用于速率兼容低密度奇偶校验码族的解码器的制作方法
本发明属于数字数据的编码和解码领域。特别地,本发明涉及用于对速率兼容奇偶校验码族进行解码的解码器、以及相应的解码方法。
背景技术
r.g.gallager在1963年麻萨诸塞州剑桥市麻省理工学院出版社的“低密度奇偶校验码”(low-densityparity-checkcodes,mitpress,cambridge,ma,1963)中介绍的低密度奇偶校验(ldpc)码是具有稀疏奇偶校验矩阵的线性码。事实证明,它们在所有通信领域都具有可管理复杂性的优异性能,并且也被视为应用于光纤通信中,如ieee光子技术快报第14卷第1208-1210、2002页的b.vasic和ibdjordjevic的“用于长距离光学通信系统的低密度奇偶校验码”(“low-densityparitycheckcodesforlong-haulopticalcommunicationsystems”,ieeephotonicstechnologyletters,vol.14,pp.1208-1210,2002)中描述。
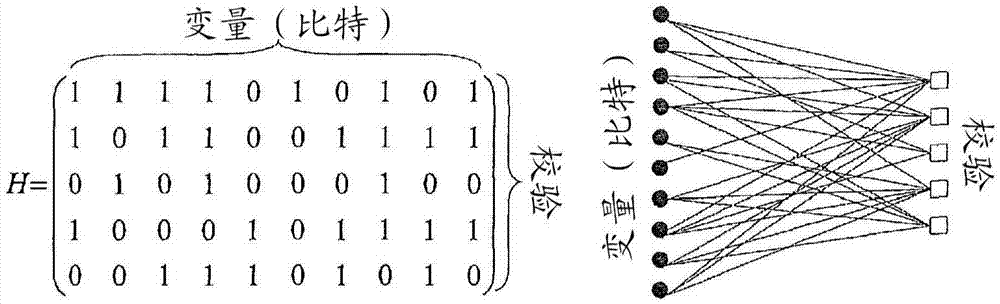
ldpc码可以由稀疏二分图表示,其左和右节点通常分别对应于码变量(比特)和校验方程。每个校验节点通过相应的边连接到两个或更多个变量节点。奇偶校验矩阵是二分图的邻接矩阵。注意,在本公开中,术语“邻接矩阵”和“奇偶校验矩阵”同义使用。图1说明了非常简单的码的奇偶校验矩阵(邻接矩阵)和二分图之间的关系。如图1所示,邻接矩阵的列表示变量节点,行表示校验节点,条目“1”分别表示连接相应列和行的变量节点和校验节点的边。
ldpc码可以通过置信传播(bp)方便地解码:节点沿着二分图的边迭代地交换消息。从变量v到校验c的消息和从c到v的消息都表示在考虑到信道值和在先前解码轮次中传递的某些消息的知识的情况下v为0或1的概率。“信道值”可以是表示比特值的发送信号的任何物理量,例如,在一个简单的例子中,电压可以高于某个阈值以表示“1”并且低于某个阈值以表示“0”。高于但接近这样的阈值的信道值(电压)将指示变量确实为“1”的较小概率,而明显高于阈值的电压将指示变量确实为“1”的更高概率。
虽然bp的功能不如例如最大后验(map)解码,但它具有以下优点:由于图的稀疏性,其复杂度仅在码大小上是线性的,并且其性能在实践中实际上是优秀的。已经表明,在多个通信信道上,能够构造ldpc码的系综,其在bp下的性能非常接近香农极限,如由t.richardson和r.urbanke在ieee信息论汇刊2001年第47卷第599-618页的“低密度奇偶校验码在消息传递解码下的能力”(“thecapacityoflow-densityparity-checkcodesundermessage-passingdecoding”,ieeetransactionsoninformationtheoryin2001,vol.47,pages599-618)中所描述以及如由t.richardson,m.shokrollahi和r.urbanke在ieee信息论汇刊2001年第47卷第619-637页的“容量接近不规则低密度奇偶校验码的设计”(“designofcapacity-approachingirregularlow-densityparity-checkcodes”,ieeetransactionsoninformationtheory,2001,vol.47,pages619-637)中所描述。
