一种微博用户关联信息筛选方法及装置与流程
本发明涉及通信领域,尤其涉及一种微博用户关联信息筛选方法及装置。
背景技术:
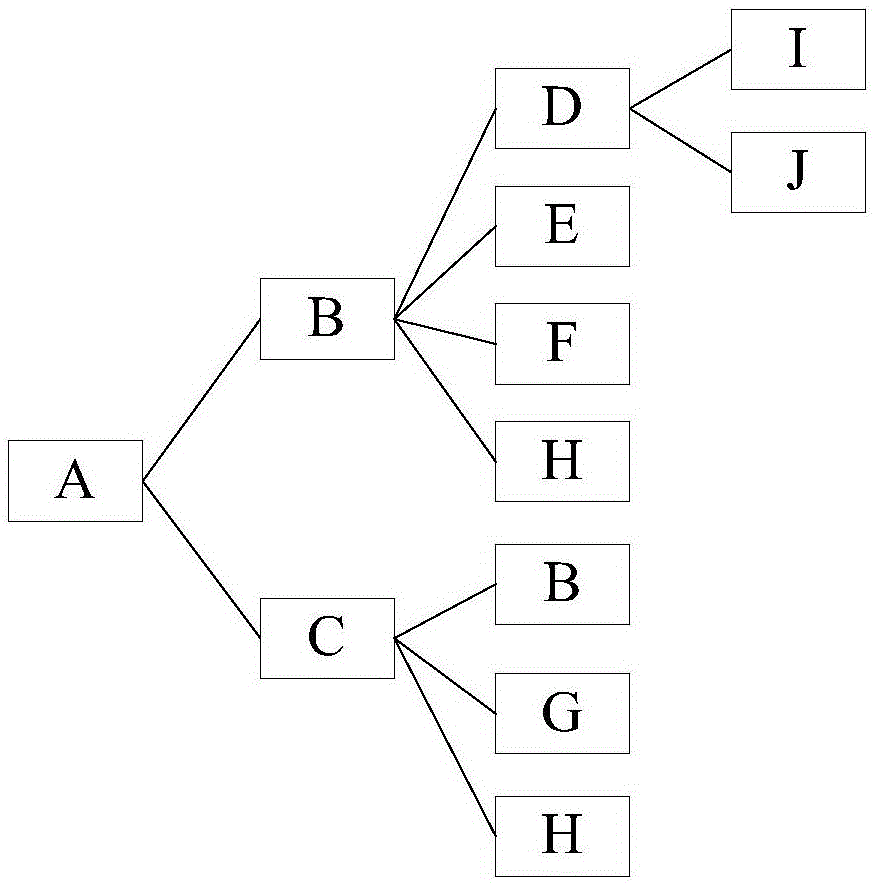
:基于Web2.0技术的诸多应用,正逐渐改变互联网用户的日常生活。微博,一种新的交流共享方式,自推出来就受到了广泛推崇,并在过去几年内,迅速吸引了亿万互联网用户。微博,即微型博客(MicroBlog)的简称,是一个基于用户关系信息分享、传播以及获取平台,是一种通过关注机制分享简短实时信息的广播式的社交网络平台。在微博平台上,用户既可以作为观众,在微博上浏览感兴趣的信息;也可以作为发布者,在微博上发布内容供别人浏览。微博服务的出现使用户可以随时使用方便的终端设备以简短的文字来分享新闻、图片、视频等各种信息,这种便捷有效的服务极大地丰富了人们的日常生活。微博之所以能够成为主流社交媒体,主要是因为它具有强大的用户实时交互性,在诸多用户行为中,“关注”行为是用户获取外部信息的重要手段,用户可以自由地关注任何其它用户并接收他们的微博,这种开放自由的风格使用户很容易就能够获取其感兴趣的各种信息。对于微博服务而言,通过挖掘关注关系,为用户推荐高质量的关注对象,并将推荐结果有区分地表现出来,可以提高微博对老用户的依赖性,增强微博对新用户的吸引力。因此,如何设计一个好的推荐方法建立牢固的用户关系、贴近用户需求成为微博服务的一个重点和难点。目前,微博用户推荐方法主流技术方案有两种,第一种为基于用户信息的推荐方式,通过考虑用户地理位置、IP信息、个人资料等注册信息进行相关推荐。第二种为基于关注传递性的推荐方式,例如,用户B关注用户A,则用户 C关注用户B,则可以将用户C推荐给用户A。大部分用户经常只转发微博,微博上的意见领袖只是少数人,由于大部分用户在获取热门微博的同时只是对其简单的转发,并无实际微博内容,因此,传统微博用户推荐方法会引起数据稀疏现象,即系统找到可以推荐的用户比较少,且并不符合需要推荐的用户的喜好,导致推荐效果不理想;传统微博用户推荐方法主要利用了一些显式信息来进行学习,例如地理位置和IP信息等,虽迅速有效,但其实每个用户的兴趣爱好并不是单一的,因此,传统方法并不能很好的针对用户的实际兴趣爱好分别进行用户推荐。总之,传统微博用户推荐方法会引起数据稀疏现象,且不能很好的针对用户的实际兴趣爱好分别进行用户推荐,会导致推荐效果不理想,进行用户推荐后,用户还要进行再次筛选,降低了系统推荐效率。技术实现要素:本发明实施例提供一种微博用户关联信息筛选方法及装置,用以解决现有技术中存在的数据稀疏的问题,以及推荐效果不理想,降低系统推荐效率的问题。本发明实施例提供的具体技术方案如下:第一方面,一种微博用户关联信息筛选方法,包括:根据预设的递归深度,获取当前用户的关联用户集合;对所述关联用户集合中的每一个关联用户的设定数目的信息内容提取特征项,并统计每一个特征项的频次,生成对应的特征向量;根据所述关联用户集合中的所有关联用户的关联关系,确定所述关联用户集合中的社区结构,以及确定每一个社区结构对应的主题;根据所述每一个关联用户对应的特征向量中的每一个特征项和所述每一个社区结构对应的主题,得到用户主题分布;根据所述用户主题分布,筛选出当前用户的目标关联用户。通过这种方法,得到的目标关联用户推荐给当前用户,该目标关联用户与当前用户的兴趣爱好一致,避免了现有技术中存在的数据稀疏的问题,以及推荐效果不理想,降低系统推荐效率的问题。