一种加热炉总括热吸收率的辨识方法及装置与流程
本发明涉及钢铁企业的加热炉
技术领域:
,尤其涉及一种加热炉总括热吸收率的辨识方法及装置。
背景技术:
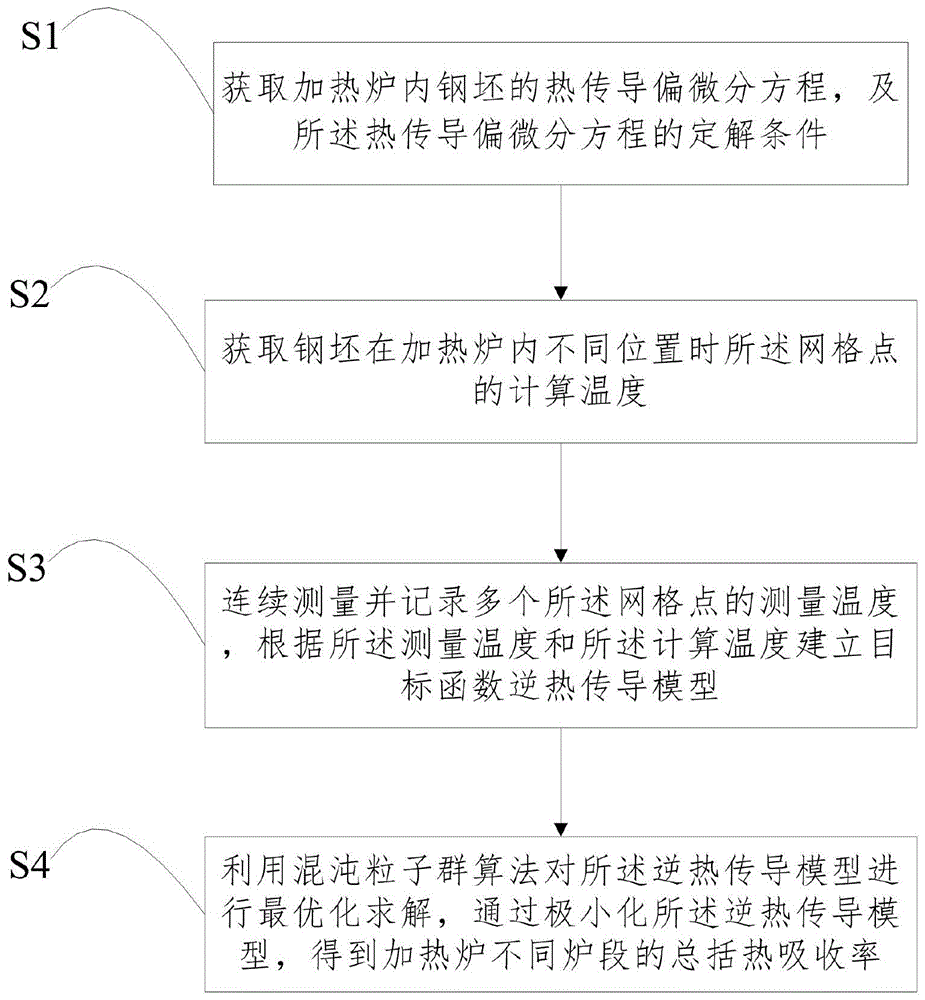
:在钢铁企业中,加热炉能耗占整个钢坯生产总能耗能达到25%,是钢铁企业中能耗较大的设备。从炉头的入料口至炉尾的出料口沿着炉长方向可分为热回收段、预热段、加热一段、加热二段和均热段,用来将来自保温坑的钢坯或者是直接来自于连铸机的钢坯等进行再加热或热处理,使得钢坯在出炉时刻的温度分布能够满足轧机进行轧制的生产设备。加热炉的在线炉温优化控制既要求传热过程的计算过程能够达到一定的精度要求和计算速度,所以总括热吸收率法因其算法简洁、计算量小,在加热炉在线控制数学模型中已得到广泛应用。总括热吸收率系数是加热炉在线控制数学模型中的关键参数,其计算得准确与否将直接影响加热炉在线炉温优化控制问题的求解精度。对于逆热传导模型的求解,在“黑匣子实验”测量的钢坯温度的基础上,研究方法大致可以被分成两类:基于梯度的优化算法与基于非梯度的随机智能优化算法。基于梯度的优化方法能够有效地解决传热学反演问题,但是,它们需要以初始猜测值为起点来计算目标函数的偏导数,如果给定的初始猜测值不恰当,容易陷入局部最优解而停止。非梯度的智能优化算法通常是全局搜索的算法,适应性较好,但是,此类方法往往计算成本较大,使其应用受到了一定的限制。解决总括热吸收率的辨识问题需要保证快速性和准确性,然而这两者在现有技术里存在矛盾。技术实现要素:(一)要解决的技术问题本发明提供了一种加热炉总括热吸收率的辨识方法及装置,旨在解决总括热吸收率的辨识的快速性和准确性。(二)技术方案为了解决上述问题,本发明提供了一种加热炉总括热吸收率的辨识方法,如图1所示,包括以下步骤:s1:获取加热炉内钢坯的热传导偏微分方程,及所述热传导偏微分方程的定解条件,所述定解条件包括边界条件和初始条件;s2:将钢坯划分为多个离散的网格点,并对所述热传导偏微分方程和所述边界条件分别进行离散化处理,获取钢坯在加热炉内不同位置时所述网格点的计算温度;s3:将钢坯从进加热炉到出加热炉的过程中,连续测量并记录多个所述网格点的测量温度,根据所述测量温度和所述计算温度建立目标函数逆热传导模型:其中,k是指钢坯上的测量点,且所述测量点k所对应的所述网格点的在钢坯上的坐标为(x,y);k∈(1,2,3...m)且m是指钢坯从加热炉炉口到加热炉炉尾的路径上选取了m个采集点;tc(x,y,k;p)是钢坯位于所述采集点时,测量点k对应的网格点处的所述计算温度;tm(x,y,k)是钢坯位于所述采集点时,所述测量点k的测量温度;p为辨识的总括热吸收率;s4:利用混沌粒子群算法对所述逆热传导模型进行最优化求解,通过极小化所述逆热传导模型,得到加热炉不同炉段的总括热吸收率。优选地,在所述步骤s1中;所述热传导偏微分方程为:所述边界条件为:所述初始条件为:t(x,y,0)=t0其中,x∈(0,lx),y∈(0,ly),lx,ly分别为钢坯的宽度和厚度;分别为钢坯切面的宽度和厚度方向的微分单元;为单位时间变化量;t是温度分布,λ是导热系数;ρ是钢坯密度;c是等比热;q1、q2分别钢坯上、下表面的热流密度;q3、q4分别为钢坯左、右表面的热流密度;u1(t)、u2(t)分别为钢坯在加热炉内运行过程中的上、下表面的炉气温度;u3(t)为钢坯在加热炉内运行过程中的左、右表面的炉气温度;p1(t)、p2(t)分别为钢坯上、下表面的总括热吸收率;p3(t)为钢坯左、右表面的总括热吸收率(左、右表面的总括热吸收率相等);t1(x,y,t)、t2(x,y,t)分别为钢坯上、下表面的计算温度;t3(x,y,t)、t4(x,y,t)分别为钢坯左、右表面的计算温度;σ为斯蒂芬—波尔茨曼常数;t0表示入炉时刻t=0的钢坯初始温度分布值。