在构建ldpc码的许多可能方法中,一种强有力的方法是使用所谓的原型图(protograph)码,其由j.thorpe在2003年8月15日ipn进展报告42-154页的“从原型图构建的低密度奇偶校验(ldpc)码”(“low-densityparity-check(ldpc)codesconstructedfromprotographs”,ipnprogressreport42-154,august15,2003)中介绍。thorpe的程序包括通过以下两步复制和置换操作来对名为“原型图”的通常很小的模板图进行扩展:
1.复制原型图q次,然后
2.置换边的端点以互连副本。
在第一步之后,对于原型图的每个节点,获得q个同源节点。在第二步中,边的端点在每类同源节点内进行置换。这种在图论中被称为“提升”的结构保证了通常称为系综阈值的ldpc系综的渐近(即,对于无约束的码长度)纠错能力完全由原型图单独确定。
在其原始公式中,bp算法根据两阶段洪泛计划实施:在每次迭代时,在第一阶段期间,使用先前生成的变量至校验(variable-to-check)消息来计算所有变量至校验消息,并且在第二阶段,使用先前生成的变量至校验消息来计算所有校验至变量消息。尽管该调度具有理论上的重要性,但在实践中,对于给定数量的解码迭代,所有消息的同时计算和传播不会导致最佳可能的纠错能力。
相反,在本领域中众所周知,顺序调度可以胜过洪泛调度,因为在每个节点它们都使用最新的可用传入消息来计算新的传出消息。出于这个原因,顺序调度通常是本领域中优选的。然而,为了允许顺序调度的至少部分并行实现,提出了特殊的ldpc构造,其中奇偶校验矩阵具有块结构,该块结构具有构成子矩阵,所述构成子矩阵是大小为q×q的置换矩阵或零矩阵。由于置换矩阵每列和每行只有一个“1”,所以置换中涉及的每个q节点(变量或校验)因此在相同的置换群中恰好连接到另一个节点(校验,或分别地,变量)。这意味着没有两个变量(校验)可以有助于更新相同的校验(分别地,变量),因此可以同时处理置换群中的所有q个变量(校验)而不放弃顺序调度。所述构成置换子矩阵的大小q对应于仍然严格的顺序调度的最大并行度。如果置换矩阵被限制为表示循环置换,则获得特别硬件友好的实现。所得到的ldpc码被称为准循环(qc),并且已经(例如)由m.fossorier在ieee信息论汇刊2004年第50卷第1788-1793页的“来自循环置换矩阵的准循环低密度奇偶校验码”(“quasi-cycliclow-densityparity-checkcodesfromcirculantpermutationmatrices”,ieeetrans-actionsoninformationtheoryin2004,vol.50,pages1788-1793)中研究过。
在文献中已经描述了几个顺序调度。第一组基于校验节点更新的顺序:在每一轮中,一组q个独立的校验至变量消息被计算并用于更新变量节点的概率。这种方法的一些变体,例如由e.yeo,p.pakzad,b.nikolic和v.anantharam在2001年11月德克萨斯州圣安东尼奥市2001全球通信会议记录第3019-3024页的“高通量低密度奇偶校验解码器架构”(“high-throughputlow-densityparity-checkdecoderarchitectures”,proceedingsofthe2001globalconferenceoncommunications,sanantonio,tx,pages3019-3024,november2001)中描述并由m.munour和n.shanbhag在ieee最大规模集成(vlsi)系统汇刊2003年12月第11卷第6期第976-996页的“高通量ldpc解码器”(“high-throughputldpcdecoders”,ieeetransactionsonverylargescaleintegration(vlsi)systems,vol.11,no.6,pp.976-996,december2003)中描述并由d.e.hocevar在2004年ieee信号处理系统研讨会(sips)记录第107-112页的“通过分层解码ldpc码降低复杂度的解码器架构”(“areducedcomplexitydecoderarchitecturevialayereddecodingofldpccodes”,proceedingsoftheieeeworkshoponsignalprocessingsystems(sips),pages107-112,2004)中描述。
