风力发电机组的聚类方法和设备与流程
本发明涉及风力发电领域。更具体地讲,涉及一种风力发电机组的聚类方法和设备。
背景技术:
随着风电行业的快速发展,风电场的建设已经从平坦地形扩展到复杂地形,传统的以整个风电场为一个簇采用统一的标准或指标评估风电场中各个机组的运行状态或出力状况已经不符合实际情况。因为在复杂地形条件下,在相同的机组配置参数下,由于不同风力发电机组间的运行环境与运行状态各有差异,如果此时用同一标准推测整个风场的其他风力发电组也存在同样的运行状态或潜在故障则不合理。
在现有的风力发电机组的聚类方法中,一般从构建机组等值模型出发,以求用更少的模型表征整个风电场的某些特性,模型输入单一,无法适应复杂环境中的风力发电机组聚类分析。因此,现有的风力发电机组的聚类方法不够合理,聚类结果不够准确。
技术实现要素:
本发明的目的在于提供一种更加有效和准确的风力发电机组的聚类方法和设备,以解决现有的聚类方法中存在理的问题。
根据本发明的一方面,提供一种风力发电机组的聚类方法所述聚类方法包括如下步骤:获取风电场中的每台风力发电机组的数据;提取所述每台风力发电机组的数据中的预定数据,以形成每台风力发电机组的数据集合,其中,所述预定数据包括:每台风力发电机组的控制参数数据、地理位置数据、环境数据和运行数据中的至少两种数据;通过聚类算法对风电场中的所有风力发电机组的数据集合进行聚类,以实现对风力发电机组的聚类。
可选地,所述控制参数数据包括以下参数中的至少一种参数:控制器关键参数、机组滤波器参数和机组配置参数。
可选地,所述控制参数数据通过获取每个风力发电机组的机组初始化文件的版本号来获取,其中,所述机组初始化文件的版本号中包括用于指示所述控制参数数据的字符。
可选地,当所述预定数据包括所述控制参数数据时,对所述预定数据进行预处理,具体包括:对所述版本号进行编码以得到作为数据集合的数据。
可选地,所述环境数据包括预定时间段的风资源数据、环境湿度和/或环境温度。
可选地,所述预定时间段的风资源数据包括预定时间段的风速,其中,当所述预定数据包括所述预定时间段的风资源数据时,对所述风资源数据进行预处理,具体包括:根据预定时间段的风速计算得到预定时间段内各个风速的出现次数以及各个风速的湍流强度,以作为数据集合的数据。
可选地,所述运行数据包括预定时间段的桨距角数据。
可选地,当所述预定数据包括所述运行数据时,对运行数据进行预处理,具体包括:根据预定时间段的桨距角数据计算得到预定时间段内各个桨距角的出现次数,以作为数据集合的数据。
可选地,在将所有风力发电机组的数据集合进行聚类的步骤之前,还包括:对每个风力发电机组的数据集合进行维数约减,其中,通过将维数约减后的所有风力发电机组的数据集合进行聚类来对风力发电机组进行聚类。
可选地,所述聚类方法还包括:验证所有风力发电机组的数据集合之间是否存在本征簇,其中,当存在本征簇时,将所有风力发电机组的数据集合进行聚类。
可选地,在验证本征簇的步骤中采用霍普金斯统计方法验证所有风力发电机组的数据集合之间是否存在本征簇,其中,当霍普金斯统计结果小于预定阈值时,存在本征簇。
可选地,通过聚类算法对风电场中的所有风力发电机组的数据集合进行聚类的步骤包括:确定用于聚类的最优聚类个数和用于聚类的最优聚类中心;根据确定的用于聚类的最优聚类个数和用于聚类的最优聚类中心,将所有风力发电机组的数据集合进行聚类。
