基于改进CS‑BPNN的食用菌发酵过程关键参量的软测量方法与流程
本发明是一种用于解决食用菌发酵过程中难以用物理传感器在线实时测量的菌丝生物量这个关键生化变量的在线估计问题,属于软测量及软仪表构造的技术领域。
背景技术:
发酵是一类重要的工业生产工程,其典型特征是内在机理复杂、可重复性差、生产波动差,具有高度的非线性和时变特性;对其进行在线测量,是进行补料、供氧等动态控制的重要依据,同时也是进行优化调度的前提和基础。一般的,重要过程变量的测得是通过实验室周期性的采样、离线操作、分析测定。取样的周期对测得的变量数值有较大的影响,且时间上往往滞后,导致变量信息滞后,使得发酵过程难以进行实时闭环优化控制。因此,研究如何及时获得食用菌发酵过程中关键变量的状态信息,对发酵过程构建最优生长环境,进而实施优化控制,提高产品产量与质量均具有重要意义。
bp神经网络软测量是近年来应用很广泛的一种数据驱动软测量方法,因其优良的非线性逼近能力,已被广泛地被用于非线性系统过程的软测量建模。在本发明中,针对食用菌发酵过程非线性、大滞后、易染菌且关键生化参数难以实时在线测量等问题,提出一种改进cs-bp神经网络的软测量建模方法。该方法使得cs算法在搜索前期保证全局寻优能力;在搜索后期,充分利用局部信息,提高搜索精度,缩短了学习时间。
技术实现要素:
为了解决食用菌发酵过程中非常重要,但难以用物理传感器在线实时测量或实时测量代价非常高的状态量的测量方法之不足,本发明提出一种基于改进cs-bpnn的食用菌发酵过程关键变量软测量方法,通过常规在线测量仪表提供的输入变量的测量信号,给出当前关键状态变量的预测值,为食用菌发酵过程的参数检测和优化运行提供关键工艺指标。
本发明的技术方案如下:
基于改进的cs-bpnn食用菌发酵过程关键状态变量软测量方法,包括如下步骤:
步骤1:辅助变量选择,选取能直接测量且与过程密切相关的外部变量,用基于离散pso的辅助变量选择算法来选取最适的外部变量作为软测量模型的辅助变量;
步骤2:建立训练数据库,采集相同工艺下若干历史罐批次的辅助变量和关键状态变量数据,构造输入输出向量对的集合,生成静态训练样本数据库;并对其进行归一化处理;其中输入向量是辅助变量,输出向量即关键状态变量;
步骤3:设计bp神经网络模型,设置其输入、隐含层以及输出层的神经元个数;
步骤4:利用改进的布谷鸟算法优化bp神经网络的权值与阈值,寻找预测效果最好的权值与阈值;训练优化后的神经网络得到软测量模型。
步骤5:利用已经训练好的软测量模型,根据当前待预测罐批的最新输入向量,获得关键状态变量的预测值。
进一步地,步骤1包括:
步骤1.1,采集发酵过程外部变量数据:通过气体流量传感器、转速传感器、co2气敏电极、液位探头、热电阻、溶氧电极、ph电极、蠕动泵采集空气流量q、电机搅拌转速r、co2释放量u、发酵液体积v、发酵罐温度t、溶解氧do、发酵液酸碱度ph、葡萄糖流加速率ρ、氨水流加速率η;发酵液经离心分离器分离后离线检测得到关键状态变量,包括菌丝生物量s;
步骤1.2,基于离散pso的辅助变量选择算法,找到最优位置和速度的粒子,将其离散化,得到最适辅助变量组合。具体实现包括:
