一种基于视觉特征的网页关键内容检测系统及方法与流程
本发明涉及互联网技术领域,特别涉及一种基于视觉特征的网页关键内容自动化检测系统及方法。
背景技术:
随着互联网的广泛应用,网页成为了用户获取信息的重要载体。搜索引擎在利用网络爬虫软件对网页进行抓取,需要分析其中的关键内容,去除网页中广告、导航栏和用户评论等非关键内容,向用户提供目标网页的摘要。另一方面,随着网页设计的复杂化和多样化,加上网页动态渲染技术的进一步普及,很多关键内容往往是通过javascript代码动态添加的,而传统的基于静态html代码的标签分析进行关键内容检测的方法已经无法适应日益复杂的网页设计技术。
西安交通大学在其申请的专利文献“一种基于dom的网页关键内容抽取方法”(申请号:201410840805.7,申请公布号:cn103559202a)中公开了一种基于dom的网页关键内容抽取方法。采用该发明可以在网页关键内容的位置及具体内容均未知的情况下对关键内容进行抽取,具有抽取内容完整、可读性强,抽取信息量大,以及抽取效率高的优点。但是,该方法仍然存在的不足之处是,在dom特征提取过程中没有充分考虑视觉相关的特征,流程实现过于复杂,算法缺乏自学习的能力。
中国科学院计算技术研究所在其申请的专利文献“一种网页信息抽取的系统及方法”(申请号:200910076548.3,申请公布号:cn101464905a)中公开了一种网页信息抽取的系统及方法。采用该发明能够对应不同类的网页生成多个模板,并对网页中多个属性进行抽取。但是,该方法仍然存在的不足之处是,内容的抽取需要事前定制网页模板,一旦网页结构发生变化,将降低内容抽取的成功率。
综上所述,基于机器学习的网页关键内容检测是实现复杂网页关键内容提取的重要方案之一。提出的解决方案大部分为基于标签的基础特征、内容的语义特征来检测关键内容,然而随着网页叠层、动态渲染等技术的出现,仅仅依靠标签基础特征和语义特征并不能很好的识别关键内容。其次是机器学习的算法上面,普遍的都会只选取一种算法进行测试,无论是机器学习还是深度学习,都无法统筹兼顾的提升总体学习的准确率。
本发明提出的解决方案不仅提出基于dom视觉特征的关键内容检测,还首次使用多种机器学习算法,选取准确度最高的模型,进一步提高了检测的准确性。
技术实现要素:
本发明技术解决问题:克服现有技术的不足,提供一种基于视觉特征的网页关键内容检测系统及方法,能够大大提高关键内容检测精度。
本发明技术解决方案:一种基于视觉特征的网页关键内容检测系统,包括:样本处理模块、特征提取模块、预处理模块、机器学习模块和关键内容检测模块;
样本处理模块:收集网页样本库,利用chrome-headless动态渲染html文件,人工标注网页中的关键内容;
特征提取模块:根据chrome-headless软件动态渲染结果,对当前页面中的dom组件进行遍历,并提取目标dom组件的位置、大小、颜色等视觉特征和标签、子组件等基础特征,将以上信息正则化后形成该dom组件的特征矩阵,并存储在数据库中;
预处理模块:对特征提取模块获取的特征矩阵进行处理,去除掉无影响特征,初步获得与关键内容相关性最大的特征组;
机器学习模块:通过6种机器学习算法,即决策树、随机森林、贝叶斯分析、逻辑回归、支持向量机、k-近邻,进行准确率检测,得出训练样本不同比例下的准确率,选取准确率最高的模型作为最终模型;
关键内容检测模块:搜索引擎在通过网络爬虫软件获得目标url的html代码后,进行渲染,并计算目标dom组件的特征矩阵,利用前期训练的机器学习模型进行关键内容的检验,并返回该组件为关键内容的概率;
