一种现场可编程门阵列及通信方法与流程
本申请涉及集成电路技术领域,特别涉及一种现场可编程门阵列及通信方法。
背景技术:
现场可编程门阵列(FPGA,Field Programmable Gate Array)是在可编程逻辑阵列(PLA,Programmable Logic Array)、门阵列逻辑GAL(Gate Array Logic)、复杂可编程逻辑器件(CPLD,Complex Programmable Logic Device)等可编程器件的基础上进一步发展的产物。FPGA作为专用集成电路(ASIC,Application Specific Integrated Circuit)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。FPGA是当今数字系统设计的主要硬件平台,其主要特点就是完全由用户通过软件进行配置和编程,从而完成某种特定的功能,且可以反复擦写。因此,FPGA应用地越来越广泛。
FPGA芯片结构目前主要是基于查找表(LUT,Look-Up-Table)技术,并且整合了常用功能(例如RAM、时钟管理和DSP)的硬核(ASIC型)模块。
由于基于LUT的FPGA具有很高的集成度,其器件密度从数万门到数千万门不等,可以完成极其复杂的时序与逻辑组合电路功能。其主要的组成部分为:可编程输入输出单元、基本可编程逻辑单元、完整的时钟管理、嵌入式块RAM、丰富的布线资源、内嵌的底层功能单元和内嵌专用硬件模块。
参见图1,该图为现有技术中的FPGA的应用示意图。
由于FPGA的规模已经达到兆(K*K)级别的逻辑元件(LE,Logic Element),FPGA能完成的功能也极其丰富和复杂。因此,FPGA开发会划分成很多个功能模块(Module),每一个功能模块完成一部分相对比较独立的功能,实现整个芯片的一部分电路;而功能模块之间需要通过接口来实现相互传递数据和信息。
例如图1的一个应用实例中,可能用到十个功能模块(功能模块0-功能模块10),很多功能模块之间存在通信,以功能模块0为例,功能模块0与功能模块1、功能模块3和功能模块5之间均存在通信。
功能模块之间进行通信时需要通过定义的接口进行通信,由于数据流量较大,数据位宽有的会比较大,如果某些功能模块与较多功能模块进行通信,则需要定义多个通信接口,这样通过不同的通信接口与不同的功能模块相通信。
各个功能模块采用LUT和触发器完成电路功能,各个电路通过FPGA的布线实现互联。
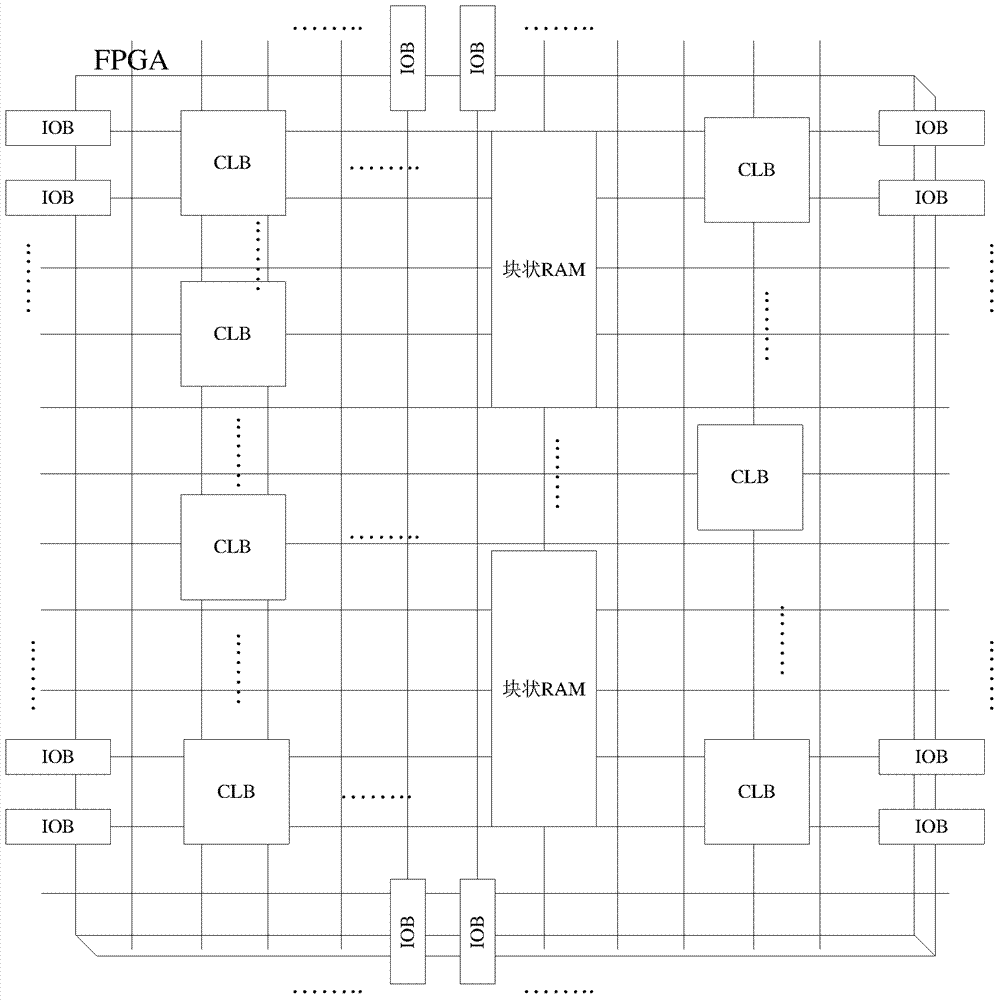
参见图2,该图为现有技术中FPGA的内部结构示意图。
其中,横线和竖线表示布线资源,可以通过编程完成各个可配置逻辑模块(CLB,Configurable Logic Block)的输入和输出的互联。图2中的FPGA与外界连接是靠输入输出模块(IOB,Input Out Block)。
一些分布比较靠近的CLB一起实现一个功能模块的电路,另外一些靠近的CLB一起实现另外一个功能模块的电路。而功能模块之间的通信接口和互联,可以通过一些CLB和布线来完成。
参见图3,该图为现有技术中功能模块在FPGA上的映射示意图。
图3中包括三个功能模块,分别是功能模块0、功能模块3和功能模块8。
每个功能模块由靠近的多个CLB组成(图3中的小方格),各个模块之间通过布线连接(图3中的箭头)。
图3中的功能模块0、功能模块3、功能模块8分别被部署在FPGA的上左、右中、下左位置,功能模块0和功能模块3之间有接口需要互联和通信,同样功能模块3和功能模块8之间也有接口需要互联和通信。
