一种基于FPGA的卷积神经网络加速器的制作方法
本发明涉及cnn加速技术,特别是一种基于fpga的卷积神经网络加速器。
背景技术:
随着边缘计算的兴起,嵌入式设备等资源受限实现cnn变得尤为迫切,现有的基于通用处理器的方案以及基于gpu加速的方案难以在资源受限的嵌入式设备上实现。
现有的实现方案是基于通用处理器的方案或者基于gpu加速的方案,但是通用处理器实现cnn难以满足高性能的要求,gpu加速的方案功耗过大,难以在资源受限的嵌入式设备上实现。
为此,基于fpga的加速方案如何在资源受限的情况下满足高性能,低功耗的要求成为当前需要解决的技术问题。
技术实现要素:
针对现有技术中的问题,本发明提供一种基于fpga的卷积神经网络加速器,该加速器借助于对运算处理单元的重构,处理cnn网络中各层的操作,达到资源的重复利用,进而可满足嵌入式设备上实现cnn网络,且降低功耗。
第一方面,本发明提供一种基于fpga的卷积神经网络加速器,包括:
控制器、n路并行的运算处理单元、权值更新单元、偏置更新单元;
所述控制器与每一路的运算处理单元连接,所述权值更新单元和所述偏置更新单元分别与所述控制器、每一路的运算处理单元连接;
其中,n大于等于所述卷积神经网络cnn的第一层结构中并行的卷积核的数量;
所述控制器依据所述cnn的第m层结构,重构每一路的运算处理单元中各模块的连接关系以匹配所述第m层结构,并采用权值更新单元和所述偏置更新单元分别更新重构的运算处理单元的权值和偏置,以使重构的运算处理单元按照所述第m层结构的处理方式对信息进行处理,所述m大于等于1,n大于1。
可选地,所述cnn为lenet-5网络时,所述lenet-5网络的第一层结构包括:6个卷积核和6个池化层,处理方式为对原始图像进行卷积之后,进行平均值池化;得到6个特征图;
第二层结构包括:6*12个卷积核;处理方式为:6个特征图分别与12排的6个卷积核相乘之后相加输出一个结果,具体地,6个缓存的第一层结构输出的特征图与第一排对应的卷积核相乘的结果再相加输出第一个特征图,6个缓存的第一层结构输出的特征图再与第二排的6个对应的卷积核相乘之后的结果再相加输出第二个特征图,依次方式,总共输出12个特征图;
基于所述lenet-5网络的第一层结构和第二层结构,所述加速器的运算处理单元的数量为6路。
可选地,每一路的运算处理单元包括:
池化缓存模块、卷积模块、卷积缓存模块、池化模块;
所述池化缓存模块连接一地址发生器和一卷积地址产生器;
所述卷积缓存模块连接一地址产生器和一池化地址发生器;
所述池化缓存模块和卷积模块之间设置有用于选择输入到卷积模块的数据的数据选择模块data-mux;
所述卷积模块和卷积缓存模块之间设置有用于选择卷积后池化模块的卷积选择器conv-mux;
所述池化模块和所述池化缓存模块之间设置有用于选择池化后操作的池化选择器pooling-mux;
其中,所有运算处理单元使用一个data-mux、conv-mux、pooling-mux;
所述data-mux连接用于输入原始图像的原始图像地址发生器的输入端、所述pooling-mux连接输出端,
所述控制器连接所述data-mux、conv-mux、pooling-mux,以及连接每一路运算处理单元的卷积缓存模块的池化地址发生器,每一次池化模块的输出连接所述控制器;
所述权值更新单元连接每一个卷积模块,偏置更新单元连接每一个卷积模块。
可选地,所述加速器中匹配第一层结构的处理方式包括:
所述控制器向每一个卷积模块下发需要的权值和偏置,并将原始图像输入至每一个卷积模块进行卷积操作,以输出6个特征图,输出的每一个特征图在各自对应的卷积缓存模块中进行缓存;
当卷积模块的卷积操作结束之后,每一个特征图进入到池化模块进行池化操作,池化操作后的特征图输出到池化缓存模块,以进行第二层操作。
可选地,所述加速器中匹配第二层结构的处理方式包括:
控制器根据所述池化模块完成池化操作之后发送的池化结束信号,重构用于进行第二层操作的结构,并向每一卷积模块下发需要的偏置和权值,以对应lenet-5网络中第二层结构的第一排;
