一种轻量型图像分类硬件加速器及其加速方法
本技术涉及图像数据处理,尤其涉及一种轻量型图像分类硬件加速器及其加速方法。
背景技术:
1、深度可分离卷积将传统卷积解耦为深度卷积和逐点卷积,因此传统的卷积神经网络加速器已经不适用于进行深度可分离卷积神经网络的计算,对于此,现有技术提出了一种流水线式的计算架构,通过引入额外的feature bank预先将off-chip memory中的数据进行读入,以两块不同的计算单元分别进行逐点卷积和深度卷积的计算。但是,引入额外的存储单元意味着硬件资源消耗的增加以及数据读写时间的增长,此外,shufflenetv2的构造块交替使用了逐点卷积和深度卷积,这种流水线式的结构也会造成计算的不连贯,降低计算效率;同样也有考虑了网络模型中不同卷积计算模式的组合,进而设计出了一个可重构的深度可分离神经网络加速器,计算模块同时支持逐点卷积和深度卷积的计算。然而这种可重构的结构未能保证各种计算模式能够充分利用计算资源,在进行计算时仍会有一部分计算资源处于闲置状态,其结构也并不支持分组卷积和网络混洗操作,使得加速器无法发掘并行性的潜力从而提升性能;也存在通过算法与硬件协同设计,单独分离了跳跃分支,并在逐点卷积后将两部分的结果相连接,实现了加速器中通道混洗的操作。这种方式虽然在一定程度上保持了特征图存储的连续性,但是仍然会产生大量的内存读写,造成延时。
2、综上,相关技术中存在的技术问题有待得到改善。
技术实现思路
1、本技术实施例的主要目的在于提出一种轻量型图像分类硬件加速器及其加速方法,能够在提高图像分类硬件的计算效率的同时提高图像分类识别的准确率。
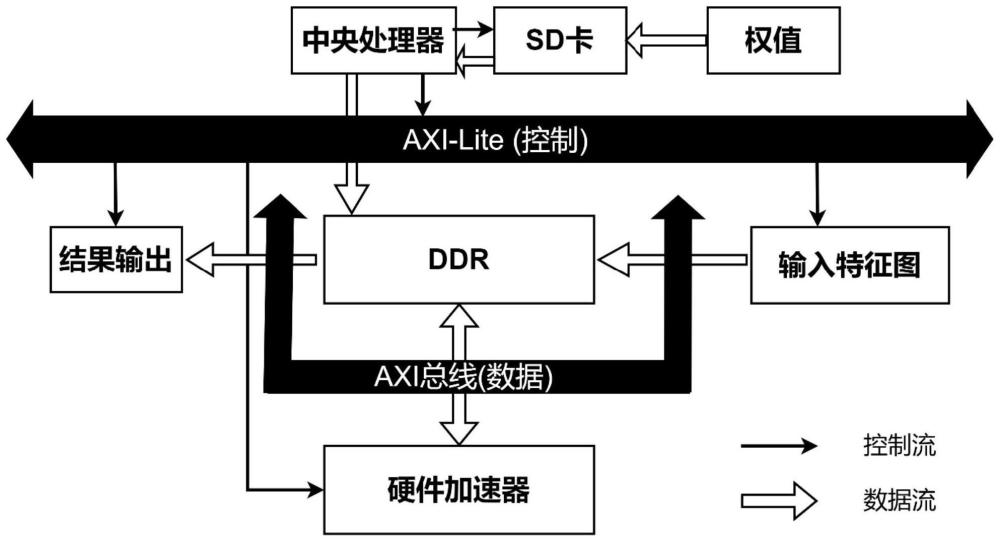
2、为实现上述目的,本技术实施例的一方面提出了一种轻量型图像分类硬件加速器,所述图像分类硬件加速器包括sd卡、中央处理器、双数据速率存储器和硬件加速器,所述sd卡的输出端与所述中央处理器的输入端连接,所述中央处理器的输出端与所述双数据速率存储器的第一输入端连接,所述双数据速率存储器的输出端与所述硬件加速器的输入端连接,所述硬件加速器的输出端与所述双数据速率存储器的第二输入端连接,其中:
3、所述sd卡用于存储训练后的卷积核权值;
4、所述中央处理器用于产生指令对所述图像分类硬件加速器进行控制;
5、所述双数据速率存储器用于获取特征图像数据并进行分类计算;
6、所述硬件加速器引入卷积阵列与通道混洗模块,用于对所述特征图像数据的分类计算过程进行加速。
7、在一些实施例中,所述硬件加速器包括控制模块、存储模块、缓存模块和计算模块,所述控制模块的第一输出端与所述缓存模块的第一输入端连接,所述控制模块的第二输出端与所述计算模块的第一输入端连接,所述缓存模块的第一输出端与所述计算模块的第二输入端连接,所述计算模块的输出端与所述缓存模块的第二输入端连接,所述缓存模块的第二输出端与所述存储模块的输入端连接,所述存储模块的输出端与所述缓存模块的第三输入端连接,其中:
8、所述控制模块用于控制所述硬件加速器的工作;
9、所述存储模块用于存储所述特征图像数据的分类计算过程的中间数据;
10、所述缓存模块用于对所述特征图像数据的读入与写出;
11、所述计算模块用于对所述特征图像数据的分类计算过程进行加速。
12、在一些实施例中,所述缓存模块包括权值缓存器、激活缓存器和输出缓存器,其中:
13、所述权值缓存器用于读取所述训练后的卷积核权值;
14、所述激活缓存器用于读取所述特征图像数据;
15、所述输出缓存器用于将所述特征图像数据的分类计算过程的中间数据存入所述存储模块。
16、在一些实施例中,所述计算模块包括卷积阵列、加法树模块、池化模块、激活模块和通道混洗模块,所述卷积阵列的输出端与所述加法树模块的输入端连接,所述加法树模块的输出端与所述池化模块的输入端连接,所述池化模块的输出端与所述激活模块的输入端连接,所述激活模块的输出端与所述通道混洗模块的输入端连接,其中:
17、所述卷积阵列用于将所述特征图像数据与所述训练后的卷积核权值进行乘法计算,得到若干乘法计算结果;
18、所述加法树模块用于将若干所述乘法计算结果进行累加,完成卷积计算过程;
