纤维素酶突变体及其组合物的制作方法
1.本发明公开了纤维素酶变体,以及编码所述纤维素酶变体的多核苷酸,其中所述纤维素酶变体具有内切葡聚糖酶活性。本文还公开了组合物,所述组合物包含所述纤维素酶变体;载体和/或宿主细胞,所述载体和/或宿主细胞包含编码所述纤维素酶变体的多核苷酸;和方法,所述方法用于制备和/或使用所述纤维素酶变体和/或含有所述纤维素酶变体的组合物。
背景技术:
2.纤维素酶是将纤维素水解为葡萄糖的一组酶系的总称。根据纤维素酶的催化性质可分为3类:(1)外切-β-葡聚糖酶(ec 3.2.1.91),它作用于纤维素分子的两端,从纤维素分子两端切下纤维二糖。外切-β-葡聚糖酶对纤维素分子的无定型区和结晶区均有作用;(2)内切-β-葡聚糖酶(ec 3.2.1.4),它作用于纤维素分子内部无定型区,通过水解β-1,4-糖苷键将纤维素大分子截短;(3)β-葡萄糖苷酶(ec3.2.1.21),它是一种非专一性酶,可以水解多种纤维寡糖如纤维二糖和纤维三糖等。
3.纤维素酶能作用于天然或再生的各种纤维素纤维,包括棉纤维、麻纤维、竹纤维、粘胶纤维和铜氨纤维等。纤维素酶对织物进行处理后,可以去掉表面的微纤维绒毛,使织物质量得到提高。
4.内切-β-葡聚糖酶是最有效的牛仔布生物整理的纤维素酶组分。jinichiro koga等人对1600个真菌的培养上清液进行筛选,结果他们发现了内切葡聚糖酶45家族的一个新成员stce1(staphylotrichum coccosporum nbrc 31817的培养上清液)。stce1主要包含三个部分:n-末端催化区域,linker区域和c-端纤维素结合区域。n-端(adgkstrywdcckpscswpgkasvn)是内切葡聚糖酶45家族的保守氨基酸序列,所以stce1被认为是gh45家族的成员。c-端含有cbm结构域是纤维素的结合区域。在n-端第87氨基酸处(n-x-s/t)是stce1潜在的糖基化位点。stce1在去除微纤维、抗阴离子表面活性剂和氧化剂等方面性能优异,在纺织洗涤业具有广泛的应用前景{参考文献:cn200480036105b和koga,j.,y.baba,a.shimonaka,t.nishimura,s.hanamura和t.kono(2008).purification and characterization of a new family 45endoglucanase,stce1,from staphylotrichum coccosporum and its overproduction in humicola insolens.appl.environ.microbiol.74(13):4210-4217}。
5.然而,已有的文献报道stce1的产量和酶活均不高。stce1原始菌株staphylotrichum coccosporum nbrc 31817的上清培养液中仅有0.0085g/l。jinichiro koga等已经成功将stce1转入到腐质霉中,重组的stce1是以一个成熟蛋白的形式在腐质霉中表达,酶活力很高,上清液中含有目的蛋白0.90g/l,占总蛋白的27%{参考文献:koga,j.,y.baba,a.shimonaka,t.nishimura,s.hanamura和t.kono(2008).purification and characterization of anew family 45endoglucanase,stce1,from staphylotrichum coccosporum and its overproduction in humicola insolens.appl.environ.microbi
ol.74(13):4210-4217}。常艳艳等采用毕赤酵母表达stce1,其上清粗酶液酶活力2.09u/ml。采用大肠杆菌进行表达,酶活力为1.23u/ml{参考文献:常艳艳.中性内切葡聚糖酶基因stce1的克隆与表达.深圳大学硕士学位论文}。stce1的低酶活和低产量限制了其在纺织洗涤业的应用。
技术实现要素:
6.本发明就现有技术的问题,将来源于staphylotrichum coccosporum的stce1进行突变,得到的突变体酶活和/或蛋白表达相应提高。
7.具体的,
8.一方面,本发明提供了一种包含如下氨基酸序列的纤维素酶变体或其活性片段,所述氨基酸序列包含选自以下对应于seq id no:1的一个或多个位置的突变:
9.(1).76、81、91、100、114、121、138、141、156、158、160、162、171、191、193、218、250、285、289、294;
10.(2).76l/v/a、81q/d/t、91i/v、100h/g、114v/i/n、121i/f、138s、141i/t、156e/n、158m、160g、162i/v、171n/e、191q/d、193l/y、218t/w、250e/d、285d/e、289n/e、294f/w;
11.(3).76l、81q、91i、100h、114v、121i、138s、141i、156e/n、158m、160g、162v、171n、191q、193l、218t、250e、285d、289n、294f;
12.其中所述变体或其活性片段具有内切葡聚糖酶活性,并且其中该变体或其活性片段的氨基酸位置通过与seq id no:1的氨基酸序列相对应来编号。
13.在一些实施例中,本发明所述的包含如下氨基酸序列的纤维素酶变体或其活性片段,所述氨基酸序列包含选自以下对应于seq id no:1的一个或多个位置的突变:(1).76、81、91、100、114、121、138、141、156、158、160、162、171、191、193、218、250、285、289、294。
