一种基于双递归的分组马尔可夫叠加编码方法与流程
本发明涉及数字通信和数字存储技术领域,特别涉及一种基于双递归的分组马尔可夫叠加编码方法。
背景技术:
通信和存储系统的数据会受到噪声的影响而出现错误,导致数据不能正确接收或不能正确恢复。随着个人数据和存储需求的日益上升,通信和存储系统中的数据可靠性越来越受到人们的重视。为实现高效可靠的数据传输和数据存储,有必要设计可逼近信道容量且具备高效编译码算法的信道编码。自从Shannon于1948年提出了著名的信道编码定理,人们一直致力于研究和设计可逼近信道容量的好码。1993年,Berrou等人提出了Turbo码,该码在迭代译码算法下可逼近信道容量。Turbo码的提出是信道编码领域的重要里程碑,开启了现代编码。在Turbo码发明之后,人们提出了更多可逼近信道容量的好码。低密度奇偶校验码(Low-Density Parity-Check code,LDPC code),极化码和空间耦合LDPC码都是可逼近香农限的好码。
分组马尔可夫叠加编码[1]也是一类可逼近信道容量的好码。分组马尔可夫叠加编码是一种由短码构造大卷积码的编码方法,其中的短码称为基本码。分组马尔可夫叠加编码可视为一种级联码,其外码是短码(这里称为基本码),内码是码率为1的非递归卷积码(其编码输入信息为数据块)。分组马尔可夫叠加编码有简单的编码算法。采用简单的重复码和奇偶校验码作为基本码,分组马尔科夫叠加编码可以通过分时来实现多码率的编码[2]。分组马尔可夫叠加编码可以采用一种基于软信息的滑窗迭代译码算法来译码,并通过选择一个合适的译码延迟d来获得好的错误性能。以上提及的分组马尔可夫叠加编码方法为非递归的,其有诸多优点。但是非递归的分组马尔可夫叠加编码方法存在如下问题:当以重复码和奇偶校验码作为基本码时,需要很大的编码记忆长度m才可有效逼近信道容量,而记忆长度m越大,所需的译码延迟d越大,相应的译码复杂度和译码延迟均越高。因此,在需要极低延迟和极低运算复杂度通信和存储系统中不能采用非递归的分组马尔可夫叠加编码方法。在Turbo码中,为获得好的输入输出分布,需要选择递归卷积码作为分量码。在多层级联码中,相对采用非递归的卷积码的情况,递归的卷积码需要更少的级联阶数来将轻重量的输入序列映射成重量随长度线性增加的输出序列。
[1]中山大学,一种分组马尔可夫叠加编码方法[P]:CN105152060A.
[2]中山大学,一种基于分时的分组马尔可夫叠加编码的多码率码编码方法[P]:CN104410428A.
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提供一种基于双递归的分组马尔可夫叠加编码方法,具有编码简单、译码复杂度低、可逼近信道容量等优点,与传统的分组马尔可夫叠加编码方法相比,本发明有更低的译码复杂度和更低的译码错误平层。
本发明的目的通过以下的技术方案实现:
一种基于双递归的分组马尔可夫叠加编码方法,以码长为n,信息位长度为k的码C[n,k]作为基本码,将长度为kL的信息序列u编码成长度为n(L+T)的码字c;其中L为耦合长度,代表长度为k的等长分组的数量,T为结尾长度;L,T取值为非负的整数;所述编码方法包括以下步骤:
步骤一、将长度为kL的信息序列u划分为L个等长分组u=(u(0),u(1),…,u(L-1)),每个分组长度为k;对于时刻t=-1,-2,…,-m1,把长度为n的序列w1(t)初始化设置为全零序列;对于时刻t=-1,-2,…,-m2,把长度为n的序列w2(t)初始化设置为全零序列;其中m1为第一编码记忆长度,m2为第二编码记忆长度,m1和m2取值为非负的整数;
