位置控制装置及位置控制方法与流程
本发明涉及位置控制装置及位置控制方法。
背景技术:
在构建通过机器人臂进行组装动作的生产系统时,通常进行通过被称为示教的人的手实施的示教作业。但是,在该示教中,机器人仅针对所存储的位置反复进行动作,因此在产生由制作、安装引起的误差的情况下,有时无法应对。因此,如果能够开发出对该个体误差进行吸收这样的位置校正技术,则能够期待生产率的提高,并且机器人活跃的情况也变大。
在现有的技术中,存在使用照相机图像进行直至将要进行连接器插入作业前为止的位置校正的技术(专利文献1)。另外,如果使用力学传感器、立体照相机等多个设备,则能够对与组装(插入、工件保持等)相关的位置的误差进行吸收。但是,为了决定位置校正量,需要明确地根据图像信息对如该参考文献这样进行了抓持的连接器的中心坐标、插入侧的连接器的中心坐标等的量进行计算。该计算依赖于连接器的形状,必须针对每个使用连接器由设计者进行设定。另外,3维信息如果能够从距离照相机等取得,则该计算也是比较容易的,但为了从2维图像信息取得,需要针对每个连接器对图像处理算法进行开发,因此花费大量的设计成本。
专利文献1:WO98-017444号公报
技术实现要素:
即,存在下述课题:仅通过来自单镜头的照相机的信息难以对用于组装的位置进行控制。
本发明就是为了解决上述的课题而提出的,目的在于仅通过单镜头照相机而进行对位。
本发明所涉及的位置控制装置的特征在于,具有:拍摄部,其对两个物体存在的图像进行拍摄;以及控制参数生成部,其将拍摄到的两个物体存在的图像的信息输入至神经网络的输入层,将用于对拍摄到的两个物体的位置关系进行控制的位置的控制量,作为神经网络的输出层而输出。
发明的效果
根据本发明,取得能够仅通过单镜头照相机而进行对位这样的效果。
附图说明
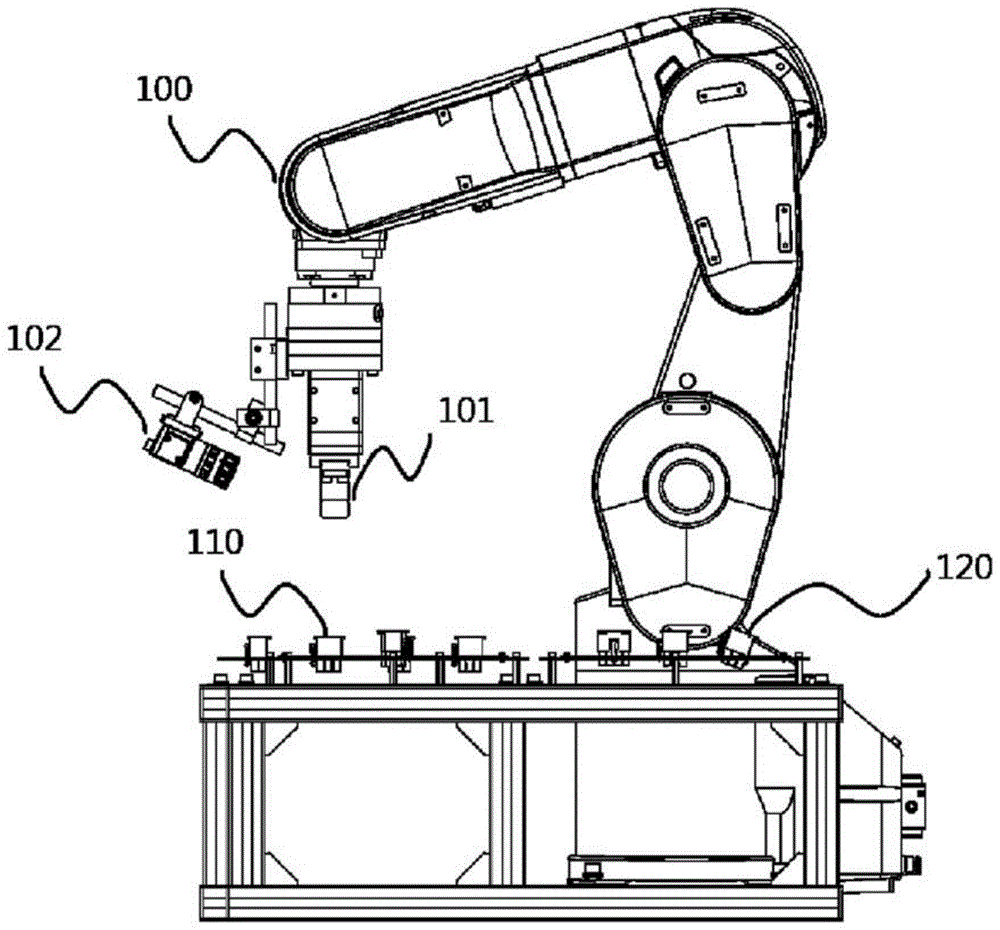
图1是实施方式1中的配置有机器人臂100和公侧连接器110、母侧连接器120的图。
图2是实施方式1中的位置控制装置的功能结构图。
图3是实施方式1中的位置控制装置的硬件结构图。
图4是实施方式1中的位置控制装置的位置控制中的流程图。
图5是表示实施方式1中的单镜头照相机102拍摄到的插入开始位置、在其周边附近的照相机图像和控制量的图例。
图6是表示实施方式1中的神经网络和神经网络的学习规则的例子的图。
图7是在实施方式1中的神经网络中,使用多个网络的流程图。
图8是实施方式2中的位置控制装置的功能结构图。
图9是实施方式2中的位置控制装置的硬件结构图。
图10是表示实施方式2中的公侧连接器110和母侧连接器120的嵌合的试行的情况的图。
图11是实施方式2中的位置控制装置的路径学习中的流程图。
图12是实施方式3中的位置控制装置的路径学习中的流程图。
图13是表示实施方式3中的神经网络和神经网络的学习规则的例子的图。
具体实施方式
实施方式1.