由此可见,功能模块之间的互联和通信,需要通过多级的布线级联起来才能实现,而多级的级联将占用中间节点的布线资源和CLB资源。这样通过的CLB和布线较多时,距离较远,将造成延时较大。对于40nm器件一级跳转可能需要0.7ns-1ns,如果距离较远,那么布线延迟达到10ns以上,逻辑很难运行到频率100MHz以上。另一方面,资源利用率低,造成整体性能较低。同时,FPGA的布线资源是宝贵而有限的,如果出现局部布线资源不够,则将导致整个设计布线不成功或者需要绕到较远的地方借用布线资源。
因此,本领域技术人员需要提供一种FPGA,能够解决目前FPGA中延迟大、性能差的问题。
申请内容
为了解决上述技术问题,本申请实施例提供了一种FPGA及通信方法,能够解决现有的FPGA延迟较大、整体性能较差的问题。
本申请实施例公开了如下技术方案:
第一方面,提供一种现场可编程门阵列FPGA,该FPGA中内嵌至少一个用于通信互联的专用集成电路ASIC化的硬核;
所述ASIC化的硬核包括:高速交换互联单元和至少一个站点;
各个所述站点与所述高速交换互联单元连接;
所述站点,用于FPGA内各个功能模块与所述ASIC化的硬核的数据传递;
所述高速交换互联单元,用于实现各个所述站点之间的数据传递。
在第一方面的第一种可能的实现方式中,所述站点的数目和功能模块的数目相等,一个所述站点与连接一个所述功能模块;
或,
每个所述站点对应多个所述功能模块,每个所述站点与对应的多个功能模块连接。
结合第一方面及上述任一种可能的实现方式中,在第二种可能的实现方式中,当所述站点的数目与功能模块的数目相等时,每个所述站点配置为与对应的功能模块保持一致的时钟频率、数据位宽和时序;
所述高速交换互联单元不可编程。
结合第一方面及上述任一种可能的实现方式中,在第三种可能的实现方式中,所述ASIC化的硬核的片内互联总线协议包括以下中的至少一种:AVALON、Wishbone、CoreConnect、AMBA。
结合第一方面及上述任一种可能的实现方式中,在第四种可能的实现方式中,所述ASIC化的硬核以纵横式交换矩阵均匀分布在FPGA中。
结合第一方面及上述任一种可能的实现方式中,在第五种可能的实现方式中,所述ASIC化的硬核采用一个AXI总线协议互联的硬核;所述AXI总线协议属于所述AMBA中的一种;
每个逻辑组中包括至少一个发起方站点和至少一个被动接收方站点。
结合第一方面及上述任一种可能的实现方式中,在第六种可能的实现方式中,所述ASIC化的硬核采用两个或两个以上AXI总线协议互联的硬核;
各个所述AXI总线协议互联的硬核之间通过AXI桥进行通信;
每个逻辑组中包括至少一个发起方站点和至少一个被动接收方站点。
结合第一方面及上述任一种可能的实现方式中,在第七种可能的实现方式中,各个所述AXI总线协议互联的硬核包括相同数目的发起方站点和相同数目的被动接收方站点,具有相同的位宽和频率。
结合第一方面及上述任一种可能的实现方式中,在第八种可能的实现方式中,各个所述AXI总线协议互联的硬核包括不同数目的发起方站点和不同数目的被动接收方站点,以及具有不同的位宽和不同的频率。
结合第一方面及上述任一种可能的实现方式中,在第九种可能的实现方式中,部分所述AXI总线协议互联的硬核包括相同数目的发起方站点和相同数目的被动接收方站点,具有相同的位宽和频率;其余的所述AXI总线协议互联的硬核包括不同数目的发起方站点和不同数目的被动接收方站点,以及具有不同的位宽和不同的频率。
结合第一方面及上述任一种可能的实现方式中,在第十种可能的实现方式中,所述高速交换互联单元以环路总线均匀分布在FPGA中。