14.在一些实施例中,本发明所述的包含如下氨基酸序列的纤维素酶变体或其活性片段,所述氨基酸序列包含选自以下对应于seq id no:1的一个或多个位置的突变:(2).76l/v/a、81q/d/t、91i/v、100h/g、114v/i/n、121i/f、138s、141i/t、156e/n、158m、160g、162i/v、171n/e、191q/d、193l/y、218t/w、250e/d、285d/e、289n/e、294f/w。
15.在一些实施例中,本发明所述的包含如下氨基酸序列的纤维素酶变体或其活性片段,所述氨基酸序列包含选自以下对应于seq id no:1的一个或多个位置的突变:(3).76l、81q、91i、100h、114v、121i、138s、141i、156e/n、158m、160g、162v、171n、191q、193l、218t、250e、285d、289n、294f。
16.在一些实施例中,本发明所述的纤维素酶变体或其活性片段中在对应于seq id no:1位置的两个或更多个位置的突变选自:
17.(i).91+141、114+160、121+295、138+156、141+191、141+193、121+295、193+289、162+193+289、121+162+295;
18.(ii).91i+141i、114v+160g、121i+295i、114i+160g、121i+285d、138s+156e、138s+156n、141i+191q、141i+191d、141i+250e、141i+250d、193l+289n、193y+289n、121i+162v+289n、121i+162i+289n、162v+193l+289n、162v+193y+289n、162i+193y+289n;
19.(iii).91i+141i、114v+160g、121i+295i、121i+285d、138s+156n、141i+191q、141i+250e、193l+289n、121i+162v+289n、162v+193l+289n。
20.在一些实施例中,所述的纤维素酶变体或其活性片段中在对应于seq id no:1位置的两个或更多个位置的突变选自:(i).91+141、114+160、121+295、138+156、141+191、141+193、121+295、193+289、162+193+289、121+162+295。
21.在一些实施例中,所述的纤维素酶变体或其活性片段中在对应于seq id no:1位置的两个或更多个位置的突变选自:(ii).91i+141i、114v+160g、121i+295i、114i+160g、121i+285d、138s+156e、138s+156n、141i+191q、141i+191d、141i+250e、141i+250d、193l+289n、193y+289n、121i+162v+289n、121i+162i+289n、162v+193l+289n、162v+193y+289n、162i+193y+289n。
22.在一些实施例中,所述的纤维素酶变体或其活性片段中在对应于seq id no:1位置的两个或更多个位置的突变选自:(iii).91i+141i、114v+160g、121i+295i、121i+285d、138s+156n、141i+191q、141i+250e、193l+289n、121i+162v+289n、162v+193l+289n。
23.在一些实施例中,所述的纤维素酶变体或其活性片段进一步包含选自以下的一个或多个突变:
24.(a).在对应于seq id no:1的1位之前具有一个、两个、三个或更多个氨基酸残基的插入;
25.(b).在对应于seq id no:1的1位之前具有一个、两个、三个或更多个氨基酸残基的插入,其中所属插入选自:l、k、r、a、ea、la、ar、ala、lar;
26.(c).在对应于seq id no:1的1位之前具有一个或两个氨基酸残基的插入,其中所属插入选自:a、la;
27.(d).在对应于seq id no:1的295位之后具有一个、两个、三个或更多个氨基酸残基的插入;
28.(e).在对应于seq id no:1的295位之后具有一个、两个、三个或更多个氨基酸残基的插入,其中所属插入选自:l、k、r、a、ea、la、ar、ala、lar;
29.(f).在对应于seq id no:1的295位之后具有一个或两个氨基酸残基的插入,其中所属插入选自:k、kr;
30.(g).(a)至(c)中任一项与(d)至(f)中任一项的组合。
31.在一些实施例中,所述的纤维素酶变体或其活性片段进一步包含选自以下的一个或多个突变:(a).在对应于seq id no:1的1位之前具有一个、两个、三个或更多个氨基酸残基的插入。
32.在一些实施例中,所述的纤维素酶变体或其活性片段进一步包含选自以下的一个或多个突变:(b).在对应于seq id no:1的1位之前具有一个、两个、三个或更多个氨基酸残基的插入,其中所属插入选自:l、k、r、a、ea、la、ar、ala、lar。
33.在一些实施例中,所述的纤维素酶变体或其活性片段进一步包含选自以下的一个或多个突变:(c).在对应于seq id no:1的1位之前具有一个或两个氨基酸残基的插入,其中所属插入选自:a、la。
34.在一些实施例中,所述的纤维素酶变体或其活性片段进一步包含选自以下的一个或多个突变:(d).在对应于seq id no:1的295位之后具有一个、两个、三个或更多个氨基酸残基的插入。
