一种时空部件图的视频目标分割方法与流程
本发明涉及一种视频目标分割方法,特别是时空部件图的视频目标分割方法。
背景技术:
视频目标分割是在第一帧或参考帧上手动或自动给出特定目标掩模,而后在整个视频序列中的分割这些特定目标。当前方法与实际应用还有很大距离,其中目标遮挡、快速移动、外观变化以及不同实例之间的相似性仍然是主要障碍。文献“fastvideoobjectsegmentationbyreference-guidedmaskpropagation.ieeeoncomputervisionandpatternrecognition,usa,2018:7376-7385”公开了一种视频目标分割方法,使用参考引导的掩模传播方式,将带有标签的参考帧和具有前一帧掩模的当前帧同时用于深度网络,输出目标掩模,取得了一定的效果。但是,该方法使用第一帧中的初始目标掩模来匹配当前帧目标,由于视觉目标分割是变化场景的动态过程,在连续帧中目标外观之间存在很强的时空关系;且简单的叠加参考帧图像和目标掩模、以及当前帧图像和前一帧掩模,没有挖掘两帧图像上空间和时域信息,易导致视觉目标的漂移问题,使得视频目标分割失败。且该方法使用多阶段特征解码方式,但不同的阶段具有不同的识别能力,从而导致不同的一致性表现,使用分割的细节有待提升。
技术实现要素:
本发明的目的是要提供一种时空部件图的视频目标分割方法,解决目标外观变化而导致的视觉目标漂移问题,并解决多阶段特征一致性表现,提高目标分割细节。
为了实现上述技术目的,本发明采用如下技术方案:
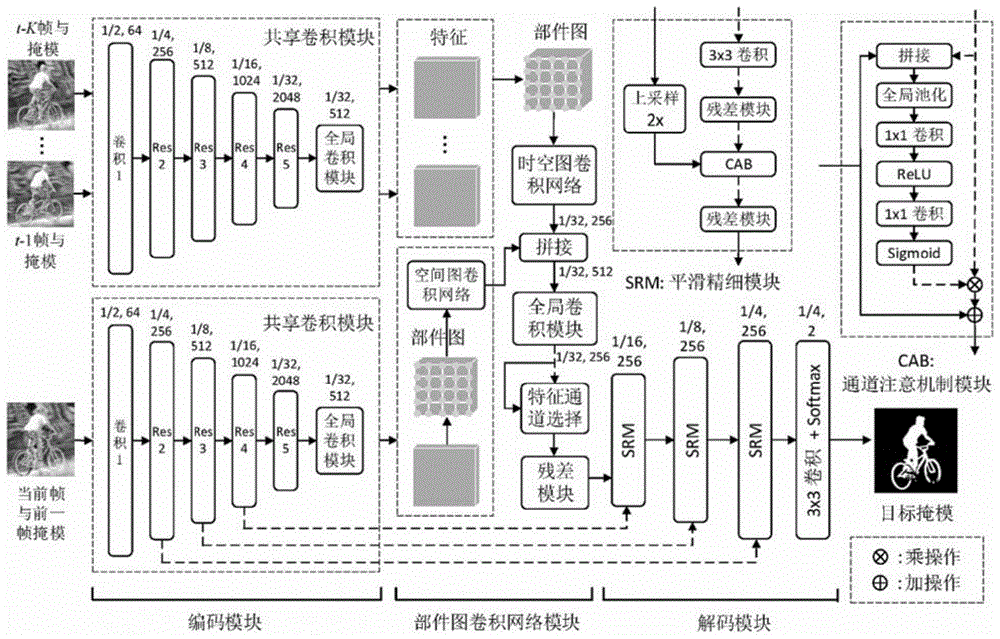
一种时空部件图神经网络的视频目标分割方法,包括以下几个步骤:
s1、使用孪生编码模型构建时空孪生编码模块,所述孪生编码模型分两个分支:一个分支输入历史帧和掩模捕获序列的动态特征,另一个分支输入当前帧图像和前一帧的分割掩模;
s2,构建时空部件图,使用图卷积网络,学习时空特征,增强目标的外观和运动模型;并引入通道注意模块,把鲁棒的时空目标模型输出到解码模块;
s3,设计平滑精细模块,结合相邻阶段的多尺度图像特征,从时空信息中分割出目标。
进一步的,步骤s1具体包括:
s1.1、时空孪生框架有两个分支:第一个分支的输入为一个图像-掩模对
s1.2、在得到resnet50中第5阶段的图像特征之后,使用全局卷积模块生成图像特征,即第一个分支的输出为zt和第二个分支的输出为{zt-k,...,zt-1};
s1.3、将这些特征输入到时空部件图卷积网络中,以处理后输出到解码模块。
进一步的,步骤s2具体包括:
s2.1、构建时空部件外观模型
首先,把时空孪生框架中第二个分支的输出{zt-k,...,zt-1}生成为一个时空部件外观模型,在具有n=h×w个部件和k帧上构建了一个无向时空部件图gst=(v,e),这些帧k具有帧内和帧间部件的关系;
其中,v是无向时空部件图中的节点集,v={vkn|k=t-1,...,t-k;n=1,...,n}包含所有k中所有的节点,其中,vkn为一个节点,f(vkn)为特征向量;
e是无向时空部件图中的边集,边集e包含两类边:第一类是空间边es表示每一帧图像特征中帧内节点之间的关系,表示为es={vkivkj|1≤i,j≤n,i≠j};