19、所述池化模块用于对所述卷积计算过程进行最大池化处理;
20、所述激活模块用于对所述卷积计算过程进行映射处理;
21、所述通道混洗模块用于对特征图像数据分类计算结果进行通道混洗处理,得到最终的特征图像数据分类计算结果。
22、在一些实施例中,所述卷积阵列包括第一图片处理单元、第二图片处理单元和第三图片处理单元,所述第一图片处理单元、所述第二图片处理单元和所述第三图片处理单元均包括若干乘法器单元,所述第一图片处理单元、所述第二图片处理单元和所述第三图片处理单元通过并行方式连接。
23、为实现上述目的,本技术实施例的另一方面提出了一种轻量型图像分类硬件加速器的加速方法,所述方法包括:
24、获取所述训练后的卷积核权值和所述特征图像数据;
25、基于所述训练后的卷积核权值和所述特征图像数据进行图像分类计算处理;
26、引入加速器,对所述图像分类计算处理进行加速,得到最终的特征图像数据分类计算结果。
27、在一些实施例中,所述基于所述训练后的卷积核权值和所述特征图像数据进行图像分类计算处理,包括:
28、对所述图像分类硬件加速器进行初始化处理,将开始信号进行拉高处理并获取载入数据信号;
29、基于所述载入数据信号将所述训练后的卷积核权值和所述特征图像数据进行载入;
30、对载入后的所述训练后的卷积核权值与载入后的所述特征图像数据进行图像分类计算处理,计算结束后获取运算结束标志;
31、循环载入所述训练后的卷积核权值和所述特征图像数据的步骤以及所述图像分类计算处理的步骤,直至所述开始信号为低,结束所述图像分类计算处理。
32、在一些实施例中,所述引入加速器,对所述图像分类计算处理进行加速,得到最终的特征图像数据分类计算结果,包括:
33、引入加速器,将所述特征图像数据与所述训练后的卷积核权值进行乘法计算,得到若干乘法计算结果;
34、对若干所述乘法计算结果进行累加计算,得到累加后的乘法计算结果;
35、对所述累加后的乘法计算结果进行最大池化处理,得到最大池化后的乘法计算结果;
36、对所述最大池化后的乘法计算结果进行映射处理,得到映射后的乘法计算结果;
37、对所述映射后的乘法计算结果进行通道混洗处理,得到最终的特征图像数据分类计算结果。
38、在一些实施例中,所述对所述累加后的乘法计算结果进行最大池化处理,得到最大池化后的乘法计算结果,包括:
39、对所述累加后的乘法计算结果进行行维度比较与列维度比较;
40、获取行维度比较得到的最大行维度累加后的乘法计算结果与列维度比较得到的最大列维度累加后的乘法计算结果;
41、将所述最大行维度累加后的乘法计算结果与所述最大列维度累加后的乘法计算结果进行比较,选取最大的累加后的乘法计算结果作为最大池化后的乘法计算结果。
42、在一些实施例中,所述对所述映射后的乘法计算结果进行通道混洗处理,得到最终的特征图像数据分类计算结果,包括:
43、对所述映射后的乘法计算结果进行划分处理,得到若干组特征图,每组特征图包括若干组通道数;
44、令i表示当前为第i组特征图,j表示当前组下第j特征图通道,group表示每组包含的通道数,k表示总通道数channel和group的比值,channel表示所有特征图的总通道数;
45、当j小于group时,进入内层循环;
46、若i小于k/2,表示正在跳跃分支部分通道地址,每间隔一个group写入到新的地址addr2中;
47、若i大于k/2,表示正在遍历残差分支部分,每隔一个group写入到地址addr2剩余部分中;
48、完成第一次内层循环后,特征图组数i加一,进入下一次循环,直至组数与k值相等,输出最终的特征图像数据分类计算结果。
49、本技术实施例至少包括以下有益效果:本技术提供一种轻量型图像分类硬件加速器及其加速方法,该方案通过引入硬件加速器对特征图像数据的分类计算过程进行加速,硬件加速器加速中采用了可重构的卷积计算阵列,能够同时支持标准卷积模式和深度卷积模式,两种卷积模式进行计算时都能够完全利用到阵列中的所有计算单元,提高计算效率的同时能够达到很高的资源利用率,采用了改进的通道混洗模式,在保证识别准确率的前提下大大减少了数据读写的次数,减少了内存读写的延时和资源消耗。
- 还没有人留言评论。精彩留言会获得点赞!