由单张图像联合估计场景深度与语义的方法与流程
本发明属于计算机视觉和计算机图形学领域,特别涉及使用深度学习的方法去估计场景的深度信息和语义信息。
背景技术:
在计算机视觉领域,单目深度估计一直是长期存在并且讨论议论较多的一个主题。深度信息在三维重建、虚拟现实、导航等应用上都有比较大的帮助。现如今,虽然有不少硬件能够直接获取到深度图,但它们都有各自的缺陷。比如3dlidar设备非常昂贵;基于结构光的深度摄像头像kinect等在室外无法使用,测量距离有限并且深度图噪声比较大;双目摄像头需要利用立体匹配算法,计算量比较大,而且对于纹理不丰富的场景效果不好。单目摄像头相对来说成本最低,设备也最普及,所以从单目摄像头设计算法去估计深度是一个比较好的选择。之前的方法主要使用手动设计的特征和图模型去估计深度,但是随着深度学习的兴起,更多的注意力放在了使用深度学习的方法去估计深度。eigen等人(d.eigen,c.puhrsch,andr.fergus.depthmappredictionfromasingleamulti-scaledeepnetwork.innips,pages2366-2374,2014.)提出了一个多尺度的卷积神经网络用于深度估计,并且取得了不错的结果。
语义分割实际上是图像分类的一种扩展。语义分割所要做的是对于给定图像的每一个像素做分类。在图像领域,语义指的是图像的内容,即对图片意思的理解。语义分割在地理信息系统、无人车驾驶、医疗影像分析还有机器人等领域中有着比较广泛的应用。如今,做语义分割最先进的方法都是基于深度学习的。long(j.long,e.shelhamer,andt.darrell.fullyconvolutionalnetworksforsemanticsegmentation.incvpr,pages3431–3440,2015.)等人提出了使用全卷积网络去做语义分割,之后的大部分工作都是基于全卷积网络基础上的。随着深度相机的普及和rgbd数据集的出现,一些方法开始尝试将深度信息融合到网络中去估计语义信息,不再局限于只使用彩色图像去做语义分割。
技术实现要素:
为了能够获得彩色图像所对应的深度图和语义图,本发明是设计一个迭代式的网络去联合估计深度信息和语义信息,利用二者之间的互补特性改善彼此的预测结果。为此,本发明提供了一个合成数据集,专门用来室内的三维重建和场景理解。本发明并不局限于学习深度信息与语义信息,相关的两种任务都可以。具体来说,本发明采取的技术方案是,由单张图像联合估计场景深度与语义的方法,步骤如下:
1)利用任何带有单目摄像头的设备进行拍照,获取得到的彩色图像作为网络的输入;
2)迭代网络:将一张彩色图像输入多任务的深度卷积网络构成的对于深度估计和语义分割迭代联合优化的框架,估计出其深度和语义信息,深度信息用来重建三维场景,语义信息能够实现场景的理解。
迭代网络是一个多任务的深度卷积网络,包含两个部分,深度估计子网络和语义分割子网络,具体包括以下部分:
1)深度估计子网络:包括彩色图支路和语义支路,彩色图支路是由一条主干的编解码网络和一条使结果精细化的网络组成,精细化的网络由几个连续条件随机场模块组成,用来提取主干网络中不同尺度的信息,也就是解码出来的不同尺度的信息;语义分割子网络的输出处理结果到语义支路,语义支路是由编解码网络组成,最后,两路信息通过组合用条件随机场模块组合起来,得到最后的深度估计结果;
2)语义估计子网络:包括彩色图支路和深度支路,先对来自深度估计子网络输出的深度图进行质心编码,然后输入到深度支路,彩色图的支路由空洞卷积和多孔空间金字塔池化组成,深度支路由全卷积构成,最终通过长短期记忆网络进行融合;
3)联合优化:对于每一个子网络单独训练,每一个子网络的每一条支路先分别训练,然后组合起来,微调,取深度子网络中彩色图的支路在融合前的特征作为初始化的深度,同理,也取出语义作为初始化,然后将获得的深度和彩色图送到网络中进行迭代。
联合优化具体步骤如下:对于深度估计网络的训练,首先,先单独训练彩色图输入的那一条支路,等到在验证集上的结果不再下降之后,再加入语义分割图输入的那一条支路,联合训练,由于输入彩色图的那一条支路已经训练过了,所以在彩色图输入支路上进行微调即可,主要训练输入语义的那一条支路,到在验证集上的结果基本不再下降之后,训练停止;对于训练语义分割的网络,首先对输入彩色图像的支路进行训练,饱和之后,加入输入深度图的那一条支路,联合训练;要使迭代网络运行起来,需要一个初始化的深度或者语义,具体取深度子网络中彩色图的支路在融合前的特征作为初始化的深度,同理,也取出语义作为初始化;迭代的具体过程是,获得了一个初始化的语义,要想进行迭代就通过输入彩色图和这个获得的语义到深度估计子网络中,学习得到深度图,再将这个深度图和彩色图输入到语义估计子网络中,学习语义分割图,如此进行迭代。
