数据处理方法、装置及芯片与流程
本申请属于计算机技术领域,具体涉及一种数据处理方法、装置及芯片。
背景技术:
随着计算机技术以及大数据技术的迅速发展,各种神经网络模型的应用变得越来越普遍,例如各种应用程序会根据用户的兴趣自动调整社交多媒体内容。在智能监控领域,神经网络模型可以应用于安全保障、提供增强的面部识别功能、群体行为分析等。在电子支付领域,神经网络模型对于诈骗行为的检测更加的强大。
神经网络模型需要的计算量通常较大,需要高水平的硬件性能支持。现有技术中,神经网络模型通常需要进行前向推理计算,以满足性能和功耗的需求。然而,在运行神经网络模型时对内存访问量很大,产生了较大的访存功耗,造成计算延迟较高,降低了整体的运算性能。
技术实现要素:
本申请实施例的目的是提供一种数据处理方法、装置及芯片,能够解决现有技术中,在运行神经网络模型时对内存访问量较大的问题。
为了解决上述技术问题,本申请是这样实现的:
第一方面,本申请实施例提供了一种数据处理方法,所述方法应用于神经网络计算设备,所述方法包括:
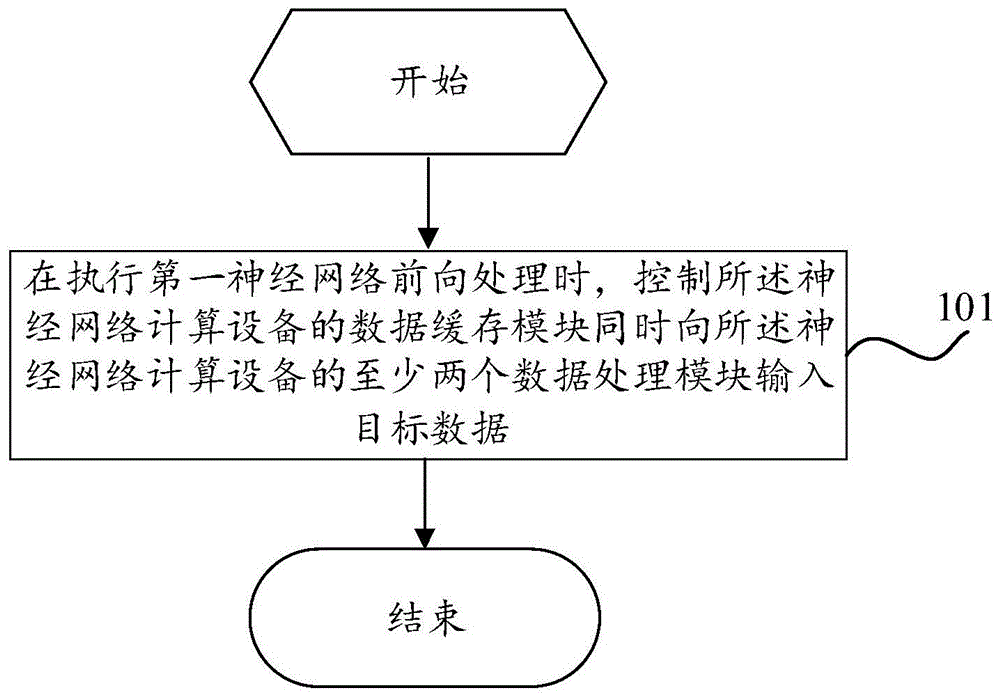
在执行第一神经网络前向处理时,控制所述神经网络计算设备的数据缓存模块同时向所述神经网络计算设备的至少两个数据处理模块输入目标数据;
其中,所述数据处理模块包括第一处理模块、第二处理模块以及第三处理模块。
第二方面,本申请实施例还提供了一种数据处理装置,所述数据处理装置包括:
第一控制模块,用于在执行第一神经网络前向处理时,控制所述神经网络计算设备的数据缓存模块同时向所述神经网络计算设备的至少两个数据处理模块输入目标数据;
其中,所述数据处理模块包括第一处理模块、第二处理模块以及第三处理模块。
第三方面,本申请实施例还提供了一种电子设备,该电子设备包括存储器、处理器及存储在存储器上并可在处理器上运行的程序或指令,所述处理器执行所述程序或指令时实现如上所述的数据处理方法中的步骤。
第四方面,本申请实施例还提供了一种可读存储介质,该可读存储介质上存储有程序或指令,所述程序或指令被处理器执行时实现如上所述的数据处理方法中的步骤。
第五方面,本申请实施例提供了一种芯片,所述芯片包括处理器和通信接口,所述通信接口和所述处理器耦合,所述处理器用于运行程序或指令,实现如上所述的方法。
在本申请实施例中,在执行第一神经网络前向处理时,控制所述神经网络计算设备的数据缓存模块同时向所述神经网络计算设备的至少两个数据处理模块输入目标数据,减少访问内存的次数,进而降低内存访问量,提升硬件加速器的性能。
附图说明
为了更清楚地说明本申请实施例的技术方案,下面将对本申请实施例的描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1表示本申请实施例提供的数据处理方法的流程图;
图2表示本申请实施例提供的第一示例的示意图;
图3表示本申请实施例提供的第二示例的示意图;
图4表示本申请实施例提供的第三示例的示意图;
图5表示本申请的实施例提供的数据处理装置的框图;
图6表示本申请的实施例提供的电子设备的框图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
本申请的说明书和权利要求书中的术语“第一”、“第二”等是用于区别类似的对象,而不用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便本申请的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,说明书以及权利要求中“和/或”表示所连接对象的至少其中之一,字符“/”,一般表示前后关联对象是一种“或”的关系。
