非线性迟滞动力学模型参数识别的粒子群新算法的制作方法
本发明涉及非线性迟滞动力学模型参数识别的粒子群新算法,属于非线性迟滞系统参数识别、群智能算法的领域。
背景技术:
迟滞特性作为一种非线性动力学特性,广泛存在于橡胶、压电陶瓷、磁流变等材料中。在对此类材料进行非线性动力学分析时,为了建立准确的动力学模型,需采用非线性迟滞动力学模型。非线性迟滞动力学模型能够准确模拟结构的非线性迟滞特性,但具有较多的模型参数,需要利用优化算法进行识别。由于非线性迟滞动力学模型的参数较多,彼此之间存在耦合,这使得对模型参数准确、快速识别的难度大大增加。
针对非线性迟滞动力学模型的特点,国内外提出了许多参数识别方法,如最小二乘法、遗传算法、帝国主义竞争算法、粒子群算法等。其中粒子群算法,由于具有收敛迅速、原理简单、易于实现的特点,被广泛运用于多目标优化、模式识别、信号处理、损伤识别等领域。但是标准粒子群算法作为一种随机搜索算法,容易陷入局部极值,发生早熟收敛,无法获得真正的最优解。为了克服标准粒子群算法的这些缺点,对标准粒子群算法的改进措施多集中于修改算法的惯性系数,引入新的机制,以及将标准粒子群算法同其他智能算法混合。
技术实现要素:
发明目的:针对上述现有技术,提出一种非线性迟滞动力学模型参数识别的粒子群新算法,改进标准粒子群算法的收敛性能,保证粒子群算法在前期迭代过程中的全局寻优能力以及后期迭代过程中的局部寻优能力。
技术方案:非线性迟滞动力学模型参数识别的粒子群新算法,包括如下步骤:
步骤1,读入包含试验状态与迟滞回线在内的试验数据;
步骤2,初始化粒子群,将D个代表待识别参数的N维粒子随机布置在搜索域内;
步骤3,利用D个粒子的N维参数,调用非线性迟滞动力学模型的分析模块,计算全体粒子的迟滞回线;
步骤4,计算各个粒子的迟滞回线计算值与试验值之间的差距,利用适应度函数确定各个粒子的适应度值;
步骤5,通过将各个粒子的适应度值与各个粒子的历史最优适应度值以及全局最优适应度值比较,更新各个粒子的历史最优位置和粒子群的全局最优位置;
步骤6,利用步骤5中确定的各个粒子新的历史最优位置和粒子群新的全局最优位置,更新各个粒子的位置;
步骤7,当算法达到最大迭代步数时,输出识别结果,完成整个识别过程。
进一步的,步骤4所述迟滞回线计算值与试验值之间的差距,利用公式计算;其中,M为迟滞回线试验值的个数,ωi为迟滞回线第i个试验值的权系数,为第i个试验值的纵坐标,为第i个试验值的横坐标处迟滞回线计算值的纵坐标。
进一步的,步骤4所述适应度函数为其中a为平移因子,b为缩放因子。
进一步的,所述平移因子a和缩放因子b的确定方法为:首先,利用标准粒子群算法对模型参数进行一次识别,确定适应度随迭代步的变化趋势,假设第1迭代步和最大迭代步J时,利用识别的模型参数计算得到的迟滞回线计算值与试验值之间的差距分别为e1和eJ,缩放因子b等于(x2-x1)/(e1-eJ),平移因子a等于x1-eJ(x2-x1)/(e1-eJ);其中[x1,x2]为区间,x1∈[0.15,0.35],x2∈[2.5,4]。