35.在一些实施例中,所述的纤维素酶变体或其活性片段进一步包含选自以下的一个
或多个突变:(e).在对应于seq id no:1的295位之后具有一个、两个、三个或更多个氨基酸残基的插入,其中所属插入选自:l、k、r、a、ea、la、ar、ala、lar。
36.在一些实施例中,所述的纤维素酶变体或其活性片段进一步包含选自以下的一个或多个突变:(f).在对应于seq id no:1的295位之后具有一个或两个氨基酸残基的插入,其中所属插入选自:k、kr。
37.在一些实施例中,所述的纤维素酶变体或其活性片段进一步包含选自以下的一个或多个突变:(a)和(d);或(a)和(e);或(a)和(f);或(b)和(d);或(b)和(e);或(b)和(f);或(c)和(d);或(c)和(e);或(c)和(f);其中,(a),(b),(c),(d),(e),(f)为本发明定义的突变情况。
38.在一些实施例中,所述的纤维素酶变体或其活性片段具有seq id no:3至seq id no:32中任一序列。
39.在一些实施例中,所述的纤维素酶变体或其活性片段具有seq id no:3的序列;或具有seq id no:4的序列;或具有seq id no:5的序列;或具有seq id no:6的序列;或具有seq id no:7的序列;或具有seq id no:8的序列;或具有seq id no:9的序列;或具有seq id no:10的序列;或具有seq id no:11的序列;或具有seq id no:12的序列;或具有seq id no:13的序列;或具有seq id no:14的序列;或具有seq id no:15的序列;或具有seq id no:16的序列;或具有seq id no:17的序列;或具有seq id no:18的序列;或具有seq id no:19的序列;或具有seq id no:20的序列;或具有seq id no:21的序列;或具有seq id no:22的序列;或具有seq id no:23的序列;或具有seq id no:24的序列;或具有seq id no:25的序列;或具有seq id no:26的序列;或具有seq id no:27的序列;或具有seq id no:28的序列;或具有seq id no:29的序列;或具有seq id no:30的序列;或具有seq id no:31的序列;或具有seq id no:32的序列。
40.stce1-1的氨基酸序列:seq id no:3
41.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatslsggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
42.stce1-2的氨基酸序列:seq id no:4
43.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggnqaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
44.stce1-3的氨基酸序列:seq id no:5
45.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeitftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
46.stce1-4的氨基酸序列:seq id no:6
47.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsy
gfaatsisggneaswccgcyeltftsgpvahktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
48.stce1-5的氨基酸序列:seq id no:7
49.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdvgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
50.stce1-6的氨基酸序列:seq id no:8
51.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdiampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
52.stce1-7的氨基酸序列:seq id no:9
53.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqsgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
54.stce1-8的氨基酸序列:seq id no:10
55.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfggiagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
56.stce1-9的氨基酸序列:seq id no:11
57.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcesfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
58.stce1-10的氨基酸序列:seq id no:12