步骤二、在t=0,1,…,L-1时刻,将长度为k的序列送入基本码C[n,k]的编码器ENC进行编码,得到长度为n的编码序列并结合序列w1(t-i)和计算码字c的第t个子序列c(t);所述的v(t)结合w1(t-i)和计算码字c的第t个子序列c(t),按如下步骤进行:
首先,对于1≤i≤m1,将序列w1(t-i)送入交织器Πi,得到交织后长度为n的序列x1(t-i);对于m1+1≤i≤m1+m2,将序列送入交织器Πi,得到交织后长度为n的序列
然后,将所述序列v(t)和所述序列x1(t-i)送入第一逐符号混叠器S1,得到长度为n的序列w1(t);
最后,将所述序列w1(t)和所述序列送入第二逐符号混叠器S2,得到长度为n的序列c(t)和w2(t),其中c(t)=w2(t);
步骤三、在t=L,L+1,…,L+T-1时刻,将长度为k的全零序列u(t)=0送入基本码的编码器ENC,得到长度为n的全零序列v(t),并结合w1(t-i),和,计算码字c的第t个子序列c(t);所述的结合w1(t-i)和计算码字c的第t个子序列c(t)的方法按照所述步骤二中“所述的v(t)结合w1(t-i)和计算码字c的第t个子序列c(t)”步骤进行。
特别地,在本发明中,当i取值1≤i≤m1时,序列w1(t-i)表示以下各序列w1(t-1),w1(t-2),...,序列x1(t-i)表示以下各序列x1(t-1),x1(t-2),...,;当i取值m1+1≤i≤m1+m2时,序列表示以下各序列w2(t-1),w2(t-2),...,;序列表示以下序列各x2(t-1),x2(t-2),...,。
优选的,所述的编码方法中,信息序列u是二元序列或多元序列。编码器ENC是任意类型的编码器。交织器Πi是任意类型的交织器。
优选的,所述的编码方法中,若序列v(t),w1(t-i)和是有限域上的长度为n的序列,则第一逐符号混叠器S1和第二逐符号混叠器S2是逐符号有限域加权和运算器,第一逐符号混叠器S1的功能如下:输出长度为n的序列w1(t),w1(t)的第j个分量其中,和分别是v(t)和x1(t-i)的第j个分量,是取自有限域的m1+1个域元素,为二元或多元符号,加法运算和乘法运算按有限域运算法则运算;第一逐符号混叠器S2功能如下:输出长度为n的序列c(t),c(t)的第j个分量其中,和分别是w1(t),x2(t-i)的第j个分量,是取自有限域的m2+1个域元素,为二元或多元符号,加法运算和乘法运算按有限域运算法则运算。
优选的,若所述序列v(t),w1(t-i)和是多元序列且序列的元素是整数符号,则所述第一逐符号混叠器S1和第二逐符号混叠器S2是逐符号模加权和运算器,第一逐符号混叠器S1的功能如下:输出长度为n的序列w1(t),w1(t)的第j个分量其中,和分别是v(t)和x1(t-i)的第j个分量,是取自整数集合{0,1,2,…,q-1},是与q互素的m1+1个整数,加法运算和乘法运算按模q运算法则运算;所述第二逐符号混叠器S2功能如下:输出长度为n的序列c(t),c(t)的第j个分量其中,和分别是w1(t),x2(t-i)的第j个分量,是取自整数集合{0,1,2,…,q-1},是与q互素的m2+1个整数,加法运算和乘法运算按模q运算法则运算。
本发明的编码方法编码后得到的码字c=(c(0),c(1),…,c(L+T-1))经调制后被送入信道;接收端接收到向量y=(y(0),y(1),…,y(L+T-1)),其中y(t)为对应码字子序列c(t)的接收序列;接收端根据接收向量y和信道特征,进行译码并得到发送序列u的估计
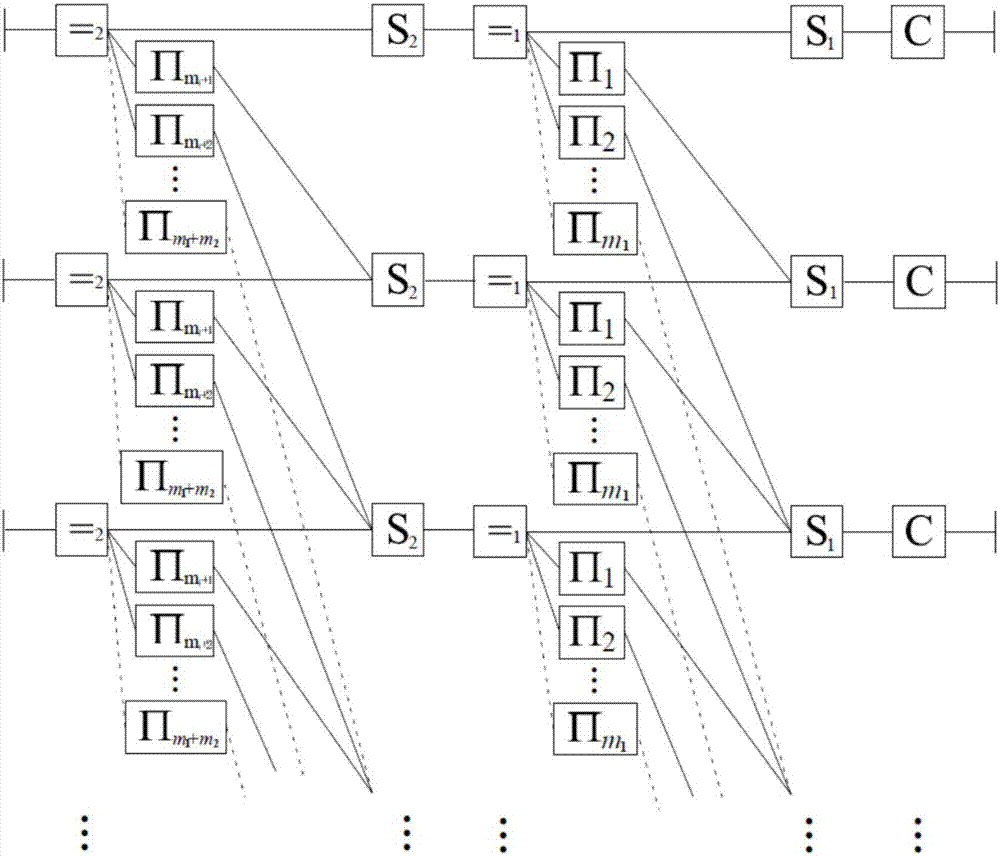