第二方面,提供一种基于FPGA的数据通信方法,该FPGA中内嵌至少一个用于通信互联的专用集成电路ASIC化的硬核;所述ASIC化的硬核包括:高速交换互联单元和至少一个站点;各个所述站点与所述高速交换互联单元连接;所述站点实现FPGA内各个功能模块与所述ASIC化的硬核的数据传递;所述高速交换互联单元实现各个所述站点之间的数据传递;包括以下步骤:
高速交换互联单元通过数据源功能模块对应的站点接收数据源功能模块发送的数据;所述数据中携带目的功能模块的信息;
所述高速交换互联单元根据所述目的功能模块的信息通过目的功能模块对应的站点将接收的所述数据发送给目的功能模块。
在第二方面的第一种可能的实现方式中,
所述站点的数目和功能模块的数目相等,一个所述站点与连接一个所述功能模块;
或,
每个所述站点对应多个所述功能模块,每个所述站点与对应的多个功能模块连接。
结合第二方面及上述任一种可能的实现方式中,在第二种可能的实现方式中,当所述站点的数目与功能模块的数目相等时,每个所述站点配置为与对应的功能模块保持一致的时钟频率、数据位宽和时序;
所述高速交换互联单元不可编程。
结合第二方面及上述任一种可能的实现方式中,在第三种可能的实现方式中,所述ASIC化的硬核的片内互联总线协议包括以下中的至少一种:AVALON、Wishbone、CoreConnect、AMBA。
结合第二方面及上述任一种可能的实现方式中,在第四种可能的实现方式中,所述ASIC化的硬核以纵横式交换矩阵均匀分布在FPGA中。
由上述实施例可以看出,与现有技术相比,本申请具有如下优点:
本申请提供的FPGA中内嵌ASIC化的硬核,并且该ASIC化的硬核均匀分布在FPGA中,这样可以方便各个功能模块就近与其进行数据交换,从而降低时间延迟。由于ASIC化的硬核包括高速交换互联单元和至少一个站点,站点均匀分布,这样方便功能模块与就近的站点进行连接,源功能模块将数据发给站点,站点将数据发给高速交换互联单元,高速交换互联单元将数据通过与目的功能模块连接的站点将数据发给目的功能模块。从而完成源功能模块与目的功能模块之间的数据传递。本实施例提供的FPGA可以实现数据的快速传递,并且由于ASIC化的硬核具有较高的性能,因此可以满足高性能FPGA的要求。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是现有技术中的FPGA的应用示意图;
图2是现有技术中FPGA的内部结构图;
图3是现有技术中功能模块在FPGA上的映射示意图;
图4是本申请提供的FPGA实施例一示意图;
图5是本申请提供的FPGA实施例二示意图;
图6a是本申请提供的一种功能模块在FPGA中的示意图;
图6b是本申请提供的另一种功能模块在FPGA中的示意图;
图7是本申请提供的FPGA实施例三示意图;
图8a是本申请提供的FPGA实施例四示意图;
图8b是本申请提供的FPGA实施例五示意图;
图9是本申请提供的FPGA实施例六示意图;
图10是本申请提供的FPGA实施例七示意图;
图11是本申请提供的基于FPGA的数据通信方法实施例一示意图;
图12是本申请提供的基于FPGA的数据通信方法信令图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
为使本申请的上述目的、特征和优点能够更加明显易懂,下面结合附图对本申请的具体实施方式做详细的说明。
实施例一:
参见图4,该图为本申请提供的FPGA实施例一示意图。
本实施例提供的FPGA中内嵌用于通信互联的专用集成电路ASIC化的硬核;
由于ASIC化的硬核可以满足高性能的要求,频率可以运行到1GHz以上,具备提供Tbps带宽的能力。
