基于强化学习的传感器采样调度方法
本发明涉及工业物联网,尤其涉及一种基于强化学习的传感器采样调度方法、装置、设备及介质。
背景技术:
1、随着5g商用网络部署范围不断扩大,物联网络发展进入了新的发展阶段。根据思科的报告,到2023年,全球将有147亿互联网设备,平均全球每个人将会有1.8个传感器。而根据爱立信的移动报告,到2026年,将有269亿的互联网设备接入。
2、其中,工业物联网(industrial internet of things,iiot)设备占据很大的比重,是物联网最重要的发展方向之一。工业物联网被视为工业系统最大的范式转变之一,它有可能彻底改变工业生产的现有体。由于泛在链接和泛在计算,工业物联网由端到端的通信网络转变为一个具备信息收集、处理、分析能力的综合系统。由于系统是以信息为中心的,因此系统的主要成员都为信息服务,比如捕捉信息的传感器,存储信息的缓存单元,利用信息的决策器。在不间断运行的工业系统中,服务质量受新鲜信息的传输时效性影响最大。比如,工业自动化生产流水线中控制器需要实时掌握机器的信息,以便做出使系统平稳运行的操作。
3、综上,如何调度iiot中的信息,使得控制服务可以获得新鲜的系统信息是一个重要的问题。
技术实现思路
1、本发明提供一种基于强化学习的传感器采样调度方法、装置、计算机设备及介质,通过合理调度工业物联网中的信息,使得控制服务可以获得新鲜的系统信息,更优地实现工业生产实时调度的效果,进一步促进技术落地,实现工业生产效率的优化。
2、第一方面,提供了一种基于强化学习的传感器采样调度方法,包括:
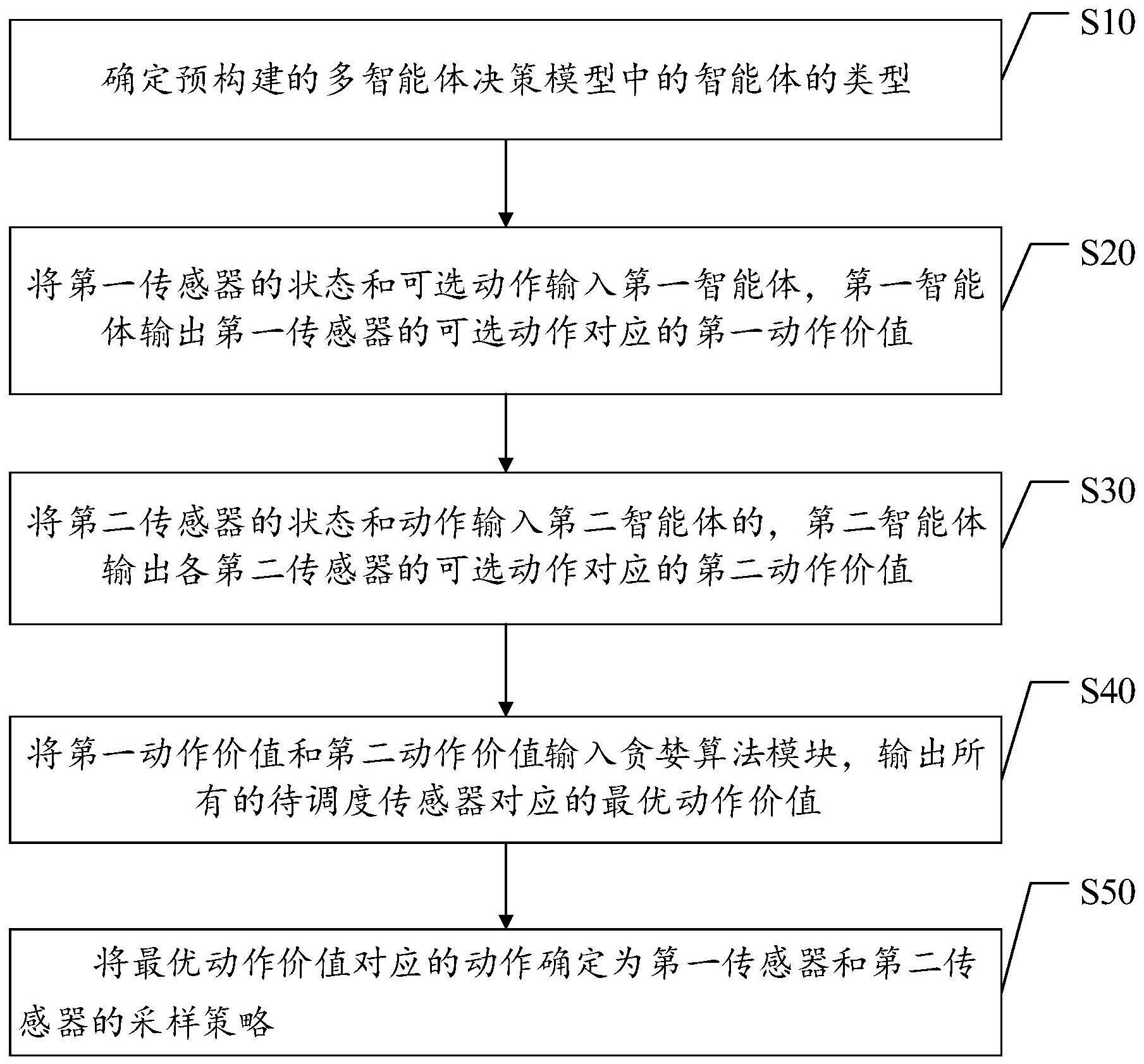
3、根据待调度传感器的分类构建多智能体决策模型,其中,待调度传感器包括第一传感器和第二传感器,多智能体模型包括第一智能体和第二智能体,第一智能体与第一传感器一一对应,第二智能体与多个第二传感器对应;
4、将各第一传感器的状态和动作输入与各第一传感器对应的第一智能体,第一智能体输出第一传感器动作对应的第一动作价值;
5、将各第二传感器的状态和动作依次输入第二智能体,第二智能体依次输出各第二传感器动作对应的第二动作价值;其中,当前第二传感器的状态包括输入第二智能体的顺序排序在当前第二传感器之前的各其他第二传感器的动作;当前第二类传感为当前利用第二智能体运算第二动作价值的第二类传感;
6、根据第一动作价值和第二动作价值,得到待调度传感器的优选动作价值;
7、根据优选动作价值确定待调度传感器的采样调度方法。
8、在一些实施例中,待调度传感器包括第一传感器和第二传感器,包括:
9、待调度传感器包括支持智能体运算的第一传感器和不支持智能体运算的第二传感器。
10、在一些实施例中,根据待调度传感器的分类构建多智能体决策模型,包括:
11、构建多智能体决策模型为马尔科夫博弈过程,多智能体决策模型的数学语言表示为{n,s,{ai}i=1,2,...n,п,γ,{ri}i=1,2...n};