每一个池化缓存中的特征图与各自的卷积模块进行卷积操作之后,将6个卷积操作之后的特征图相加并缓存在第一个卷积缓存模块中,由第一个池化模块进行池化操作,输出第一个特征图;
此时,控制器接收到第一个池化模块发送的池化结束信号之后,向每一个卷积模块下发需要的偏置和权值,以对应lenet-5网络中第二层结构的第二排;
每一个池化缓存中的特征图与各自的卷积模块进行卷积操作之后,将6个卷积操作之后的特征图相加并缓存在第二个卷积缓存模块中,由第二个池化模块进行池化操作,输出第二个特征图;
重复上述更新偏置和权值的步骤,依次类推,直至输出十二个特征图。
可选地,所述池化缓存模块连接的卷积地址产生器中存储池化缓存模块缓存的特征图需要的像素地址;
所述地址发生器中存储对应卷积模块卷积操作的特征图需要的像素地址;
所述卷积缓存模块连接的地址产生器中存储有卷积缓存模块缓存的特征图需要的像素地址;
所述池化地址发生器中存储对应池化模块池化操作的特征图需要的像素地址。
第二方面,本发明提供一种嵌入式设备,包括上述第一方面任一所述的基于fpga的卷积神经网络加速器,以使所述嵌入式设备能够实现卷积神经网络加速器。
本发明具有的有益效果:
1)本发明的基于阵列处理器的卷积神经网络加速器,通过硬件设计实现了软件程序的cnn中各层的信息处理过程,使得在资源受限的嵌入式设备上满足高性能,低功耗的要求。
2)本发明中,运算处理单元通过控制器下发控制信号,进而组建内部模块实现处理cnn网络的第一层、第二层的操作。
此外,对于不同层、不同操作(卷积和池化)所需要的像素值不同,本发明在上述处理过程中还可以自主选择不同的地址发生器,使得地址发生器非常灵活。
附图说明
图1a为当前的lenet-5的网络结构示意图;
图1b为图1a中第二层结构的示意图;
图2为本发明一实施例提供的基于fpga的卷积神经网络加速器的结构示意图;
图3a为图2所示的第一层操作的流程示意图;
图3b示出图2所示的第一层操作时运算处理单元的结构示意图;
图4a为图2所示的第二层操作的流程示意图;
图4b为图2所示的第二层操作时运算处理单元的结构示意图。
具体实施方式
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
实施例一
cnn网络是一种高度并行的网络,层层之间互相独立。通用处理器实现cnn是串行的方式实现,针对高度并行的cnn,显然性能不高,而本发明是基于fpga的实现,fpga本身固有的并行性切合该网络的高度并行,基于fpga的实现方案能够满足高性能的要求;另外,基于gpu的加速方案,虽然gpu是并行处理的,但是过高的功耗难以在资源受限的嵌入式设备上实现,而fpga是一种低功耗的加速方案,满足嵌入式设备的资源受限的要求。
如图2所示,本实施例提供一种基于fpga的卷积神经网络加速器,本实施例的加速器为硬件结构,其通过硬件的各种连接实现cnn网络的功能。具体地,本实施例的加速器包括:
控制器、n路并行的运算处理单元、权值更新单元、偏置更新单元;
所述控制器与每一路的运算处理单元连接,所述权值更新单元和所述偏置更新单元分别与所述控制器、每一路的运算处理单元连接;
其中,n大于等于所述卷积神经网络cnn的第一层结构中并行的卷积核的数量;
所述控制器依据cnn的第m层结构,重构每一路的运算处理单元中各模块的连接关系以匹配所述第m层结构,并采用权值更新单元和所述偏置更新单元分别更新重构的所述运算处理单元的权值和偏置,以使重构的运算处理单元按照所述第m层结构的处理方式对信息进行处理,所述m大于等于1,n大于1。
结合图2所示,本实施例的加速器还包括全连接层,经过运算处理单元待输出的结果经过全连接层之后再进行结果输出。
特别说明的是,本实施例的加速器为通过硬件方式实现对软件的cnn网络的信息处理过程。
在一种可能的实现方式中,上述每一路的运算处理单元可包括:
池化缓存模块、卷积模块、卷积缓存模块、池化模块;
所述池化缓存模块连接一地址发生器和一卷积地址产生器;
