一种基于偏好统计的数据表征的模型拟合方法与流程
本发明涉及计算机视觉技术,尤其是涉及一种基于偏好统计的数据表征的模型拟合方法。
背景技术:
视觉是人类从大自然中获取信息的最主要的手段之一。人类感知外界信息很大一部分是通过视觉得到,其它的由味觉,听觉等得到。由此可见视觉信息的重要性。随着计算机技术的不断发展,人们不仅希望计算机能够获取得图像信息,也希望计算机具有人类视觉的感知功能,使其高效地处理图像信息,因此计算机视觉这门新兴的综合学科得到广泛关注。在过去的十几年里计算机视觉取得了蓬勃的发展,并出现了大量的基于计算机视觉的产品。例如:具有人脸自动检测和全景拍摄功能的数码相机,具有美颜功能的手机、汽车的智能泊车功能、汽车无人驾驶等。
对计算机视觉而言的一项重要任务是,如何让计算机从图像中获取人类所需要的信息。在大部分情况下,这些信息可以用参数模型来表示。所需要的这些参数模型可以通过,模型拟合方法从输入的数据中计算得到。因此,在很多计算机视觉的任务中,模型拟合具有重要的作用。
在过去的几十年里,大量的模型拟合方法已经被提出来。随机抽样一致的方法ransac,由于其简单和高效而被广泛地应用,但是该方法初始的设计,只能处理单一结构的数据。为处理多结构数据,许多方法(例如j-linage,ransacov)已经被提出来,并且提高了拟合的性能。然而,这些方法的拟合精度对于内点噪声尺度非常地敏感。因此,取代类似于ransac采用基于一致统计分析的方法,rha提出了偏好分析的方法。例如,j-linage提出采用二值偏好的方式来表征数据点,其中二值偏好是通过一系列获选模型的一致分析获取的。为了更加精确地描述点的偏好,t-linkage和rpa将二值偏好松弛为连续偏好来表征数据点。并且t-linkage和rpa分别利用一个连续的指数核函数和一个连续的鲁棒柯西函数来表征连续的偏好分析。另外,kf提出根据点到生成的模型假设的升序的残差安排来表征每个数据点。基于偏好分析的数据表征的模型拟合方法,在更加充分的描述数据点时发挥了很大的优势。然后这些拟合方法运用了偏好信息,他们缺少了一致信息,这可能导致不好的拟合结果。
技术实现要素:
本发明的目的在于提出一种基于偏好统计的数据表征的模型拟合方法。
本发明包括以下步骤:
1)准备数据集;
在步骤1)中,所述准备数据集的具体方法可为:输入n个数据点x={xi}i=1,...,n,从输入的数据点中采样m个最小子集生成模型假设h={hj}j=1,...,m,其中一个最小子集是估计一个模型所需要的最小子集,当生成一条直线需要两个点时,估计一个基础矩阵需要7个点或者8个点。
2)针对每个点xi,计算该点到m个模型假设的绝对残差(可用sampson距离度量);
3)j-linkage的一致统计分析本质是统计所有的残差值中小于固定阈值的残差,所述阈值由指定的或者估计的内点噪声尺度决定;一种非常粗糙的残差直方图数据表征,它将所有的小于阈值的残差归到一个直方图簇中和将大于阈值的残差归到另一个直方图簇中;提出将所有的残差值中小于固定阈值的残差,归到k个簇的残差直方图中进行残差数据表征,其中,k是一个相对小的整数>1,即,针对每个数据点xi,对该点关于每个假设的残差值进行排序,并且安排这些残差值到直方图的k个簇中,其中,k∈{1,...,k},因此,定义一个偏好统计矩阵
4)基于非参的核密度估计技术,获得
5)分析矩阵
其中,r(r<k)是在第i行中所出现的簇值的数目,ait表示第i行中的第t个簇值出现的次数,以及p(ait)是第i行中第t个簇值的概率,p(ait)通过归一化数值ait在所有簇集中的值,计算如下:
根据公式(1),能够在每一行
6)根据保留下来的内点,分割数据到不同的数据结构里,提出一种新型的基于自适应聚类的模型选取算法,该算法能够自动学习数据相似矩阵并同时执行聚类来估计模型实例,能够有效地处理处于交叉模型实例附近的数据点。