所述步骤1.2的具体过程包括:
步骤1.2.1:初始化离散pso的种群和参数,初始化种群数m=22、惯性权重w=0.8、加速常数c1=c2=0.7、最大限速vmax=4;随机产生元素0和1的m个粒子xi=(xi1,xi2,...,xid),i=1,...,m,组成初始群;随机产生(0,1)之间的随机数作为各粒子的初始速度vij,组成初始速度矩阵vm×d。每个粒子的历史最好位置pi和种群最好位置pg初始值都设为d维0向量;
步骤1.2.2:评价每个粒子的适应值;根据pls回归算法和式
步骤1.2.3:更新粒子最优位置。对每个粒子xi,将其适应值f(xi)与其经历过的最好位置pi对应的适应值f(pi)作比较,如果f(xi)优于f(pi),则将xi替换为当前的最好位置;
步骤1.2.4:更新种群最优位置。对当前种群(m个粒子)中最好位置pbest,将其对应的适应值f(pbest)与种群所经历过的最好位置pg对应的适应值f(pg)作比较,如果f(pbest)优于f(pg),则将pbest替换为种群最优位置;为防止结果陷入局部优化,将种群最优位置pg记下后,再将其对应的那个粒子重新初始化;
步骤1.2.5:在t+1时刻,粒子i在第d(d=1,2,...,d)维空间的速度和位置的表达式为:vid(t+1)=w×vid(t)+c1r1×(pid(t)-xid(t))+c2r2×(pgd(t)-xid(t))和xid(t+1)=xid(t)+vid(t+1);根据这两个公式调整当前粒子的位置和速度,并根据式
步骤1.2.6:判断是否达到终止条件,若上述条件满足,终止迭代,否则返回步骤1.2.2。
进一步地,步骤3的实现具体如下:
选取的网络结构为三层神经网络结构,根据辅助变量的个数确定输入层设置为5个神经元,根据关键状态变量的个数确定输出层设置为1个神经元,根据构造法经验公式midn=2inn+1设置隐含层的节点数,其中midn为隐含层节点数,inn为输入层节点数。
进一步地,步骤4的实现包括如下步骤:
步骤4.1,将bp神经网络看作是改进cs算法的适应度函数,那么可利用算法自身的全局寻优能力强的优势去寻觅最优的权值阈值组合。根据样本维数初步确定bp网络结构,依次确定权值和阈值总数,进而确定改进cs算法中布谷鸟个体的编码长度。随机产生n个鸟巢xi(i=1,2,...,n),每个鸟巢代表一组将要优化训练的神经网络的权值和阈值,设置种群规模n,最大迭代次数nmax、最大发现概率pamax、最小发现概率pamin、发现概率pa;
步骤4.2,根据适应度函数
步骤4.3,按照公式
步骤4.4,再测试改变后的鸟巢位置,并与上一代鸟巢对比。最终在测试结果较优的一组鸟巢
步骤4.5,将获得的最优解向量进行反编码操作,提取出bp神经网络的权值和阈值后建立改进cs-bpnn模型,应用样本数据训练神经网络,当训练误差不再减小时,训练则可结束。
本发明的有益效果:
1.本发明利用计算机系统和常规的检测仪表提供的在线过程数据,仅仅通过少量的人工采样,实现了食用菌发酵过程的关键状态变量的改进cs-bp神经网络的软测量建模,解决了发酵过程中没有状态变量在线检测仪表难以在线检测的难题。
