一种土壤重金属生物可利用性含量预测的方法与流程
1.本发明属于生态环境保护技术领域,特别涉及一种土壤重金属生物可利用性含量预测的方法。
背景技术:
2.土壤污染物在具有生物可利用性时才具有毒性,然而,大多数关于污染物的含量水平和环境风险评价多基于污染物的总浓度,而不是生物可利用性,这可能导致对潜在毒性风险的高估。研究表明,土壤性质具有改变污染物生物可利用性的能力,因此,确定污染物生物可利用性比测定总浓度更适合评估土壤生态风险。
3.我国在生物可利用性(bioaccessibility)的测试评估和预测模型等方面的研究缺少,导致不能精确的评估污染土壤的生态风险。
4.为了最大程度地减少决策过程中的不确定性,迫切需要开展进一步的工作,以解决生物可利用性评估的科学有效性工具和预测模型的问题。
技术实现要素:
5.本发明的主要目的在于提供一种至少部分解决上述技术问题的土壤重金属生物可利用性含量预测的方法。
6.为实现上述目的,本发明采取的技术方案为:
7.一种土壤重金属生物可利用性含量预测的方法,包括:
8.s1、确定目标土壤性质以及通过测试获取所述目标土壤对应的重金属总含量;
9.s2、将所述目标土壤性质及对应的重金属总含量,代入预先构建的土壤重金属生物可利用性含量预测模型进行计算,输出预测的重金属生物可利用性含量数据。
10.进一步地,所述土壤性质包括:ph值、阳离子交换量、有机质含量、黏土含量以及铁矿物含量。
11.进一步地,所述土壤重金属生物可利用性含量预测模型的构建过程,包括:
12.s21、搜集构建目标土壤重金属生物可利用性回归模型的土壤重金属生物可利用性含量数据;
13.s22、搜集或测试所述土壤重金属生物可利用性含量数据对应的土壤理化性质及土壤重金属总含量;
14.s23、根据预设规则对所述土壤理化性质及土壤重金属总含量进行筛选;
15.s24、将经筛选后的所述土壤理化性质及土壤重金属总含量,进行数据处理;所述数据处理包括:对数转换和/或通过缺失值插补法补充土壤性质参数的缺失值;
16.s25、根据表征的生物类型将经数据处理后的生物可利用性数据分组;
17.s26、将分组后数据分别进行逐步回归分析,采用所述土壤性质和重金属总含量作为自变量,生物可利用性含量作为因变量,建立逐步回归模型。
18.进一步地,所述土壤重金属生物可利用性含量预测模型的构建过程,还包括:s27、
采用实验数据对所述逐步回归模型的预测效果进行计算与比较,验证所述逐步回归模型的可靠性。
19.进一步地,步骤s23中的预设规则包括:
20.删去未按标准方法开展试验的数据;
21.删去没有受试土壤性质的数据;
22.删去非自然土壤数据;
23.选用测试规范、数据清晰的文献数据。
24.进一步地,步骤s24中的通过缺失值插补法补充土壤性质参数的缺失值,包括:采用基于链式方程的多重插补方法与随机森林插补法联用的缺失值处理方法,具体如下:
25.a.存在缺失值的数据集:f(y
mis
|y
obs
);
26.b.用随机森林法用于预测连续缺失值并填充数据形成m个填补值,得到 m个完整数据集:f(q|y
obs
,y
mis
);
27.c.对产生的m个数据集分析,分析填充效果,得到m个分析后的填补值:∫dy
mis
;
28.d.将m个分析结果综合得到对目标变量的估计,得到最终的完整数据集: f(q|y
obs
);
29.式中,y
mis
表示缺失值;y
obs
表示观测值;m默认为5;c步骤中数据集分析方法为对m个插补数据集进行数据集t检验,检验某数据集是否合格;d 步骤中对m个数据集进行f检验,检验整个方法是否合格。
30.进一步地,步骤s27,包括:
31.将实测土壤性质和重金属总含量代入到所述逐步回归模型,计算预测值和实测值的差异系数;根据差异系数来划分预测效果;所述差异系数=max(预测值,实测值)/min(预测值,实测值)。
32.进一步地,步骤s2包括:
33.当所述土壤重金属生物可利用性含量预测模型包括多个模型时,根据所述目标土壤性质选择拟合效果相关指数较大的模型;将所述目标土壤性质及对应的重金属总含量代入选择的模型中进行计算,输出预测的重金属生物可利用性含量数据。
34.进一步地,步骤s2还包括:
35.当多个模型的拟合效果相关指数处于同一等级时,将所述目标土壤性质及对应的重金属总含量分别代入选择的多个模型中进行计算,将输出的多个计算结果求其几何平均值;所述几何平均值作为最终输出预测的重金属生物可利用性含量数据。
36.与现有技术相比,本发明具有如下有益效果:
37.本发明提出了土壤重金属生物可利用性含量预测的方法,包括:s1、确定目标土壤性质以及通过测试获取所述目标土壤对应的重金属总含量;s2、将所述目标土壤性质及对应的重金属总含量,代入预先构建的土壤重金属生物可利用性含量预测模型进行计算,输出预测的重金属生物可利用性含量数据。该方法可实现对不同类型土壤中的重金属生物可利用性含量进行分析,可消除土壤性质差异带来的生物可利用性的差异。为生物可利用性在实际应用中提供了新思路,可为精准评估污染土壤的生态风险和环境风险管理工作提供技术支持。
38.进一步地,本方法基于生物类型对生物可利用性含量测试方法进行了分组,以削
弱不同方法产生的测试结果差异,然后通过土壤性质(ph、阳离子交换量(cec)、有机质含量(om)、黏土(clay)含量以及铁矿物含量(fe)等) 和土壤中重金属总含量对重金属生物可利用含量进行预测。列出了预测方法的使用步骤,并提供了生物可利用性预测模型,涉及了多种土壤性质和测试方法,预测模型可直接用于目标土壤重金属生物可利用性含量的预测。
附图说明
39.图1为本发明提供的土壤重金属生物可利用性含量预测的方法的流程图;
40.图2为本发明提供的土壤重金属生物可利用性含量预测的整体架构图;
41.图3为本发明提供的土壤重金属生物可利用性含量预测模型的构建流程图。
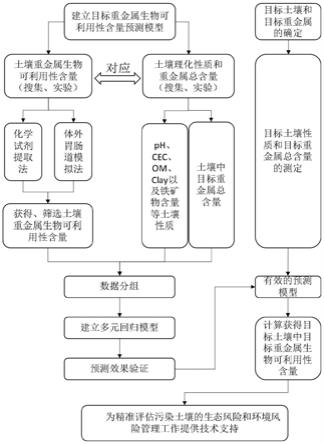
42.图4为本发明提供的数据验证结果图。
具体实施方式
43.为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
44.在本发明的描述中,需要说明的是,术语“上”、“下”、“内”、“外”“前端”、“后端”、“两端”、“一端”、“另一端”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性。
45.在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“设置有”、“连接”等,应做广义理解,例如“连接”,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
46.参照图1所示,本发明提供的一种土壤重金属生物可利用性含量预测的方法,包括:
47.s1、确定目标土壤性质以及通过测试获取所述目标土壤对应的重金属总含量;
48.s2、将所述目标土壤性质及对应的重金属总含量,代入预先构建的土壤重金属生物可利用性含量预测模型进行计算,输出预测的重金属生物可利用性含量数据。
49.本实施例中,首先确定需要预测的目标区域的土壤性质,比如ph值、阳离子交换量、有机质含量、黏土含量以及铁矿物含量等,并根据测试实验获得该需要预测土壤的重金属含量,比如:镉、砷、铜、锌、铝等含量。然后将土壤性质与重金属总含量作为输入,代入预先构建的土壤重金属生物可利用性含量预测模型,输出该目标区域预测的重金属生物可利用性含量数据。该方法步骤较为简单,基于构建的土壤重金属生物可利用性含量预测模型,即可得到目标区域土壤的准确污染水平,准确的评估土壤生态风险,相比简单测定污染物总浓度,更精准,更科学,也可为后续决策提供有力的数据支持。
50.从实现的过程来说,本发明通过具体的两个部分来实现:
51.第一部分为土壤重金属生物可利用性含量预测模型的构建:具体包括
52.1、生物可利用性和所对应的土壤理化性质数据的搜集;