结合第一方面,在第一种可能的实现方式中,根据预设的递归深度,获取当前用户的关联用户集合,包括:获取所述当前用户的直接关联用户;将与所述直接关联用户直接关联的用户作为递归深度为1的关联用户;以及将与所述递归深度为1的关联用户直接关联的用户作为递归深度为2的关联用户,直至得到递归深度为预设的递归深度的关联用户;对小于或等于所述预设的递归深度的所有关联用户进行消重处理,并将消重处理后的所有所述关联用户作为关联用户集合。通过这种方法,可以得到当前用户的预设递归深度的关联用户集合。结合第一方面,在第二种可能的实现方式中,对所述关联用户集合中的任意一个关联用户的任意一个信息内容提取特征项,并统计每一个特征项的频次,包括:判定所述任意一个信息内容中有词语时,对所述任意一个信息内容进行分词处理,将每一个词语作为一个特征项,并统计每一个词语对应的频次;判定所述任意一个信息内容有转发地址ID时,将所述转发ID作为特征项,并统计所述转发ID对应的频次。通过这种方法,可以准确的得到每个信息内容中的各个特征项。结合第一方面的第二种可能的实现方式,在第三种可能的实现方式中,对所述关联用户集合中的任意一个关联用户的设定数目的信息内容提取特征项,并统计每一个特征项的频次,生成对应的特征向量,包括:将所述任意一个关联用户的设定数目的信息内容中每一个特征项和对应的频次作为所述任意一个关联用户对应的特征向量。通过这种方法,可以准确的得到每个关联用户设定数目的信息内容中的特 征项向量。结合第一方面,在第四种可能的实现方式中,根据所述关联用户集合中的所有关联用户的关联关系,确定所述关联用户集合中的社区结构,包括:将每一个关联用户作为节点,根据所述每一个关联用户的关联关系,将所述每一个关联用户、与所述每一个关联用户直接关联的关联用户相连接,生成关联网络;根据所述关联网络中的节点,将所述关联网络分割为多个组;在多个组中筛选出组内节点间的连接大于设定数目的组,作为社区结构。通过这种方法,可以确定关联用户集合中的社区结构,进而确定每个社区结构对应一个主题。结合第一方面,在第五种可能的实现方式中,根据所述每一个关联用户对应的特征向量中的每一个特征项和所述每一个社区结构对应的主题,得到用户主题分布,包括:针对每一个关联用户对应的特征向量中的每一个特征项,在所有社区结构对应的主题中生成一个随机主题;对每一个关联用户的特征向量中的每一个特征项的主题进行采样,得到采样参数,并生成用户主题分布和特征项主题分布;重新针对每一个关联用户对应的特征向量中的每一个特征项,在所有社区结构对应的主题除当前随机主题之外的主题中生成一个随机主题;根据上一次得到的采样参数、用户主题分布和特征项主题分布,对每一个关联用户的特征向量中的每一个特征项的主题进行采样,得到当前的采样参数,并生成当前的用户主题分布和特征项主题分布,重复采样预设的采样次数后,根据预设的采样总次数与所述预设的采样次数,对当前的用户主题分布进行均值处理,得到目标用户主题分布。通过这种方法,可以准确的得到用户的主题分布,进而根据主题分布推荐给当前用户。结合第一方面的第五种可能的实现方式,在第六种可能的实现方式中,运 用以下公式,得到采样参数:Wij=CijWT+βΣiCijWT+Lβ*CjkUT+αΣjCjkUT+Kα]]>其中,表示特征项i的主题为j的总个数,表示用户的特征向量k中包含主题j的总个数,α与β是预设的参数,L为所有特征向量中消重后的特征项数目,K为主题的数目。