循环流化床生活垃圾焚烧锅炉炉膛出口烟气含氧量的预测系统及方法与流程
本发明涉及能源工程领域,特别地,涉及一种循环流化床生活垃圾焚烧锅炉炉膛出口烟气含氧量排放预测系统及方法。
背景技术:
垃圾焚烧由于能够良好实现垃圾处理技术的减容化、减量化、无害化和资源化,近十几年内,在国家相关产业政策的引导下,国内垃圾焚烧行业取得了蓬勃的发展。从上世纪90年代开始,国内多家科研结构对中国城市生活垃圾(municipalsolidwaste,msw)燃烧机理进行了大量深入研究,掌握了混合收集、水分高、成分复杂的城市生活垃圾的燃烧特性,根据我国对煤、煤矸石等劣质燃料循环流化床(circulatingfluidizedbed,cfb)燃烧技术的开发经验的基础上,开发出了循环流化床垃圾焚烧锅炉,从1998年浙江大学开发的第一台流化床垃圾焚烧炉投入运行开始,表现出了适用于对国内高水分、热值偏低且波动性很大的生活垃圾进行大规模的焚烧处理的特点。目前,cfb垃圾焚烧技术已经在国内的多个城市进行了推广应用,截止2015年底,国内已建成垃圾焚烧锅炉70余台,日处理垃圾量6.9万吨,为我国的垃圾焚烧处理行业做出了重要的贡献。
锅炉炉膛出口烟气含氧量是衡量锅炉是否安全、经济、环保运行的重要标志之一。炉膛出口含氧量太低则炉膛内的燃烧不能充分进行,大量的可燃物质未能燃尽,垃圾中的有害物质也无法得到充分的破坏,必然会导致炉渣的热灼减率超过《生活垃圾焚烧污染控制标准》(gb18485-2014)的规定的最低标准,炉膛本身也面临值结软焦的危险;炉膛出口含氧量太高,则过量的冷空气会带走炉膛中热量,炉膛中温度难以维持稳定,影响锅炉的安全稳定运行。工业生产中通常采用氧化锆对炉膛出口的烟气含氧量进行监测,然而炉膛内的环境极端复杂,经常使氧化锆测点因磨损而无法正常工作。同时,单纯的硬件测量系统无法探知炉膛出口烟气含氧量的运行变化特性。因此,构建一个足够精度的炉膛出口烟气含氧量预测系统和模型具有十分重要的意义。
国内外的研究人员对循环流化床锅炉的炉膛出口烟气含氧量动态特性建模进行了研究,主要有以下几种方法。一种是根据cfb锅炉燃烧动力学、流体力学、传热传质的特性,在经过合理的简化假设之后建立,通过数学描述的方式建立机理模型。这种方法能够反映烟气含氧量的变化趋势,但由于假设模型和真实模型之间的偏差而无法达到足够的精确度;另一种方法是在大量的试验台试验或者现场试验的基础上,通过回归分析的方法建立关于烟气含氧量动态特性的经验模型。这种方法需要耗费大量的人力物力,时间成本高,同时无法保证试验覆盖所有的工况,具有一定局限性;第三种方法利用计算流体力学、计算传热学和化学反应的简化机理模拟炉内燃烧过程,精确地求解烟气含氧量的生成情况,显示了良好的效果具有很大的发展潜力。但这种方法主要受限于流体力学模型和化学反应的简化机理与实际情况的差距,需要高端的计算机配置和很长的计算时间,因此采用这种方法仍处于初步发展阶段。此外,cfb垃圾焚烧锅炉的给料系统均匀性较差,入炉垃圾的热值波动性大、组分复杂、多边性强,是烟气含氧量预测建模过程中的面临的主要困难之一,它要求所建立的烟气含氧量动态特性模型具有良好的自适应能力,上述三种建模方法在这方面仍有所欠缺。
随着电子技术、计算机技术和信息技术的发展,集散控制系统(distributedcontrolsystem,dcs)广泛的应用于cfb生活焚烧锅炉的运行过程,包含温度、压力、流量等参数在内的过程数据都被完善得保存下来,这些历史数据中包含丰富过程信息,是人们认识和了解生产过程的重要途径之一,具有很高的挖掘价值,为智能数据挖掘算法的应用研究和应用提供了绝佳的软硬件平台。支持向量机基于统计学习理论的vc(vapnik-chervonenkis)维理论和结构风险最小化(structuralriskminimization)原则的统计学习方法,svm的一个重要特征就是输入与输出之间的黑箱特性,它将待建模系统视为一个黑箱,不关心待求解问题的内部机制如何复杂,只关心系统的输入与输出。这使得svm特别适用于cfb生活垃圾焚烧锅炉的炉膛出口烟气含氧量动态特性的建模,采用这种方法可以绕开烟气含氧量变化过程中带有的滞后性、非线性和时变性等难点,实现烟气含氧量与各影响因素之间的复杂映射关系。同时,svm具有自学习能力,能够根据新鲜样本进行训练,自适应调整模型参数。当煤种、积灰以及设备性能(如垃圾给料系统的性能变化等)发生变化时,烟气含氧量动态特性模型也将随之发生变化。利用svm的自学习特性可以在线训练调整烟气含氧量动态特性模型,保证模型的精度。