所述卷积缓存模块连接一地址产生器和一池化地址发生器。
本实施例中的池化地址发生器可理解图2中所示的a、b和c的整体。在本实施例的硬件电路结构中,每个相关的缓存模块前面都分别有个地址产生器和地址发生器。地址产生器和地址发生器同时存在,相互配对,相当于一存一取。地址产生器是存,地址发生器是取。
池化缓存模块前面有地址发生器和地址产生器,是一对的,要送到卷积模块,此时可以分别叫卷积地址发生器,卷积地址产生器,在本实施例中称作地址发生器,卷积地址产生器。同理,卷积缓存模块前面也有个地址发生器和地址产生器,可以分别叫做池化地址发生器,池化地址产生器,在本实施例中可简单称作地址产生器,这个地址产生器和上面的卷积地址产生器是对应的,对应的功能也是一样的。
在图2中,池化地址发生器可包括:28*28的地址发生器(如图2中的“a”)和10*10的地址发生器(如图2中的“b”)。
如下举例的在实现lenet-5神经网络的第一层的信息处理时,使用28*28的地址发生器,在实现lenet-5神经网络的第二层的信息处理时,使用10*10的地址发生器。控制器通过图2中示出的“c”表示的pc_mux选择28*28的地址发生器还是10*10的地址发生器。
进一步地,所述池化缓存模块连接的卷积地址产生器中存储池化缓存模块缓存的特征图需要的像素地址;
所述地址发生器中存储对应卷积模块卷积操作的特征图需要的像素地址;
所述卷积缓存模块连接的地址产生器中存储有卷积缓存模块缓存的特征图需要的像素地址;
所述池化地址发生器中存储对应池化模块池化操作的特征图需要的像素地址。
所述池化缓存模块和卷积模块之间设置有用于选择输入到卷积模块的数据的数据选择模块data-mux;
所述卷积模块和卷积缓存模块之间设置有用于选择卷积后池化模块的卷积选择器conv-mux;
所述池化模块和所述池化缓存模块之间设置有用于选择池化后操作的池化选择器pooling-mux;
其中,所有运算处理单元使用一个data-mux、conv-mux、pooling-mux;
所述data-mux连接用于输入原始图像的原始图像地址发生器的输入端、所述pooling-mux通过全连接层连接输出端。
本实施例中的全连接层和cnn的全连接层的功能一致。在池化后可以经过全连接层再输出。
所述控制器连接所述data-mux、conv-mux、pooling-mux,以及连接每一路运算处理单元的卷积缓存模块的池化地址发生器,每一次池化模块的输出连接所述控制器;
所述权值更新单元连接每一个卷积模块,偏置更新单元连接每一个卷积模块。在图2中,权值更新单元与偏置更新单元分别与6个卷积模块相连,每次都可以同时下发给6个卷积模块需要的权值与偏置。
举例来说,数据选择模块data_mux:根据控制器控制,一开始运算的是lenet-5神经网络的第一层,需要的是原始的图像,控制器控制输入到6个卷积模块的数据是原始图像(如图3b所示),进入lenet-5神经网络的第二层操作,还是通过pooling_end信号,控制输入到卷积模块的是池化缓存数据(如图4b所示),因为第一层操作的是原始图像,第二层操作的是第一层池化之后的数据,可以理解一个开关,一开始开关连接原始图像,到了第二层开关连接的是池化缓存模块。
卷积选择器conv_mux:基于上述理解,例如在第一层的时候,卷积结果直接输入到卷积缓存模块,在第二层的时候,卷积后的结果会相加输入到第一个池化模块(此时,第二层每次只用到第一个池化模块,其他的五个属于空闲状态)。
池化选择器pooling_mux:基于上述描述,如果是第一层结果输出到池化缓存模块,如果是第二层,就是最后的输出结果。
本实施例的基于阵列处理器的卷积神经网络加速器,使得在资源受限的嵌入式设备上满足高性能,低功耗的要求。
此外,上述每一路运算处理单元通过控制器下发控制信号,进而组建内部模块实现处理cnn网络的第一层、第二层的操作。
特别地,对于不同层、不同操作(卷积和池化)所需要的像素值不同,本发明在上述处理过程中还可以自主选择不同的地址发生器,使得地址发生器非常灵活。