有益效果:(1)本发明通过定义适应度函数改进了标准粒子群算法的收敛性能,保证了算法在前期迭代过程中的全局寻优能力以及后期迭代过程中的局部寻优能力,避免算法陷入局部极值,发生早熟收敛,无法获得真正的最优解。
(2)本发明能够实现对非线性迟滞动力学模型参数准确、快速地识别,可以广泛运用于各类非线性迟滞动力学模型的参数识别。
附图说明
图1是本发明的算法流程图;
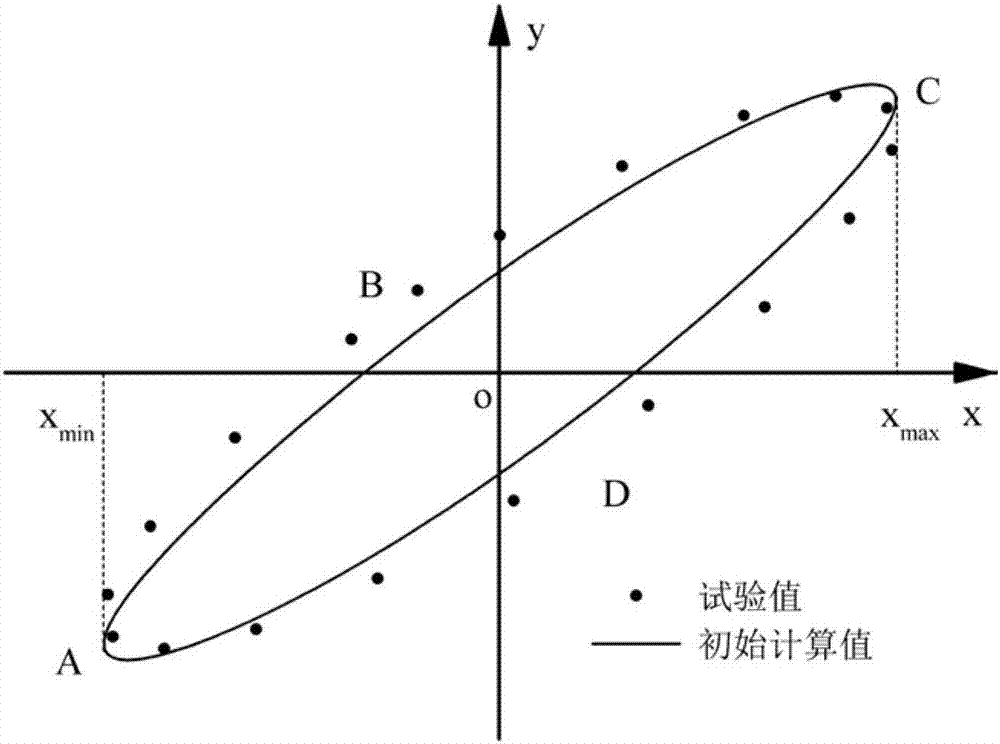
图2是迟滞回线示意图;
图3是函数y=1/x的示意图;
图4是NACA0012翼型的迎角-法向力系数迟滞回线;
图5是NACA0012翼型的适应度均值收敛曲线;
图6是滞弹位移场模型的应变-应力迟滞回线;
图7是滞弹位移场模型的适应度均值收敛曲线。
具体实施方式
下面结合附图对本发明做更进一步的解释。
如图1所示,本发明非线性迟滞动力学模型参数识别的粒子群新算法,包括如下步骤:
步骤1,读入包含试验状态与迟滞回线在内的试验数据。迟滞回线的试验值与利用粒子初始参数得到的迟滞回线计算值如图2所示。迟滞回线试验值的坐标为(i=1,2,…,M),M为迟滞回线试验值的个数,为第i个试验值的横坐标,为第i个试验值的纵坐标;迟滞回线计算值的坐标为(k=1,2,…,K),K为迟滞回线计算值的个数,为第k个迟滞回线计算值的横坐标,为第k个迟滞回线计算值的纵坐标。读入迟滞回线试验值时,从横坐标最小值处开始按顺时针方向读到横坐标最大值处,再读回横坐标最小值处,即图2中A-B-C-D-A的读入顺序。
步骤2,初始化粒子群,将D个代表待识别参数的N维粒子随机布置在搜索域内。N维粒子对应需要识别的N个模型参数。第d个粒子的第n个模型参数的初始值记为(d=1,2,…,D;n=1,2,…,N)。
步骤3,利用D个粒子的N维参数,调用非线性迟滞动力学模型的分析模块,计算各个粒子对应的迟滞回线。非线性迟滞动力学模型方程的一般形式为:
y=F(x,c1,c2,…,cN) (1)
其中,c1,c2,…,cN即为待识别的N个模型参数。对于第d个粒子,利用公式(1)以及(n=1,2,…,N)即可得到其对应迟滞回线的计算值的坐标(k=1,2,…,K)。迟滞回线计算值同样按照A-B-C-D-A的顺序排列。
步骤4,由于迟滞回线计算值与试验值的横坐标不同,计算各个粒子的迟滞回线计算值与试验值之间的差距时,需首先利用与试验值横坐标临近的计算值,线性插值确定横坐标处对应的计算值(i=1,2,…,M)。再利用下式确定迟滞回线计算值与试验值之间的差距:
其中,ωi为迟滞回线第i个试验值的权系数,即为第i个试验值的横坐标处迟滞回线计算值的纵坐标。
