数据分类方法、装置以及计算机可读存储介质与流程
本发明涉及数据处理领域,尤其涉及一种数据分类方法、装置以及计算机可读存储介质。
背景技术:
如今,互联网技术飞速发展,各行业数字化信息飞速增长,数据占用的存储空间变得越来越大,对海量数据进行处理、挖掘以及运用成为当下科技型企业竞争中至关重要的能力。
科技型企业在收集到的海量数据后,通常需要对数据进行处理,将自然语言变为计算机能够识别的数据,并排除大量相似的数据,避免因重复运算而浪费时间与成本。
现有技术中计算相似度的方案是,将获取的自然语言数据处理为二进制数据,并将所有的二进制数据作为一个集合,通过计算机计算这个集合里每条二进制数据与其他二进制数据之间的相似度。然而采用上述方案时,如果一共有x条二进制数据,那么需要进行计算的次数为x(x+1)/2,当集合中的数据量十分庞大时,上述方法需要的运算时间过长,成本较高。
技术实现要素:
本发明解决的技术问题是数据分类不合理导致对集合内数据进行计算时所需的运算时间过长,成本较高。
为解决上述技术问题,本发明实施例提供一种数据分类方法,包括:获取自然语言数据;对所述自然语言数据进行预处理,获取每一条自然语言数据对应的代码数据;将每一条代码数据分别划分为n份标签数据;n≥2;根据所述n份标签数据对应的位次顺序,将存在相同的标签数据且所述相同的标签数据的位次顺序相同的代码数据划分为一个全量集合。
可选的,获取每一条自然语言数据对应的自然语言字段值;对每一条自然语言字段值进行分词处理,并提取相应的关键词;获取每一条自然语言字段值对应的关键词的哈希值;对每一条自然语言字段值对应的关键词的哈希值进行相似度计算,获取每一条自然语言对应的代码数据。
可选的,所述相似度计算包括以下至少一种:加权计算、合并计算和降维计算。
可选的,所述代码数据为simhash签名。
可选的,对每一条自然语言字段值对应的关键词的哈希值进行相似度计算,获取每一条自然语言对应的预设位数的代码数据。
可选的,将具有m份相同标签数据且所述m份相同标签数据处于相同位次顺序的代码数据作为一个全量集合;m<n。
本发明还提供一种数据分类装置,其特征在于,包括:获取单元,用于获取自然语言数据;处理单元,用于对所述自然语言数据进行预处理,获取每一条自然语言数据对应的代码数据;划分单元,用于将每一条代码数据分别划分为n份标签数据;n≥2;分类单元,用于根据所述n份标签数据对应的位次顺序,将存在相同的标签数据且所述相同的标签数据的位次顺序相同的代码数据划分为一个全量集合。
可选的,所述处理单元,用于获取每一条自然语言数据对应的自然语言字段值;对每一条自然语言字段值进行分词处理,并提取相应的关键词;获取每一条自然语言字段值对应的关键词的哈希值;对每一条自然语言字段值对应的关键词的哈希值进行相似度计算,获取每一条自然语言对应的代码数据。
可选的,所述相似度计算包括以下至少一种:加权计算、合并计算和降维计算。
可选的,所述代码数据为simhash签名。
可选的,所述处理单元,用于对每一条自然语言字段值对应的关键词的哈希值进行相似度计算,获取每一条自然语言对应的预设位数的代码数据。
可选的,所述分类单元,用于将具有m份相同标签数据且所述m份相同标签数据处于相同位次顺序的代码数据作为一个全量集合;m<n。
本发明还提供一种计算机可读存储介质,其上存储有计算机指令,其特征在于,所述计算机指令运行时执行上述任一种的数据分类方法的步骤。
