文档与话题相关度的计算方法、装置、设备及介质与流程
本发明涉及数据处理
技术领域:
,特别是涉及一种文档与话题相关度的计算方法及装置。
背景技术:
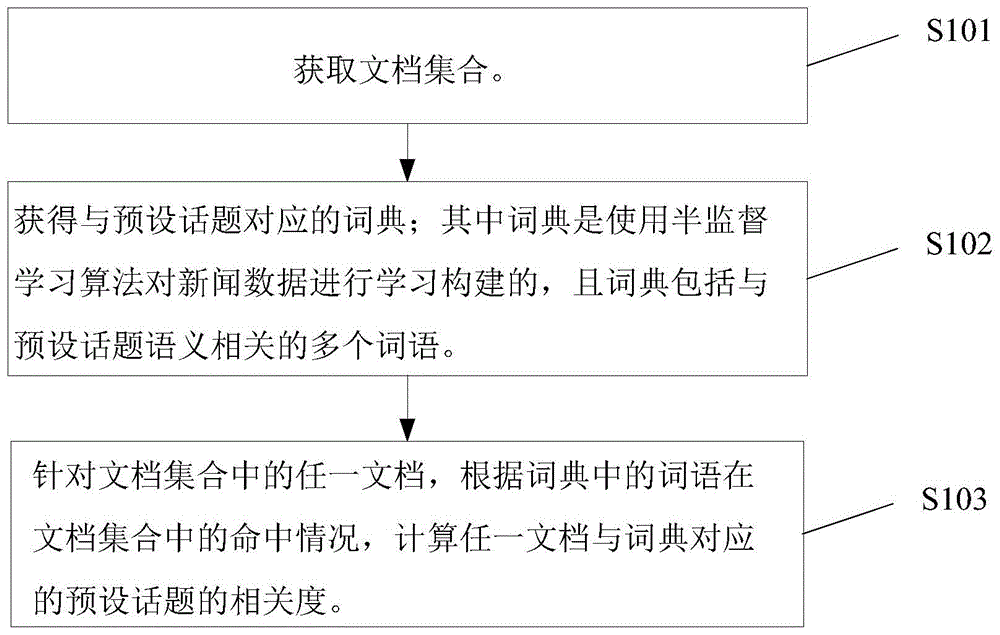
:目前,许多影视作品都来源于文学作品的改编,如《青云志》、《盗墓笔记》等影视都是改编于小说作品。文学作品数量较多种类繁多,将哪些文学作品进行影视改编,需要考量文学作品的改编价值。热门的文学作品拥有大量读者,改编而成的影视作品会吸引很多观众,因此,文学作品的影视改编价值的一种现有考量方法是,对阅读量较大的文学作品通过评论数、点赞数及付费情况对该文学作品进行评估,选取评估分数较高的文学作品作为影视改编题材。但是,经研究发现,一些由文学作品改编的与社会热点相关的影视作品也具有改编价值,如《人民的名义》、《蜗居》、《我不是药神》等作品的观影数量很高。但这类文学作品的阅读量却很低,通过以上方法并不能考量出这类作品的改编价值。技术实现要素:有鉴于此,本发明提供了一种文档与话题相关度的计算方法,用于确定文档与话题之间的相关程度,进而为选取与话题贴切的文档提供依据。为实现上述目的,本发明实施例提供如下技术方案:第一方面,本发明提供了一种文档与话题相关度的计算方法,包括:获得文档集合;获得与预设话题对应的词典;其中所述词典是使用半监督学习算法对话题数据进行学习构建的,且所述词典包括与所述预设话题语义相关的多个词语;针对所述文档集合中的任一文档,根据所述词典中的词语在所述文档集合中的命中情况,计算所述任一文档与所述词典对应的预设话题的相关度。第二方面,本发明提供了一种文档与话题相关度的计算装置,包括:文档获取模块,用于获得文档集合;词典获取模块,用于获得与预设话题对应的词典;其中所述词典是使用半监督学习算法对话题数据进行学习构建的,且所述词典包括与所述预设话题语义相关的多个词语;相关度计算模块,用于针对所述文档集合中的任一文档,根据所述词典中的词语在所述文档集合中的命中情况,计算所述任一文档与所述词典对应的预设话题的相关度。第三方面,本发明提供了一种文档与话题相关度的计算设备,包括:处理器和存储器,所述处理器通过运行存储在所述存储器内的软件程序、调用存储在所述存储器内的数据,至少执行如下步骤:获得文档集合;获得与预设话题对应的词典;其中所述词典是使用半监督学习算法对话题数据进行学习构建的,且所述词典包括与所述预设话题语义相关的多个词语;针对所述文档集合中的任一文档,根据所述词典中的词语在所述文档集合中的命中情况,计算所述任一文档与所述词典对应的预设话题的相关度。第四方面,本发明提供了一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述的账号分享检测方法。基于以上技术方案可以看出,本发明提供了一种文档与话题相关度的计算方法,该方法可以获取文档集合及与预设话题对应的词典,根据预设话题词典中的词语在文档集合中的命中情况,可以计算出文档集合中任一文档与预设话题的相关度。文档与预设话题的相关度可以表示出文档内容与预设话题之间的相关密切程度,可以作为考量文档是否适合改编为热点话题相关影视作品的依据。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。图1示出了本发明提供的一种文档与话题相关度的计算方法流程图;图2示出了本发明提供的一种话题词典的构建过程的流程图;图3示出了本发明提供的一种文档与话题相关度的计算方法中lda主题模型输出显示图;图4示出了本发明提供的一种文档与话题相关度的计算装置结构示意图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。在本发明中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。见图1,本发明提供了一种文档与话题相关度的计算方法,包括步骤s101~s103。s101:获取文档集合。