人工智能的混淆技术方法及装置与流程
本发明涉及计算机技术领域,具体而言,涉及一种人工智能的混淆技术方法及装置。
背景技术:
当今社会人们对于计算机及其软件的依赖越来越大,软件的安全问题也日益凸显,已经开始影响到人们的正常使用,如果软件被逆向工程破解,就会造成机密信息的泄露,软件信息被重组修改,一些应用软件的密钥或其它机密信息被篡改会给销售商带来巨大经济损失。
所谓程序混淆,就是在保持程序功能基本不变的前提下通过代码变换t将原始程序p混淆后变成新程序p1,混淆后的程序很难被反编码,这样就达到了保护软件的目的。其中要满足的条件有两个:第一,p和p1在经过正常混淆转换终止后必须具有相同的输出;第二,p输入出错终止或终止失败时,p1不一定终止。程序混淆的保护机制不是在于保护p1不受攻击,而是加大从p1恢复成p的时间,使攻击者攻击的代价超过其利益,恢复后的p可读性也非常差,以此来达到保护软件的作用。
混淆技术是目前保护电子机密资源最有效的方法之一,目前在控制流混淆技术上已经取得了一些显著成就,但在数据混淆技术上研究还不是很深入,各种混淆算法的复杂度和抗攻击性也不是很高。随着破解技术的完善以及电脑硬件资源成本的迅速降低,造成海量资源暴力破解算法以及逆向生成,从而使电子机密资源被盗走,计算机安全问题已经越来越受到人们的重视及预防。
技术实现要素:
本发明旨在至少解决现有技术或相关技术中存在的技术问题之一。
为此,本发明的一个目的在于提出了一种人工智能的混淆技术方法。
本发明的另一个目的在于提出了一种人工智能的混淆技术装置。
有鉴于此,根据本发明的一个目的,提出了一种人工智能的混淆技术方法,包括:接收视频声音信息,其中视频声音信息包含用户行为属性;分析视频声音信息,获取用户行为属性;根据用户行为属性,对待传送的电子资料进行混淆处理,生成混淆电子资料;将混淆电子资料发送至终端。
本发明提供的人工智能的混淆技术方法,在传送需要混淆的电子机密资料时,同时通过视频声音信息来采集用户的随机的行为属性,根据此行为属性来随机混淆电子资料,最终将混淆后的电子资料发送给终端,本发明解决了现有技术中混淆技术的复杂度和抗攻击性不高的缺点,能够放置海量资源被暴力破解,实现了电子机密资料的安全存储,避免电子机密资料被盗走的风险。
根据本发明的上述人工智能的混淆技术方法,还可以具有以下技术特征:
在上述技术方案中,优选地,分析视频声音信息,获取用户行为属性,具体包括:将视频声音信息切分成单一图像声音数据;选取单一图像声音数据进行识别分析,获取用户行为属性。
在该技术方案中,获取到视频声音资料后,将该视频声音资料进行切分,使整段视频声音资料切分成单一图像声音数据,完成切分之后随机选取单一图像声音数据进行识别分析,保存好识别后的行为属性,进而通过利用用户的行为属性混淆电子资料,确保电子资料的安全。
在上述任一技术方案中,优选地,接收视频声音信息之前,还包括:发送获取视频声音信息请求。
在该技术方案中,向终端发送获取用户视频声音信息的请求,用户可以通过终端摄像头或者麦克风实时采集一段视频声音资料,或者直接传送已经存储好的视频声音资料,获取视频声音信息的过程简单易行,能够通过简单的方法将电子资料进行混淆,以及安全性能更高。
在上述任一技术方案中,优选地,还包括:将用户行为属性发送至终端,以供终端确认用户行为属性是否识别正确。
在该技术方案中,将获取到的用户行为属性发送至终端,以供终端确认用户行为属性是否识别正确,通过用户对用户行为属性的确认,确保用户行为属性无误,进而正确无误地对电子资源进行混淆。