迟滞回线计算值与试验值之间的差距越小,说明识别的模型参数越好。适应度值作为评价各个粒子的N个模型参数优劣的依据,如果直接将迟滞回线计算值与试验值之间的差距作为适应度值,那么前期迭代过程中各个粒子的适应度值差距较大,各个粒子会向其中最优的粒子方向收敛,发生早熟收敛;后期迭代过程中各个粒子的适应度差距较小,会使各个粒子陷入局部极值。这使得计算得到的最优位置可能并非真正的最优位置,识别出的参数也可能并非最优解。如果一个函数可以将前期迭代过程中各个粒子的适应度值差距缩小,将后期迭代过程中各个粒子的适应度值差距放大,那便可以克服标准粒子群算法的这些缺点。本发明采用下式定义适应度函数,
本发明定义的适应度函数值越大,说明迟滞回线的计算值与试验值越接近,识别的模型参数越好。本发明定义的适应度函数基于函数y=1/x,如图3所示。从图3可以看出,当x小于1时,x的变化对y影响较大;当x大于1时,x的变化对y影响较小。如果x对应于迟滞回线计算值与试验值之间的差距ed,利用平移因子a和缩放因子b可以将ed布置在合理区间[x1,x2],使得ed在前期迭代过程被缩小,在后期迭代过程被放大。
为了确定平移因子a和缩放因子b,首先,需利用标准粒子群算法对模型参数进行一次识别,确定适应度随迭代步的变化趋势。假设第1迭代步和最大迭代步J时,利用识别的模型参数计算得到的迟滞回线计算值与试验值之间的差距分别为e1和eJ。为了将区间[eJ,e1]转换到图3中的区间[x1,x2],缩放因子b等于(x2-x1)/(e1-eJ),平移因子a等于x1-eJ(x2-x1)/(e1-eJ)。对于区间[x1,x2],x1不能过于靠近0,x2不能远大于1,否则会使得改进粒子群算法在后期和前期迭代步需要消耗过多迭代步才能收敛。x1适宜的取值区间为[0.15,0.35],x2适宜的取值区间为[2.5,4]。实施实例中,[x1,x2]对应的区间为[0.2,3]。
步骤5,将各个粒子在之前的迭代过程中,适应度值最大时的N维参数,称为粒子的历史最优位置,第d个粒子在第j迭代步的历史最优位置记为将全体粒子在之前的迭代过程中,适应度值最大时的N维参数称为全局最优位置,第j迭代步的全局最优位置记为通过将各个粒子的适应度值与各个粒子的历史最优适应度值以及全局最优适应度值比较,更新各个粒子的历史最优位置和粒子群的全局最优位置。
步骤6,利用步骤5中确定的各个粒子新的历史最优位置和粒子群新的全局最优位置,更新各个粒子的位置,即指粒子对应的N维参数。在第j迭代步,第d个粒子的第n个参数按下式迭代更新:
其中,为第j迭代步,第d个粒子的第n个参数的速度,a1和a2为[0,2]区间的加速度系数,r1和r2为[0,1]区间的随机数,w为惯性系数,随着迭代步数按下式线性递减:
其中,wmax和wmin分别为惯性系数的最大值和最小值,J为最大迭代步数。