2.与人工取样化验相比,减少了现场操作人员的工作量,降低了发酵过程中人为操作引入的测量的不确定性,提高了测量的时效性,减少了离线取样带来的数据滞后的问题。
3.本发明采用改进的布谷鸟算法来优化bp神经网络,与标准的cs-bp神经网络方法相比,本发明中软测量方法中克服了标准cs-bp神经网络收敛速度和局部搜索能力上有所欠缺的问题。
4.本发明全面考虑了影响食用菌发酵过程关键状态变量的因素,大量采用现有的常规检测信号来实现关键状态变量的在线预测,应用简单、容易、成本较低,软测量结果较精确。该方法有助于食用菌发酵过程的优化控制和优化运行。
附图说明
图1食用菌发酵过程的流程、测量仪表及计算机配置图;
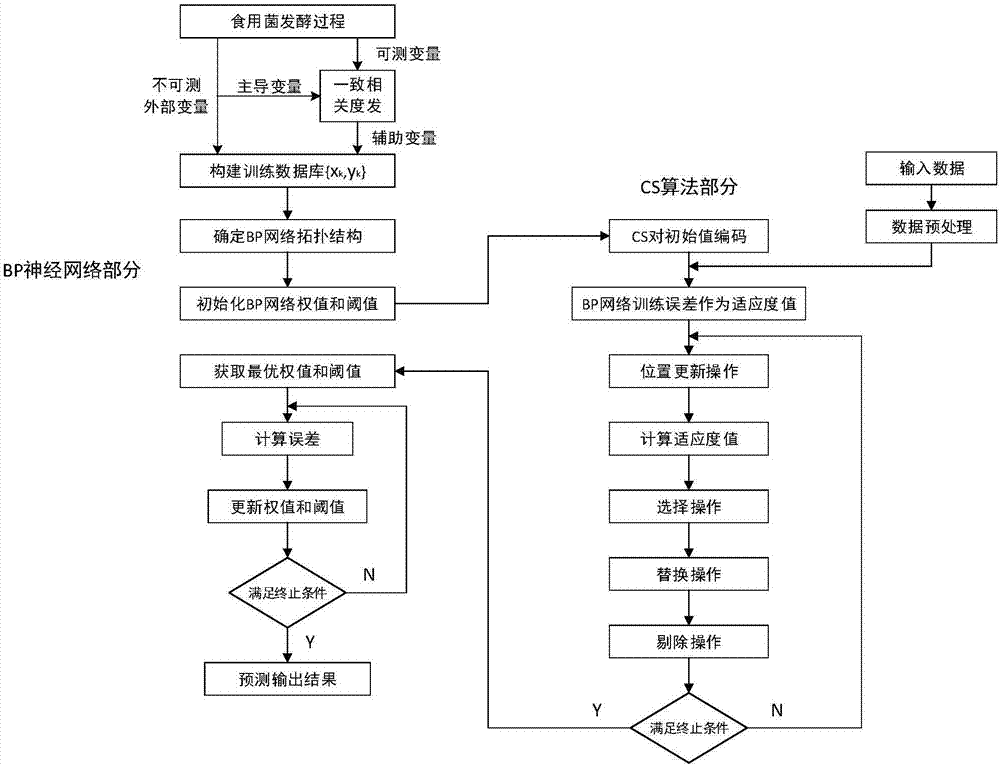
图2基于改进cs-bp神经网络的食用菌发酵关键变量软测量模型建立流程图;
图1中:1生物发酵罐,2蒸汽发生器,3空气压缩机,4空气过滤器,5气体流量传感器,6转速传感器,7co2气敏电极,8液位探头,9热电阻,10溶氧电极,11ph电极,12蠕动泵,13蠕动泵,14离心分离器,15智能控制器,16上位计算机。
图1中所用标记符号如下:
发酵罐温度—t、电机搅拌转速—r、发酵液体积—v
空气流量—q、co2释放率—u、葡萄糖流加速率—ρ、
氨水流加速率—η、溶解氧do、发酵液酸碱度—ph。
图1中,实线箭头表示物流(发酵液,水、空气和蒸汽)方向,虚线表示信号流。
具体实施方式
以下结合食用菌发酵过程关键状态变量预测的实施例子和图2所示的实施流程图,对本发明实施例子作出详细描述。
选择辅助向量:辅助变量选择,选取能直接测量且与过程密切相关的外部变量,用基于离散pso的辅助变量选择算法来选取最适的外部变量作为软测量模型的辅助变量;
1.发酵过程数据的获得
食用菌发酵采用sf-500l型发酵监控系统进行发酵培养。如图1所示监控系统由发酵罐1、蒸汽发生器2、空气压缩机3、空气过滤器和4供水系统组成。食用菌发酵过程中通过气体流量传感器5、转速传感器6、co2气敏电极7、液位探头8、热电阻9、溶氧电极10、ph电极11、蠕动泵12和蠕动泵13采集空气流量q、电机搅拌转速r、co2释放率u、发酵液体积v、发酵罐温度t、溶解氧do、发酵液酸碱度ph、葡萄糖流加速率ρ和氨水流加速率η。发酵液经离心分离器14分离后离线检测得到菌丝生物量。
基于离散pso的辅助变量选择的过程如下:
对于得到的外部变量数据(发酵罐温度t、电机搅拌转速r、发酵液体积v、空气流量q、co2释放率u、葡萄糖流加速率ρ、氨水流加速率η、溶解氧do、发酵液酸碱度ph)用基于离散pso的辅助变量选择算法寻找到最适的外部变量作为软测量模型的辅助变量。
因软测量辅助变量选择是各个自变量的优化组合问题,即每个粒子都是0、1组成的一个向量,0代表某变量未被选中,1代表被选中。这就需要将连续的pso向二进制空间扩展,构造一种离散形式的二进制粒子优化模型。