与已有技术相比,本发明的技术特点与效果:
首先,本发明的发明是在单目彩色图像的基础上,相比传统的单目深度估计和语义估计,本发明方法主要具有以下特点:
1、基于单目的彩色图像,利用深度卷积网络学习得到深度图和语义分割图。
2、设计了一个迭代联合优化的框架,输入一张彩色图像到网络中进行迭代,最终得到深度图以及语义分割图。这种框架不仅仅局限于深度估计和语义分割,也可以用在其它相关联的任务上。
3、提出了一个用来室内场景三维重建和理解的合成数据集,可以用来训练迭代网络。
本发明基于彩色图像,实现上简单易行,且有让人较为满意的效果。所提出的方法具有很好的扩展性。
附图说明
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
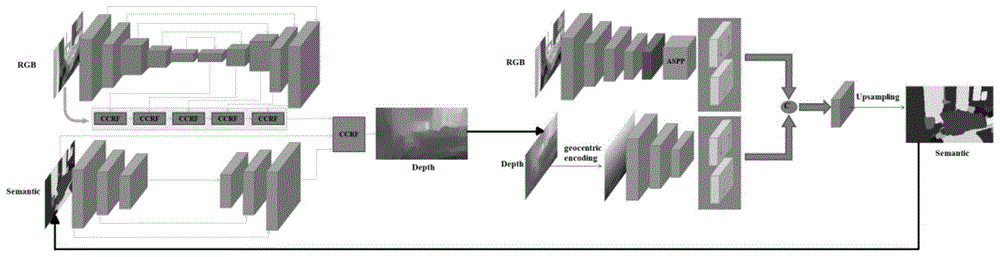
图1为本发明实施例基于迭代网络进行深度估计和语义分割的示意图。
图2为本发明实施例是基于nyuv2数据集(p.k.nathansilberman,derekhoiemandr.fergus.indoorsegmentationandsupportinferencefromrgbdimages.ineccv,2012.)上获得的深度估计结果与其它方法的对比示意图。从左至右依次是输入的彩色图,深度图的真值,eigen等人(d.eigen,c.puhrsch,andr.fergus.depthmappredictionfromasingleimageusingamulti-scaledeepnetwork.innips,pages2366–2374,2014.)估计出来的结果,laina等人(i.laina,c.rupprecht,v.belagiannis,f.tombari,andn.navab.deeperdepthpredictionwithfullyconvolutionalresidualnetworks.)估计得到的结果,xu等人(d.xu,e.ricci,w.ouyang,x.wang,andn.sebe.multi-scalecontinuouscrfsassequentialdeepnetworksformonoculardepthestimation.incvpr,2017.)估计得到的结果以及本发明所估计得到的结果。
图3为本发明实施例是基于nyuv2数据集上获得的语义估计结果与其它方法的对比示意图。从左至右依次是输入的彩色图,语义分割图的真值,long等人(j.long,e.shelhamer,andt.darrell.fullyconvolutionalnetworksforsemanticsegmentation.incvpr,pages3431–3440,2015.)估计得到的结果,chen等人(l.-c.chen,g.papandreou,i.kokkinos,k.murphy,anda.l.yuille.deeplab:semanticimagesegmentationwithdeepconvolutionalnets,atrousconvolution,andfullyconnectedcrfs.ieeetrans.pami,40(4):834–848,2018.)估计得到的结果,li等人(z.li,y.gan,x.liang,y.yu,h.cheng,andl.lin.lstm-cf:unifyingcontextmodelingandfusionwithlstmsforrgb-dscenelabeling.ineccv,pages541–557,2016.)估计得到的结果,zhao等人(h.zhao,y.zhang,s.liu,j.shi,c.c.loy,d.lin,andj.jia.psanet:point-wisespatialattentionnetworkforsceneparsing.ineccv,2018.)估计得到的结果以及本发明估计得到的结果。
图4为所提出的数据集中的一些例子,从上到下依次是彩色图,深度图和语义分割图。
具体实施方式
本发明旨在实现只基于彩色图片,实现深度估计和语义分割估计的目的。本发明将以任何一台能够采集彩色图片的设备作为起点,利用迭代网络学习得到深度图和语义图。