在上述任一技术方案中,优选地,还包括:接收对用户行为属性的确认信息;当确认信息为用户行为属性识别不正确时,重新分析视频声音,获取用户行为属性;或接收由终端发送的用户行为属性。
在该技术方案中,当用户行为属性识别不正确时,再重新进行识别,或者直接接收由用户输入的行为属性。
在上述任一技术方案中,优选地,还包括:当接收到还原资料请求时,通过用户行为属性验证用户身份信息;当用户身份信息验证成功后,根据还原资料请求,还原混淆电子资料,并将还原后的混淆电子资料发送至终端。
在该技术方案中,当用户想还原混淆后的电子资料时,必须通过用户行为属性来确认用户身份信息,用户身份信息确认通过后,复原电子资料并传送给终端,提高电子资料的抗攻击性,避免电子资料被破解导致机密泄露,防止给销售商带来经济损失。
根据本发明的另一个目的,提出了一种人工智能的混淆技术装置,包括:接收模块,用于接收视频声音信息,其中视频声音信息包含用户行为属性;识别分析模块,用于分析视频声音信息,获取用户行为属性;技术混淆模块,用于根据用户行为属性,对待传送的电子资料进行混淆处理,生成混淆电子资料;发送模块,用于将混淆电子资料发送至终端。
本发明提供的人工智能的混淆技术装置,在传送需要混淆的电子机密资料时,同时通过接收模块接收到的视频声音信息,利用识别分析模块采集用户的随机的行为属性,根据此行为属性通过技术混淆模块来随机混淆电子资料,最终发送模块将混淆后的电子资料发送给终端,本发明解决了现有技术中混淆技术的复杂度和抗攻击性不高的缺点,能够放置海量资源被暴力破解,实现了电子机密资料的安全存储,避免电子机密资料被盗走的风险。根据本发明的上述人工智能的混淆技术装置,还可以具有以下技术特征:
在上述技术方案中,优选地,识别分析模块,具体用于:将视频声音信息切分成单一图像声音数据;选取单一图像声音数据进行识别分析,获取用户行为属性。
在该技术方案中,获取到视频声音资料后,识别分析模块将该视频声音资料进行切分,使整段视频声音资料切分成单一图像声音数据,完成切分之后随机选取单一图像声音数据进行识别分析,保存好识别后的行为属性,进而通过利用用户的行为属性混淆电子资料,确保电子资料的安全。
在上述任一技术方案中,优选地,发送模块,还包括:发送获取视频声音信息请求。
在该技术方案中,发送模块向终端发送获取用户视频声音信息的请求,用户可以通过终端摄像头或者麦克风实时采集一段视频声音资料,或者直接传送已经存储好的视频声音资料,获取视频声音信息的过程简单易行,能够通过简单的方法将电子资料进行混淆,以及安全性能更高。
在上述任一技术方案中,优选地,发送模块,还包括:将用户行为属性发送至终端,以供终端确认用户行为属性是否识别正确。
在该技术方案中,发送模块将获取到的用户行为属性发送至终端,以供终端确认用户行为属性是否识别正确,通过用户对用户行为属性的确认,确保用户行为属性无误,进而正确无误地对电子资源进行混淆。
在上述任一技术方案中,优选地,接收模块,还用于接收对用户行为属性的确认信息;识别分析模块,还用于当确认信息为用户行为属性识别不正确时,重新分析视频声音,获取用户行为属性;或接收模块,还用于接收由终端发送的用户行为属性。
在该技术方案中,当用户行为属性识别不正确时,再重新进行识别,或者直接接收由用户输入的行为属性。
在上述任一技术方案中,优选地,还包括:验证模块,用于当接收到还原资料请求时,通过用户行为属性验证用户身份信息;还原模块,用于当用户身份信息验证成功后,根据还原资料请求,还原混淆电子资料,并将还原后的混淆电子资料发送至终端。