优选地,所述步骤s2中,对所述热传导偏微分方程离散化得到离散方程为:其中,将钢坯划分为多个离散的网格点,具体为将钢坯连续空间域和时间域离散为具有有限个所述网格点,所述网格点在钢坯上的空间位置坐标表示为(i,j),i∈[1,ni],j∈[1,nj」,ni表示钢坯宽度方向上离散后的单元格数量,nj表示钢坯厚度方向上离散后的单元格数量,t∈[0,nt],nt表示钢坯在炉内加热的总时间离散后得到的时刻数,所以离散以后的网格点对应的温度值为表示在第t时刻(i,j)对应的所述网格点温度;δt为相邻的两个时刻的时间差,δx为钢坯在宽度方向上,两个相邻的所述网格点的距离;δy为钢坯在厚度方向上,两个相邻的所述网格点的距离;对所述边界条件离散化处理得到所述离散边界方程:其中,分别为计算钢坯上、下表面的温度时所产生的虚拟点,分别为计算钢坯左、右表面的温度时所产生的虚拟点。优选地,所述步骤s4具体为:s41:混沌初始化,生成一个有f个粒子的种群,且每个粒子中都包括有n个元素;s42:计算每个粒子的适应值fitness(i),其中fitness(i)表示第i个粒子的适应值,求第i个粒子的适应值具体为:首先,将第i个粒子中的前1/3的元素设置为所述p1(t)的初始解,第i个粒子中的中间的1/3的元素设置为所述p2(t)的初始解,第i个粒子中的最后的1/3的元素设置为所述p3(t)的初始解;然后,将所述p1(t)的初始解中的元素依次代入所述离散边界方程中的p1(t);将所述p2(t)的初始解中的元素依次代入所述离散边界方程中的p2(t);将所述p3(t)的初始解中的元素依次代入所述离散边界方程的p3(t);进而通过所述离散边界方程和所述离散方程得到钢坯上、下、左、右表面在加热炉内不同位置的计算温度;再然后,根据所述离散方程计算钢坯处于所述采集点时,测量点k对应的网格点的计算温度;再然后,选择钢坯处于所述采集点时,测量点k对应的网格点处的计算温度,所述测量点k对应的网格点的测量温度;最后,根据所述逆热传导模型,求得s(p),并将所述s(p)作为第i个粒子的所述适应值;s43:判断当前粒子是否陷入局部最优,如果是,则执行步骤s44,如果为否,则执行s45;s44:加入混沌扰动,其中,表示第i个粒子经过第b+1次迭代后的粒子位置,表示第i个粒子经过第b+1次迭代的粒子速度,且δz为一维扰动量,δz=(δz1,δz2,δz3...,δzn),其中,表示粒子中的第d个元素;s45:按照粒子更新公式更新所述粒子,所述粒子更新公式为:其中,w为惯性因子,c1,c2为加速因子且是常数;r1,r2为[0,1]范围内的随机数;第i个粒子在前b步更新后产生的b+1个粒子中所述适应值最小的粒子作为个体最优解,表示所述个体最优解的第d个元素;所有所述粒子在前b步更新产生的粒子中所述适应值最小的粒子作为群体最优解,表示所述群体最优解的第d个元素;s46:当满足结束条件后,停止迭代,并将所述群体最优解对应的粒子中的元素对应为所述总括热吸收率。优选地,所述步骤s46还包括:当不满足所述结束条件时,返回步骤s42。