实施例二
为了更好的理解本发明中基于阵列处理器的卷积神经网络加速器的结构,其加速器中运算处理单元的可重构性能,以下以lenet-5神经网络的结构及信息处理过程进行举例说明。
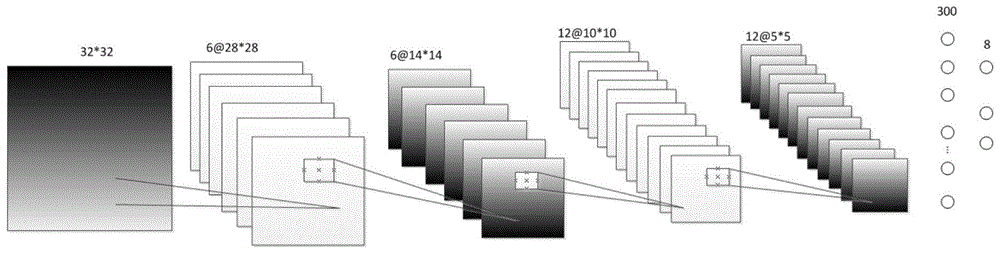
如图1a所示,lenet-5网络的第一层结构包括:6个卷积核和6个池化层,处理方式为对原始图像进行卷积之后,进行平均值池化;得到6个特征图;
如图1b所示,第二层结构包括:6*12个卷积核;处理方式为:6个特征图分别与12排的6个卷积核相乘之后相加输出一个结果,具体地,6个缓存的第一层结构输出的特征图与第一排对应的卷积核相乘的结果再相加输出第一个特征图,6个缓存的第一层结构输出的特征图再与第二排的6个对应的卷积核相乘之后的结果再相加输出第二个特征图,依次方式,总共输出12个特征图;图1b示出了lenet-5网络的第二层结构的示意图。
具体地,第二层的操作过程是,第一层结构的输出结果缓存以后,6个特征图分别与12排的6个卷积核相乘之后相加输出一个结果,也就是6个缓存与第一排的对应的卷积核相乘结果相加输出第一个特征图,然后特征图与第二排的6个对应卷积核相乘之后相加输出第二个特征图,总共输出12个特征图。
基于所述lenet-5网络的软件程序实现的第一层结构和第二层结构,所述加速器的运算处理单元的数量为6路。
结合图3a和图3b所示,本实施例中硬件结构的加速器中匹配第一层结构的处理方式包括:
所述控制器通过权值更新单元和偏置更新单元向每一个卷积模块下发需要的权值和偏置,并将原始图像输入至每一个卷积模块进行卷积操作,以输出6个特征图,输出的每一个特征图在各自对应的卷积缓存模块中进行缓存;
当卷积模块的卷积操作结束之后,每一个特征图进入到池化模块进行池化操作,池化操作后的特征图输出到池化缓存模块,以进行第二层操作。
结合图4a和图4b所示,本实施例中硬件结构的加速器中匹配第二层结构的处理方式包括:
控制器根据所述池化模块完成池化操作之后发送的池化结束信号(eop_out_1h信号),重构用于进行第二层操作的结构,例如,通过权值更新单元和偏置更新单元向每一卷积模块下发需要的偏置和权值,以对应lenet-5网络中第二层结构的第一排。
每一个池化缓存模块中的特征图与各自的卷积模块进行卷积操作之后,将6个卷积操作之后的特征图相加并缓存在第一个卷积缓存模块中,由第一个池化模块进行池化操作,输出第一个特征图;
此时,控制器接收到第一个池化模块发送的池化结束信号之后,向每一个卷积模块下发需要的偏置和权值,以对应lenet-5网络中第二层结构的第二排;
每一个池化缓存中的特征图与各自的卷积模块进行卷积操作之后,将6个卷积操作之后的特征图相加并缓存在第二个卷积缓存模块中,由第二个池化模块进行池化操作,输出第二个特征图;
重复上述更新偏置和权值的步骤,依次类推,直至输出十二个特征图。
可理解的是,针对第二层神经网络的操作,模拟第一排:6个池化缓存模块与第一排的卷积模块卷积之后,经过第一个池化模块输出第一个特征图;
再继续做模拟第二排的相同操作,在池化模块结束池化以后设置了一个eop_out_1h信号,每次池化结束,输出一个特征图的时候,控制器接收这个信号就让权值更新单元和偏置更新单元下发下一排的卷积模块所需要的权值和偏置,同理控制器根据eop_out_1h信号重新控制池化缓存模块重新输出第一个到最后一个卷积模块需要的像素值,(也就是控制缓存从头到尾取值取12次)。
本实施例中,控制器根据池化完成以后会有个eop_out_1h信号,这个信号是是池化结束的意思,每次碰到这个信号,都会下发下次需要的权值和偏置。根据这个eop_out_1h信号控制下发。
在本实施例中,以lenet-5网络第一层操作的权值和偏置是可以预先获知的,第二层操作中每一排的权值和偏置也是可以先获知的,为此,控制器可以依据lenet-5网络中第一层操作的权值和偏置、第二层操作中每一排的权值和偏置依序控制加速器中重构的用于实现第一层操作、第二层操作各排功能的运算处理单元的权值和偏置。