在该技术方案中,当用户想还原混淆后的电子资料时,必须利用验证模块通过用户行为属性来确认用户身份信息,用户身份信息确认通过后,还原模块复原电子资料并传送给终端,提高电子资料的抗攻击性,避免电子资料被破解导致机密泄露,防止给销售商带来经济损失。
本发明的附加方面和优点将在下面的描述部分中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1a示出了本发明的一个实施例的人工智能的混淆技术方法的流程示意图;
图1b示出了本发明的另一个实施例的人工智能的混淆技术方法的流程示意图;
图2示出了本发明的一个实施例的人工智能的混淆技术装置的示意框图;
图3示出了本发明的一个具体实施例的人工智能的混淆技术装置构架示意图;
图4示出了本发明的一个具体实施例的人工智能的混淆技术装置图。
其中,图3中附图标记与部件名称之间的对应关系为:
302手机,304摄像机,306pc电脑,308识别平台,310混淆平台。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不限于下面公开的具体实施例的限制。
本发明第一方面的实施例,提出一种人工智能的混淆技术方法,图1a示出了本发明的一个实施例的人工智能的混淆技术方法的流程示意图:
步骤102,接收视频声音信息,其中视频声音信息包含用户行为属性;
步骤104,分析视频声音信息,获取用户行为属性;
步骤106,根据用户行为属性,对待传送的电子资料进行混淆处理,生成混淆电子资料;
步骤108,将混淆电子资料发送至终端。
本发明提供的人工智能的混淆技术方法,在传送需要混淆的电子机密资料时,同时通过视频声音信息来采集用户的随机的行为属性,根据此行为属性来随机混淆电子资料,最终将混淆后的电子资料发送给终端,本发明解决了现有技术中混淆技术的复杂度和抗攻击性不高的缺点,能够放置海量资源被暴力破解,实现了电子机密资料的安全存储,避免电子机密资料被盗走的风险。
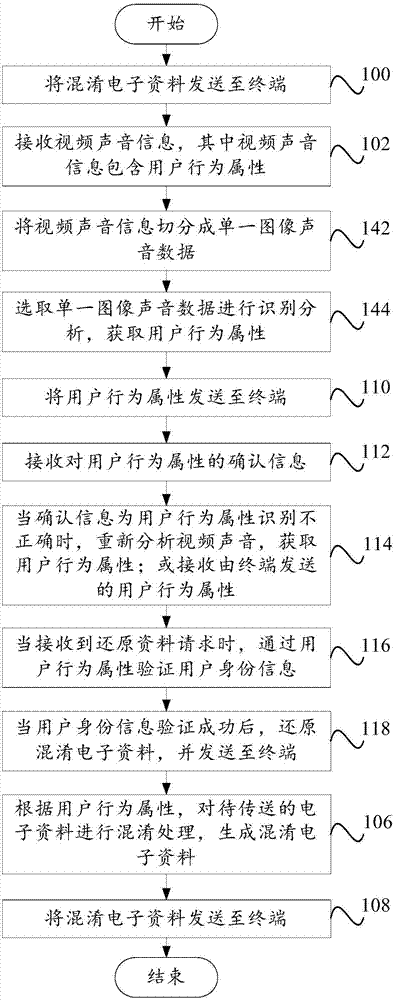
图1b示出了本发明的另一个实施例的人工智能的混淆技术方法的流程示意图,下面参照图1b描述根据本发明一些实施例所述的人工智能的混淆技术方法。
在本发明的一个实施例中,如图1b所示,优选地,该方法包括:
步骤100,发送获取视频声音信息请求;
步骤102,接收视频声音信息,其中视频声音信息包含用户行为属性;
步骤142,将视频声音信息切分成单一图像声音数据;
步骤144,选取单一图像声音数据进行识别分析,获取用户行为属性;
步骤106,根据用户行为属性,对待传送的电子资料进行混淆处理,生成混淆电子资料;
步骤108,将混淆电子资料发送至终端。
在该实施例中,向终端发送获取用户视频声音信息的请求,用户可以通过终端摄像头或者麦克风实时采集一段视频声音资料,或者直接传送已经存储好的视频声音资料,获取视频声音信息的过程简单易行,能够通过简单的方法将电子资料进行混淆,以及安全性能更高,获取到视频声音资料后,将该视频声音资料进行切分,使整段视频声音资料切分成单一图像声音数据,完成切分之后随机选取单一图像声音数据进行识别分析,保存好识别后的行为属性,进而通过利用用户的行为属性混淆电子资料,确保电子资料的安全。
在本发明的一个实施例中,如图1b所示,优选地,该方法包括:
步骤100,发送获取视频声音信息请求;
步骤102,接收视频声音信息,其中视频声音信息包含用户行为属性;
步骤142,将视频声音信息切分成单一图像声音数据;
步骤144,选取单一图像声音数据进行识别分析,获取用户行为属性;