优选地,所述步骤s41具体为:首先,随机生成一个n维向量y1=(y11,y12,y13...y1n),然后根据迭代公式迭代n次,得到n个向量:y1,y2,y3...,yn组成一个向量y=(y1,y2,y3...,yn);所述迭代公式为:y(l+1),m=μyl,m(1-yl,m),l,m∈[1,n],μ为控制参数,且μ∈(2,4];然后,根据所述y生成初始解x1,x2,x3...,xn,xl向量中每一个元素对应的是相应位置的总括热吸收率系数,其中:xl,m=am+(bm-am)yl,mam表示向量y第m列元素的下界,bm表示向量y第m列元素的上界,yl,m代表y中(l,m)位置元素;xl,m代表初始解xl中第m个元素;最后,求得所有所述初始解的所述适应值,并选出所述适应值最小的f个初始解作为一个具有f个粒子的种群,一个所述初始解对应一个所述粒子。优选地,所述步骤s43中:所述判断当前粒子是否陷入局部最优具体为:在对第i个粒子进行第b次迭代后,已经连续出现的nc次迭代,若满足:其中,为所述粒子中第i个粒子在经过e次迭代后的所述适应值,为所述粒子中第i个粒子在经过第b次迭代后的所述个体最优解,e∈[b-nc,b-nc+1,b-nc+2...b],δ,nc为预先设定的值;则,当前粒子已经陷入局部最优;否则,当前粒子未陷入局部最优。优选地,本发明还提供了一种加热炉总括热吸收率的辨识装置,包括:储存介质、cpu和gpu;所述cpu用于执行所述存储介质上存储的计算机程序,实时实现如权利要求1-7中任意一项所述的辨识方法的步骤;所述gpu在接收到所述cpu的指令后,对钢坯上的所有网格点的温度采用并行计算的方式得到网格点的计算温度;所述gpu上划分为很多线程块,一个所述线程块里面包含很多线程,一个所述粒子对应一个所述线程块,钢坯划分为ni*nj个网格点,所述线程与钢坯网格点按位置一一对应,所有网格点的温度同时计算。优选地,所述线程块内包括一个共享内存,所述线程块内部的所有所述线程都与所述共享内存进行数据通讯;所述gpu包括全局内存,所述共享内存与所述全局内存进行数据通讯。(三)有益效果为了达到上述效果,利用混沌粒子群算法在经典pso算法优势的基础上,除了向比自己好的粒子和全局最好粒子学习之外,克服随机生成的初始解会对算法整体的收敛速度和精度产生影响,可以在迭代过程跳出局部最优,具有收敛于全局最优点的性质。利用gpu对划分的温度场空间网格并行计算,大大提高了计算效率。附图说明图1为本发明一种加热炉总括热吸收率的辨识方法的流程图;图2为本发明中混沌粒子群算法的流程图。具体实施方式为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。需要说明,本发明实施例中所有方向性指示(诸如上、下、左、右、前、后……)仅用于解释在某一特定姿态(如附图所示)下各部件之间的相对位置关系、运动情况等,如果该特定姿态发生改变时,则该方向性指示也相应地随之改变。另外,在本发明中如涉及“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。在本发明中,除非另有明确的规定和限定,术语“连接”、“固定”等应做广义理解,例如,“固定”可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系,除非另有明确的限定。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。本发明中的加热炉总括热吸收率的辨识方法是基于如下假设:1、不考虑钢坯氧化对传热的影响。