ASIC化的硬核均匀分布在FPGA中,这样可以保证FPGA中各个功能模块能够就近地与ASIC化的硬核进行数据传递,这样可以降低时间延迟。
需要说明的是,ASIC化的硬核均匀分布在FPGA中是为了实现FPGA中的各个功能模块均能够就近地与ASIC化的硬核进行连接。
所述ASIC化的硬核包括:高速交换互联单元100和至少一个站点I/F;
所有站点I/F均匀分布;这样可以使各个功能模块周围尽量均设置了站点,从而使功能模块可以与空间距离较近的站点I/F进行连接;从而降低数据传递时的时间延迟。
各个所述站点I/F和高速交换互联单元100连接;
所述站点I/F,用于FPGA内各个功能模块与所述ASIC化的硬核的数据传递;
所述高速交换互联单元100,用于实现所有所述站点之间的数据传递。
可以理解的是,在实体上,FPGA中的各个功能模块是与站点I/F进行连接的,而每个站点I/F是与高速交换互联单元100进行连接的,因此,一个功能模块可以通过站点I/F和高速交换互联单元100将数据转发给另一个功能模块,从而实现各个功能模块之间数据的传递。
由于ASIC化的硬核可以满足高性能的要求,频率可以运行到1GHz以上,具备提供Tbps带宽的能力。
本实施例提供的FPGA中内嵌ASIC化的硬核,并且该ASIC化的硬核均匀分布在FPGA中,这样可以方便各个功能模块就近与其进行数据交换,从而降低时间延迟。由于ASIC化的硬核包括高速交换互联单元和至少一个站点,站点均匀分布,这样方便功能模块与就近的站点进行连接,源功能模块将数据发给站点,站点将数据发给高速交换互联单元,高速交换互联单元将数据通过与目的功能模块连接的站点将数据发给目的功能模块。从而完成源功能模块与目的功能模块之间的数据传递。本实施例提供的FPGA可以实现数据的快速传递,并且由于ASIC化的硬核具有较高的性能,因此可以满足高性能FPGA的要求。
实施例二:
参见图5,该图为本申请提供的FPGA实施例二示意图。
下面以两个功能模块进行数据交换为例详细说明本申请实施例提供的FPGA的工作过程。
从图5中可以看出,其中,功能模块0位于FPGA的左上角,功能模块8位于FPGA的右下角;两个功能模块距离较远,其中的功能模块0为源数据模块,功能模块8为目的功能模块,即功能模块0向功能模块8发送数据。
可以理解的是,源功能模块和目的功能模块是相对的,功能模块0也可以作为目的功能模块,功能模块8也可以作为源功能模块。
功能模块0和功能模块8均是虚框内若干个CLB组成的。
需要说明的是,站点与功能模块进行连接时可以采用就近原则,即在空间布局上功能模块优先与自己空间距离最近的站点进行连接。
本实施例中以一个站点与一个功能模块进行连接为例进行介绍,由于这样一对一的设置实现比较简单,即有几个功能模块,就对应设置几个站点。每个功能模块与空间距离最近的站点进行连接即可。
例如,图5中的功能模块0与站点I/F0进行连接,功能模块8与站点I/F8进行连接。
首先,功能模块0通过站点I/F0将数据发送给高速交换互联单元100,高速交换互联单元100再通过站点I/F8将数据发送给功能模块8。
需要说明的是,功能模块0发送的数据内携带功能模块8的信息,因此,高速交换互联单元100可以从数据中携带的信息判断来需要将数据发送给与功能模块8相连接的站点I/F8。
可以理解的是,数据内携带的信息可以为功能模块的ID,也可以采用地址映射。因为某一段地址属于某一个功能模块。
从图5中可以看出,本实施例中采用ASIC化的硬核以后,两个功能模块之间通过ASIC化的硬核进行数据传递即可,不需要经过任何的CLB,由于ASIC化的硬核中的高速交换互联单元100速度很快,因此可以降低时间的延迟。
