实施例中,使用的balb/c小鼠购自广东省医学实验动物中心。
[0198]
所用的对照抗体药物为hu5f9-g4(中山康方生物医药有限公司合成,采用forty seven,inc.的cd47抗体hu5f9-g4序列制备而成,即us20150183874的seq id no:37作为重链可变区,seq id no:42作为轻链可变区,ig gamma-4链恒定区(genbankid:p01861.1))。
[0199]
实施例1:抗人cd47的抗体6f7的制备
[0200]
1.杂交瘤细胞株6f7的制备
[0201]
杂交瘤细胞株6f7的制备抗cd47抗体所用的抗原为cd47 igv tev-his(包括genbankid:np 942088.1位置:19-141人cd47成熟肽与tev(氨基酸序列为enlyfqg,seq id no:74)-his标签的融合蛋白,由中山康方生物医药有限公司合成)和3t3-cd47细胞(nih/3t3,厂家:atcc,货号:crl-1658,在nih/3t3的基础上转染上述人cd47成熟肽进细胞,构建3t3-cd47稳定表达系)。取免疫后小鼠的脾细胞与小鼠骨髓瘤细胞融合,制成杂交瘤细胞,分别以cd47 igv tev-his,3t3-cd47细胞作为抗原,对杂交瘤细胞进行间接elisa法筛选,获得能够分泌与cd47特异性结合的抗体的杂交瘤细胞。对elisa筛选得到的杂交瘤细胞,通过竞争elisa筛选出能够分泌与受体人sirpαecd-hfc-biotin(其中sirpαecd表示sirpα的胞外区,蛋白genbank登录号:np_542970.1的位置31-373;hfc为人igg fc纯化标签,具体为ig gamma-1chain c region,genbankid:p01857位置114-330)竞争结合人cd47 igv tev-his的单克隆抗体的杂交瘤细胞株,并经过有限稀释法得到稳定的杂交瘤细胞株。将以上杂交瘤细胞株命名为杂交瘤细胞株lt012,其分泌的单克隆抗体命名为6f7。
[0202]
杂交瘤细胞株lt012(cd47-6f7),其于2018年6月21日保藏于中国典型培养物保藏中心(cctcc),保藏编号为cctcc no:c2018135,保藏地址为中国.武汉.武汉大学,邮编:430072。
[0203]
2.抗cd47的抗体6f7的制备
[0204]
用cd培养基(chemical defined medium)对上面制得的lt011、lt012和lt015细胞株分别进行培养(cd培养基,内含1%青链霉素,于5%co2,37℃细胞培养箱中进行培养),7天后收集细胞培养上清,通过高速离心、微孔滤膜抽真空过滤以及hitrap protein a hp柱进行纯化,制得抗体6f7。
[0205]
实施例2:抗cd47的抗体6f7的序列分析
[0206]
按照培养细胞细菌总rna提取试剂盒(tiangen,货号dp430)的方法,从实施例1中培养的lt012细胞株中提取mrna。
[0207]
按照invitrogeniii first-strand synthesis system for rt-pcr试剂盒说明书合成cdna,并进行pcr扩增。
[0208]
pcr扩增产物直接进行ta克隆,具体操作参考peasy-t1 cloning kit(transgen ct101)试剂盒说明书进行。
[0209]
将ta克隆的产物直接进行测序,测序结果如下:
[0210]
重链可变区的核酸序列如seq id no:1所示,长度为351bp。
[0211]
其编码的氨基酸序列如seq id no:2所示,长度为117aa,其中重链cdr1的序列如seq id no:5所示,重链cdr2的序列如seq id no:6所示,重链cdr3的序列如seq id no:7所示。
[0212]
轻链可变区的核酸序列如seq id no:3所示,长度为321bp。
[0213]
其编码的氨基酸序列如seq id no:4所示,长度为107aa,其中轻链cdr1的序列如seq id no:8所示,轻链cdr2的序列如seq id no:9所示,轻链cdr3的序列如seq id no:10所示。
[0214]
实施例3:抗人cd47的人源化抗体6f7 h1l1(hg4)、6f7 h2l2(hg4)和6f7 h3l3(hg4)的轻链和重链设计和制备
[0215]
1.抗人cd47的人源化抗体6f7 h1l1(hg4)、6f7h2l2(hg4)和6f7 h3l3(hg4)的轻链和重链设计
[0216]
根据人cd47蛋白的三维晶体结构(hage t,reinemer p,sebald w.crystals of a 1∶1 complex between human interleukin-4 and the extracellular domain of its receptor alpha chain.eur j biochem.1998;258(2):831-6.)以及实施例2获得的抗体6f7的序列,通过计算机模拟抗体模型,根据模型设计突变,得到抗体6f7h1l1、6f7 h2l2和6f7 h3l3的可变区序列(抗体恒定区序列,来自ncbi的数据库,重链恒定区序列为ig gamma-4 chain c region,accession:p01861.1;轻链恒定区为ig kappa chain c region,accession:p01834)。
[0217]
设计的可变区序列如下:
[0218]
(1)人源化单克隆抗体6f7h1 l1的重链可变区和轻链可变区序列
[0219]
重链可变区的核酸序列如seq id no:11所示,长度为351bp。
[0220]
其编码的氨基酸序列如seq id no:12所示,长度为117aa,其中重链cdr1的序列如seq id no:5所示,重链cdr2的序列如seq id no:6所示,重链cdr3的序列如seq id no:7所示。
[0221]
轻链可变区的核酸序列如seq id no:13所示,长度为321bp。
[0222]
其编码的氨基酸序列如seq id no:14所示,长度为107aa,其中轻链cdr1的序列如seq id no:8所示,轻链cdr2的序列如seq id no:9所示,轻链cdr3的序列如seq id no:10所示。
[0223]
(2)人源化单克隆抗体6f7 h2l2的重链可变区和轻链可变区序列
[0224]
重链可变区的核酸序列如seq id no:15所示,长度为351bp。
[0225]
其编码的氨基酸序列如seq id no:16所示,长度为117aa,其中重链cdr1的序列如seq id no:5所示,重链cdr2的序列如seq id no:6所示,重链cdr3的序列如seq id no:7所示。
[0226]
轻链可变区的核酸序列如seq id no:17所示,长度为321bp。
[0227]
其编码的氨基酸序列如seq id no:18所示,长度为107aa,其中轻链cdr1的序列如seq id no:8所示,轻链cdr2的序列如seq id no:9所示,轻链cdr3的序列如seq id no:10所示。
[0228]
(3)人源化单克隆抗体6f7 h3l3的重链可变区和轻链可变区序列
[0229]
重链可变区的核酸序列如seq id no∶19所示,长度为351bp。
[0230]
其编码的氨基酸序列如seq id no:20所示,长度为117aa,其中重链cdr1的序列如seq id no:5所示,重链cdr2的序列如seq id no:6所示,重链cdr3的序列如seq id no:7所示。
[0231]
轻链可变区的核酸序列如seq id no:21所示,长度为321bp。
[0232]
其编码的氨基酸序列如seq id no:22所示,长度为107aa,其中轻链cdr1的序列如seq id no:8所示,轻链cdr2的序列如seq id no:9所示,轻链cdr3的序列如seq id no:10所示。
[0233]
2.人源化抗体6f7 h1l1(hg4)、6f7 h2l2(hg4)和6f7 h3l3(hg4)的制备
[0234]
重链恒定区均采用ig gamma-4chain c region,accession:p01861.1;轻链恒定区均采用ig kappa chain c region,accession:p01834。
[0235]