在本发明中,首先通过样本处理模块获取到可以提取特征的dom组件;然后通过特征提取模块计算样本的特征矩阵;使用预处理模块处理上一步获得的特征矩阵,获得适用于机器学习模块的特征表;在机器学习模块检测模型准确率,选取准确率高的模型,作为最终模型;最后实现网络爬虫提交dom组件信息,关键内容检测模块返回检测结果。。
所述机器学习模块中的机器学习分类算法选用决策树、随机森林、贝叶斯分析、逻辑回归、支持向量机、k-近邻。
本发明为一种基于视觉特征的网页关键内容检测方法,包括以下步骤:
第一步,收集标注为关键内容的dom组件和标注为非关键内容的dom组件作为初始样本集;
第二步,收集初始样本集的特征,形成关键内容特征数据库;
第三步,对所述关键内容特征数据库进行数据预处理;
第四步,利用6种机器学习算法对第三步预处理后的特征表格进行检测,选取准确率最高的模型并对其进行参数调节,选取准确率最高的模型作为检测模型;
第五步,对于待检测的软件,利用最终检测模型对所选软件检测后返回结果。
第一步中,所述初始样本集包括标注为关键内容的dom组件数据集和标注为非关键内容的dom组件数据集,其中关键内容dom组件样本500个,非关键内容dom组件样本500个。
第二步中,所述特征包括:组件位置、大小、颜色等视觉特征和标签、子组件等基础特征。
第四步中,所述6种机器学习算法为选用决策树、随机森林、贝叶斯分析、逻辑回归、支持向量机和k-近邻,并划分90%、80%、70%、60%、50%的测试集和训练集分别进行测试。
本发明与现有技术相比的优点在于:
(1)在特征选取上,现有技术大多根据dom的路径、子组件个数等特征判定目标dom是否属于关键内容,本发明采用dom的视觉特征,能够更充分地反映关键内容的本质特征。
(2)在检测算法上,现有技术大多采用私有算法,其准确性和鲁棒性缺乏充分的验证,本发明使用多种通用算法进行对比,不同的训练集占总样本比例划分,能更加准确的说明各个算法在关键内容检测方面的适应性。
(3)在样本采集和处理上,现有技术所采集样本的覆盖率较低,没有对动态html进行适配,无法获得真实数据,可能产生一定偏差,本发明采集了1000个网页样本,并使用chrome-headless软件进行渲染,能够更全面地采集关键内容dom的特征。
附图说明
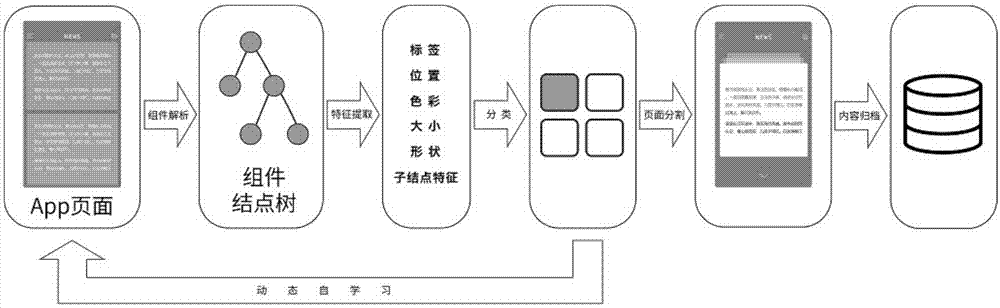
图1为本发明检测方法框图。
具体实施方式
本发明解决方案通过以下方案实现:首先通过样本处理模块获取到可以提取特征的dom组件;然后通过特征提取模块获取所有实验样本的特征;经过预处理模块对实验数据的处理,得出适合在机器学习模块检测的特征表;在机器学习模块检测其准确率,选取准确率高的模型,进行参数调优,得出最佳模型;最后实现网络爬虫提交dom组件信息,关键内容检测模块返回检测结果。
1.本发明的实现过程为:
(1)收集网页样本库,利用chrome-headless动态渲染html文件,人工对网页中的关键内容进行标注,形成该方案的初始样本集。
(2)根据chrome-headless软件动态渲染结果,对当前页面中的dom组件进行遍历,并提取目标dom组件的视觉特征,形成特征矩阵,并存储在数据库中。
(3)用机器学习的6种算法(决策树、随机森林、贝叶斯分析、逻辑回归、支持向量机和k-近邻)对获取到的数据进行处理,并调节训练集和测试集比例得出准确率最高的模型。
(4)存储识别率最高的模型,用于后期的检测。
(5)搭建检测平台,网络爬虫提交dom组件后,加载系统提前选择好的模型,然后经过模型检测返回改dom组件为关键内容的概率。