2、对于长方形的钢坯,可以认为其沿着长度方向上的温差比较小,因此认为钢坯在加热炉内的导热过程是沿着钢坯厚度和宽度方向的二维空间进行传导的;3、钢坯的上下表面在加热炉内一直是均匀加热的过程;4、钢坯在加热炉内保持匀速前进;5、假设钢坯在加热过程中无体积变化;6、忽略炉气横向温度差。7、钢坯宽度方向参数变量对称相等。对于炉膛温度分布分布模型的处理方法,采用线性插值模型,为确定两个热电偶测量点之间的某处炉温,会通过线性插值的方法来获得炉温的具体数值。加热炉炉温的分布曲线是沿炉长方向的分段线性函数,即加热炉炉温在存在热电偶的区域,该处的炉温即为热电偶所测炉温;而在不存在热电偶的区域,加热炉的炉温用公式一表示:式中:s表示钢坯在加热炉沿着炉长方向的位置;li:表示存在热电偶的位置;ui表示加热炉内在li处热电偶的位置的温度;tf(s)在加热炉的s处的炉温;本发明提供了一种加热炉总括热吸收率的辨识方法,包括以下步骤:s1:获取加热炉内钢坯的热传导偏微分方程,及热传导偏微分方程的定解条件,定解条件包括边界条件和初始条件。其中热传导偏微分方程为:边界条件为:初始条件为:t(x,y,0)=t0其中,x∈(0,lx),y∈(0,ly),lx,ly分别为为钢坯的宽度和厚度,分别为钢坯切面的宽度和厚度方向的微分单元,为单位时间变化量,t是温度分布,λ是导热系数,ρ是铸坯密度,c是等比热;q1、q2分别钢坯上、下表面的热流密度,q3、q4分别为钢坯左、右表面的热流密度,u1(t)、u2(t)分别为钢坯在加热炉内运行过程中的上、下表面的炉气温度;u3(t)为钢坯在加热炉内运行过程中的左、右表面的炉气温度;,p1(t),p2(t)分别为钢坯上、下表面的总括热吸收率,p3(t)为钢坯左、右表面的总括热吸收率(左、右表面的总括热吸收率相等),t1(x,y,t),t2(x,y,t)分别为钢坯上、下表面的计算温度,t3(x,y,t)、t4(x,y,t)分别为钢坯左、右表面的计算温度,σ为斯蒂芬—波尔茨曼常数;t0表示入炉时刻t=0的钢坯初始温度分布值。s2:将钢坯划分为多个离散的网格点,并对热传导偏微分方程和边界条件分别进行离散化处理,获取钢坯在加热炉内不同位置时网格点的计算温度;具体为:利用差分法将所述传导偏微分方程离散化得到离散方程,在将所述边界条件离散化得到离散边界方程,利用所述离散边界方程和所述离散方程得到表面温度方程,所述表面温度方程是钢坯表面温度关于总括热吸收率的表达式,再利用所述钢坯表面温度和所述离散方程以及初始条件得到钢坯在加热炉内不同位置时所述网格点的计算温度。对热传导偏微分方程离散化得到离散方程为:其中,将钢坯划分为多个离散的网格点具体为将钢坯连续空间域和时间域离散为具有有限个网格点,网格点在钢坯上的空间位置坐标表示为(i,j),i∈[1,ni],j∈[1,nj」,ni表示钢坯宽度方向上离散后的单元格数量,nj表示钢坯厚度方向上离散后的单元格数量,t∈[0,nt],nt表示钢坯在炉内加热的总时间离散后得到的时刻数,所以离散以后的网格点对应的温度值为表示在第t时刻(i,j)对应的网格点温度;δt为相邻的两个时刻的时间差,δx为钢坯在宽度方向上,两个相邻的网格点的距离;δy为钢坯在厚度方向上,两个相邻的网格点的距离;对离散方程进行变形得到同一网格点在相邻时刻的关系,即:通过离散方程的变形式,可以知道钢坯内部的一个网格点在t+1时刻的温度,只与该网格点在其厚度和宽度方向上相邻的四个网格点在t时刻的温度有关;对边界条件离散化处理得到离散边界方程:其中,分别为计算钢坯上、下表面的温度时所产生的虚拟点,分别为计算钢坯左、右表面的温度时所产生的虚拟点;表示上表面上的网格点,表示下表面上的网格点,表示左表面上的网格点,表示右表面上的网格点。