通过这种方法,根据采样参数可以对用户主题分布进行迭代,得到最准确的用户的主题分布。结合第一方面的第五种可能的实现方式,在第七种可能的实现方式中,运用以下公式,得到目标用户主题分布:CjkUT=Σ1Q-PCjkUTQ-P]]>其中,表示用户的特征向量k中包含主题j的总个数,Q为预设的采样总次数,P为预设的采样次数。通过这种方法,可以得到目标用户主题分布。结合第一方面或第一方面的任意一种可能的实现方式,在第八种可能的实现方式中,根据所述用户主题分布,筛选出当前用户的目标关联用户,包括:对所述用户主题分布进行归一化处理,得到针对每一个主题的每一个关联用户的概率值;分别针对每一个主题,对关联用户的概率值进行从大到小排序,选择前预设数目的概率值对应的关联用户作为目标关联用户。通过这种方法,可以筛选出与当前用户的兴趣爱好一致的关联用户推荐给当前用户。第二方面,一种微博用户关联信息筛选装置,包括:获取单元,用于根据预设的递归深度,获取当前用户的关联用户集合;生成单元,用于对所述关联用户集合中的每一个关联用户的设定数目的信 息内容提取特征项,并统计每一个特征项的频次,生成对应的特征向量;确定单元,用于根据所述关联用户集合中的所有关联用户的关联关系,确定所述关联用户集合中的社区结构,以及确定每一个社区结构对应的主题;计算单元,用于根据所述每一个关联用户对应的特征向量中的每一个特征项和所述每一个社区结构对应的主题,得到用户主题分布;筛选单元,用于根据所述用户主题分布,筛选出当前用户的目标关联用户。这样,得到的目标关联用户推荐给当前用户,该目标关联用户与当前用户的兴趣爱好一致,避免了现有技术中存在的数据稀疏的问题,以及推荐效果不理想,降低系统推荐效率的问题。结合第二方面,在第一种可能的实现方式中,所述获取单元根据预设的递归深度,获取当前用户的关联用户集合,包括:获取所述当前用户的直接关联用户;将与所述直接关联用户直接关联的用户作为递归深度为1的关联用户;以及将与所述递归深度为1的关联用户直接关联的用户作为递归深度为2的关联用户,直至得到递归深度为预设的递归深度的关联用户;对小于或等于所述预设的递归深度的所有关联用户进行消重处理,并将消重处理后的所有所述关联用户作为关联用户集合。这样,可以得到当前用户的预设递归深度的关联用户集合。结合第二方面,在第二种可能的实现方式中,所述生成单元对所述关联用户集合中的任意一个关联用户的任意一个信息内容提取特征项,并统计每一个特征项的频次,包括:判定所述任意一个信息内容中有词语时,对所述任意一个信息内容进行分词处理,将每一个词语作为一个特征项,并统计每一个词语对应的频次;判定所述任意一个信息内容有转发地址ID时,将所述转发ID作为特征项,并统计所述转发ID对应的频次。这样,可以准确的得到每个信息内容中的各个特征项。结合第二方面的第二种可能的实现方式,在第三种可能的实现方式中,所述生成单元对所述关联用户集合中的任意一个关联用户的设定数目的信息内容提取特征项,并统计每一个特征项的频次,生成对应的特征向量,包括:将所述任意一个关联用户的设定数目的信息内容中每一个特征项和对应的频次作为所述任意一个关联用户对应的特征向量。这样,可以准确的得到每个关联用户设定数目的信息内容中的特征项向量。