2.在步骤(1)中收集网页样本库,抓取常用网站的html代码进行人工标注,利用chrome-headless动态渲染html文件,一同组成该方案的初始样本集。
在步骤(2)中根据chrome-headless软件动态渲染结果,对当前页面中的dom组件进行遍历,并提取目标dom组件的视觉特征,采集的dom组件特征包括:位置、大小、颜色等视觉特征和标签、子组件等基础特征,并存储在数据库中。
在步骤(3)中选用当前比较流行的6种算法,决策树、随机森林、贝叶斯分析、逻辑回归、支持向量机和k-近邻。然后每一种算法分别划分六种不同比例(六种训练集比例分别为90%、80%、70%、60%、50%)的测试集和训练集,分别测试,单个分析用于后期检测。
在步骤(4)中挑选其中准确率最高的模型,作为最终模型,用于后期的检测。
在步骤(5)中建立检测平台,对于用户提交上来的待测数据,先在平台上进行分析,加载系统提前选择好的模型,提取特征后自动进行计算,返回该dom组件为关键内容的概率。
下面进行详细说明。
如图1所示,首先通过样本处理模块获取到可以提取特征的dom组件;然后通过特征提取模块获取所有实验样本的特征;经过预处理模块对实验数据的处理,得出适合在机器学习模块检测的特征表;在机器学习模块检测其准确率,选取准确率高的模型,进行参数调优,得出最佳模型;最后实现网络爬虫提交dom组件信息,关键内容检测模块返回检测结果。
1.本发明的实现过程为:
(1)收集网页样本库,使用chrome-headless软件动态渲染html文件,人工对网页中的关键内容进行标注,并存储在数据库中,形成该方案的初始样本集。
(2)根据chrome-headless软件动态渲染结果,对当前页面中的dom组件进行遍历,并提取目标dom组件的视觉特征,对数值型特征进行归一以消除量纲,对分类型特征构建单热向量表示,形成特征矩阵,并存储在数据库中。
(3)用机器学习的6种算法(决策树、随机森林、贝叶斯分析、逻辑回归、支持向量机和k-近邻)对获取到的数据进行处理,多次试验可能的参数,并调节训练集和测试集比例得出准确率最高的模型。
(4)对于识别率最高的模型进行训练,并持久化存储,用于后期的检测。
(5)搭建检测平台,网络爬虫提交dom组件后,加载系统提前选择好的模型,然后经过模型检测返回改dom组件为关键内容的概率。
2.在步骤(1)中收集网页样本库,抓取常用网站的html代码进行人工标注,利用chrome-headless动态渲染html文件,一同组成该方案的初始样本集。
在步骤(2)中根据chrome-headless软件动态渲染结果,对当前页面中的dom组件进行遍历,并提取目标dom组件的视觉特征,采集的dom组件特征包括:位置、大小、颜色等视觉特征和标签、子组件等基础特征,对数值型特征进行归一以消除量纲,对分类型特征构建单热向量表示,形成特征矩阵,并存储在数据库中。
在步骤(3)中选用当前比较流行的6种算法,决策树、随机森林、贝叶斯分析、逻辑回归、支持向量机和k-近邻。然后每一种算法分别划分六种不同比例(六种训练集比例分别为90%、80%、70%、60%、50%)的测试集和训练集,多次试验可能的参数,分别测试,单个分析用于后期检测。
在步骤(4)中挑选其中准确率最高的模型,作为最终模型,用于后期的检测。
在步骤(5)中建立检测平台,对于用户提交上来的待测数据,先在平台上进行分析,加载系统提前选择好的模型,提取特征后自动进行计算,返回该dom组件为关键内容的概率。
- 还没有人留言评论。精彩留言会获得点赞!