具体地,文档的获取方式可以包括多种,如网上爬取、扫描书籍或其他获取方式。其中,以网上爬取小说这种类型的文档为例,利用爬虫工具,对如起点网、17k等各种网站上的文档进行数据爬虫,爬取到的数据包括文档名称、作者、文档简介、文档前5章内容及评论等。需要说明的是,文档是由文字内容组成的文章,可以是任何形式,文档的类型可以是各种,例如可以是小说等文学作品。将爬取到的数据进行清洗,去除乱码,将数据格式统一化。将处理过后的文档数据可以写入mysql(mystructuredquerylanguage)数据库中。例如对起点网上的小说内容进行爬取,得到对应的表格1:小说爬虫数据表hot_social_novel_crawl:字段名注释字段类型属性备注novel_id小说编号int(11)非空主键自增novel_date小说发布时间varchar(50)非空novel_title小说题目varchar(100)非空novel_author小说作者varchar(255)非空novel_centent小说正文text可空novel_summary小说简介text可空表1从表1中可以看出,将获取的小说进行编号,并将号码赋值给novel_id,其中novel_id是11个字符整型类型。其他参数均以这种方式进行编程,以下表格中的各个参数可以以此为参考。另外,爬虫工具所爬取到的小说评论内容也可以存储在数据表中,如表2所示的小说评论数据表hot_social_comments_crawl:字段名注释字段类型属性备注novel_id小说编号int(11)非空主键comment_date评论时间varchar(50)非空comment_content评论正文varchar(255)非空表2在实际应用中,本步骤s101获取文档集合的一种具体实施方式可以包括:使用爬虫工具从每篇文档中提取能够表示文档的主题的内容数据,进而将从每篇文档中提取出的内容数据组合为文档集合。具体地,互联网中,文档资源丰富,为发掘出具有改变价值的文档,需获取对大量的文档进行计算。其中,采用爬虫工具获取文档,对于大量数据的获取来说,该方式较为方便、快捷。爬虫工具可以从文档中提取文档中的一部分内容数据,这部分内容数据是能够表示文档主题的部分,如文档名称、作者、文档简介、文档前5章内容及评论等。当然,爬取的数据并不局限于这些部分的内容,还可以是其他。为获取大量的文档与话题的相关度,需要对多篇文档进行计算,为此,需要爬取多篇文档,并将多篇文档组合为文档集合,输入至算法模型中筛选。以上方式可以获取到文档集合,除了获取文档集合外,还需要获取话题相关的词典。s102:获得与预设话题对应的词典;其中词典是使用半监督学习算法对话题数据进行学习构建的,且词典包括与预设话题语义相关的多个词语。其中,话题是预先设置的,例如可以包括各种热点话题:民生、经济、文化、教育、健康、体育、科普等。在词典的构建过程中,需要使用预先设置的话题,具体过程见下述说明。话题对应的词典是从话题数据中提炼出来的,例如通过爬虫工具得到话题数据,将话题数据输入至主题提取算法模型中,主题提取算法模型将话题数据进行分词,并将各个分词划分为多个聚类,不同的聚类表示不同的主题,需要说明的是,主题为隐含主题,是算法自动划分的依据。该算法模型不需要人为监督,由主题提取算法模型自动完成。另外,话题数据指的是,关于某个话题公众所表达的观点内容数据,话题数据可以是任何媒体形式如互联网、报刊杂志等等上的内容数据,话题数据的形式也可以包括多种,如新闻数据、带标签的热点话题等等。主题提取算法模型得到的多个主题聚类后,再根据预先设置的话题,在主题聚类中提取与话题语义相关的词语,从而得到该话题对应的词典。如果话题为多个,每个话题都可以按照此种方式得到各自对应的词典。s103:针对文档集合中的任一文档,根据词典中的词语在文档集合中的命中情况,计算任一文档与词典对应的预设话题的相关度。根据以上步骤获取到的文档集合和话题相关的词典,统计话题对应的词典中的词语在文档集合中的命中情况。例如,民生这一话题,通过以上步骤得到民生话题对应的词典,在获取的文档集合中,统计每个文档出现民生词典中各个词语的情况。