基于FPGA实现65536点脉冲压缩的装置及方法与流程
本发明属于雷达信号处理
技术领域:
,尤其涉及一种基于FPGA实现65536点脉冲压缩的装置及方法,可在高分辨率探测雷达中,进行距离向或方位向的实时脉冲压缩处理。
背景技术:
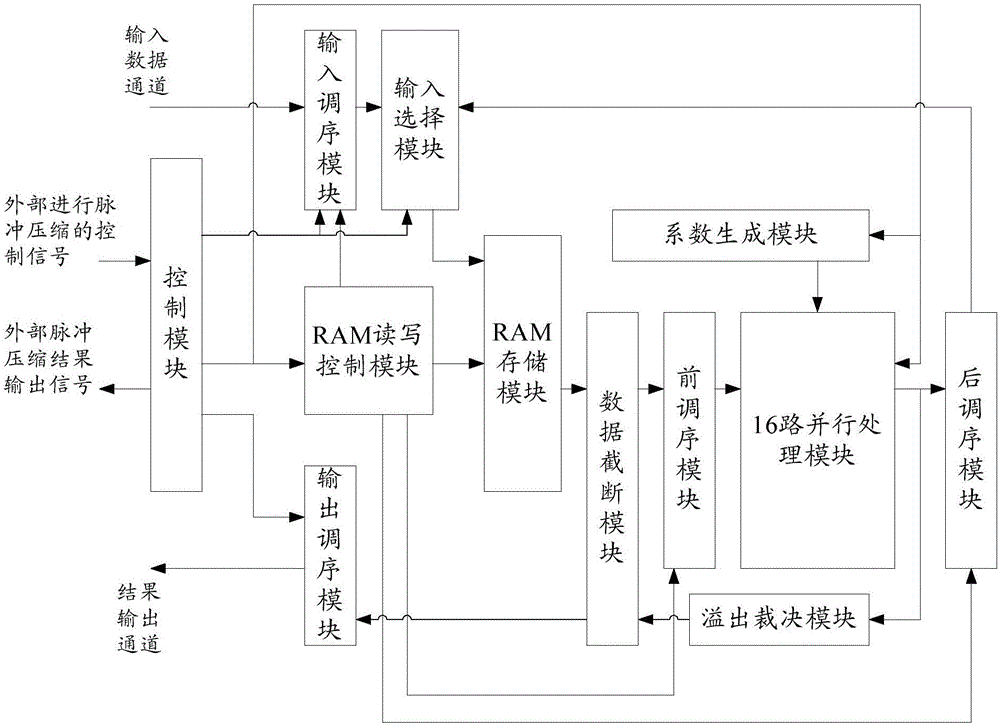
:在雷达系统中,脉冲压缩处理可以将宽脉冲信号压缩成窄脉冲信号,这样既可以发射宽脉冲以提高平均功率和雷达的检测能力,又能保持窄脉冲的距离分辨率,有效地解决雷达作用距离与距离分辨率之间的矛盾,在不降低作用距离的前提下提高雷达的距离分辨率。在同样进行脉冲压缩处理时,运算点数越多雷达的分辨率越高。随着时代发展,对雷达的要求越来越高,这样就需要大点数的实时脉冲压缩处理技术。用FPGA实现脉冲压缩时,一般采用在频域进行匹配滤波的方法,其处理流程如图1所示,数据先进行FFT处理,然后乘以频域的匹配滤波系数,再进行IFFT处理。脉冲压缩技术的FPGA实现,现有的方案是:方案一:用FFT模块、匹配滤波模块和IFFT模块级联实现,其中FFT模块和IFFT模块直接例化FPGA厂商的IP核;方案二:用FFT模块实现FFT/IFFT处理,FFT处理结果直接进行匹配滤波,匹配滤波的结果先进行缓存然后送到FFT模块进行IFFT处理。现有技术有如下缺点:(1)处理速度慢,用现有的FFT的IP核实现FFT/IFFT处理时采用低的分裂基算法,在进行大点数数据的FFT处理时运算量大并行度低导致处理速度慢;由于FFT的IP核的接口并行度低(最高支持4路并行),导致匹配滤波处理速度慢;(2)接口速率低,由于IP核接口并行度低,导致整个模块的数据输入输出并行度低,接口速度严重影响了整体的数据吞吐率;(3)资源占用多,方案一中FFT和IFFT用两个单独的模块浪费资源,方案二中对FFT模块进行了复用,但是数据需要缓存,占用的RAM资源仍然很多。技术实现要素:针对上述现有技术的缺点,本发明的目的在于提供一种基于FPGA实现65536点脉冲压缩的装置及方法,以解决传统设计方案中数据处理速度慢、接口速率低和以及FFT、匹配滤波和IFFT之间的数据传输延时的问题。为达到上述目的,本发明的实施例采用如下技术方案予以实现。技术方案一:一种基于FPGA实现65536点脉冲压缩的装置,所述装置的输入端与外部进行脉冲压缩的16路输入数据通道连接,所述装置的输出端与外部脉冲压缩结果输出通道连接,所述装置包括:输入调序模块,输入选择模块,RAM存储模块,RAM读写控制模块,数据截断模块,前调序模块,16路并行处理模块,后调序模块,系数生成模块,输出调序模块,溢出裁决模块,控制模块;其中,所述输入调序模块的输入端与外部进行脉冲压缩的16路输入数据通道连接,输入调序模块的输出端与输入选择模块的第一输入端连接,输入选择模块的输出端与RAM存储模块的输入端连接,RAM读写控制模块的第一输出端与RAM存储模块的控制端连接,RAM读写控制模块的第二输出端与前调序模块的控制端连接,RAM读写控制模块的第三输出端与后调序模块的控制端连接,RAM存储模块的输出端与数据截断模块的第一输入端连接,数据截断模块的第一输出端与前调序模块的输入端连接,前调序模块的输出端与16路并行处理模块的第一输入端连接,系数生成模块的输出端与16路并行处理模块的第二输入端连接,16路并行处理模块的输出端分别与后调序模块的输入端、溢出裁决模块的输入端连接,后调序模块的输出端与输入选择模块的第二输入端连接,溢出裁决模块的输出端与数据截断模块的第二输入端连接,数据截断模块的第二输出端与输出调序模块的输入端连接,所述输出调序模块的输出端与外部脉冲压缩结果输出通道连接,所述控制模块的输入端与外部进行脉冲压缩的控制信号连接,控制模块的第一输出端分别与输入调序模块的控制端和输入选择模块的控制端连接,控制模块的第二输出端分别与RAM读写控制模块的控制端、16路并行处理模块的控制端和系数生成模块的控制端连接,控制模块的第三输出端与输出调序模块的控制端连接,控制模块的第四输出端与外部脉冲压缩结果输出信号连接。