一种存算FPGA架构的制作方法
一种存算fpga架构
技术领域
1.本发明涉及fpga架构的修改和近存储器系统结构,具体是涉及了一种支持通用网络mac运算的存算fpga架构。
背景技术:
2.互联网、云计算、人工智能和物联网等高新技术的发展,推动了数据量的急剧增长。而这些技术的发展都离不开深度神经网络。但是在处理深度神经网络这类数据密集型应用的过程中,处理器和存储器间大量数据的频繁传输会造成严重的性能损耗和能量消耗,这也是当前冯诺依曼架构最大的瓶颈。传统的冯诺依曼架构由运算器、控制器、存储器以及输入输出设备组成,各个模块之间通过总线互联。这种结构包括独立的计算单元和存储单元,其在执行各种计算任务的过程中,需要在存储单元和计算单元之间反复传输大量的数据,这将导致巨大的延迟和能量损耗,从而限制了数据处理的效率。为了打破冯诺依曼瓶颈,在智能大数据背景下构建更高效的硬件设施与计算架构,存内计算技术被提出。该技术将计算和存储融合,支持数据在存储模块中直接运算,并将最终结果反馈回处理器,从而大幅缩减了数据在总线传输的用时和能耗。
技术实现要素:
3.为了解决背景技术中存在的问题,本发明提出了一种存算fpga架构,具有fpga的并行性、可重构性的优势和存储器内计算低功耗的优势,支持多种网络映射。
4.本发明所采用的技术方案是:
5.本发明的fpga架构包括了输入输出模块iob、逻辑功能块clb、存储块bram;输入输出模块iob分布在fpga的外围,基本的存储块bram分布在fpga内部,逻辑功能块clb分布在fpga内部的各处,还包括用于取代部分逻辑功能块clb的存算核cim_core;存算核cim_core、存储块bram、逻辑功能块clb按照行列阵列排布,以岛型架构布置。
6.所述的存算核cim_core主要由sram阵列、寄存器、加法树adder tree、移位加模块mux and add和量化模块quantization、地址译码电路和写控制电路构成,寄存器包括多个输入寄存器和一个输出寄存器;
7.所述的sram阵列含有若干个行列阵列排布的sram,一个sram用于存储一位数据,地址译码电路的各个输出端和sram阵列的各行sram连接,写控制电路的各个输出端和sram阵列的各列sram连接,sram阵列的每八列sram和对应的一个输入寄存器通过多路选择器mux和或非门连接到加法树adder tree的一个8bit输入端口,加法树adder tree的输出端口依次经移位加模块mux and add和量化模块quantization后和输出寄存器连接。
8.其中,sram阵列的每列sram的各个sram输出连接到各自对应的一个或非门的一个输入端,各个或非门的另一个输入端均经同一个多路选择器mux连接到同一个输入寄存器中,或非门的输出端和加法树adder tree的一个输入端口连接。
9.所述的地址译码电路接收地址数据,处理生成各路写字线信号wwl、读字线信号
rwl和读字线反信号rwlb,每路写字线信号wwl、读字线信号rwl和读字线反信号rwlb输入到sram阵列的一行sram中;
10.是每个sram的输出读位线信号rbl,写控制电路生成各路写位线信号wbl、写位线反信号wblb,每路写位线信号wbl、读位线信号rbl、写位线反信号wblb输入到sram阵列的一列sram中;
11.sram阵列的每个sram根据写字线信号wwl、读字线信号rwl、读字线反信号rwlb、写位线信号wbl、读位线信号rbl、写位线反信号wblb的控制处理输出一位数值,每个输入寄存器存储多位数值,输入寄存器的多位数值根据多路选择器mux选择其中一位数值发送到一个或非门与sram阵列中的一个sram输出的一位数值一起经过或非计算获得一位输出数值,sram阵列的各列中各个sram输出的各位数值经或非门对应获得的各位输出数值按照列中各个sram顺序连接成多位阵列数值,多位阵列数值输入到加法树adder tree的一个输入端口;