下面,对本发明的实施方式进行说明。
在实施方式1中,对学习各连接器的插入位置、在生产线中进行组装的机器人臂和其位置控制方法进行说明。
对结构进行说明。图1是实施方式1中的配置有机器人臂100和公侧连接器110、母侧连接器120的图。在机器人臂100中具有对公侧连接器110进行抓持的抓持部101,在可观察该抓持部的位置将单镜头照相机102安装于机器人臂100。该单镜头照相机102位置被设置为,在机器人臂100的前端的抓持部101抓持着公侧连接器110时,被抓持的公侧连接器110的前端部和被插入侧的母侧连接器120可见。
图2是实施方式1中的位置控制装置的功能结构图。
在图2中,由下述部分构成:拍摄部201,其是图1中的单镜头照相机102的功能,对图像进行拍摄;控制参数生成部202,其使用拍摄到的图像而生成机器人臂100的位置的控制量;控制部203,其使用位置的控制量而针对机器人臂100的驱动部204对电流·电压值进行控制;以及驱动部204,其基于从控制部203输出的电流·电压值而对机器人臂100的位置进行变更。
控制参数生成部202如果从是单镜头照相机102的功能、对图像进行拍摄的拍摄部201取得图像,则决定与机器人臂100的位置(X,Y,Z,Ax,Ay,Az)的值对应的控制量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz),向控制部203输出控制量(X、Y、Z为机器人臂的位置,Ax、Ay、Az为机器人臂100的姿态角度)。
控制部203基于与接收到的机器人臂100的位置(X,Y,Z,Ax,Ay,Az)的值对应的控制量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz),决定针对构成驱动部204的各设备的电流·电压值并进行控制。
驱动部204通过从控制部203接收到的针对各设备的电流·电压值而进行动作,由此机器人臂100移动至(X+ΔX,Y+ΔY,Z+ΔZ,Ax+ΔAx,Ay+ΔAy,Az+ΔAz)的位置。
图3是实施方式1中的位置控制装置的硬件结构图。
单镜头照相机102经由输入输出接口301而与处理器302、存储器303可通信地连接,无论是有线还是无线均可。由输入输出接口301、处理器302、存储器303构成图2中的控制参数生成部202的功能。输入输出接口301还与控制部203所对应的控制电路304可通信地连接而无论是有线还是无线。控制电路304还与电动机305电连接。电动机305与图2中的驱动部204相对应,构成为用于对各设备的位置进行控制的部件。此外,在本实施方式中,作为与驱动部204相对应的硬件的方式而设为电动机305,但只要是能够对位置进行控制的硬件即可。因此,在单镜头照相机201和输入输出接口301间、输入输出接口301和控制电路间304间,可以分体地构成。
接下来,对动作进行说明。
图4是实施方式1中的位置控制装置的位置控制中的流程图。
首先,在步骤S101中,机器人臂100的抓持部101对公侧连接器110进行抓持。该公侧连接器110的位置、姿态在图2的控制部203侧被事先登记,基于在预先控制部203侧登记的控制程序而进行动作。
接下来,在步骤S102中,将机器人臂100接近至母侧连接器120的插入位置附近。该母侧连接器110的大致的位置、姿态,在图2的控制部203侧被事先登记,基于在预先控制部203侧登记的控制程序,使公侧连接器110的位置进行动作。
接下来,在步骤S103中,控制参数生成部202针对单镜头照相机102的拍摄部201,指示对图像进行拍摄,单镜头照相机103对反映出抓持部101所抓持的公侧连接器110和成为插入目标的母侧连接器120这两者的图像进行拍摄。
接下来,在步骤S104中,控制参数生成部202从拍摄部201取得图像,决定控制量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)。关于该控制量的决定,控制参数生成部202将图3的处理器302、存储器303作为硬件使用,并且使用神经网络对控制量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)进行计算。使用神经网络的控制量的计算方法在后面记述。
接下来,在步骤S105中,控制部203取得由控制参数生成部202输出的控制量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz),并且对预先决定的阈值和控制量的全部成分进行比较。如果控制量的全部成分小于或等于阈值,则向步骤S107进入,控制部203对驱动部204进行控制,以使得将公侧连接器110向母侧连接器120插入。
如果控制量的任意的成分大于阈值,则在步骤S106中,控制部203使用由控制参数生成部202输出的控制量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)而对驱动部204进行控制,向步骤S103返回。
接下来对图4的步骤S104中的使用神经网络的控制量的计算方法进行说明。
在进行使用神经网络的控制量的计算前,作为事前准备,为了使得能够通过神经网络对从输入图像至嵌合成功为止的移动量进行计算,事先汇集图像和所需的移动量的组(set)。例如,针对位置已知的嵌合状态的公侧连接器110和母侧连接器120,通过机器人臂100的抓持部101对公侧连接器110进行抓持。而且,一边在已知的拉出方向移动抓持部101、一边移动至插入开始位置,并且通过单镜头照相机102取得多张图像。另外,不仅是将插入开始位置作为控制量(0,0,0,0,0,0)而从嵌合状态至插入开始为止的移动量的移动量,还取得其周边的移动量,即与控制量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)相对应的图像。