步骤110,将用户行为属性发送至终端,以供终端确认用户行为属性是否识别正确;
步骤112,接收对用户行为属性的确认信息;
步骤114,当确认信息为用户行为属性识别不正确时,重新分析视频声音,获取用户行为属性;或接收由终端发送的用户行为属性;
步骤106,根据用户行为属性,对待传送的电子资料进行混淆处理,生成混淆电子资料;
步骤108,将混淆电子资料发送至终端。
在该实施例中,将获取到的用户行为属性发送至终端,以供终端确认用户行为属性是否识别正确,通过用户对用户行为属性的确认,确保用户行为属性无误,进而正确无误地对电子资源进行混淆,当用户行为属性识别不正确时,再重新进行识别,或者直接接收由用户输入的行为属性。
在本发明的一个实施例中,如图1b所示,优选地,该方法包括:
步骤100,发送获取视频声音信息请求;
步骤102,接收视频声音信息,其中视频声音信息包含用户行为属性;
步骤142,将视频声音信息切分成单一图像声音数据;
步骤144,选取单一图像声音数据进行识别分析,获取用户行为属性;
步骤110,将用户行为属性发送至终端,以供终端确认用户行为属性是否识别正确;
步骤112,接收对用户行为属性的确认信息;
步骤114,当确认信息为用户行为属性识别不正确时,重新分析视频声音,获取用户行为属性;或接收由终端发送的用户行为属性;
步骤116,当接收还原资料请求时,通过用户行为属性验证用户身份信息;
步骤118,当用户身份信息验证成功后,根据还原资料请求,还原混淆电子资料,并将还原后的混淆电子资料发送至终端;
步骤106,根据用户行为属性,对待传送的电子资料进行混淆处理,生成混淆电子资料;
步骤108,将混淆电子资料发送至终端。
在该实施例中,当用户想还原混淆后的电子资料时,必须通过用户行为属性来确认用户身份信息,用户身份信息确认通过后,复原电子资料并传送给终端,提高电子资料的抗攻击性,避免电子资料被破解导致机密泄露,防止给销售商带来经济损失。
本发明第二方面的实施例,提出一种人工智能的混淆技术装置200,图2示出了本发明的一个实施例的人工智能的混淆技术装置200的示意框图。其中,该装置包括:
接收模块202,用于接收视频声音信息,其中视频声音信息包含用户行为属性;
识别分析模块204,用于分析视频声音信息,获取用户行为属性;
技术混淆模块206,用于根据用户行为属性,对待传送的电子资料进行混淆处理,生成混淆电子资料;
发送模块208,用于将混淆电子资料发送至终端。
本发明提供的人工智能的混淆技术装置,在传送需要混淆的电子机密资料时,同时通过接收模块接收到的视频声音信息,利用识别分析模块采集用户的随机的行为属性,根据此行为属性通过技术混淆模块来随机混淆电子资料,最终发送模块将混淆后的电子资料发送给终端,本发明解决了现有技术中混淆技术的复杂度和抗攻击性不高的缺点,能够放置海量资源被暴力破解,实现了电子机密资料的安全存储,避免电子机密资料被盗走的风险。根据本发明的上述人工智能的混淆技术装置,还可以具有以下技术特征:
在本发明的一个实施例中,优选地,识别分析模块204,具体用于:将视频声音信息切分成单一图像声音数据;选取单一图像声音数据进行识别分析,获取用户行为属性。
在该实施例中,获取到视频声音资料后,识别分析模块204将该视频声音资料进行切分,使整段视频声音资料切分成单一图像声音数据,完成切分之后随机选取单一图像声音数据进行识别分析,保存好识别后的行为属性,进而通过利用用户的行为属性混淆电子资料,确保电子资料的安全。
在本发明的一个实施例中,优选地,发送模块208,还包括:发送获取视频声音信息请求。
