一种基于数据驱动的热轧板凸度预测方法与流程
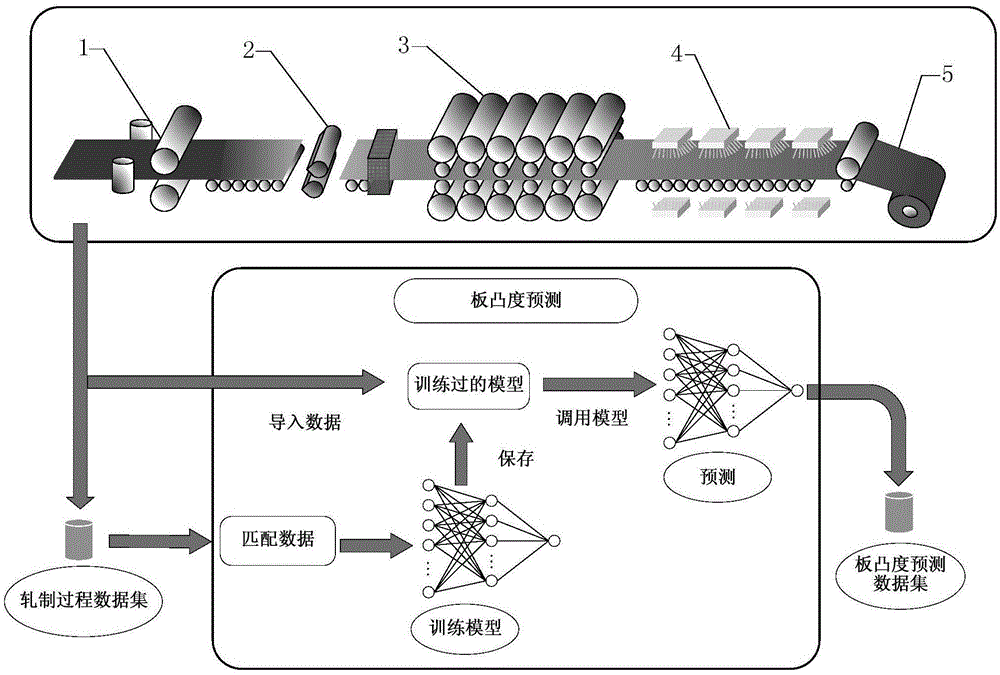
本发明涉及轧制过程自动控制技术领域,具体涉及一种基于数据驱动的热轧板凸度预测方法。
背景技术:
板形是衡量带钢产品质量的指标之一,通常衡量板形好坏的两个指标分别是板凸度和平直度。板凸度又称带钢横向厚度差,是指板带材沿宽度方向的厚度差。有效控制带钢板凸度不但可以防止如楔形等缺陷的出现,而且能够保证带钢平直度。
对于有效的板凸度的控制,一般是将检测装置、数学模型、轧机辊型配置、负荷分配、弯辊系统等影响板凸度的各类因素有机结合在一起。但是,随着用户对于产品质量的要求日益提高,传统的机理的方法已经很难有较大的进步与改善了。以某热轧场为例,按照带钢实际凸度在目标凸度的±10μm内属于合格品的规定,其生产的带钢仅有61.95%符合要求。这样的生产状况给企业造成了巨大的经济损失。
技术实现要素:
针对现有技术存在的问题,本发明提供一种基于数据驱动的热轧板凸度预测方法,可以加快增量式运动结构恢复算法的计算效率,并提高生成点云模型的质量。
为了实现上述目的,一种基于数据驱动的热轧板凸度预测方法,包括以下步骤:
步骤1:采集带钢的生产数据,包括钢卷号、生产时间、中间坯厚度、f1~f6机架的轧制力、f1~f6机架的弯辊力、f1~f6机架的窜辊量、轧后带钢的宽度、轧后带钢的厚度、轧后带钢的凸度、精轧入口温度以及终轧温度;
步骤2:对采集到的生产数据进行预处理,包括去除异常值、平滑处理和归一化,具体步骤如下:
步骤2.1:计算各生产数据的平均值和标准差;
步骤2.2:对生产数据的异常值进行剔除;
步骤2.3:对剔除异常值后的生产数据进行平滑处理;
步骤2.4:对平滑处理后的生产数据进行归一化处理;
步骤3:建立单隐层神经网络模型,具体步骤如下:
步骤3.1:采用经验公式计算经验值,然后在经验值±50%的区间范围内进行遍历搜索,获得隐含层神经元节点数n;
步骤3.2:遍历搜索0.1~0.5,确定单隐层神经网络学习率lr;
步骤3.3:两两组合purelin、logsig和tansig3种传递函数,产生9种组合,分别测试并选取单隐层神经网络隐含层和输出层的传递函数;
步骤3.4:遍历常用的方法,选择单隐层神经网络的训练函数;
步骤4:采用快速非支配排序遗传算法对单隐层神经网络模型进行优化,具体步骤如下:
步骤4.1:设置最大进化代数gmax,并令当前进化代数g=1;
步骤4.2:根据训练函数对单隐层神经网络模型进行训练,再将预处理后的生产数据输入到训练后的单隐层神经网络模型中进行预测并输出预测结果;
步骤4.3:计算单隐层神经网络的训练误差;
步骤4.4:采用二进制编码法将单隐层神经网络权值和阈值转换成为0和1组成的数字串;
步骤4.5:随机产生一个由n个个体组成的种群,由该种群代表可能解的集合;
步骤4.6:对种群中的每个个体p进行快速非支配排序,具体步骤如下:
步骤4.6.1:对于种群中的每个个体p,考察它所支配的个体集sp,找到所有解个体的数量np=0的个体p,并将个体p存入当前集合f1中;
步骤4.6.2:对于当前集合f1中的每个个体j,考察它所支配的个体集sj,将集合sj中的每个个体k的解个体的数量nk减去1,若nk一1=0,则将个体k存入另一个集合h中;
