一种空调负荷预测方法及装置与流程
本发明涉及时间序列分析领域,尤其涉及一种空调负荷预测方法及装置。
背景技术:
随着城市建设的飞速发展,建筑能耗量也在高速增长。空调运行能耗占建筑尤其大型公共建筑运行能耗比重很大,因此降低空调系统的运行能耗一直是建筑节能的重点。采用合理的运行调节方法是提高空调系统能源利用率的主要技术途径之一,而该途径的实现则需要依赖于是否能够准确的对空调负荷进行预测,可见预测空调负荷的方法显得尤其重要。
空调负荷预测是指在建筑运行阶段,对未来时刻空调系统运行所需要的冷热量进行短期预测,其目的是为空调系统优化控制服务,以预测的负荷分布为基础,确定最优的运行工况或设定点,指定最佳的空调运行策略,保证空调房间的舒适性和空调系统运行的节能型。
空调负荷数据可看作是一种时间序列,线性自相关性较强,同时又受到多种外部随机因素的影响,如太阳辐射热(天气)、室外空气温度、新风、建筑环境内机电设备的使用数量等。除此之外,空调负荷量同其生产和工作状态有关,以天为单位进行周而复始地运转,即具有日周期性的特点。因此,传统的时间序列模型对具有上述特点的数据进行回归拟合和预测时会受到局限,预测结果往往不太理想。
技术实现要素:
本发明提供一种空调负荷预测方法及装置,用以提高预测精度。
本发明实施例提供了一种空调负荷预测方法,该预测方法包括:
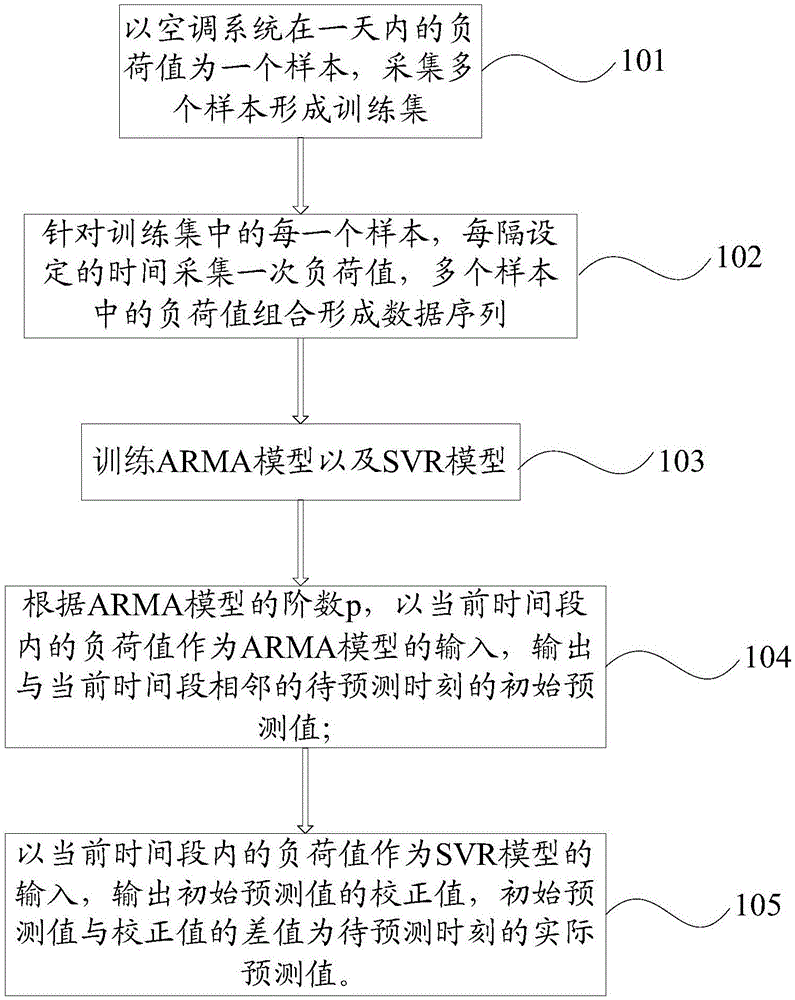
以空调系统在一天内的负荷值为一个样本,采集多个样本形成训练集;
针对所述训练集中的每一个样本,每隔设定的时间采集一次负荷值,多个所述样本中的负荷值组合形成数据序列;
采用所述数据序列训练arma(p、q)模型;
根据所述arma模型的阶数p,依次以所述数据序列中的负荷值作为所述arma模型的输入,输出与输入的负荷值相对应的下一时刻的负荷值的估计值;根据所述数据序列中的负荷值以及负荷值与对应的估计值的差值训练svr模型;
根据所述arma模型的阶数p,以当前时间段内的负荷值作为所述arma模型的输入,输出与所述当前时间段相邻的待预测时刻的初始预测值;以所述当前时间段内的负荷值作为svr模型的输入,输出所述初始预测值的校正值,所述初始预测值与所述校正值的差值为所述待预测时刻的实际预测值。
上述实施例中,通过训练arma模型,对数据序列的线性部分进行拟合,并以上述数据序列作为arma模型的输入,输出与输入的负荷值相对应的下一时刻的负荷值的估计值,再将该数据序列中的负荷值以及负荷值与对应的估计值的差值训练svr模型,对数据序列的非线性部分进行拟合;在进行预测时,以svr模型的输出结果作为校正值,用于修正arma模型的预测结果,这两个模型相结合的算法提高了单一模型的准确率,即提高了预测精度。
可选的,所述训练集具体通过以下方式获得:
采集多个样本形成采样集;
对所述采样集进行多次随机采样,得到多个所述训练集;
还包括:
针对多个所述训练集,根据对应的实际预测值,采用结合策略,得到最终预测值。
可选的,所述训练集中的样本均为工作日样本,或所述训练集中的样本均为非工作日样本。
可选的,所述采用所述数据序列训练arma(p、q)模型具体包括:
根据贝叶斯信息准则函数分别确定arma模型的阶数p和q。
可选的,所述针对多个所述训练集,根据对应的实际预测值,采用结合策略,得到最终预测值具体为:
计算每个训练集对应的权值;