s3:将钢坯从进加热炉到出加热炉的过程中,连续测量并记录多个网格点的测量温度,根据测量温度和计算温度建立目标函数逆热传导模型:其中,k是指钢坯上的测量点,且测量点k所对应的网格点的在钢坯上的坐标为(x,y);k∈(1,2,3...m)且m是指钢坯从加热炉炉口到加热炉炉尾的路径上选取了m个采集点;tc(x,y,k;p)是钢坯位于采集点时,测量点k对应的网格点处的计算温度;tm(x,y,k)是钢坯位于采集点时,测量点k的测量温度;p为辨识的总括热吸收率;其中钢坯上的网格点可以通过热电偶测量方法得到钢坯的温度信息。通常,这种方法被称作“黑匣子实验”或“埋偶实验”。热电偶及相关设备的安装过程如下所示:在钢坯一侧切除豁口,在豁口下部焊接托板,用来安装黑匣子。托板必须双面打坡口、双面焊满,同时需要在豁口两侧焊接螺丝用来固定黑匣子。按试验钢坯测点位置对热电偶进行长度处理,并与温度记录仪主体连接。对温度记录仪设定,保持固定采样间隔,电偶类型为k型,并设置16个通道为全开状态,然后将温度记录仪装入保温箱内。保温箱外用保温石棉捆扎固定,安装后的试验钢坯按照正常的生产计划装炉。按规定经过一定的加热时间后,试验钢坯从加热炉内被移出,然后尽快吊至料场,放置在地面上,进行试验设备的拆除,尽快将记录仪主体从保温设备中取出,待冷却后进行数据处理。s4:利用混沌粒子群算法对逆热传导模型进行最优化求解,通过极小化逆热传导模型,得到加热炉不同炉段的总括热吸收率。其中步骤s4具体为,如图2所示:s41:混沌初始化,生成一个有f个粒子的种群,且每个粒子中都包括有n个元素;s42:计算每个粒子的适应值fitness(i),其中fitness(i)表示第i个粒子的适应值,求第i个粒子的适应值具体为:首先,将第i个粒子中的前1/3的元素设置为p1(t)的初始解,第i个粒子中的中间的1/3的元素设置为p2(t)的初始解,第i个粒子中的最后的1/3的元素设置为p3(t)的初始解;然后,将p1(t)的初始解中的元素依次代入离散边界方程中的p1(t);将p2(t)的初始解中的元素依次代入离散边界方程中的p2(t);将p3(t)的初始解中的元素依次代入离散边界方程的p3(t);进而通过离散边界方程和离散方程得到钢坯上、下、左、右表面在加热炉内不同位置的计算温度;再然后,根据所述离散方程计算钢坯处于所述采集点时,测量点k对应的网格点的计算温度;再然后,选择钢坯处于采集点时,测量点k对应的网格点处的计算温度,测量点k对应的网格点的测量温度;最后,根据逆热传导模型,求得s(p),并将s(p)作为第i个粒子的适应值;s43:判断当前粒子是否陷入局部最优,如果是,则执行步骤s44,如果为否,则执行s45;s44:加入混沌扰动,其中,表示第i个粒子经过第b+1次迭代后的粒子位置,表示第i个粒子经过第b+1次迭代的粒子速度,δz为一维扰动量,δz=(δz1,δz2,δz3...,δzn),其中,表示粒子中的第d个元素;生成δz的具体步骤可以为:首先,生成利用随机函数先随机生成一个n维的向量:l0=(l01,l02....l0n),且l01∈[0,1]。然后,更新l0得到l1,且:l1=μl0(1-l0),μ为控制参数,且μ∈(2,4];l1=(l11,l12....l1n),l1h=μl0h(1-l0h),h=(1,2,3...n)。再然后,生成每一维变量的混沌扰动量δz=(δz1,δz2,δz3...,δzn),其中:δzj=-β+2βl1h,β表示扰动幅度,扰动范围是[-β,β]。