本发明还提供一种数据分类装置,包括存储器和处理器,所述存储器上存储有计算机指令,其特征在于,所述计算机指令运行时所述处理器执行上述任一种的数据分类方法的步骤。
与现有技术相比,本发明实施例的技术方案具有以下有益效果:
将获取的自然语言数据进行预处理,获取各条自然语言对应的代码数据,将代码数据划分为n份标签数据,将相同标签数据处于相同位次的代码数据作为一个全量集合,最终将代码数据分类为多个全量集合。在进行相似度计算时,只需要分别计算每个全量集合内代码数据之间的相似度,因此可以大大减少运算时间,降低运算成本。
附图说明
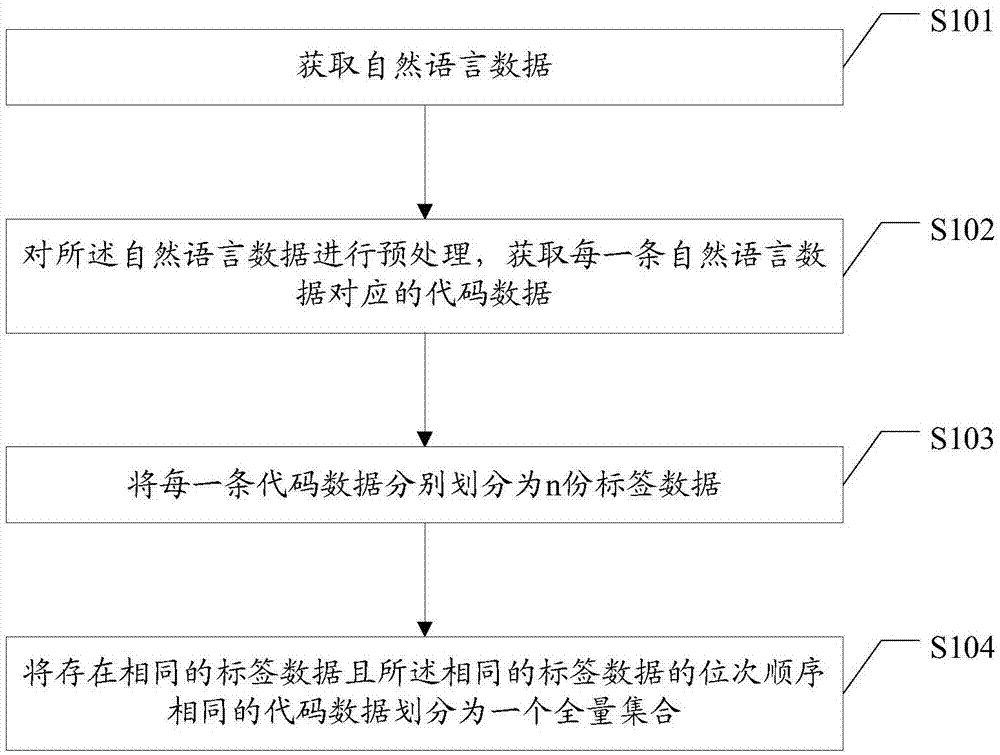
图1是本发明实施例提供的一种数据分类方法的流程示意图;
图2是本发明实施例提供的一种数据分类装置的结构示意图。
具体实施方式
科技型企业在收集到的海量数据后,通常需要对数据进行处理,将自然语言变为计算机能够识别的数据,并排除大量相似的数据,避免因重复运算而浪费时间与成本。
现有技术中计算相似度的方案是,将获取的自然语言数据处理为二进制数据,并将所有的二进制数据作为一个集合,通过计算机计算这个集合里每条二进制数据与其他二进制数据之间的相似度。然而采用上述方案时,如果一共有x条二进制数据,那么需要进行计算的次数为x(x+1)/2,当集合中的数据量十分庞大时,上述方法需要的运算时间过长,成本较高。
本发明实施例中,将获取的自然语言数据进行预处理,获取各条自然语言对应的代码数据,将代码数据划分为n份标签数据,将相同标签数据处于相同位次的代码数据作为一个全量集合,最终将代码数据分类为多个全量集合。在进行相似度计算时,只需要分别计算每个全量集合内代码数据之间的相似度,大大减少了运算时间,降低了运算成本。
为使本发明的上述目的、特征和有益效果能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
参阅图1,本发明实施例提供的一种数据分类方法,具体步骤如下,其中;
步骤s101,获取自然语言数据。
在具体实施中,可以从互联网平台获取自然语言数据,也可以从数据库获取自然语言数据。在实际应用中,用户可以根据实际需求确定自然语言数据的来源,本发明并不对自然语言数据的获取来源做限定。
步骤s102,对所述自然语言数据进行预处理,获取每一条自然语言数据对应的代码数据。
在具体实施中,由于计算机无法直接对自然语言数据进行处理,因此可以先对自然语言数据进行预处理,将自然语言数据转换为计算机可读的代码数据。
在具体实施中,计算机可读的代码数据通常表现为二进制数据,用户也可以根据实际需求确定代码数据的格式。
步骤s103,将每一条代码数据分别划分为n份标签数据。
在具体实施中,n的取值通常大于等于2。
在具体实施中,n的取值由用户根据实际需求确定。
在具体实施中,代码数据的划分方式由用户根据实际需求确定。
例如,代码数据10011100,n=4,对应的标签数据可以分别是10,01,11和00,也可以是100,111,0和0。
在具体实施中,通常每一条代码数据的划分方式均是相同的。例如,第一条代码数据为10011100,对应的标签数据分别是10,01,11和00;第二条代码数据为11100011,对应的标签数据分别是11,10,00,11。