技术方案二:一种基于FPGA实现65536点脉冲压缩的方法,所述方法包括如下步骤:步骤1,在每个时钟周期获取16点输入数据,并将所述16点输入数据按照无冲突存储的方式分别存储于16个子存储模块中;从而经过4096个时钟周期获取65536点数据,并存储于RAM存储模块中;步骤2,从RAM存储模块中获取16个待处理数据;步骤3,数据截断模块根据溢出裁决模块输出的移位位数,对16个待处理数据进行移位;所述溢出裁决模块输出的移位位数初值为零;步骤4,前调序模块将移位后的16个待处理数据的顺序调整为基-16蝶形运算规则的顺序;步骤5,所述前调序模块将调序后的16个待处理数据发送至16路并行处理模块,且系数生成模块生成16个待处理数据对应的旋转因子,并发送至16路并行处理模块;步骤6,所述16路并行处理模块根据接收到的16个待处理数据和对应的旋转因子,进行基-16蝶形运算,得到该组数据的基-16蝶形运算结果;步骤7,所述溢出裁决模块对所述基-16蝶形运算结果进行溢出判断,得到移位位数;步骤8,将所述基-16蝶形运算结果按照16个待处理数据在RAM存储模块中的存储位置进行原位存储;步骤9,将步骤2至步骤8以流水线的方式重复执行4096次,得到第一级蝶形运算结果;步骤10,将步骤2至步骤9重复执行4次,得到65536点数据的傅里叶变换结果;此时所述RAM存储模块中存储的数据为快速傅里叶变换后的65536点数据;步骤11,从RAM存储模块中获取16个快速傅里叶变换后的数据;步骤12,数据截断模块根据溢出裁决模块输出的移位位数,对16个待处理数据进行移位;步骤13,前调序模块将移位后的16个快速傅里叶变换后的数据的顺序调整为基-16蝶形运算规则的顺序;步骤14,所述前调序模块将调序后的16个快速傅里叶变换后的数据发送至16路并行处理模块,且系数生成模块生成16个快速傅里叶变换后的数据对应的匹配滤波系数,并发送至16路并行处理模块;步骤15,所述16路并行处理模块根据接收到的16个快速傅里叶变换后的数据和对应的匹配滤波系数,进行复数乘法运算,得到该组数据的匹配滤波运算结果;步骤16,所述溢出裁决模块对所述匹配滤波运算结果进行溢出判断,得到移位位数;步骤17,将所述匹配滤波运算结果按照16个快速傅里叶变换后的数据在RAM存储模块中的存储位置进行原位存储;步骤18,将步骤11至步骤17以流水线的方式重复执行4096次,得到匹配滤波运算结果;此时所述RAM存储模块中存储的数据为匹配滤波运算后的65536点数据;步骤19,从RAM存储模块中获取16个匹配滤波运算后的数据;步骤20,数据截断模块根据溢出裁决模块输出的移位位数,对16个匹配滤波运算后的数据进行移位;步骤21,前调序模块将移位后的16个匹配滤波运算后的数据的顺序调整为基-16蝶形运算规则的顺序;步骤22,所述前调序模块将调序后的16个匹配滤波运算后的数据取共轭后发送至16路并行处理模块,且系数生成模块生成16个匹配滤波运算后的数据对应的旋转因子,并发送至16路并行处理模块;步骤23,所述16路并行处理模块根据接收到的16个匹配滤波运算后的数据和对应的旋转因子,进行基-16蝶形运算,得到该组数据的基-16蝶形运算结果;步骤24,所述溢出裁决模块对所述基-16蝶形运算结果进行溢出判断,得到移位位数;步骤25,将所述基-16蝶形运算结果取共轭后按照16个匹配滤波运算后的数据在RAM存储模块中的存储位置进行原位存储;步骤26,将步骤19至步骤25以流水线的方式重复执行4096次,得到第一级蝶形运算结果;步骤27,将步骤19至步骤26重复执行4次,得到65536点匹配滤波运算后的数据的逆傅里叶变换结果,即脉冲压缩结果;此时所述RAM存储模块中存储的数据为脉冲压缩后的65536点数据;步骤28,数据截断模块根据溢出裁决模块输出的移位位数,对从RAM存储模块中读取的65536点脉冲压缩后的数据进行移位;步骤29,输出调序模块将移位后的脉冲压缩结果进行顺序调整,并输出。