图5是表示实施方式1中的单镜头照相机102拍摄到的插入开始位置、在其周边附近的照相机图像和控制量的图例。
而且,使用从嵌合状态至插入开始位置为止的移动量和由单镜头照相机102中的插入开始位置及周边的位置的图像构成的多个组,基于一般性的神经网络的学习规则(例如:概率的梯度法)进行学习。
在神经网络中存在CNN、RNN等各种方式,但本发明不依赖于其方式,能够使用任意的方式。
图6是表示实施方式1中的神经网络和神经网络的学习规则的例子的图。
向输入层输入从单镜头照相机102得到的图像(例如各像素的亮度、色差的值),输出层将控制量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)输出。
在神经网络的学习过程中,使从输入的图像经由中间层而得到的输出层的输出值与在图像组中存储的控制量近似,因此进行使中间层的参数优化。作为其近似方法而存在概率的梯度法等。
因此,如图5所示,不仅是从嵌合状态至插入开始为止的移动量的移动量,还取得与其周边的移动相对应的图像而进行学习,由此能够进行更准确的学习。
另外,在图5中,示出公侧连接器110相对于单镜头照相机102而位置固定,仅母侧连接器120的位置变化的情况,但实际上,机器人臂100的抓持部101并非在准确的位置处对公侧连接器110进行抓持,由于个体差等,还存在公侧连接器110的位置偏离的情况。因此,在该学习的过程中取得公侧连接器110从准确的位置偏离的情况下的插入开始位置、其附近的位置的多个控制量和图像的组而进行学习,由此进行能够应对公侧连接器110和母侧连接器120这两者的个体差的学习。
但是,在这里需要注意的是,控制量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)是除以从拍摄的时刻的嵌合状态位置至插入开始位置为止的移动量而计算的,因此关于从插入开始位置至嵌合状态位置为止的移动量,由于在图4的步骤S107中使用,因此无需另行存储。另外,上述坐标作为单镜头照相机的坐标系而求出,因此控制部203需要将单镜头照相机的坐标系变换为机器人臂100整体的坐标系不同的情况,然后对机器人臂100进行控制。
在该实施例中,将单镜头照相机固定于机器人臂100,其原因在于,设置有母侧连接器120的坐标系和单镜头照相机102的坐标系不同。因此,如果单镜头照相机102是与母侧连接器120的位置相同的坐标系,则无需从单镜头照相机102的坐标系向机器人臂100的坐标系的变换。
接下来,对图4的动作的详细内容和动作例进行说明,
在步骤S101中,机器人臂100为了对公侧连接器110进行抓持,按照事先登记的动作那样对公侧连接器110进行抓持,在步骤S102中,母侧连接器120大致向上移动。
此时,被抓持的公侧连接器110的要被抓持前的位置不一定始终恒定。由于对该公侧连接器110的位置进行设置的机械的微小微笑的动作偏差等,有可能始终产生微小的误差。同样地母侧连接器120也有可能具有某种误差。
因此,在步骤S103中,在如图5所示通过附属于机器人臂100的单镜头照相机102的拍摄部201拍摄到的图像中,取得反映出公侧连接器110和母侧连接器120这两者的图像变得重要。单镜头照相机102相对于机器人臂100的位置始终固定,因此公侧连接器110和母侧连接器120的相对性的位置信息反映于该图像。
在步骤S104中,通过具有事先学习了该相对性的位置信息的图6所示这样的神经网络的控制参数生成部202对控制量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)进行计算。但是,根据能否学习,有时控制参数生成部202输出的控制量无法至插入开始位置为止进行动作。在该情况下,有时通过将步骤S103~S106的循环反复多次,从而控制参数生成部202反复计算,以使得小于或等于步骤S105所示的阈值,控制部203和驱动部204进行控制而对机器人臂100的位置进行控制。
S105所示的阈值是根据嵌合的公侧连接器110和母侧连接器120的要求精度而决定的。例如,在与连接器的嵌合松弛,作为原本连接器的特性而无需如此精度的情况下,能够将阈值设定得大。另外在相反的情况下将阈值设定得小。通常来说在制造工序的情况下,大多对制作所能够容许的误差进行规定,因此也能够使用该值。
另外,根据能否学习,如果设想出控制参数生成部202输出的控制量无法至插入开始位置为止进行动作的情况,则也可以将插入开始位置进行多个位置设定。如果在没有充分地得到公侧连接器110和母侧连接器120的距离的情况下设定插入开始位置,则在进行插入开始前公侧连接器110和母侧连接器120抵接,存在任意者损坏的风险。在该情况下,例如将公侧连接器110和母侧连接器120的间隙最初设为5mm,然后设为20mm,然后设为10mm,可以与图4中的步骤S103~步骤S106之间的循环的次数相应地设定插入开始位置。
此外,在本实施方式中,使用连接器而进行了说明,但该技术的应用并不限定于连接器的嵌合。例如在基板载置IC的情况下也能够应用,特别是在将脚的尺寸误差大的电容器等插入至基板的孔时,如果使用相同的方法,则也会取得效果。
另外,并不一定限定于向基板的插入,也能够应用于根据图像和控制量的关系而求出控制量的位置控制整体。在本发明中,使用神经网络而对图像和控制量的关系进行学习,由此具有下述优点,即,能够对在进行物体和物体的对位时的各自的个体差进行吸收。