将6f7h1l1(hg4)重链cdna和轻链的cdna、6f7h2l2(hg4)的重链cdna和轻链的cdna、以及6f7h3l3(hg4)重链cdna和轻链的cdna,分别克隆到puc57simple(金斯瑞公司提供)载体中,分别获得puc57simple-6f7h1、puc57simple-6f7l1;puc57simple-6f7h2、puc57simple-6f7l2、puc57simple-6f7h3和puc57simple-6f7l3。参照《分子克隆实验指南(第二版)》介绍的标准技术,ecori&hindiii酶切基因合成的重、轻链全长基因,通过限制酶(ecori&hindiii)的酶切亚克隆到表达载体pcdna3.1中;获得表达质粒pcdna3.1-6f7h1,pcdna3.1-6f7l1,pcdna3.1-6f7h2 pcdna3.1-6f7l2,pcdna3.1-6f7h3,和pcdna3.1-6f7l3,并进一步对重组表达质粒的重轻链基因进行测序分析。随后将含有相应的轻、重链重组质粒设计基因组合(pcdna3.1-6f7h1/pcdna3.1-6f7l 1,pcdna3.1-6f7h2/pcdna3.1-6f7l2,和pcdna3.1-6f7h3/pcdna3.1-6f7l3)分别共转染293f细胞后收集培养液进行纯化。测序验证正确后,制备去内毒素级别的表达质粒并将质粒瞬时转染hek293细胞进行抗体表达,培养7天后收集细胞培养液,采用protein a柱(mabselect sure(ge))进行亲和纯化获得人源化抗体。
[0236]
实施例4:抗人cd47的人源化抗体6f7h1l 1(g1m)、6f7h2l2(g1m)和6f7 h3l3(g1m)的轻链和重链设计和制备
[0237]
1.抗人cd47的人源化抗体6f7h1l1(g1)、6f7h2l2(g1)和6f7 h3l3(g1)的轻链和重链设计
[0238]
根据人cd47蛋白的三维晶体结构(hage t,reinemer p,sebald w.crystals of a 1:1 complex between human interleukin-4 and the extracellular domain of its receptor alpha chain.eur j biochem.1998;258(2):831-6.)以及实施例2获得的抗体6f7的序列,通过计算机模拟抗体模型,根据模型设计突变,得到抗体6f7h1l1、6f7 h2l2和6f7 h3l3的可变区序列(抗体恒定区序列,来自ncbi的数据库,重链恒定区为ig gamma-1chain c region,accession:p01857;轻链恒定区为ig kappa chain c region,accession:p01834),为了与前述实施例3中的人源化抗体相区分,上述人源化抗体分别命名为6f7h1l1(g1)、6f7h2l2(g1)和6f7 h3l3(g1)。
[0239]
本实施例中设计的人源化抗体6f7h1l1(g1)、6f7h2l2(g1)和6f7 h3l3(g1)的可变区序列与实施例3中6f7 h1l1(hg4)、6f7h2l2(hg4)和6f7 h3l3(hg4)的可变区序列一致。
[0240]
2.人源化抗体6f7h1l1(g1)、6f7h2l2(g1)和6f7 h3l3(g1)的制备
[0241]
重链恒定区均采用ig gamma-1chain c region,accession:p01857;轻链恒定区均采用ig kappa chain c region,accession:p01834。
[0242]
将6f7h1l1重链cdna和轻链的cdna、6f7h2l2的重链cdna和轻链的cdna、以及6f7h3l3重链cdna和轻链的cdna,分别克隆到puc57simple(金斯瑞公司提供)载体中,分别获得puc57simple-6f7h1、puc57simple-6f7l1;puc57simple-6f7h2、puc57simple-6f7l2、puc57simple-6f7h3和puc57simple-6f7l3。参照《分子克隆实验指南(第二版)》介绍的标准技术,ecori&hindiii酶切基因合成的重、轻链全长基因,通过限制酶(ecori&hindiii)的酶切亚克隆到表达载体pcdna3.1中获得表达质粒pcdna3.1-6f7h1,pcdna3.1-6f7l1,pcdna3.1-6f7h2,pcdna3.1-6f7l2,pcdna3.1-6f7h3,和pcdna3.1-6f7l3,并进一步对重组表达质粒的重轻链基因进行测序分析。随后将含有相应的轻、重链重组质粒设计基因组合(pcdna3.1-6f7h1/pcdna3.1-6f7l1,pcdna3.1-6f7h2/pcdna3.1-6f7l2,和pcdna3.1-6f7h3/pcdna3.1-6f7l3)分别共转染293f细胞后收集培养液进行纯化。测序验证正确后,制备去内毒素级别的表达质粒并将质粒瞬时转染hek293细胞进行抗体表达,培养7天后收集细胞培养液,采用protein a柱(mabselect sure(ge))进行亲和纯化获得人源化抗体。
[0243]
3.基于人源化抗体6f7h1l1(g1)、6f7h2l2(g1)和6f7 h3l3(g1)的非可变区氨基酸突变设计
[0244]
发明人在6f7h1l1(g1)、6f7h2l2(g1)和6f7 h3l3(g1)的基础上,通过在其重链铰链区域第234号位点引进了亮氨酸到丙氨酸的点突变(l234a),第235号位点引进了亮氨酸到丙氨酸的点突变(l235a),获得了新的人源化抗体,并分别命名为6f7h1l1(g1m)、6f7h2l2(g1m)和6f7 h3l3(g1m)。
[0245]
实施例5.elisa方法检测抗体与抗原的结合活性
[0246]
1.elisa方法测定抗体6f7 h1l1(hg4)与抗原人cd47 igv tev-his的结合活性
[0247]
实验步骤:将人cd47 igv tev-his,2μg/ml包被酶标板,4℃孵育12小时。孵育结束后使用pbs漂洗包被了抗原的酶标板3次,后使用1%bsa的pbs溶液作为酶标板封闭液,封闭2小时。酶标板结束封闭后用pbs漂洗3次。在酶标板孔内加入pbst溶液梯度稀释的抗体,抗体稀释梯度详见表2。加入待测抗体的酶标板置于37℃条件下孵育30分钟,孵育完成后用pbst洗板3次。洗板后加入1∶5000比例稀释的hrp标记的羊抗人igg(h+l)(购自jackson immunoresearch inc.,货号:109-035-088)二抗工作液,置于37℃条件下孵育30分钟。孵育完成后使用pbst洗板3次,后加入tmb(neogen,308177)避光显色5min,加入终止液终止显色反应。立即把酶标板放入酶标仪中,选择450nm光波长读取酶标板各孔的od数值。用softmax pro 6.2.1软件对数据进行分析处理。
[0248]
检测抗体6f7 h1l1(hg4)与抗原人cd47 igv tev-his结合的结果如图1所示。各剂量的od值见表1。以抗体浓度为横坐标,吸光度值为纵坐标进行曲线拟合,计算抗体的结合ec
50
,结果如下表1所示。
[0249]
结果表明,6f7 h1l1(hg4)与人cd47 igv tev-his的结合ec50为0.078nm,结合活性与hu5f9-g4相当。
[0250]
表1 6f7 h1l1(hg4)与人cd47 igv tev-his的结合活性检测结果
[0251][0252]
2.elisa方法测定抗体6f7 h1l1(g1m)与抗原人cd47 igv tev-his的结合活性
[0253]
实验步骤:将人cd47 igv tev-his,2μg/ml包被酶标板,4℃孵育12小时。孵育结束后使用pbs漂洗包被了抗原的酶标板3次,后使用1%bsa的pbs溶液作为酶标板封闭液,封闭2小时。酶标板结束封闭后用pbs漂洗3次。在酶标板孔内加入pbst溶液梯度稀释的抗体,抗体稀释梯度详见表2。加入待测抗体的酶标板置于37℃条件下孵育30分钟,孵育完成后用pbst洗板3次。洗板后加入1∶5000比例稀释的hrp标记的羊抗人igg(h+l)(购自jackson immunoresearch inc.,货号:109-035-088)二抗工作液,置于37℃条件下孵育30分钟。孵育完成后使用pbst洗板3次,后加入tmb(neogen,308177)避光显色5min,加入终止液终止显色反应。立即把酶标板放入酶标仪中,选择450nm光波长读取酶标板各孔的od数值。用softmax pro 6.2.1软件对数据进行分析处理。
[0254]
检测抗体6f7 h1l1(g1m)与抗原人cd47 igv tev-his结合的结果如图2所示。各剂量的od值见表2。以抗体浓度为横坐标,吸光度值为纵坐标进行曲线拟合,计算抗体的结合ec
50
,结果如下表2所示。
[0255]