下面结合附图,通过具体的实施例及其应用场景对本申请实施例提供的数据处理方法进行详细地说明。
参见图1,本申请一实施例提供了一种数据处理方法,可选地,所述方法可应用于神经网络计算设备,所述神经网络计算设备可以是硬件加速器、中央处理器(centralprocessingunit,cpu)、图形处理器(graphicsprocessingunit,gpu)、数字信号处理器(digitalsignalprocess,dsp)等。所述神经网络计算设备还可以是包括硬件加速器、中央处理器(centralprocessingunit,cpu)、图形处理器(graphicsprocessingunit,gpu)、数字信号处理器(digitalsignalprocess,dsp)中任一种的电子设备,例如手机、电脑。
所述方法包括:
步骤101,在执行第一神经网络前向处理时,控制所述神经网络计算设备的数据缓存模块同时向所述神经网络计算设备的至少两个数据处理模块输入目标数据;其中,所述数据处理模块包括第一处理模块、第二处理模块以及第三处理模块。
其中,数据缓存模块用于输入和输出数据的缓存管理。数据缓存模块可以是采用多个存储库(bank)的静态随机存取存储器(staticrandom-accessmemory,sram)结构,可设置至少两个读写端口,以同时向每个数据处理模块传输数据。
第一神经网络前向处理例如卷积神经网络计算操作,以卷积神经网络计算操作为例,电子设备在执行第一神经网络前向处理时,第一处理模块用于执行卷积算子的计算,并将结果传输给第二处理模块,或者写回数据缓存模块。其中,第二处理模块例如激活函数模块,激活函数模块用于执行卷积神经网络的神经元的非线性处理,将处理后的结果传递给第三处理模块。第三处理模块例如池化模块、缩放模块、求和模块等,用于对数据做池化、缩放、对应点相加等操作后将结果写回数据缓存模块。
在执行第一神经网络前向处理时,控制所述神经网络计算设备的数据缓存模块同时向所述神经网络计算设备的至少两个数据处理模块输入目标数据,目标数据即输入至数据处理模块的数据,数据缓存模块通过同时向多个数据处理模块输入目标数据,可在执行整个数据处理过程只访问内存一次,以减少访问内存的次数,进而降低内存访问量。
作为第一示例,结合图2,图2中以第一神经网络前向处理为卷积神经网络计算操作为例,第一处理模块为卷积计算模块,第二处理模块为激活函数模块,第三处理模块包括池化模块、缩放模块、求和模块等;在执行卷积神经网络计算操作时,数据缓存模块同时向卷积计算模块、激活函数模块、池化模块、缩放模块、求和模块等其中的至少两个输入目标数据,实现一次反访问内存(即访问内存模块)读取数据后,向多个模块输入数据,进而减少数据缓存模块访问内存的次数。避免每向所述模块输入一次数据,就访问一次内存;比如,若在卷积处理模块完成卷积之后,数据缓存模块再向激活函数模块输入数据,此时仍需要再次访问内存一次。
本申请实施例中,在执行第一神经网络前向处理时,控制所述神经网络计算设备的数据缓存模块同时向所述神经网络计算设备的至少两个数据处理模块输入目标数据,减少访问内存的次数,进而降低内存访问量,提升硬件加速器的性能。本申请实施例解决了现有技术中,在运行神经网络模型时对内存访问量较大的问题。
在一个可选实施例中,若所述第一神经网络前向处理包括卷积运算操作,则所述卷积运算操作包括至少两个卷积层;其中,卷积神经网络中的每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算的目的是提取输入的不同特征,作为第二示例,如图3所示,包括第一卷积层和第二卷积层;每个卷积层之间可能具有数据依赖关系,例如第一层卷积层的输出数据可以作为第二次卷积层的输入数据;例如第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,而第二层卷积层能从低级特征中迭代提取更复杂的特征,以提高卷积运输提取特征的能力。