本发明提出了一种通过迭代网络去联合估计深度与语义信息的方法,结合附图及实施例详细说明如下:
本发明利用某种设备所获取的彩色图像,输入到深度估计和语义分割迭代的网络中联合优化,得到该图所对应的深度图和语义分割图。如图1所示,为本发明实施例所提出的迭代网络设计,迭代网络是一个多任务的深度卷积网络,它主要包含两个部分,深度估计子网络和语义分割子网络,具体实施方案如下:
1)深度估计子网络的设计。在网络结构设计上,一共使用了两条支路,第一条支路是输入彩色图像,第二条支路是输入的语义分割图像,两条支路各自通过一个编码-解码网络,在最后,联结起来去预测深度信息。彩色图输入的支路是主支路,它是最后的深度估计主要的贡献者,语义分割的支路主要是对最后结果进行改善,主要表现在物体的边缘上,它能够输出较为精准的边缘。本发明使用了连续条件随机场去组合多个尺度的特征,彩色图的支路是由一条主干的网络(编解码网络)和一条使结果精细化的网络组成,精细化的网络主要有几个连续条件随机场模块组成,用来提取主干网络中不同尺度的信息;语义的支路是由编解码网络组成。最后,两路信息通过条件随机场模块组合起来,得到最后的深度估计结果。本方案所采用的编解码网络里用的都是卷积模块
2)语义估计子网络的设计。在网络结构设计上,一共使用了两条支路,第一条支路是输入彩色图像,第二条支路是输入深度估计图(由深度估计子网络的输出得到),两条支路各自通过一个卷积网络,在最后把两路提取出来的特征进行组合,学习出最后的语义分割结果。彩色图输入的是主要支路,它为最后的语义结果提供了较多的信息,输入深度估计的那一条支路,是对语义结果进行修缮。本发明使用了长短期记忆信息融合的模块去组合不同的特征,它能够融合不同来源的信息,比如说光度信息和深度信息。长短期记忆网络(longshort-termmemorynetwork),简称lstm,它是在循环神经网络(rnn)的基础上提出来的,能够解决训练rnn过程中易出现的梯度消失的问题,用它来建模序列之间的相关性,在图像上用来表达相邻像素之间的相关性。本发明也把多孔空间金字塔池化模块加入到网络中,用它作为多尺度特征的提取器。在深度图送入到网络之前,先对深度图进行质心编码,然后喂给深度支路。彩色图的支路由空洞卷积和多孔空间金字塔池化组成,深度支路由全卷积构成,最终通过长短期记忆网络进行融合。
3)联合优化。要训练的网络有两个,分别是深度估计的网络和语义估计的网络。二者的训练分开进行,以深度估计网络的训练为例,首先,先单独训练彩色图输入的那一条支路,等到在验证集上的结果基本不再下降之后,再加入语义分割图输入的那一条支路,联合训练,由于输入彩色图的那一条支路已经训练过了,所以在这一条支路上进行微调即可,主要训练输入语义的那一条支路,等到在验证集上的结果基本不再下降之后,训练停止。同理,训练语义分割的网络,也是如此进行分步训练,先对输入彩色图像的支路进行训练,饱和之后,加入输入深度图的那一条支路,联合训练。这样的训练方法虽然繁琐了一些,但是每一条支路训练起来相对容易,能够达到一个比较好的训练效果。要使本发明的迭代网络运行起来,需要一个初始化的深度或者语义,本发明取深度子网络中彩色图的支路在融合前的特征作为初始化的深度,同理,也可以取出语义作为初始化。比如获得了一个初始化的语义,要想进行迭代就可以通过输入彩色图和这个获得的语义到深度估计网络中,学习得到深度图,再将这个深度图和彩色图输入到语义估计网络中,学习语义分割图,如此进行迭代。
4)训练。对于每一个子网络而言,都是单独训练的。以深度估计子网络为例,对于两路分支分别训练,然后连在一起进行微调。语义分割子网络也用同样的方式进行训练。该网络的实现是基于caffe深度学习框架,运行在英伟达gtx1080ti显卡上。对于深度估计子网络初试学习率设为10-11,每30轮学习率下降0.9,训练批次大小设为16。动量和权值衰减权重分别设为0.9和0.0005。对于语义分割子网络,遵循同样的训练规则,不过初始学习率设为10-4。批次大小、动量和权值衰减分别设为8,0.9和0.005。学习率每20轮下降0.9。当每个分支的预训练结束之后,然后对整个网络进行微调。
5)测试。注意到迭代网络是需要一个初始化的深度或者语义的,这可以通过彩色图支路提取的特征获得。具体而言,如果目的是获得一个初始的语义,那么可以取语义分割估计子网络中,彩色图最后一层特征最为初始化的语义,要想进行迭代就可以通过输入彩色图和这个获得的语义到深度估计网络中,学习得到深度图,再将这个深度图和彩色图输入到语义估计网络中,学习语义分割图,如此进行迭代。
- 还没有人留言评论。精彩留言会获得点赞!