表2 6f7 h1l1(g1m)与人cd47 igv tev-his的结合活性检测结果
[0256][0257]
结果表明,6f7 h1l1(g1m)与人cd47 igv tev-his的结合ec50为0.037nm,结合活性略优于hu5f9-g4。
[0258]
3.竞争elisa方法分别测定抗体6f7h1l1(hg4)与人sirpαecd-hfc-biotin竞争结合人cd47 igv tev-his的活性
[0259]
实验步骤:以2μg/ml的人cd47 igv tev-his,每孔50μl包被酶标板,4℃孵育16小时。洗板一次拍干,每孔加入300μl1%bsa溶液(用pbs溶解)封闭,37℃孵育2小时,洗板三次拍干。抗体稀释至3μg/ml(终浓度1.5μg/ml)作为起始浓度,在酶标板上进行1∶3的梯度稀释共7个浓度,另设空白对照,均做2个复孔,每孔体积50μl,室温孵育10分钟。将0.2μg/ml(终浓度为0.1μg/ml)的人sirpα ecd-hfc-biotin(中山康方生物医药有限公司合成)加入到酶标板中,每孔体积50μl与抗体体积1∶1轻柔混匀,37℃孵育30分钟。洗板三次拍干,每孔加入50μl sa-hrp(kpl,14-30-00)工作液,37℃孵育30分钟。洗板四次拍干,每孔加入50μl的tmb显色液,室温避光显色5分钟后,每孔加入50μl终止液终止显色反应。立即把酶标板放入酶标仪中,选择450nm光波长读取酶标板各孔的od数值,用softmax pro 6.2.1软件对数据进行分析处理。
[0260]
检测结果如图3所示。各剂量的od值见表3。通过对结合的抗体进行吸光强度定量分析,曲线模拟抗体的结合效率获得结合ec50(表3)。
[0261]
结果表明,6f7 h1l1(hg4)能有效地阻断抗原人cd47 igv tev-his与其受体人sirpα ecd-hfc-biotin的结合,阻断效率呈现剂量依赖关系,6f7h1 l1(hg4)的阻断ec50为0.194nm,阻断活性与hu5f9-g4相同。
[0262]
表3.6f7 h1l1(hg4)与人sirpα ecd-hfc-biotin竞争结合人cd47 igv tev-his的活性检测结果
[0263][0264]
4.竞争elisa方法分别测定抗体6f7 h1l1(g1m)与人sirpα
[0265]
ecd-hfc-biotin竞争结合人cd47 igv tev-his的活性
[0266]
实验步骤:以2μg/ml的人cd47 igv tev-his,每孔50μl包被酶标板,4℃孵育16小时。洗板一次拍干,每孔加入300μl 1%bsa溶液(用pbs溶解)封闭,37℃孵育2小时,洗板三次拍干。抗体稀释至3μg/ml(终浓度0.5μg/ml)作为起始浓度,在酶标板上进行1∶3的梯度稀释共7个浓度,另设空白对照,均做2个复孔,每孔体积50μl,室温孵育10分钟。将0.2μg/ml(终浓度为0.1μg/ml)的人sirpα ecd-hfc-biotin加入到酶标板中,每孔体积50μl与抗体体积1∶1轻柔混匀,37℃孵育30分钟。洗板三次拍干,每孔加入50μl sa-hrp(kpl,14-30-00)工作液,37℃孵育30分钟。洗板四次拍干,每孔加入50μl的tmb显色液,室温避光显色5分钟后,每孔加入50μl终止液终止显色反应。立即把酶标板放入酶标仪中,选择450nm光波长读取酶标板各孔的od数值,用softmax pro 6.2.1软件对数据进行分析处理。
[0267]
检测结果如图4所示。各剂量的od值见表4。通过对结合的抗体进行吸光强度定量分析,曲线模拟抗体的结合效率获得结合ec50(表4)。
[0268]
表4 6f7 h1l1(g1m)与人sirpα ecd-hfc-biotin竞争结合人cd47 igv tev-his的活性检测结果
[0269][0270]
结果表明,6f7 h1l1(g1m)能有效地阻断抗原人cd47 igv tev-his与其受体人sirpα ecd-hfc-biotin的结合,阻断效率呈现剂量依赖关系,6f7 h1l1(g1m)的阻断ec50为0.274nm,阻断活性与hu5f9-g4相当。
[0271]
实施例6:鼠源抗体6f7与人cd47的亲和力常数测定
[0272]
使用fortebio分子相互作用仪(forteio,型号:qke)测定鼠源抗体6f7与抗原人cd47 igv tev-his结合的动力学参数。
[0273]
使用edc/nhs激活ar2g传感器(forteio,货号:18-5092),采用氨基偶联的方式把抗体固定到激活的ar2g传感器上,传感器在pbst中平衡300s,固定在传感器上的抗原与抗体结合,抗原浓度为3.125-100nm(两倍梯度稀释),结合时间为420s,抗原抗体在pbst中解离,时间600s。
[0274]
鼠源抗体6f7以及hu5f9-g4(作为对照抗体)与人cd47 igv tev-his的亲和力常数测定结果见表5,检测结果如图5所示。
[0275]
表5鼠源抗体6f7与人cd47亲和力常数检测结果
[0276][0277]
kd为亲和力常数;kd=kdis/kon。
[0278]
结果表明:结果如表5和图5所示,鼠源抗体6f7以及hu5f9-g4与人cd47 igv tev-his的亲和力常数分别为6.52e-10m和6.38e-10m,两个亲和力常数的结果相当。提示6f7的cdr区结合cd47的能力与hu5f9-g4相当,都具有较强的结合能力。
[0279]
实施例7.6f7 h1l1(hg4)与人cd47的亲和力常数测定
[0280]
按照说明书,采用biacore分子相互作用仪(forteio,型号:qke)检测抗体6f7 h1l1(hg4)与人cd47 igv tev-his的亲和力常数。缓冲液为pbst,采用氨基偶联方式将人cd47 igv-tev-his固定于cm5芯片表面,固定的信号值为171.6ru。抗体与人cd47结合,抗体
浓度为0.78-12.5nm(两倍稀释),流速为30μl/min,结合的时间为120s,解离时间为300s。芯片使用3m mgcl2再生,流速为30μl/min,时间为30s。数据以1∶1模型拟合分析,得到亲和力常数。使用biacore control 2.0软件进行数据采集,biacore t200 evaluation 2.0软件进行数据分析。6f7 h1l1(hg4)以及hu5f9-g4(作为对照抗体)与人cd47 igv tev-his亲和力常数检测结果见表6,检测结果如图6、7。
[0281]
结果表明:结果如图所示,6f7 h1l1(hg4)与人cd47 igv tev-his的亲和力常数为1.52e-10m,hu5f9-g4与人cd47 igv tev-his的亲和力常数为4.42e-11m,提示6f7 h1 l1(hg4)与人cd47有较强的结合能力。
[0282]
表6.6f7 h1l1(hg4)与人cd47 igv tev-his亲和力常数检测结果
[0283]
抗体名称kd(m)ka(1/ms)se(ka)kd(1/s)se(kd)rmax(ru)6f7h1l1(hg4)1.52e-102.54e+061.48e+043.88e-041.14e-06253.21-272.60hu5f9-g44.42e-113.00e+068.49e+031.32e-045.69e-07238.81-327.23
[0284]
kd为亲和力常数;kd=kdis/kon。
[0285]
实施例8:6f7 h1l1(g1m)细胞生物学活性研究
[0286]
1.facs方法检测6f7 h1l1(g1m)与正常人rbc的结合情况
[0287]
在生物安全柜中进行正常人血红细胞的分离操作:将血液缓冲液a和b按1∶9的比例混合均匀得到血液缓冲液;将20ml的新鲜血液用60ml血液缓冲液混合均匀;向50ml的离心管中加入15ml ficoll plaque分离液,按照3∶4体积比缓慢加入稀释后的新鲜血液于分离液液面上,即每管加入稀释后的血液20ml;1550rpm离心30min;小心吸取离心管底部rbc并用pbs离心洗涤3次;用500μl 1%pbsa重悬细胞沉淀,计数;调整rbc细胞浓度,按每管30万细胞将细胞转移至1.5ml离心管;5600rpm/min离心5min,弃上清;按实验设计加入相应浓度的抗体(终浓度为,100,10,1,0.1,0.01,0.001,nm),每管100μl,并设计blank(pbsa+细胞)和同型对照(higg)组,冰上孵育1h;加入500μl1%pbsa,5600rpm/min离心5min,去上清;每管加入100μl fitc山羊抗人igg(1∶500),混匀后,冰上避光孵育30min;加入500μl 1%pbsa,5600rpm/min离心5min,去上清;200μl1%洗涤缓冲液/管重悬细胞,在流式细胞仪上用fitc通道检测荧光信号。