本发明技术方案与现有技术相比,具有以下有益效果:(1)处理速度快。基于16路并行流水线处理单元,将FFT/IFFT处理和匹配滤波处理整合在一起。相比于现有实现方法中采用至多4路并行运算,本发明方法在减小计算量的同时提高数据处理的并行度,大幅度提高了处理速度。进行65536点数据的脉冲压缩处理,传统设计方法,需要131260时钟才能完成运算,本发明方法设计的模块28839时钟即可完成,速度是其4.55倍。(2)接口速度更高。采用16路并行的数据输入输出方式,消除了数据输入输出瓶颈,相较于传统设计方法中最多支持4路并行输出,本发明方法一次可以输入输出16个数据,本发明的接口速度是其4~16倍。(3)整体上数据吞吐率高。综合考虑接口速度和处理速度,相比于传统设计方法,本发明方法实现的吞吐率是其11.95倍,在200M时钟下仅需要不到164us即可完成65536点数据的脉冲压缩。(4)节省RAM资源。传统设计方法需要396个36K的块RAM,而共本发明模块仅需要95个36K的块RAM。相比于传统设计方法,本发明方法仅用了不到其1/4的RAM资源。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明实施例提供的现有技术中用FPGA实现脉冲压缩时,在频域进行匹配滤波的方法流程示意图;图2为本发明实施例提供的一种基于FPGA实现65536点脉冲压缩的装置的结构示意图;图3为本发明实施例提供的16路并行处理模块的结构示意图;图4为本发明实施例提供的系数生成模块生成旋转因子和匹配滤波系数的流程示意图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明实施例提供的一种基于FPGA实现65536点脉冲压缩的装置,所述装置的输入端与外部进行脉冲压缩的16路输入数据通道连接,所述装置的输出端与外部脉冲压缩结果输出通道连接;其结构示意图如图2所示:所述装置包括:输入调序模块,输入选择模块,RAM存储模块,RAM读写控制模块,数据截断模块,前调序模块,16路并行处理模块,后调序模块,系数生成模块,输出调序模块,溢出裁决模块,控制模块;其中,所述输入调序模块的输入端与外部进行脉冲压缩的16路输入数据通道连接,输入调序模块的输出端与输入选择模块的第一输入端连接,输入选择模块的输出端与RAM存储模块的输入端连接,RAM读写控制模块的第一输出端与RAM存储模块的控制端连接,RAM读写控制模块的第二输出端与前调序模块的控制端连接,RAM读写控制模块的第三输出端与后调序模块的控制端连接,RAM存储模块的输出端与数据截断模块的第一输入端连接,数据截断模块的第一输出端与前调序模块的输入端连接,前调序模块的输出端与16路并行处理模块的第一输入端连接,系数生成模块的输出端与16路并行处理模块的第二输入端连接,16路并行处理模块的输出端分别与后调序模块的输入端、溢出裁决模块的输入端连接,后调序模块的输出端与输入选择模块的第二输入端连接,溢出裁决模块的输出端与数据截断模块的第二输入端连接,数据截断模块的第二输出端与输出调序模块的输入端连接,所述输出调序模块的输出端与外部脉冲压缩结果输出通道连接,所述控制模块的输入端与外部进行脉冲压缩的控制信号连接,控制模块的第一输出端分别与输入调序模块的控制端和输入选择模块的控制端连接,控制模块的第二输出端分别与RAM读写控制模块的控制端、16路并行处理模块的控制端和系数生成模块的控制端连接,控制模块的第三输出端与输出调序模块的控制端连接,控制模块的第四输出端与外部脉冲压缩结果输出信号连接。