在步骤6)中,所述提出一种新型的基于自适应聚类的模型选取算法,该算法能够自动学习数据相似矩阵并同时执行聚类来估计模型实例,能够有效地处理处于交叉模型实例附近的数据点的具体步骤可为:
采用cosine距离作为度量,决定每个点的最近邻居点,通过在偏好统计矩阵
根据两两点之间的cosine构造相似矩阵,以及定义每个内点
式中,α是正则化参数,在谱分析中,ls=d-(st+s)/2被成为拉普拉斯矩阵,式中度矩阵
在步骤3)中,所述k=6。
在步骤6)中,所述α=20,μ=0.06。
本发明提出一种基于新型的数据表征,处理包含噪点和离群点的多结构数据的模型拟合方法。所提出的数据表征通过残差直方图簇的频次计算分析直方图的特性表征数据,其中残差是一个数据点关于生成的模型假设的残差。所提出的基于直方图分析的数据表征结合了一致统计和偏好分析的优点。接着,为了有效利用嵌入在所提出的数据表征的统计信息,一种简单的熵阈值方法被用来自适用地离群点去除。最后,基于自适应图学习技术(该技术能够处理在模型实例交叉附近处的数据点)提出一种有效的模型选取方法;并且结合结构限制自动地估计模型实例的数目。
相比现有的模型拟合方法,所提出的拟合方法主要有以下三个贡献点:第一,提出一种新型的数据表征方法,基于残差直方图簇的频次计算分析。所提出的数据表征结合了一致统计和偏好分析的优点,提高了模型拟合的精度。第二,提出采用简单的信息熵阈值的算法进行自适用离群点去除,该做法充分利用了嵌入在所提出的数据表征的统计信息,使得该算法能够用很少的时间复杂度去除离群点。第三,提出一种基于自适用图学习的模型选取算法,该算法能够处理位于交叉模型实例附近的数据点,更重要的是该算法能够自动估计模型实例的数目。
本发明主要有以下技术效果:
第一,提出一种新型的数据表征方法,基于残差直方图簇的频次计算分析。所提出的数据表征结合了一致统计和偏好分析的优点,提高了模型拟合的精度。
第二,提出采用简单的信息熵阈值的算法进行自适用离群点去除,该做法充分利用了嵌入在所提出的数据表征的统计信息,使得该算法能够用很少的时间复杂度去除离群点。
第三,提出一种基于自适用图学习的模型选取算法,该算法能够处理位于交叉模型实例附近的数据点,更重要的是该算法能够自动估计模型实例的数目。
附图说明
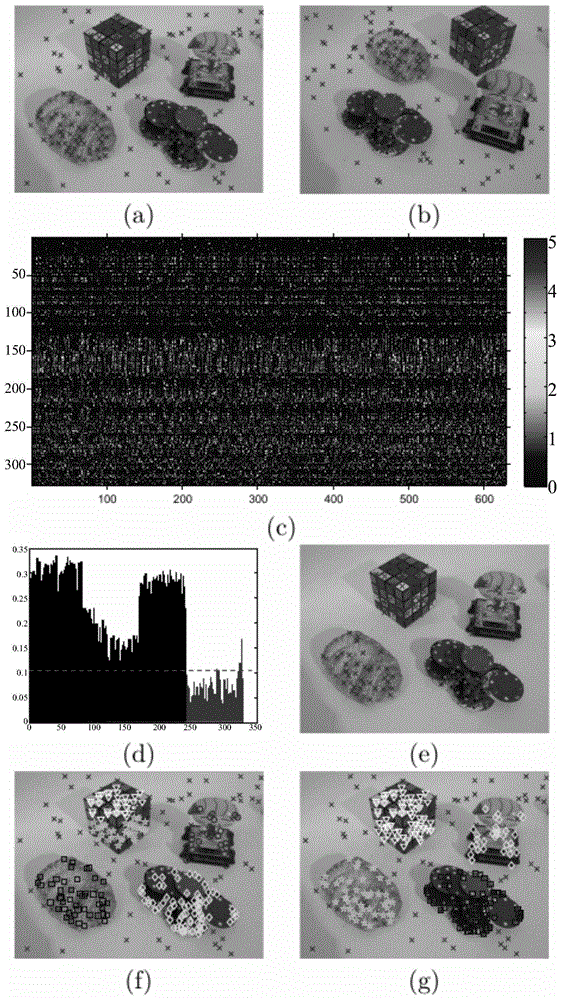
图1为本发明实施例的整体流程图。在图1中,a和b为准备数据,c为偏好统计矩阵,d为每个数据点对应的熵值,e为去掉离群点的结果,f为模型选取,g为优化模型选取。
图2为本发明实施例的数据表征与现在两种流行的数据表征(即j-linkage和t-linkage)方法进行对比。在图2中,a为p-linkage,b为j1-linkage,c为t-linkage。为测试数据表征的性能,将t-linkage的偏好数据表征替换为j-linkage的一致数据表征,构成j1-linakge。同时也将t-linkage的偏好数据表征替换为偏好统计数据表征,构成p-linkage。使p-linkagej1-linakget-linkage在j-linkage数集进行直线(star5和star11)和圆形(circle5)拟合,同时在adelaidermf数据集(h.s.wong,t.-j.chin,j.yu,andd.suter.dynamicandhierarchicalmulti-structuregeometricmodelfitting.inproc.oficcv,pages1044–1051,2011.)上进行单应性矩阵(homograph)和基础矩阵(fundamental)估计。总体上,偏好统计数据表征p-linkage取得最低平均错误率。