需要说明的是,命中情况中的“命中”指的是词典中的词语出现在文档集合中的文档中。文档中出现词典中词语的情况,可以反映文档与该词典的语义相关程度,进而可以根据该命中情况,来计算文档与词典对应的话题的相关度。在实际应用中,本步骤s103的一种具体实施方式如下所示。文档与话题相关度的计算,需要先计算出词典在单个文档中出现频率,即词频,再计算词典在文档集合中出现的频率,即逆文档频率,进而根据词频和逆文档频率,计算出该文档与话题的相关度。因此:首先,根据词典中的词语在任一文档中的出现次数,计算词典对于任一文档的词频。具体地,词典中包含多个词语,统计词典中每个词语在某一文档中出现的次数以及统计该文档中的总词数,并根据词典中每个词语在某一文档中出现的次数及该文档中的总词数,来计算该词典在该文档中的词频。在实际应用中,本步骤的一种具体实施方式包括如下步骤:a1~a2。a1:统计所述词典中各个词语在所述任一文档中出现的总次数,以及统计所述任一文档中的总词数。a2:将所述词典中各个词语在所述任一文档中出现的总次数与所述任一文档中的总词数的比值,作为词典对于任一文档的词频。具体地,统计词典中的所有词在该文档中出现的总次数,例如,假设民生话题对应的词典中包含“贫困”、“就业”2个词,若某文档中出现了两次“贫困”,一次“就业”,则民生话题对应的词典中的词在该文档中出现了三次。根据公式计算出话题对应的词典在文章中出现的频率,其中tf为词典在某一文档中的词频。仍以上述示例为例,若该文档的总词数为100个,则该民生词典在该文档中的词频为0.03。其次,根据词典中的词语在文档集合中所有文档的出现次数,计算词典对于文档集合的逆文档频率。统计词典中的词语在文档集合中所有文档的出现次数,以及统计文档集合中文档的总数量,并根据统计词典中的词语在文档集合中所有文档的出现次数,以及文档集合中文档的总数量计算词典对于文档集合的逆文档频率。在实际应用中,本步骤的一种具体实施方式包括如下步骤:b1~b2。b1:统计词典中的词语在文档集合中各个文档中的出现次数,并将出现次数满足预设阈值的文档作为包含词典的文档。其中,针对文档集合中的所有文档,统计词典中的词语在每个文档中的出现次数。如果出现次数较多,则认为文档包含该词典;相反如果出现次数较少,则认为文档不包含该词典。因此本发明预先设置阈值作为出现次数较少或较多的标准。具体地,包含词典的文档,要求出现词典中的词语次数必须大于或等于log2n次;其中n为词典中的总词数,log2n即为预设阈值。b2:计算文档集合中所有文档的总数与包含词典的文档的比值,并将比值确定为词典对于文档集合的逆文档频率。具体地,统计文档集合中所有文档的总数量,进而根据该总数量与包含词典的文档的数量,来计算逆文档频率。具体例如:根据公式计算出词典在所有文档集合中出现的次数。其中,idf为某一词典的在所有文档中出现的频率,即该词典的逆文档频率,该公式中为防止对数内的分母不为零,在统计的包含词典的文档总数上加1。最后,计算词频与逆文档频率的乘积,并将乘积作为任一文档与词典对应的话题的相关度。具体地,根据以上步骤得到的词频和逆文档频率,根据公式tf_idf=tf·idf计算出任一文档与词典对应的话题的相关度tf_idf。例如:假设获取到话题topic1对应的词典d,词典d包含32个词语,获取包含2000篇文档的文档集合,预先统计得到,包含词典d的文档总数为19,从2000篇文档中选取其中一篇,该篇文档有10000字,词典d中的词语在该文档中出现的次数为500次,基于上述统计数据计算该篇文档与话题topic1的对应度,具体如下:tf_idfd=tfd·idfd=0.05×2=0.1计算得到的tf_idfd即为该文档与词典d对应的话题topic1的相关度。文档与话题之间的相关度可以进行存储,例如假设文档为小说,则可以将相关度依照如下表3的字段类型写入数据库中,数据库中存储的数据表为小说主题相关度表hot_social_novel_topic_correlation_degree,该数据表中包含有表3所示的字段。