结合第二方面,在第四种可能的实现方式中,所述确定单元根据所述关联用户集合中的所有关联用户的关联关系,确定所述关联用户集合中的社区结构,包括:将每一个关联用户作为节点,根据所述每一个关联用户的关联关系,将所述每一个关联用户、与所述每一个关联用户直接关联的关联用户相连接,生成关联网络;根据所述关联网络中的节点,将所述关联网络分割为多个组;在多个组中筛选出组内节点间的连接大于设定数目的组,作为社区结构。这样,可以确定关联用户集合中的社区结构,进而确定每个社区结构对应一个主题。结合第二方面,在第五种可能的实现方式中,所述计算单元根据所述每一个关联用户对应的特征向量中的每一个特征项和所述每一个社区结构对应的主题,得到用户主题分布,包括:针对每一个关联用户对应的特征向量中的每一个特征项,在所有社区结构对应的主题中生成一个随机主题;对每一个关联用户的特征向量中的每一个特征项的主题进行采样,得到采样参数,并生成用户主题分布和特征项主题分布;重新针对每一个关联用户对应的特征向量中的每一个特征项,在所有社区结构对应的主题除当前随机主题之外的主题中生成一个随机主题;根据上一次得到的采样参数、用户主题分布和特征项主题分布,对每一个关联用户的特征 向量中的每一个特征项的主题进行采样,得到当前的采样参数,并生成当前的用户主题分布和特征项主题分布,重复采样预设的采样次数后,根据预设的采样总次数与所述预设的采样次数,对当前的用户主题分布进行均值处理,得到目标用户主题分布。这样,可以准确的得到用户的主题分布,进而根据主题分布推荐给当前用户。结合第二方面的第五种可能的实现方式,在第六种可能的实现方式中,所述计算单元运用以下公式,得到采样参数:Wij=CijWT+βΣiCijWT+Lβ*CjkUT+αΣjCjkUT+Kα]]>其中,表示特征项i的主题为j的总个数,表示用户的特征向量k中包含主题j的总个数,α与β是预设的参数,L为所有特征向量中消重后的特征项数目,K为主题的数目。这样,根据采样参数可以对用户主题分布进行迭代,得到最准确的用户的主题分布。结合第二方面的第五种可能的实现方式,在第七种可能的实现方式中,所述计算单元运用以下公式,得到目标用户主题分布:CjkUT=Σ1Q-PCjkUTQ-P]]>其中,表示用户的特征向量k中包含主题j的总个数,Q为预设的采样总次数,P为预设的采样次数。这样,可以得到目标用户主题分布。结合第二方面或第二方面的任意一种可能的实现方式,在第八种可能的实现方式中,所述筛选单元根据所述用户主题分布,筛选出当前用户的目标关联用户,包括:对所述用户主题分布进行归一化处理,得到针对每一个主题的每一个关联 用户的概率值;分别针对每一个主题,对关联用户的概率值进行从大到小排序,选择前预设数目的概率值对应的关联用户作为目标关联用户。这样,可以筛选出与当前用户的兴趣爱好一致的关联用户推荐给当前用户。采用本发明技术方案,确定当前用户的关联用户集合、特征向量、以及社区结构和主题,根据每一个关联用户对应的特征向量中的每一个特征项和每一个社区结构对应的主题,得到用户主题分布,并基于用户主题分布,筛选出当前用户的目标关联用户,这样,得到的目标关联用户推荐给当前用户,该目标关联用户与当前用户的兴趣爱好一致,避免了现有技术中存在的数据稀疏的问题,以及推荐效果不理想,降低系统推荐效率的问题。附图说明图1为本发明实施例提供的一种微博用户关联信息筛选方法的具体流程图;图2为本发明实施例提供的关联用户的递归关联关系示意图;图3为本发明实施例提供的一种微博用户关联信息筛选装置结构图。