[0288]
flowing software分析结果,graphpad prism 5分别以mfi和样品浓度进行曲线拟合,计算ec50。
[0289]
6f7 h1l1(g1m)与正常人rbc细胞膜表面cd47结合的结果见图8。结果表明,6f7 h1l1(g1m)和同靶点上市药hu5f9-g4均可特异性与正常人rbc细胞膜表面cd47结合,其结合ec50分别为0.077nm和0.057nm,两者结合活性相当。
[0290]
2.facs法检测6f7 h1l 1(g1m)与raji的结合活性
[0291]
收集对数期raji细胞,离心洗涤,1%pbsa重悬细胞沉淀,计细胞数及活率,按3.0*105细胞/500μl/管将细胞转移至1.5ml离心管;5600rpm离心5min弃上清;按实验设计加入梯度稀释的相应抗体,每管100μl,并设计空白(pbsa+细胞)和同型对照组(higg),冰上孵育1hr;1hr后,加入1%pbsa,5600rpm离心5min,去上清;每管加入100μl fitc山羊抗人igg(1∶500),混匀后冰上避光孵育30min;加入500μl 1%pbsa,5600rpm离心5min,去上清;1%pbsa/管重悬细胞,在流式细胞仪上用fitc通道检测荧光信号。以mfi和样品浓度进行曲线拟合,计算ec50。
[0292]
6f7 h1l1(g1m)与raji的结合活性结果见图9。如图所示,结合试验结果表明,6f7 h1l1(g1m)与hu5f9-g4均可特异性与raji细胞膜表面cd47结合,其结合ec50分别为0.013nm和0.012nm,两者结合活性相当。
[0293]
3.facs法检测6f7 h1l1(g1m)与sirp竞争结合lovo的生物学活性
[0294]
常规收集对数期lovo细胞(中国科学院细胞中心,编号:bio-73085),离心洗涤。1%pbsa重悬细胞沉淀,计细胞数及活率;1%pbsa将细胞浓度调整至合适范围,并将细胞按组转移至1.5ml离心管,每管500μl共30万细胞,5600rpm离心5min,弃上清;加入梯度稀释后的抗体(终浓度从高到低依次为:300、100、10、1、0.3、0.1、0.01、0.001、0.0001nm),同时设置空白对照(100μl 1%pbsa加细胞)和同型对照(human igg),冰上孵育30min。每管加入100μl sirpα-mfc,混匀,终浓度为20nm,冰上继续孵育1h;加入1%pbsa,5600rpm离心5min,弃上清;加入fitc山羊抗鼠igg,每管100μl(1∶500稀释),冰上避光孵育40min;加入1%pbsa,5600rpm离心5min,弃上清。加200μl 1%pbsa重悬细胞沉淀,转移至流式上样管;在流式细胞仪上用fitc通道检测荧光信号。以mfi和样品浓度进行曲线拟合,计算ec50。
[0295]
6f7 h1l1(g1m)与sirp竞争结合lovo的活性检测。结果见图10。如图所示,6f7 h1l1(g1m)与hu5f9-g4均可与sirp竞争结合lovo膜表面cd47,从而阻断sirp与cd47的结合,其竞争结合ec50分别为0.16nm和0.24nm,两者结合活性相当。
[0296]
4.6f7 h1l1(g1m)对正常人rbc凝集的影响
[0297]
正常人血rbc的准备:按照分离液ficoll-paque plus试剂说明书分离人血pbmc,沉淀底部的红细胞用于本实验;用pbs将红细胞稀释,使红细胞浓度为1*107/ml,获得红细胞悬液;将红细胞悬液加入到圆底96孔板中,加入相应浓度的阳性抗体,对照加入0.1g/ml的dextran t500,阴性对照加入相应higg或pbs,置于37度培养4小时;观察红细胞凝集现象并拍照。
[0298]
6f7 h1 l1(g1m)对正常人红细胞凝集作用的影响见图11。如图所示,6f7 h1l1(g1m)和对照抗体hu5f9-g4在抗体浓度低于20μg/ml时,对红细胞凝集均无影响,但当抗体浓度高于20μg/ml时,hu5f9-g4可见明显的促红细胞凝集现象,而6f7 h1l1(g1m)对红细胞凝集仍无影响。
[0299]
实施例9:6f7 h1l1(hg4)细胞生物学活性研究
[0300]
1.facs方法检测6f7 h1l1(hg4)与正常人rbc的结合情况
[0301]
实验步骤:将血液缓冲液a(d-(+)-glucose:1g,cacl2:0.0056g,mgcl2·
6h2o:0.1992g,kcl:0.4026g,tris:17.5650g,取以上试剂溶于1l超纯水)和b(nacl:8.19g溶于1l超纯水)按1∶9的比例混合均匀得到血液缓冲液。将新鲜血液与血液缓冲液混合均匀(浓缩后的血液稀释比例为1∶3)。往50ml的离心管中加入15ml ficoll plaque plus分离液(ge,货号:17-1440-02),按照3∶4体积比缓慢加入稀释后的新鲜血液于分离液液面上,既每管加入稀释后的血液20ml。每管配平后离心1550rpm,30min。吸取中间白膜层的细胞pbmc。按照细胞体积比∶血液缓冲液=1∶4的比例加入血液缓冲液混合均匀,离心950rpm,15min后弃上清。加入血液缓冲液20ml将pbmc混悬,离心弃上清。离心,重复洗两次。用10ml rpmi-1640(无fbs)洗涤细胞一次。离心弃上清,用5ml rpmi-1640(含10%fbs)重悬细胞,计数,3*105细胞/样本,每管加入500μl 1%pbsa,5600rpm离心5min弃上清;按加入相应浓度的抗体(终浓度为300,100,10,1,0.1,0.01,0.001nm),每管100μl,并设计blank(pbsa+细胞)和同型对
照(人igg),冰上孵育1h;加入1%pbsa,5600rpm离心5min,去上清;每管加入100μl fitc山羊抗人igg(jacson,货号:109-095-098,1∶500稀释)或fitc山羊抗鼠igg(bd bioscience,货号:555988)(1∶500),混匀后冰上避光孵育30min;加入1%pbsa,5600rpm离心5min,去上清;200μl洗涤缓冲液/管,重悬细胞,在流式细胞仪上用fitc通道检测荧光信号。flowing software分析结果,graphpad prism 5分别以mfi和样品浓度进行曲线拟合,计算ec50。
[0302]
6f7 h1l1(hg4)与正常人rbc细胞膜表面cd47结合的结果见图12和表7。结果表明,6f7 h1l1(hg4)和同靶点上市药hu5f9-g4均可特异性与正常人rbc细胞膜表面cd47结合,其结合ec50分别为0.60nm和0.06nm,hu5f9-g4与rbc的亲和力高出6f7 h1l1(hg4)约10倍。
[0303]
表7 facs检测抗-cd47抗体与人rbc结合的结果
[0304]
浓度(nm)/mfi0.001230.01230.1231.233.711.133.3ec50hu5f9-g419.4859.35132.68212.25207.52219.34219.020.066f7 h1l1(hg4)10.2519.5547.29134.58152.50185.31190.180.60
[0305]
2.facs法检测6f7 h1l1(hg4)与rajji的结合活性
[0306]
通过流式细胞法检测cd47抗体与肿瘤细胞raji(中国科学院上海生命科学研究院细胞资源中心,货号:tchu44)结合的生物学活性。
[0307]
取raji细胞计数及活率,3*105细胞/样本,每管加入500μl 1%pbsa,5600rpm离心5min弃上清;按实验设计加入梯度稀释的相应抗体,并设计空白(pbsa+细胞)和同型对照组(人igg),冰上孵育1h;加入1%pbsa,5600rpm离心5min,去上清;每管加入100μl fitc山羊抗人igg(1∶500)或fitc山羊抗鼠igg(1∶500),混匀后冰上避光孵育30min;加入500μl 1%pbsa,5600rpm离心5min,去上清;200μl洗涤缓冲液/管,重悬细胞,在流式细胞仪上用fitc通道检测荧光信号。
[0308]
6f7 h1l1(hg4)与raji的结合活性结果见图13和表8。如图和表所示,结合试验结果表明,6f7 h1l1(hg4)与hu5f9-g4均可特异性与raji细胞膜表面cd47结合,其结合ec50分别为0.32nm和0.22nm,二者活性相当。
[0309]
表8 facs检测抗-cd47抗体与肿瘤细胞raji结合的结果
[0310][0311][0312]