表3由上述计算方式可以看出,某一文档与预设话题之间的相关度,包含两个影响因素,即词频及逆文档频率。需要说明的是,在计算词典的逆文档频率时,可能会出现一种情况,即该某一文档包含词典中词语的数量没有达到阈值要求,也就是说,该某一文档并不包含该词典,但是文档集合中的其他文档可能包含该词典,按照上述提供的逆文档频率的计算方式,仍可以计算出逆文档频率的值。但是,在这种情况下可以直接认为词典与该某一文档并不相关,因此可以直接认定该词典的逆文档频率为0。因此在实际应用中,计算词典对于文档集合的逆文档频率时,可以首先判断词典中的词语在该某一文档(即当前用于计算的文档)的出现次数是否满足预设阈值,如果为否,则直接将词典对于文档集合的逆文档频率确定为0,如果为否,则可以按照上述提供的逆文档频率的计算方式进行计算。由于逆文档频率被确定为0,则按照上述词频与逆文档频率相乘的方式可知,该某一文档与预设话题之间的相关度也为0。由以上技术方案可知,本发明提供了一种文档与话题相关度的计算方法,该方法可以获取文档集合及话题对应的词典,根据话题词典中的词语在文档集合中的命中情况,可以计算出文档集合中任一文档与话题的相关度。文档与话题的相关度可以表示出文档内容与话题之间的相关密切程度,可以作为考量文档是否适合改编为热点话题相关影视作品的依据。见图2,本发明实施例提供了一种话题词典的构建方式,具体包括步骤s201~s203。s201:使用爬虫工具抓取话题数据。具体地,为获取到话题,可以对新闻内容进行搜集,例如对人民网、中国日报、中国青年报等新闻媒体以及自由媒体平台上的新闻内容进行爬虫,得到话题数据。将爬虫到的数据进行清洗,去除乱码,将数据格式统一化。将处理过后的话题数据可以写入mysql数据库中。每个网站设计一张表,如社会话题数据表hot_social_news_crawl如下:字段名注释字段类型属性备注news_tag标识varchar(100)非空主键时间和标题拼接news_date新闻发布时间varchar(50)非空news_topic新闻主题varchar(100)可空新闻网板块news_title新闻标题varchar(255)非空词典的相关度news_content新闻内容text可空news_url当前urlvarchar(255)可空from_url上一级urlvarchar(255)可空相关新闻表4表格中的news_url为当前的网址,from_url为当前网址的上一级网址,用于判定相关新闻之间的联系。除了社会新闻表,还有中国日报hot_social_news_crawl_chinese_daily,人民网hot_social_news_crawl_renmin_net,爬取到的数据以表格所显示的字段类型写入数据库中。爬取到的话题数据作为主题模型的输入。s202:将话题数据输入至主题模型工具中,以从话题数据中提取出主题词语的分类。具体地,主题模型工具是现有的用于提取主题的工具,其可以对输入至自身的数据内容进行分类,每个分类表示一个主题。本步骤将话题数据作为数据内容输入至主题模型工具中,该工具便可以对话题数据进行分类,从而得到关于主题词语的分类。主题模型工具进行主题分类的具体过程可以表示为,对于话题数据,在主题分布中抽取一个主题;在抽取到的主题所对应的单词分布中随机抽取一个单词;重复上述过程直至遍历整篇话题数据中的每个单词。该处理过程是基于对文档的生成过程的分析,即认为文档在生成之前,首先确定该篇文档需要包含的主题,然后围绕主题再选择相关的词语进行遣词造句,从而生成了相应的文档。主题模型工具基于文档生成原理,将给定的话题数据作为一篇文档,按照上述过程推测出该话题数据的主题分布。主题模型工具的一个具体示例为lda(latentdirichletallocation,隐含狄利克雷分布)主题模型,lda也称为三层贝叶斯概率模型,包含词、主题和文档三层结构。lda是一种非监督学习方法,采用词袋模型,每一篇文档视为一个词频向量,词袋模型没有考虑词与词之间的顺序。