一种多炉并联运行的污染物控制量分配调控系统及方法与流程
1.本发明涉及锅炉控制领域,特别是涉及一种多炉并联运行的污染物控制量分配调控系统及方法。
背景技术:
2.由于生产需要,往往会建造多台炉(电厂锅炉、石灰窑炉等),在烟气治理时,为了降低治理成本往往将多台炉烟气进行汇流统一进入烟气治理系统,待烟气治理后从烟囱排出,因为监控平台设置在烟囱和治理系统之间,往往采集的是汇总烟气的总排。当其中一台或多台炉工况发生变化时,此时,很难通过监控数据对各个炉污染物的控制量进行精准分配。
技术实现要素:
3.本发明的目的是提供一种多炉并联运行的污染物控制量分配调控系统及方法,对各个炉污染物的控制量进行精准分配。
4.为实现上述目的,本发明提供了如下方案:
5.一种多炉并联运行的污染物控制量分配调控系统,所述调控系统包括:
6.数据采集模块,用于采集历史烟气温度、含氧量以及污染物入口浓度;
7.污染物浓度预测模型建立模块,用于建立各台炉出口污染物浓度预测模型;所述污染物浓度预测模型为神经网络模型;
8.污染物浓度预测模块,用于采用所述污染物预测模型对污染物浓度进行预测,得到污染物浓度预测值;
9.各污染物浓度的变化值引起的总控制量计算模块,用于基于所述污染物的浓度预测值、污染物浓度目标值以及污染物浓度实时反馈值采用遗传-神经网络算法确定每台炉的各污染物浓度的变化值引起的总控制量;所述污染物目标值为目标值为用户要求的污染物排放限值,所述实时反馈值为在线实测值;
10.每台炉的分配控制量计算模块,用于基于所述各污染物浓度的变化值引起的总控制量确定每台炉的分配控制量。
11.可选的,所述系统还包括:
12.校正模块,用于对所述污染物浓度预测值进行校正。
13.可选的,所述校正模块具体包括:
14.污染物浓度实际值获取单元,用于获取k时刻污染物浓度实际值;
15.污染物浓度预测值获取单元,用于获取k-1时刻污染物浓度预测值;
16.偏差计算单元,用于计算所述k时刻污染物浓度实际值和所述k-1时刻污染物浓度预测值的偏差;
17.校正单元,用于将所述偏差作为k时刻预测误差的估计值,并将所述估计值作为反馈校正信号补偿到k时刻的污染物浓度预测模型中,得到校正后的污染物浓度。
18.可选的,所述每台炉的分配控制量计算模块具体采用以下公式:
19.其中,i=1,2,3....n,ui分表示第i台锅炉分配的控制量,qi表示第i台炉的烟气量,单位为m3/h,δci表示第i台炉的污染物的变化量,单位为mg/m3,δm表示污染物变化引起的总控制量。
20.基于本发明中的上述系统,本发明另外提供一种多炉并联运行的污染物控制量分配调控方法,所述调控方法包括以下步骤:
21.采集历史烟气温度、含氧量以及污染物入口浓度;
22.建立各台炉出口污染物浓度预测模型;所述污染物浓度预测模型为神经网络模型;
23.采用所述污染物预测模型对污染物浓度进行预测,得到污染物浓度预测值;
24.基于所述污染物的浓度预测值、污染物浓度目标值以及污染物浓度实时反馈值采用遗传-神经网络算法确定每台炉的各污染物浓度的变化值引起的总控制量;所述污染物目标值为目标值为用户要求的污染物排放限值,所述实时反馈值为在线实测值;
25.基于所述各污染物浓度的变化值引起的总控制量确定每台炉的分配控制量。
26.可选的,所述方法在采用所述污染物预测模型对污染物浓度进行预测,得到污染物浓度预测值之前还包括:
27.对所述污染物浓度预测值进行校正。
28.可选的,对所述污染物浓度预测值进行校正具体包括以下步骤:
29.获取k时刻污染物浓度实际值;
30.获取k-1时刻污染物浓度预测值;
31.计算所述k时刻污染物浓度实际值和所述k-1时刻污染物浓度预测值的偏差;
32.将所述偏差作为k时刻预测误差的估计值,并将所述估计值作为反馈校正信号补偿到k时刻的污染物浓度预测模型中,得到校正后的污染物浓度。
33.可选的,基于所述各污染物浓度的变化值引起的总控制量确定每台炉的分配控制量具体采用以下公式:
34.其中,i=1,2,3....n,ui分表示第i台锅炉分配的控制量,qi表示第i台炉的烟气量,单位为m3/h,δci表示第i台炉的污染物的变化量,单位为mg/m3,δm表示污染物变化引起的总控制量。