步骤s104,将存在相同的标签数据且所述相同的标签数据的位次顺序相同的代码数据划分为一个全量集合。
在具体实施中,根据所述n份标签数据对应的位次顺序。
例如,代码数据a按照自身的数据排列顺序被划分为11,00,11和00四个标签数据,代码数据b按照自身的数据排列顺序被划分为11,11,00和11四个标签数据,由于代码数据a和代码数据b中的第一位次的标签数据是相同的,因此可以将代码数据a与代码数据b划分于同一全量集合。
在具体实施中,在计算代码数据之间的相似度时,是根据代码数据间相同位次的数据计算,因此,不同全量集合内不同的代码数据之间不具有相似度,或相似度过低不具备参考性。
采用上述方案划分全量集合,计算机在计算代码间的相似度时,可以计算全量集合内的代码数据间的相似度。若总共x条代码数据被划分为4个全量集合,每个全量集合内的代码数据条数分别为x1,x2,x3和x4,那么相似度计算次数为x1(x1+1)/2+x2(x2+1)/2+x3(x3+1)/2+x4(x4+1)/2,相比直接将所有的代码数据两两间计算相似度而言,降低了运算量。
在具体实施中,通常x1+x2+x3+x4=x,然而可能存在同一条代码数据被划分入不止一个全量集合中,因此x1+x2+x3+x4的值可能稍大于x。
本发明实施例中,将自然语言数据转换为代码数据可以从自然语言数据中提取出自然语言字段值。
本发明实施例中,将自然语言字段值进行分词处理,所述分词处理包括先对自然语言字段值进行去除括号以及括号内的内容、删除空格、英文同一转换成小写的处理,然后去除自然语言字段值中的一些停用词,提取出自然语言字段值中的关键词,并确定每个关键词的重要程度。
本发明实施例中,在获取自然语言字段值中的关键词后,可以将关键词作为特征向量,计算每一个特征向量的哈希值(hash),然后对关键词对应的哈希值进行相似度计算,获取每一条自然语言对应的代码数据。
本发明实施例中,所述相似度计算包括以下至少一种:加权计算、合并计算和降维计算。
例如,自然语言字段值“美国51区雇员称内部有9架飞碟,曾看见灰色外星人”,对上述自然语言字段值进行分词,获得“美国(4)51区(5)雇员(3)称(1)内部(2)有(1)9架(3)飞碟(5)曾(1)看见(3)灰色(4)外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
计算各个关键词的哈希值,比如“美国”通过hash算法计算为100101,“51区”通过hash算法计算为101011。这样字符串就变成了一串串数字。
加权计算:根据各个关键词的哈希值,以及关键词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4-4-44-44”;“51区”的hash值为“101011”,通过加权计算为“5-55-555”。
合并计算:将上述各个关键词经加权计算得到的序列值累加,变成只有一个序列串。比如“美国”的“4-4-44-44”,“51区”的“5-55-555”,把每一位进行累加,“4+5-4+-5-4+54+-5-4+54+5”==》“9-91-119”。这里作为示例只算了两个关键词,实际计算需要把所有单词的序列串累加。
降维计算:将由合并计算得到的“9-91-119”转换为01串,形成代码数据。计算方案为,如果每一位大于0记为1,小于0记为0,计算结果为:“101011”。