本实施例中是以一个站点对应一个功能模块来说明的是,可以理解的是,当FPGA中的功能模块个数很多,而站点的个数较少时,可以设置一个站点对应多个功能模块,这样控制上比一个站点对应一个功能模块的略微复杂。但是可以实现资源的充分利用,节省成本。每个站点按照就近原则与对应的多个功能模块连接。
一个站点对应多个功能模块的工作原理与一个站点对应一个功能模块的工作原理是相同的,在此不再赘述。
另外,本实施例中仅是以2个功能模块为例进行介绍的,可以理解的是,FPGA中可以包括多个功能模块,具体可以根据实际需要来设置,并且功能模块的划分可以根据具体电路的不同而不同。下面介绍两种不同功能模块的划分。
参见图6a,该图为本申请提供的一种功能模块在FPGA中的示意图。
图6a中包括六个功能模块,分别是功能模块0-功能模块5;
每个功能模块使用一个站点I/F与高速交换互联单元100进行连接。
需要说明的是,每个可以站点配置为与对应的功能模块保持一致的时钟频率、数据位宽和时序;
例如,功能模块0传输的数据位宽为512位、时钟频率150MHz;因此,需要功能模块0配置数据为512位、150MHz。功能模块4传输的数据为256位、300MHz;因此,需要功能模块0配置数据为256位、300MHz。这样可以保证功能模块与站点之间进行顺利地数据传输。
可以理解的是,同一个FPGA中的各个站点可以配置为同样的位宽和时钟频率,也可以各个站点配置不同的时钟频率,这个取决于具体的功能模块的要求。
由此可见,本申请实施例提供的站点可以通过编程设置时钟频率、数据位宽和时序;这样可使应用时更加方便,以适应各个不同功能模块的不同需求。
另外,需要说明的是,各个功能模块之间的一些简单信号的传递,还可以通过现有技术中的传统方式来进行交互。例如,功能模块0与其他五个功能模块的简单通信,仍然可以通过图中所示的箭头线完成通信。
一般情况下,所述高速交换互联单元100不可编程,即进行参数的设置和配置。这是为了使ASIC化的硬核的性能更高,提高其应用的通用性,而且使用时更加方便。
由于FPGA中除了ASIC化的硬核以外的部分,是可编程逻辑部分,因此,各个功能模块的划分还可以为其他形态和组合,例如还可以为图6b所示。
参见图6b,该图为本申请提供的另一种功能模块在FPGA中的示意图。
在图6b中各个功能模块的划分与图6a中有所区别。
功能模块0配置为786位、150MHz;
功能模块2配置为1024位、200MHz;
功能模块4配置为288位、333MHz。
需要说明的是,本申请实施例提供的ASIC化的硬核,可以采用FPGA厂商自定义的片内互联总线协议,也可以采用目前业界常用的已经成熟的片内互联总线协议,包括但不限于:AVALON、Wishbone、CoreConnect、AMBA等。
可以理解的是,一个FPGA内,可以仅使用一种片内互联总线协议,也可以同时采用多种片内互联总线协议。例如,FPGA中一个I/F使用AVALON、另一个I/F使用Wishbone。
优选地,本申请实施例提供的高速交换互联单元以纵横式交换矩阵(Cross Bar)均匀分布在FPGA中,或者以环路总线(Ring Bus)均匀分布在FPGA中。
其中,图4和图5所示的是纵横式交换矩阵。
下面结合实施例介绍高速交换互联单元以纵横式交换矩阵分布时的具体实现,其中的ASIC化的硬核采用的片内互联总线协议以AXI-Interconnection为例进行介绍。
实施例三:
参见图7,该图为本申请提供的FPGA实施例三示意图。
本实施例中,ASIC化的硬核采用一个AXI总线协议互联的硬核;即其中的硬核采用AXI互联矩阵。
AXI总线协议属于AMBA中的一个子集。