12.加法树adder tree的输出端口输出sram阵列的所有多位阵列数值进行排布后通过移位加模块mux and add移位相加处理后获得一个(不一致)多位移位后数值,再将多位移位后数值通过量化模块quantization处理取多位移位后数值其中的连续多位输出存储到输出寄存器中。
13.所述的sram阵列的每个sram根据写字线信号wwl、读字线信号rwl、读字线反信号rwlb、写位线信号wbl、读位线信号rbl、写位线反信号wblb的控制处理输出一位数值具体为:
14.写字线信号wwl、写位线信号wbl和写位线反信号wblb用于控制sram阵列的写操作:当某一行的写字线信号wwl为1时,对该行的所有sram单元进行写操作,写入的权值由该sram单元的写位线信号wbl和写位线反信号wblb共同决定;
15.读字线信号rwl、读字线反信号rwlb和读位线信号rbl用于控制sram阵列的读操作:当某一行的读字线信号rwl为1且读字线反信号rwlb为0时,对该行的所有sram单元进行读操作,读出的权值通过每个sram单元的读位线信号rbl读出并送出sram阵列。
16.6、根据权利要求2所述的一种存算fpga架构,其特征在于:
17.每个所述sram主要由10个mos管构成,mos管m0、mos管m5和mos管m8的栅极均和写字线信号wwl连接,mos管m0源极和写位线信号wbl连接,mos管m0、mos管m1和mos管m2的漏极以及mos管m3和mos管m4的栅极连接到一起,mos管m1、mos管m3和mos管m6的源极接电压,mos管m2、mos管m4和mos管m7的源极接地,mos管m5、mos管m3和mos管m4的漏极以及mos管m1、mos管m2、mos管m6、mos管m7的栅极连接到一起,mos管m5源极和写位线反信号wblb连接,mos管m6~mos管m9的漏极连接到一起,mos管m8和mos管m9的源极均连接到一起后再和读位线信号rbl连接,mos管m8栅极和读字线信号rwl连接,mos管m9栅极和读字线反信号rwlb连接。
18.所述的加法树adder tree是由多个行波进位加法器rca构成,加法树adder tree从自身的每个输入端口接收一个多位阵列数值,将各个输入端口接收的各个多位阵列数值作为多位数值按照输入端口顺序对齐排序,通过行波进位加法器rca进行多次进位加法处理,获得最终的一个多位数值:
19.每次进位加法处理中,是将当前所有多位数值以每相邻两个多位数值组成一组通过一个行波进位加法器rca进行相加处理获得一个多位数值;若当前所有多位数值的数量
是奇数,则余下的一个多位数值在当前次进位加法处理不处理,而直接传递到下一次进位加法处理。
20.所述的加法树是由多个进位保留加法器csa、多个半加器ha和一个行波进位加法器rca构成,
21.加法树adder tree从自身的每个输入端口接收一个多位阵列数值,将各个输入端口接收的各个多位阵列数值作为多位数值按照输入端口顺序对齐排序,通过进位保留加法器csa和半加器ha的结合进行多次进位加法处理,直到多位数值的数量仅为两个:
22.每次进位加法处理中,是针对每一位作为处理位进行遍历,先将处理位下的每连续三个数值组成一组通过一个进位保留加法器csa进行相加处理获得一个处于处理位原位的数值和一个处于处理位进一位的数值;若用进位保留加法器csa处理后在处理位余下两个数值,则针对该两个数值采用半加器ha进行相加处理获得一个处于处理位原位的数值和一个处于处理位进一位的数值;若用进位保留加法器csa处理后在处理位余下一个数值,则该数值在当前次进位加法处理不处理,而直接传递到下一次进位加法处理;
23.在多位数值的数量仅为两个之后,采用行波进位加法器rca对两个多位数值进行相加处理获得最终的一个多位数值。
24.所述的移位加模块mux and add移位相加处理,具体是将加法树adder tree输出的多位数值进行移位和累加,获得最终的未量化前的结果。移位的多少取决于之前通过多路选择器mux选择的输入寄存器的哪一位,最低位则不用移位,低1位则左移一位之后再累加,依此类推。