59.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcnsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
60.stce1-11的氨基酸序列:seq id no:13
61.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsmpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
62.stce1-12的氨基酸序列:seq id no:14
63.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpgalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
64.stce1-13的氨基酸序列:seq id no:15
65.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaavkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
66.stce1-14的氨基酸序列:seq id no:16
67.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfnwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
68.stce1-15的氨基酸序列:seq id no:17
69.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpsqlvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
70.stce1-16的氨基酸序列:seq id no:18
71.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpsellartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
72.stce1-17的氨基酸序列:seq id no:19
73.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqstsssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
74.stce1-18的氨基酸序列:seq id no:20
75.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassetssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
76.stce1-19的氨基酸序列:seq id no:21
77.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcdkqndwysqcl
78.stce1-20的氨基酸序列:seq id no:22
79.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqnnwysqcl
80.stce1-21的氨基酸序列:seq id no:23
81.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqfl
82.stce1-22的氨基酸序列:seq id no:24
83.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeitftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfggiagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
84.stce1-23的氨基酸序列:seq id no:25
85.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdiampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqci
86.stce1-24的氨基酸序列:seq id no:26
87.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpsellartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqnnwysqcl
88.stce1-25的氨基酸序列:seq id no:27
89.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdiampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcdkqndwysqcl
90.stce1-26的氨基酸序列:seq id no:28
91.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdiampgggvgifdgcspqfgglagdryggvssrsqcdsfpaavkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqnnwysqcl
92.stce1-27的氨基酸序列:seq id no:29
93.aadgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqssssss
sssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
94.stce1-28的氨基酸序列:seq id no:30
95.laadgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqcl
96.stce1-29的氨基酸序列:seq id no:31
97.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqclk
98.stce1-30的氨基酸序列:seq id no:32
99.adgkstrywdcckpscswpgkasvnqpvfacsanfqrisdpnvksgcdggsayacadqtpwavndnfsygfaatsisggneaswccgcyeltftsgpvagktmvvqststggdlgtnhfdlampgggvgifdgcspqfgglagdryggvssrsqcdsfpaalkpgcywrfdwfknadnptftfrqvqcpselvartgcrrnddgnfpvftppsggqsssssssssakptstststtstkatsttstassqtssstgggcaaqrwaqcggigfsgcttcvsgttcnkqndwysqclkr
100.在一些实施例中,所述的纤维素酶变体或其活性片段当与亲本多肽比较时,所述变体具有至少一种改善的性质,所述至少一种改善的性质选自提高的酶活、提高的蛋白表达量。
101.另一方面,本发明提供了一种组合物,所述组合物包含本发明提供的纤维素酶变体或其活性片段。
102.在一些实施例中,所述组合物选自酶组合物、洗涤剂组合物和织物护理组合物。
103.另一方面,本发明提供了一种多核苷酸,所述多核苷酸包含编码本发明提供的纤维素酶变体或其活性片段的核酸序列。
104.另一方面,本发明提供了一种表达载体,所述表达载体包含本发明提供的多核苷酸。
105.另一方面,本发明提供了一种宿主细胞,所述宿主细胞包含本发明提供的表达载体。
106.另一方面,本发明提供了一种生产本发明提供的纤维素酶变体或其活性片段的方法,所述方法包括:(a)用本法明天提供的表达载体稳定地转化本法明提供的宿主细胞;(b)在适合于所述宿主细胞产生所述纤维素酶变体或其活性片段的条件下培养经转化的所述宿主细胞;和(c)回收所述纤维素酶变体或其活性片段。
107.另一方面,本发明提供了本法明所述的纤维素酶变体或其活性片段在酶组合物、洗涤剂组合物、织物护理组合物、纺织品整理加工或纸张和纸浆加工中的用途。
108.为了清楚起见定义以下术语。未定义的术语应当符合本领域中所使用的常规含义。例如,本文未定义的技术和科学术语具有与普通技术人员通常理解的相同的含义(参见,例如,singleton和sainsbury,dictionary of microbiology and molecular biology[微生物学和分子生物学词典],第2版,约翰
·
威利父子出版公司,纽约州1994;和hale和marham,哈伯科林斯生物学词典(the harper collins dictionary of biology),哈珀永
久出版社,纽约州1991)。
[0109]
除非上下文另有明确指示,单数“一个/一种”和“该/所述”包括复数引用。
[0110]
当与数值结合使用时,术语“约”是指数值的-10%至+10%的范围。
[0111]
本发明的组合物,包含有效量的本文所述的纤维素酶变体或其活性片段。在一些实施例中,纤维素酶变体或其活性片段的有效量是按组合物的重量计从约0.00001%至约10%、约0.0001%至约10%、约0.001%至约5%、约0.001%至约2%或约0.005%至约0.5%的纤维素酶。在其他实施例中,纤维素酶变体或其活性片段的有效量是从约0.001%至约5.0重量百分比的组合物。在仍其他实施例中,纤维素酶变体或其活性片段的有效量是从约0.001%至约4.5重量百分比的组合物。在仍又其他实施例中,纤维素酶变体或其活性片段的有效量是从约0.001%至约4.0重量百分比的组合物。在又甚至其他实施例中,纤维素酶变体或其活性片段的有效量是从约0.001%至约3.5、3.6、3.7、3.8或3.9重量百分比的组合物。
[0112]
本发明的组合物,还可以包括必要的辅助成分。术语“辅助成分”意指为所希望的特定类型的洗涤剂或织物护理组合物以及产品形式(例如液体、颗粒状、粉末、棒状、糊状、片剂、凝胶、单位剂量、薄片或泡沫组合物)选择的任何液体、固体或气体材料,这些材料还优选地与用于该组合物中的纤维素酶变体或其活性片段相容。在一些实施例中,颗粒状组合物处于“紧密”形式,而在其他实施例中,液体组合物处于“浓缩”形式。
[0113]
在一些实施例中,本发明组合物呈选自以下的形式:粉末、液体、颗粒状、棒状、固体、半固体、凝胶、糊状、乳剂、片剂、胶囊、单位剂量、薄片和泡沫。在甚至另外的实施例中,该组合物呈选自以下的形式:液体、粉末、颗粒状固体、片剂、薄片和单位剂量。在一些实施例中,本文所述的组合物以单位剂量形式提供,包括片剂、胶囊、药袋、小袋、薄片和多室袋。在一些实施例中,单位剂量形式被设计成在多隔室小袋(或其他单位剂量形式)内提供成分的控制释放。在一些实施例中,单位剂量形式由用水溶性膜或水溶性小袋包裹的片剂提供。
[0114]