图3为本发明在adelaidermf数据集上进行基础矩阵拟合结果。在图3中,a~g分别表示(a)game,(b)cubechips,(c)gamebisicuit,(d)breadtoycar,(e)bisicuitbookbox,(f)breadcubechips,(g)cubebreadtoychips;第一排为真实结果,第二排为本发明的实验结果。
具体实施方式
下面结合附图和实施例对本发明的方法作详细说明。
参见图1,本发明实施例包括以下步骤:
1)准备数据集;输入n个数据点x={xi}i=1,...,n,从输入的数据点中采样m个最小子集生成模型假设h={hj}j=1,...,m,其中一个最小子集是估计一个模型所需要的最小子集,比如生成一条直线需要两个点,估计一个基础矩阵需要7个点或者8个点。
2)针对每个点xi,计算该点到m个模型假设的绝对残差。(可用sampson距离度量)
3)j-linkage的一致统计分析本质是统计所有的残差值中小于固定阈值的残差(阈值是由指定的或者估计的内点噪声尺度决定)。这种做法可看作一种非常粗糙的残差直方图数据表征,它将所有的小于阈值的残差归到一个直方图簇中和将大于阈值的残差归到另一个直方图簇中。提出将所有的残差值中小于固定阈值的残差,归到k个簇的残差直方图中(k是一个相对小的整数>1)进行残差数据表征。即,针对每个数据点xi,对该点关于每个假设的残差值进行排序,并且安排这些残差值到直方图的k(k∈{1,...,k})个簇中。因此,定义一个偏好统计矩阵
4)基于非参的核密度估计技术,获得
5)分析矩阵
其中,r(r<k)是在第i行中所出现的簇值的数目,ait表示第i行中的第t个簇值出现的次数,以及p(ait)是第i行中第t个簇值的概率。p(ait)通过归一化数值ait在所有簇集中的值,计算如下:
根据公式(1),能够在每一行
6)根据保留下来的内点,分割数据到不同的数据结构里。提出一种新型的基于自适应聚类的模型选取算法,该算法能够自动学习数据相似矩阵并同时执行聚类来估计模型实例。能够有效地处理处于交叉模型实例附近的数据点。步骤如下:
采用cosine距离作为度量,来决定每个点的最近邻居点。通过在偏好统计矩阵
根据两两点之间的cosine构造相似矩阵,以及定义每个内点
式中,α是正则化参数。在谱分析中,ls=d-(st+s)/2被成为拉普拉斯矩阵,式中度矩阵
图2为本发明实施例的数据表征与现在两种流行的数据表征(即j-linkage和t-linkage)方法进行对比,为测试数据表征的性能,将t-linkage的偏好数据表征替换为j-linkage的一致数据表征,构成j1-linakge。同时也将t-linkage的偏好数据表征替换为偏好统计数据表征,构成p-linkage。使p-linkagej1-linakget-linkage在j-linkage数集进行直线(star5和star11)和圆形(circle5)拟合,同时在adelaidermf数据集(h.s.wong,t.-j.chin,j.yu,andd.suter.dynamicandhierarchicalmulti-structuregeometricmodelfitting.inproc.oficcv,pages1044–1051,2011.)上进行单应性矩阵(homograph)和基础矩阵(fundamental)估计。总体上,偏好统计数据表征p-linkage取得最低平均错误率。
图3为本发明在adelaidermf数据集上进行基础矩阵拟合结果。在图3中,a~g分别表示(a)game,(b)cubechips,(c)gamebisicuit,(d)breadtoycar,(e)bisicuitbookbox,(f)breadcubechips,(g)cubebreadtoychips;第一排为真实结果,第二排为本发明的实验结果。