25.所述的存算fpga架构用于全连接层的运算,是将全连接层中的一个全连接因子中的各个权重按顺序分别分配到一个存算核cim core同一行sram的各个sram中,全连接层中的不同全连接因子的权重分配到不同行sram中,每个输入寄存器预先存储输入特征图的一个通道的数据。
26.所述的存算fpga架构用于卷积层的运算,是将卷积层中的一个卷积核中同一位置的所有输入通道的权重按顺序分别分配到一个存算核cim core同一行的连续多个sram中,对卷积层中的一个卷积核中不同位置进行遍历,且将卷积层中的一个卷积核中所有位置的所有输入通道的权重均分配到一个存算核cim core的同一行sram中;对于输入特征图,按照卷积核滑动遍历,以卷积核覆盖的同一位置的所有输入通道的输入特征图激活按顺序分别分配到各个输入寄存器中,每个输入寄存器存储一个8bit的激活。
27.存算核cim_core取代部分逻辑功能块clb的数量根据全连接层/卷积层的运算分配情况按照最小数量处理。
28.本发明基于vtr(verilog-to-routing)工程,通过改变fpga的架构,嵌入新的既能进行存储又能实现基本的mac运算的存算核cim_core,将网络以特定的形式送入,经过转换和处理得到网络的核心信息。然后根据网络的大小和嵌入的存算核cim_core所支持的最大的尺寸大小,先对网络进行分割,然后分配尽可能少的数量的存算核完成运算。新嵌入的存算核cim_core支持存储和计算两种模式,在开始计算前让存算核工作在存储模式,此时通过接口,按照时序将网络的权重信息预先存储在存算核cim_core中;开始计算后通过使能控制端让存算核进入计算模式,此时送入存算核的数据不再进行存储操作,而是直接放入寄存器中,等待读取到的权重后开始进行计算。
29.本发明的有益效果是:
30.本发明提出的存算fpga架构,实现了在fpga上完成存内计算。既利用fpga的并行性和可重构性的优势使得的设计支持多种网络的映射,又能利用存内计算技术减少数据的搬移从而进一步降低计算功耗。
附图说明
31.图1是自定义的fpga架构示意图;
32.图2是存算核内部结构示意图;
33.图3是10t sram电路结构示意图;
34.图4是以行波进位加法器为基础单元构建的加法树和点阵表示图;
35.图5是以进位保留加法器和半加器构建加法树的点阵图;
36.图6是全连接层的映射示意图;
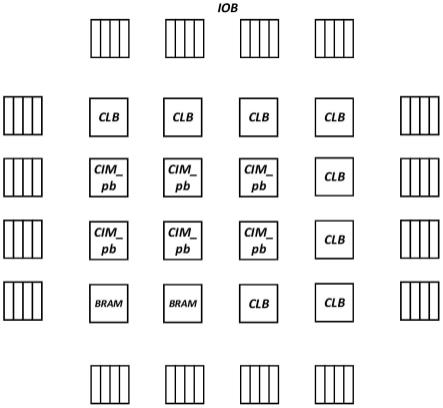
37.图7是卷积层的映射示意图;
38.图8是存算核的分配示意图;
39.图9是20x20大小的存算fpga架构示意图;
40.图10是20x20大小的一般fpga架构示意图;
41.图11是使用存算fpga架构的功率报告图;
42.图12是使用一般fpga架构的功率报告图。
具体实施方式
43.下面结合附图和具体实施对本发明作进一步说明。
44.如图1所示,fpga架构包括了输入输出模块iob、逻辑功能块clb、存储块bram;输入输出模块iob分布在fpga的外围,基本的存储块bram分布在fpga内部,逻辑功能块clb分布在fpga内部的各处,逻辑功能块clb内部包含若干查找表、寄存器和多路选择器等资源;
45.其特征在于:还包括用于取代部分逻辑功能块clb的存算核cim_core;存算核cim_core、存储块bram、逻辑功能块clb按照行列阵列排布,以岛型架构布置,且相互之间按需用布线和开关盒连接。
46.存算核cim_core取代了其中若干的逻辑功能块clb,用于加速fpga架构内部的神经网络的核心mac运算,核心mac运算是指乘加运算。
47.如图2所示,存算核cim_core主要由sram阵列、寄存器、加法树adder tree、移位加模块mux and add和量化模块quantization、地址译码电路和写控制电路构成,寄存器包括多个输入寄存器和一个输出寄存器;