因此,在实施方式1中,具有:拍摄部201,其对两个物体存在的图像进行拍摄;控制参数生成部202,其将拍摄到的两个物体的图像的信息输入至神经网络的输入层,将用于对两个物体的位置关系进行控制的位置的控制量,作为神经网络的输出层而输出;控制部203,其使用输出的位置的控制量而对用于控制两个物体的位置关系的电流或者电压进行控制;以及驱动部204,其使用用于对两个物体的位置关系进行控制的电流或者电压,使两个物体的位置关系的一方的位置移动,因此具有下述效果,即,即使存在各个物体的个体差或者两个物体的位置关系的误差,也能够仅通过单镜头照相机进行对位。
以上,对使用一个神经网络的实施例进行了说明,但根据需要有时使用多个。其原因在于,在如以上这样将输入设为图像、将输出设为数值的情况下,在该数值的近似精度存在极限,根据状况而产生百分之几左右的误差。在从图4的步骤2的插入开始附近的位置起至插入开始位置为止的量中,步骤S105的判定始终成为No,有时动作没有完成。在上述这样的情况下,如图7这样使用多个网络。
图7是在实施方式1中的神经网络中,使用多个网络的流程图。示出了图4的步骤S104的详细步骤。多个参数包含于图2的控制参数生成部。
在步骤S701中,控制参数生成部202基于输入的图像对使用哪个网络进行选择。
在循环次数为第1次或者得到的控制量大于或等于25mm的情况下,对神经网络1进行选择而进入至步骤S702。另外,在循环次数为第2次及其以后所得到的控制量大于或等于5mm而小于25mm的情况下,对神经网络2进行选择而进入至步骤S703。并且在循环次数为第2次及其以后所得到的控制量小于5mm的情况下对神经网络3进行选择而进入至步骤S704。使用在步骤S702~步骤S704中选择出的神经网络对控制量进行计算。
例如,各神经网络与公侧连接器110和母侧连接器120的距离或者控制量相应地进行学习,图中的神经网络3将误差为±1mm、±1度的范围内的学习数据、神经网络2将±1~±10mm、±1~±5度的范围的学习数据设为阶段性地进行学习的数据的范围。在这里,不使在各神经网络中使用的图像的范围重叠是有效的。
另外,在该图7中示出了3个例子,但网络的数量并没有特别限制。在使用如上所述的方式的情况下,需要将决定是使用哪个网络的步骤S701的判别功能作为“网络选择开关”进行准备。
该网络选择开关也能够由神经网络构成。在该情况下,向输入层的输入图像、输出层的输出成为网络编号。图像数据使用在全部网络中使用的图像、网络编号的配对。
此外,关于使用多个神经网络的例子也使用连接器而进行了说明,但该技术的应用并不限于连接器的嵌合。例如在将IC载置于基板的情况下也能够应用,特别是在将脚的尺寸误差大的电容器等插入至基板的孔时,如果使用相同的方法,则也会取得效果。
另外,关于使用多个神经网络的例子,并不一定限于向基板的插入,能够利用于根据图像和控制量的关系而求出控制量的位置控制整体。在本发明中,使用神经网络而学习图像和控制量的关系,由此具有在进行物体和物体的对位时能够对各自的个体差进行吸收这样的优点,能够更高精度地计算控制量。
因此,具有:拍摄部201,其对两个物体存在的图像进行拍摄;控制参数生成部202,其将拍摄到的两个物体的图像的信息输入至神经网络的输入层,将用于对两个物体的位置关系进行控制的位置的控制量,作为神经网络的输出层而输出;控制部203,其使用被输出的位置的控制量而控制用于对两个物体的位置关系进行控制的电流或者电压;以及驱动部204,其使用用于对两个物体的位置关系进行控制的电流或者电压,使两个物体的位置关系的一方的位置移动,控制参数生成部202构成为从多个神经网络选择一个,因此具有下述效果,即,即使存在各个物体的个体差或者两个物体的位置关系的误差,也能够更高精度地进行对位。
实施方式2.
在实施方式1中,针对位置已知的嵌合状态的公侧连接器110和母侧连接器120,通过机器人臂100的抓持部101对公侧连接器110进行抓持。而且,一边在已知的拉出方向上移动抓持部101、一边移动至插入开始位置,并且通过单镜头照相机102取得多张图像。在实施方式2中,对公侧连接器110和母侧连接器120的嵌合位置未知的情况进行说明。
作为机器人自身进行学习、获得适当的行动的方法的先行研究,研究出了被称为强化学习的方法。在该方法中,机器人以反复试验地方式进行各种动作,一边对得到良好的结果的行动进行存储、一边作为结果而对行动进行优化,但为了行动的优化而需要大量的试行次数。
作为减少该试行次数的方法,通常使用在强化学习中被称为对策开启(on policy)的框架。但是,在将该框架应用于机器人臂的示教时,需要对机器人臂、控制信号进行专门的各种设计,因此是困难的,还没有达到实用化。
在实施方式2中,对下述方式进行说明,即,如实施方式1中这样的机器人以反复试验的方式进行各种动作,减少用于一边对得到良好的结果的行动进行存储、一边作为结果而将行动优化的大量的试行次数。
说明系统结构。没有特别记述的部分与实施方式1相同。
作为整体的硬件结构与实施方式1的图1相同,但不同点在于,在机器人臂100附加有对抓持部101所承受的负荷进行测量的力觉传感器801(在图1中未图示)。
图8示出实施方式2中的位置控制装置的功能结构图。与图2的差异是追加有力觉传感器801、路径决定部802,且路径决定部802由Critic部803、Actor部804、评价部805、路径设定部806构成。