最后,更新l0,将l1的值赋值给l0。s45:按照粒子更新公式更新粒子,粒子更新公式为:其中,w为惯性因子,c1,c2为加速因子且是常数;r1,r2为[0,1]范围内的随机数;第i个粒子在前b步更新后产生的b+1个粒子中适应值最小的粒子作为个体最优解,表示个体最优解的第d个元素;所有粒子在前b步更新产生的粒子中适应值最小的粒子作为群体最优解,表示群体最优解的第d个元素;vi的更新公式由三部分组成:第一部分,称为惯性部分,反映的是粒子上一步的惯性,粒子速度更新一定是在上一步速度的基础上进行的,所以需要用到粒子的上一步的飞行惯性信息;第二部分,是个体认知部分。粒子速度更新要用到粒子本身的历史信息也就是粒子自身的经验;第三部分,是社会认知部分。粒子速度更新要接受群体的信息,表示粒子向群体学习有用经验的过程。s46:当满足结束条件后,停止迭代,并将群体最优解对应的粒子中的元素对应为总括热吸收率;当不满足结束条件时,返回步骤s42。结束条件可以为迭代次数达到设定值时,或者误差要求;在优选的实施方案中,步骤s41具体为:首先,随机生成一个n维向量y1=(y11,y12,y13...y1n),然后根据迭代公式迭代n次,得到n个向量:y1,y2,y3...,yn组成一个向量y=(y1,y2,y3...,yn);迭代公式为:y(l+1),m=μyl,m(1-yl,m),l,m∈[1,n],μ为控制参数,且μ∈(2,4];然后,根据y生成初始解x1,x2,x3...,xn,xl向量中每一个元素对应的是相应位置的总括热吸收率系数,其中:xl,m=am+(bm-am)yl,mam表示向量y第m列元素的下界,bm表示向量y第m列元素的上界,yl,m代表y中(l,m)位置元素;xl,m代表初始解xl中第m个元素,同时也代表加热炉在对应位置的总括热吸收率系数;最后,求得所有初始解的适应值,并选出适应值最小的f个初始解作为一个具有f个粒子的种群,一个初始解对应一个粒子。在优选的实施方案中,在步骤s43中:判断当前粒子是否陷入局部最优具体为:在对第i个粒子进行第b次迭代后,已经连续出现的nc次迭代,若满足:其中,为第i个粒子在经过e次迭代后的适应值,为第i个粒子在经过第b次迭代后的个体最优解,e∈[b-nc,b-nc+1,b-nc+2...b];δ,nc为预先设定的值;则,当前粒子已经陷入局部最优;否则,当前粒子未陷入局部最优。在优选的实施方案中,混沌粒子群算法流程如下:step1:混沌初始化,包括种群规模f,选择每一个粒子的速度vi和位置hi;step2:计算每一个粒子的适应值fitness(i);step3:粒子早熟判断,判断当前粒子是不是陷入局部最优,如果是,执行step4,如果不是,跳过step4执行step5;step4:加入混沌扰动,step5:更新个体最优pbest(i)。对每一个粒子用它的fitness(i)和个体最优比较。如果pbest(i)>fitness(i),则更新pbest(i),将fitness(i)赋值为个体最优pbest(i);step6:更新群体最优gbest(i),对每一个粒子用它的fitness(i)和群体最优gbest(i)比较。如果gbest(i)>fitness(i),则更新gbest(i),将fitness(i)赋值为群体最优gbest(i);step7:更新迭代每一个粒子的速度vi和位置hi;step8:如果满足结束条件(误差要求或达到最大迭代次数)则退出循环,否则返回step2。