或者,可以理解的是,在硬件加速器中,所有运算处理单元均是可以根据卷积过程进行重构的。即6个卷积过程需要的模块是可重构的,第一层,第二层卷积过程需要的权值与偏置是不一样,通过下发不同的偏置与权值,可以用6个运算处理单元处理第一层,第二层的操作,第二层的输出结果需要相加输出给卷积缓存模块,所以第二层的6个卷积模块卷积后需要数据交换(6个结果相加,也可以理解为把第2-6个卷积模块的输出的结果全部加个第一个卷积模块的输出结果上,然后输出到卷积缓存模块)输出到卷积缓存。
即6个卷积模块在处理第一层操作时,直接6路输出给卷积缓存模块,第二层的时候,下发第二层需要的偏置与权值完成卷积模块的卷积运算后,6个卷积模块的输出结果相加输出到一个卷积缓存模块。
控制器根据eop_out_1h信号把所有的操作分为13个时间段,第一个时间段是第一层卷积,池化完成,第二个时间段是第二层的第一排6个卷积,池化完成操作完成,第三个时间段是第二层的第二排的6个卷积,池化完成操作完成,以此类推,第13个时间段是第二层的第12排的6个卷积,池化完成,都是通过池化结束信号eop_out_1h来进行控制。
第二点控制输出的是那个时间段,也就是处在哪个操作段。控制权值更新和偏置更新下发权值和偏置。
关于地址发生器、地址产生器、卷积地址产生器、池化地址产生器的说明如下:
因为池化模块处于第一层的特征图和池化模块处于第二层的特征图不一样,比如10*10和5*5的特征图,5*5的特征图需要的像素地址在0,1,5,6地址里面,10*10的特征图需要0,1,10,11地址里面的像素值,也是根据控制器,如果是在第一层就选择输出0,1,10,11的地址发生器,如果是第二层就选择可以输出0,1,5,6的地址发生器。即,根据所处在不同的层自主选择不同的地址发生器输出池化层需要的像素值。
特征图不是像素值,比如第一层的特征图是10*10,第一个点的池化是需要0,1,10,11地址里面的像素(地址里面放着像素)遇到第二层特征图是5*5,那么需要0,1,5,6地址的像素,所以根据不同层选择不同的地址发生器,输入相应的地址里面的像素值。
因为像素值都是在地址里面,所以每次取不同的地址就会输出不同的数据也就是像素值(也就是硬件的ram),第一层,第二层的特征图不一样,每次输出数据的地址也不一样,卷积的步长可以理解为1,也就是左移动1,池化的可以理解为步长为2。
本实施例中,根据不同层需要的不一样的地址数据输出相应的地址,存在灵活性。它也是受控制器控制,选择不同的地址发生器,输出相应地址的数据。地址发生器是输出的地址,通过这些地址找到相应的地址里面的数据。
实施例三
如图1a所示,在图1a所示的结构中,原始输入图像32*32,第一层卷积有6个卷积核,卷积之后是6个28*28的特征图,对这6个28*28的特征图作取平均值池化后得到6个14*14的特征图,第二层卷积有6*12个卷积核,第二层的卷积部分不是6个特征图与卷积核相乘输出,需要注意,第二层是6个特征图与6个卷积核相乘之后再相加(pe第一层无数据交换,第二层有数据有交换如将其他5个结果加到第一个pe上)输出一个特征图,这样的操作总共有12次,最后输出12个10*10的特征图,然后再是取平均值后的池化。输出得到12个5*5的特征图。
本发明基于fpga神经网络加速器的设计方案:
fpga的并行性切合神经网络的高度并行,分析lenet-5网络,可以知道,第一层,第二层都是卷积操作和池化操作,第一层和第二层的操作大致相同(存在的区别是第一层是直接卷积输出,第二层是6个卷积核相乘之后再相加输出,并且第一层,第二层的卷积核不同,偏置不同,图像大小不一样,第一层和第二层运算大致相似但是存在很大区别)考虑到提高性能,可以6路并行处理第一层的卷积操作和池化操作,此并行可以提高6倍性能,考虑到嵌入式设备的资源利用率问题,虽然第一层第二层的处理不是一样的,但是基本功能相同,要提高资源利用率,可以将运算单元设计成可重构的,既可以处理第一层的操作,当要处理第二层操作时,运算单元根据控制信号可重构性,也可以处理第二层操作,这样可以大大提高资源利用率。分析第二层的卷积操作,最大并行化是12次6个卷积核与6个特征图的相乘之后相加的结果,如果完全将第二层做成并行的,