另一类型的顺序调度是基于变量节点更新的。在每一轮中,一组q个独立的变量至校验消息被计算并用于更新校验节点的概率。这种方法已经例如由j.zhang和m.fossorier在公布于2002年第36届关于信号、系统和计算机的阿西洛马会议的会议记录第8-15页的“重组的置信传播解码”(“shuffledbeliefpropagationdecoding”,publishedonconferencerecordofthethirty-sixthasi-lomarconferenceonsignals,systemsandcomputers,pages8-15,2002)中描述。
在信息理论中,纠错码的速率表示信息比特与包括冗余比特的总比特数的比例。码率与“码开销”有关,“码开销”是光学社区中更常见的术语,表示冗余比特与信息比特的比例。即,如果码为每k个信息比特生成n个比特,则其速率为r=k/n,并且其开销为oh=(n-k)/k=1/r-1。
在几种通信系统中,编解码器需要支持多种码率,例如,以适应实际信道条件或实现混合自动重传请求(harq)。为此,已经开发了速率兼容码族,它们都可以由单个引擎编码和解码。最常见的解决方案包括如由j.hagenauer针对卷积码的情况在ieee通信汇刊1988年4月第36卷第4期第389-400页的“速率兼容的打孔卷积码(rcpc码)及其应用”(“rate-compatiblepuncturedconvolutionalcodes(rcpccodes)andtheirapplications”,ieeetransactionsoncommunications,volume36,number4,pages389-400,april1988)中描述的对母码进行打孔。
在ieee通信汇刊2012年10月第60卷第10期第2841-2850页的文章“速率兼容的原型图ldpc码的设计”(“thedesignofrate-compatibleprotographldpccodes”,ieeetransactionsoncommunica-tions,vol.60,no.10,pp.2841-2850,october2012)中,t.v.nguyen,a.nosratinia和d.divsalar介绍了一种专门为ldpc码设想的替代解决方案。根据他们的方法,通过在几个后续步骤中将基本高速率ldpc码的奇偶校验矩阵扩展相同数量的行和列来构造一族速率兼容的ldpc码。
核心网络的光纤通信的发展对转发器的纯粹吞吐量和灵活性提出了特别苛刻的要求。为了在广泛的链路和信道配置上实现最佳性能,如果编解码器设备支持具有不同码率和纠错能力的多种码,则是有利的。在美国光学学会的光学通信与网络杂志2012年第4卷第760-768页的g.-h.gho和j.m.kahn的“用于光纤传输系统的速率自适应调制和低密度奇偶校验编码”(“rate-adaptivemodulationandlow-densityparity-checkcodingforopticalfibertransmissionsystems”,journalofopticalcommunicationsandnetworking,opticalsocietyofamerica,vol.4,pp.760-768,2012)中,描述了具有自适应编码和调制的可能传输方案。在该出版物中,所使用的ldpc码族是针对用于卫星应用的第二代数字视频广播标准(dvb-s2)而指定的。