在FPGA内直接硬化一个AXI-互联(AXI-Interconnection)的硬IP核,这个业界已有成熟的IP核(目前有两种主要的FPGA,Xilinx和Altera都有对应的软核Soft Core,只需要将其硬化,且合理布局I/F到硅片die的位置即可),风险低,性能很高(运行频率轻易达到GHz的级别),并且能够基本不需要任何修改便可以与目前大部分标准的IP核(core)对接互联。
每个逻辑组(Logic Cell Bank)中对应至少一个发起方(Master)站点I/F和一个被动接收方(Slave)站点I/F。需要说明的是,一个Master和一个Slave对外来说作为一个站点,即一个站点既包括Master,也包括Slave,既可以作为发起方发送数据,也可以作为被动接收方接收数据。这样可以尽量保证站点在FPGA内均匀分布。
本实施例中是以每个逻辑组对应一个站点为例进行介绍的,即一个逻辑模块连接一个站点,可以理解的是,一个逻辑组也可以对应多个站点。
其中逻辑组是一些CLB的组合。
可以理解的是,发起方站点就是主动发送数据的一方站点,而被动接收方站点就是被动接收数据的一方站点。
其中,发起方(Master)在图7中以M表示,被动接收方(Slave)在图7中以S表示。
本实施例中的可以包括16个M和16个S。
需要说明的是,M和S的个数可以是不同的,一般M比较少,S比较多。因为很多功能模块只需要被动接收数据即可,或者被动地等待M来读取数据。
当然,为了方便,也可以设置M和S的个数是相同的,即是成对出现的。并且M和S的具体数目可以根据实际需要来选择,不局限于本实施例中的各取16个。本实施例提供的FPGA具备16Master和16Slave并行同时数据通信和交换的能力,提供足够多的功能模块(足够带宽)的数据通信和交互。
图7中的DDR_CTRL是FPGA与外挂的DDR芯片的接口;高速接口IP核(core)也是FPGA与外挂的芯片进行通信的。串-并转换接口也是FPGA与外界进行通信的接口。
实施例四:
参见图8a,该图为本申请提供的FPGA实施例四示意图。
本实施例提供的FPGA与实施例三不同的是,实施例三中仅采用一个AXI-Interconnection;而本实施例中采用2个AXI-Interconnection,这AXI-Interconnection之间通过AXI桥(AXI-Bridge)联通从而实现通信互联硬核。
从图8a中可以看出,2个AXI-Interconnection均由AXI互联矩阵实现,每个AXI互联矩阵包括8个M和8个S。即,2个AXI互联矩阵中的M和S的个数相同。
可以理解的是,2个AXI互联矩阵中的M和S的个数也可以不同,例如,其中1个AXI互联矩阵中M和S的个数为16个,另1个AXI互联矩阵中M和S的个数为8个。
本实施例提供的FPGA相对于实施例三提供的FPGA的优点是:难度较低、硬件布局和布线难度均可以降低,同时成本也相应降低。
本实施例提供的FPGA相对于实施例三提供的FPGA的缺点是:只能实现2个AXI互联矩阵内部站点连接的功能模块之间同时数据传递,但是2个AXI互联矩阵之间的站点连接的功能模块之间数据的传递需要AXI桥来实现,这样只能通过时分复用来实现,因此,这种FPGA相对于实施例三提供的FPGA性能上有所降低,例如,传递数据的带宽(或者吞吐率)可能降低,例如两个功能模块同一段时间内均需要通过桥来实现数据交换,那么只能两个功能模块共享这个桥所提供的带宽。
本实施例中FPGA中是以2个AXI互联矩阵为例来介绍的,可以理解的是,也可以包括3个AXI互联矩阵如图8b所示,各个AXI互联矩阵之间通过AXI桥来连接;当然也可以包括更多个AXI互联矩阵,多个AXI互联矩阵之间用AXI桥进行连接即可,工作原理与本实施例中的相同,在此不再赘述。