设候选辅助变量集合为m×d维空间。则每个粒子的位置xi表示为一组长度为d的0、1编码组合,它代表辅助变量的一种选取情况。粒子的初始速度vi可以取(0,1)之间的随机数。其迭代过程是连续的,粒子位置每次更新后不再是0、1二进制数。因此,为了维持粒子的二进制形式,粒子位置更新后需将xi转化成0或1。
其具体步骤如下:
步骤一:初始化离散pso的种群和参数,初始化种群数m=22、惯性权重w=0.8、加速常数c1=c2=0.7、最大限速vmax=4。随机产生元素0和1的m个粒子xi=(xi1,xi2,...,xid),i=1,...,m,组成初始群。随机产生(0,1)之间的随机数作为各粒子的初始速度vij,组成初始速度矩阵vm×d。每个粒子的历史最好位置pi和种群最好位置pg初始值都设为d维0向量;
步骤二:评价每个粒子的适应值。根据pls回归算法和式
步骤三:更新粒子最优位置。对每个粒子xi,将其适应值f(xi)与其经历过的最好位置pi=(pi1,pi2,…,pid)对应的适应值f(pi)作比较,如果f(xi)优于f(pi),则将xi替换为当前的最好位置;
步骤四:更新种群最优位置。对当前种群(m个粒子)中最好位置pbest,将其对应的适应值f(pbest)与种群所经历过的最好位置pg=(pg1,pg2,…,pgd)对应的适应值f(pg)作比较,如果f(pbest)优于f(pg),则将pbest替换为种群最优位置。为防止结果陷入局部优化,将种群最优位置pg记下后,再将其对应的那个粒子重新初始化;
步骤五:在t+1时刻粒子i在第d(d=1,2,...,d)维空间的速度和位置为式:vid(t+1)=w×vid(t)+c1r1×(pid(t)-xid(t))+c2r2×(pgd(t)-xid(t))和xid(t+1)=xid(t)+vid(t+1)。其中,r1,r2分别为(0,1)之间的随机数,;根据这两公式调整当前粒子的位置和速度,并根据式
步骤六:判断是否达到终止条件,若上述条件满足,终止迭代,否则返回步骤二。
根据以上步骤从空气流量q、发酵液温度t、发酵液体积v、co2释放率u、氨水流加速率η、葡萄糖流加速率ρ、溶解氧do、电机搅拌速度r、发酵液酸碱度ph等9个变量中得到co2释放率u、空气流量q、溶解氧do、发酵液体积v、发酵液酸碱度ph5个变量对菌丝生物量影响最大。
2.建立训练样本数据库:采集相同工艺下若干历史罐批次的辅助变量和关键状态变量数据,构造输入输出向量对的集合,生成静态训练样本数据库,并对其进行归一化处理;其中输入向量是辅助变量,输出向量即关键状态变量。具体实现如下:
食用菌发酵过程按照如下的结构组成样本,并收集相同工艺下若干历史罐批次训练样本数据,本发明实施例中收集10批次的数据,其中90%数据作为样本数据集,10%作为验证数据集。样本表达为{xk,yk},其中xk为样本的输入,即选取的辅助向量—空气流量q、发酵液体积v、co2释放率u、溶解氧do、发酵液酸碱度ph。样本的输出yk为待预测的主导变量—菌丝生物量s。
训练样本采集记录结构如表2,时间为发酵过程中采样周期,为减少主导变量离线化验误差,根据同一样本主导变量采用三次化验结果进行样本取舍,最后取平均值:
表2样本数据结构