具体实施方式采用本发明技术方案,能够有效地避免现有技术中存在的数据稀疏的问题,以及推荐效果不理想,降低系统推荐效率的问题。本发明实施例提供了一种微博用户关联信息筛选方法,下面结合附图对本发明优选的实施方式进行详细说明。参阅图1所示,本发明实施例提供的一种微博用户关联信息筛选方法的具体处理流程包括:步骤101:根据预设的递归深度,获取当前用户的关联用户集合。具体的,执行步骤101包括以下步骤:获取当前用户的直接关联用户;将与该直接关联用户直接关联的用户作为递归深度为1的关联用户;以及将与该递归深度为1的关联用户直接关联的用户作为递归深度为2的关联用户,直至得到递归深度为预设的递归深度的关联用户;对小于或等于预设的递归深度的所有关联用户进行消重处理,并将消重处理后的所有关联用户作为关联用户集合。在实际应用中,预设的递归深度可以根据需要设置其具体数值。参阅图2所示,预设的递归深度为2,当前用户为A,首先获取A的直接关联用户——B和C,则与B和C直接关联的用户为递归深度为1的关联用户,例如与B直接关联的用户D、E、F和H,以及与C直接关联的用户B、G和H,即用户D、E、F、H以及用户B、G、H均为递归深度为1的关联用户;然后确定与递归深度为1的关联用户直接关联的用户,即与D直接关联的用户I、J,作为递归深度为2的关联用户;对小于或等于预设的递归深度的所有关联用户进行消重处理,即对D、E、F、H、B、G、H、以及I、J进行消重处理,首先删除与A的直接关联用户B,然后个数大于1的用户只保留一个,如H,得到关联用户集合——【D、E、F、H、G、I、J】。步骤102:对关联用户集合中的每一个关联用户的设定数目的信息内容提取特征项,并统计每一个特征项的频次,生成所述对应的特征向量。首先,需要确定每一个关联用户的设定数目的信息内容,通常,选择每个关联用户最近的500或1000条微博,其中,这些微博分为3类,包括有微博内容、有微博内容且有转发、无微博内容但有转发。针对不同类别的微博,进行不同的处理。具体的,对关联用户集合中的任意一个关联用户的任意一个信息内容提取特征项,并统计每一个特征项的频次,包括:判定该任意一个信息内容中有词语时,对该任意一个信息内容进行分词处 理,将每一个词语作为一个特征项,并统计每一个词语对应的频次;判定该任意一个信息内容有转发地址ID时,将该转发ID作为特征项,并统计所述转发ID对应的频次。其中,对关联用户集合中的任意一个关联用户的设定数目的信息内容提取特征项,并统计每一个特征项的频次,生成对应的特征向量,包括:将该任意一个关联用户的设定数目的信息内容中每一个特征项和对应的频次作为该任意一个关联用户对应的特征向量。优选的,特征向量的格式为{特征项1特征项1对应的频次特征项2特征项2对应的频次……特征项N特征项N对应的频次}。步骤103:根据关联用户集合中的所有关联用户的关联关系,确定该关联用户集合中的社区结构,以及确定每一个社区结构对应的主题。具体的,执行步骤103包括以下步骤:将每一个关联用户作为节点,根据每一个关联用户的关联关系,将每一个关联用户、与每一个关联用户直接关联的关联用户相连接,生成关联网络;根据该关联网络中的节点,将该关联网络分割为多个组;在多个组中筛选出组内节点间的连接大于设定数目的组,作为社区结构。