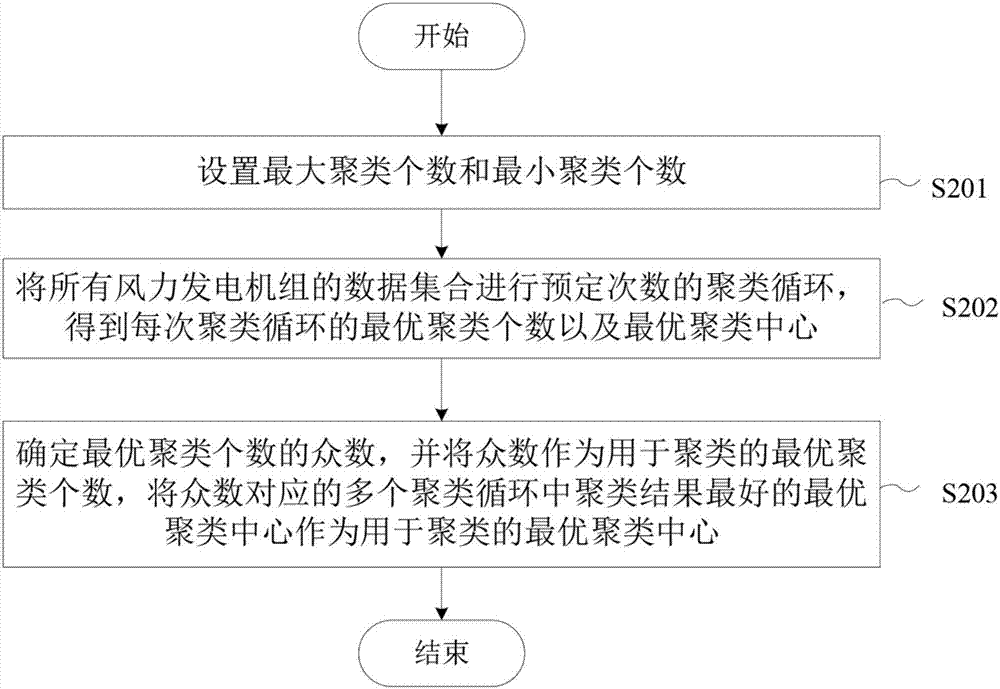
可选地,确定用于聚类的最优聚类个数和最优聚类中心的步骤包括:设置最大聚类个数和最小聚类个数;将所有风力发电机组的数据集合进行预定次数的聚类循环,得到每次聚类循环的最优聚类个数以及最优聚类中心,其中,在每次聚类循环中,分别根据最小聚类个数至最大聚类个数之间的每个聚类个数,对所有风力发电机组的数据集合进行聚类,得到每个聚类个数对应的聚类结果以及聚类中心,评价每个聚类个数对应的聚类结果,将聚类结果最好的聚类个数作为每次聚类循环的最优聚类个数;确定预定次数的聚类循环中最优聚类个数的众数,并将确定的众数作为用于聚类的最优聚类个数,以及将确定的众数对应的多个聚类循环中聚类结果最好的最优聚类中心作为用于聚类的最优聚类中心。
可选地,采用改进的K均值算法对所有风力发电机组的数据集合进行聚类,其中,所述改进的K均值算法将距离最远的样本作为初始聚类中心。
根据本发明的另一方面提供一种风力发电机组的聚类设备,所述聚类设备包括:获取单元,获取风电场中的每台风力发电机组的数据;提取单元,提取所述每台风力发电机组的数据中的预定数据,以形成每台风力发电机组的数据集合,其中,所述预定数据包括:每台风力发电机组的控制参数数据、地理位置数据、环境数据和运行数据中的至少两种数据;聚类单元,通过聚类算法对风电场中的所有风力发电机组的数据集合进行聚类,以实现对风力发电机组的聚类。
可选地,所述控制参数数据包括以下参数中的至少一种参数:控制器关键参数、机组滤波器参数和机组配置参数。
可选地,所述控制参数数据通过获取每个风力发电机组的机组初始化文件的版本号来获取,其中,所述机组初始化文件的版本号中包括用于指示所述控制参数数据的字符。
可选地,当所述预定数据包括所述控制参数数据时,提取单元对所述预定数据进行预处理,具体包括:提取单元对所述版本号进行编码以得到作为数据集合的数据。
可选地,所述环境数据包括预定时间段的风资源数据、环境湿度和/或环境温度。
可选地,所述预定时间段的风资源数据包括预定时间段的风速,其中,当所述预定数据包括所述预定时间段的风资源数据时,提取单元对所述风资源数据进行预处理,具体包括:提取单元根据预定时间段的风速计算得到预定时间段内各个风速的出现次数以及各个风速的湍流强度,以作为数据集合的数据。
可选地,所述运行数据包括预定时间段的桨距角数据。
可选地,当所述预定数据包括所述运行数据时,提取单元对运行数据进行预处理,具体包括:提取单元根据预定时间段的桨距角数据计算得到预定时间段内各个桨距角的出现次数,以作为数据集合的数据。
可选地,所述聚类设备还包括:维数约减单元,在聚类单元将所有风力发电机组的数据集合进行聚类之前,对每台风力发电机组的数据集合进行维数约减,其中,聚类单元通过将维数约减后的所有风力发电机组的数据集合进行聚类来对风力发电机组进行聚类。
可选地,所述聚类设备还包括:本征簇验证单元,验证所有风力发电机组的数据集合之间是否存在本征簇,其中,当存在本征簇时,聚类单元将所有风力发电机组的数据集合进行聚类。
可选地,本征簇验证单元采用霍普金斯统计方法验证所有风力发电机组的数据集合之间是否存在本征簇,其中,当霍普金斯统计结果小于预定阈值时,存在本征簇。
可选地,聚类单元包括:确定子单元,确定用于聚类的最优聚类个数和用于聚类的最优聚类中心;聚类子单元,根据确定用于的最优聚类个数和用于聚类的最优聚类中心,将所有风力发电机组的数据集合进行聚类。