然而svm的性能对惩罚参数c和核参数g有很大程度上的依赖,如果这两个参数设置的不理想,将直接影响svm模型的性能。为了改善这个问题,本专利将引入多种群遗传粒子群算法,用它来对参数c和g进行优化。同时,烟气含氧量预测系统具有较高的运算负荷,因此,为了提高系统的计算效率,需要合理设置系统的框架结构。
技术实现要素:
本发明的目的在于针对现有技术的不足,提供一种循环流化床生活垃圾焚烧锅炉炉膛出口烟气含氧量的预测系统及方法。本发明在分析cfb生活垃圾焚烧锅炉运行机理的基础上,选择烟气含氧量预测模型的输入变量,利用支持向量机对样本集进行训练建模,并利用多种群遗传粒子群算法对svm模型的惩罚参数c和核参数g进行寻优。为了提高计算效率和计算资源使用率,采用异构计算环境构建烟气含氧量预测系统。
本发明解决其技术问题所采用的技术方案是:一种循环流化床生活垃圾焚烧锅炉炉膛出口烟气含氧量的实时预测系统。该系统与循环流化床锅炉的集散控制系统以及生产管理系统相连,包括数据通讯接口和上位机,在上位机(服务器)中对烟气含氧量预测模型进行训练和更新,让后将训练好的模型通过通讯接口送往集散控制系统、生产管理系统(客户端),所述上位机包括:
信号采集模块。该模块用于采集cfb生活垃圾焚烧锅炉在焚烧指定生活垃圾时的运行工况状态参数和操作变量,并组成垃圾热值预测模型输入变量的训练样本矩阵x(m×n),m表示样本个数,n表示变量的个数;
数据预处理模块。对x(m×n)进行粗大误差处理和随机误差处理,以摒除那些并不是反映锅炉正常运行工况的虚假信息,将锅炉停炉、压火、给料机堵塞等异常工况排除掉,为了避免预测模型的参数之间量纲和数量级的不同对模型性能造成的不良影响,训练样本输入变量均经过归一化处理后映射到[0,1]区间内,得到标准化后的训练样本x*(m×n)。预处理过程采用以下步骤进行:
1.1)根据拉伊达准则,剔除训练样本x(m×n)中的野值;
1.2)剔除锅炉停炉运行工况,锅炉停炉时炉膛给煤机和给料机的开度为零,并且炉膛中温度接近常温;
1.3)剔除炉膛压火运行状况,锅炉压火时一次风机、二次风机引风机炉膛给煤机和给料机的开度为零,但是炉膛密相区的温度维持在350℃~450℃;
1.4)剔除给料机堵塞工况,给料机堵塞需要运行人员通过给料口的摄像头拍摄的画面对给料情况进行判断,给料机堵塞时,运行人员会显著地调高给料机的开度,反映在运行数据上,即给料机的开度大于35%;
1.5)数据归一化处理。按照式(1)将数据变量映射到[01]的区间内。
式中xj表示第j变量所组成的向量,min()表示最小值,max()表示最大值。
专家知识库模块。采用滚动时间窗口的方法不断更新训练样本,使得训练样本始终保持在最新的状态上,滚动时间窗口方法是指从当前时间开始,回溯l(单位秒)长度的时间尺寸。
模型更新判定模块。检测当前预测模型的性能,当相对预测误差超过±5%时,则判定模型需要进行更新。
智能建模模块。智能建模模块是烟气含氧量预测系统的核心部分,该模块先利用多种群遗传粒子群算法对svm模型的惩罚参数c和核参数g进行寻优,然后将得到的最优参数组合赋给svm模型,并以此为基础进行训练。算法步骤如下:
2.1)初始化算法参数。多种群粒子群算法的最大寻优代数tmax、最大惯性权重ωmax、最小惯性权重ωmin,速度更新系数r1、r2、r3、r4,种群数量pop、单个种群的粒子数量ind、移民率pi、交叉概率pc、变异概率pm、遗传代沟pe、遗传操作频度pg。
2.2)初始化种群。采用实数编码的方式,将svm模型的惩罚参数c和核参数g有序编码在一个粒子当中,并将每个权值阈值随机生成为[0,200]之间的一个实数。
2.3)初始化个体极值和群体极值。将每个粒子中包含的参数组合赋给svm模型,并结合训练样本进行学习训练,利用训练得到的预测模型计算烟气含氧量预测值
每个粒子的计算得到的适应度值作为该粒子本身的初始化极值,每个种群的当中mse最低的值作为群体极值。
2.4)更新粒子。根据最新的个体极值和全局极值,按照(3)式和(4)式更新粒子的速度vid(t)和位置xid(t):
vid(t+1)=ωvid(t)+c1r1(pid-xid(t))+c2r2(pgd-xid(t))(3)
xid(t+1)=xid(t)+vid(t+1)(4)
式中,t是粒子群优化算法的寻优代数,r1,r2是[0,1]之间的随机数,pid是指是指第i个粒子迄今为止寻搜索到最优位置,pgd指该种群迄今为止搜索最优位置。更进一步,为了改善基本粒子群算法容易陷入局部极值和收敛速度慢的缺陷,在pso算法的基础上引进了动态加速常数c1、c2和惯性权重ω:
其中,tmax为最大寻优代数,ωmax为最大惯性权重,ωmin为最小惯性权重,r1、r2、r3、r4为常数。
2.5)判断是否需要进行遗传操作。按照遗传操作频度pg进行,通常每pg代进行一次遗传操作。若要进行遗传操作则执行步骤2.6),否则执行步骤2.7)
2.6)执行遗传操作。遗传操作包括选择、交叉、变异、留优,具体如下。选择:像轮盘赌一样计算选择概率,等距离的选择个体,设n为需要选择的个体数目,选择指针的距离是1/n,第一个选择指针的位置由[0,1/n]区间内的随机数决定;交叉:采用算术重组的方法,即两个个体通过线性组合产生新的个体。假设在两个个体
式中λ1和λ2为(0,1)之间的实数,且λ1+λ2=1;变异:采取均匀性变异,假设s=(v1,v2,...,vn)是父代,z=(z1,z2,...,zn)是变异产生的后代。现在父代向量中随机地选择一个分量,假设是第k个,然后在其定义区间[ak,bk]中均匀随机地取一个数v'k代替vk以得到zk;留优:采用保留父代精英个体的策略,根据父代染色体的目标函数值,用过渡代染色体替换父代中目标函数值排名后pe×100%的染色体,pe为替换率(遗传代沟),如此,父代中部分最优的个体得以保留,不会因为选择、交叉、变异等运算消失。
2.7)粒子适应度值计算。按照式(2)计算更新之后粒子的适应度值。
2.8)更新个体极值和群体极值。以适应度值为评价指标,比较当代粒子与上一代粒子之间的适应度值大小,如果当前粒子的适应度值优于上一代,则将当前粒子的位置设置为个体极值,否则个体极值保持不变。同时获取当代所有粒子适应度值最优的粒子,并与上一代最优粒子进行比较,如果当代最优粒子的适应度值优于上一代最优粒子的适应度值,则将当代粒子的最优适应度值设置为全局最优值,否则全局最优值保持不变。
2.9)移民操作。在自然界中,一个物种的不同种群分布在不同的地域,一方面各个种群相对独立地从自然界中争取资源为己所用,不同的地域条件下催发了他们不同的生存模式和进化程度;另一方面,各个种群之间有可能通过迁徙,使彼此之间发生联系,达到互通有无、取长补短、共同进化的目的。本发明采用的多种群(multi-population,mp)遗传粒子群算法正是借鉴了自然界中普遍存在的这一现象。每一次寻优过程中,种群之间采用单向循环迁移的方式进行移民操作,第1个种群中的优秀个体迁往第2个,第2个迁往第3个,以此类推,直到最后一个迁往第一个。种群间的移民率pi=0.04,即表示用源种群中排名前pi×100%的个体替换目标种群当中排名后pi×100%的个体,以此完成种群之间最优知识的交流。
2.10)算法停止条件算法判定。判断是否达到最大迭代次数或者到达预测精度的要求,如果没有达到则返回步骤2.4),利用更新的粒子继续搜索,否则退出搜索,执行步骤2.11)。
2.11)输出最优的参数组合粒子。
2.12)将最优粒子当中的参数组合赋给svm模型,并结合训练样本进行学习。
2.13)验证模型的预测精度。将模型的预测值和实际值进行对比,计算相对预测误差。
2.14)判断相对预测误差是否在±5%以内,如果满足要求则执行步骤2.15),否则返回步骤2.12),重新进行训练。
2.15)输出满足要求的烟气含氧量预测模型。
通讯模块。该模块将满足要求烟气含氧量预测模型传送给函数集散控制系统、生产管理系统。
一种循环流化床生活垃圾焚烧锅炉炉膛出口烟气含氧量预测方法,该方法包括以下步骤:
1)分析循环流化床生活垃圾焚烧锅炉的运行机理和烟气含氧量变化机理,选择垃圾的给料量、给煤量、一次风量、二次风量、床层温度、炉膛稀相区温度和炉膛负压作为烟气含氧量预测模型的输入变量。
2)采集训练样本。按设定的时间间隔从数据库中采集输入变量的历史数据,或者采集指定工况下的运行参数,组成烟气含氧量预测模型输入变量的训练样本矩阵x(m×n),m表示样本个数,n表示变量的个数,同时采集与之对应的烟气含氧量作为模型的输出训练样本y(m×1);
3)数据预处理。对x(m×n)进行粗大误差处理和随机误差处理,以摒除那些并不是反映锅炉正常运行工况的虚假信息,将锅炉停炉、压火、给料机堵塞等异常工况排除掉,为了避免预测模型的参数之间量纲和数量级的不同对模型性能造成的不良影响,训练样本输入变量均经过归一化处理后映射到[0,1]区间内,得到标准化后的输入变量的训练样本x*(m×n)和输出变量的训练样本y*(m×1)。
4)智能算法集成建模。先利用多种群遗传粒子群算法对svm模型的惩罚参数c和核参数g进行寻优,然后将得到的最优参数组合赋给svm模型,并以此为基础进行训练。算法步骤如下:
4.1)初始化算法参数。多种群粒子群算法的最大寻优代数tmax、最大惯性权重ωmax、最小惯性权重ωmin,速度更新系数r1、r2、r3、r4,种群数量pop、单个种群的粒子数量ind、移民率pi、交叉概率pc、变异概率pm、遗传代沟pe、遗传操作频度pg。
4.2)初始化种群。采用实数编码的方式,将svm模型的惩罚参数c和核参数g有序编码在一个粒子当中,并将每个权值阈值随机生成为[0,200]之间的一个实数。
4.3)初始化个体极值和群体极值。将每个粒子中包含的参数组合赋给svm模型,并结合训练样本进行学习训练,利用训练得到的预测模型计算烟气含氧量预测值
每个粒子的计算得到的适应度值作为该粒子本身的初始化极值,每个种群的当中mse最低的值作为群体极值。
4.4)更新粒子。根据最新的个体极值和全局极值,按照(2)式和(3)式更新粒子的速度vid(t)和位置xid(t):
vid(t+1)=ωvid(t)+c1r1(pid-xid(t))+c2r2(pgd-xid(t))(2)
xid(t+1)=xid(t)+vid(t+1)(3)
式中,t是粒子群优化算法的寻优代数,r1,r2是[0,1]之间的随机数,pid是指是指第i个粒子迄今为止寻搜索到最优位置,pgd指该种群迄今为止搜索最优位置。更进一步,为了改善基本粒子群算法容易陷入局部极值和收敛速度慢的缺陷,在pso算法的基础上引进了动态加速常数c1、c2和惯性权重ω:
其中,tmax为最大寻优代数,ωmax为最大惯性权重,ωmin为最小惯性权重,r1、r2、r3、r4为常数。
4.5)判断是否需要进行遗传操作。按照遗传操作频度pg进行,通常每pg代进行一次遗传操作。若要进行遗传操作则执行步骤4.6),否则执行步骤4.7)
4.6)执行遗传操作。遗传操作包括选择、交叉、变异、留优,具体如下。选择:像轮盘赌一样计算选择概率,等距离的选择个体,设n为需要选择的个体数目,选择指针的距离是1/n,第一个选择指针的位置由[0,1/n]区间内的随机数决定;交叉:采用算术重组的方法,即两个个体通过线性组合产生新的个体。假设在两个个体
式中λ1和λ2为(0,1)之间的实数,且λ1+λ2=1;变异:采取均匀性变异,假设s=(v1,v2,...,vn)是父代,z=(z1,z2,...,zn)是变异产生的后代。现在父代向量中随机地选择一个分量,假设是第k个,然后在其定义区间[ak,bk]中均匀随机地取一个数v'k代替vk以得到zi;留优:采用保留父代精英个体的策略,根据父代个染色体的目标函数值,用过渡代染色体替换父代中目标函数值排名后pe×100%的染色体,pe为替换率(遗传代沟),如此,父代中部分最优的个体得以保留,不会因为选择、交叉、变异等运算消失。
4.7)粒子适应度值计算。按照式(1)计算更新之后粒子的适应度值。
4.8)更新个体极值和群体极值。以适应度值为评价指标,比较当代粒子与上一代粒子之间的适应度值大小,如果当前粒子的适应度值优于上一代,则将当前粒子的位置设置为个体极值,否则个体极值保持不变。同时获取当代所有粒子适应度值最优的粒子,并与上一代最优粒子进行比较,如果当代最优粒子的适应度值优于上一代最优粒子的适应度值,则将当代粒子的最优适应度值设置为全局最优值,否则全局最优值保持不变。
4.9)移民操作。在自然界中,一个物种的不同种群分布在不同的地域,一方面各个种群相对独立地从自然界中争取资源为己所用,不同的地域条件下催发了他们不同的生存模式和进化程度;另一方面,各个种群之间有可能通过迁徙,使彼此之间发生联系,达到互通有无、取长补短、共同进化的目的。本专利采用的多种群(multi-population,mp)遗传粒子群算法正是借鉴了自然界中普遍存在的这一现象。每一次寻优过程中,种群之间采用单向循环迁移的方式进行移民操作,第1个种群中的优秀个体迁往第2个,第2个迁往第3个,以此类推,直到最后一个迁往第一个。种群间的移民率pi=0.04,即表示用源种群中排名前pi×100%的个体替换目标种群当中排名后pi×100%的个体,以此完成种群之间最优知识的交流。
4.10)算法停止条件算法判定。判断是否达到最大迭代次数或者到达预测精度的要求,如果没有达到则返回步骤4.4),利用更新的粒子继续搜索,否则退出搜索,执行步骤4.11)。
4.11)输出最优的参数组合粒子。
4.12)将最优粒子当中的参数组合赋给svm模型,并结合训练样本进行学习。
4.13)验证模型的预测精度。将模型的预测值和实际值进行对比,计算相对预测误差。
414)判断相对预测误差是否在±5%以内,如果满足要求则执行步骤4.15),否则返回步骤4.12),重新进行训练。
4.15)输出满足要求的烟气含氧量预测模型。