在上述混沌粒子群算法中,作如下说明,一个群体中包含很多粒子,对应一个问题有各种各样的解,每一个粒子都是优化问题的潜在解,每一个粒子也叫做个体,粒子们组成的群体叫做种群,种群规模就是粒子的个数。同时规定每一个粒子都具有一些属性保存一些信息:1)飞行速度,是一个矢量既有大小也有方向,用vi=(vi,1,vi,2,vi,3....vi,n)表示,vi,d表示第i个粒子在d维空间中的此时的速度;2)位置,也就是当前粒子在空间中的位置,用hi=(hi,1,hi,2...hi,n)表示,代表此时粒子的位置,通俗一点就是此时的解;3)适应值,表示此时粒子在此位置时目标函数的值用fitness(i)表示,表示粒子此时所在位置(解的)优劣程度;4)粒子的最优位置,用pbest(i)表示。表示粒子自身飞行到目前为止最好的位置也就是当前最好的解;5)全体最优,用gbest(i)表示。由于种群中粒子信息是共享的,所以对每一个粒子的个体最优相互比较找到种群中当前最好的解,然后被种群中所有粒子共享。在具体的实施例中:为了钢坯的热传导偏微分方程的计算精度,将钢坯的物性参数看成是关于温度的函数。导热系数λ(也称热导率)代表物体的导热能力。常见规格钢坯的导热系数在800℃以下时会随温度的升高而显著降低。常温下导热系数越大的钢坯,其降低时的幅度会更显著。当温度超过800℃以上后,碳钢的导热系数又会随温度的升高而增大。在不同温度下的导热系数的函数公式二如下所示:其中,a3与20mnsi钢导热系数各常数的值如表1:表1:钢种λ0a1a2a3t0a355.58031.230.25893520mnsi48.77021.480.24950比热c。比热是金属的又一个重要的热物理性质,与其他合金一样,钢坯的比热容与化学成分、温度等因素有关。钢坯的比热近似为温度的分段平滑折线函数,公式三如下所示:以a3和20mnsi为例,上式中各常数的值如表2:表2:公式中的常数b3,随钢坯温度变化。当t≤t0时b3取分子的值,而如果t>t0时取分母。钢坯的密度。由于钢坯密度随钢坯温度的变化改变不是太大,因此本文将钢坯密度当作常数来处理。钢坯的密度因钢坯含碳量的不同而在7800~7850kg*m-3的范围内变化。钢的密度随温度的不同也有所变化,但随温度的变化不大,所以计算时取为常数。随着图像图形学的发展,gpu在高性能计算的领域得到了广泛的应用。gpu架构的设计初衷是为了处理逻辑简单的大规模单一任务的运算,因此gpu的核心数较多,这样gpu就可以同时处理上千个任务。本文所涉及的二维热传导方程的求解,其难点在于计算规模十分很大,由一个时刻计算出下一个时刻的温度值,加上混沌粒子群算法的寻优过程,计算量巨大。热传导方程的求解仅涉及简单的四则运算,并未包含复杂的逻辑。故本文选取基于gpu的cuda平台作为实现并行计算的工具。cuda在技术上采用的是一种异构计算环境,它会同时在cpu和gpu上的进行协调计算。cuda架构由主机(host)和设备(device)组成;其中主机是指传统的cpu,而设备在本文中指的是gpu。代码执行时,核函数在gpu上执行,其余的在cpu上执行,核函数上执行时是多个线程并行执行代码指令。本发明还提供了一种加热炉总括热吸收率的辨识装置包括:储存介质、cpu和gpu;cpu用于执行存储介质上存储的计算机程序,实时实现加热炉总括热吸收率的辨识方法的步骤;gpu在接收到cpu的指令后,对钢坯上的所有网格点的温度采用并行计算的方式得到网格点的计算温度;gpu上划分为很多线程块,一个线程块里面包含很多线程,一个粒子对应一个线程块,钢坯划分为ni*nj个网格,线程与钢坯网格按位置一一对应,所有网格点的温度同时计算。