图9是实施方式2中的位置控制装置的硬件结构图。与图3的不同点仅在于,力觉传感器801与输入输出接口301电连接或者可通信地连接。另外,输入输出接口301、处理器302、存储器303构成图8的控制参数生成部202的功能,并且还构成路径决定部802的功能。因此,在力觉传感器801、单镜头照相机201和输入输出接口301之间、输入输出接口301和控制电路间304之间可以分体地构成。
接下来,对图8的详细内容进行说明。
力觉传感器801对机器人臂100的抓持部101所承受的负荷进行测量,例如能够对图1所示的公侧连接器110和母侧连接器120抵接的情况下的力的值进行测量。
关于Critic部803及Actor部804,S3、S4与现有的强化学习这样的Critic部、Actor部相同。
在这里对现有的强化学习方法进行说明。在本实施例中在强化学习中也使用被称为Actor-Critic模型的模型(参考文献:强化学习:R.S.Sutton and A.G.Barto 2000年12月出版)。Actor部804、Critic部803通过拍摄部201、力觉传感器801而取得环境的状态。Actor部804是将使用传感器设备而取得的环境状态I设为输入、向机器人控制器输出控制量A的函数。Critic部803是Actor部804用于相对于输入I而适当地学习输出A的机构,以使得与Actor部804嵌合适当地成功。
下面,关于现有的强化学习方法的方式进行记载。
在强化学习中,对被称为收益R的量进行定义,使得将该R最大化的行动A能够由Actor部804获得。作为一个例子,如果将进行学习的作业设为如实施方式1所示这样的公侧连接器110和母侧连接器120的嵌合,则定义为在嵌合成功时R=1,在嵌合不成功时R=0等。行动A本次示出从当前时刻的位置(X,Y,Z,Ax,Ay,Az)起的移动校正量,A=(dX,dY,dZ,dAx,dAy,dAz)。在这里,X、Y、Z示出将机器人的中心部作为原点的位置坐标,Ax、Ay、Az各自示出了以X轴、Y轴、Z轴为中心的旋转量。移动校正量是从当前的地点起关于与公侧连接器110的嵌合,从用于首先试行的嵌合开始位置起的移动量。环境状态、即试行结果的观测,是根据来自拍摄部201的图像和力觉传感器801的值而得到的。
在强化学习中,将被称为状态价值函数V(I)的函数通过Critic部803进行学习。在这里,在时刻t=1(例如嵌合试行开始时)时,在状态I(1)下取得行动A(1),在时刻t=2(例如第1次的嵌合试行结束后第2次的嵌合开始前)时环境变化为I(2),设为得到收益量R(2)(初次的嵌合试行结果)。考虑各种更新式,将下述作为一个例子而举出。
V(I)的更新式通过以下方式进行定义。
【式1】
δ=R(2)+γV(I(2))-V(I(1))
【式2】
在这里,δ为预测误差,α为学习系数且为0~1的正实数,γ为减利率且为0~1的正实数。
Actor部804将输入设为I、将输出设为A(I),如下面这样对A(I)进行更新。
在δ>0时
【式3】
在δ≤0时
【式4】
在这里,σ表示输出的标准偏差的值,Actor在状态I中,对A(I)加上具有平均0、将分散设为σ2的分布的随机数。即,与试行的结果无关,随机地决定第2次的移动校正量。
此外,将上述的更新式作为一个例子使用,但Actor-Critic模型还存在各种更新式,如果不采用上述而是通常使用的模型,则能够变更。
但是,Actor部804在上述的结构中,在各状态下觉察适当的行动,但如实施方式1这样进行动作是在学习完成的时刻。在学习中从路径设定部806对学习时的推荐行动进行计算并发送,因此在学习时针对控制部203,直接接收来自路径设定部806的移动信号而控制部203对驱动部204进行控制。
即,在Actor-Critic的现有的模型中,定义为在嵌合成功时R=1,在嵌合不成功时R=0,因此在嵌合成功时初次进行学习,且直至嵌合成功为止,在试行中使用的移动校正量被随机赋予,因此不进行与试行的失败程度相对应的用于下一次试行的移动校正量的决定。其原因在于,不仅是Actor-Critic的现有的模型,即使使用Q-Learning等其他强化学习模型,也只会对嵌合的成功和失败本身进行评价,因此成为相同的结果。在本发明的本实施方式中,对该失败程度进行评价而对决定用于下一次试行的移动校正量的过程进行说明。
评价部805生成进行各嵌合试行时的评价的函数。
图10是表示实施方式2中的公侧连接器110和母侧连接器120的嵌合的试行的情况的图。
例如如图10(A)这样的图像作为试行的结果而到手。在该试行中,由于连接器的嵌合位置大幅地偏离,因此失败。此时对是与哪个程度成功接近进行测量而数值化,求出表示成功程度的评价值。作为数值化的方法,例如如图10(B)这样,存在在图像中对插入目标侧的连接器表面积(像素数)进行计算的方法。在该方法中,在通过机器人臂100的力觉传感器801检测到公侧连接器110和母侧连接器120的插入失败时,仅将母侧连接器120嵌合面的表面涂敷与其他背景不同的颜色,或者粘贴贴纸,由此来自图像的数据取得和计算变得更简易。另外,在至此为止所述的方法中,是照相机的数量为一台的情况,但也可以将多台照相机并排而拍摄,将使用拍摄到的各自的图像结果进行综合。另外,在连接器表面积以外,取得2维方向(例如X、Y方向)的像素数等,也能够进行相同的评价。
路径设定部806可知作为处理而进行两个步骤。
在第一步骤中,对通过评价部805处理后的评价结果和机器人实施的动作进行学习。在将机器人的移动校正量设为A、将通过评价部805处理后的表示成功程度的评价值设为E时,路径设定部806准备将A设为输入、将E设为输出的函数,进行近似。作为函数,作为一个例子而举出RBF(Radial Basis Function)网络。RBF已知作为能够将各种未知的函数简单地近似的函数。