在一个可选实施例中,所述方法还包括:
将所述目标数据同时输入至每个所述卷积层,控制所述第一处理模块合并处理每个所述卷积层的运算操作。
作为第三示例,如图4所示,每个卷积层之间也可能不具有数据依赖关系;这样,目标数据作为输入数据,被同时输入至每个卷积层(第一卷积层和第二卷积层),这样数据缓存模块可通过仅访问内存一次,便可完成向卷积层输入数据,避免向每个卷积层输入数据时均访问内存一次,而造成内存访问量过高。
在一个可选实施例中,所述卷积层包括第一卷积层以及第二卷积层;
所述方法还包括:
将所述目标数据输入至所述第一卷积层得到第一处理数据,并将所述第一处理数据输入至所述第二卷积层,控制所述第一处理模块合并处理每个所述卷积层的运算操作。
对于具有数据依赖关系的卷积层,结合图3,第一卷积层即前一层卷积层,第二卷积层即后一层卷积层,前一层卷积层的输出数据作为后一层卷积层的输入数据,当前一层卷积层部分或全部计算完成后,输出数据(即卷积计算的结果)可不写回内存,而是由数据缓存模块直接将输出数据作为后一层卷积层的卷积计算的输入数据,然后直接开始下一层卷积的计算,以减少内存访问。
在一个可选实施例中,若所述第三处理模块的输入数据包括至少两个层级的输出数据,控制所述第三处理模块执行第二神经网络前向处理时,将第一层级的输出数据输入至第二层级;其中,所述层级为所述第二神经网络前向处理对应的神经网络的拓扑结构中的层级。
以所述第一神经网络前向处理包括求和操作为例,若所述第三处理模块的输入数据包括至少两个层级的输出数据,所述层级包括第一层级以及第二层级;所述层级即在所述第二神经网络前向处理对应的神经网络的拓扑结构中,在所述第三处理模块之前的分支层,例如第三处理模块处理求和操作时,其输入数据包括至少来自两个激活函数模块传输的数据。
当一层运算需要两层的输出数据作为输入数据时,控制所述第三处理模块执行第二神经网络前向处理时,将第一层级的输出数据输入至第二层级,即第一层级的输出数据可以不回写数据到内存,直接进行第二层级的计算,以减少分支层对内存写入和读取。
本申请实施例中,在执行第一神经网络前向处理时,控制所述神经网络计算设备的数据缓存模块同时向所述神经网络计算设备的至少两个数据处理模块输入目标数据,减少访问内存的次数,进而降低内存访问量,提升硬件加速器的性能。本申请实施例解决了现有技术中,在运行神经网络模型时对内存访问量较大的问题。
以上介绍了本申请实施例提供的数据处理方法,下面将结合附图介绍本申请实施例提供的数据处理装置。
需要说明的是,本申请实施例提供的数据处理方法,执行主体可以为数据处理装置,或者该数据处理装置中的用于执行数据处理方法的控制模块。本申请实施例中以数据处理装置执行数据处理方法为例,说明本申请实施例提供的数据处理方法。
参见图5,本申请实施例还提供了一种数据处理装置500,包括:
第一控制模块501,用于在执行第一神经网络前向处理时,控制所述神经网络计算设备的数据缓存模块同时向所述神经网络计算设备的至少两个数据处理模块输入目标数据;
其中,所述数据处理模块包括第一处理模块、第二处理模块以及第三处理模块。
其中,数据缓存模块用于输入和输出数据的缓存管理。数据缓存模块可以是采用多个存储库(bank)的静态随机存取存储器(staticrandom-accessmemory,sram)结构,可设置至少两个读写端口,以同时向每个数据处理模块传输数据。