另外,本实施例中的2个AXI互联矩阵的性能相同,下面介绍一种FPGA中的AXI互联矩阵性能不相同的情况。性能不同是为了适应具体的需要,例如在某些应用场合,一个FPGA中只有少数的功能模块需要高性能的数据传递,例如需要更高的带宽等,这样为了节省成本,可以设置一个AXI互联矩阵具有高性能,以匹配这些高性能要求的功能模块,其他普通的功能模块可以使用普通性能的AXI互联矩阵来实现。
下面结合附图来介绍这种内部AXI互联矩阵性能不一样的FPGA。
实施例六:
参见图9,该图为本申请提供的FPGA实施例六示意图。
本实施例提供的FPGA包括2个AXI互联矩阵,其中1个AXI互联矩阵是正常模式AXI互联矩阵,1个AXI互联矩阵为高性能模式AXI互联矩阵;
高性能模式AXI互联矩阵的位宽和频率均比正常模式AXI互联矩阵的高。
本实施例中,正常模式AXI互联矩阵包括16个M和16个S;高性能模式AXI互联矩阵包括8个M和8个S。
可以理解的是,正常模式AXI互联矩阵和高性能模式AXI互联矩阵中的M和S的具体数目可以根据实际需要来选择,本申请实施例中不做具体限定,仅是举例进行说明而已。
需要说明的是,本实施例中是以1个高性能模式AXI互联矩阵和1个正常模式AXI互联矩阵为例进行介绍的。可以理解的是,也可以包括多个高性能模式AXI互联矩阵和/或多个正常模式AXI互联矩阵。各个AXI互联矩阵之间通过AXI桥进行连接。
以上实施例均是以FPGA中的高速交换互联单元采用纵横式交换矩阵均匀分布在FPGA中,本申请还提供一种高速交换互联单元采用环路总线(Ring Bus)的方式均匀分布在FPGA中。
实施例七:
参见图10,该图为本申请提供的FPGA实施例七示意图。
本实施例提供的FPGA中的高速交换互联单元采用环路总线(Ring Bus)的方式均匀分布在FPGA中。
由于环路总线是一个闭合的环路,因此,可以更加均匀地分布在FPGA中,环路总线上的站点也可以更加均匀地分布,这样可以更方便使各个功能模块就近地与环路总线上的站点进行连接。
需要说明的是,在图10所示的FPGA中,环路总线上也可以设置成对出现的M和S,这样可以提高使用的方便性,使制造也更加简单;当然也可以设置M和S的数目不相同,例如,设置M的个数大于M的个数,这个可以根据实际需要来选择。
在环路总线架构中,各个站点之间能够一级一级将数据传递到目的地,并且可以双向传递和并发进行。双向传递的优点是:可以降低时间的延迟。例如只提供顺时钟方向的数据传递,那么功能模块需要与前一个节点通信,就需要绕整个芯片一圈。但是如果采用双向传递,则只需逆时钟方向传递一个节点即可。
并发进行的优点是:双向传递并发,相当于有两条数据传递路径,并且两条路径都可以提供一定带宽,这样就达到了带宽增倍。
图10中的FPGA中的DDR_CTRL、高速接口IP核(core)以及串-并转换接口与图7对应的实施例中的作用相同,在此不再赘述。
综上,以上各个实施例提供的FPGA,通过在FPGA中内嵌ASIC化的硬核,各个功能模块可以就近接入,从而可以有效降低数据传递的延迟时间,提高了整个FPGA的性能。
基于以上实施例提供的一种FPGA,本申请实施例还提供了一种基于以上实施例提供的FPGA的一种数据通信方法,下面结合附图进行具体介绍。
方法实施例一:
参见图11,该图为本申请提供的基于FPGA的一种数据通信方法实施例一流程图。
本实施例提供的基于FPGA的数据通信方法,包括以下步骤:
S1101:高速交换互联单元通过数据源功能模块对应的站点接收数据源功能模块发送的数据;所述数据中携带目的功能模块的信息;