5)模型自适应更新。当烟气含氧量与模型预测值的误差超过±5%时,立即更新模型。
本发明的有益效果是:在利用循环流化床生活垃圾焚烧锅炉的运行机理和运行历史数据中隐含的知识的基础上,采用支持向量机算法和多种群遗传粒子群优化算法集成建模的方法,构建了一种快速经济且自适应更新的系统和方法对锅炉炉膛出口烟气含氧量进行实时预测,避开了繁琐复杂的机理建模工作。其中,利用svm算法的非线性动力学特性、泛化能力和实时预测能力来表征烟气含氧量的动态变化特性,为运行人员和设计人员掌握了解烟气含氧量的变化特性提供新的途径;利用粒子群优化算法对svm算法惩罚参数c和核参数g进行优化,提高模型的泛化能力;引入多种群迁移机制,提高粒子群优化算法解的多样性,减少粒子群算法寻优算陷入局部最优的可能性;引入选择、交叉、变异等遗传操作,融合遗传算法并行搜索的特性,使其能够搜索到多个局部最优点,大大提高了全局搜索能力和搜索速度,同时能够有效地利用历史信息来推测下一代期望性能有所提高的寻优点集;异构的计算环境,大大提高了模型构建效率,使计算机资源得打了最大的发挥。整个建模过程逻辑清晰,建模自动化程度高,易于掌握和推广。训练良好的烟气含氧量预测模型可以用于指导运行人员的实际运行过程,可以服务那些基于模型的控制算法,或者作为软测量仪表与烟气含氧量硬件测量系统相互补充校核。
附图说明
图1是本发明所提出的系统的结构图。
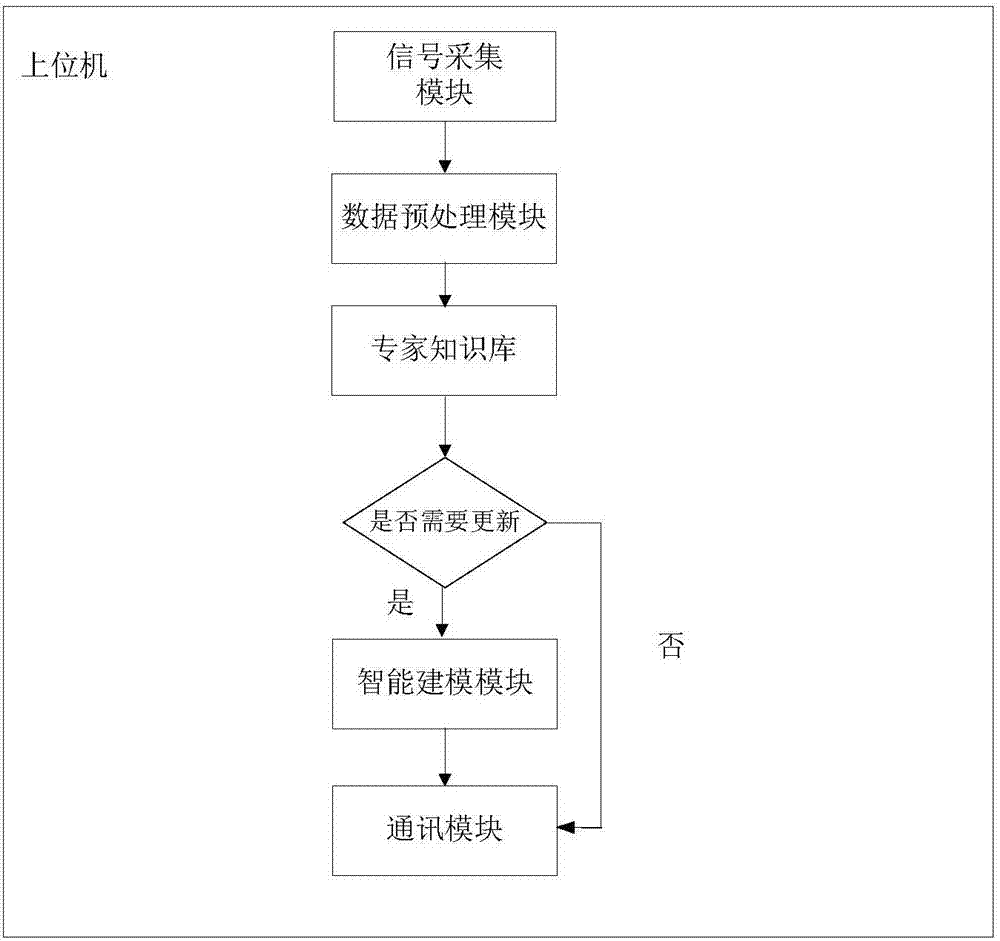
图2是本发明所提出的上位机系统的结构图。
图3是本发明所提出的智能建模方法的流程图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
实施例1
参照图1、图2、图3,本发明提供的一种循环流化床生活垃圾焚烧锅炉炉膛出口烟气含氧量预测系统,包括循环流化床生活垃圾焚烧锅炉,以及用于该锅炉运行控制的集散控制系统,数据通讯接口,数据库以及上位机。数据库通过数据通讯接口从集散控制系统中读取数据,并用于上位机的训练学习和测试,上位机通过数据通讯接口与集散控制系统进行数据交换,所述的上位机包括在线学习、在线更新、验证部分和在线预测部分。具体包括:
信号采集模块。该模块用于采集cfb生活垃圾焚烧锅炉在焚烧指定生活垃圾时的运行工况状态参数和操作变量,并组成垃圾热值预测模型输入变量的训练样本矩阵x(m×n),m表示样本个数,n表示变量的个数;
数据预处理模块。对x(m×n)进行粗大误差处理和随机误差处理,以摒除那些并不是反映锅炉正常运行工况的虚假信息,将锅炉停炉、压火、给料机堵塞等异常工况排除掉,为了避免预测模型的参数之间量纲和数量级的不同对模型性能造成的不良影响,训练样本输入变量均经过归一化处理后映射到[0,1]区间内,得到标准化后的训练样本x*(m×n)。预处理过程采用以下步骤进行:
1.1)根据拉伊达准则,剔除训练样本x(m×n)中的野值;
1.2)剔除锅炉停炉运行工况,锅炉停炉时炉膛给煤机和给料机的开度为零,并且炉膛中温度接近常温;
1.3)剔除炉膛压火运行状况,锅炉压火时一次风机、二次风机引风机炉膛给煤机和给料机的开度为零,但是炉膛密相区的温度维持在350℃~450℃;
1.4)剔除给料机堵塞工况,给料机堵塞需要运行人员通过给料口的摄像头拍摄的画面对给料情况进行判断,给料机堵塞时,运行人员会显著地调高给料机的开度,反映在运行数据上,即给料机的开度大于35%;
1.5)数据归一化处理。按照式(1)将数据变量映射到[01]的区间内。
式中xj表示第j变量所组成的向量,min()表示最小值,max()表示最大值。
专家知识库模块。采用滚动时间窗口的方法不断更新训练样本,使得训练样本始终保持在最新的状态上,滚动时间窗口方法是指从当前时间开始,回溯l(单位秒)长度的时间尺寸。
模型更新判定模块。检测当前预测模型的性能,当相对预测误差超过±5%时,则判定模型需要进行更新。
智能建模模块。智能建模模块是烟气含氧量预测系统的核心部分,该模块先利用多种群遗传粒子群算法对svm模型的惩罚参数c和核参数g进行寻优,
然后将得到的最优参数组合赋给svm模型,并以此为基础进行训练。算法步骤如下:
2.1)初始化算法参数。多种群粒子群算法的最大寻优代数tmax=100、最大惯性权重ωmax=1.4、最小惯性权重ωmin=0.4,速度更新系数r1=1、r2=0.5、r3=6、r4=2,种群数量pop=5、单个种群的粒子数量ind=20、移民率pi=0.04、交叉概率pc=0.8、变异概率pm=0.04、遗传代沟pe=0.05、遗传操作频度pg=2。