本发明提供了一种适用于所发明的编码方法的译码方法,它是一种基于滑窗的软输入软输出的迭代译码方法。译码器框图如图2所示,图中方框表示编码约束,下文中我们称这些方框为节点,节点之间的连线表示变量。在下文的译码流程描述中,我们用方框内的符号指代各节点。节点是消息处理器,节点之间通过连线传递消息。
本发明所述的译码方法中,传递和处理的消息为变量的概率分布或与之等价的其它量。每个码字子序列c(t)对应一个译码层,共有L+T个译码层。译码层包括“=”节点、“Πi”节点、“S”节点和“C”节点这4类节点。设定译码滑窗窗口d和最大迭代次数Imax。当接收端接收到y(t),y(t+1),…,y(t+d-1)(t=0,1,…,L-1),开始译码获取发送消息u(t)的估计具体步骤包括:
(Y1)对于j=t,t+1,…,t+d-1,如果j≤L+T-1,根据接收的向量y(j)和信道特征计算c(j)的后验概率分布;初始化迭代次数计数器I=0;
(Y2)对于j=t,t+1,…,t+d-1,如果j≤L+T-1,处理第j层消息,把第j层的消息传递到第j+1,j+2,…,j+m层;否则,执行步骤(Y3);
(Y3)对于j=t+d-1,t+d-2,…,t+1,如果j≤L+T-1,处理第j层消息,把第j层的消息传递到第j-1,j-2,…,j-m层;否则,执行步骤(Y4);
(Y4)设置I=I+1;如果译码达到最大迭代次数I=Imax,停止迭代,硬判决获取发送消息u(t)的估计否则,转到步骤(Y2)。
本发明所述的译码方法中,所述的处理第j层消息,按如下步骤进行I=Imax:
(S1)在“=2”节点处,处理并传递到“Πi”节点和“S2”节点的外信息,其中1≤i≤m2;
(S2)在“Πi”节点处,处理并传递从节点“=2”到节点“S2”或从节点“S2”到节点“=2”的外信息,其中1≤i≤m2;
(S3)在“S2”节点处,处理并传递到“=2”节点和“=1”节点的外信息;
(S4)在“=1”节点处,处理并传递到“Πi”节点,“S1”节点和“S2”节点的外信息,其中1≤i≤m1;
(S5)在“Πi”节点处,处理并传递从节点“=1”到节点“S1”或从节点“S1”到节点“=1”的外信息,其中1≤i≤m1;
(S6)在“C”节点处,使用软输入软输出译码,更新到“S1”节点的外信息,并更新译码器的译码输出信息。
本发明与现有技术相比,具有如下优点和有益效果:
1、本发明提出的基于双递归的分组马尔可夫叠加编码方法,具有编码简单、译码复杂度低、构造灵活、可逼近信道容量等优点。
2、本发明提出的基于双递归的分组马尔可夫叠加编码方法,与传统的分组马尔可夫叠加编码方法相比,译码中所有处理节点的度最多为三,因此拥有极低的译码复杂度。
3、本发明提出的基于双递归的分组马尔可夫叠加编码方法,与传统的分组马尔可夫叠加编码方法相比,译码的错误平层更低。
附图说明
图1是基于双递归的分组马尔可夫叠加编码方法的编码框图。
图2是基于双递归的分组马尔可夫叠加编码方法的译码框图。
图3是实施例的双递归的分组马尔可夫叠加编码方法的编码框图(第一编码记忆长度和第二编码记忆长度都为1)。
图4是基于双递归的分组马尔可夫叠加编码方法在BPSK-AWGN信道上的BER性能曲线。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例1
设置m1=m2=1,参照图1,相应的编码图如图3。参照图3,长度为K=kL=1250×343的二元信息序列u划分为L=343个等长分组u=(u(0),u(1),…,u(342)),每个分组长度为k=1250。基本码编码器ENC使用一个码长n=2,信息位长度k=1的重复码。本实例中,使用两个随机交织器。逐符号混叠器S采用逐比特二元域和运算器。结尾长度T设置为与译码延迟d相同,即T=d。参照图1,其编码方法包括以下步骤:
步骤一、把信息序列u划分为343个等长分组u=(u(0),u(1),…,u(342)),每个分组长度为1250;对于t=-1,把长度为2500的序列w1(t)和w2(t)初始化设置为全零序列,即对于t=-1,有w1(t)=w2(t)=0;
步骤二、在t=0,1,…,342时刻,将长度为1250的序列u(t)=(u0(t),u1(t),…,u1249(t))送入基本码编码器ENC进行编码,得到长度为2500的编码序列v(t)=(v0(t),v1(t),…,v2499(t)),并结合w1(t-1)和w2(t-1)计算码字c的第t个子序列c(t):
首先,将序列w1(t-1)和w2(t-1)送入交织器,得到交织后长度为2500的序列x1(t-1)和x2(t-1);
然后,将v(t)和x1(t-1),x2(t-1)送入第一逐符号混叠器S1和第二逐符号混叠器S2,按如下操作得到长度为2500的序列w1(t),w2(t)和c(t):其中和分别是v(t),x1(t-1),x2(t-1)的第j个分量,加法运算按二元域运算法则运算。
步骤三、在t=343,344,…,342+T时刻,将长度为1250的全零序列u(t)送入编码器ENC,得到长度为2500的全零序列v(t),并结合w1(t-1)和w2(t-1)计算码字c的第t个子序列c(t)。
码字c=(c(0),c(1),…,c(342+T))经BPSK调制后送入AWGN信道,接收端接收到对应码字c的接收序列y=(y(0),y(1),…,y(342+T))。设定最大迭代次数Imax=18。当接收端接收到y(t),y(t+1),…,y(t+d-1),进行译码并得到发送消息序列u的估计
参照图3,其译码方法包括以下步骤:
(Y1)对于j=t,t+1,…,t+d-1,如果j<343+T,根据接收的向量y(j)和信道特征计算c(j)的后验概率分布;初始化迭代次数计数器I=0;
(Y2)对于j=t,t+1,…,t+d-1,如果j<343+T,处理第j层消息,把第j层的消息传递到第j+1和j+2层;否则,执行步骤(Y3);
(Y3)对于j=t+d-1,t+d-2,…,t+1,如果j<343+T,处理第j层消息,把第j层的消息传递到第j-1和j-2层;否则,执行步骤(Y4);
(Y4)设置I=I+1;如果译码达到最大迭代次数Imax=18,停止迭代,硬判决获取发送消息u(t)的估计否则,转到步骤(Y2)。
仿真结果见图4。从图4可见,随着译码延迟d的增大,基于双递归的分组马尔可夫叠加编码方法在瀑布区和错误平层误比特率性能都变优。采用译码延迟为d=7时,基于双递归的分组马尔可夫叠加编码方法即使在误比特率为10-8时也没有出现错误平层,在误比特率为10-8时距离香农限约0.9dB。同时图4中给出了传统的分组马尔科夫叠加编码在记忆长度m=10时的性能下界,从图4可以看出,双递归的分组马尔科夫叠加编码方法具有更低的错误平层。为进一步说明本发明的性能,我们还仿真了采用码长2140的重复码为基本码、译码窗窗口为d=6的双递归分组马尔科夫叠加编码的性能。从图4可以看出,该码与采用2500码长的重复码作为基本码的双递归分组马尔科夫叠加编码的性能相当。
一方面,本发明所提出的编码方法拥有传统的分组马尔可夫叠加编码方法的大多数优点,譬如编码简单和可逼近信道容量。另一方面,相对传统的分组马尔可夫叠加编码方法,本发明提出的基于双递归的分组马尔可夫叠加编码方法仅需要更少的寄存器来逼近信道容量,并因此拥有更低的译码复杂度。译码窗口大小为两万比特的基于双递归的分组马尔可夫叠加编码方法,可实现比记忆长度为8的传统的分组马尔可夫叠加编码方法更低的错误平层。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!