3.facs法检测6f7 h1l1(hg4)与sirp竞争结合raji的竞争结合活性
[0313]
常规收集对数期raji细胞,离心洗涤。1%pbsa重悬细胞沉淀,计细胞数及活率;1%pbsa将细胞浓度调整至合适范围,并将细胞按组转移至1.5ml离心管,每管500μl共30万细胞,5600rpm离心5min,弃上清;加入梯度稀释后的抗体(终浓度从高到低依次为:1、0.3、0.1、0.01、0.001、0.0001nm),同时设置空白对照(100μl 1%pbsa加细胞)和同型对照(人igg),冰上孵育30min。每管加入100μl sirpα-ecd-mfc(mfc的序列如seq id no:71所示),使终浓度为20nm,混匀,冰上继续孵育1h;加入1%pbsa,5600rpm离心5min,弃上清;加入fitc山羊抗鼠igg,每管100μl(1∶500稀释),冰上避光孵育40min;加500μl 1%pbsa,5600rpm离心5min,弃上清。加200μl 1%pbsa重悬细胞沉淀,在流式细胞仪上用fitc通道检测荧光信号。
[0314]
6f7 h1l1(hg4)与sirp竞争结合肿瘤细胞raji的结果见图14和表9。如图和表所示,6f7 h1l1(hg4)与hu5f9-g4均可与sirp竞争结合raji膜表面cd47,阻断sirp与cd47的结合,竞争结合ec50分别为0.017nm和0.014nm,二者竞争结合活性相当。
[0315]
表9 facs检测抗-cd47抗体与sirp竞争结合raji细胞的结果
[0316]
浓度(nm)/mfi0.00010.0010.010.10.31ec50hu5f9-g454.8349.3737.1610.7710.3411.40.0146f7 h1l1(hg4)50.2754.3742.6416.8015.6614.830.017
[0317]
4.facs法检测6f7 h1l1(hg4)与lovo的结合活性
[0318]
收集对数期lovo细胞(中国科学院细胞中心,编号:bio-73085),离心洗涤,500μl 1%pbsa重悬细胞沉淀,计细胞数及活率,按3.0*105细胞/500μl/管将细胞转移至1.5ml离心管;5600rpm离心5分钟弃上清;按实验设计加入梯度稀释的相应抗体,每管100μl,并设计空白(pbsa+细胞)和同型对照组(人igg,其重链序列为seq id no:72,轻链序列为seq id no:73),冰上孵育1小时;之后,加入500μl 1%pbsa,5600rpm离心5分钟,去上清;每管加入100μl fitc山羊抗人igg(1∶500),混匀后冰上避光孵育30分钟;加入500μl1%pbsa,5600rpm离心5分钟,去上清;200μl1%pbsa/管重悬细胞,转移至流式上样管;上流式细胞仪bd facscalibur检测;flowing software分析结果,graphpad prism 5分别以mfi和样品浓度进行曲线拟合,计算ec50。
[0319]
6f7 h1l1(hg4)与肿瘤细胞lovo的结合结果见图15和表10。如图和表所示,6f7 h1l1(hg4)与hu5f9-g4均可特异性与lovo细胞膜表面cd47结合,其结合ec50分别为0.02nm和0.06nm,6f7 h1l1(hg4)略优于hu5f9-g4。
[0320]
表10.facs检测抗-cd47抗体与lovo结合的结果
[0321]
浓度(nm)/mfi0.00010.0010.010.10.31ec50hu5f9-g411.3513.0430.44102.94145.13150.570.066f7 h1l1(hg4)15.2625.4148.15135.95146.67149.810.02
[0322]
5.facs法检测6f7 h1l1(hg4)与sirp竞争结合lovo的生物学活性
[0323]
实验步骤同本实施例3,仅是将raji细胞换为lovo细胞。
[0324]
6f7 h1l1(hg4)与sirp竞争结合lovo的活性检测结果见图16和表11。如图和表所示,6f7 h1l1(hg4)与hu5f9-g4均可与sirp竞争结合lovo膜表面cd47,从而阻断sirp与cd47的结合,其竞争结合ec50分别为0.10nm、0.24nm,6f7 h1l1(hg4)略优于hu5f9-g4。
[0325]
表11 facs检测抗-cd47抗体与sirp竞争结合lovo细胞的结果
[0326]
浓度(nm)/mfi0.00010.0010.010.10.3110100300ec50hu5f9-g469.8162.4764.4547.3038.9811.6310.519.599.930.246f7 h1l1(hg4)56.7959.5964.5234.2123.7626.5217.4611.359.440.10
[0327]
6.抗-cd47抗体对正常人rbc凝集的影响
[0328]
正常人血rbc的准备:按照分离液ficoll-paque_plus(ge,货号:17-1440-02)试剂说明书分离人血pbmc,沉淀底部的红细胞用于本实验;用pbs将红细胞稀释,使红细胞浓度为1*107/ml,获得红细胞悬液;将红细胞悬液加入到圆底96孔板中,加入相应浓度的阳性抗体,对照加入0.1g/ml的dextran t500,阴性对照加入相应人igg1(康方生物)或pbs,置于37摄氏度培养4小时;观察红细胞凝集现象并拍照。
[0329]
6f7h1l1(hg4)对正常人红细胞凝集作用的影响见图17。如图所示,6f7 h1l1(hg4)在所有试验浓度均不导致红细胞凝集,对照抗体hu5f9-g4浓度等于低于3.3μg/ml时,不导致红细胞凝集。当浓度大于等于时,10μg/ml时,hu5f9-g4可见明显的促红细胞凝集现象。
[0330]
实施例10:6f7 h1l1(hg4)对mda-mb-231皮下移植瘤的治疗作用
[0331]
通过测定6f7 h1l1(hg4)给药后scid/beige小鼠上人乳腺癌细胞mda-mb-231皮下移植瘤体积,对6f7 h1l1(hg4)体内活性做研究。收集的mda-mb-231(atcc,货号:htb-26)细胞以5
×
106个细胞/只小鼠接种于scid/beige小鼠右侧腰窝皮下,共接种40只小鼠。当肿瘤体积达到100-120mm3左右时,将小鼠按照肿瘤体积平均分成5组,模型组、hu5f9-g4高剂量组、hu5f9-g4低剂量组、6f7 h1l1(hg4)高剂量组和6f7 h1l1(hg4)低剂量组,高剂量组给药剂量为0.2mg/kg,低剂量组给药剂量为0.02mg/kg,分组当天记为d0,分别在d0,d3,d7,d10,d14,d17给药,每组7只。
[0332]
分组后每周两次使用游标卡尺测量肿瘤大小,并根据计算公式tv=0.5
×
ab2计算肿瘤体积,其中a是肿瘤的长径,b是肿瘤的短径,tv是肿瘤的体积,根据肿瘤体积计算tgi(%)(肿瘤生长抑制率),公式:%tgi=(1-(ti-t0)/(ci-c0))*100%,ti和ci分别为给药组和模型组第i天的平均肿瘤体积,t0和c0分别为给药组和模型组第0天的平均肿瘤体积。组间比较采用graphpad统计学处理软件处理后,进行单因素方差分析评价结果。
[0333]
结果如图18所示,分组后第24天,对照抗体hu5f9-g4高剂量组和6f7h1l1(hg4)高剂量组均能够有效抑制mda-mb-231肿瘤的生长(p<0.01),且hu5f9-g4和6f7 h1l1(hg4)对mda-mb-231肿瘤生长的抑制均具有量效关系,对照抗体hu5f9-g4高剂量组、6f7 h1l1(hg4)高剂量组、6f7 h1l1(hg4)低剂量组的tgi(%)分别为67%、63%、25%,与对照抗体组相比,6f7 h1l1(hg4)低剂量组药效显著优于hu5f9-g4,高剂量相当6f7 h1l1(hg4)高剂量药效与对照抗体高剂量相当,(p>0.05)。
[0334]
实施例11:6f7 h1l1(hg4)与hu5f9-g4食蟹猴单次给药对血红蛋白和红细胞压积的影响
[0335]
食蟹猴4只,按体重、性别随机分为2组,每组2只,雌雄各半。试验设6f7 h1l1(hg4)组,hu5f9-g4组,给药剂量10mg/kg,给药方式为静脉。血液分析仪检测血红蛋白(hemoglobin)、红细胞压积(hematocrit)。
[0336]
检测结果见图19和20,以及表12所示。
[0337]
结果表明,食蟹猴单次静脉注射10mg/kg,6f7 h1l1(hg4)和hu5f9-g4在给药后血红蛋白、红细胞压积,出现不同程度的降低,2-7天出现贫血最低点,其中hu5f9-g4的贫血情况较6f7 h1l1(hg4)严重;两个抗体的贫血情况可以自发恢复,大约在给药后20天恢复到基线水平。