考虑到样本数据应该具有代表性,并且尽可能覆盖范围较宽,至少应该包括发酵过程正常工作范围,通过手动调控发酵罐压力、发酵罐温度和电机搅拌转速,在生产工艺允许的范围内尽可能改变发酵过程的工作点,每次操作条件改变系统平稳后取样化验。
3.构建bp神经网络模型:设置输入层为5个神经元,输出层为1个神经元,经过bp神经网络自适应个数试验选取隐层为11个神经元。其中bp神经网络输入层为5个神经元,分别对应发酵液体积v、空气流量q、co2释放率u、溶解氧do、发酵液酸碱度ph,输出层1个神经元,对应需要预测的关键参量——菌丝生物量。
4.利用改进的布谷鸟算法优化步骤三的bp神经网络,找到最优的权值与阈值,得到优化的软测量模型。具体步骤如下所示:
(1)首先根据样本数据的维数,即辅助变量的个数来确定神经网络的结构,包括权值和阈值的总数,进而确定改进cs算法中搜索空间的维数;其次,构造鸟巢坐标与神经网络权值阈值之间的映射关系。可以将待确定的权值和阈值视为改进cs算法中有待寻找的鸟窝坐标,可把所有鸟巢单体都看成是权值和阈值的组合之一,那么这相应的也代表着一种bp神经网络的结构,且任意一个鸟巢的好坏都由适应度函数来决定。依据神经网络权值和阈值特点,布谷鸟个体编码采用实数编码方法,每个个体由一个实数串表示,该实数串由输入层、隐含层、输出层之间的权值与阈值组成,且每个布谷鸟个体都可以经过反编码提取出所有的权值和阈值。算法的搜索目标,就是找到一个最适应鸟巢的坐标(即一组权值和阈值),使选取的适应度函数值得到最小值;最后,把该鸟巢坐标分量赋予bp神经网络以用作其权值与阈值用来构建改进后的csbp神经网络;
(2)选取的网络结构为应用最为典型的三层神经网络结构,其中输入层设置5个神经元,输出层设置1个神经元,根据构造法经验公式:midn=2inn+1,其中midn为隐含层节点数,inn为输入层节点数。在用改进的cs算法训练bp神经网络时,定义鸟巢位置分量为网络的权值和阈值。连接权值个数为5*11+11*1=66,阈值为11+1=12,所以鸟巢维度设为66+12=78。鸟巢种群数量为n=50,鸟蛋被发现的最大概率pamax=0.9、最小发现概率pamin=0.1,迭代次数设为nmax=2000;
(3)根据适应度函数
其他鸟巢位置按照公式
(4)按照公式
(5)再测试改变后的鸟巢位置,并与上一代鸟巢对比。最终在测试结果较优的一组鸟巢
(6)将获得的最优解向量进行反编码操作,提取出所有bp神经网络的权值和阈值后建立改进cs-bp模型,应用样本数据训练神经网络,当训练误差不再减小时,训练则可结束。
5.预测关键状态变量:利用步骤4训练好的改进的cs-bp神经网络软测量模型,根据当前待预测罐批的最新输入向量,获得关键状态变量的预测值。具体实现如下:
软测量模型建立完毕后,采用嵌入式c语言编程实现,并嵌入到智能控制器15里,当待预测罐批的输入向量xi+1,经测量仪表读入智能控制器15后,智能控制器15利用软测量程序计算得到关键状态变量的预测值,并将预测结果经数据通道传送到上位计算机16上实时显示。
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!