53.2、生物可利用性数据的筛选;
54.3、数据缺失值插补处理;
55.4、生物可利用性数据分组;
56.5、数据多元回归处理;
57.6、多元回归的校验。
58.第二部分为构建的预测方法(模型公式)的应用,具体可分为:
59.1)、目标土壤性质及重金属总含量的测试与获取;
60.2)、目标土壤性质及重金属总含量的代入与计算;
61.3)、预测的重金属生物可利用性含量数据;
62.4)、数据应用于后续的土壤污染风险评估中。
63.下面结合图2所示,对上述两个部分进行详细的说明:
64.第一部分:
65.土壤重金属生物可利用性含量预测模型的构建过程,如图3所示,包括:
66.s21、搜集构建目标土壤重金属生物可利用性回归模型的土壤重金属生物可利用性含量数据;
67.s22、搜集或测试所述土壤重金属生物可利用性含量数据对应的土壤理化性质及土壤重金属总含量;
68.s23、根据预设规则对所述土壤理化性质及土壤重金属总含量进行筛选;
69.s24、将经筛选后的所述土壤理化性质及土壤重金属总含量,进行数据处理;所述数据处理包括:对数转换和/或通过缺失值插补法补充土壤性质参数的缺失值;
70.s25、根据表征的生物类型将经数据处理后的生物可利用性数据分组;
71.s26、将分组后数据分别进行逐步回归分析,采用所述土壤性质和重金属总含量作为自变量,生物可利用性含量作为因变量,建立逐步回归模型;
72.s27、采用实验数据对所述逐步回归模型的预测效果进行计算与比较,验证所述逐步回归模型的可靠性。
73.上述步骤s21中,土壤重金属生物可利用性数据的搜集:比如通过国内外数据库和文献,结合实验测试的方法,搜集构建土壤目标重金属生物可利用性回归模型的土壤重金属生物可利用性含量数据。包括化学试剂提取法和体外胃肠道模拟法等方法测定的重金属生物可利用性含量数据。
74.步骤s22中,搜集或测试上述生物可利用性数据涉及的土壤理化性质及土壤重金属总含量。获得的土壤性质(比如:ph、阳离子交换量(cec)、有机质含量(om)、黏土(clay)含量以及铁矿物含量(fe)等)的数据和重金属总含量数据为后续模型建立提供参数支持。另外,注意有机质和有机碳的区分,当有的文献中出现有机碳时,可将其转换为有机质,一般认为om=1.724*oc。
75.步骤s23中,数据的筛选规则:删去未按标准方法开展试验的数据,如无对照组,未设平行组;删去没有受试土壤性质的数据,包括土壤性质(cec、 om等)未明确标注的数据;删去非自然土壤数据(即人工配制土壤或自然土壤中人工添加重金属的试验数据)。选用测试规范、数据清晰的文献进行研究。其中测试规范,比如是符合实验操作规章制度进行的,数据清晰是指数据的记录是从实验中获得,非主观认定。
76.步骤s24中,数据处理:所搜集的数据量多,涉及的测试方法和土壤性质差别大时,为了使数据的分布正态化,可对数据进行对数转换。对于部分土壤性质参数缺失的数据,通过缺失值插补法补充该部分参数,以提高预测结果的可靠性。本发明可采用基于链式方程的多重插补方法(mice)与随机森林插补法(rf)联用的缺失值处理方法,可由r和rstudio软件中的“mice”数据包实现。具体插补流程如下:
77.a.存在缺失值的数据集:f(y
mis
|y
obs
);
78.b.用随机森林法用于预测连续缺失值并填充数据形成m个填补值,得到 m个完整数据集:f(q|y
obs
,y
mis
);
79.c.对产生的m个数据集分析,分析填充效果,得到m个分析后的填补值:∫dy
mis
;
80.d.将m个分析结果综合得到对目标变量的估计,得到最终的完整数据集: f(q|y
obs
);
81.式中y
mis
表示缺失值;y
obs
表示观测值;m默认为5;c步骤中数据集分析方法为对m个插补数据集进行数据集t检验,检验某数据集是否合格(0.05 检验水平);d步骤中对m个数据集进行f检验,检验整个方法是否合格(0.05 检验水平)。