需要说明的是,外部进行脉冲压缩的65536点数据分为16个通道进行数据输入,且按照第1个通道的第一个数据编号为0,第2个通道的第一个数据编号为1,第16个通道的第一个数据编号为15,第1个通道的第二个数据编号为16,第2个通道的第二个数据编号为17,第16个通道的第二个数据编号为31的方式对65536点数据进行编号;且65536点数据以16位补码的形式进行存储。在一个时钟周期内16个通道的每个通道输入一个数据,从而外部进行脉冲压缩的65536点数据需要4096个时钟周期完成数据输入。具体的,控制模块生成高电平的输入指示信号input_flag,用于指示输入待处理的65536点数据;所述控制模块生成高电平的输出指示信号output_flag,用于指示输出脉冲压缩结果;且所述控制模块生成15位的运行指示信号step_sig[14:0],在16路并行处理模块运行期间,15位的运行指示信号step_sig[14:0]的高3位用于指示16路并行处理模块进行运算的级,其中,第0~3级为快速傅里叶变换,第4级为匹配滤波运算,第5~8级为逆快速傅里叶变换,15位的运行指示信号step_sig[14:0]的低12位用于指示每级基-16蝶形运算的次数。需要说明的是:65536点的FFT/IFFT运算需要4级基-16蝶形运算,每一级进行4096次蝶形运算,匹配滤波需要进行4096次16路并行的复数乘法运算。所述输入调序模块,用于按照无冲突存储的方式对16个通道的输入数据进行调序;从而使得数据编号间隔为1、16、256、4096的数据不会存储在同一个子存储模块中;进一步的,输入调序模块在input_flag信号使能下生成16个12位计数器count,初值分别为0~15,每个时钟使能计数器加16,这样计数器的值就代表输入数据的编号。用计数器生成块地址信号block_addr[3:0]指示每个数据存储的RAM的编号,其公式为block_addr[3:0]=count[11:8]+count[7:4]+count[3:0],根据信号block_addr的值将16路输入数据进行调序,然后送到RAM存储模块。这样的存储方式,数据编号间隔为1、16、256、4096的点都不在同一个子RAM中,可以实现16路并行的FFT处理。所述输入选择模块,用于将输入调序模块的输出数据输入到RAM存储模块;或者,用于将后调序模块的输出数据输入到RAM存储模块;具体的,该模块在数据输入阶段(input_flag=1),将RAM存储模块的输入数据选通为输入调序模块的调序数据,否则选通为16路并行处理模块的处理结果。所述RAM存储模块,用于缓存进行脉冲压缩的16路输入数据,或者,用于原位存储后调序模块输出的16路数据;进一步的,所述RAM存储模块包含16个双端口的子RAM,分别编号为RAM0-RAM15。具体的,该模块用于暂存接收到的数据,并存储每一级运算的中间结果。该模块由16个双端口的块RAM组成,每个块RAM的位宽是40位,深度为4096。数据在RAM中的存储格式为:40位中高20位是数据的实部,低20位是数据的虚部,数据都是补码的形式。需要说明的是:从外部数据输入通道接收到的数据实部虚部都是16位的,采用低位对齐高位补零的方式存储。所述RAM读写控制模块,在输入调序模块输入65536点数据时,生成写使能信号和每16路数据在RAM存储模块中对应的存储地址;在获取输入16路并行处理模块的16路数据时,生成读使能信号和前调序控制信号,所述前调序控制信号用于指示前调序模块从所述RAM存储模块中读取16路数据,并对读取的16路数据进行调序;在获取16路并行处理模块的16路输出数据时,生成写使能信号和后调序控制信号,所述后调序控制信号用于指示后调序模块对所述16路并行处理模块输出的16路数据进行调序,并将调序后的16路数据写入RAM存储模块中;在输出调序模块输出65536点脉冲压缩结果数据时,生成读使能信号和输出调序控制信号,所述输出调序控制信号用于指示所述输出调序模块从RAM存储模块中读取16路脉冲压缩结果数据,并将其进行调序输出。具体的,该模块用于生成RAM存储模块的读写地址和使能信号。