第二类为时序边et表示帧间节点之间的关系,将连续帧中具有相同位置的部件连接,即et={vkjv(k+1)j};
基于上述无向时空图,使用图卷积网络对其中节点之间关系进行处理,用图卷积实现,首先,基于无向时空部件图gst关系确定了邻近矩阵a的权重;其次,将邻近矩阵和特征矩阵h(0)表示为图卷积网络的输入,而图卷积网络的输出为更新h(l+1):
其中,θ是需要训练的特定于层的权重矩阵,i为单位矩阵,relu(·)为非线性激活函数;
使用两层图卷积网络,输出矩阵为
其次,时空部件的图卷积网络模块的输入有两个部分,已经生成了时空部件特征模型zst,而另一个部分为当前帧图像特征模型zt,构建一个无向空间部件图gs,无向空间部件图gs与上述无向时空部件图gst相似,不同之处只在于帧的数量,即无向空间部件图gs的图像帧为1,而无向时空部件图gst的图像帧为k,之后,与上述两层图卷积网络处理步骤相同,获得空间部件特征
s2.2、生成鲁棒统一时空部件外观模型
接下来,将时空部件特征zst和空间部件特征zs进行通道对齐,拼接为一个整体特征,此时,使用全局卷积模块将这个特征的两个部分进行特征匹配,这一模块中所有卷积层的产生的特征图的通道都为256,输出特征为z;
最后,时空部件外观模型和空间部件外观模型的输出特征具有不同的特性,采用注意机制为所有的特征分配不同的权重,即特征通道选择,用下列非线性变换把特征z变换为
其中,
进一步的,步骤s3具体包括:
解码模块将步骤s1统一时空目标外观特征作为输入,并与编码模型中的当前帧中生成的特征进行连接,产生图像帧中目标掩码输出;
解码模块包含三个平滑精细模块,再添加一个卷积层和一个softmax层组成,其中,平滑精细模块有两个输入:
一是从上一阶段特征,进行了两倍上采样;
二是从编码模块相同阶段特征:首先使用3×3卷积层,其作用是将通道数统一为256;中间使用两个残差模块优化特征图,通道注意机制模块合并两个特征图,而通道注意机制模块与步骤s2中特征通道选择的操作相似,不同之处在于两个特征图拼接之后再进行加操作;
接下来,softmax层之后掩模输出的尺寸为输入图像的0.25倍,每一个目标都有生成一个两通道掩模图,即输出目标掩模。
进一步的,还包括步骤s4模型训练与推理:
s4.1、进行模型训练,使用从静态图像生成的仿真图像对进行网络预训练,把真实图像和目标掩模作为编码模块的k帧图像,而真实图像的仿真图像和目标掩模作为编码模块的下部分输入;
s4.2、在视频目标分割数据集上微调此预训练模型,即使用davis-2016和davis-2017的训练数据集,分辨率为480p;
为了更好地估计训练中在测试时发生的掩模错误传播,将时间窗口大小k设置为3,即使用来自视频的随机时间索引的k+1个连续目标帧,最后一个图像帧作为分割的当前帧;此外,使用最小化交叉熵损失,用adam优化器以1e-5的学习率训练模型;
s4.3、推理目标分割中,用半监督方式给出了第一帧的真实掩模,依次估计其余帧的掩模,在初始化时,将第一帧重复k次做为参考帧与掩模,k设置为3;
在视频目标分割过程中,使用间隔3来更新参考帧图像与掩模;
此外,对于每个间隔帧,删除一个样本,再添加新的样本。