[0338]
表12.6f7 h1l1(hg4)和hu5f9-g4食蟹猴单次给药后血红蛋白及红细胞压积个体数据
[0339][0340]
以上对本发明的实施方式进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做出种种的等同变型或替换,这些等同的变型或替换均包含在本申请权利要求所限定的范围内。
[0341]
序列表:
[0342]
6f7重链可变区:
[0343]
caggtgcagctgcagcagccaggagcagagctggtgaggccaggagcatccgtgaagctgtcttgtaaggccagcggctacaccttcacatcctattggatgaactgggtgaagcagaggcctggacagggactggagtggatcggcatgatcgacccaagcgattccgagacccacaacaatcagatgtttaaggacaaggccaccctgacagtggataagagctccaataccgcctacatgcacctgtctagcctgacatctgaggacagcgccgtgtatcactgcgcccggctgtacagatggtattttgacgtgtggggagcaggaaccacagtgaccgtgtcctct(seq id no:1)
[0344]
qvqlqqpgaelvrpgasvklsckasgytftsywmnwvkqrpgqglewigmidpsdsethnnqmfkdkatltvdkssntaymhlssltsedsavyhcarlyrwyfdvwgagttvtvss(seq id no:2)
[0345]
6f7轻链可变区:
[0346]
aacatcgtgatgacccagtcccccaagtctatgagcatgtccctgggcgagagggtgaccctgtcctgtaaggcctctgagatcgtgggcacatacgtgtcttggtttcagcagaagccacaccagagccccaagctgctgatctacggcgcctccaatcggtatacaggcgtgcctgacagattcaccggctctggcagcgccacagacttcaccctgacaatctctaacgtgcaggccgaggacctggccgattatcactgcggccagagctacaatttcccttatacctttggcggcggcacaaagctggagatcaag(seq id no:3)
[0347]
nivmtqspksmsmslgervtlsckaseivgtyvswfqqkphqspklliygasnrytgvpdrftgsgsatdftltisnvqaedladyhcgqsynfpytfgggtkleik(seq id no:4)
[0348]
6f7cdr
[0349]
hcdr1:gytftsyw(seq id no:5)
[0350]
hcdr2:idpsdset(seq id no:6)
[0351]
hcdr3:arlyrwyfdv(seq id no:7)
[0352]
lcdr1:eivgty(seq id no:8)
[0353]
lcdr2:gas(seq id no:9)
[0354]
lcdr3:gqsynfpyt(seq id no:10)
[0355]
6f7h1:
[0356]
caggtgcagctggtgcagagcggagcagaggtggtgaagccaggagcctctgtgaagctgagctgtaaggcctccggctacaccttcacaagctattggatgaactgggtgcggcagagaccaggacagggactggagtggatcggaatgatcgacccttccgattctgagacccacaatgcccagaagtttcagggcaaggccaccctgacagtggacaagagcacctccacagcctacatgcacctgagctccctgcggtccgaggacacagccgtgtactattgcgccaggctgtaccgctggtattttgacgtgtggggagcaggaaccacagtgaccgtgtctagc(seq id no:11)
[0357]
qvqlvqsgaevvkpgasvklsckasgytftsywmnwvrqrpgqglewigmidpsdsethnaqkfqgkatltvdkststaymhlsslrsedtavyycarlyrwyfdvwgagttvtvss(seq id no:12)
[0358]
6f7l1:
[0359]
aacatcgtgatgacccagtccccagccacaatgtctatgagcccaggagagagggtgaccctgtcctgtagagcctctgagatcgtgggcacatacgtgtcttggtttcagcagaagccaggacaggcacctaggctgctgatctacggagcaagcaacaggtataccggagtgccagcacgcttctccggctctggcagcggcacagactttaccctgacaatcagctccgtgcagcctgaggacctggccgattatcactgcggccagtcttacaatttcccatatacctttggcggcggcacaaagctggagatcaag(seq id no:13)
[0360]
nivmtqspatmsmspgervtlscraseivgtyvswfqqkpgqaprlliygasnrytgvparfsgsgsgtdftltissvqpedladyhcgqsynfpytfgggtkleik(seq id no:14)
[0361]
6f7h2:
[0362]
caggtgcagctggtgcagagcggagcagaggtggtgaagccaggagcctctgtgaaggtgagctgtaaggcctccggctacaccttcacatcctattggatgaactgggtgcggcagagaccaggacagggactggagtggatcggaatcatcgacccttccgattctgagacctctaatgcccagaagtttcagggccgggtgaccctgacagtggacaagagcacctccacagcctacatgcacctgagctccctgaggagcgaggacacagccgtgtactattgcgccaggctgtaccgctggtattttgacgtgtggggagcaggaaccacagtgaccgtgtctagc(seq id no:15)
[0363]
qvqlvqsgaevvkpgasvkvsckasgytftsywmnwvrqrpgqglewigiidpsdsetsnaqkfqgrvtltvdkststaymhlsslrsedtavyycarlyrwyfdvwgagttvtvss(seq id no:16)
[0364]
6f7l2:
[0365]
aacatcgtgatgacccagtccccagccacactgtctctgagcccaggagagagggtgaccctgtcctgtagagcctctgagatcgtgggcacatacgtgtcttggtttcagcagaagccaggacaggcacctaggctgctgatctatggcgccagcaacagggcaaccggcatccccgcacgcttctccggctctggcagcggcacagactttaccctgacaatcagctccctgcagcctgaggacctggccgattactattgcggccagtcttacaatttcccatatacctttggcggcggcacaaagctggagatcaag(seq id no:17)
[0366]
nivmtqspatlslspgervtlscraseivgtyvswfqqkpgqaprlliygasnratgiparfsgsgsgtdftltisslqpedladyycgqsynfpytfgggtkleik(seq id no:18)
[0367]
6f7h3:
[0368]
caggtgcagctggtgcagagcggagcagaggtggtgaagccaggagcctctgtgaaggtgagctgtaaggcctccggctacaccttcacatcctattggatgaactgggtgcggcaggcaccaggacagggactggagtggatcggcatcatcgacccttccgattctgagacctcttacgcccagaagtttcagggcagggtgaccctgacagtggacaagagcacctccacagcctatatggagctgagctccctgcgcagcgaggacacagccgtgtactattgcgcccggctgtacagatggtattttgacgtgtggggagcaggaaccacagtgaccgtgtctagc(seq id no:19)