第一神经网络前向处理例如卷积神经网络计算操作,以卷积神经网络计算操作为例,电子设备在执行第一神经网络前向处理时,第一处理模块用于执行卷积算子的计算,并将结果传输给第二处理模块,或者写回数据缓存模块。其中,第二处理模块例如激活函数模块,激活函数模块用于执行卷积神经网络的神经元的非线性处理,将处理后的结果传递给第三处理模块。第三处理模块例如池化模块、缩放模块、求和模块等,用于对数据做池化、缩放、对应点相加等操作后将结果写回数据缓存模块。
在执行第一神经网络前向处理时,控制所述神经网络计算设备的数据缓存模块同时向所述神经网络计算设备的至少两个数据处理模块输入目标数据,目标数据即输入至数据处理模块的数据,数据缓存模块通过同时向多个数据处理模块输入目标数据,可在执行整个数据处理过程只访问内存一次,以减少访问内存的次数,进而降低内存访问量。
作为第一示例,结合图2,图2中以第一神经网络前向处理为卷积神经网络计算操作为例,第一处理模块为卷积计算模块,第二处理模块为激活函数模块,第三处理模块包括池化模块、缩放模块、求和模块等;在执行卷积神经网络计算操作时,数据缓存模块同时向卷积计算模块、激活函数模块、池化模块、缩放模块、求和模块等其中的至少两个输入目标数据,实现一次反访问内存(即访问内存模块)读取数据后,向多个模块输入数据,进而减少数据缓存模块访问内存的次数。避免每向所述模块输入一次数据,就访问一次内存;比如,若在卷积处理模块完成卷积之后,数据缓存模块再向激活函数模块输入数据,此时仍需要再次访问内存一次。
在一个可选实施例中,若所述第一神经网络前向处理包括卷积运算操作,则所述卷积运算操作包括至少两个卷积层;其中,卷积神经网络中的每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算的目的是提取输入的不同特征,作为第二示例,如图3所示,包括第一卷积层和第二卷积层;每个卷积层之间可能具有数据依赖关系,例如第一层卷积层的输出数据可以作为第二次卷积层的输入数据;例如第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,而第二层卷积层能从低级特征中迭代提取更复杂的特征,以提高卷积运输提取特征的能力。
在一个可选实施例中,所述装置500还包括:
第二控制模块,用于将所述目标数据同时输入至每个所述卷积层,控制所述第一处理模块合并处理每个所述卷积层的运算操作。
作为第三示例,如图4所示,每个卷积层之间也可能不具有数据依赖关系;这样,目标数据作为输入数据,被同时输入至每个卷积层(第一卷积层和第二卷积层),这样数据缓存模块可通过仅访问内存一次,便可完成向卷积层输入数据,避免向每个卷积层输入数据时均访问内存一次,而造成内存访问量过高。
在一个可选实施例中,所述卷积层包括第一卷积层以及第二卷积层;
所述装置500还包括:
第三控制模块,用于将所述目标数据输入至所述第一卷积层得到第一处理数据,并将所述第一处理数据输入至所述第二卷积层,控制所述第一处理模块合并处理每个所述卷积层的运算操作。
对于具有数据依赖关系的卷积层,结合图3,第一卷积层即前一层卷积层,第二卷积层即后一层卷积层,前一层卷积层的输出数据作为后一层卷积层的输入数据,当前一层卷积层部分或全部计算完成后,输出数据(即卷积计算的结果)可不写回内存,而是由数据缓存模块直接将输出数据作为后一层卷积层的卷积计算的输入数据,然后直接开始下一层卷积的计算,以减少内存访问。
在一个可选实施例中,所述装置500还包括:
第四控制模块,用于若所述第三处理模块的输入数据包括至少两个层级的输出数据,控制所述第三处理模块执行第二神经网络前向处理时,将第一层级的输出数据输入至第二层级;
其中,所述层级为所述第二神经网络前向处理对应的神经网络的拓扑结构中的层级。