根据所述每个训练集对应的权值以及实际预测值,采用加权平均法得到所述最终预测值。
可选的,所述计算每个训练集对应的权值具体为:
针对所述每个训练集对应的arma模型以及svr模型,选取除自身以外的其它训练集中的数据序列作为所述arma模型以及所述svr模型的测试数据,计算所述每个训练集对应的预测错误率et为:
其中,yi为所选取的数据序列中所包含的负荷值;以所选取的数据序列为所述arma模型以及所述svr模型的输入,hi为所述arma模型的输出值与所述svr模型的输出值的差值;n为所选取的数据序列中所包含的数据个数;
根据所述每个训练集对应的预测错误率et,权值λt为:
可选的,所述对所述采样集进行多次随机采样,得到多个所述训练集具体为:
采用自助采样法对所述采样集进行多次采样,得到多个所述训练集。
可选的,采用所述数据序列训练arma模型前还包括:
对所述数据序列进行平稳性检验,若满足平稳性特征,则进入下一步;若不满足平稳性特征,则对所述数据序列进行差分处理,直到满足平稳性特征。
本发明实施例还提供了一种空调负荷预测装置,该空调负荷预测装置包括:
采样模块,用于采集多个样本形成训练集,其中,以空调系统在一天内的负荷值为一个样本;
数据处理模块,用于针对所述训练集中的每一个样本,每隔设定的时间采集一次负荷值,并将多个所述样本中的负荷值组合形成数据序列;
模型训练模块,用于采用所述数据序列训练arma(p、q)模型;根据所述arma模型的阶数p,以所述数据序列中的负荷值作为所述arma模型的输入,输出与输入的负荷值相对应的下一时刻的负荷值的估计值;根据所述数据序列中的负荷值以及负荷值与对应的估计值的差值训练svr模型;
预测模块,用于根据所述arma模型的阶数p,以当前时间段内的负荷值作为所述arma模型的输入,输出与所述当前时间段相邻的待预测时刻的初始预测值;以所述当前时间段内的负荷值作为svr模型的输入,输出所述初始预测值的校正值,将所述初始预测值与所述校正值的差值作为所述待预测时刻的实际预测值。
上述实施例中,通过模型训练模块分别训练arma模型以及svr模型,并在进行预测时,以svr模型的输出结果作为校正值,用于修正arma模型的预测结果,这两个模型相结合的算法提高了单一模型的准确率,即提高了预测精度。
可选的,所述采样模块,具体用于采集多个样本形成采样集,并对所述采样集进行多次随机采样,得到多个所述训练集;
所述数据处理模块,还用于对每个训练集中的样本进行处理,得到相应的数据序列;
所述模型训练模块,还用于采用所述每个训练集对应的数据序列训练arma模型和svr模型;
所述预测模块,还用于将当前时间段内的负荷值输入每个训练集对应的arma模型和svr模型中,得到实际预测值,并针对多个所述训练集,根据对应的实际预测值,采用结合策略,得到最终预测值。
可选的,所述模型训练模块,具体用于根据贝叶斯信息准则函数分别确定arma模型的阶数p和q。
可选的,所述预测模块,具体用于根据所述每个训练集对应的权值以及实际预测值,采用加权平均法得到所述最终预测值。
可选的,所述采样模块,采用自助采样法对所述采样集进行多次随机采样,得到多个所述训练集。
附图说明
图1为本发明实施例提供的预测方法的算法流程图;