[0369]
qvqlvqsgaevvkpgasvkvsckasgytftsywmnwvrqapgqglewigiidpsdsetsyaqkfqgrvtltvdkststaymelsslrsedtavyycarlyrwyfdvwgagttvtvss(seq id no:20)
[0370]
6f7l3:
[0371]
aacatcgtgatgacccagtccccagccacactgtctctgagcccaggagagagggtgaccctgtcctgtagagcctctgagatcgtgggcacatacctgtcttggtatcagcagaagccaggacaggcacctaggctgctgatctacggagccagcaccagggcaacaggcatccccgcacgcttctccggctctggcagcggcaccgactttaccctgacaatcagctccctgcagcctgaggattttgccgtgtactattgcggccagtcttacaatttcccatatacctttggcggcggcacaaagctggagatcaag(seq id no:21)
[0372]
nivmtqspatlslspgervtlscraseivgtylswyqqkpgqaprlliygastratgiparfsgsgsgtdftltisslqpedfavyycgqsynfpytfgggtkleik(seq id no:22)
[0373]
6f7重链骨架区
[0374]
fr-h1:qvqlqqpgaelvrpgasvklsckas(seq id no:23)
[0375]
fr-h2:mnwvkqrpgqglewigm(seq id no:24)
[0376]
fr-h3:hnnqmfkdkatltvdkssntaymhlssltsedsavyhc(seq id no:25)
[0377]
fr-h4:wgagttvtvss(seq id no:26)
[0378]
6f7轻链骨架区
[0379]
fr-l1:nivmtqspksmsmslgervtlsckas(seq id no:27)
[0380]
fr-l2:vswfqqkphqspklliy(seq id no:28)
[0381]
fr-l3:nrytgvpdrftgsgsatdftltisnvqaedladyhc(seq id no:29)
[0382]
fr-l4:fgggtkleik(seq id no:30)
[0383]
6f7h1骨架区
[0384]
fr-h1:qvqlvqsgaevvkpgasvklsckas(seq id no:31)
[0385]
fr-h2:mnwvrqrpgqglewigm(seq id no:32)
[0386]
fr-h3:hnaqkfqgkatltvdkststaymhlsslrsedtavyyc(seq id no:33)
[0387]
fr-h4:wgagttvtvss(seq id no:34)
[0388]
6f7l1骨架区
[0389]
fr-l1:nivmtqspatmsmspgervtlscras(seq id no:35)
[0390]
fr-l2:vswfqqkpgqaprlliy(seq id no:36)
[0391]
fr-l3:nrytgvparfsgsgsgtdftltissvqpedladyhc(seq id no:37)
[0392]
fr-l4:fgggtkleik(seq id no:38)
[0393]
6f7h2骨架区
[0394]
fr-h1:qvqlvqsgaevvkpgasvkvsckas(seq id no:39)
[0395]
fr-h2:mnwvrqrpgqglewigi(seq id no:40)
[0396]
fr-h3:snaqkfqgrvtltvdkststaymhlsslrsedtavyyc(seq id no:41)
[0397]
fr-h4:wgagttvtvss(seq id no:42)
[0398]
6f7l2骨架区
[0399]
fr-l1:nivmtqspatlslspgervtlscras(seq id no:43)
[0400]
fr-l2:vswfqqkpgqaprlliy(seq id no:44)
[0401]
fr-l3:nratgiparfsgsgsgtdftltisslqpedladyyc(seq id no:45)
[0402]
fr-l4:fgggtkleik(seq id no:46)
[0403]
6f7h3骨架区
[0404]
fr-h1:qvqlvqsgaevvkpgasvkvsckas(seq id no:47)
[0405]
fr-h2:mnwvrqapgqglewigi(seq id no:48)
[0406]
fr-h3:syaqkfqgrvtltvdkststaymelsslrsedtavyyc(seq id no:49)
[0407]
fr-h4:wgagttvtvss(seq id no:50)
[0408]
6f7l3骨架区
[0409]
fr-l1:nivmtqspatlslspgervtlscras(seq id no:51)
[0410]
fr-l2:lswyqqkpgqaprlliy(seq id no:52)
[0411]
fr-l3:tratgiparfsgsgsgtdftltisslqpedfavyyc(seq id no:53)
[0412]
fr-l4:fgggtkleik(seq id no:54)
[0413]
igg1m重链恒定区
[0414]
astkgpsvfplapsskstsggtaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtqtyicnvnhkpsntkvdkkvepkscdkthtcppcpapeaaggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsrdeltknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk(seq id no:55)
[0415]
重链恒定区ig gamma-4chain c region
[0416]
astkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcpscpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslgk(seq id no:56)
[0417]
轻链恒定区ig kappa chain c region
[0418]
rtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec(seq id no:57)
[0419]
重链恒定区ig gamma-1chain cregion
[0420]
astkgpsvfplapsskstsggtaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtqtyicnvnhkpsntkvdkkvepkscdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsrdeltknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk(seq id no:58)
[0421]
6f7h1l1(g1m)重链的氨基酸序列
[0422]
qvqlvqsgaevvkpgasvklsckasgytftsywmnwvrqrpgqglewigmidpsdsethnaqkfqgka
tltvdkststaymhlsslrsedtavyycarlyrwyfdvwgagttvtvssastkgpsvfplapsskstsggtaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtqtyicnvnhkpsntkvdkkvepkscdkthtcppcpapeaaggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsrdeltknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk(seq id no:59)