82.步骤s25数据分组:研究表明,不同的测试方法所得到的重金属生物可利用性含量通常只与某一类型生物体组织内的重金属生物富集含量具有较好的相关性,对于土壤环境基准和风险评估的研究工作,可依据生态受体的差异采用适宜的生物可利用性测定方法。因此,依据表征的生物类型将生物可利用性测试方法分组,表1是根据文献数据库总结的简易分组表,主要将生物可利用性测试方法分为三类:人体、土壤植物、土壤动物。比如ubm、pbet 等属于人体体外胃肠道模拟方法,主要测定的是能被人体潜在吸收的重金属生物可利用性,这些方法测定的重金属生物可利用性含量可分到人体组; cacl2、hno3、edta等化学试剂主要用于测定能被植物体或土壤动物潜在吸收的重金属生物可利用性,其中表征的植物体主要为体长不超过4米的草本植物或灌木,表征的土壤动物主要为蚯蚓,这些方法测定的生物可利用性含量可分到土壤植物和土壤动物组中;例如seg方法主要针对蚯蚓肠道对重金属吸收,便分到土壤动物组中。以上分组方法不唯一,若数据量足够的情况下可将数据分成更小的组分,比如蚯蚓组等,若数据量不充足时可分为上述的三大组。
83.表1生物可利用性测试方法简易分组表
[0084][0085]
表1中,(1)pbet(physiologically based extraction test)表示生理原理提取法;sbet(simplified bioaccessibility extraction test)表示生物可及性简化提取法;ubm(the barge unified bioaccessibility method)表示欧洲生物可及性研究小组生物可及性统一测定法;rbalp(relative bioavailability leaching procedure)表示相对生物有效性浸出程序;sbrc(solubility/bioavailability research consortium)表示溶解性/生物有效性研究联盟;
[0086]
seg(simulated earthworm gut test)表示蚯蚓肠道模拟实验; edta(ethylenediaminetetraacetic acid)表示乙二胺四乙酸; dtpa(diethylenetriaminepentaacetic acid)表示二乙基三胺五乙酸;hcl、 hoac、hno3、nh4oac:表示稀酸溶液;cacl2、nahco3、kh2po4、nah2po4、 mgcl2:表示无机盐溶液;bcr(european community bureau of reference)表示欧洲共同体标准物质局提出的一种化学连续提取法。
[0087]
(2)表征/模拟生物体指文献中生物(或模拟生物)实验测定生物富集含量时所使用(或模拟)的生物,此生物测定的生物富集含量与利用土壤所测定的生物可利用性含量建立有相关关系。
[0088]
上述步骤s26中,将上述分组后数据分别进行逐步回归分析,采用ph、 cec、om、clay以及铁矿物含量(fe)等理化性质和重金属总含量作为自变量,生物可利用性含量作为因变量,即可建立逐步回归模型,模型一般表达式例如:
[0089]
lg(bα)=a lg(tα)+g
[0090]
lg(bα)=a lg(tα)+fph+g
[0091]
lg(bα)=a lg(tα)+blg(om)+fph+g
[0092]
lg(bα)=a lg(tα)+blg(om)+c lg(cec)+fph+g
[0093]
lg(bα)=a lg(tα)+blg(om)+clg(cec)+d lg(clay)+fph+g
[0094]
lg(bα)=a lg(tα)+blg(om)+c lg(cec)+d lg(clay)+e lg(fe)+fph+g
[0095]
式中a、b、c、d、e、f和g为模型系数;α为重金属;bα为生物可利用性含量;tα为土壤中重金属总含量。
[0096]