对于具有数据依赖关系的卷积层,结合图3,第一卷积层即前一层卷积层,第二卷积层即后一层卷积层,前一层卷积层的输出数据作为后一层卷积层的输入数据,当前一层卷积层部分或全部计算完成后,输出数据(即卷积计算的结果)可不写回内存,而是由数据缓存模块直接将输出数据作为后一层卷积层的卷积计算的输入数据,然后直接开始下一层卷积的计算,以减少内存访问。
本申请实施例中,第一控制模块501在执行第一神经网络前向处理时,控制所述神经网络计算设备的数据缓存模块同时向所述神经网络计算设备的至少两个数据处理模块输入目标数据,减少访问内存的次数,进而降低内存访问量,提升硬件加速器的性能。
本申请实施例中的数据处理装置500可以是装置500,也可以是终端中的部件、集成电路、或芯片。该装置可以是移动电子设备,也可以为非移动电子设备。示例性的,移动电子设备可以为手机、平板电脑、笔记本电脑、掌上电脑、车载电子设备、可穿戴设备、超级移动个人计算机(ultra-mobilepersonalcomputer,umpc)、上网本或者个人数字助理(personaldigitalassistant,pda)等,非移动电子设备可以为服务器、网络附属存储器(networkattachedstorage,nas)、个人计算机(personalcomputer,pc)、电视机(television,tv)、柜员机或者自助机等,本申请实施例不作具体限定。
本申请实施例中的数据处理装置可以为具有操作系统的装置。该操作系统可以为安卓(android)操作系统,可以为ios操作系统,还可以为其他可能的操作系统,本申请实施例不作具体限定。
本申请实施例提供的数据处理装置能够实现图1至图4的方法实施例中数据处理装置实现的各个过程,为避免重复,这里不再赘述。
可选的,本申请实施例还提供一种电子设备,包括处理器610,存储器609,存储在存储器609上并可在所述处理器610上运行的程序或指令,该程序或指令被处理器610执行时实现上述数据处理方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
需要注意的是,本申请实施例中的电子设备包括上述所述的移动电子设备和非移动电子设备;所述电子设备可以是包括硬件加速器、cpu、gpu、dsp等模块的设备。
图6为实现本申请各个实施例的一种电子设备600的硬件结构示意图;
该电子设备600包括但不限于:射频单元601、网络模块602、音频输出单元603、输入单元604、传感器605、显示单元606、用户输入单元607、接口单元608、存储器609、处理器610、以及电源611等部件。
本领域技术人员可以理解,电子设备600还可以包括给各个部件供电的电源(比如电池),电源可以通过电源管理系统与处理器610逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。图6中示出的电子设备结构并不构成对电子设备的限定,电子设备可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置,在此不再赘述。
其中,处理器610,用于在执行第一神经网络前向处理时,控制所述神经网络计算设备的数据缓存模块同时向所述神经网络计算设备的至少两个数据处理模块输入目标数据;
其中,所述数据处理模块包括第一处理模块、第二处理模块以及第三处理模块。
可选地,处理器610,用于若所述第一神经网络前向处理包括卷积运算操作,则所述卷积运算操作包括至少两个卷积层。
可选地,处理器610,用于将所述目标数据同时输入至每个所述卷积层,控制所述第一处理模块合并处理每个所述卷积层的运算操作。
可选地,所述卷积层包括第一卷积层以及第二卷积层;
处理器610,用于将所述目标数据输入至所述第一卷积层得到第一处理数据,并将所述第一处理数据输入至所述第二卷积层,控制所述第一处理模块合并处理每个所述卷积层的运算操作。