可选地,确定子单元包括:设置模块,设置最大聚类个数和最小聚类个数;聚类循环模块,将所有风力发电机组的数据集合进行预定次数的聚类循环,得到每次聚类循环的最优聚类个数以及最优聚类中心,其中,在每次聚类循环中,分别根据最小聚类个数至最大聚类个数之间的每个聚类个数,对所有风力发电机组的数据集合进行聚类,得到每个聚类个数对应的聚类结果以及聚类中心,评价每个聚类个数对应的聚类结果,将聚类结果最好的聚类个数作为每次聚类循环的最优聚类个数;众数确定模块,确定预定次数的聚类循环中最优聚类个数的众数,并将确定的众数作为用于聚类的最优聚类个数,以及将确定的众数对应的多个聚类循环中聚类结果最好的最优聚类中心作为用于聚类的最优聚类中心。
可选地,聚类单元采用改进的K均值算法对所有风力发电机组的数据集合进行聚类,其中,所述改进的K均值算法将距离最远的样本作为初始聚类中心。
根据本发明的实施例的风力发电机组的聚类方法和设备,根据每台风力发电机组的数据集合来对风力发电机组进行聚类,可实现合理的聚类。
此外,根据本发明的实施例的风力发电机组的聚类方法和设备,参考了控制参数数据、地理位置数据、环境数据和运行数据中的至少两种数据,根据多维度的数据综合考虑风力发电机组间的相似情况,聚类更加合理,聚类结果更加准确,为后续的基于聚类的结果进行机组控制提供了精确的数据基础。
附图说明
通过下面结合附图进行的详细描述,本发明的上述和其它目的、特点和优点将会变得更加清楚,其中:
图1示出根据本发明的实施例的风力发电机组的聚类方法的流程图;
图2示出根据本发明的实施例的确定用于聚类的最优聚类个数和最优聚类中心的步骤的流程图;
图3示出根据本发明的实施例的预定次数的聚类循环中各最优聚类个数的频次直方图示例;
图4示出根据本发明的实施例的维数约减中维数与方差值的对应关系图示例;
图5示出根据本发明的实施例的维数约减中维数与累积贡献率的对应关系图示例;
图6示出根据本发明的实施例的风电场中的风电机组分组结果示例;
图7示出根据本发明的实施例的风力发电机组的聚类设备的框图;
图8示出根据本发明的实施例的确定子单元的框图。
具体实施方式
现在,将参照附图更充分地描述不同的示例实施例。
图1示出根据本发明的实施例的风力发电机组的聚类方法的流程图。根据本发明的实施例的风力发电机组的聚类方法可用于对风电场中的风力发电机组进行分组。一个风电场可包括多个风力发电机组。
在步骤S101,获取风电场中的每台风力发电机组的数据。该数据是对风力发电机组的聚类存在影响的各种数据。在本发明的一个优选实施例,每台风力发电机组的数据可包括控制参数数据、地理位置数据、环境数据和运行数据中的至少两种数据。上述各种数据可从存储风力发电机组的数据的数据库中获取。在本发明的上述优选实施例中采用的数据可以实现更准确的风力发电机组的聚类。
控制参数数据为与风力发电机组的控制相关的各种参数数据。在本发明的一个优选实施例,控制参数数据可包括以下参数中至少一种参数:控制器关键参数、机组滤波器参数和机组配置参数。在机组初始化文件的版本号中包括用于指示所述控制参数数据(即,控制器关键参数、机组滤波器参数和机组配置参数)的字符的情况下,可通过获取每台风力发电机组的机组初始化文件的版本号来获取该控制参数数据。该版本号还可包括机组初始化文件的修改日期等,但不限于此。