在一些实施例中,本发明组合物进一步包含一种或多种表面活性剂。在一些其他实施例中,该表面活性剂选自非离子、两性的、半极性、阴离子、阳离子、两性离子及其组合和混合物。在其他实施例中,该表面活性剂选自阴离子、阳离子、非离子和两性离子化合物。在一些实施例中,该组合物包含按组合物的重量计从约0.1%至约60%、约1%至约50%或约5%至约40%的表面活性剂。
[0115]
术语“纤维素酶变体”是指通过取代、添加或缺失一个或多个氨基酸衍生自亲本多肽或参比多肽的重组多肽。纤维素酶变体与亲本多肽可以相差少量的氨基酸残基并且可以通过它们与亲本多肽的一级氨基酸序列同源性/同一性的水平来定义。例如,纤维素酶变体与亲本(或参比)多肽具有至少60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或小于100%的氨基酸序列同一性。
[0116]
术语“突变”是指氨基酸序列中的任何变化或改变,包括用与起始氨基酸不同的氨基酸对氨基酸序列的鉴定位置处的氨基酸进行的取代、在氨基酸序列的鉴定位置处的氨基酸的缺失、在氨基酸序列的鉴定位置处的氨基酸的插入、在氨基酸序列中的氨基酸侧链的替换、和/或氨基酸序列的化学修饰。
[0117]
术语“表达载体”是指包含编码特定多肽的dna序列的dna构建体,并且有效地连接到能够在适合的宿主中实现多肽表达的适合的控制序列。这样的控制序列包括影响转录的
启动子,控制这种转录的任选的操纵子序列,编码适合的mrna核糖体结合位点的序列,以及控制转录和翻译终止的序列。载体可以是质粒、噬菌体颗粒,或简单地是潜在的基因组插入物。一旦转化入适合的宿主中,载体可以独立于宿主基因组复制和起作用,或者在某些情况下可以整合入基因组本身。在一些实施例中,表达载体可以在异源宿主细胞中提供,该异源宿主细胞适合用于表达本文所述的纤维素酶变体或其活性片段或者适合用于在将该表达载体引入适合的宿主细胞之前繁殖该表达载体。在一些实施例中,通过标准分子克隆技术将多核苷酸包含在表达盒中和/或克隆到适合的表达载体中。此类表达盒或载体含有辅助转录起始和终止的序列(例如启动子和终止子),并且通常含有可选择标记。
[0118]
术语“宿主细胞”通常是指用本领域已知的重组dna技术构建的载体转化或转染的原核或真核宿主。经转化的宿主细胞能够复制编码蛋白质变体的载体或表达所希望的蛋白质变体。在编码蛋白质变体预成型(pre-form)或形式(pro-form)的载体的情况下,当表达时,这些变体典型地从宿主细胞分泌到宿主细胞培养基中。在一些实施例中,宿主细胞,其中本文所述的纤维素酶变体或其活性片段在异源生物体(即除了是大孢圆孢霉属(staphylotrichum)物种之外的生物体)中表达。示例性异源生物体包括例如:枯草芽孢杆菌(b.subtilis)、地衣芽孢杆菌(b.licheniformis)、迟缓芽孢杆菌(b.lentus)、短芽孢杆菌(b.brevis)、嗜热脂肪土芽孢杆菌(geobacillus(先前为芽孢杆菌属)stearothermophilus)、嗜碱芽孢杆菌(b.alkalophilus)、解淀粉芽孢杆菌(b.amyloliquefaciens)、凝结芽孢杆菌(b.coagulans)、环状芽孢杆菌(b.circulans)、灿烂芽胞杆菌(b.lautus)、巨大芽孢杆菌(b.megaterium)、苏云金芽孢杆菌(b.thuringiensis)、变铅青链霉菌(s.lividans)、鼠灰链霉菌(s.murinus)、荧光假单孢菌(p.fluorescens)、施氏假单胞菌(p.stutzerei)、奇异变形杆菌(p.mirabilis)、富养罗尔斯通菌(r.eutropha)、肉葡萄球菌(s.carnosus)、乳酸乳球菌(l.lactis)、大肠杆菌(e.coli)、酵母(例如像酵母菌属物种(saccharomyces spp.)或裂殖酵母属物种(schizosaccharomyces spp.),例如酿酒酵母(s.cerevisiae),卢克诺文思金孢子菌(c.lucknowense)和丝状真菌例如曲霉属物种(aspergillus spp.),例如米曲霉(a.oryzae)或黑曲霉(a.niger)、灰腐质霉(h.grisea)、特异腐质霉和里氏木霉(t.reesei.)。用于将核酸转化到这些生物体中的方法是本领域熟知的。用于转化曲霉属宿主细胞的适合的程序描述于例如ep 238023中。用于转化木霉属宿主细胞的适合的程序描述于例如steiger等人,2011,appl.environ.microbiol.[应用与环境微生物学]77:114-121。
[0119]
术语“杂交”是指通过碱基配对将核酸链与互补链连接的过程,如本领域已知的。
[0120]
术语“杂交条件”是指进行杂交反应的条件。这些条件通常根据杂交在其下测量的条件的“严格”度来分类。严格度可以是基于例如结合复合物或探针的核酸的解链温度(tm)。例如,“最大严格”典型地发生在约tm-5℃(低于探针的tm 5℃);“高严格”发生在低于tm约5℃-10℃;“中等严格”发生在低于探针的tm约10℃-20℃;并且“低严格”发生在低于tm约20℃-25℃。可替代地,或另外地,杂交条件可以基于杂交的盐或离子强度条件,和/或一次或多次严格洗涤,例如:6x ssc=非常低严格;3x ssc=低至中严格;1x ssc=中严格;以及0.5x ssc=高严格。在功能上,最大严格条件可以用于鉴定与杂交探针具有严格同一性或近乎严格同一性的核酸序列;而高严格条件用于鉴定与探针具有约80%或更高序列同一
性的核酸序列。对于需要高选择性的应用,通常希望使用相对严格的条件来形成杂交(例如,使用相对较低的盐和/或高温条件)。