48.sram阵列含有若干个行列阵列排布的sram,一个sram用于存储一位数据,地址译码电路的各个输出端和sram阵列的各行sram连接,写控制电路的各个输出端和sram阵列的各列sram连接,sram阵列的每列sram和对应的一个输入寄存器通过多路选择器mux和数量与每列sram中sram数量相同的多个或非门连接到加法树adder tree的一个输入端口,加法树adder tree的输出端口依次经移位加模块mux and add和量化模块quantization后和输出寄存器连接。
49.一个存算核cim_core实质上完成的是一次矩阵向量积的运算,外部向量即激活通
过端口进来暂存在寄存器中,每个计算周期从sram阵列中读取一行的权重然后和激活进行mac运算,下一个计算周期通过地址端控制读取下一行的权重。
50.其中,sram阵列的每列sram的各个sram输出连接到各自对应的一个或非门的一个输入端,各个或非门的另一个输入端均经同一个多路选择器mux连接到同一个输入寄存器中,或非门的输出端和加法树adder tree的一个输入端口连接。
51.地址译码电路接收地址数据,处理生成数量与sram阵列中行数相同的各路写字线信号wwl、读字线信号rwl和读字线反信号rwlb,每路写字线信号wwl、读字线信号rwl和读字线反信号rwlb输入到sram阵列的一行sram中;
52.写控制电路生成数量与sram阵列中列数相同的各路写位线信号wbl、写位线反信号wblb,每路写位线信号wbl、写位线反信号wblb输入到sram阵列的一列sram中;
53.sram阵列的每个sram根据写字线信号wwl、读字线信号rwl、读字线反信号rwlb、写位线信号wbl、读位线信号rbl、写位线反信号wblb的控制处理输出一位数值到自身对应的或非门中,每个输入寄存器存储多位数值,输入寄存器的多位数值根据多路选择器mux按照顺序选择其中一位数值发送到一个或非门与sram阵列中的一个sram输出的一位数值一起经过或非计算获得一位输出数值,sram阵列的各列中各个sram输出的各位数值经或非门对应获得的各位输出数值按照列中各个sram顺序连接成多位阵列数值,多位数值的位数和sram阵列的列数一致,多位阵列数值输入到加法树adder tree的一个输入端口;
54.加法树adder tree的输出端口输出sram阵列的所有多位阵列数值进行排布后通过移位加模块mux and add移位相加处理后获得一个位数和sram阵列的列数一致的多位移位后数值,再将多位移位后数值通过量化模块quantization处理取多位移位后数值其中的连续多位输出存储到输出寄存器中。
55.sram阵列的每个sram根据写字线信号wwl、读字线信号rwl、读字线反信号rwlb、写位线信号wbl、读位线信号rbl、写位线反信号wblb的控制处理输出一位数值具体为:
56.写字线信号wwl、写位线信号wbl和写位线反信号wblb用于控制sram阵列的写操作。当某一行的写字线信号wwl为1时,可以对该行的所有sram单元进行写操作。写入的权值由该sram单元的写位线信号wbl和写位线反信号wblb共同决定。
57.读字线信号rwl、读字线反信号rwlb和读位线信号rbl用于控制sram阵列的读操作。当某一行的读字线信号rwl为1且读字线反信号rwlb为0时,可以对该行的所有sram单元进行读操作。读出的权值通过每个sram单元的读位线信号rbl读出并送出sram阵列。
58.如图3所示,每个sram主要由10个mos管构成,mos管m0、mos管m5和mos管m8的栅极均和写字线信号wwl连接,mos管m0源极和写位线信号wbl连接,mos管m0、mos管m1和mos管m2的漏极以及mos管m3和mos管m4的栅极连接到一起,mos管m1、mos管m3和mos管m6的源极接电压,mos管m2、mos管m4和mos管m7的源极接地,mos管m5、mos管m3和mos管m4的漏极以及mos管m1、mos管m2、mos管m6、mos管m7的栅极连接到一起,mos管m5源极和写位线反信号wblb连接,mos管m6~mos管m9的漏极连接到一起,mos管m8和mos管m9的源极均连接到一起后再和读位线信号rbl连接,mos管m8栅极和读字线信号rwl连接,mos管m9栅极和读字线反信号rwlb连接。