这里,所述控制器关键参数是指风力发电机组的主要控制器的参数中对机组控制影响较大的参数。机组滤波器参数是风力发电机组的主要滤波器的参数。机组配置参数是指风力发电机组的硬件配置参数。
地理位置数据为指示风力发电机组的地理位置的数据。例如,地理位置数据可包括机组的经纬度和海拔等数据。
环境数据为与风力发电机组所处的环境相关的数据。例如,环境数据可包括以下至少一种:预定时间段的风资源数据、环境湿度和环境温度等,但不仅限于此,例如,所述预定时间段可以是1个月、6个月等且可由用户根据需要而不同地设置。该预定时间段的风资源数据可包括预定时间段的风速、风向等,但不限于此。
运行数据为与风力发电机组的运行情况相关的数据。例如,所述运行数据可包括预定时间段的桨距角数据和/或功率数据,例如,所述预定时间段可以是1个月、6个月等,且可由用户根据需要而不同地设置。需要说明的是,运行数据的预定时间段与上述风资源数据的预定时间段可以相同,也可以不相同。
在步骤S102,提取所述每台风力发电机组的数据中的预定数据,以形成每台风力发电机组的数据集合。所述预定数据可包括每台风力发电机组的控制参数数据、地理位置数据、环境数据和运行数据中的至少两种数据。
优选地,为了清洗数据,减少数据量,可对预定数据中的部分数据进行预处理,获得体现风力发电机组的主要特征的数据,并作为数据集合的数据。
在步骤S102可以针对不同的预定数据进行不同的预处理。
在每台风力发电机组的预定数据包括控制器参数数据,且通过获取每台风力发电机组的机组初始化文件的版本号来获取该控制器参数数据的情况下,可对控制参数数据进行预处理,具体可包括:对该版本号进行编码来得到作为数据集合的数据的用数值表示的版本号。这里,可采用预定的编码规则将标本号编码为用数值表示的版本号。
当所述预定数据包括所述预定时间段的风资源数据时,且所述预定时间段的风资源数据包括预定时间段的风速,对所述风资源数据进行预处理,具体包括:根据预定时间段的风速计算得到预定时间段内各个风速的出现次数以及各个风速的湍流强度,以作为数据集合的数据。这里,可采用现有技术中的各种方法根据预定时间段的风速计算得到预定时间段内各个风速的湍流强度。
在每台风力发电机组的预定数据包括所述运行数据的情况下,且所述运行数据包括预定时间段的桨距角时,对运行数据进行预处理,具体包括:根据预定时间段的桨距角数据计算得到预定时间段内各个桨距角的出现次数,以作为数据集合的数据。
在步骤S102,可将对预定数据中的部分数据进行预处理获得的数据与每台风力发电机组的预定数据中的未被预处理的数据组合成每台风力发电机组的数据集合。未被预处理的数据可包括以下至少一种:环境温度、环境湿度、机组的经纬度、机组的海拔。
在步骤S103,通过聚类算法对风场中的所有风力发电机组的数据集合进行聚类,以实现对风力发电机组的聚类。这里,将每台风力发电机组的数据集合作为一个样本来对所有风力发电机组的数据集合进行聚类。
这里,可采用各种聚类算法来对所有风力发电机组的数据集合进行聚类。例如,可采用以下任一算法来聚类:改进的K均值算法、基于层次聚类和具有噪声的基于密度的聚类算法(DBSCA)。该改进的K均值算法将距离最远的样本作为初始聚类中心。
优选地,为了提高聚类结果的准确性,可先确定用于聚类的最优聚类个数和最优聚类中心;再根据确定用于聚类的最优聚类个数和最优聚类中心,将所有风力发电机组的数据集合进行聚类。在进行聚类时,将用于聚类的最优聚类中心作为聚类中心,将所有风力发电机组的数据集合聚类为用于聚类的最优聚类个数的簇。