图2为本发明实施例提供的预测方法的原理框架图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步详细地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供了一种空调负荷预测方法,该预测方法通过采用svr模型训练arma模型的残差,提高了单一模型的准确率。该预测方法具体包括:
以空调系统在一天内的负荷值为一个样本,采集多个样本形成训练集;
针对训练集中的每一个样本,每隔设定的时间采集一次负荷值,多个样本中的负荷值组合形成数据序列;
采用该数据序列训练arma(p、q)模型;
根据arma模型的阶数p,依次以数据序列中的负荷值作为arma模型的输入,输出与输入的负荷值相对应的下一时刻的负荷值的估计值;根据数据序列中的负荷值以及负荷值与对应的估计值的差值训练svr模型;
根据arma模型的阶数p,以当前时间段内的负荷值作为arma模型的输入,输出与当前时间段相邻的待预测时刻的初始预测值;以当前时间段内的负荷值作为svr模型的输入,输出初始预测值的校正值,初始预测值与校正值的差值为待预测时刻的实际预测值。
上述实施例中,通过训练arma模型,对数据序列的线性部分进行拟合,并以上述数据序列作为arma模型的输入,输出与输入的负荷值相对应的下一时刻的负荷值的估计值,再将该数据序列中的负荷值以及负荷值与对应的估计值的差值训练svr模型,对数据序列的非线性部分进行拟合;在进行预测时,以svr模型的输出结果作为校正值,用于修正arma模型的预测结果,这两个模型相结合的算法提高了单一模型的准确率,即提高了预测精度。
为了更加清楚的了解本发明实施例提供的空调负荷预测方法的原理,现结合附图进行详细的描述。
如图1所示,该预测方法主要包括以下步骤:
步骤s101:以空调系统在一天内的负荷值为一个样本,采集多个样本形成训练集;如以天为单位,采集m天的负荷值形成该训练集;
步骤s102:针对训练集中的每一个样本,每隔设定的时间采集一次负荷值,多个样本中的负荷值组合形成数据序列;
步骤s103:采用该数据序列训练arma(p、q)模型;根据arma模型的阶数p,依次以数据序列中的负荷值作为arma模型的输入,输出与输入的负荷值相对应的下一时刻的负荷值的估计值;根据数据序列中的负荷值以及负荷值与对应的估计值的差值训练svr模型;
步骤s104:根据arma模型的阶数p,以当前时间段内的负荷值作为arma模型的输入,输出与当前时间段相邻的待预测时刻的初始预测值;
步骤s105:以当前时间段内的负荷值作为svr模型的输入,输出初始预测值的校正值,初始预测值与校正值的差值为待预测时刻的实际预测值。
受节假日等的影响,空调负荷将呈现出不同的变化规律,因此,为提高预测精度,如在步骤s101中,训练集中的样本均为工作日样本,或者均为非工作日样本,并根据训练得到的arma模型以及svr模型去预测工作日待预测时刻的负荷值,或预测非工作日待预测时刻的负荷值。
在采用数据序列训练arma模型前,需要进行平稳性检验,若满足平稳性特征,则进入下一步;若不满足平稳性特征,则需对数据序列进行差分处理,直到满足平稳性特征。为了便于描述,采用d={y1,y2…yk}来表示上述数据序列,k表示时刻;通过平稳性检测后,采用该数据序列训练arma模型的具体方法为:
首先,自回归移动平均模型(auto-regressivemovingaverage,arma)的表达式为:
yt=φ1yt-1+φ2yt-2+……+φpyt-p+at-θ1at-1-θ2at-2-……-θqat-q
其中,φi和p分别为自回归系数和自回归部分的滞后阶数,θj和q分别为移动平均系数和移动平均部分的滞后阶数,at是白噪声序列;
根据贝叶斯信息准则函数(bayesianinformationcriteria,bic)分别确定arma模型的阶数p和q,阶数确定后,arma模型的参数
其中,r0,r1,...rq为序列的自协方差函数,利用数值解法即可得到各参数的解。根据不同的训练集,arma模型的阶数选择不同,从而辨识的参数也不同,进而增强了个体学习器的多样性。
其次,arma模型确定后,根据arma模型的阶数p,依次以数据序列中的负荷值作为上述arma模型的输入,输出与输入的负荷值相对应的下一时刻的负荷值的估计值;根据数据序列中的负荷值以及负荷值与对应的估计值的差值训练svr模型;
具体的,支持向量回归模型(supportvectorregression,svr)的表达式为:
f(x,w)=w·φ(x)+b
即以数据集
s.t.f(xi)-yi≤ε+ξi
yi-f(xi)≤ε+ξ′i
ξi≥0,ξ′i≥0,i=1,2...n
使用拉格朗日方程将该问题转化成一个对偶问题:
通过smo算法可辨识出svr模型的参数。
最后,通过得到的arma模型与svr模型对未来时刻的空调负荷进行预测,即,以当前时间段内的负荷值作为arma模型的输入,输出与当前时间段相邻的待预测时刻的初始预测值;以当前时间段内的负荷值作为svr模型的输入,输出初始预测值的校正值,初始预测值与校正值的差值为待预测时刻的实际预测值。
为了进一步提高预测精度,可以获取多个步骤s101中的训练集,对每个训练集依次采用步骤s102~步骤s104中所述的方法操作,最终得到的待预测时刻的负荷值有多个,根据这些预测值,采用结合策略,如平均法、加权平均法等,得到最终的预测结果。
具体的,步骤s201:采集多个样本形成采样集,并对采样集进行多次随机采样,得到多个上述训练集;
其中,采样集中的样本均为工作日样本或非工作日样本,并通过自助采样法对采样集进行采样,这样可以使得每个训练集中的数据差异最大化,自助采样法具体为:给定包含m个样本的数据集d,对它进行采样产生数据集d′;每次随机从d中挑选一个样本,将其拷贝放入d′,然后再将该样本放回初始数据集d中,使得该样本在下次采样时仍有可能被采到;这个过程重复执行m次后,即得到了包含m个样本的数据集d′。
步骤s202:针对每个训练集中的每一个样本,每隔设定的时间采集一次负荷值,并将属于同一训练集的多个样本中的负荷值组合形成数据序列;
步骤s203:针对每个训练集,分别采用步骤s103中的方法训练arma模型和svr模型;
步骤s204:针对每个训练集,分别采用步骤s104中的方法对待预测时刻的负荷值进行预测,得到多个实际预测值;
步骤s205:针对上述多个训练集,根据对应的实际预测值,采用结合策略,得到最终预测值。
步骤s201~步骤s205中,每个训练集可以看作是一个弱学习器的训练集,通过每个训练集对应的数据序列训练得到的arma模型以及svr模型为该弱学习器的训练模型,并且,arma模型输出的初始预测值以及svr模型输出的校正值的差值即为该弱学习器的输出值;多个这样的弱学习器通过结合策略得到一个预测精度更高的强学习器。
