一种基于编码分布式计算的神经网络BP译码方法
本发明涉及无线通信,属于信道译码方法,具体涉及一种基于编码分布式计算的神经网络bp译码方法。
背景技术:
1、置信传播(belief-propagation,bp)算法是目前最常用的信道译码方案之一。近年来,随着神经网络(neural networks,nns)在计算机视觉、自然语言处理和语音识别等领域的广泛应用,有研究将nns引入信道译码领域,提出了基于nns的bp译码方法(nns-bp)。nns显著增强了短到中等长度下高密度奇偶校验码(high-densityparity check,hdpc)的译码性能。在某些场景下,nns-bp甚至可以接近最大似然译码性能。
2、然而,随码长增长,nns-bp面临着计算复杂度高和内存开销大的挑战。具体而言,nns-bp隐藏层中神经元数量等于码的奇偶校验矩阵中非零元素的个数。hdpc码的高密度导致译码器中存在大量需要进行浮点乘法和双曲运算操作的神经元。例如,polar(128,64)的译码器每层由1792个神经元组成,而polar(512,256)的译码器则有16592个神经元。虽然nns可以通过gpu进行高效离线训练,但在实时推理阶段,计算资源是有限的。随着hdpc码长度的进一步增长,在资源有限的设备(如无人机)上执行实时推理/译码是不切实际的。
3、分布式计算使得在多个资源受限设备上执行大规模任务成为可能。然而,随着分布式系统中节点数量的增加,由于网络时延、资源共享和功耗限制等原因,缓慢甚至失效节点的存在将不可避免。上述节点通常被称为掉队节点,其速度可能比正常节点慢五到八倍,甚至无法响应。因此,掉队节点的存在会引入不可预测的延迟,降低整个系统的计算效率。
4、最近,编码分布式计算(coded distributed computing,cdc)成为了解决大规模分布式计算环境中节点掉队问题的可行方案。通过编码引入计算冗余,cdc使得主节点能够仅从一部分从节点的结果中恢复所需的结果,而无需等待所有从节点。受cdc的启发,有研究提出了基于cdc的矩阵乘法加速方案。具体而言,上述研究关注恢复阈值、数值稳定性、节点部分掉队、稀疏性保持以及集群异构等多个方面。
5、基于此,针对nns-bp所面临的计算复杂度高和内存开销大的挑战,研究如何将cdc应用于nns-bp场景,从而有效提升译码速度,同时解决分布式系统中节点掉队导致的不可预测延迟问题,具有重要实际意义。
技术实现思路
1、基于此,本发明提出了一种基于编码分布式计算的神经网络bp译码方法,通过分布式并行化,将计算任务卸载到多个节点上同时执行提高译码速度,同时,通过编码引入计算冗余使得分布式系统能够抵抗节点掉队的影响。