以下以该主题模型工具为例,对主题模型工具的分类过程进行简要说明。具体地,将话题数据、主题数量k、词语数量n输入至lda主题模型工具中,其中主题数量k、词语数量n为工具中的预设参数,主题数量k表示该工具需要将话题数据划分为多少个主题分类,每个主题分类中包含多个主题词语,词语数量n用于表示每个主题分类中需要选取的主题词语的数量。需要说明的是,lda主题模型工具可以计算出每个主题词语相对于该主题分类的概率值,概率值表示的是主题词语归属于该主题分类的概率值,因此在选取主题词语时可以按照概率值由高到低的方式进行选取。基于上述预设参数的设置,将m篇话题数据输入至lda主题模型中后,lda主题模型可以将话题数据自动划分为k个主题聚类,每个主题聚类分别表示一个独立的主题,主题的具体内容并不能由lda主题模型得到,因此主题聚类可以称为隐含主题。另外,每个主题聚类中包含有n个主题词语。假设,将lda主题模型工具中的主题数量k设置为30,词语数量n设置为10,将某些话题数据输入值如此设置的lda主题模型工具中,得到图3所示的输出结果。如图3所示,lda主题模型工具输出30组词语的聚类,每个聚类表示一个主题,左侧第一列数字为主题的编号,每个主题包含有10个主题词语。需要说明的是,lda主题模型是服从dirichlet(狄利克雷)分布的算法模型,划分的k个主题服从参数为α的dirichlet分布,每个主题中的n个词语服从参数β的dirichlet分布。每个词语都存在一个概率,该概率表示与隐含主题的关联程度,在根据隐含主题分词时,lda主题模型根据概率的大小选取前n个概率大的词作为隐含主题词的分类。并按照概率从大到小的顺序排列。s203:将预设话题与主题词语的分类输入至词向量生成模型中,以得到与话题语义相近的多个词语;其中多个词语组成话题的词典。具体地,可以预先设置一个或多个话题。如果话题为多个,则将每个话题分别与主题词语的分类输入至词向量生成模型中,以分别得到每个话题对应的词典。词向量生成模型用于从主题词语的分类中得到与话题语义相近的多个词语,这些词语便是话题的词典。词向量生成模型的一个示例为work2vec词向量生成模型,以该模型为例对词典的生成过程进行简要说明。例如,将“民生”话题以及主题词语的分类,输入至work2vec词向量生成模型中,work2vec根据输入的民生话题,在主题词语的分类中寻找与民生话题语义相关的词语,即通过算法算出主题词语中,每个词与预设的话题的概率,再按照概率大到小的顺序选取一定数量(该数量可以是预先设置的)的词语,作为话题对应的词典。在实际应用中,在计算得到文档与话题的相关度之后,还可以进行排序。一种情况是,预设的话题为多个,每个话题都可以按照上述方式计算文档与话题之间的相关度,这样对于任一文档来说,可以获得与多个话题之间的相关度,从而将该任一文档与各个话题的相关度进行排序。排序可以是按照话题与该文档相关度的高低顺序排列,与该文档相关度最高的话题为该文档的话题,进而可以将该话题作为该文档改编为影视作品的改编方向。另一种情况是,文档集合中的文档为多个,进而可以将文档集合中各个文档与同一话题的相关度进行排序。排序的标准也可以是按照相关度由高到低的顺序,与该话题相关度最高的文档为该话题最相关的文档。参见图4,本发明实施例提供了一种文档与话题相关度的计算装置的结构。如图4所示,该装置可以具体包括:文档获取模块401、词典获取模块402及相关度计算模块403。文档获取模块401,用于获得文档集合。词典获取模块402,用于获得与预设话题对应的词典;其中所述词典是使用半监督学习算法对话题数据进行学习构建的,且所述词典包括与所述预设话题语义相关的多个词语。相关度计算模块403,用于针对所述文档集合中的任一文档,根据所述词典中的词语在所述文档集合中的命中情况,计算所述任一文档与所述词典对应的预设话题的相关度。在一种实施方式中,相关度计算模型403可以具体包括:词频计算子模块、逆文档频率计算子模块及相关度计算子模块。