在一个具体的实施例中,采用的结合策略为:计算每个训练集对应的权值;根据每个训练集对应的权值以及实际预测值,采用加权平均法得到最终预测值。即可以为每个弱学习器分配一个权值,其中,权值根据弱学习器的泛化误差确定,误差越小的弱学习器其权值则越大,即在最终强学习器中的作用越大。
相应的算法为:
针对每个训练集对应的arma模型以及svr模型,选取除自身以外的其它训练集中的数据序列作为该arma模型以及svr模型的测试数据,计算相应的每个弱学习器的预测错误率et为:
其中,yi为所选取的数据序列中所包含的负荷值;以所选取的数据序列为arma模型以及svr模型的输入,hi为该arma模型的输出值与该svr模型的输出值的差值;n为所选取的数据序列中所包含的数据个数;
根据每个弱学习器的预测错误率et,权值λt为:
在进行预测时,根据每个弱学习器的输出值ht(实际预测值)以及相应的权值λt得到强学习器的输出值h(最终预测值)为:
h=λ1h1+λ2h2+……+λtht
在一个具体的实施例中,如图2所示,取样本天数m=16,弱学习器个数t=12,arma模型的阶数限制在p≤5,q≤5内。
本实施例包括如下步骤:
步骤s301:以空调系统在一天内的负荷值为一个样本,在工作日中采集多个样本形成工作日采样集,在非工作日中采集多个样本形成非工作日采样集,分别标记为d1和d2,在d1和d2中分别筛选出缺失值少、采样点较完备的16天的数据;
步骤s302:对第一步中得到的工作日采样集d1,分别借助自助采样法,对其进行采样,具体为,以天为单位,每次采样为一天的数据,随机采样一次后将样本放回原采样集,再进行第二次随机采样,共计16次,得到一个包含16天,即16个样本的训练集;重复上述操作12次,即可得到12个训练集,每个训练集为一个弱学习器的训练集;
步骤s303:对每个弱学习器重复以下操作:
1)针对训练集中的每一个样本,删除无效值,补充缺失值,对空调负荷曲线进行平滑滤波,在早上7点之后,每十分钟截取一次数据,得到一天后预处理的数据约为60-70个;
2)16个样本中的负荷值组合形成数据序列,对该数据序列进行平稳性检验,若满足平稳性特征,则进入步骤3),若不满足,则对其进行差分处理,再进行平稳性检验,直至其满足弱平稳性特征;
3)采用相应的数据序列对arma模型进行参数辨识,arma模型的表达式为:
yt=φ1yt-1+φ2yt-2+......+φpyt-p+at-θ1at-1-θ2at-2-......-θqat-q
采用bic准则定阶,确定p值和q值后,对应的参数估计公式如下:
其中,r0,r1,...rq为序列的自协方差函数。利用数值解法得到各参数的解,arma模型参数辨识完毕;
4)arma模型确定后,根据arma模型的阶数p,依次以数据序列中的负荷值作为上述arma模型的输入,输出与输入的负荷值相对应的下一时刻的负荷值的估计值;根据数据序列中的负荷值以及负荷值与对应的估计值的差值训练svr模型;
即以数据集
核函数k(xi,xj)=φ(xi)tφ(xi)选用高斯核函数,即径向基函数(radialbasisfunction,rbf):
其中,xc为核函数中心,σ为函数的宽度参数,控制了函数的径向作用范围;上述对偶问题求解采用smo(sequentialminimaloptimization)算法,最终得到svr模型参数w和b;