然而,遗憾的是,速率兼容码的这些硬件要求,即允许更大开销或者说允许更低码率,是非常苛刻的。事实上,解码器所需的处理速度随着开销而增加,并且通常需要强大的处理器,这增加了硬件成本、电力消耗和操作中的热量产生。结果,目前在光纤传输系统中使用的速率兼容解码器被限制在最多25-30%的开销。
技术实现要素:
本发明要解决的问题是提供一种结合了速率兼容的奇偶校验码族的解码器,该解码器即使在高开销时也允许硬件有效的解码。该问题通过根据权利要求1的解码器以及根据权利要求14的解码方法解决。优选实施方式在从属权利要求中限定。
根据本发明,提供了一种用于解码一族l个速率兼容的奇偶校验码的解码器。该奇偶校验码族包括:
第一码,能够由二分图表示,二分图具有表示变量的变量节点、表示校验方程的校验节点、以及将每个校验节点与两个或更多个变量节点连接起来的边;以及
码率越来越低的l-1个码,其中第i码能够由表示第(i-1)码的二分图增加相同数量的ni个变量节点和校验节点的二分图来表示。这里,所增加的校验节点通过边与第i码中包括的变量节点中的所选变量节点连接,而所增加的变量节点通过边仅与所选择的所增加的校验节点连接,或者换句话说,不与第(i-1)码中已经存在的校验节点连接。
此外,解码器包括l个校验节点处理单元,其中第i校验节点处理单元仅处理超出第(i-1)码在第i码中增加的校验节点,其中对校验节点的处理包括沿着与校验节点连接的二分图的边交换消息,该消息表示相应变量为0或1的概率。l个校验节点处理单元被配置为并行操作。例如,校验节点处理单元可以与相同asic内的单独块相似,但是本发明不限于硬件中的任何特定实现,只要校验节点处理单元能够并行操作即可。
注意,由于多个校验节点处理单元并行操作,因此省去了顺序置信传播(bp)的概念。虽然根据本领域的普遍看法,顺序bp调度优于并行调度,因为它们在任何阶段都使用最新的可用信息来计算新消息,但与现有技术中已知的相比,本发明的码和解码器体系结构的特定组合实际上确实可以实现非常高的性能和更有利的硬件资源使用。令人惊讶的是,尽管所提出的算法不是顺序的,但由于几个原因的相互作用,它在实践中基本上获得了顺序算法的相同性能。首先,它建立在具有最低开销的码的错误纠正能力的基础上,为此它有效地应用顺序调度;其次,由于校验节点处理单元中的并行处理,它增强了在构建码族成员的各种阶段期间增加的校验节点组之间的信息交换,或者换句话说,增强了在下面更详细定义的相应邻接矩阵的“频带”之间的信息交换;最后,它允许轻松优化资源使用,这将从下面的具体示例中变得更加明显。
另一方面,与纯并行调度相反,作为两阶段洪泛调度,所提出的架构允许方便地路由bp消息并避免消息传递解码器中的拥塞问题。
注意,与本发明相反,上面提到的可用顺序调度不被认为是解码通过连续扩展获得的速率兼容码。较高开销码具有更多变量和校验需要处理,但是现有技术码和解码调度仅允许与该族的所有其他码相同的最大并行度q,其中q与置换子矩阵的大小再次一致。因此,为了获得所需的吞吐量,现有技术的顺序解码引擎的速度必须随着码开销而增长。
这样做的第一个缺点是必须根据最高开销码的处理速度确定引擎的尺寸。这意味着最大可行码开销受到复杂性约束的限制,并且在实践中,难以为高吞吐量应用实现大开销码。
另一个缺点是包括高开销码的族的实现需要大的置换子矩阵以允许高度并行性,并因此导致长码、大延迟和bp消息的复杂路由。最后,具有新的更高开销码的已经设计的码族的扩展(例如用于下一代产品)是困难的,因为最大并行度q不再是自由设计参数且总吞吐量的增加必须完全通过提高处理速度来实现。令人惊讶的是,所有这些问题都可以通过本发明的码族结构和解码器的特定组合来克服。