12、其中,n表示多智能体的数目;
13、s表示所有智能体共享的环境状态集,s={si}i=1,2,3,...n,每一个传感器共享的状态信息包括ap信息池中传感器信息的aoi值和每个传感器自身电池信息,信息对应应用关系,具体表达式为:
14、
15、式中,ai表示第i个智能体的动作集,智能体的动作集用智能体的信息更新策略表示:
16、ai(t)=αi(t)={xi(t),qi(t),pi(t)}
17、π表示智能体动作选择策略的合集,π={π1,π2,...πn},每一个πi表示的是si→ai的概率;
18、γ表示状态转移概率,用s×a1×a2×...×an→s’表示。
19、r表示的是多智能体合作行为的立即奖励;其中,立即奖励由应用的aoci的绝对值和应用aoci的相对值两部分的加权和组成;
20、在传感器耗尽电池能源时和/或一个预设计算周期结束,智能体获得-rb的惩罚项作为最终奖励;在传感器顺利完成周期内的信息采集任务后,根据运行过程中的峰值aoci,会获得rf(δ)的额外奖励。
21、在一些实施例中,将各第二传感器的状态和动作依次输入第二智能体,第二智能体依次输出各第二传感器动作对应的第二动作价值,包括:
22、对第二传感器进行顺序编号,其中,顺序编号用于表示第二传感器输入第二智能体的顺序;
23、按照顺序编号依次将各第二传感器的状态和动作输入第二智能体,其中,每次决策为一个sub-step,每一步个sub-step获得的奖励对于第二智能体的更新是需要折扣因子的,具体表示为:
24、gss=rss+1+γ2rss+2+...=∑γ2irss+i+1
25、式中,γ2是折扣因子,且0≤γ2≤1,在sub-step的第ss步采用的策略获得的奖励值是rss,则后续奖励是rss+1,rss+2,价值函数vπ(s)是在采用策略π时,累积回报在状态s处的期望值,具体表示为:
26、vπ(s)=e{gss|sss=s}=eπ{∑γ2nrss+n+1|sss=s}
27、其中,策略π需要满足以下条件:
28、argamaxvπ(s)=argamaxeσπ{r2nrss+n+1|sss=s}
29、
30、在一些实施例中,根据第一动作价值和第二动作价值,得到待调度传感器的优选动作价值,包括:
31、利用贪婪算法根据第一动作价值和第二动作价值,确定各第一智能体和第二智能体输出的最大动作价值,得到待调度传感器的优选动作价值,具体公式为:
32、
33、其中,最优动作价值与任一第一智能体和第二智能体之间满足以下条件:
34、
35、
36、式中,qtot代表优选动作价值;
37、q1,i代表任一第一智能体;
38、q2代表第二智能体。
39、在一些实施例中,得到待调度传感器的优选动作价值,包括:
40、将第一动作价值和第二动作价值输入一个权重为正值的神经网络,神经网络输出优选动作价值。
41、在一些实施例中,多智能体决策模型包括至少两个第一智能体、至少一个第二智能体和贪婪算法模型;方法还包括训练多智能体决策模型,