图2示出本发明的实施例的确定用于聚类的最优聚类个数和最优聚类中心的步骤的流程图。
在步骤S201,设置最大聚类个数和最小聚类个数。
在步骤S202,将所有风力发电机组的数据集合进行预定次数的聚类循环,得到每次聚类循环的最优聚类个数以及最优聚类中心。这里,在每次聚类循环中,分别根据最小聚类个数至最大聚类个数之间的每个聚类个数,对所有风力发电机组的数据集合进行聚类,得到每个聚类个数对应的聚类结果以及聚类中心,评价每个聚类个数对应的聚类结果,将聚类结果最好的聚类个数作为每次聚类循环的最优聚类个数。
这里,可采用各种聚类算法,来根据所述每个聚类个数,对所有风力发电机组的数据集合进行聚类。例如,可采用以下任一算法来聚类:改进的K均值算法、基于层次聚类和具有噪声的基于密度的聚类算法(DBSCA)。
可采用各种方法来评价每个聚类个数对应的聚类结果。例如,可采用以下任一算法来评价每个聚类个数对应的聚类结果:贝叶斯信息准则(BIC)、间隙统计算法(Gap statistic)和方差比例准则(VRC)等。在采用VRC准则来评价每个聚类个数对应的聚类结果时,VRC准则越大的聚类个数对应的聚类结果越好。
在步骤S203,确定预定次数的聚类循环中最优聚类个数的众数,并将确定的众数作为用于聚类的最优聚类个数,以及将确定的众数对应的多个聚类循环中聚类结果最好的最优聚类中心作为用于聚类的最优聚类中心。该预定次数的聚类循环中最优聚类个数的众数是指,在预定次数的聚类循环中,出现次数最多的最优聚类个数。图3示出根据本发明的实施例的预定次数的聚类循环中各最优聚类个数的频次直方图示例。如图3所示,在预定次数为100次的聚类循环中最优聚类个数为4的情况出现的次数最多,为31次,所以众数为4,用于聚类的最优聚类个数为4。在一个优选的实施例中,为了减少数据量,提高计算效率,在步骤S103之前,可对每台风力发电机组的数据集合进行维数约减。相应地,在步骤S103中,通过将维数约减后的所有风力发电机组的数据集合进行聚类来对风力发电机组进行聚类。
在本实施例中,可采用各种方法来进行维数约减。例如,可采用主成分分析方法(PCA)的来进行维数约减,在该方法中,通过计算方差贡献率的方式实现维数约减,选取累积贡献率大于预定值时对应的维数作为最终的维数约减结果。维数约减后的数据集合保留了未进行维数约减的数据集合的主要信息。图4示出根据本发明的实施例的维数约减中维数与方差值的对应关系图示例。如图4所示,横坐标表示维数约减后的维数,纵坐标表示方差值。图5示出根据本发明的实施例的维数约减中维数与累积贡献率的对应关系图示例。如图5所示,横坐标表示维数约减后的维数,纵坐标表示累积贡献率,选取累积贡献率大于预定值(如0.95)时对应的维数9作为最终的维数约减结果。
在另一个优选的实施例中,为了减少不必要的计算开销,以及使分类结果更加合理,可在步骤S103之前,验证所有风力发电机组的数据集合之间是否存在本征簇。这是由于风电场中的风力发电机组间的运行环境与机组运行状态各有差异,如果在数据集合不存在本征簇时直接聚类,则聚类结果的参考意义很有限,只有当确定存在本征簇的前提下进行聚类,才能使聚类更加合理,且有意义。当存在本征簇时,表示所有风力发电机组的数据集合之间具有不同的簇,可在步骤S103进行聚类分析。如果不存在本征簇时,表示所有风力发电机组的数据集合之间不具有不同的簇,无需进行聚类分析,所有的风力发电机组可视为一组,可免去聚类带来的计算开销。