进一步的,所述基础网络的权重在同一输入的每个网络之间共享。
本发明有益效果,
由于采用了上述方案,构建时空部件图卷积网络,利用历史帧信息,生成时空部件特征;并借助注意机制,构建更好的特征表示。可生成鲁棒目标外观和运动特征,解决目标遮挡、快速变化及背景杂波等问题,进而缓解目标外观变化而导致的视觉目标漂移问题;同时在解码模型,构建平滑精细模块加入注意机制模块,合并多尺度上下文中相邻阶段的特征,处理不同尺度目标的分割,增加目标边缘细节信息,能够提高视频目标分割的性能。
附图说明
图1本发明中时空部件图的视频目标方法框架图。
图2全局卷积模块框架图和残差模块框架图。
具体实施方式
实施例1:主要包括三个部分:时空孪生编码模块、时空部件图神经网络模块以及注意机制的平滑精细解码模块,最后进行模型训练与推理。首先使用孪生编码模型,分两个分支:一个分支输入历史帧和掩模捕获序列的动态特征,另一个分支输入当前帧图像和前一帧的分割掩模。其次,构建时空部件图,使用图卷积网络,学习时空特征,增强目标的外观和运动模型;并引入通道注意模块,把鲁棒的时空目标模型输出到解码模块。最后,设计平滑精细模块,结合相邻阶段的多尺度图像特征,从时空信息中分割出目标。其特点是包括以下步骤:
(1)时空孪生编码模块
(a)首先,时空孪生框架有两个分支:第一个分支的输入为一个图像-掩模对
(b)在得到resnet50中第5阶段(res5)的图像特征之后,使用全局卷积模块生成图像特征,即第一个分支的输出为zt和第二个分支的输出为{zt-k,...,zt-1},提升了网络的分类和密集像素定位能力,且可提高处理效率。
(2)时空部件图神经网络模块
本步骤,将构建一个基于部件(节点)的结构化图表示模型,把zt生成为一个空间目标部件外观模型,同时把{zt-k,...,zt-1}生成为一个时空部件外观模型;之后,通过融合两个外观模型,生成鲁棒的统一时空部件外观模型。具体如下:
(a)构建时空部件外观模型
首先,把{zt-k,...,zt-1}生成为一个时空部件外观模型。在具有n=h×w个部件(节点)和k(即t-k,…,t-1)帧上构建了一个无向时空部件图gst=(v,e),这些帧k具有帧内和帧间部件(节点)的关系。v和e是无向时空部件图中的节点集和边集。其中,节点集v={vkn|k=t-1,...,t-k;n=1,...,n}包含所有k中所有的节点,其中vkn为一个节点,f(vkn)为特征向量。此外,边集e包含两类边:第一类是空间边es表示每一帧图像特征中帧内节点之间的关系,表示为es={vkivkj|1≤i,j≤n,i≠j}。鉴于图像中目标部件具有各种变化,会出现各种相互关系,我们采用完全连接图来描述空间关系。第二类为时序边et表示帧间节点之间的关系,我们将连续帧中具有相同位置的部件(节点)连接,即et={vkjv(k+1)j}。也可看为一个特定部件随着时间的跟踪轨迹。
基于上述无向时空图,使用图卷积网络对其中节点之间关系进行处理,用图卷积实现。首先,基于图gst关系确定了邻近矩阵a的权重;其次,将邻近矩阵和特征矩阵h(0)表示为图卷积网络的输入,而图卷积网络的输出为更新h(l+1):
其中,θ是需要训练的特定于层的权重矩阵,i为单位矩阵,relu(·)为非线性激活函数。本发明中使用两层图卷积网络,输出矩阵为