可选地,处理器610,用于若所述第三处理模块的输入数据包括至少两个层级的输出数据,控制所述第三处理模块执行第二神经网络前向处理时,将第一层级的输出数据输入至第二层级;
其中,所述层级为所述第二神经网络前向处理对应的神经网络的拓扑结构中的层级。
本申请实施例中,处理器610在执行第一神经网络前向处理时,控制所述神经网络计算设备的数据缓存模块同时向所述神经网络计算设备的至少两个数据处理模块输入目标数据,减少访问内存的次数,进而降低内存访问量,提升硬件加速器的性能。
应理解的是,本申请实施例中,输入单元604可以包括图形处理器(graphicsprocessingunit,gpu)6041和麦克风6042,图形处理器6041对在视频捕获模式或图像捕获模式中由图像捕获装置(如摄像头)获得的静态图片或视频的图像数据进行处理。显示单元606可包括显示面板6061,可以采用液晶显示器、有机发光二极管等形式来配置显示面板6061。用户输入单元607包括触控面板6071以及其他输入设备6072。触控面板6071,也称为触摸屏。触控面板6071可包括触摸检测装置和触摸控制器两个部分。其他输入设备6072可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆,在此不再赘述。存储器609可用于存储软件程序以及各种数据,包括但不限于应用程序和操作系统。处理器610可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可以理解的是,上述调制解调处理器也可以不集成到处理器610中。
本申请实施例还提供一种可读存储介质,可读存储介质上存储有程序或指令,该程序或指令被处理器执行时实现上述数据处理方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
其中,所述处理器为上述实施例中所述的电子设备中的处理器。所述可读存储介质,包括计算机可读存储介质,如计算机只读存储器(read-onlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、磁碟或者光盘等。
本申请实施例另提供了一种芯片,所述芯片包括处理器和通信接口,所述通信接口和所述处理器耦合,所述处理器用于运行程序或指令,实现上述数据处理方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
应理解,本申请实施例提到的芯片还可以称为系统级芯片、系统芯片、芯片系统或片上系统芯片等。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。此外,需要指出的是,本申请实施方式中的方法和装置的范围不限按示出或讨论的顺序来执行功能,还可包括根据所涉及的功能按基本同时的方式或按相反的顺序来执行功能,例如,可以按不同于所描述的次序来执行所描述的方法,并且还可以添加、省去、或组合各种步骤。另外,参照某些示例所描述的特征可在其他示例中被组合。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本申请各个实施例所述的方法。
上面结合附图对本申请的实施例进行了描述,但是本申请并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本申请的启示下,在不脱离本申请宗旨和权利要求所保护的范围情况下,还可做出很多形式,均属于本申请的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!