在本实施例中,可采用各种验证方法来进行本征簇验证。例如,可采用霍普金斯统计方法(Hopkins statistic)、集群趋势的视觉评价方法(Visual Assessment of cluster Tendency)等方法来进行本征簇验证。在采用霍普金斯统计方法来进行本征簇验证的情况下,如果霍普金斯统计结果小于预定阈值时,则存在本征簇。如果霍普金斯统计结果大于或等于预定阈值时,则不存在本征簇,不需要进行聚类分析。
应该理解,在本实施例中,为了减少数据计算量,可验证维数约减后的所有风力发电机组的数据集合之间是否存在本征簇。
图6示出根据本发明的实施例的风电场中的风电机组分组结果示例。如图6所示,该风电场中包括21台风力发电机组,根据本发明的实施例的风力发电机组的聚类方法,将该21台风力发电机组分成了4组。
图7示出根据本发明的实施例的风力发电机组的聚类设备的框图。如图7所示,根据本发明的实施例的风力发电机组的聚类设备包括获取单元701、提取单元702和聚类单元703。
获取单元701获取风电场中的每台风力发电机组的数据。
提取单元702提取所述每台风力发电机组的数据中的预定数据,以形成每台风力发电机组的数据集合。所述预定数据可包括每台风力发电机组的控制参数数据、地理位置数据、环境数据和运行数据中的至少两种数据。
优选地,为了清洗数据,减少数据量,提取单元702可对预定数据中的部分数据进行预处理,获得体现风力发电机组的主要特征的数据,并作为数据集合的数据。
提取单元702可以针对不同的预定数据进行不同的预处理。
在每台风力发电机组的预定数据包括控制器参数数据,且通过获取每台风力发电机组的机组初始化文件的版本号来获取该控制器参数数据的情况下,可对控制参数数据进行预处理,具体包括:对该版本号进行编码来得到作为数据集合的数据的用数值表示的版本号。这里,可采用预定的编码规则将标本号编码为用数值表示的版本号。
当所述预定数据包括所述预定时间段的风资源数据时,且所述预定时间段的风资源数据包括预定时间段的风速,对所述风资源数据进行预处理,具体包括:根据预定时间段的风速计算得到预定时间段内各个风速的出现次数以及各个风速的湍流强度,以作为数据集合的数据。这里,可采用现有技术中的各种方法根据预定时间段的风速计算得到预定时间段内各个风速的湍流强度。
在每台风力发电机组的预定数据包括所述运行数据的情况下,且所述运行数据包括预定时间段的桨距角时,对运行数据进行预处理,具体包括:根据预定时间段的桨距角数据计算得到预定时间段内各个桨距角的出现次数,以作为数据集合的数据。
提取单元702可将对预定数据中的部分数据进行预处理获得的数据与每台风力发电机组的预定数据中的未被预处理的数据组合成每台风力发电机组的数据集合。未被预处理的数据可包括以下至少一种:环境温度、环境湿度、机组的经纬度、机组的海拔。
聚类单元703通过聚类算法对风场中的所有风力发电机组的数据集合进行聚类,以实现对风力发电机组的聚类。这里,将每台风力发电机组的数据集合作为一个样本来对所有风力发电机组的数据集合进行聚类。
这里,可采用各种聚类算法来对所有风力发电机组的数据集合进行聚类。例如,可采用以下任一算法来聚类:改进的K均值算法、基于层次聚类和具有噪声的基于密度的聚类算法(DBSCA)。该改进的K均值算法将距离最远的样本作为初始聚类中心。