上述步骤s27中,为了验证预测模型的可靠性,采用实验数据对预测模型的预测效果进行计算与比较,即将实测土壤性质和重金属总含量代入到预测模型,计算预测值和实测值的差异系数,差异系数=max(预测值,实测值)/min(预测值,实测值),即:将预测值、实测值中的最大值除以预测值、实测值中的最小值,得到的结果作为差异系数,然后根据差异系数来划分预测效果。比如,当预测值和实测值的差异系数<1.5表明预测效果优秀,差异系数<2.0表明预测效果良好,差异系数<4.0表明预测效果一般。
[0097]
第二部分:
[0098]
(1)目标土壤性质和重金属总含量的测试与获取。依照国内外标准测试方法,获得目标土壤的ph、cec、om、clay以及铁矿物含量(fe)等理化性质和重金属总含量。
[0099]
(2)依据所要表征的生物类型将目标土壤性质和重金属总含量代入到上述构建的相应组别的回归模型中。在实际使用过程中,若同一组别中有多个模型时,可依据获取的土壤性质数据多少择优选择拟合效果较好的模型。比如拟合效果可采用相关指数r2>0.9表明拟合效果很好;r2>0.7表明拟合效果较好;r2>0.5表明拟合效果一般;r2<0.4表明拟合效果不好,不建议使用。可根据上述区间来表示相应等级。若多个模型r2值都较高(即相同,或相近且位于同一等级中),则代入计算后求取所有数据的几何平均值或相近且位于同一等级中),则代入计算后求取所有数据的几何平均值n表示选择模型的数量,x1x2...xn分别表示模型1、模型2、...模型n的预测结果。
[0100]
(3)计算获得目标土壤性质下的土壤重金属生物可利用性含量数据,为后续的生态风险评估提供生物可利用性数据,减少土壤性质差异和生物可利用性测试方法差异所导致的土壤污染水平的不确定性。
[0101]
下面再通过一个具体的实施例来说明本发明的技术方案:
[0102]
以我国土壤环境污染研究为例,对土壤中镉(cd)、砷(as)、铜(cu)、锌(zn) 和铅(pb)的生物可利用性(bioaccessibility)进行研究。筛选了已发表论文中生物可利用性与所对应的土壤性质的数据,并分析了它们之间的潜在关系,建立了生物可利用性含量的回归模型。基于生物类型对测试方法进行了分组,以削弱不同方法产生的测试结果差异,期望基于土壤性质和土壤中重金属总含量构建得到科学有效的镉(cd)、砷(as)、铜(cu)、锌(zn)和铅(pb)生物可利用性含量预测模型,为后续的生态风险评估提供数据支持。
[0103]
第一:数据的获取、筛选与处理;
[0104]
采用elsevier(http://www.sciencedirect.com)、中国知网 (http://www.cnki.net)、web of science(http://app.webofknowledge.com)等数据库,以主题“生物可利用性”、“土壤”、“镉”、“砷”、“铜”、“锌”、“铅”等对土壤重金属生物可利用性数据进行搜索,初步筛选约400篇文献。查找文献中报道了重金属(cd、as、cu、zn、pb)生物可利用性含量和对应的土壤性质(ph、阳离子交换量(cec)、有机质含量(om)、黏土(clay)含量以及铁矿物含量(fe))的数据。删去没有受试土壤性质的数据,包括土壤性质(cec、 om等)未明确标注的数据;删去非自然土壤数据(即人工配制土壤或自然土壤中人工添加重金属的试验数据)。选用了剩余的80篇测试规范、数据清晰的文献进行研究。
[0105]
获取的数据包括土壤中重金属的总含量和生物可利用性含量以及所对应的土壤性质。所搜集的数据量多,涉及的测试方法和土壤性质差别大,为了使数据的分布正态化,对数据进行了对数转换。对于部分土壤性质参数缺失的数据,通过缺失值插补法补充该部分参数,以提高研究结果的可靠性。本实施例中采用了基于链式方程的多重插补方法(mice)来处理缺失值问题,由r 4.0.4和rstudio 1.3.1073软件中的“mice”数据包进行处理,数据包中包含随机森林(rf)法。研究表明mice、rf以及mice与rf联用等方法在空气质量缺失值、土壤性质参数(ph等)缺失值、水质参数缺失值等方面有很好的插补效果。