在数据输入阶段(input_flag=1),拉高写使能wea信号,并将写地址信号addra在写使能下递增计数,4096个时钟完成整个65536点的数据输入。在数据运算阶段,FFT处理的四级运算中每次蝶形运算的数据编号间隔分别为1、16、256和4096,在生成地址时还需要考虑的是顺序存储的数据,经FFT运算后变成倒序的数据,因此IFFT和FFT运算地址的生成是不一样的。实现方式是:先根据step_sig信号生成16个计数器cnt0~cnt15,该组计数器满足蝶形运算对数据间隔的要求,然后用这组计数器生成每次蝶形运算需要数据的RAM地址和RAM编号,送到RAM存储模块。在进行IFFT处理时,RAM存储模块中存储的是倒序的数据,用按位倒序的计数器生成RAM地址和RAM编号。匹配滤波的地址生成方式和IFFT处理第一级的相同。所述前调序模块,用于将RAM存储模块中16个子存储模块的数据按照基-16蝶形运算的要求,进行顺序调整,并将顺序调整后的16路数据输入16路并行处理模块;所述系数生成模块,用于在16路并行处理模块进行快速傅里叶变换或者逆快速傅里叶变换时,生成与16路输入数据对应的旋转因子;或者,在16路并行处理模块进行匹配滤波运算时,生成与16路输入数据对应的匹配滤波系数;所述16路并行处理模块,用于将顺序调整后的16路数据与系数生成模块发送的对应旋转因子进行基-16蝶形运算,得到快速傅里叶变换结果;所述16路并行处理模块,还用于将快速傅里叶变换结果与系数生成模块发送的对应匹配滤波系数进行复数乘法运算,得到匹配滤波结果;所述16路并行处理模块,还用于将匹配滤波结果数据与系数生成模块发送的对应旋转因子进行基-16蝶形运算,得到脉冲压缩结果;进一步的,所述16路并行处理模块以基-16蝶形运算单元为基础,并采用基-16蝶形运算单元的复数乘法器实现匹配滤波运算的过程;若所述16路并行处理模块进行快速傅里叶变换,则前调序模块每次从RAM存储模块获取16个待处理数据,系数生成模块每次实时生成16个待处理数据分别对应的旋转因子,然后16个待处理数据以及16个待处理数据分别对应的旋转因子作为基-16蝶形运算单元的输入,并且以流水线的方式完成一级4096次基-16蝶形运算,从而四级基-16蝶形运算的结果作为快速傅里叶变换的结果;若所述16路并行处理模块进行匹配滤波运算,则前调序模块每次从RAM存储模块获取16个快速傅里叶变换结果数据,系数生成模块每次实时生成16个快速傅里叶变换结果数据分别对应的匹配滤波系数,然后16个快速傅里叶变换结果数据以及16个快速傅里叶变换结果数据分别对应的匹配滤波系数作为16个复数乘法器的输入,16个复数乘法器的输出作为此次匹配滤波运算的结果,并且以流水线的方式完成4096次复数乘法运算,从而完成4096次16路并行的匹配滤波运算;若所述16路并行处理模块进行逆快速傅里叶变换,则前调序模块每次从RAM存储模块获取16个匹配滤波运算结果数据并对其取共轭,系数生成模块每次实时生成16个匹配滤波运算结果数据分别对应的旋转因子,然后16个取共轭后的匹配滤波运算结果数据以及16个取共轭后的匹配滤波运算结果数据分别对应的旋转因子作为基-16蝶形运算单元的输入,并且以流水线的方式完成一级4096次基-16蝶形运算,从而四级基-16蝶形运算的结果再次取共轭作为逆傅里叶变换的结果。更进一步的,16路并行处理模块完成65536点数据的脉冲压缩,需要进行65536点数据的快速傅里叶变换、65536点数据的逆快速傅里叶变换,65536点数据的匹配滤波运算,其中,65536点数据的快速傅里叶变换、65536点数据的逆快速傅里叶变换分别需要进行四级基-16蝶形运算,且每级基-16蝶形运算包含4096次基-16蝶形运算,65536点数据的匹配滤波运算包含4096次16路并行的复数乘法运算。