在优选实施方式中,第i校验节点处理单元被配置为并行处理超出第(i-1)码在第i码中增加的校验节点中的qi个校验节点的子组。注意,在相同码扩展内增加的校验节点,或者换句话说,邻接矩阵的相同“频带”内的校验节点,原则上可以被顺序处理,因为它们由相同的校验节点处理单元处理。如上所述,基于本发明的码的奇偶校验矩阵可以具有块结构,该块结构具有构成子矩阵,构成子矩阵是大小为q×q的置换矩阵或零矩阵,其允许并行处理多达q个校验节点而不放弃顺序调度。因此,qi可以对应于q或者可以被q整除的数并且仍然允许顺序处理。
在优选实施方式中,并行处理的所述子组的大小qi在校验节点处理单元之间不同。换句话说,可以针对不同的校验节点处理单元单独地选择并行度,从而优化硬件资源的使用。例如,通过选择较小尺寸qi的子组,可以采用较小的处理器,因为它仅需要并行处理较少数量的节点。因此,虽然本发明需要使用多个校验节点处理单元,但是各个校验节点处理单元要满足的硬件要求可能不会非常高,并且如果选择足够低的qi,则尤其如此。此外,通过为每个校验节点处理单元单独选择并行度,可以获得理想的调度,例如,从而确保在不同的校验节点处理单元内,所有校验节点在相同或至少几乎相同的时间段内都被处理相同的次数。
在特别优选的实施方式中,在校验节点处理单元中,对于至少一对i,j,以下不等式成立:对于i>j,qi<qj,其中i=2,3,......l且j=1,2,......l-1。换句话说,根据该实施方式,至少一个高阶处理单元(例如,第i校验节点处理单元)以比低阶处理单元之一(例如,第j个校验节点处理单元)更低的并行度qi操作。这意味着仅针对速率自适应码的相应高扩展操作的高阶校验节点处理单元仅需要被配置用于相对低的并行度,并且因此可能仅具有适度的硬件要求,这对于仅偶尔使用(即当需要解码具有较高开销的码时)的处理单元是有利的。
在优选实施方式中,速率兼容解码器还包括存储器,用于为每个变量节点存储与变量为0或1的概率有关的信息。
优选地,每个校验节点处理单元被配置为针对待处理的每个校验节点接收与连接至待处理校验节点的变量节点有关的先验概率,并根据相关的校验方程计算更新的变量概率。
此外,速率兼容解码器优选地包括组合器,用于组合由不同校验节点处理单元并行确定的相同变量节点的更新的变量概率。
在优选实施方式中,奇偶校验码族可以由邻接矩阵表示,其中邻接矩阵的列表示变量节点,邻接矩阵的行表示校验节点,元素“1”表示分别连接相应列和行的变量节点和校验节点的边。这里,邻接矩阵包括q×q个子矩阵组成,其中该q×q个子矩阵是置换矩阵或零矩阵。如上所述,该结构允许处理在相同码扩展内增加的多达q个校验节点,而不会在这部分处理中放弃顺序调度。
在优选实施方式中,所述子矩阵的大小q是由第i节点处理单元并行处理的校验节点的子组数量qi的整数倍,并且其中并行处理的校验节点的子组属于q×q子矩阵的相同行。
在优选实施方式中,第l码的码率为60%或更小,优选为55%或更小,更优选为50%或更小。这种低码率,或者换句话说,这种高码开销,对于现有技术的解码器来说非常难以处理,但是可以利用本发明的解码器和解码方法很好地实现。
优选地,连接到第l码中增加的校验节点的平均边数和/或连接到在第(l-1)码中增加的校验节点的平均边数小于连接到第一码的校验节点的平均边数。换句话说,码的第二高的扩展中的一个或两个是这样一种扩展,其具有连接到增加的校验节点的相对较少的边,这意味着将由相应的最高和/或第二高阶校验节点处理单元执行的计算工作量比较轻微。
在优选实施方式中,解码器用于解码通过光数据传输发送的数据信号。由于光纤通信的特征在于非常高的数据速率,因此用于速率兼容码的解码器的实现特别困难,并且本发明提供的益处特别高。
附图说明
图1示出了邻接矩阵和由邻接矩阵表示的低密度奇偶校验码的二分图。