2、本发明提出了一种基于编码分布式计算的神经网络bp译码方法,包括以下步骤:
3、步骤1:使用配置矩阵w定义已知的神经网络bp译码器中层与层间神经元的连接关系,配置矩阵w中的元素即为层与层的神经元间的连接权重系数;
4、步骤2:基于各层的配置矩阵,将译码器奇数层和输出层的乘加运算建模为矩阵-向量乘法,通过引入对数与指数变换,将偶数层的连乘运算亦建模为矩阵-向量乘法;
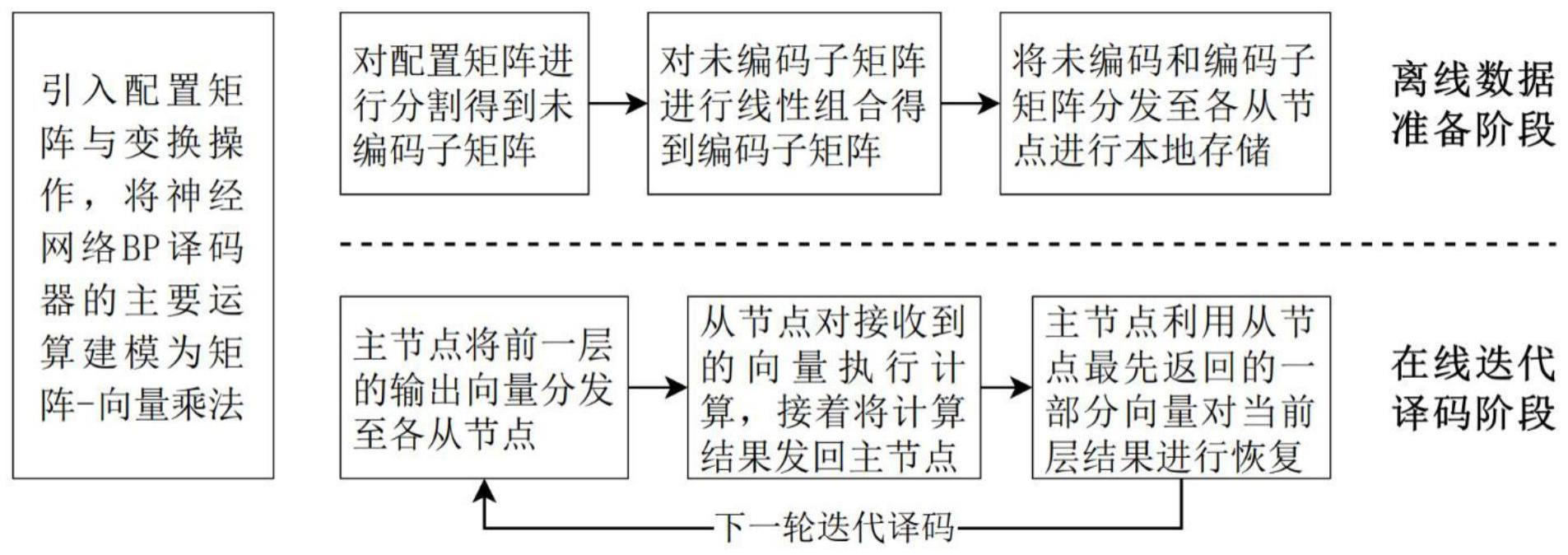
5、步骤3:离线数据准备阶段,具体包括以下子步骤:
6、步骤3-1:主节点对各层间的各配置矩阵w进行垂直分割,得到δ个未编码子矩阵wi,在分割前需判断矩阵列数能否被δ整除,若无法整除,则需先用全0向量将矩阵填充至合适维度;
7、步骤3-2:主节点利用随机线性编码矩阵r,对δ个未编码子矩阵进行随机线性组合,得到m·c个编码子矩阵即将生成的未编码和编码子矩阵分发给m个从节点,各从节点将得到u=δ/m个未编码子矩阵以及c个编码子矩阵,并在本地进行存储;
8、步骤4:在线迭代译码阶段,具体包括以下子步骤:
9、步骤4-1:主节点将前一隐藏层的输出向量x[s-1]广播至所有从节点,其后,从节点对接收到的向量按序与本地存储的子矩阵作矩阵-向量乘法,有:
10、首先,对于从节点k={1,2,…,m},有索引i从(k-1)·u+1到k·u,先完成未编码子矩阵-向量乘法其中表示第s-1与第s隐藏层间的配置矩阵的子矩阵,t表示转置计算;
11、然后,有索引j从(k-1)·c+1到k·c,完成编码子矩阵-向量乘法并发送编码结果至主节点,表示第s-1与第s隐藏层间配置矩阵的编码子矩阵;
12、若s为奇数,则计算其中表述输入层和第s隐藏层间的配置矩阵的子矩阵;
13、若s为偶数,则计算
14、在完成后续计算后,需将结果向量与拼接,得到随后发送给主节点;
15、步骤4-2:主节点利用从节点最先返回的δ个向量以及编码矩阵r,通过求解线性方程组对未收到的结果向量进行恢复,并对恢复结果执行相应的后续计算,然后将计算得到的结果向量及接收到结果向量进行垂直拼接,得到当前层的输出向量x[s];
16、步骤5:重复步骤4-1、步骤4-2直到达到最大迭代次数,最终由主节点通过输出层获得译码结果。
17、进一步的,所述步骤1中,神经网络bp译码器不同层间的连接关系分为三种:输入层和第s隐藏层,第(s-1)隐藏层和第s隐藏层,第2t隐藏层和输出层,其中t表示bp迭代译码次数;
18、上述连接关系可分别由配置矩阵w[s](s=2,3,...,2t)以及w0来表示。
19、进一步的,所述步骤2中,借助矩阵和w[s],将奇数层的乘加运算建模为矩阵-向量乘法,得到奇数层输出向量其中l为信道输入的llr向量;