2.2)初始化种群。采用实数编码的方式,将svm模型的惩罚参数c和核参数g有序编码在一个粒子当中,并将每个权值阈值随机生成为[0,200]之间的一个实数。
2.3)初始化个体极值和群体极值。将每个粒子中包含的参数组合赋给svm模型,并结合训练样本进行学习训练,svm算法的描述如下:
假设svm模型的训练样本集是(xi,yi),i=1,…,n,x∈rd,y∈r,模型输入输出变量之间的关系如下:
式中,应用非线性函数
为了保证模型有解,考虑到测量数据难以避免地含有噪声,需要对理想状况下的线性回归函数(2)进行修正,即引入ε线性不敏感损失函数和惩罚因子c和数值上大于零的松弛变量ξi、
引入拉格朗日乘子,以及利用映射函数φ组成满足mercer条件的核函数k(xi,x),根据kkt条件,可以达到最优的函数拟合方程
其中,xi为支持向量,nsv为支持向量的个数。核函数的选择对svm模型的泛化能力有较为显著的影响。选用灵活性和通用性较高的高斯径向基函数(rbf)作为核函数,其表达式为:
k(xi,x)=exp(-g·||xi-x||2)(6)
式中,g为核参数,g>0;||·||2为2-范数。
利用训练得到的预测模型计算烟气含氧量预测值
每个粒子的计算得到的适应度值作为该粒子本身的初始化极值,每个种群的当中mse最低的值作为群体极值。
2.4)更新粒子。根据最新的个体极值和全局极值,按照(8)式和(9)式更新粒子的速度vid(t)和位置xid(t):
vid(t+1)=ωvid(t)+c1r1(pid-xid(t))+c2r2(pgd-xid(t))(8)
xid(t+1)=xid(t)+vid(t+1)(9)
式中,t是粒子群优化算法的寻优代数,r1,r2是[0,1]之间的随机数,pid是指是指第i个粒子迄今为止寻搜索到最优位置,pgd指该种群迄今为止搜索最优位置。更进一步,为了改善基本粒子群算法容易陷入局部极值和收敛速度慢的缺陷,在pso算法的基础上引进了动态加速常数c1、c2和惯性权重ω:
其中,tmax为最大寻优代数,ωmax为最大惯性权重,ωmin为最小惯性权重,r1、r2、r3、r4为常数。
2.5)判断是否需要进行遗传操作。按照遗传操作频度pg进行,通常每pg代进行一次遗传操作。若要进行遗传操作则执行步骤2.6),否则执行步骤2.7)
2.6)执行遗传操作。遗传操作包括选择、交叉、变异、留优,具体如下。选择:像轮盘赌一样计算选择概率,等距离的选择个体,设n为需要选择的个体数目,选择指针的距离是1/n,第一个选择指针的位置由[0,1/n]区间内的随机数决定;交叉:采用算术重组的方法,即两个个体通过线性组合产生新的个体。假设在两个个体
式中λ1和λ2为(0,1)之间的实数,且λ1+λ2=1;变异:采取均匀性变异,假设s=(v1,v2,...,vn)是父代,z=(z1,z2,...,zn)是变异产生的后代。现在父代向量中随机地选择一个分量,假设是第k个,然后在其定义区间[ak,bk]中均匀随机地取一个数v'k代替vk以得到zi;留优:采用保留父代精英个体的策略,根据父代染色体的目标函数值,用过渡代染色体替换父代中目标函数值排名后pe×100%的染色体,pe为替换率(遗传代沟),如此,父代中部分最优的个体得以保留,不会因为选择、交叉、变异等运算消失。
2.7)粒子适应度值计算。按照式(7)计算更新之后粒子的适应度值。
2.8)更新个体极值和群体极值。以适应度值为评价指标,比较当代粒子与上一代粒子之间的适应度值大小,如果当前粒子的适应度值优于上一代,则将当前粒子的位置设置为个体极值,否则个体极值保持不变。同时获取当代所有粒子适应度值最优的粒子,并与上一代最优粒子进行比较,如果当代最优粒子的适应度值优于上一代最优粒子的适应度值,则将当代粒子的最优适应度值设置为全局最优值,否则全局最优值保持不变。
2.9)移民操作。在自然界中,一个物种的不同种群分布在不同的地域,一方面各个种群相对独立地从自然界中争取资源为己所用,不同的地域条件下催发了他们不同的生存模式和进化程度;另一方面,各个种群之间有可能通过迁徙,使彼此之间发生联系,达到互通有无、取长补短、共同进化的目的。本专利采用的多种群(multi-population,mp)遗传粒子群算法正是借鉴了自然界中普遍存在的这一现象。每一次寻优过程中,种群之间采用单向循环迁移的方式进行移民操作,第1个种群中的优秀个体迁往第2个,第2个迁往第3个,以此类推,直到最后一个迁往第一个。种群间的移民率pi=0.04,即表示用源种群中排名前pi×100%的个体替换目标种群当中排名后pi×100%的个体,以此完成种群之间最优知识的交流。