图2示出了码率越来越低的一族码中的第四码的邻接矩阵。
图3示出了如图2中所示的同一族速率兼容ldpc码的调度参数表。
图4示出了如图2中所示的同一族速率兼容ldpc码的可替换调度参数表。
图5示出了用于解码一族四个奇偶校验码的速率兼容解码器的示意图。
图6示出了总结在前六个操作轮次中由图5的解码器的每个校验节点处理单元处理的块行的表格。
具体实施方式
为了促进对本发明原理的理解,现在将参考附图中所示的优选实施方式,并且将使用特定语言来描述它们。然而,应该理解的是,本发明的范围不由此受限,对于本发明所涉及领域的技术人员来说,在所示的装置中的这种改变和进一步的修改以及如文中所示的本发明的原理的这种进一步的应用被认为是现在或者未来通常会发生的。
本发明的各种实施方式涉及用于解码一族l个速率兼容奇偶校验码的解码器和编码调度。该奇偶校验码族包括可由二分图表示的第一码,二分图具有表示变量的变量节点、表示校验方程的校验节点、以及将每个校验节点与两个或更多个变量节点连接的边。该奇偶校验码族还包括码率越来越低的l-1个码,其中第i码能够由表示第(i-1)码的二分图增加相同数量的ni个变量节点和校验节点的二分图来表示。这里,所增加的校验节点经由边连接至第i码中所包含的变量节点中的所选变量节点,即在第i码的生成中增加的变量节点或已经存在于任何前体码中的变量节点,而所增加的变量节点经由边仅连接至所选的被增加的校验节点,即第(i-1)码中不存在的校验节点。
为了更好地说明待由本发明的解码器解码的奇偶校验码族的结构,在图2中,示出了包括码率越来越低的l=4个码的码族的第四或最低码率码的相应邻接矩阵或奇偶校验矩阵。同样,邻接矩阵的列表示变量节点,而行表示校验节点。矩阵包括9×13个大小为q×q的块或子矩阵。包含在这个9×13个块的矩阵中,在左上角是3×7个块的矩阵,它代表码族中的第一码的邻接矩阵。通过将第一码扩展n2=2·q个变量节点和校验节点来获得码族中的第二码,使得代表第二码的矩阵包括5×9个块。该5×9块矩阵同样包括在图2的矩阵中。注意,在将3×7块矩阵扩展到5×9块矩阵时,在新块列的前三个块行中仅增加零矩阵,这意味着所增加的变量节点确实仅与所增加的校验节点连接,但不与第一码中已包含的校验节点连接。然而,增加的校验节点可以经由边与增加的变量节点和已经包括在第一码中的变量节点连接。
类似地,通过将第二码的邻接矩阵扩展n3=3·q个变量节点和校验节点,可以获得与码族内的第三码对应的邻接矩阵,使得表示第三码的矩阵包括8×12个块,然后通过将第三码的邻接矩阵扩展n4=q个变量节点和校验节点来获得对应于如图2所示的该族内的第四码的邻接矩阵,使得表示第四码的该矩阵如图2所示获取9×13个块的大小。
如图2所示,通过连续扩展而获得的一族l个速率兼容ldpc码的奇偶校验或邻接矩阵可在l个水平频带中自然地分解,所述l个水平频带与在从第(i-1)码生成第i码时增加的ni个校验节点组相对应。解码第一或最高码率码因此等于单独处理顶部频带,并且解码该族的第i码(i=1,2,...,l)意味着处理校验变量的前(从顶部)i个频带。
如在图2中进一步看到的,码族的每个奇偶校验矩阵都具有块结构,并且其构成q×q子矩阵是置换矩阵或零矩阵。这引起子矩阵的行(或者简称为q比特宽的“块行”)中的每个频带的更精细划分。以相同的方式,自然地引入q比特宽的“块列”。具有这种块结构的矩阵可以例如通过说明书的前言部分中描述的提升过程从原型图邻接矩阵获得。
我们用ml表示第l个频带(l=1,2,...,l)中的块行数。在图2的示例中,l等于4并且频带分别包括m1=3,m2=2,m3=3和m4=1块行。由于奇偶校验矩阵的结构,每个频带内的顺序处理的最大并行度是q。所提出的解码器在每一轮处理第l个频带(l=1,2,...,l)内的q1个独立校验节点,其中q可整除q1。因此,处理第l个频带的块行需要进行pl=q/ql轮并且处理整个第l个频带一次需要pl·ml轮。