20、将偶数层的连乘运算建模为矩阵-向量乘法,得到输出向量x[s]=2tanh-1(exp(w[s]t×ln(x)(x[s-1])));
21、对于输出层,借助矩阵w0,得最终输出向量
22、进一步的,所述步骤3-1中,对配置矩阵w进行垂直分割,其分块数量δ=lcm(m,1/γ),式中,lcm表示最小公倍数计算,γ≤1表示给定的分配给每个从节点的w[s]矩阵份额,有c=γδ-u,由此得到未编码子矩阵w1,w2,w3……,wδ;
23、进一步的,所述步骤3-1中,分割前还需用全0向量对矩阵进行填充,使得填充后的矩阵列数等于lcm(ne,δ),其中ne是配置矩阵w未填充前的列数。
24、进一步的,所述步骤3-2中,随机线性编码矩阵r的维度为m·c×δ,其第i行j列的元素值为:
25、
26、式中,符号*表示独立同分布地从连续分布中取得的非零元素。
27、进一步的,所述步骤3-2中,子矩阵分配规则如下:设ju=(k-1)×u,其中k={1,2,...,m}为从节点索引,定义集合tu={ju+1,...,ju+u}(mod δ),将各层的未编码子矩阵发送给从节点k,其中索引i∈tu;设jc=(k-1)×c,定义集合tc={jc+1,…,jc+c}(modm·c),将编码子矩阵发送给从节点k,其中索引i∈tc。
28、所述步骤4-2中,主节点收到δ-λ个拼接结果和λ个编码结果,
29、若λ=0,将δ个拼接结果中的向量按序垂直拼接,所得即为第s隐藏层的最终输出向量x[s];
30、若δ≠0,则λ个编码结果和δ-λ个拼接结果中的向量可与r联立,求解一线性方程组,以恢复未接收到的λ个向量,并对其执行后续计算;最后,将结果向量与δ-λ个拼接结果中的向量垂直拼接,得到x[s],然后将其作为第(s+1)隐藏层的输入广播给每个从节点。
31、本发明的有益效果在于:引入配置矩阵和变换操作,将神经网络bp译码过程矩阵化,不仅有利于该过程的分布式并行实现,更为通过编码注入计算冗余创造了机会。以此为基础,本发明面向主从分布式架构,设计了一种编码分布式神经网络bp译码方案,通过分布式并行化将译码任务卸载到多个计算节点上执行,实现了译码加速。同时,在此过程中通过对配置矩阵进行编码,有效嵌入计算冗余,使得分布式系统具备抵抗节点掉队的能力。此外,本发明还考虑了从节点的存储限制,且不损失译码精度。在亚马逊aws集群上进行的实验结果表明,在有节点掉队的情况下,本发明显著提高了神经网络bp译码的速度,当使用8个从节点时,bch码、qr码、polar码的译码耗时分别缩短了79%、77%和67%。
- 还没有人留言评论。精彩留言会获得点赞!