2.10)算法停止条件算法判定。判断是否达到最大迭代次数或者到达预测精度的要求,如果没有达到则返回步骤2.4),利用更新的粒子继续搜索,否则退出搜索,执行步骤2.11)。
2.11)输出最优的参数组合粒子。
2.12)将最优粒子当中的参数组合赋给svm模型,并结合训练样本进行学习。
2.13)验证模型的预测精度。将模型的预测值和实际值进行对比,计算相对预测误差。
2.14)判断相对预测误差是否在±5%以内,如果满足要求则执行步骤2.15),否则返回步骤2.12),重新进行训练。
2.15)输出满足要求的烟气含氧量预测模型。
通讯模块。该模块将满足要求烟气含氧量预测模型传送给函数集散控制系统、生产管理系统。
实施例2
参照图1、图2、图3,本发明提供的一种循环流化床生活垃圾焚烧锅炉炉膛出口烟气含氧量预测方法,该方法包括以下步骤:
1)分析循环流化床生活垃圾焚烧锅炉的运行机理和烟气含氧量变化机理,选择垃圾的给料量、给煤量、一次风量、二次风量、床层温度、炉膛稀相区温度和炉膛负压作为烟气含氧量预测模型的输入变量。
国内的城市生活垃圾多为混合收集,导致入厂、入炉垃圾成分较为复杂,一般主要包括厨余垃圾、纸、塑料、橡胶、织物、木头、竹子以及无机物等主要成分,表现出低热值、高水分和波动性较大的特征。为了保证循环流化床垃圾焚烧锅炉的稳定燃烧,通常会添加煤作为辅助燃料。垃圾在循环流化床中的燃烧是一个十分复杂的剧烈物理化学变化过程,垃圾在进入炉膛之后会经历几个过程:干燥加热、挥发分析出及燃烧、焦炭燃烧。垃圾中质轻易碎的组分如纸纸张、塑料以及细颗粒等会在流化风的作用下进入炉膛上部,经历干燥、挥发分的析出及燃烧以及残炭的燃烧等一系列过程;而密度较大、含水率高以及颗粒尺寸较大的组分如木头、厨余垃圾等终端速度大于流化速度的组分会落入密相区,并在密相区中被床料加热、燃烧,与煤的热量释放规律不同,垃圾中高水分低热值的组分会在密相区中吸收大量的热,而大量的挥发分在悬浮段燃烧。
cfb炉膛出口烟气含氧量是由炉膛中的温度场分布状况和有机挥发分浓度的分布状况决定的。给煤量、给料量和一二次风量共同决定了温度场分布、氧气浓度分布和有机挥发分浓度分布,他们通过床层温度、炉膛稀相区温度和烟气含氧量反映出来。尤其需要注意的是,在实际运行过程中,会出现温度场、组分场分布不均的情况,而通过烟气氧量测点和炉膛温度测点无法完全获知,而炉膛负压的波动情况可以在一定程度上反映它们的波动情况,因此也将它作为模型的输入变量之一。
2)采集训练样本。按设定的时间间隔从数据库中采集输入变量的历史数据,或者采集指定工况下的运行参数,组成烟气含氧量预测模型输入变量的训练样本矩阵x(m×n),m表示样本个数,n表示变量的个数,同时采集与之对应的烟气含氧量作为模型的输出训练样本y(m×1);
3)数据预处理。对x(m×n)进行粗大误差处理和随机误差处理,以摒除那些并不是反映锅炉正常运行工况的虚假信息,将锅炉停炉、压火、给料机堵塞等异常工况排除掉,为了避免预测模型的参数之间量纲和数量级的不同对模型性能造成的不良影响,训练样本输入变量均经过归一化处理后映射到[0,1]区间内,得到标准化后的输入变量的训练样本x*(m×n)和输出变量的训练样本y*(m×1)。
4)智能算法集成建模。先利用多种群遗传粒子群算法对svm模型的惩罚参数c和核参数g进行寻优,然后将得到的最优参数组合赋给svm模型,并以此为基础进行训练。算法步骤如下:
4.1)初始化算法参数。多种群粒子群算法的最大寻优代数tmax=100、最大惯性权重ωmax=1.4、最小惯性权重ωmin=0.4,速度更新系数r1=1、r2=0.5、r3=6、r4=2,种群数量pop=5、单个种群的粒子数量ind=20、移民率pi=0.04、交叉概率pc=0.8、变异概率pm=0.04、遗传代沟pe=0.05、遗传操作频度pg=2。
4.2)初始化种群。采用实数编码的方式,将svm模型的惩罚参数c和核参数g有序编码在一个粒子当中,并将每个权值阈值随机生成为[0,200]之间的一个实数。
4.3)初始化个体极值和群体极值。将每个粒子中包含的参数组合赋给svm模型,并结合训练样本进行学习训练,svm算法的描述如下:
假设svm模型的训练样本集是(xi,yi),i=1,…,n,x∈rd,y∈r,模型输入输出变量之间的关系如下:
式中,应用非线性函数
为了保证模型有解,考虑到测量数据难以避免地含有噪声,需要对理想状况下的线性回归函数(1)进行修正,即引入ε线性不敏感损失函数和惩罚因子c和数值上大于零的松弛变量ξi、
引入拉格朗日乘子,以及利用映射函数φ组成满足mercer条件的核函数k(xi,x),根据kkt条件,可以达到最优的函数拟合方程