为了解码第i码(i=1,2,...,l),本发明的解码器同时处理前i个频带。通常,由于属于不同块行的校验节点不是独立的,并且因为根据本发明不同频带的块行被同时处理,所以算法不实现顺序调度。相反,调度仅在各个频带内是连续的,这就是为什么在此可以将其称为“频带顺序”的原因。
此外,第l个频带(l=1,2,...,l)被处理最大数量ni,l次,这可以取决于码索引i。如果满足所有校验方程,则整个解码算法可被停止,这减少了有效执行的解码步骤的数量。如果不满足停止标准,则第i码的整个解码过程需要ri=max(ni,l·pl·ml)轮来完成。根据该调度,i个频带以不同的速度独立处理,并且解码迭代的常规概念不适用。
在优选实施方式中,所有频带都需要相同的处理时间,即ni,l·pl·ml与l无关。此条件可确保全时利用所有处理资源并避免空闲周期。在提议的调度的框架内,这可以通过设计参数pl和ni,l的多个选择来实现。参考图2所示的族的第四码,在图3的表中描述了第一个可能的选择:在这种情况下,并行度对于所有频带都是恒定的,并且四个频带中的校验节点被处理不同次数。第二种可能性在图4的表格中示出:这里,每个频带都使用其各自的并行度,并且所有校验节点被处理相同的次数。这两种解决方案对应于性能和复杂性之间的不同权衡。
图5示出了根据本发明实施方式的用于一族四个速率兼容码的解码器10的架构。变量(比特)为0或1的概率优选地表示为对数似然比(llr),如由j.hagenauer,e.grom和l.papke在ieee信息论汇刊1996年第42卷第429-445页的“二进制块和卷积码的迭代解码”(“iterativedecodingofbinaryblockandconvolutionalcodes”,ieeetransactionsoninformationtheory,vol.42,pages429-445,1996)中所述。
对应于后验概率(app)的llr存储在中央存储器12中。所有变量的信道值表示算法的输入并且在解码过程开始时用于初始化中央储存器或存储器12。在每一轮,appllr根据bp算法更新并因此考虑与二分图的逐渐变大的部分相对应的码约束。在预定义的最大轮数之后,或者一旦满足所有校验方程,就终止解码过程,并输出储存器的内容,其传达每个比特为0或1的最终估计概率。
llr更新由合适的校验节点处理器(cnp)14计算为校验至变量消息。cnp14的数量等于所考虑的码族的成员数量,或者等效地,整体奇偶校验或邻接矩阵中的频带数量。为了处理具有第i最低开销(包括图2的奇偶校验矩阵中的最顶部的i个频带)的码,仅使用i个cnp,而其他cnp保持空闲以节省功率。因此,并行度的有效程度随着码开销和校验节点的数量而增长,而各个处理器的速度保持不变。
对于每个校验变量对,cnp14跟踪最后计算的校验至变量消息。在初始化阶段,所有校验至变量消息都将被重置。在每一轮中,存储的校验至变量消息用于“外化(extrinsicate)”app-llr,如下所述。
如图5中进一步所示,提供选择器块16,其向每个cnp14转发与处理的块行中涉及的块列的子集相对应的app-llr。在进入第l个cnp14之前,根据奇偶校验矩阵的各个置换子矩阵,由π1置换块18置换appllr。在cnp块14内,当处理校验c时,每个所涉及的变量v的appllr从c到v减少校验至节点(check-to-node)消息,该消息先前被计算并存储在cnp14中。该操作在文献中称为“外化”并且用于避免使输入信息再循环。cnp14的输出是从ql个被处理校验到每个所涉及变量的增量消息的集合并且表示在当前轮次获得的附加信息。该消息集合可以例如根据由x.-y.hu,e.eleftheriou,d.