[0106]
第二:生物可利用性含量预测模型构建;
[0107]
采用spss 25.0软件进行逐步回归分析,使得最后保留在模型中的解释变量既是重要的,又没有严重多重共线性,推导出的回归模型一般表达式如下:
[0108]
lg(bα)=a lg(tα)+b lg(om)+c lg(cec)+d lg(clay)+e lg(fe)+fph+g
[0109]
式中a、b、c、d、e、f和g为模型系数;α为重金属;bα为生物可利用性含量;tα为土壤中重金属总含量。
[0110]
为了进一步验证预测模型的可靠性,本实施例采用其他学者的实验数据对预测模型的预测效果进行计算与比较,所选数据未用于预测模型的构建。
[0111]
第三:生物可利用性预测模型
[0112]
依据表征的生物类型将测试方法分为三组:第一组为人,主要包括pbet、sbet、ubm、sbrc、rbalp方法;第二组为植物,主要包括edta、hcl、 cacl2等方法;第三组为蚯蚓,主要包括seg、bcr、dtpa等方法。
[0113]
基于逐步回归分析方法,构建了5种重金属的多个土壤生物可利用性含量预测模型(表2)。由回归方程可知,土壤中重金属可利用性含量的变化主要由金属总含量解释(r2:0.350~0.986)。此外每个组别中还有其他影响因素(如 om、cec等),通过逐步纳入更多参数,获得了更为可靠的预测模型(相关性 r2值提高)(表2)。
[0114]
表2重金属生物可利用性含量的逐步回归模型
[0115][0116][0117]
预测模型校验:
[0118]
采用已发表论文中的土壤性质数据对构建的预测模型进行验证,共产生蚯蚓、植物、人三个分组的49组数据点(图4)。图4显示,94%的数据点在95%预测带内,43%的数据点在95%置信带内,说明回归方程预测效果较好,其中 cu、pb的预测效果最好。在涉及多种土壤类型及测试方法的情况下,基于生物类型对测试方法分组,以削弱不同方法产生的测
试结果差异,在实际使用过程中可依据获取的土壤性质数据择优选择r2值较高的模型,可对生物可利用性含量进行较好的预测。
[0119]
根据土壤性质(ph、oc、cec、clay和铁矿物含量)对土壤重金属镉(cd)、砷(as)、铜(cu)、锌(zn)和铅(pb)的生物可利用性含量进行回归分析,获得镉 (cd)、砷(as)、铜(cu)、锌(zn)和铅(pb)的30种生物可利用性含量预测模型,通过验证发现预测模型可较好地预测其它土壤条件下的生物可利用性含量值,从而减少不同土壤性质引起的生物可利用性含量差异。
[0120]
本发明提出土壤重金属生物可利用性含量预测的方法,并建立了涉及土壤理化性质和土壤重金属总含量的生物可利用性含量的回归预测模型,实现对不同类型土壤中的重金属生物可利用性含量进行分析,可为重金属的土壤污染水平分析提供重金属生物可利用性含量预测的可直接使用的模型公式。方法和公式的获得可消除土壤性质差异带来的生物可利用性的差异。
[0121]
本发明能够根据土壤性质(ph、阳离子交换量(cec)、有机质含量(om)、黏土(clay)含量以及铁矿物含量(fe)等)以及土壤重金属总含量对土壤重金属生物可利用性进行分析,获得土壤重金属的多元回归模型。回归模型在涉及多种土壤类型及生物可利用性测试方法的情况下,基于生物类型对测试方法分组,以削弱不同方法产生的测试结果差异,在实际使用过程中可依据获取的土壤性质数据择优选择模型,可对生物可利用性含量进行较好的预测。依据回归模型获得了不同土壤类型条件下重金属的生物可利用性含量的数据,然后应用于后续的重金属生态毒性研究中。基于生物可利用性的土壤重金属生态毒性研究,可避免土壤性质差异带来的毒性效应差异,可为精准评估污染土壤的生态风险和环境风险管理工作提供技术支持。
[0122]
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1