需要说明的是,数据源功能模块就是发送数据的一方,目的功能模块就是接收数据的一方,可以理解的是,每个功能模块即可以作为数据源功能模块也可以作为目的功能模块。
由于数据源功能模块发送的数据中携带目的功能的信息,因此,高速交换互联单元可以根据所述信息找到目的功能模块对应的站点是哪一个,这样通过目的功能模块对应的站点可以将数据转发给目的功能模块。
需要说明的是,当采用的片内互联总线协议确定了以后,就确定了目的功能模块的信息的内容,因为片内互联总线协议中规范了信息的内容。本申请实施例中目的功能模块的信息可以为功能模块的ID,也可以为地址映射,因为某一段地址属于某一个功能模块,由地址可以找到该地址对应的是哪个功能模块。
S1102:所述高速交换互联单元根据所述目的功能模块的信息通过目的功能模块对应的站点将接收的所述数据发送给目的功能模块。
本实施例提供的方法,由于FPGA内嵌了ASIC化的硬核,ASIC化的硬核包括高速交换互联单元和至少一个站点。数据源功能模块可以通过所述高速交换互联单元将数据发送给目的功能模块,因为数据源功能模块发送的数据中携带目的功能模块的信息,因此,高速交换互联单元可以根据所述信息确定出目的功能模块对应连接的站点。由于每个功能就近与站点进行连接,因此,该方法可以有效降低数据传递的延迟时间,提高整个FPGA的性能。
方法实施例二:
参见图12,该图为本申请提供的基于FPGA的一种数据通信方法信令图。
所述站点的数目与功能模块的数目相同,每个所述站点与一个所述功能模块连接;
或,
每个所述站点对应多个所述功能模块,每个所述站点与对应的多个功能模块连接。
本实施例中以一个站点对应一个功能模块为例进行介绍,这样控制比较简单,实现容易。
下面以两个功能模块之间的数据传递为例进行介绍,分别是数据源功能模块和目的功能模块。
S1:数据源功能模块在需要发送的数据中添加目的功能模块的信息;
S2:将添加完信息后的数据发送给数据源功能模块连接的站点;
S3:数据源功能模块连接的站点将接收的数据发送给高速交换互联单元;
S4:高速交换互联单元根据信息将数据发送给目的功能模块连接的站点;
S5:目的功能模块连接的站点将数据发送给目的功能模块。
本实施例中详细介绍了如何利用以上实施例提供的FPGA实现数据传递。
所述站点的数目和功能模块的数目相等,一个所述站点与连接一个所述功能模块;
或,
每个所述站点对应多个所述功能模块,每个所述站点与对应的多个功能模块连接。
当所述站点的数目与功能模块的数目相等时,每个所述站点配置为与对应的功能模块保持一致的时钟频率、数据位宽和时序;
所述高速交换互联单元不可编程。
所述ASIC化的硬核的片内互联总线协议包括以下中的至少一种:AVALON、Wishbone、CoreConnect、AMBA。
所述ASIC化的硬核以纵横式交换矩阵均匀分布在FPGA中。
以上所述,仅是本申请的较佳实施例而已,并非对本申请作任何形式上的限制。虽然本申请已以较佳实施例揭露如上,然而并非用以限定本申请。任何熟悉本领域的技术人员,在不脱离本申请技术方案范围情况下,都可利用上述揭示的方法和技术内容对本申请技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。因此,凡是未脱离本申请技术方案的内容,依据本申请的技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均仍属于本申请技术方案保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!