步骤7,当算法达到最大迭代步数J时,各个粒子均收敛于同一位置,此位置即为非线性迟滞动力学模型参数的识别结果,即
其中,为第n个模型参数在第J迭代步的识别结果。输出识别结果,完成整个识别过程。
实施实例:
为了体现本发明的实际效果,采用本发明的参数识别方法,分别识别了两种非线性迟滞动力学模型,即Leishman-Beddoes动态失速模型与粘弹阻尼器的滞弹位移场模型的参数。这两种模型对于分析直升机旋翼气弹动力学问题,提高旋翼气弹稳定性都非常重要。需要说明的是此处的实施实例仅仅用于解释本发明,并不用于限定本发明。
实例1.翼型迎角动态变化时,由于气流分离与动态失速的作用,翼型剖面的迎角-法向力系数曲线呈现滞回现象。利用Leishman-Beddoes动态失速模型能够准确计算翼型气动力随迎角的变化,但该模型具有较多的模型参数,需要利用试验数据进行识别。
利用本发明提出的粒子群新算法,识别了翼型的Leishman-Beddoes动态失速模型的参数。粒子群算法中布置的粒子数为10,迭代步数为100,重复次数为50。
NACA0012翼型,弦长0.1米,来流马赫数为0.38,迎角变化为α=10.3°+8.1°sin(0.075S)。50次重复识别后,利用识别的最优模型参数计算得到的翼型迎角-法向力系数迟滞回线如图4所示,适应度的均值收敛曲线如图5所示。
从图4可以看出,本发明能够准确识别Leishman-Beddoes动态失速模型的参数,计算得到翼型迎角-法向力系数迟滞回线同试验值非常吻合。从图5可以看出,对于Leishman-Beddoes动态失速模型的参数识别问题,相比于标准粒子群算法,本发明能够更准确、快速地收敛于最优解,具有比标准粒子群算法更好的收敛性能。
实例2.由金属和橡胶构成的粘弹阻尼器,能够增加结构的刚度与阻尼,起到耗能减振的作用,被广泛运用于航空航天,高层建筑,机械工程等各个领域。在交变载荷作用下,粘弹阻尼器的应变与应力之间会呈现非线性迟滞特性。
滞弹位移场模型能够准确模拟粘弹阻尼器的应力-应变迟滞回线,其模型参数需要利用试验数据进行识别。
利用本发明提出的粒子群新算法,识别了粘弹阻尼器滞弹位移场模型的参数。粒子群算法中布置的粒子数为10,迭代步数为100,重复次数为50。粘弹阻尼器所受交变载荷的频率为4赫兹。
50次重复识别后,利用识别的最优模型参数计算应变激励幅值为0.1,0.5和1.0时的应变-应力迟滞回线如图6所示,适应度的均值收敛曲线如图7所示。
从图6可以看出,本发明能够准确识别粘弹阻尼器滞弹位移场模型的参数,计算得到不同激励幅值下的粘弹阻尼器应变-应力迟滞回线同试验值非常吻合。从图7可以看出,对于粘弹阻尼器滞弹位移场模型的参数识别问题,相比于标准粒子群算法,本发明能够更准确、快速地收敛于最优解,具有比标准粒子群算法更好的收敛性能。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!