线程块内包括一个共享内存,线程块内部的所有线程都与共享内存进行数据通讯;gpu包括全局内存,共享内存与全局内存进行数据通讯。cuda编程模型主要涉及三个重要的概念,即thread线程,block线程块,grid网格,当kernel函数(核函数)开始执行时,会在gpu上生成一个与之对应的grid网格,一个grid网格下面会包含若干个block线程块,一个block线程块下面又会包含若干个thread线程。gpu网格内包括多个block,每个粒子对应一个block,将钢坯二维截面划分为ni*nj的空间网格,等同于一个线程对应一个钢坯温度场网格,所以整个温度场映射到线程块上。ni,nj分别是x,y方向上的网格总数。温度场的变化伴随着时间的变化,这里时间网格划分为tstep个单元格,每个单元格对应设定的加热时间。空间网格和时间网格划分以后,温度场的计算总共包含f*ni*nj*tstep次逆热传热问题的求解,需要非常大的计算机容量。最外层的循环是粒子群循环,主要是在不同总括热吸收率下采用在粒子群算法求解传热模型f次。接下来是时间循环,主要是计算每个元素处钢坯温度的更新,更新需要已知和周围四个元素的钢坯温度,意味着整个空间上的元素更新都是同时的。针对钢坯二维动态温度场,本文分别给出了基于cpu的串行计算和基于gpu并行计算的伪代码。其中,基于cpu计算的伪代码如表3所示:表3:钢坯二维动态温度场的求解需要四个for循环,从到的单次时间计算不仅包括对钢坯物性参数(导热系数和比热)的计算,还有温度信息的迭代,cpu串行计算的计算量是非常大。下面基于gpu计算的伪代码如表4所示:表4:基于gpu采用混沌粒子群算法,当主机端调用核函数时,将钢坯初始温度场分布、物性参数等数据传入到设备中,设备申请空间进行数据存储以后,并行计算程序启动。每一个粒子对应一个线程块,线程块划分为许多线程对应一个个温度网格点,所有网格温度节点同时计算。访问数据的时间往往远远大于真正的计算时间,所以如何组织数据的存储模式是加速计算的一个关键问题。cuda提供了丰富的存储模型,包括局内存,局部内存,共享内存,纹理内存等,全局内存(globalmemory)是gpu内大小最大的内存。grid中所有的线程都可以访问全局内存,因此全局内存不受到访问的限制使用起来非常便于线程直接的数据交互,但是全局内存的访问速度是最慢的。在进行更新时,如果采用全局内存的话,每次更新需要读写五次,分别是这样是非常浪费时间的。共享存储(sharedmemory)的访问速度要比寄存器慢但比全局内存快,同一个block内的线程都可以访问到sharedmemory的内容,而block外的线程则无法访问到本block的sharedmemory,所以sharedmemeory的使用可以让同一个block内的线程达成数据交互和互相协作的目的。因此对于同一个线程块来说,可以只需要从全局内存中读取一次,剩下的四次在共享内存中读取,最终通过内存的读取节省了很多时间,提升了计算效率。在更加优选的实施方案中加热炉总括热吸收率的辨识装置安装在加热炉上,具体安装在加热炉的控制系统上。需要理解的是,以上对本发明的具体实施例进行的描述只是为了说明本发明的技术路线和特点,其目的在于让本领域内的技术人员能够了解本发明的内容并据以实施,但本发明并不限于上述特定实施方式。凡是在本发明权利要求的范围内做出的各种变化或修饰,都应涵盖在本发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1