需要12个第一层的6路并行,考虑cnn运算中,第一层的运算数据量远远高于池化以后第二层的数据量,如果完全使第二层并行,过多的资源并没有带来很大的数据提升,本发明考虑到嵌入式设备的资源问题,采用完全利用第一层的6路并行设计,第二层复用第一层的资源采取并行加串行的设计方式,以求资源的最大利用。具体实现结构图如图2所示。
图2所示的加速器采用的是6路并行设计,第一层数据处理完成,根据控制器将运算单元进行重构,并且控制权值和偏置,动态的调节运算单元,使运算单元既可处理第一层的操作也可处理第二层的操作,最终输出结果。
图2所示的加速器主要的运算单元是6路卷积与6路池化,该6路卷积与6路池化在控制器的控制下既可以满足第一层的运算,也可以满足第二层的运算,因为第一层,第二层所需要的权值与偏置不一样,控制根据不同层下发不同的权值与偏置,使运算单元具有灵活性可处理第一层与第二层的操作。在最大化并行的情况下,最大化利用资源,使运算单元可处理第一层与第二层的操作。
结合图3a所示,第一层具体操作流程包括:原始图像通过控制器下发的权重与偏置,使原始图像与6个卷积模块的卷积核作卷积,输出的6个maps,全部在卷积缓存模块中进行缓存,当卷积结束之后进入各自的池化模块进行池化操作,在进行6个池化操作,输出结果缓存到池化缓存模块中,以进行第二层操作。
data_mux多路选择器通过控制器在第一层连接原始图像到卷积模块的输入。conv_mux多路选择器通过控制器选择6个卷积模块的输出到6个卷积缓存模块。如图3a所示,在图3中加粗的黑色箭头指向对应cnn第一层操作中用到的模块,其中,黑色箭头指向信息走向。
结合图4a所示,第二层具体操作流程包括:第一层操作结束的数据缓存到池化缓存模块中,第二层有6*12=72个卷积核,每6个卷积核与第一层的6个maps卷积之后相加得到一个maps,这样的操作有12次,最后得到12个maps,为了充分利用第一层的6个卷积模块,把第一层的6个卷积模块做成可重构的,通过控制层下发不同的卷积核,可以分别完成第一层,第二层的卷积操作,第一层的输出结果与6个卷积核运算之后相加得到的一个maps全部缓存起来之后进入池化模块输出最后结果,然后重新输入第一层的缓存循环迭代12次,得到最终的结果。
第二层第一个池化后的特征图出来以后,pooling_end信号让池化缓存前的地址发生器重新开始生成地址,总共循环12次。这个时候卷积地址产生器是空闲的,因为不需要存数。
缓冲的设计:该加速器有卷积缓存模块,池化缓存模块,当卷积模块完成之后,结果都会存进卷积缓存模块之中,等缓存完成之后,根据需要,把缓存的值输入到下一个级池化模块进行运算,第一层运算结束将数据放在池化缓存模块中,然后通过多路选择器,将池化之后的缓存送入到第二层的卷积模块,进而经由池化模块后再经过全连接层输出最终结果。
本实施例中,通用处理是串行处理数据,对于32*32的原始图像,如果用串行处理第一层的卷积操作,将有28*28*6次运算,而fpga的并行处理,只有28*28次运算,可以提高6倍运算速度,同理并行的池化和串行操作可以大大提高运算性能,而对于gpu的高功耗,也可以大大减少功耗,满足嵌入式设备上实现cnn网络。
本发明针对的是lenet-5网络,不同的网络层数不一样,可以重构运算处理单元,处理所有的神经网络的每层的运算,因为神经网络每层的运算处理单元都相似,可以重构这个运算处理单元处理所有层的中间运算部分。
上述各个实施例可以相互参照,本实施例不对各个实施例进行限定。
最后应说明的是:以上所述的各实施例仅用于说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或全部技术特征进行等同替换;而这些修改或替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!