[0121]
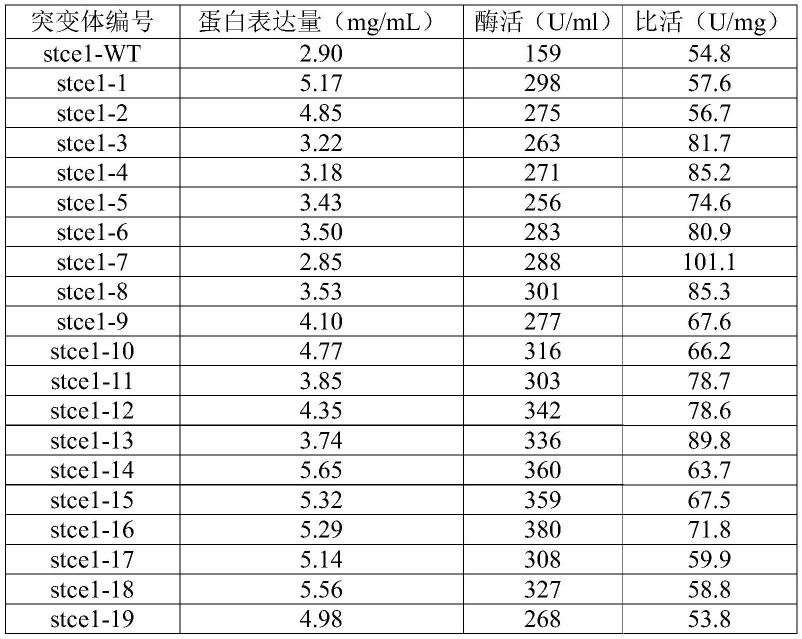
术语“多核苷酸”涵盖能够编码多肽的dna、rna、异源双链体、以及合成分子。核酸可以是单链的或双链的,并且可以具有化学修饰。术语“核酸”和“多核苷酸”可互换地使用。由于遗传密码是简并的,可以使用多于一个密码子来编码特定的氨基酸,并且本发明的组合物和方法涵盖编码特定氨基酸序列的核苷酸序列。除非另有说明,核酸序列以5’至3’取向呈现。
[0122]
术语“多肽”是指包含通过肽键连接的多个氨基酸的分子。术语“多肽”、“肽”和“蛋白质”可互换地使用。蛋白质可以任选地被修饰(例如,糖基化、磷酸化、酰化、法尼基化、异戊二烯化和磺化)以增加功能性。当此类氨基酸序列展现出活性时,它们可以被称为“酶”。使用针对氨基酸残基的常规单字母或三字母密码,采用标准氨基-至-羧基端取向(即n
→
c)表示的氨基酸序列。
[0123]
术语“重组”是指例如像通过以下被修饰以改变其序列或表达特征的遗传材料(即核酸、它们编码的多肽、以及包含此类多核苷酸的载体和细胞):使编码序列突变以产生改变的多肽,将编码序列融合到另一基因的编码序列,将基因置于不同启动子的控制下,在异源生物体中表达基因,以降低或升高的水平表达基因,和以与其天然表达谱不同的方式有条件地或组成地表达基因。通常,基于此的重组核酸、多肽和细胞已被人为操纵,这样使得它们与自然界中发现的相关的核酸、多肽和/或细胞不相同。
[0124]
术语“信号序列”是指与多肽的n末端部分结合的并且促进成熟形式的蛋白质从细胞中分泌的氨基酸序列。细胞外蛋白质的成熟形式缺乏在分泌过程中被切除的信号序列。
[0125]
术语“衍生自”涵盖术语“起源于”、“获得自”、“可获得自”、“分离自”和“产生自”,并且通常表示一种指定的材料在另一种指定的材料中找到其起源或具有可以参考另一种指定的材料来描述的特征。
[0126]
术语“内切葡聚糖酶”是指内切-1,4-(1,3;1,4)-β-d-葡聚糖4-葡聚糖水解酶(e.c.3.2.1.4),其催化纤维素、纤维素衍生物(如羧甲基纤维素和羟乙基纤维素)、地衣多糖、混合的β-1,3葡聚糖如谷物β-d-葡聚糖或木葡聚糖中的β-1,4键、以及包含纤维素组分的其他植物材料中的1,4-β-d-糖苷键的内切水解。可以根据实例中描述的程序确定内切葡聚糖酶活性。
[0127]
在将核酸序列插入细胞中的背景下,术语“引入”意指转化、转导或转染。转化手段包括本领域已知的原生质体转化、氯化钙沉淀、电穿孔、裸dna等等。
[0128]
术语“信号序列”或“信号肽”是指与多肽的n末端部分结合的并且促进成熟形式的蛋白质从细胞中分泌的氨基酸序列。细胞外蛋白质的成熟形式缺乏在分泌过程中被切除的信号序列。
[0129]
术语“野生型”或“亲本”是指在一个或多个氨基酸位置处不包括人造的取代、插入或缺失的天然存在的多肽。相似地,关于多核苷酸,术语“野生型”或“亲本”是指在一个或多个核苷处不包括人造的取代、插入或缺失的天然存在的多核苷酸。然而,编码野生型或亲本多肽的多核苷酸不限于天然存在的多核苷酸,并且涵盖编码野生型或亲本多肽的任何多核苷酸。
[0130]
术语“天然存在的”是指在自然界中发现的任何物质(例如多肽或核酸序列)。相
反,术语“非天然存在的”是指在自然界中没有发现的任何物质(例如,在实验室中生产的重组核酸和多肽序列或野生型序列的修饰)。
[0131]
本文所述的氨基酸取代使用一个或多个以下命名法:位置或起始氨基酸:位置:一个或多个取代的氨基酸。对仅一个位置的提及涵盖可以存在于参比多肽、亲本或野生型分子中在该位置处的任何起始氨基酸,以及此类起始氨基酸可以被其取代的任何氨基酸(即,氨基酸取代排除了此类参比多肽、亲本或野生型分子的起始氨基酸)。对经取代的氨基酸或起始氨基酸的提及可以进一步表示为由斜线(“/”)分开的若干个经取代的氨基酸或若干个起始氨基酸。例如,x130a/n-209-213代表三个氨基酸取代组合,其中x是在位置130处的可以被丙氨酸(a)或天冬酰胺(n)取代的任何起始氨基酸;209代表任何起始氨基酸可以被不是起始氨基酸的氨基酸取代的位置;并且213代表任何起始氨基酸可以被不是起始氨基酸的氨基酸取代的位置。通过另外的实例,e/q/s101f/g/h/t/v代表在位置101处的五个可能的取代,其中该起始氨基酸谷氨酸(e)、谷氨酰胺(q)或丝氨酸(s)可以被苯丙氨酸(f)、甘氨酸(g)、组氨酸(h)、苏氨酸(t)或缬氨酸(v)取代。
附图说明
[0132]
图1是载体phect-stce1结构图
[0133]
图2是亲本stce1-wt和stce1突变体发酵液sds-page分析
具体实施方式
[0134]
下面结合实例对本发明的方法做进一步说明。但实例仅限于说明,并不限于此。下列实施例中未注明具体条件的实验方法,通常可按常规条件,如j.萨姆布鲁克(sambrook)等编写的《分子克隆实验指南》中所述的条件,或按照制造厂商所建议的条件运行。本领域相关的技术人员可以借助实施例更好地理解和掌握本发明。但是,本发明的保护和权利要求范围不限于所提供的案例。下面结合实施例对本发明的方法做进一步说明。
[0135]
实施例1:stce1及其突变体表达菌株的构建
[0136]