5)通过得到的arma模型与svr模型对空调负荷进行预测,即,根据arma模型的阶数p,以当前时间段内的负荷值作为arma模型的输入,输出与当前时间段相邻的待预测时刻的初始预测值;以当前时间段内的负荷值作为svr模型的输入,输出初始预测值的校正值,初始预测值与校正值的差值为待预测时刻的实际预测值;
6)选取除自身以外的其它训练集中的数据序列作为该arma模型以及svr模型的测试数据,计算每个弱学习器对应的预测错误率et为:
其中,yi为所选取的数据序列中所包含的负荷值;以所选取的数据序列为arma模型以及svr模型的输入,hi为该arma模型的输出值与该svr模型的输出值的差值;n为所选取的数据序列中所包含的数据个数;
根据弱学习器的预测错误率et,确定弱学习器的权值λt为:
步骤s304:采用加权平均的结合策略,将弱学习器集成为一个强学习器
本发明实施例还提供了一种空调负荷预测装置,该装置包括:
采样模块,用于采集多个样本形成训练集,其中,以空调系统在一天内的负荷值为一个样本;
数据处理模块,用于针对训练集中的每一个样本,每隔设定的时间采集一次负荷值,并将多个样本中的负荷值组合形成数据序列;
模型训练模块,用于采用数据序列训练arma(p、q)模型;根据arma模型的阶数p,以数据序列中的负荷值作为arma模型的输入,输出与输入的负荷值相对应的下一时刻的负荷值的估计值;根据数据序列中的负荷值以及负荷值与对应的估计值的差值训练svr模型;
预测模块,用于根据arma模型的阶数p,以当前时间段内的负荷值作为arma模型的输入,输出与当前时间段相邻的待预测时刻的初始预测值;以当前时间段内的负荷值作为svr模型的输入,输出初始预测值的校正值,将初始预测值与校正值的差值作为待预测时刻的实际预测值。
为了进一步提高预测精度,可以获取多个这样的训练集,并通过数据处理模块对每个训练集中的样本进行处理,得到一组数据序列;根据相应的数据序列,通过模型训练模块训练arma模型以及svr模型,最终通过预测模块分别输出待预测时刻的负荷值,根据这些预测值,采用结合策略,如算法平均法、加权平均法等,得到最终的预测结果。
具体的,采样模块,具体用于采集多个样本形成采样集,并对采样集进行多次随机采样,得到多个训练集,通常采用自助采样法对采样集进行多次随机采样;
数据处理模块,还用于对每个训练集中的样本进行处理,得到相应的数据序列;
模型训练模块,还用于采用每个训练集对应的数据序列训练arma模型和svr模型;其中,可以根据贝叶斯信息准则函数分别确定arma模型的阶数p和q;
预测模块,还用于将当前时间段内的负荷值输入每个训练集对应的arma模型和svr模型中,得到实际预测值,并针对多个训练集,根据对应的实际预测值,采用结合策略,如算术平均法、加权平均法,得到最终预测值;在一个具体的实施方式中,具体用于根据每个训练集对应的权值以及实际预测值,采用加权平均法得到最终预测值。
通过以上描述可以看出,本发明实施例中,采用自助采样法以及算法参数扰动法增大了弱学习器之间的差异性;每个弱学习器中,采用svr模型训练arma模型的残差,用以修正arma模型的预测结果,这两种模型的结合,提高了单一模型的准确率;结合多个弱学习器,采用加权平均法得到强学习器,提高了预测精度。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!