35.根据本发明提供的具体实施例,本发明公开了以下技术效果:
36.本发明中的上述系统及方法,通过设置数据采集模块,采集烟气温度、含氧量以及污染物入口浓度;通过设置污染物浓度预测模型建立模块建立各台炉出口污染物浓度预测模型;通过设置污染物浓度预测模块采用所述污染物预测模型对污染物浓度进行预测,得到污染物浓度预测值;通过设置各污染物浓度的变化值引起的总控制量计算模块,用于基于所述污染物的浓度预测值、污染物浓度目标值以及污染物浓度实时反馈值采用遗传-神经网络算法确定每台炉的各污染物浓度的变化值引起的总控制量;通过设置每台炉的分配控制量计算模块,用于基于所述各污染物浓度的变化值引起的总控制量确定每台炉的分配控制量,采用上述方法及系统可定量的计算各炉因工况波动带来的控制量的变化,自主的
分配的各个炉的控制量,采用遗传-神经网络联用模型更精准的分析测算炉因负荷变化所带来的总控制量变化,当各炉工况进行变化时,能够精准分配控制量,大大节约了控制量的耗量,从而降低运行和投入成本;采用本发明能够解决多炉污染物共用污染物监测设备,导致难以有效单独控制调节的问题。
附图说明
37.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
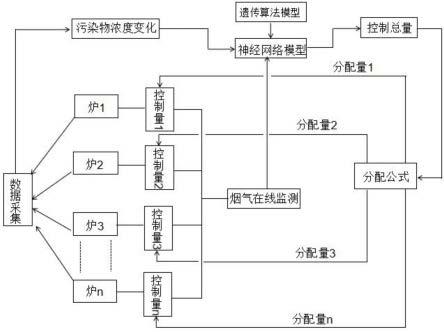
38.图1为本发明实施例多台炉智能分配流程图;
39.图2为本发明实施例污染物及控制量预测图;
40.图3为本发明实施例出口污染物实测值;
41.图4为本发明实施例遗传-神经网络算法流程图;
42.图5为本发明实施例污染物浓度预测模型结构示意图。
具体实施方式
43.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
44.本发明的目的是提供一种多炉并联运行的污染物控制量分配调控系统及方法,对各个炉污染物的控制量进行精准分配。
45.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
46.本发明中的上述系统及方法以烟气温度、含氧量,污染物入口浓度等烟气参数以及设备参数进行数据采集,以在线监测出口污染物浓度进行反馈校正建立各台炉出口污染物预测模型,得出污染物变化浓度,再以污染物浓度预测值、污染物目标值、污染物实时反馈值为参数,并通过遗传-神经网络算法联用模型分析测算每台炉的各污染物(no
x
、so2、粉尘等)浓度的变化值引起总控制量,按每台炉污染物浓度变化占比总污染浓度的变化来确定每台炉的贡献,根据控制量分配计算公式,从而得到每台炉的分配控制量进行精准分配
47.结合图1-图3,本发明中的系统包括:数据采集模块、污染物浓度预测模型建立模块、污染物浓度预测模块、各污染物浓度的变化值引起的总控制量计算模块以及每台炉的分配控制量计算模块。
48.其中,数据采集模块用于采集烟气温度、含氧量以及污染物入口浓度。
49.污染物浓度预测模型建立模块用于建立各台炉出口污染物浓度预测模型。
50.污染物浓度预测模块用于采用所述污染物预测模型对污染物浓度进行预测,得到污染物浓度预测值。
51.各污染物浓度的变化值引起的总控制量计算模块用于基于所述污染物的浓度预
测值、污染物浓度目标值以及污染物浓度实时反馈值采用遗传-神经网络算法确定每台炉的各污染物浓度的变化值引起的总控制量。
52.每台炉的分配控制量计算模块用于基于所述各污染物浓度的变化值引起的总控制量确定每台炉的分配控制量。
53.所述每台炉的分配控制量计算模块具体采用以下公式:
54.其中,i=1,2,3....n,ui分表示第i台锅炉分配的控制量,qi表示第i台炉的烟气量,单位为m3/h,δci表示第i台炉的污染物的变化量,单位为mg/m3,δm表示污染物变化引起的总控制量。
55.为了提高测量精度,本发明中的上述系统还包括:
56.校正模块,用于对所述污染物浓度预测值进行校正。