在该实施例中,发送模块208向终端发送获取用户视频声音信息的请求,用户可以通过终端摄像头或者麦克风实时采集一段视频声音资料,或者直接传送已经存储好的视频声音资料,获取视频声音信息的过程简单易行,能够通过简单的方法将电子资料进行混淆,以及安全性能更高。
在本发明的一个实施例中,优选地,发送模块208,还包括:将用户行为属性发送至终端,以供终端确认用户行为属性是否识别正确。
在该实施例中,发送模块208将获取到的用户行为属性发送至终端,以供终端确认用户行为属性是否识别正确,通过用户对用户行为属性的确认,确保用户行为属性无误,进而正确无误地对电子资源进行混淆。
在本发明的一个实施例中,优选地,接收模块202,还用于接收对用户行为属性的确认信息;识别分析模块,还用于当确认信息为用户行为属性识别不正确时,重新分析视频声音,获取用户行为属性;或接收模块,还用于接收由终端发送的用户行为属性。
在该实施例中,当用户行为属性识别不正确时,再重新进行识别,或者直接接收由用户输入的行为属性。
在本发明的一个实施例中,如图2所示,优选地,还包括:验证模块210,用于当接收到还原资料请求时,通过用户行为属性验证用户身份信息;还原模块212,用于当用户身份信息验证成功后,根据还原资料请求,还原混淆电子资料,并将还原后的混淆电子资料发送至终端。
在该实施例中,当用户想还原混淆后的电子资料时,必须利用验证模块210通过用户行为属性来确认用户身份信息,用户身份信息确认通过后,还原模块212复原电子资料并传送给终端,提高电子资料的抗攻击性,避免电子资料被破解导致机密泄露,防止给销售商带来经济损失。
图3示出了本发明的一个具体实施例的人工智能的混淆技术装置构架示意图,识别平台通过各种终端设备,如:手机302、摄像机304、pc电脑306等等,通过网络将用户录制的行为数据传输给服务器,识别平台308识别用户行为属性并确认之后传输给混淆平台310,混淆平台310加入行为属性对电子资料进行混淆处理。
图4示出了本发明的一个具体实施例的人工智能的混淆技术装置图,包括:视频声音发送装置、视频声音接收装置、机器识别分析平台、技术混淆平台。用户在传送需要混淆的电子机密资料时,混淆平台需要同时采集用户端随机获取的特征属性,根据此属性来随机混淆电子资料,最终将混淆后的资料发送给用户。
用户通过终端访问混淆平台传送需要混淆的电子资料时,平台服务器会发送指令给终端请求获取一段视屏声音数据。用户通过终端摄像头或者麦克风实时采集一段视频声音资料或直接传送已经存储好的一段视频声音资料给平台。
平台获取到视频声音资料后,先将该资料进行切分,将整段视频声音资料切分成单一的图像声音数据,完成切分之后随机选取单一数据进行识别分析,保存好识别后的行为属性。比如:单一图片数据是头部侧面,识别出来的行为属性是摇头,识别成功之后将行为属性发送给终端让用户确认是否识别正确,如果不正确再进行识别或者用户根据此数据输入行为属性特征。
平台将最终确认的行为属性特征导入混淆算法中,将传送的电子资料根据此行为属性进行混淆处理,最终将混淆后的电子资料传送给用户。用户想还原混淆后的电子资料时,必须通过平台传送相同的行为属性特征来确认用户身份,确认通过之后,平台复原资料传送给用户。
在本说明书的描述中,术语“一个实施例”、“一些实施例”、“具体实施例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或实例。而且,描述的具体特征、结构、材料或特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!