优选地,为了提高聚类结果的准确性,聚类单元703可包括确定子单元和聚类子单元。确定子单元确定用于聚类的最优聚类个数和最优聚类中心。聚类子单元根据确定用于聚类的最优聚类个数和最优聚类中心,将所有风力发电机组的数据集合进行聚类。在进行聚类时,聚类子单元将用于聚类的最优聚类中心作为聚类中心,将所有风力发电机组的数据集合聚类为用于聚类的最优聚类个数的簇。
图8示出本发明的实施例的确定子单元的框图。如图8所示,本发明的实施例的确定子单元包括设置模块801、聚类循环模块802和众数确定模块803。
设置模块801设置最大聚类个数和最小聚类个数。
聚类循环模块802将所有风力发电机组的数据集合进行预定次数的聚类循环,得到每次聚类循环的最优聚类个数以及最优聚类中心。这里,在每次聚类循环中,分别根据最小聚类个数至最大聚类个数之间的每个聚类个数,对所有风力发电机组的数据集合进行聚类,得到每个聚类个数对应的聚类结果以及聚类中心,评价每个聚类个数对应的聚类结果,将聚类结果最好的聚类个数作为每次聚类循环的最优聚类个数。
这里,可采用各种聚类算法,来根据所述每个聚类个数,对所有风力发电机组的数据集合进行聚类。例如,可采用以下任一算法来聚类:改进的K均值算法、基于层次聚类和具有噪声的基于密度的聚类算法(DBSCA)。
可采用各种方法来评价每个聚类个数对应的聚类结果。例如,可采用以下任一算法来评价每个聚类个数对应的聚类结果:贝叶斯信息准则(BIC)、间隙统计算法(Gap statistic)和方差比例准则(VRC)等。在采用VRC准则来评价每个聚类个数对应的聚类结果时,VRC准则越大的聚类个数对应的聚类结果越好。
众数确定模块803确定预定次数的聚类循环中最优聚类个数的众数,并将确定的众数作为用于聚类的最优聚类个数,以及将确定的众数对应的多个聚类循环中聚类结果最好的最优聚类中心作为用于聚类的最优聚类中心。该预定次数的聚类循环中最优聚类个数的众数是指,在预定次数的聚类循环中,出现次数最多的最优聚类个数。
在一个优选的实施例中,为了减少数据量,提高计算效率,根据本发明的实施例的风力发电机组的聚类设备还可包括维数约减单元(未示出)。维数约减单元在聚类单元703进行聚类之前,对每台风力发电机组的数据集合进行维数约减。相应地,聚类单元703通过将维数约减后的所有风力发电机组的数据集合进行聚类来对风力发电机组进行聚类。
在本实施例中,可采用各种方法来进行维数约减。例如,可采用主成分分析方法(PCA)的来进行维数约减,在该方法中,通过计算方差贡献率的方式实现维数约减,选取累积贡献率大于预定值时对应的维数作为最终的维数约减结果。维数约减后的数据集合保留了未进行维数约减的数据集合的主要信息。
在另一个优选的实施例中,为了减少不必要的计算开销,以及使分类结果更加合理,根据本发明的实施例的风力发电机组的聚类设备还可包括本征簇验证单元(未示出)。这是由于风电场中的风力发电机组间的运行环境与机组运行状态各有差异,如果在数据集合不存在本征簇时直接聚类,则聚类结果的参考意义很有限,只有当确定存在本征簇的前提下进行聚类,才能使聚类更加合理,且有意义。本征簇验证单元在聚类单元703进行聚类之前,验证所有风力发电机组的数据集合之间是否存在本征簇。当存在本征簇时,表示所有风力发电机组的数据集合之间具有不同的簇,聚类单元703可进行聚类分析。当不存在本征簇时,表示所有风力发电机组的数据集合之间不具有不同的簇,无需进行聚类分析,所有的风力发电机组可视为一组,可免去聚类带来的计算开销。