词频计算子模块,用于根据所述词典中的所有词语在所述任一文档中的出现次数,计算所述词典的词频;逆文档频率计算子模块,用于根据所述词典中的所有词语在所述文档集合中所有文档的出现次数,计算所述词典的逆文档频率;相关度计算子模块,用于计算所述词频与所述逆文档频率的乘积,并将所述乘积作为所述任一文档与所述词典对应的预设话题的相关度。在一种实施方式中,词频计算子模块可以具体包括:单文档词典统计单元、文档词语统计单元及词频计算单元。单文档词典统计单元,用于统计所述词典中各个词语在所述任一文档中出现的总次数;文档词语统计单元,用于统计所述任一文档中的总词数;词频计算单元,用于将所述词典中各个词语在所述任一文档中出现的总次数与所述任一文档中的总词数的比值,作为所述词典的词频。一种实施方式中,逆文档频率计算子模块可以具体包括:多文档词典统计单元及逆文档频率计算单元。多文档词典统计单元,用于统计所述词典中的所有词语在所述文档集合中各个文档中的出现次数,并将出现次数满足预设阈值的文档作为目标文档;逆文档频率计算单元,用于计算所述文档集合中所有文档的总数与目标文档的数量的比值,并将所述比值确定为所述词典的逆文档频率。一种实施方式中,逆文档频率计算子模块可以具体包括:逆文档频率计算单元。预设阈值单元,用于若所述词典中的所有词语在所述任一文档的出现次数不满足预设阈值,则将所述词典的逆文档频率确定为0。一种实施方式中,文档与话题相关度的计算装置还可以包括词典构建模块,用于构建与预设话题对应的词典。其中,词典构建模块可以具体包括:新闻抓取子模块、分类词语子模块、词语生成子模块以及词典生成子模块。新闻抓取子模块,用于使用爬虫工具抓取话题数据;分类词语子模块,用于将所述话题数据输入至主题模型工具中,以从所述话题数据中提取出主题词语的分类;词语生成子模块,用于将预设话题与所述主题词语的分类输入至词向量生成模型中,以得到与所述预设话题语义相近的多个词语;词典生成子模块,用于根据与所述预设话题语义相近的多个词语组成所述预设话题的词典。一种实施方式中,所述文档获取模块可以具体包括:文档抓取子模块及文档组合子模块。文档抓取子模块,用于使用爬虫工具从网络中爬取多篇文档,其中爬取的是每篇所述文档中能够表示所述文档的主题的内容数据;文档组合子模块,用于将所述多篇文档组合为文档集合。一种实施方式中,文档与话题相关度的计算装置还可以包括:排序模块。排序模块,用于若预设话题为多个,则将所述任一文档与各个所述预设话题的相关度进行排序;或,将所述文档集合中各个所述文档与同一所述预设话题的相关度进行排序。由以上技术方案可知,本发明提供了一种文档与话题相关度的计算装置,该装置可以获取文档集合及与预设话题对应的词典,根据话题词典中的词语在文档集合中的命中情况,可以计算出文档集合中任一文档与预设话题的相关度。文档与预设话题的相关度可以表示出文档内容与预设话题之间的相关密切程度,可以作为考量文档是否适合改编为热点话题相关影视作品的依据。另外,本申请还提供了一种文档与话题相关度的计算设备,具体包括:处理器和存储器,所述处理器通过运行存储在所述存储器内的软件程序、调用存储在所述存储器内的数据,至少执行如下步骤:获得文档集合;获得与预设话题对应的词典;其中所述词典是使用半监督学习算法对话题数据进行学习构建的,且所述词典包括与所述预设话题语义相关的多个词语;针对所述文档集合中的任一文档,根据所述词典中的词语在所述文档集合中的命中情况,计算所述任一文档与所述词典对应的预设话题的相关度。另外,本申请还提供了一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述任意实施例提供的文档与话题相关度的计算方法。本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统或系统实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的系统及系统实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1