将关联用户集合中的每一个关联用户作为节点,并确定与每一个关联用户直接关联的关联用户,将每一个关联用户、与该每一个关联用户直接关联的关联用户连接,生成一个关联网络;将该关联网络分割为多个组,其中,组内连接较稠密,组间连接较稀少,在多个组中筛选出组内节点间的连接大于设定数目的组作为社区结构,由于社区结构中的节点间的连接数目较多,因此,社区结构中每一个关联用户属于同一个兴趣爱好的概率较大。每一个社区结构可以确定对应的主题,即该社区结构中的关联用户之间的兴趣爱好。步骤104:根据每一个关联用户对应的特征向量中的每一个特征项和每一个社区结构对应的主题,得到用户主题分布。具体的,执行步骤104包括以下步骤:针对每一个关联用户对应的特征向量中的每一个特征项,在所有社区结构对应的主题中生成一个随机主题;对每一个关联用户的特征向量中的每一个特征项的主题进行采样,得到采样参数,并生成用户主题分布和特征项主题分布;重新针对每一个关联用户对应的特征向量中的每一个特征项,在所有社区结构对应的主题除当前随机主题之外的主题中生成一个随机主题;根据上一次得到的采样参数、用户主题分布和特征项主题分布,对每一个关联用户的特征向量中的每一个特征项的主题进行采样,得到当前的采样参数,并生成当前的用户主题分布和特征项主题分布,重复采样预设的采样次数后,根据预设的采样总次数与该预设的采样次数,对当前的用户主题分布进行均值处理,得到目标用户主题分布。优选的,运用公式一,得到采样参数,Wij=CijWT+βΣiCijWT+Lβ*CjkUT+αΣjCjkUT+Kα]]>公式一其中,表示特征项i的主题为j的总个数,表示用户的特征向量k中包含主题j的总个数,α与β是预设的参数,L为所有特征向量中消重后的特征项数目,K为主题的数目。优选的,运用公式二,得到目标用户主题分布:CjkUT=Σ1Q-PCjkUTQ-P]]>公式二其中,表示用户的特征向量k中包含主题j的总个数,Q为预设的采样总次数,P为预设的采样次数。具体的,通过以下步骤执行步骤104:a)首先,针对每一个关联用户对应的特征向量中的每一个特征项,在所有社区结构对应的主题中生成一个随机主题,可以采用以下代码表示:ForDocm=0toM-1doForWordi=0toNm-1doTmi=RandInt(K)其中,Doc为一个关联用户对应的特征向量,M为特征向量的个数即关联用户集合中关联用户的个数,Word为特征向量中的特征项,Nm为第m个特征向量中特征项的数目,Tmi为第m个特征向量中的第i个特征项的主题,K为K为主题的数目,RandInt(K)表示在K个主题中随机选择一个主题。b)然后,对每一个关联用户的特征向量中的每一个特征项的主题进行采样,得到采样参数,并生成用户主题分布和特征项主题分布,可以采用以下代码表示:ForDocm=0toM-1doForWordi=0toNm-1doForTopicj=0toK-1doWij=CijWT+βΣiCijWT+Lβ*CjkUT+αΣjCjkUT+Kα]]>ForTopicj=0toK-1dosum+=Wijchoice=RandDouble()*sumForTopicj=0toK-1dosum_tmp+=Wijif(sum_tmp>=sum)Tmi=j其中,Topic为主题。