选择编码纤维素酶stce1的基因(koga,j.,y.baba,a.shimonaka,t.nishimura,s.hanamura和t.kono(2008).purification and characterization of a new family 45endoglucanase,stce1,from staphylotrichum coccosporum and its overproduction in humicola insolens.appl.environ.microbiol.74(13):4210-4217)作为亲本纤维素酶stce1-wt(核苷酸序列如seq id no:2所示),交付通用生物系统(安徽)有限公司合成,合成的stce1-wt基因位于载体phect-stce1上,位于cbhi启动子和cbhi终止子之间。载体phect-stce1结构图如图1所示。
[0137]
使用本领域已知的分子生物学技术,以载体phect-stce1为模板,采用takara的定点突变试剂盒takara mutanbest kit(code no.r401),将多个氨基酸突变(取代、插入)引入亲本stce1-wt中,得到包含各种stce1突变体的表达载体。
[0138]
参照文献(penttila m,nevalainen h,ratto m,et al.a versatile transformation system for the cellulolytic filamentous fungus trichoderma reesei[j].gene,1987,61(2):155-164.)报道的原生质体转化方法,将亲本stce1-wt和stce1突变体表达载体分别导入里氏木霉rut-c30宿主中。构建的亲本stce1-wt和stce1突
变菌株的编号、突变位点和seq id no如下表1所示。
[0139]
表1 stce1-wt和stce1突变体编号、突变位点和seq id no
[0140]
突变体编号突变位点氨基酸长度seq id nostce1-wt未突变2951stce1-176l2953stce1-281q2954stce1-391i2955stce1-4100h2956stce1-5114v2957stce1-6121i2958stce1-7138s2959stce1-8141i29510stce1-9156e29511stce1-10156n29512stce1-11158m29513stce1-12160g29514stce1-13162v29515stce1-14171n29516stce1-15191q29517stce1-16193l29518stce1-17218t29519stce1-18250e29520stce1-19285d29521stce1-20289n29522stce1-21294f29523stce1-2291i+141i29524stce1-23121i+295i29525stce1-24193l+289n29526stce1-25121i+285d29527stce1-26121i+162v+289n29528stce1-27位置1之前插入a29629stce1-28位置1之前插入la29730stce1-29位置295之后插入k29631stce1-30位置295之后插入kr29732
[0141]
实施例2:stce1及其突变体的摇瓶诱导表达
[0142]
将构建的亲本stce1-wt和stce1突变菌株接种于接种pda(马铃薯葡萄糖肉汤培养基+2%琼脂)固体平板中,培养7天。用无菌水洗下孢子制成孢子悬液,接种至50ml种子培养基(乳糖20g/l,氯化钙1g/l,硫酸镁0.6g/l,磷酸二氢钾5g/l,硫酸铵2.5g/l,玉米浆20g/l,氨水调节ph4.5)中,并加入50μl tr2溶液(硼酸2g/l,一水硫酸锌15g/l,七水硫酸铜8g/l,
六水氯化钴20g/l,硫酸亚铁50g/l,一水硫酸锰16g/l),28℃220rpm培养26-28h。取5ml培养好的种子菌液转接至50ml发酵培养基(葡萄糖5g/l,乳糖13g/l,氯化钙0.5g/l,硫酸镁1g/l,磷酸二氢钾5.9g/l,硫酸铵5.6g/l,玉米浆2.7g/l,氨水调节ph4.5)并加入20μl tr2溶液和20μl tr1溶液(柠檬酸铁5.76g/l,乙酸锌0.768g/l,edta 0.81g/l),28℃220rpm培养。每24h用氨水调ph至4.5。发酵168小时结束,收集发酵上清液。
[0143]
实施例3:stce1及其突变体酶活和比活的测定
[0144]
按照文献(常艳艳.中性内切葡聚糖酶基因stce1的克隆与表达.深圳大学硕士学位论文.)所述的cmcna方法对纤维素酶活力进行测定。纤维素酶活力的定义为在50℃、ph为6.0条件下,每分钟从浓度10mg/ml羧甲基纤维素钠溶液中,降解释放1μmol还原糖所需要的酶量为一个酶活力单位u,还原糖以葡萄糖等量。
[0145]
按照takara bradford protein assay kit(code no.t9310a)对发酵液上清的总蛋白浓度进行测定。各取等量的stce1-wt和stce1突变体的发酵液进行sds-page检测,stce1-wt和stce1突变体蛋白条带在45-50kda之间,结果如图2所示。根据sds-page条带使用gel analysis pro软件计算亲本stce1-wt和stce1突变体的发酵液上清总蛋白占比,从而得到亲本stce1-wt和stce1突变体的蛋白浓度,进而得出stce1-wt和stce1突变体的比活(比活=酶活/蛋白浓度),如表2所示。
[0146]
表2亲本stce1-wt和stce1突变体的酶活、蛋白表达量和比活
[0147]
[0148][0149]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
[0150]
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1