其中,xi为支持向量,nsv为支持向量的个数。核函数的选择对svm模型的泛化能力有较为显著的影响。选用灵活性和通用性较高的高斯径向基函数(rbf)作为核函数,其表达式为:
k(xi,x)=exp(-g·||xi-x||2)(5)
式中,g为核参数,g>0;||·||2为2-范数。
利用训练得到的预测模型计算烟气含氧量预测值
每个粒子的计算得到的适应度值作为该粒子本身的初始化极值,每个种群的当中mse最低的值作为群体极值。
4.4)更新粒子。根据最新的个体极值和全局极值,按照(7)式和(8)式更新粒子的速度vid(t)和位置xid(t):
vid(t+1)=ωvid(t)+c1r1(pid-xid(t))+c2r2(pgd-xid(t))(7)
xid(t+1)=xid(t)+vid(t+1)(8)
式中,t是粒子群优化算法的寻优代数,r1,r2是[0,1]之间的随机数,pid是指是指第i个粒子迄今为止寻搜索到最优位置,pgd指该种群迄今为止搜索最优位置。更进一步,为了改善基本粒子群算法容易陷入局部极值和收敛速度慢的缺陷,在pso算法的基础上引进了动态加速常数c1、c2和惯性权重ω:
其中,tmax为最大寻优代数,ωmax为最大惯性权重,ωmin为最小惯性权重,r1、r2、r3、r4为常数。
4.5)判断是否需要进行遗传操作。按照遗传操作频度pg进行,通常每pg代进行一次遗传操作。若要进行遗传操作则执行步骤4.6),否则执行步骤4.7)
4.6)执行遗传操作。遗传操作包括选择、交叉、变异、留优,具体如下。选择:像轮盘赌一样计算选择概率,等距离的选择个体,设n为需要选择的个体数目,选择指针的距离是1/n,第一个选择指针的位置由[0,1/n]区间内的随机数决定;交叉:采用算术重组的方法,即两个个体通过线性组合产生新的个体。假设在两个个体
式中λ1和λ2为(0,1)之间的实数,且λ1+λ2=1;变异:采取均匀性变异,假设s=(v1,v2,...,vn)是父代,z=(z1,z2,...,zn)是变异产生的后代。现在父代向量中随机地选择一个分量,假设是第k个,然后在其定义区间[ak,bk]中均匀随机地取一个数v'k代替vk以得到zi;留优:采用保留父代精英个体的策略,根据父代染色体的目标函数值,用过渡代染色体替换父代中目标函数值排名后pe×100%的染色体,pe为替换率(遗传代沟),如此,父代中部分最优的个体得以保留,不会因为选择、交叉、变异等运算消失。
4.7)粒子适应度值计算。按照式(6)计算更新之后粒子的适应度值。
4.8)更新个体极值和群体极值。以适应度值为评价指标,比较当代粒子与上一代粒子之间的适应度值大小,如果当前粒子的适应度值优于上一代,则将当前粒子的位置设置为个体极值,否则个体极值保持不变。同时获取当代所有粒子适应度值最优的粒子,并与上一代最优粒子进行比较,如果当代最优粒子的适应度值优于上一代最优粒子的适应度值,则将当代粒子的最优适应度值设置为全局最优值,否则全局最优值保持不变。
4.9)移民操作。在自然界中,一个物种的不同种群分布在不同的地域,一方面各个种群相对独立地从自然界中争取资源为己所用,不同的地域条件下催发了他们不同的生存模式和进化程度;另一方面,各个种群之间有可能通过迁徙,使彼此之间发生联系,达到互通有无、取长补短、共同进化的目的。本专利采用的多种群(multi-population,mp)遗传粒子群算法正是借鉴了自然界中普遍存在的这一现象。每一次寻优过程中,种群之间采用单向循环迁移的方式进行移民操作,第1个种群中的优秀个体迁往第2个,第2个迁往第3个,以此类推,直到最后一个迁往第一个。种群间的移民率pi=0.04,即表示用源种群中排名前pi×100%的个体替换目标种群当中排名后pi×100%的个体,以此完成种群之间最优知识的交流。
4.10)算法停止条件算法判定。判断是否达到最大迭代次数或者到达预测精度的要求,如果没有达到则返回步骤4.4),利用更新的粒子继续搜索,否则退出搜索,执行步骤4.11)。
4.11)输出最优的参数组合粒子。
4.12)将最优粒子当中的参数组合赋给svm模型,并结合训练样本进行学习。
4.13)验证模型的预测精度。将模型的预测值和实际值进行对比,计算相对预测误差。
414)判断相对预测误差是否在±5%以内,如果满足要求则执行步骤4.15),否则返回步骤4.12),重新进行训练。
4.15)输出满足要求的烟气含氧量预测模型。
5)模型自适应更新。当烟气含氧量与模型预测值的误差超过±5%时,立即更新模型。
- 还没有人留言评论。精彩留言会获得点赞!