例如,已知CWT、CUT参见表1和表2,Wij的计算方法如下:表1CWTTopicj=1Topicj=2Topicj=3Wordi=1124Wordi=2215Wordi=3642Wordi=4216总计11817表2CUTTopicj=1Topicj=2Topicj=3总计Userk=156718Userk=282616Userk=343714预设的α=17,β=0.01,Wij=CWord1,Topic1WT+βΣiCi,Topic1WT+Lβ*CUser1,Topic1UT+αΣjCUser1,jUT+Kα=1+β11+4*β*5+1718+3*17=0.0292]]>c)Tmi的值发生变化,则相应的CWT、CUT也相应的更新。d)对步骤b和步骤c重复预设的采样次数——P次,根据预设的采样总次数Q与预设的采样次数P,根据公式二得到目标用户主题分布。步骤105:根据用户主题分布,筛选出当前用户的目标关联用户。具体的,执行步骤105包括以下步骤:对该用户主题分布进行归一化处理,得到针对每一个主题的每一个关联用户的概率值;分别针对每一个主题,对关联用户的概率值进行从大到小排序,选择前预设数目的概率值对应的关联用户作为目标关联用户。仍以表2为例,对表2中的用户主题分布进行归一化处理参阅表3所示:表3CUTTopicj=1Topicj=2Topicj=3总计Userk=15/18=0.276/18=0.337/18=0.4018Userk=28/16=0.502/16=0.126/18=0.3816Userk=34/14=0.283/14=0.227/14=0.5014分别针对每一个主题,对关联用户的概率值进行从大到小排序,选择前预设数目的概率值对应的关联用户作为目标关联用户,具体的,对主题Topic1的关联用户的概率进行从大到小排序,{User2,User3,User1},若设定每一个主题推荐关联数目为2,则将User2和User3推荐给当前用户。基于上述实施例,参阅图3所示,本发明实施例还提供了一种微博用户关联信息筛选装置,该装置包括:获取单元301、生成单元302、确定单元303、计算单元304以及筛选单元305,其中获取单元301,用于根据预设的递归深度,获取当前用户的关联用户集合;生成单元302,用于对该关联用户集合中的每一个关联用户的设定数目的信息内容提取特征项,并统计每一个特征项的频次,生成对应的特征向量;确定单元303,用于根据该关联用户集合中的所有关联用户的关联关系,确定该关联用户集合中的社区结构,以及确定每一个社区结构对应的主题;计算单元304,用于根据每一个关联用户对应的特征向量中的每一个特征项和每一个社区结构对应的主题,得到用户主题分布;筛选单元305,用于根据用户主题分布,筛选出当前用户的目标关联用户。获取单元301根据预设的递归深度,获取当前用户的关联用户集合,包括:获取当前用户的直接关联用户;将与该直接关联用户直接关联的用户作为递归深度为1的关联用户;以及将与该递归深度为1的关联用户直接关联的用户作为递归深度为2的关联用户,直至得到递归深度为预设的递归深度的关联用户;对小于或等于预设的递归深度的所有关联用户进行消重处理,并将消重处理后的所有关联用户作为关联用户集合。生成单元302对关联用户集合中的任意一个关联用户的任意一个信息内容提取特征项,并统计每一个特征项的频次,包括:判定任意一个信息内容中有词语时,对该任意一个信息内容进行分词处理,将每一个词语作为一个特征项,并统计每一个词语对应的频次;判定该任意一个信息内容有转发地址ID时,将该转发ID作为特征项,并统计该转发ID对应的频次。