42、通过最小化损失函数训练每一步第一智能体和第二智能体,其中损失函数是:
43、
44、式中,表示多智能体强化学习模型的目标状态值,表示为:
45、
46、γtot是折扣因子,表示后续状态的价值在目前状态的现值比例;
47、是网络训练过程中的目标网络;
48、是下一时刻的系统状态集;
49、是下一时刻状态下,每个智能体选取最优动作下的动作值函数;
50、
51、通过网络与环境交互,获得经验,然后用经验训练网络。
52、第二方面,提供了一种基于强化学习的传感器采样调度装置,包括:
53、构建单元,用于根据待调度传感器的分类构建多智能体决策模型,其中,待调度传感器包括第一传感器和第二传感器,多智能体模型包括第一智能体和第二智能体,第一智能体与第一传感器一一对应,第二智能体与多个第二传感器对应;
54、第一智能体单元,用于将各第一传感器的状态和动作输入与各第一传感器对应的第一智能体,第一智能体输出第一传感器动作对应的第一动作价值;
55、第二智能体单元,用于将各第二传感器的状态和动作依次输入第二智能体,第二智能体依次输出各第二传感器动作对应的第二动作价值;其中,当前第二传感器的状态包括输入第二智能体的顺序排序在当前第二传感器之前的各其他第二传感器的动作;当前第二类传感为当前利用第二智能体运算第二动作价值的第二类传感;
56、动作价值输出单元,用于利用贪婪算法根据第一动作价值和第二动作价值,得到待调度传感器的优选动作价值;
57、结果输出单元,用于根据优选动作价值确定待调度传感器的采样调度方法。
58、第三方面,提供了一种计算机设备,包括存储器、处理器以及存储在存储器中并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述基于强化学习的传感器采样调度方法的步骤。
59、第四方面,提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现上述基于强化学习的传感器采样调度方法的步骤。
60、上述基于强化学习的传感器采样调度方法、装置、计算机设备及存储介质所实现的方案中,可以通过根据待调度传感器的分类构建多智能体决策模型;将各第一传感器的状态和动作输入与各第一传感器对应的第一智能体,第一智能体输出第一传感器动作对应的第一动作价值;将各第二传感器的状态和动作依次输入第二智能体,第二智能体依次输出各第二传感器动作对应的第二动作价值;其中,当前第二传感器的状态包括输入第二智能体的顺序排序在当前第二传感器之前的各其他第二传感器的动作;当前第二类传感为当前利用第二智能体运算第二动作价值的第二类传感;根据第一动作价值和第二动作价值,得到待调度传感器的优选动作价值;根据优选动作价值确定待调度传感器的采样调度方法。在本发明中,契合工业应用发展趋势,有效提升工业物联网中应用以来信息的新鲜度,优化了工业应用的准确性。
- 还没有人留言评论。精彩留言会获得点赞!