所述后调序模块,用于将16路并行处理模块输出的运算结果进行顺序调整,使其按照无冲突存储方式原位存储于RAM存储模块中;所述溢出裁决模块,用于对所述16路并行处理模块输出的运算结果进行溢出位宽判断,从而得到溢出位宽,将溢出位宽发送给数据截断模块;该模块用于对16路并行处理模块运算后的数据进行溢出判断,具体判断规律依据下表进行,得到数据的每组16个数据的溢出位宽,然后取一级所有运算结果中溢出的最大值作为该级的溢出位宽ovflow_num,送到数据截取模块。编号高5位值溢出位数000000/111110100001/11110120001x/1110x23001xx/110xx3401xxx/10xxx4所述数据截断模块,用于根据溢出裁决模块发送的溢出位宽,将从RAM存储模块中读取的数据进行相应的移位,得到16位有效数据;具体的,该模块将根据溢出裁决模块生成的溢出位宽overflow_num[3:0],将从RAM存储模块中读取的数据进行右移overflow_num位,前面补上符号位(最高位),这样得到的数据最大有16位的有效位,经运算后不会溢出20位的位宽,再次进行运算时还会进行截取,从而最大限度保证数据精度。所述输出调序模块,用于将经过移位后的所述RAM存储模块中存储的脉冲压缩结果进行调序并输出;具体的,该模块用于对数据运算后的结果进行调序,使按照16路并行顺序的方式输出,同输入调序模块类似,根据output_flag信号生成每次从RAM存储模块中读取的16个数据的编号,然后根据编号生成子RAM的地址和编号,读取子RAM中的数据并进行调序,结果顺输出。本发明实施例还提供一种基于FPGA实现65536点脉冲压缩的方法,所述方法包括如下步骤:步骤1,在每个时钟周期获取16点输入数据,并将所述16点输入数据按照无冲突存储的方式分别存储于16个子存储模块中;从而经过4096个时钟周期获取65536点数据,并存储于RAM存储模块中;步骤2,从RAM存储模块中获取16个待处理数据;步骤3,数据截断模块根据溢出裁决模块输出的移位位数,对16个待处理数据进行移位;所述溢出裁决模块输出的移位位数初值为零;步骤4,前调序模块将移位后的16个待处理数据的顺序调整为基-16蝶形运算规则的顺序;步骤5,所述前调序模块将调序后的16个待处理数据发送至16路并行处理模块,且系数生成模块生成16个待处理数据对应的旋转因子,并发送至16路并行处理模块;步骤6,所述16路并行处理模块根据接收到的16个待处理数据和对应的旋转因子,进行基-16蝶形运算,得到该组数据的基-16蝶形运算结果;步骤7,所述溢出裁决模块对所述基-16蝶形运算结果进行溢出判断,得到移位位数;步骤8,将所述基-16蝶形运算结果按照16个待处理数据在RAM存储模块中的存储位置进行原位存储;步骤9,将步骤2至步骤8以流水线的方式重复执行4096次,得到第一级蝶形运算结果;步骤10,将步骤2至步骤9重复执行4次,得到65536点数据的傅里叶变换结果;此时所述RAM存储模块中存储的数据为快速傅里叶变换后的65536点数据;步骤11,从RAM存储模块中获取16个快速傅里叶变换后的数据;步骤12,数据截断模块根据溢出裁决模块输出的移位位数,对16个待处理数据进行移位;步骤13,前调序模块将移位后的16个快速傅里叶变换后的数据的顺序调整为基-16蝶形运算规则的顺序;步骤14,所述前调序模块将调序后的16个快速傅里叶变换后的数据发送至16路并行处理模块,且系数生成模块生成16个快速傅里叶变换后的数据对应的匹配滤波系数,并发送至16路并行处理模块;步骤15,所述16路并行处理模块根据接收到的16个快速傅里叶变换后的数据和对应的匹配滤波系数,进行复数乘法运算,得到该组数据的匹配滤波运算结果;步骤16,所述溢出裁决模块对所述匹配滤波运算结果进行溢出判断,得到移位位数;步骤17,将所述匹配滤波运算结果按照16个快速傅里叶变换后的数据在RAM存储模块中的存储位置进行原位存储;步骤18,将步骤11至步骤17以流水线的方式重复执行4096次,得到匹配滤波运算结果;此时所述RAM存储模块中