步骤4.6.3:将当前集合f1作为第一级非支配个体集合,并赋予该集合内个体一个相同的非支配序prank,然后继续对集合h作上述分级操作并赋予相应的非支配序,直到所有的个体都被分级;
步骤4.6.4:计算群体中每个个体p的两个属性:非支配序prank和拥挤度pd;
步骤4.6.5:判断种群中两个个体的非支配排序是否相同,若相同,则取拥挤度较小的个体,继续步骤4.7,若不同,则取非支配序级别较小的个体,继续步骤4.7;
步骤4.7:将所选取的个体组成为新的种群,并进行遗传操作,具体步骤如下:
步骤4.7.1:选择操作:从选取个体组成的新种群中选择a个个体并根据单隐层神经网络的训练误差,计算每个个体的适应度,选择适应度较小的b个个体作为双亲用于繁殖后代,产生新的个体;
步骤4.7.2:交叉操作:根据交叉概率随机选择用于繁殖的每一对个体的同一基因位,将其染色体在此基因位断开并相互交换;
步骤4.7.3:变异操作:根据变异概率随机从群体中选择c个个体,对于选中的个体,根据高斯分布,随机选择一位用随机数进行代替;
步骤4.8:判断当前进化代数g是否小于最大进化代数gmax,若是,则返回步骤4.2,若否,则输出优化后单隐层神经网络模型的权值和阈值,继续步骤5;
步骤5:对神经网络的权值和阈值进行解码,并赋予神经网络模型,输出经非支配排序的遗传算法优化的神经网络模型。
优选的,所述步骤2.2中对生产数据中的异常值进行剔除的方式为拉衣达准则,具体方式为对满足如下公式的生产数据进行异常值剔除:
其中,xi为第i个生产数据,
优选的,所述步骤2.3中对剔除异常值后的生产数据进行平滑处理的方式是采用5点3次平滑法,具体公式如下:
其中,yi是第i个剔除异常值后的生产数据,
本发明的有益效果:
本发明提出一种基于数据驱动的热轧板凸度预测方法,利用神经网络结合快速非支配排序遗传算法预测板凸度,克服热轧生产过程中参数检测困难精度差的缺陷不仅精度高,而且运算速度快,利用大量的生产过程数据通过直接在计算机上编程,即可实现投入使用,成本十分低廉。
附图说明
图1为本发明实施例中基于数据驱动的热轧板凸度预测方法与生产线结合的结构示意图;
其中,1为粗轧机;2为飞剪;3为精轧机(f1-f6);4为层流冷却机;5为卷取机;
图2为本发明实施例中基于数据驱动的热轧板凸度预测方法的流程图;
图3为本发明实施例中建模前对数据进行异常值去除的示意图;
图4为本发明实施例中模型预测值与测量值的散点拟合图。
具体实施方式
为了使本发明的目的、技术方案及优势更加清晰,下面结合附图和具体实施例对本发明做进一步详细说明。此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
本实施例中,基于数据驱动的热轧板凸度预测方法与生产线结合的结构如图1所示,采用六架hcw轧机组成的热连轧生产线数据,轧辊直径630mm~700mm,可轧带钢的宽度为700mm~2130mm,厚度为1.2mm~25.4mm。
一种基于数据驱动的热轧板凸度预测方法,流程如图2所示,包括以下步骤:
步骤1:采集带钢的生产数据,包括钢卷号、生产时间、中间坯厚度、f1~f6机架的轧制力、f1~f6机架的弯辊力、f1~f6机架的窜辊量、轧后带钢的宽度、轧后带钢的厚度、轧后带钢的凸度、精轧入口温度以及终轧温度。
本实施例中,采集某热轧厂热连轧的生产数据,共计4000个钢卷;数据包含122个特征。选取其中对于板凸度影响最为大的36个特征进行研究,包括中间坯厚度、f1~f6轧制速度、f1~f6轧制力、f1~f6弯辊力、f1~f6窜辊量、f1~f6后凸度、轧后带钢的宽度、厚度、凸度以及精轧入口温度、终轧温度。
步骤2:对采集到的生产数据进行预处理,包括去除异常值、平滑处理和归一化,具体步骤如下:
步骤2.1:计算各生产数据的平均值和标准差。
本实施例中,计算各生产数据的平均值
其中,m为生产数据的个数,xi为第i个生产数据。
步骤2.2:对生产数据的异常值进行剔除。
本实施例中,对生产数据中的异常值进行剔除的方式为拉衣达准则,具体方式为对满足公式(3)的生产数据进行异常值剔除:
如图3所示,本实施例中,合计83个数据点被剔除。
步骤2.3:对剔除异常值后的生产数据进行平滑处理。
本实施例中,采用5点3次平滑法对剔除异常值后的生产数据进行平滑处理,具体公式公式(4)所示:
其中,yi是第i个剔除异常值后的生产数据,
步骤2.4:对平滑处理后的生产数据进行归一化处理。
本实施例中,采用最大最小归一化法对平滑处理后的生产数据进行归一化处理,如公式(5)所示:
其中,
步骤3:建立单隐层神经网络模型,具体步骤如下:
步骤3.1:采用经验公式计算经验值,然后在经验值±50%的区间范围内进行遍历搜索,获得最优的隐含层神经元节点数n。
所述经验公式如公式(6)所示:
n=log2t(6)
其中,t为输入特征数,n为隐含层神经元节点数。
本实施例中,根据经验公式并考虑可能存在误差,综合测试神经元数目为5~9的所有情况,最终确定7个节点为最优。
步骤3.2:遍历搜索0.1~0.5,确定最优的单隐层神经网络学习率lr。
本实施例中,以0.1为增量,从0.1至0.5分别测试5次,寻找到最优的学习率0.2。
步骤3.3:两两组合purelin、logsig和tansig3种传递函数,产生9种组合,分别测试并选取最优的组合作为单隐层神经网络隐含层和输出层的传递函数。
本实施例中,经过测试,选择logsig和purelin分别作为隐含层和输出层的传递函数。
步骤3.4:遍历常用的方法,选择最优的单隐层神经网络的训练函数。
本实施例中,依次测试梯度下降法、动态梯度下降法、拟牛顿法、贝叶斯规则化法和列文伯格-马夸尔特法(l-m法),确定l-m法为最优的训练函数。
步骤4:采用快速非支配排序遗传算法对神经网络模型进行优化,具体步骤如下:
步骤4.2:设置最大进化代数gmax,并令当前进化代数g=1。
本实施例中,设置设置最大进化代数gmax=100。
步骤4.2:根据训练函数对单隐层神经网络模型进行训练,再将预处理后的生产数据输入到训练后的单隐层神经网络模型中进行预测并输出预测结果。
步骤4.3:计算单隐层神经网络的训练误差。
步骤4.4:采用二进制编码法将单隐层神经网络权值和阈值转换成为0和1组成的数字串。
步骤4.5:随机产生一个由n个个体组成的种群,由该种群代表可能解的集合。