生成单元302对关联用户集合中的任意一个关联用户的设定数目的信息内容提取特征项,并统计每一个特征项的频次,生成对应的特征向量,包括:将任意一个关联用户的设定数目的信息内容中每一个特征项和对应的频次作为该任意一个关联用户对应的特征向量。确定单元303根据关联用户集合中的所有关联用户的关联关系,确定该关联用户集合中的社区结构,包括:将每一个关联用户作为节点,根据该每一个关联用户的关联关系,将该每一个关联用户、与该每一个关联用户直接关联的关联用户相连接,生成关联网 络;根据该关联网络中的节点,将关联网络分割为多个组;在多个组中筛选出组内节点间的连接大于设定数目的组,作为社区结构。计算单元304根据每一个关联用户对应的特征向量中的每一个特征项和每一个社区结构对应的主题,得到用户主题分布,包括:针对每一个关联用户对应的特征向量中的每一个特征项,在所有社区结构对应的主题中生成一个随机主题;对每一个关联用户的特征向量中的每一个特征项的主题进行采样,得到采样参数,并生成用户主题分布和特征项主题分布;重新针对每一个关联用户对应的特征向量中的每一个特征项,在所有社区结构对应的主题除当前随机主题之外的主题中生成一个随机主题;根据上一次得到的采样参数、用户主题分布和特征项主题分布,对每一个关联用户的特征向量中的每一个特征项的主题进行采样,得到当前的采样参数,并生成当前的用户主题分布和特征项主题分布,重复采样预设的采样次数后,根据预设的采样总次数与预设的采样次数,对当前的用户主题分布进行均值处理,得到目标用户主题分布。计算单元304运用以下公式,得到采样参数:Wij=CijWT+βΣiCijWT+Lβ*CjkUT+αΣjCjkUT+Kα]]>其中,表示特征项i的主题为j的总个数,表示用户的特征向量k中包含主题j的总个数,α与β是预设的参数,L为所有特征向量中消重后的特征项数目,K为主题的数目。计算单元304运用以下公式,得到目标用户主题分布:CjkUT=Σ1Q-PCjkUTQ-P]]>其中,表示用户的特征向量k中包含主题j的总个数,Q为预设的采样总次数,P为预设的采样次数。筛选单元305根据用户主题分布,筛选出当前用户的目标关联用户,包括:对用户主题分布进行归一化处理,得到针对每一个主题的每一个关联用户的概率值;分别针对每一个主题,对关联用户的概率值进行从大到小排序,选择前预设数目的概率值对应的关联用户作为目标关联用户。综上所述,通过本发明实施例中提供的一种微博用户关联信息筛选方法,首先确定当前用户的关联用户集合、特征向量、以及社区结构和主题,根据每一个关联用户对应的特征向量中的每一个特征项和每一个社区结构对应的主题,得到用户主题分布,并基于用户主题分布,筛选出当前用户的目标关联用户,这样,得到的目标关联用户推荐给当前用户,该目标关联用户与当前用户的兴趣爱好一致,避免了现有技术中存在的数据稀疏的问题,以及推荐效果不理想,降低系统推荐效率的问题。尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。显然,本领域的技术人员可以对本发明实施例进行各种改动和变型而不脱离本发明实施例的精神和范围。这样,倘若本发明实施例的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1