本发明实施例中,所述代码数据为simhash签名。
本发明实施例中,在对自然语言对应的关键词的哈希值进行相似度计算时,可以设定获得的代码数据的位数,以便于后续的运算以及标签数据的划分,具体位数可以由用户根据实际情况确定。
本发明实施例中,在将代码数据划分为n份后,具有m份相同标签数据且所述m份相同标签数据处于相同位次顺序的代码数据作为一个全量集合;m<n。
例如,代码数据c划分为11,00,11三个标签数据,代码数据d划分为11,00,10,代码数据e划分为11,11,01。当设定m=1时,代码数据c、d和e的第一位次的标签数据均相同,为11,因此可以将代码数据c、d、e划分入同一个全量集合。当设定m=2时,代码数据c、d的第一位次和第二位次的标签数据相同,因此可以将代码数据c、d划分入同一个全量集合。
在具体实施中,m的值可以由用户根据实际情况确定。
在具体实施中,采用上述方案对代码数据进行分类后,相同位次上的标签数据均不相同,或相同的较少的代码数据被划分入不同的全量集合,不同全量集合内的代码数据的相似较低。因此,若对数据库进行精简,排除相似度较高的代码数据时,只需计算单个全量集合内的代码数据之间的相似度,相比现有技术中的方案,大大减小了运算量,降低了成本。
参阅图2,本发明还提供一种数据分类装置20,包括:
获取单元201,用于获取自然语言数据;
处理单元202,用于对所述自然语言数据进行预处理,获取每一条自然语言数据对应的代码数据;
划分单元203,用于将每一条代码数据分别划分为n份标签数据;n≥2;
分类单元204,用于根据所述n份标签数据对应的位次顺序,将存在相同的标签数据且所述相同的标签数据的位次顺序相同的代码数据划分为一个全量集合。
本发明实施例中,所述处理单元202,用于获取每一条自然语言数据对应的自然语言字段值;对每一条自然语言字段值进行分词处理,并提取相应的关键词;获取每一条自然语言字段值对应的关键词的哈希值;对每一条自然语言字段值对应的关键词的哈希值进行相似度计算,获取每一条自然语言对应的代码数据。
本发明实施例中,所述相似度计算包括以下至少一种:加权计算、合并计算和降维计算。
本发明实施例中,所述代码数据为simhash签名。
本发明实施例中,所述处理单元202,用于对每一条自然语言字段值对应的关键词的哈希值进行相似度计算,获取每一条自然语言对应的预设位数的代码数据。
本发明实施例中,所述分类单元204,用于将具有m份相同标签数据且所述m份相同标签数据处于相同位次顺序的代码数据作为一个全量集合;m<n。
本发明还提供一种计算机可读存储介质,其上存储有计算机指令,所述计算机指令运行时执行上述任一种的数据分类方法的步骤。
本发明还提供一种数据分类装置,包括存储器和处理器,所述存储器上存储有计算机指令,所述计算机指令运行时所述处理器执行上述任一种的数据分类方法的步骤。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指示相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:rom、ram、磁盘或光盘等。
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!