59.sram阵列由基本的10t结构组成,t表示mos管,与传统6t的sram相比额外增加了一个反相器和一个传输门,具体的电路结构如图3所示。
60.本发明10t sram结构与基本的6t结构相比,通过反相器能隔绝内部存储结点和读取路径。这种结构能将读位线信号rbl进行充分地充放电,这样可以不需要额外的预充电电路。对于读位线信号rbl上消耗的动态功耗,只有当读取的数据改变时才会存在。换句话说,这种结构在读取恒
‘0’
或者恒
‘1’
的数据时,读位线信号rbl上不存在动态功耗的损失。
61.如图4所示,方案一:加法树adder tree是由多个行波进位加法器rca构成,加法树adder tree从自身的每个输入端口接收一个多位阵列数值,将各个输入端口接收的各个多位阵列数值作为多位数值按照输入端口顺序对齐排序,通过行波进位加法器rca进行多次进位加法处理,获得最终的一个多位数值:
62.每次进位加法处理中,是将当前所有多位数值以每相邻两个多位数值组成一组通过一个行波进位加法器rca进行相加处理获得一个多位数值;若当前所有多位数值的数量是奇数,则余下的一个多位数值在当前次进位加法处理不处理,而直接传递到下一次进位加法处理。
63.上述方案一是以行波进位加法器构建加法树,每一级用到的行波进位加法器的进位链都比上一级的进位链深1位,它最明显的优势就是结构比较规整简洁。
64.如图5所示,方案二:加法树是由多个进位保留加法器csa、多个半加器ha和一个行波进位加法器rca构成,
65.加法树adder tree从自身的每个输入端口接收一个多位阵列数值,将各个输入端口接收的各个多位阵列数值作为多位数值按照输入端口顺序对齐排序,通过进位保留加法器csa和半加器ha的结合进行多次进位加法处理,直到多位数值的数量仅为两个:
66.每次进位加法处理中,是针对每一位作为处理位进行遍历,先将处理位下的每连续三个数值组成一组通过一个进位保留加法器csa进行相加处理获得一个处于处理位原位的数值和一个处于处理位进一位的数值;若用进位保留加法器csa处理后在处理位余下两个数值,则针对该两个数值采用半加器ha进行相加处理获得一个处于处理位原位的数值和一个处于处理位进一位的数值;若用进位保留加法器csa处理后在处理位余下一个数值,则该数值在当前次进位加法处理不处理,而直接传递到下一次进位加法处理;
67.在多位数值的数量仅为两个之后,采用行波进位加法器rca对两个多位数值进行相加处理获得最终的一个多位数值。
68.上述方案二是以wallace树构建乘法器的思路来构建加法树。采用csa进位保留加法器作为基本的构建单元,事实上一个csa其实就是一个全加器,只是在使用的过程中不将两个相邻的全加器做级联。
69.移位加模块mux and add移位相加处理,具体是将加法树adder tree输出的多位数值进行移位和累加,获得最终的未量化前的结果。移位的多少取决于之前通过多路选择器mux选择的输入寄存器的哪一位,最低位则不用移位,低1位则左移一位之后再累加,依此类推。
70.如图6所示,存算fpga架构用于全连接层的运算,是将全连接层中的一个全连接因子中的各个权重按顺序分别分配到一个存算核cim core同一行sram的各个sram中,全连接层中的不同全连接因子的权重分配到不同行sram中,每个输入寄存器预先存储输入特征图的一个8b数据。
71.如图7所示,存算fpga架构用于卷积层的运算,是将卷积层中的一个卷积核中同一