[0423]
6f7h1l1(g1m)轻链的氨基酸序列
[0424]
nivmtqspatmsmspgervtlscraseivgtyvswfqqkpgqaprlliygasnrytgvparfsgsgsgtdftltissvqpedladyhcgqsynfpytfgggtkleikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec(seq id no:60)
[0425]
6f7h2l2(g1m)重链的氨基酸序列
[0426]
qvqlvqsgaevvkpgasvkvsckasgytftsywmnwvrqrpgqglewigiidpsdsetsnaqkfqgrvtltvdkststaymhlsslrsedtavyycarlyrwyfdvwgagttvtvssastkgpsvfplapsskstsggtaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtqtyicnvnhkpsntkvdkkvepkscdkthtcppcpapeaaggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsrdeltknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk(seq id no:61)
[0427]
6f7h2l2(glm)轻链的氨基酸序列
[0428]
nivmtqspatlslspgervtlscraseivgtyvswfqqkpgqaprlliygasnratgiparfsgsgsgtdftltisslqpedladyycgqsynfpytfgggtkleikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec(seq id no:62)
[0429]
6f7h3l3(glm)重链的氨基酸序列
[0430]
qvqlvqsgaevvkpgasvkvsckasgytftsywmnwvrqapgqglewigiidpsdsetsyaqkfqgrvtltvdkststaymelsslrsedtavyycarlyrwyfdvwgagttvtvssastkgpsvfplapsskstsggtaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtqtyicnvnhkpsntkvdkkvepkscdkthtcppcpapeaaggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsrdeltknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk(seq id no:63)
[0431]
6f7h3l3(g1m)轻链的氨基酸序列
[0432]
nivmtqspatlslspgervtlscraseivgtylswyqqkpgqaprlliygastratgiparfsgsgsgtdftltisslqpedfavyycgqsynfpytfgggtkleikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec(seq id no:64)
[0433]
6f7h1l1(hg4)重链的氨基酸序列
[0434]
qvqlvqsgaevvkpgasvklsckasgytftsywmnwvrqrpgqglewigmidpsdsethnaqkfqgka
tltvdkststaymhlsslrsedtavyycarlyrwyfdvwgagttvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcpscpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslgk(seq id no:65)
[0435]
6f7h1l1(hg4)轻链的氨基酸序列
[0436]
nivmtqspatmsmspgervtlscraseivgtyvswfqqkpgqaprlliygasnrytgvparfsgsgsgtdftltissvqpedladyhcgqsynfpytfgggtkleikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec(seq id no:66)
[0437]
6f7h2l2(hg4)重链的氨基酸序列
[0438]
qvqlvqsgaevvkpgasvkvsckasgytftsywmnwvrqrpgqglewigiidpsdsetsnaqkfqgrvtltvdkststaymhlsslrsedtavyycarlyrwyfdvwgagttvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcpscpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytokslslslgk(seq id no:67)
[0439]
6f7h2l2(hg4)轻链的氨基酸序列
[0440]
nivmtqspatlslspgervtlscraseivgtyvswfqqkpgqaprlliygasnratgiparfsgsgsgtdftltisslqpedladyycgqsynfpytfgggtkleikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec(seq id no:68)
[0441]
6f7h3l3(hg4)重链的氨基酸序列
[0442]
qvqlvqsgaevvkpgasvkvsckasgytftsywmnwvrqapgqglewigiidpsdsetsyaqkfqgrvtltvdkststaymelsslrsedtavyycarlyrwyfdvwgagttvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcpscpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslgk(seq id no:69)
[0443]
6f7h3l3(hg4)轻链的氨基酸序列
[0444]
nivmtqspatlslspgervtlscraseivgtylswyqqkpgqaprlliygastratgiparfsgsgsgtdftltisslqpedfavyycgqsynfpytfgggtkleikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec(seq id no:70)
[0445]
mfc标签的序列:(seq id no:71)
[0446]
prgptikpcppckcpapnllggpsvfifppkikdvlmislspivtcvvvdvseddpdvqiswfvnnvev
htaqtqthredynstlrvvsalpiqhqdwmsgkefkckvnnkdlpapiertiskpkgsvrapqvyvlpppeeemtkkqvtltcmvtdfmpediyvewtnngktelnykntepvldsdgsyfmysklrvekknwvernsyscsvvheglhnhhttksfsrtpgk
[0447]
higg的重链序列(seq id no:72)
[0448]
evqleqsgaelmkpgasvkisckatgytfttywiewikqrpghslewigeilpgsdstyynekvkgkvtftadassntaymqlssltsedsavyycargdgfyvywgqgttltvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslgk
[0449]
higg的轻链序列(seq id no:73)
[0450]
dieltqspatlsvtpgdsvslscrasqsisnnlhwyqqkshesprllikytsqsmsgipsrfsgsgsgtdftlsinsvetedfgvyfcqqsgswprtfgggtkldikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
[0451]
tev氨基酸序列为enlyfqg,seq id no:74
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1