本发明与其它几种模型拟合方法在adelaidermf数据集上进行单应性矩阵估计拟合的平均误差错误率参见表1。其中m1~m8对应为(m1:p-linkage;m2:j1-linkage;m3:t-linkage;m4:kf;m5:akswh;m6:ransacov;m7:mshf;m8:ours.)和本发明提出的方法。
表1
在表1中,j-linkage对应为r.toldo等人提出的方法(r.toldoanda.fusiello.robustmultiplestructuresestimationwithj-linkage.inproc.ofeccv,pages537–547,2008.);
ransac对应为m.a.fischler等人提出的方法(m.a.fischlerandr.c.bolles.randomsampleconsensus:aparadigmformodelfittingwithapplicationstoimageanalysisandautomatedcartography.comm.acm,24(6):381–395,1981.);
ransacov对应为l.magri等人提出的方法(l.magrianda.fusiello.multiplemodelfittingasasetcoverageproblem.inproc.ofcvpr,pages3318–3326,2016.);
rha对应为w.zhang等人提出的方法(w.zhangandj.kǒsecká.nonparametricestimationofmultiplestructureswithoutliers.inproc.ofeccv,pages60–74.2006.);
t-linkage对应为l.magri等人提出的方法(l.magrianda.fusiello.t-linkage:acontinuousrelaxationofj-linkageformulti-modelfitting.inproc.ofcvpr,pages3954–3961,2014.);
rpa对应为l.magri等人提出的方法(l.magrianda.fusiello.multiplestructurerecoveryviarobustpreferenceanalysis.ivc,67:1–15,2017.);
kf对应为t.-j.chin等人提出的方法(t.-j.chin,h.wang,andd.suter.robustfittingofmultiplestructures:thestatisticallearningapproach.inproc.oficcv,pages413–420,2009.);
akswh对应为h.wang等人提出的方法(h.wang,t.-j.chin,andd.suter.simultaneouslyfittingandsegmentingmultiple-structuredatawithoutliers.ieeetrans.pami,34(6):1177–1192,2012.)
mshf对应为h.wang等人提出的方法(h.wang,g.xiao,y.yan,andd.suter.searchingforrepresentativemodesonhypergraphsforrobustgeometricmodelfitting.ieeetrans.pami,2018.);
adelaidermf数据集对应为h.s.wong,t.-j.chin,j.yu,andd.suter.dynamicandhierarchicalmulti-structuregeometricmodelfitting.inproc.oficcv,pages1044–1051,2011。
- 还没有人留言评论。精彩留言会获得点赞!