在本实施例中,可采用各种验证方法来进行本征簇验证。例如,可采用霍普金斯统计方法(Hopkins statistic)或集群趋势的视觉评价方法(VisualAssessment of cluster Tendency)等方法来进行本征簇验证。在采用霍普金斯统计方法来进行本征簇验证的情况下,如果霍普金斯统计结果小于预定阈值时,则存在本征簇。如果霍普金斯统计结果大于或等于预定阈值时,则不存在本征簇,不需要进行聚类分析。
应该理解,在本实施例中,为了减少数据计算量,可验证维数约减后的所有风力发电机组的数据集合之间是否存在本征簇。
根据本发明的实施例的风力发电机组的聚类方法和设备,根据每台风力发电机组的数据集合来对风力发电机组进行聚类,可实现合理的分类。
此外,根据本发明的实施例的风力发电机组的聚类方法和设备,参考了控制参数数据、地理位置数据、环境数据和运行数据中的至少两种数据,根据多维度的数据综合考虑风力发电机组间的相似情况,分类更加合理,分类结果更加准确,为后续的基于分类的结果进行机组控制提供了精确的数据基础。
此外,根据为本发明的实施例的风力发电机组的聚类方法和设备可为风电场级的故障诊断提供对比分析策略,如同一个组内的机组出现故障时,可比对组内其他机组的运行情况,或评估组内其他机组的风险水平,而不是盲目的排查整个风电场全部机组,大大的降低了人工维护成本。此外,机组的诊断模型会存在一定概率的误报而进行虚假预警,同一簇内的机组的诊断结果可以相互验证,降低诊断模型误报概率。
此外,根据本发明的实施例的风力发电机组的聚类方法和设备进行的机组聚类分组有利于后续的机组性能比较。例如,在进行同组内功率曲线的比较时,在相似的风资源、地理信息、机组控制参数下机组的出力情况如果表现不一,则该类机组存在潜在问题的可能性比较高。在进行同组内机组的故障表现形式的对比时,有利于梳理故障模式与外部条件或机组特性的梳理。在同组内某台机组大部件出现问题时,定检时应更有针对性的检查同组内的其他机组,其潜在的风险会高于其他组内的机组,定检维护更具有目的性。上述机组聚类分组还可为定制化服务做准备,如控制参数定制化、功率提升定制化等。
此外,应该理解,根据本发明的实施例的风力发电机组的聚类方法可实现为计算机可读记录介质上的计算机可读代码。计算机可读记录介质是可存储其后可由计算机系统读出的数据的任意数据存储装置。计算机可读记录介质的示例包括:只读存储器(ROM)、随机存取存储器(RAM)、CD-ROM、磁带、软盘、光数据存储装置和载波(诸如经有线或无线传输路径通过互联网的数据传输)。计算机可读记录介质也可分布于连接网络的计算机系统,从而计算机可读代码以分布式存储和执行。此外,完成本发明的功能程序、代码和代码段可容易地被与本发明相关的领域的普通程序员在本发明的范围之内解释。
此外,根据本发明的实施例的风力发电机组的聚类设备中的各个单元可完全由硬件来实现,例如现场可编程门阵列(FPGA)或专用集成电路(ASIC);还可以由硬件和软件相结合的方式来实现;也可以完全通过计算机程序来以软件方式实现。
尽管已经参照其示例性实施例具体显示和描述了本发明,但是本领域的技术人员应该理解,在不脱离权利要求所限定的本发明的精神和范围的情况下,可以对其进行形式和细节上的各种改变。
- 还没有人留言评论。精彩留言会获得点赞!