其次,时空部件的图卷积网络模块的输入有两个部分,已经生成了时空部件特征模型zst,而另一个部分为当前帧图像特征模型zt。构建一个无向空间部件图gs,gs与上述图gst相似,不同之处只在于帧的数量,即gs的图像帧为1,而gst的图像帧为k。之后,与上述两层图卷积网络处理步骤相同,获得空间部件特征
(b)生成鲁棒统一时空部件外观模型
接下来,将时空部件特征zst和空间部件特征zs进行通道对齐,拼接为一个整体特征。此时,使用全局卷积模块将这个特征的两个部分进行特征匹配。这一模块中所有卷积层的产生的特征图的通道都为256,输出特征为z。
最后,时空部件外观模型和空间部件外观模型的输出特征具有不同的特性,采用注意机制为所有的特征分配不同的权重,即特征通道选择,用下列非线性变换把特征z变换为
其中,
(3)注意机制的平滑精细解码模块
解码模块将步骤(2)统一时空目标外观特征作为输入,并与编码模型中的当前帧中生成的特征进行连接,产生图像帧中目标掩码输出。根据编码模型中resnet50特征图的尺寸,可以分为五个阶段,不同的阶段具有不同的识别能力,从而导致不同的一致性表现。在较低的阶段,网络对较精细的空间信息进行编码,但是没有空间上下文指导,且处理的视野较小,使得语义一致性较差。而较高阶段时,处理视野较大,具有很强语义一致性,但预测的空间像素比较粗糙,这样就可以结合其优势,使用平滑精细模块,加入注意机制模块,合并多尺度上下文中相邻阶段的特征。
解码模块包含三个平滑精细模块,再添加一个卷积层和一个softmax层组成。其中,平滑精细模块有两个输入:一是从上一阶段特征,进行了两倍上采样;二是从编码模块相同阶段特征:首先使用3×3卷积层,其作用是将通道数统一为256。中间使用两个残差模块优化特征图,通道注意机制模块合并两个特征图。而通道注意机制模块与步骤(2)中特征通道选择的操作相似,不同之处在于两个特征图拼接之后再进行加操作。接下来,softmax层之后掩模输出的尺寸为输入图像的0.25倍,每一个目标都有生成一个两通道掩模图(背景图和前景图),即输出目标掩模。
(4)模型训练与推理
时空部件图的方法模型构建之后,进行训练与推理。首先进行模型训练,使用从静态图像生成的仿真图像对进行网络预训练。把真实图像和目标掩模作为编码模块的k帧图像,此外k=1,而真实图像的仿真图像和目标掩模作为编码模块的下部分输入。之后,在视频目标分割数据集上微调此预训练模型,即使用davis-2016和davis-2017的训练数据集,分辨率为480p。为了更好地估计训练中在测试时发生的掩模错误传播,将时间窗口大小k设置为3,即使用来自视频的随机时间索引的k+1个连续目标帧,最后一个图像帧作为分割的当前帧。此外,使用最小化交叉熵损失,用adam优化器以1e-5的学习率训练模型。
其次,推理目标分割中,用半监督方式给出了第一帧的真实掩模,依次估计其余帧的掩模。在初始化时,将第一帧重复k次做为参考帧与掩模,k设置为3。在视频目标分割过程中,使用间隔3来更新参考帧图像与掩模,这样可以有效记忆历史信息。此外,对于每个间隔帧,删除一个样本,再添加新的样本。这样可减少编码模块特征计算内存和时间,使得推理更加高效。
- 还没有人留言评论。精彩留言会获得点赞!