例如,第k次的输入
【式5】
x^k=(x_1^k,…,x_i^k,…x_I^k)
针对该式输出f(x)以下述方式进行定义。
【式6】
【式7】
在这里,σ为标准偏差,μ代表RBF的中心。
通过RBF进行学习的数据,不使用单体,而是使用从试行开始时至最新的数据为止的全部。例如,当前,在第N次的试行的情况下,准备了N个数据。需要通过学习而决定上述的W=(w_1、···w_J),关于该决定而考虑各种方法,但作为一个例子而举出如下述这样的RBF补全。
【式8】
【式9】
F=(f(x1),…,f(xN))
此时
【式10】
W=Φ-1F
由此,学习完成。
在通过RBF补全而结束近似后,根据最急下降法、PSO(Particle Swam Optimization)等通常的优化方法,通过上述RBF网络而求出最小值。将该最小值作为下一个推荐值而向下一个Actor部804输入。
总之,如果对上述事例具体地说明,则将与失败时的移动校正量相对应的表面积、2维方向的像素数作为评价值而针对每个试行次数以时间序列排列,使用该排列值求出最佳解。也可以更简单地在减少2维方向的像素数的方向上求出以一定比例移动后的移动校正量。
接下来,在图11中示出动作流程。
图11是实施方式2中的位置控制装置的路径学习中的流程图。
首先,在步骤S1101中,机器人臂100的抓持部101对公侧连接器110进行抓持。该公侧连接器110的位置、姿态在图8的控制部203侧被事先登记,基于预先在控制部203侧登记的控制程序而进行动作。
接下来,在步骤S1102中,将机器人臂100接近至母侧连接器120的插入位置附近。该母侧连接器110的大致的位置、姿态,在图8的控制部203侧被事先登记,基于预先在控制部203侧登记的控制程序,使公侧连接器110的位置进行动作。至此为止与实施方式1中的图4的流程图的步骤S101~S102相同。
接下来,在步骤S1103中,路径决定部802针对单镜头照相机102的拍摄部201,指示对图像进行拍摄,单镜头照相机102对反映出抓持部101抓持着的公侧连接器110和成为插入目标的母侧连接器120两者的图像进行拍摄。并且,路径决定部802针对控制部203和单镜头照相机102,指示对当前位置附近处的图像进行拍摄,在基于指示给控制部203的多个移动值而通过驱动部204移动后的位置处,通过单镜头照相机对反映出公侧连接器110和成为插入目标的母侧连接器120两者的图像进行拍摄。
接下来,在步骤S1104中,路径决定部802部的Actor部804,将用于进行嵌合的移动量赋予给控制部203而通过驱动部204使机器人臂100移动,试行公侧连接器110和成为插入目标的母侧连接器120的嵌合。
接下来,在步骤S1105中,在通过驱动部204将机器人臂100移动中连接器彼此接触的情况下,针对移动量的每个单位量将力觉传感器801的值和来自单镜头照相机102的图像由路径决定部802的评价部805和Critic部803进行存储。
而且,在步骤S1106中由评价部805和Critic部803对嵌合是否成功进行确认。
通常,在该时刻嵌合没有成功。因此,在步骤S1108中评价部805通过在图10中说明的方法对成功程度进行评价,将表示相对于对位的成功程度的评价值赋予给路径设定部806。
而且,在步骤S1109中,路径设定部806使用上述的方法进行学习,路径设定部806将下一个推荐值赋予给Actor部804,并且Critic部803对与收益量相应地求出的值进行输出,Actor部804进行接收。在步骤S1110中,Actor部804将由Critic部803输出的与收益量相应地求出的值、和由路径设定部806输出的下一个推荐值进行相加而求出移动校正量。此外,在该步骤中,在仅使用由路径设定部806输出的下一个推荐值就具有充分的效果的情况下,当然无需对由Critic部803输出的与收益量相应地求出的值进行相加。另外,Actor部804为了求出移动校正量,也可以与由Critic部803输出的与收益量相应地求出的值和由路径设定部806输出的下一个推荐值的相加比率进行设定,与相加比率相应地变更。
然后,在步骤S1111中,Actor部804将移动校正量赋予给控制部203,使机器人臂100的抓持部101移动。
然后,再次返回至步骤1103,在通过移动校正量移动后的位置对图像进行拍摄,进行嵌合动作。直至成功为止将其反复进行。
在嵌合成功的情况下,在步骤S1107中,在嵌合成功后,关于从嵌合成功时的步骤S1102至S1106为止的I进行Actor部804及Critic部803的学习。最后,路径决定部802将该学习得到的神经网络的数据赋予给控制参数生成部202,由此能够进行实施方式1中的动作。
此外,在上述步骤S1107中,设为在嵌合成功的情况下关于I进行Actor部804及Critic部803的学习,但也可以从嵌合试行公开至成功为止使用全部试行时的数据而Actor部804及Critic部803进行学习。在该情况下,在实施方式1中,关于与控制量相应地形成多个神经网络的情况进行了记载,但如果知晓嵌合的成功的位置,则能够使用直至嵌合成功为止的距离而同时地形成与控制量的大小相对应的适当的多个神经网络。
作为强化学习模块而在基础中记载有Actor-Critic模型,但也可以使用Q-Learning等其他强化学习模型。
作为函数近似而举出了RBF网络,但也可以使用其他函数近似方法(线性、二次函数等)。
作为评价方法,举出在连接器的表面设置颜色差异的方法,但也可以是通过其他图像处理技术对连接器间的偏差量等进行评价的评价方法。