-m.arnold和a.dholakia在2001年1月globecomieee全球电信会议“用于解码ldpc码的和积算法的高效实现”(“efficientimplementationsofthesum-productalgorithmfordecodingldpccodes”,ieeeglobaltelecommunicationsconference,globecom'01,2001)中描述的方法来计算。第l个cnp14的输出在逆置换块20中经历了逆变换πl-1,其恢复原始秩。由cnp14同时产生的校验至节点消息在组合器块22中组合,该组合相当于根据llr算术的求和,并且被增加到中央存储器12中的appllr。
出于说明的目的,应考虑根据图4的调度来解码图2中所示的族的第四码。图6中所示的表报告了在前6轮调度期间由每个cnp14处理的块行的索引。在轮次1和2期间,cnp14集合中的cnp1处理奇偶校验矩阵的块行0。选择器16将块列1,2,3,4,5,6中变量的appllr转发到置换块π1,置换块π1将置换π0,1,π0,2,π0,3,π0,4,π0,5,π0,6分别应用至每个llr块。cnp1产生的校验至变量消息在到达组合器之前经历逆置换π0,1-1,π0,2-1,π0,3-1,π0,4-1,π0,5-1。其他频段以类似的方式处理。例如,cnp4在第1-6轮的整个持续时间期间处理块行8。所涉及的块列的索引是2,7和12,并且相应的置换是π8,2,π8,7,π8,12。可以重复所描述的6轮序列,直到实现期望的解码性能。
由每个cnp14计算的消息适用于不同的变量节点。然而,由不同cnp计算的消息可以指代同一组变量,因此在存储在appllr存储器中之前必须在组合器块22中求和。
在图2的示例中,密度,即奇偶校验矩阵中的非零元素的比例在频带上变化很大。由于在bp算法中计算和交换的消息数量与二分图中的边数量成比例,因此解码较低密度的频带需要较少的资源。在所示的示例中,cnp4比cnp1消耗更少的资源,因为它在奇偶校验矩阵的较低密度区域上操作并且具有较高的并行度(p1=2,p4=6,如表2所示)。因此,利用所提出的体系结构,与标准顺序体系结构相反,在额外需要的资源方面,在给定码族中包括高开销码可以是非常便宜的。
所公开的体系结构和相关的调度被明确地设想为解码由连续扩展构造的速率兼容的ldpc码族。解码器10包括若干功能单元、cnp14和置换块18,20,它们专用于处理奇偶校验矩阵的特定区域,该区域在文中称为“频带”。一方面,这允许并行度随着码开销自然增长;另一方面,使用专门定制的解码设备10可以实现显着的复杂性节省。特别是,并行度和所分配的资源可以根据每个频带的宽度和密度单独优化。
虽然根据本领域的普通技术,顺序bp调度通常被认为提供比并行调度更好的性能,因为它们在任何阶段都使用最新的可用信息来计算新消息,与此共识相反,本发明采用了并行的调度。令人惊讶的是,尽管所提出的算法不是顺序的,但它在实践中基本上获得了与顺序算法相同的性能,这由发明人归因于几个原因。首先,它建立在具有最低开销的码的纠错能力的基础上,为此它有效地应用顺序调度;第二,由于并行cnp14,它增强了不同频段之间的信息交换;最后,它优化了资源使用。另一方面,与纯粹的并行调度相比,作为两阶段洪泛调度,所提出的架构允许方便地路由bp消息并避免消息传递解码器中的可怕拥塞问题。
尽管在附图和前面的说明书中详细示出和指定了优选的示例性实施方式,但是这些应当被视为纯粹示例性的而不是对本发明的限制。在这方面应注意,仅示出和指定了优选的示例性实施方式,并且应当保护所有的变化和修改,这些变化和修改目前或将来都在权利要求所限定的本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!