本实施例中,测试种群规模为30、40、50、60的情况,依次遍历搜索,确定最佳种群数为50,即令n=50。
步骤4.6:对种群中的每个个体p进行快速非支配排序,具体步骤如下:
步骤4.6.1:对于种群中的每个个体p,考察它所支配的个体集sp,找到所有解个体的数量np=0的个体p,并将个体p存入当前集合f1中。
步骤4.6.2:对于当前集合f1中的每个个体j,考察它所支配的个体集sj,将集合sj中的每个个体k的解个体的数量nk减去1,若nk一1=0,则将个体k存入另一个集合h中。
步骤4.6.3:将当前集合f1作为第一级非支配个体集合,并赋予该集合内个体一个相同的非支配序prank,然后继续对集合h作上述分级操作并赋予相应的非支配序,直到所有的个体都被分级。
步骤4.6.4:计算群体中每个个体p的两个属性:非支配序prank和拥挤度pd。
步骤4.6.5:判断种群中两个个体的非支配排序是否相同,若相同,则取拥挤度较小的个体,继续步骤4.7,若不同,则取非支配序级别较小的个体,继续步骤4.7。
步骤4.7:将所选取的个体组成为新的种群,并进行遗传操作,具体步骤如下:
步骤4.7.1:选择操作:从选取个体组成的新种群中选择a个个体并根据单隐层神经网络的训练误差,计算每个个体的适应度,选择适应度较小的b个个体作为双亲用于繁殖后代,产生新的个体。
本实施例中,选择操作采用锦标赛选择法,适应度函数的公式如公式(7)所示:
其中,f为适应度函数,k为常数,yp为第p个个体的真实值,
步骤4.7.2:交叉操作:根据交叉概率随机选择用于繁殖的每一对个体的同一基因位,将其染色体在此基因位断开并相互交换,模拟二进制选择法的公式如公式(8)所示:
其中,x1和x2分别为被选中的用来交叉的两个染色体,x′1和x′2分别为经过交叉后的两个染色体,γp为交叉位置参数。
所述交叉位置参数γp的计算公式如公式(9)所示:
其中,up为在0~1内的随机数,η为常数1;
本实施例中,交叉概率一般选择较大的值,以0.1为增量,测试0.6~0.9这4种情况,交叉概率为0.8时,模型的性能最优,故选择交叉概率为0.8。
步骤4.7.3:变异操作:根据变异概率随机从群体中选择c个个体,对于选中的个体,根据高斯分布,随机选择一位用随机数进行代替。
步骤4.8:判断当前进化代数g是否小于最大进化代数gmax,若是,则返回步骤4.2,若否,则输出优化后单隐层神经网络模型的权值和阈值,继续步骤5。
步骤5:对神经网络的权值和阈值进行解码,并赋予神经网络模型,输出经非支配排序的遗传算法优化的神经网络模型。
根据工业生产的要求,实际凸度值在设定值±10μm内视为产品合格,那么由图4可以看出,采用本发明提出的预测模型进行预测有94.42%的产品符合要求,相对于现有实际情况中仅有61.95%的产品合格是很有优势的。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解;其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;因而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!