57.以污染物控制系统为研究对象,污染物图ym为出口污染物浓度目标值,y为出口污染物浓度预测值,yc为预测模型出口污染物预测值,yf为校正后的出口污染物浓度预测值。通过算法运行,可以得到出口污染物浓度y(k-1)以及预测模型出口污染物浓度yc(k)。相应的,也可以得到y(k)和yc(k+1)。将k时刻实际输出y(k)与k-1时刻模型输出yc(k)之间的偏差视为k时刻预测误差的估计值,并将其作为反馈校正信号补偿到k时刻的预测模型输出yc(k+1)中,即反馈校正后的预测值为:
58.yf(k+1)=yf(k+1)+y(k)-yf(k)
59.反馈校正环节考虑了上一时刻的模型预测误差,一定程度上提高了模型预测精度。将yf(k+1)和ym(k+1)输入目标函数中,进行不断地滚动优化,从而得到更精准的出口污染物浓度预测。
60.具体的,校正模块主要包括:
61.污染物浓度实际值获取单元,用于获取k时刻污染物浓度实际值;
62.污染物浓度预测值获取单元,用于获取k-1时刻污染物浓度预测值;
63.偏差计算单元,用于计算所述k时刻污染物浓度实际值和所述k-1时刻污染物浓度预测值的偏差;
64.校正单元,用于将所述偏差作为k时刻预测误差的估计值,并将所述估计值作为反馈校正信号补偿到k时刻的污染物浓度预测模型中,得到校正后的污染物浓度。
65.基于本发明中的上述系统,本发明另外提供一种多炉并联运行的污染物控制量分配调控方法,所述方法包括:
66.步骤101:采集历史烟气温度、含氧量以及污染物入口浓度。所述历史烟烟气温度、含氧量以及污染物入口浓度用于对后续的污染物浓度预测模型进行训练。其中,x=(x1,x2,
…
,xn),y=f(x1,x2,
…
,xn){(x,y)}x为输入量,y为x对应的理想输出量}。
67.步骤102:建立各台炉出口污染物浓度预测模型;所述污染物浓度预测模型为神经网络模型。图5为本发明实施例污染物浓度预测模型结构示意图,如图5所示,所述污染物浓度预测模型为神经网络模型,具体包括:输入层、隐藏层以及输出层。
68.步骤103:采用所述污染物预测模型对污染物浓度进行预测,得到污染物浓度预测值。
69.步骤104:基于所述污染物的浓度预测值、污染物浓度目标值以及污染物浓度实时
反馈值采用遗传-神经网络算法确定每台炉的各污染物浓度的变化值引起的总控制量。所述污染物目标值为目标值为用户要求的污染物排放限值,所述实时反馈值为在线实测值。
70.遗传算法变量选择是利用遗传算法进行优化,编码长度设计为ⅵ,种群大小为p,最大进化代数设为n,染色体一一对应输人变量。每一位基因仅取“0”和“1”两种情况:若为“1”,其对应的输入变量参与最后的优化;若为“0”,则不参与最后优化。取测试样本集和方差的倒数为遗传算法适应度函数,选择运算采用比例选择算子,交叉运算采用多点交叉算子,变异运算采用多点变异算子,经过大量数据的不断迭代进化。当满足迭代终止条件(最大进化代数n)时,筛选出最优变量{u1,u2,u3,
…
,ui},并以遗传算法筛选出的{u1,u2,u3,
…
,ui}作为网络输入变量,构建神经网络模型,利用大量数据进行数据挖掘,采用交叉验证的方法训练神经网络模型。采用循环训练法找出最佳值,从而达到最好的预测效果,具体如图4所示。
71.步骤105:基于所述各污染物浓度的变化值引起的总控制量确定每台炉的分配控制量。
72.具体公式如下:
73.其中,i=1,2,3....n,ui分表示第i台锅炉分配的控制量,qi表示第i台炉的烟气量,单位为m3/h,δci表示第i台炉的污染物的变化量,单位为mg/m3,δm表示污染物变化引起的总控制量。
74.本发明中的上述系统及方法具有以下效果:
75.采用本发明中的上述方法可定量的计算各炉因工况波动带来的控制量的变化,自主的分配的各个炉的控制量。
76.采用遗传-神经网络联用模型更精准的分析测算炉因负荷变化所带来的总控制量变化。
77.当各炉工况进行变化时,能够精准分配控制量,大大节约了控制量的耗量,从而降低运行和投入成本。
78.采用该发明能够解决多炉污染物共用污染物监测设备,导致难以有效单独控制调节的问题。
79.本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
80.本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1