位置的所有输入通道的权重按顺序分别分配到一个存算核cim_core同一行的连续多个sram中,对卷积层中的一个卷积核中不同位置进行遍历,且将卷积层中的一个卷积核中所有位置的所有输入通道的权重均分配到若干个存算核cim_core的同一行sram中;对于输入特征图,按照卷积核滑动遍历,以卷积核所遍历的输入特征图中的同一位置的所有输入通道的激活按顺序分别分配到各个输入寄存器中,每个输入寄存器存储一个8b激活。
72.如图8所示,存算核cim_core中同一行sram的输出结果还需要经过累加器进行累加,再通过量化模块进行量化处理,同一列的存算核共用输入向量的值。此处的累加器的累加和量化模块的量化均可以在逻辑功能块clb中实现,将存算核cim_core中同一行sram的输出结果传递到逻辑功能块clb中完成。
73.对于存算核的分配与网络映射,以全连接层和卷积层为例子进行说明。上面提到设计的存算核实质上完成的是矩阵向量积运算,进行映射的过程,实质上就是将某层网络转换成矩阵向量积的过程。
74.如图6所示,是一个输入通道数为8、输出通道数为4的全连接层,按照图片所示的形式将输入激活展开成向量,权重展开成权重矩阵,选择的存储策略是将每个全连接因子的所有通道的值存放在一行中,不同的全连接因子存放在不同行中。事实上全连接层可以视为特殊的卷积层,输入特征图为1x1xic,输出特征图的大小为1x1xoc,卷积核的大小为1x1xic,卷积核的个数为oc个。对于用存算来完成神经网络的映射,其实是一种weight-stationary的数据流设计。卷积核的数据全部存放在存算核cim_core中,但是每个存算核cim_core所支持的最大输入通道数和输出通道数是一定的,对于不同大小的全连接层所需要的权重矩阵大小和每个存算核cim_core的尺寸共同决定分配存算核cim_core的数量,分配过程如图8所示。根据图8的权重矩阵的尺寸决定w_num与h_num的大小,w_num与h_num和单个存算核cim_core所支持的最大输入通道数与输出通道数共同决定该层网络所需要的存算核cim_core的个数。同一行的存算核cim_core的输出结果还需要经过累加器进行累加,同一列的存算核cim_core共用输入向量的值。
75.卷积层与全连接层相比,权重矩阵的映射方法基本一致,所不同的是,它的输入不是向量而是矩阵,矩阵的值需要经过im2col变换得到,图7为卷积层的映射示意图。该图示意了一个5x5x3的输入特征图,卷积核为3x3,卷积核个数为3,步长为1的映射变换过程。经过变换后,由于存算核cim_core只支持矩阵向量积,所以还需要将输入矩阵按一定的时序依次送入到分配的存算核cim_core当中。
76.本发明的具体实施例如下:
77.为了进一步说明提出的存算fpga架构的优势,将同样大小的一个网络64x64的全连接层(输入通道数为64,输出通道数为64),分别映射到的存算fpga架构上和一般的fpga架构上,然后进行布局布线,并最后在同样的时钟频率下(100mhz)测试两者的功耗。存算核cim_core设置的阵列尺寸为64x256。最后的映射结果分别如图9、图10所示。图9和图10中输入输出模块iob分布在fpga架构的外围。逻辑功能块clb分布在fpga架构的内部大小为1x1,存储块bram分布在fpga架构的内部大小为1x6。与图10不同的是,图9额外分布着两个存算核cim_core大小为2x3。
78.图11和图12分别为使用存算fpga架构和一般fpga架构的功率报告图,通过对比可知使用存算fpga架构的功耗只有10.99mw而使用一般存算fpga架构的功耗有22.01mw。即对
于一个相同大小的网络进行映射功耗差距就相差一倍多。
79.经过上述一个简单的网络的对比测试,进一步验证了提出的存算fpga架构的优势。使用存内计算技术,减少数据的搬移,可以降低设计的功耗,同时在fpga上实现网络的映射,利用fpga的可重构性能快速地支持各种大小的网络。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1