另外,如在实施方式1及本实施方式中所述这样,该技术的应用并不限定于连接器的嵌合。例如在将IC载置于基板的情况下也能够应用,特别是在将脚的尺寸误差大的电容器等插入至基板的孔的情况下,如果使用相同的方法,则也会取得效果。
另外,并不一定限定于向基板的插入,也能够利用于根据图像和控制量的关系而求出控制量的位置控制整体。在本发明中,具有下述优点,即,使用神经网络而学习图像和控制量的关系,由此能够在进行物体和物体的对位时对各自的个体差进行吸收,能够更高精度地计算控制量。
因此,在本实施方式中,在为了学习控制量而使用Actor-Critic模型时,Actor部804求出用于将由Critic部803与收益量相应地求出的值和由路径设定部806基于评价值求出的推荐值相加而试行的移动校正量,由此在通常的Actor-Critic模型中,直至对位成功为止需要非常多的反复试验次数,但根据本发明,能够大幅地削减对位的试行次数。
此外,在本实施方式中,关于对来自对位失败时的拍摄部201的图像进行评价而削减对位的试行次数进行了记载,但使用对位试行时的力觉传感器801的值也能够削减试行次数。例如,在包含连接器的嵌合或者两个物体的插入的对位中,通常在失败时由Actor部804对在力觉传感器801的值大于或等于阈值时是否处于两个物体的位置嵌合或者插入完成的位置进行判断。在该情况下,还考虑a.在达到阈值的时刻是嵌合或者插入中途的情况,b.嵌合和插入完成的嵌合或者插入中途的力觉传感器801的值表示一定程度的值的情况等。
在a.的情况下,存在对力觉传感器801的值和图像这两者进行学习的方法,如果使用在实施方式3中记载的方法,则能够实施详细内容。
在b.的情况下,作为仅对力觉传感器801的值进行学习的方法,如果使用在实施方式3中记载的方法,则能够实施。另外,作为其他方法,在Actor-Critic模型中的收益R的定义中,在将嵌合或者插入过程中所承受的最大负荷设为F,将A设为正的常数时,在成功时,定义为R=(1-A/F),在失败时,定义为R=0,也能够取得相同的效果。
实施方式3.
在本实施方式中,关于在实施方式2中在对位成功之后进行的学习过程中高效地对数据进行收集的方法进行说明。因此,关于没有特别说明的情况设为与实施方式2相同。即,实施方式3中的位置控制装置的功能结构图为图8,硬件结构图为图9。
在动作中,对从实施方式2中的图11的步骤S1107的动作时高效地对学习数据进行收集的方法进行以下说明。
图12示出了实施方式3中的位置控制装置的路径学习中的流程图。
首先,步骤S1201中,在图11的步骤S1107中公侧连接器110和母侧连接器120的嵌合成功的情况下,路径设定部806将变量设为i=0、j=1、k=1而初始化。变量i为此后的机器人臂100的学习次数,变量k为从公侧连接器110和母侧连接器120的嵌合脱离时起的学习次数,变量j为图12的流程图的循环次数。
接下来,在步骤S1202中,经由Actor部804向控制部203赋予移动量,通过驱动部204使机器人臂100移动,以使得路径设定部806从在图11步骤S1104中为了进行嵌合而赋予的移动量起返回1mm的量。而且对变量i加上1。在这里,赋予了从移动量起返回1mm的指示,但无需一定限定于1mm,也可以是0.5mm或2mm等的单位量。
接下来,在步骤S1203中,路径设定部806将此时的坐标设为O(i)(此时i=1)而存储。
在步骤S1204中,路径设定部806以O(i)为中心,随机地决定移动量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz),经由Actor部804向控制部203赋予移动量,通过驱动部204使机器人臂100移动。此时,该移动量的最大量能够在可移动的范围任意地设定。
接下来在步骤S1205中,在步骤S1204中移动后的位置,Actor部804对与移动量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)相对应的力觉传感器801的值进行收集,并且在步骤S1206中,Critic部803和Actor部804将对移动量乘以-1(-ΔX,-ΔY,-ΔZ,-ΔAx,-ΔAy,-ΔAz)和为了对公侧连接器110进行保持所承受的力进行测量的力觉传感器801的传感器值,作为学习数据而记录。
接下来在步骤S1207中,路径设定部806对收集到的数据数是否能够达到规定数J进行判定。如果数据数不足,则在步骤S1208中对变量j加1而返回至步骤S1204,将移动量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)通过随机数改变而取得数据,直至储存规定数J个的数据为止反复进行S1204~S1207。
在储存规定数的数据后,在步骤S1209中,路径设定部806将变量j设为1,然后在步骤S1210中,对公侧连接器110和母侧连接器120的嵌合脱离进行确认。
如果没有脱离,则经由步骤S1211而返回至步骤S1202。
在步骤S1211中路径设定部806经由Actor部804而向控制部203赋予移动量,通过驱动部204使机器人臂100移动,以使得机器人臂100的坐标返回至赋予移动量前的坐标O(i)。
然后,直至公侧连接器110和母侧连接器120的嵌合脱离为止重复进行步骤S1202至步骤S1210为止的循环,重复进行从为了进行嵌合而赋予的移动量起返回1mm或者单位量的处理、和以返回的位置为中心赋予移动量而对力觉传感器801的数据进行收集的处理。在公侧连接器110和母侧连接器120的嵌合脱离的情况下,进入至步骤S1212。