存储的数据为匹配滤波运算后的65536点数据;步骤19,从RAM存储模块中获取16个匹配滤波运算后的数据;步骤20,数据截断模块根据溢出裁决模块输出的移位位数,对16个匹配滤波运算后的数据进行移位;步骤21,前调序模块将移位后的16个匹配滤波运算后的数据的顺序调整为基-16蝶形运算规则的顺序;步骤22,所述前调序模块将调序后的16个匹配滤波运算后的数据取共轭后发送至16路并行处理模块,且系数生成模块生成16个匹配滤波运算后的数据对应的旋转因子,并发送至16路并行处理模块;步骤23,所述16路并行处理模块根据接收到的16个匹配滤波运算后的数据和对应的旋转因子,进行基-16蝶形运算,得到该组数据的基-16蝶形运算结果;步骤24,所述溢出裁决模块对所述基-16蝶形运算结果进行溢出判断,得到移位位数;步骤25,将所述基-16蝶形运算结果取共轭后按照16个匹配滤波运算后的数据在RAM存储模块中的存储位置进行原位存储;步骤26,将步骤19至步骤25以流水线的方式重复执行4096次,得到第一级蝶形运算结果;步骤27,将步骤19至步骤26重复执行4次,得到65536点匹配滤波运算后的数据的逆傅里叶变换结果,即脉冲压缩结果;此时所述RAM存储模块中存储的数据为脉冲压缩后的65536点数据;步骤28,数据截断模块根据溢出裁决模块输出的移位位数,对从RAM存储模块中读取的65536点脉冲压缩后的数据进行移位;步骤29,输出调序模块将移位后的脉冲压缩结果进行顺序调整,并输出。具体的,如图3所示是本发明实施例提供的16路并行处理模块的结构示意图,将FFT处理和匹配滤波处理统一起来,该模块将基-16蝶形运算单元进行改进,减小了运算延时,并能兼容处理匹配滤波的运算。下面对该模块的设计进行详细说明。图中x0~x15是进行一次运算的数据(FFT或匹配滤波),是实部虚部都为16位补码的复数,f0~f15是进行一次运算的系数,在FFT运算时该组系数是和数据对应的旋转因子,在进行匹配滤波运算时,该组系数是和数据对应的匹配滤波系数。图中C0~C15是复数乘法器,直接用FPGA的内部DSP实现,输入位宽为16位复数,输出位宽为20位复数,截断类型为收敛性舍入,完成一次复数乘法需要消耗4个时钟。C16~C23也是复数乘法器,同样用FPGA内部DSP实现,输入为20位和16位的复数,输出截断低16位得到20位的复数,完成一次复数乘法需要消耗4个时钟,其中,复数乘法器C16~C23的16位系数实部和虚部列于下表:乘法器系数实部系数虚部乘法器系数实部系数虚部C1616′h2d4116′hd2bfC2016′h187d16′hc4e0C1716′hd2bf16′hd2bfC2116′h187d16′hc4e0C1816′h3b2016′he783C2216′hd2bf16′hd2bfC1916′h2d4116′hd2bfC2316′hc4e016′h187d图中“D4”操作为将数据流水延时4个时钟,目的是和复数乘法运算的结果同步。图中“-jD”操作为先将数据虚部实部交换位置再将虚部取反,然后流水延时4个时钟。下面用a+ib表示第一个操作数,c+id表示第二个操作数,结果用x+iy表示,解释图中的运算。图中“+”操作为将两个20位数直接相加,x=a+c,y=b+d。图中“-”操作为:第一个操作数据减去第二个操作数,即x=a-c,y=b-d。图中“j+”操作为:第一个操作数据加上第二个操作数乘以j的值,即x=a-d,y=b+c。图中“j-”操作为:第一个操作数减去第二操作数乘以j的值,即x=a+d,y=b-c。图中“S”为数据选择,在进行FFT运算时选择最后一步运算的结果输出,进行匹配滤波运算时,选择复数乘法的结果输出。进一步的,本发明实施例提供的系数生成模块生成系数的流程示意图如图4所示。在说明生成系数的流程前先说明匹配滤波系数的生成理论。匹配滤波系数生成公式为:fr=[-fs/2:fs/nrn:fs/2-fs/nrn];Fr=fftshift(fr)SR=exp(j*pi*tp/B*Fr2);其中,fs表示采样频率,nrn表示距离向的点数,fr表示频域中频率的范围,Fr表示零频在中点的频域中频率的范围,tp表示脉冲宽度,B表示信号带宽,SR表示匹配滤波器的系数,fftshift()函数的作用是将0频点移频谱中间。令cnt=[-nrn/2:nrn/2-1];cnt2=fftshift(cnt);gama=π*tp*B*fs2/nrn2带入SR的公式中得:SR=exp(j*π*tp/B*(cnt2.^2)*(fs^2/nrn^2));=exp(j*gama*cnt2)其中cnt、cnt2和gama没有意义,是为了方便计算而生成的中间变量。cnt2的范围是0~32767,-32768~-1,cnt2在生成匹配滤波器系数时要进行平方运算,因此在实现时用一个计数器表示其绝对值。gama可以用matlab提前计算好,当用38位量化时可以满足绝大多数调频率的需要,不同场合下需要修改gama的值就可以生成响应的匹配滤波系数。生成系数需要先设计一个三角函数查找表:先用matalb设计一个三角函数表:将一个周期的余弦值,进行65536点抽取,然后128个余弦数据为一组共512组,每组数据用最小二乘法进行一次拟合,得到的零次项系数作为这128个数据的基,一次项系数作为这128个数据的单位偏移,因此,用基和偏移量就可以还原这128个数据的余弦值。由于三角函数的对称性,只存储1/2周期的基和偏移,其中基用24位量化,偏移用11位量化,基在高位偏移在低位组成35位的数据进行存储。这样得到的余弦函数有16位数据精度。在进行FFT、IFFT和匹配滤波运算时,先根据step_sig生成三角函数表的地址,查表后根据基和偏移就可以生成旋转因子或匹配滤波系数。系数生成模块的处理流程如下:整个模块开始运行后根据step_sig信号的高3位判断是否在进行匹配滤波运算,当这3位的值为4时当前进行匹配滤波运算,否则进行的是FFT/IFFT运算。进行匹配滤波时,生成匹配滤波系数有如下步骤:(1)根据step_sig信号生成一组16个编号,该组编号和进行一次蝶形运算的数据对应。(2)编号进行调序,相当于公式中的fftshift运算,不过得到的是绝对值,具体是当编号的值大于32768时,用65536减去该编号得到fr,否则直接将编号的值赋给fr,也就是公式中的fa。(3)求fr的平方。(4)将匹配滤波参数gama与fr的平方相乘。(5)将乘积的结果进行截取得到地址。(6)将乘积进行截取得到地址,具体是截取后得到的量化地址是实际值的三角函数变量的512倍。(7)根据地址通过查表得到基和斜率。(8)最后根据基、斜率和地址偏移计算得到匹配滤波系数,具体是斜率乘以地址偏移再加上基。进行FFT/IFFT运算时,生成匹配滤波系数有如下步骤:(1)根据step_sig信号生成一组16个编号,该组编号和进行一次蝶形运算的数据对应。(2)根据编号就可以直接生成地址,具体是地址的值是编号值的256倍。(3)根据地址通过查表得到基和斜率。(4)最后根据基、斜率得和地址偏移得到匹配滤波系数,具体是斜率乘以地址偏移再加上基。综上,(1)针对传统设计处理速度慢的问题,本发明实施例设计一个16路并行处理模块作为核心处理单元,该处理模块可以16路并行进行FFT/IFFT处理或脉冲压缩处理,提高处理的速度;(2)针对传统设计方法中,最高支持4路并行输入和输出,本发明实施例设计一个16路并行输入输出接口,提高设计模块的接口速率;(3)针对传统设计方法占用资源多的问题,本发明实施例设计统一的控制逻辑将核心处理模块进行复用的,用原位存储方式实现数据缓存RAM的复用,节省资源。另外关于旋转因子和匹配滤波系数,采用三角函数分段线性化存储,然后查表插值的方式实时生成,进一步节省资源。以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1