在步骤S1212中,路径设定部806将变量i设为I(I为比在判定为公侧连接器110和母侧连接器120的嵌合脱离时的i的值大的整数),并且经由Actor部804而对控制部203赋予移动量,通过驱动部204使机器人臂100移动,以使得从为了进行嵌合而赋予的移动量起返回例如10mm(在这里也可以是其他值)。
接下来,在步骤S1213中,路径设定部806将在步骤S1212中移动的机器人臂100的坐标的位置作为中心位置O(i+k)而存储。
接下来,在步骤S1214中,路径设定部806以中心位置O(i+k)为中心,再次随机地决定移动量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz),然后经由Actor部804对控制部203赋予移动量,通过驱动部204使机器人臂100移动。
在步骤S1215中,Critic部803和Actor部804取得在通过移动量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)移动后的机器人臂100位置由单镜头照相机102的拍摄部201拍摄到的图像。
在步骤S1216中,Critic部803和Actor部804将对移动量乘以-1的(-ΔX,-ΔY,-ΔZ,-ΔAx,-ΔAy,-ΔAz)图像作为1个学习数据而进行记录。
在步骤S1217中,路径设定部806对收集的数据数是否能够达到规定数J进行判定。如果数据数不足,则在步骤S1212中对变量j加上1而返回至步骤S1214,将移动量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)通过随机数改变而取得数据,直至积蓄规定数J个数据为止而重复S1214~S1217。
此外,能够取得S1204中的移动量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)和S1204中的移动量的随机值的最大值不同的值。
通过以上的方法取得的学习数据,进行Actor部804及Critic部803的学习。
图13是表示实施方式3中的神经网络和神经网络的学习规则的例子的图。
关于实施方式1、2,对使用力觉传感器801的数据的学习方法进行了记载。在实施方式1和2中,输入层仅针对图像,在实施方式3中,向输入层取代图像而输入力觉传感器801的值即可。力觉传感器801的值在3个(力和2个方向的力矩)的情况下和6个(3个方向和3个方向力矩)的情况下均可。输出层将控制量(ΔX,ΔY,ΔZ,ΔAx,ΔAy,ΔAz)输出。此外,在公侧连接器110和母侧连接器120的嵌合脱离的情况下,向输入层同时地输入图像和力觉传感器801的值。
在神经网络的学习过程中,为了使输入的图像及根据从力觉传感器801的值经由中间层而得到的输出层的输出值与图像及力觉传感器801的值和在组中存储的控制量近似,对中间层的参数进行优化,进行学习。
最后,路径决定部802将该学习的神经网络的数据赋予给控制参数生成部202,由此能够进行实施方式1中的动作。
此外,在本实施方式中,从用于进行公侧连接器110和母侧连接器120的嵌合的移动起稍微返回,并为了使机器人臂100微小地向周边移动而学习,以直至嵌合脱离为止通过单镜头照相机102的图像的像素量无法进行充分的学习为前提而进行了说明。
但是,在即使单镜头照相机102的图像是充分高精细且使机器人臂100微小地向周边移动的图像,仍能够充分地学习的情况下,也可以仅通过单镜头照相机102的图像进行学习,在公侧连接器110和母侧连接器120嵌合的情况下,也可以使用单镜头照相机102的图像和力觉传感器801的值两者。
并且,在实施方式1、2中,对使用多个神经网络的情形进行了说明。在本实施方式中,在例如公侧连接器110和母侧连接器120嵌合的状态、公侧连接器110和母侧连接器120没有嵌合的情况下,也可以区分神经网络。如上述说明所述,在公侧连接器110和母侧连接器120嵌合的状态下仅在输入层形成力觉传感器801,仅通过从嵌合脱离的图像形成输入层,能够进行更高精度的学习,在仅通过图像进行学习的情况下,能够与没有嵌合的情况进行区分,由此能够为了图像的结构而进行高精度的学习。
此外,如在实施方式1、2中所述这样,在本实施方式中,该技术的应用并不限定于连接器的嵌合。例如也能够应用于对基板载置IC的情况,特别是在将脚的尺寸误差大的电容器等向基板的孔插入的情况下,如果使用相同的方法,则也会取得效果。
另外,并不一定限定于向基板的插入,能够利用于根据图像和控制量的关系而求出控制量的位置控制整体。在本发明中,使用神经网络对图像和控制量的关系进行学习,由此具有下述优点,即,在进行物体和物体的对位时能够对各自的个体差进行吸收,能够更高精度地对控制量进行计算。
因此,在本实施方式中,具有:路径设定部806,其在关于两个物体包含伴随插入的对位的情况下,为了学习控制量,对向在从插入状态拔出时从插入状态起的路径上和其周边移动的移动量进行指示;以及Actor部804,其取得移动后的位置的输出层、为了将移动后的位置的力觉传感器801的值作为输入层而学习所移动后的位置和力觉传感器801的值,因此能够高效地对学习数据进行收集。
标号的说明
100:机器人臂,
101:抓持部,
102:单镜头照相机
110:公侧连接器
120:母侧连接器
201:拍摄部
202:控制参数生成部
203:控制部
204:驱动部
301:输入输出接口
302:处理器,
303:存储器,
304:控制电路,
305:电动机,
801:力觉传感器
802:路径决定部
803:Critic部
804:Actor部
805:评价部
806:路径设定部
- 还没有人留言评论。精彩留言会获得点赞!