一种性能指标监控方法和装置与流程
本发明涉及动态基线算法领域,特别涉及一种性能指标监控方法和装置。
背景技术:
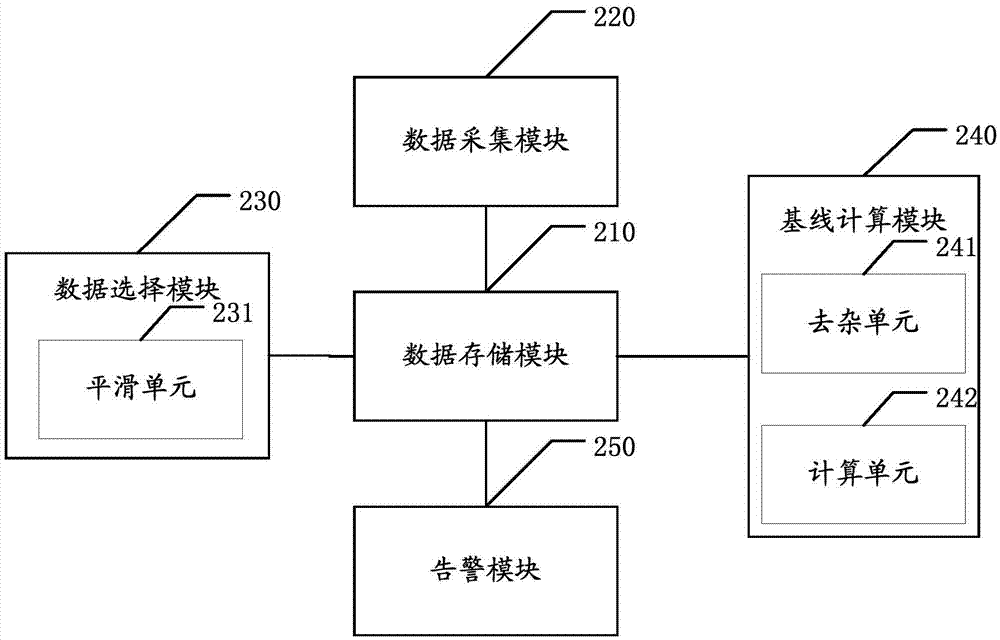
:在很多领域中都需要对一些性能指标数据进行实时监控,以判断当前的数据是否异常,例如在移动通信领域中,经常需要监控业务处理延时、接通率、用户容量、网络流量等指标,以诊断网络故障或进行性能优化等。传统的监控方法一般是将需要告警的条件进行梳理,然后配置一些监控规则,当某一性能指标的数据触发了这些监控规则时,向用户告警。但是,对于大规模业务,就需要配置大量的规则,在这种情况下,从规则的获取到规则的维护都是十分困难的。并且,所有的规则都是人为主观设定的,不一定能客观的反映被监控指标的变化规律,同时由于监控规则本身没有学习能力,不能很好地适应业务的变化。目前也出现了一些根据历史数据确定告警条件的方法,但是这些方案都较为简单,考虑因素较少,以至于不能精准的给出判断告警条件,不能满足人们的要求。技术实现要素:为了解决上述问题,本发明提供了一种性能指标监控方法和装置。依据本发明的一个方面,本发明提供了一种性能指标监控方法,包括:采集一定时期内所述性能指标的历史性能数据,并将所述历史性能数据存储在第一数据表中;从所述第一数据表中选取与所述性能指标的当前数据对应的同期历史性能数据,并存储在第二数据表中;根据所述第二数据表中的历史性能数据计算上基线和下基线;根据所述上基线、所述下基线和预先配置的相对容忍度比率计算出对应的上容忍度和下容忍度;若所述性能指标的当前数据大于所述上容忍度或小于所述下容忍度,则发出告警。其中,所述从所述第一数据表中选取与所述性能指标当前数据对应的同期历史性能数据,并存储在第二数据表中,具体包括:当所述同期历史性能数据存在于所述第一数据表中时,直接将其放入所述第二数据表中;当所述同期历史性能数据不存在于所述第一数据表中时,选取与其上下相邻的两个时间点的历史性能数据,做数据平滑,估计所述同期历史性能数据的近似值,放入所述第二数据表中。其中,所述根据所述第二数据表中的历史性能数据计算上基线和下基线,具体包括:删除所述第二数据表中的异常数据,仅保留能反映所述性能指标变化规律的典型数据;根据所述典型数据,采用概率分布算法计算所述上基线和所述下基线。其中,所述删除所述第二数据表中的异常数据,仅保留能反映所述性能指标变化规律的典型数据,包括:删除所述第二数据表中的最小值和最大值;将剩余数据分配到若干个区间中,每个区间的长度为所述剩余数据的最大值除以区间的个数再向上取整,且第一个区间的左端点为零;取数据个数最多的区间和与其相邻的区间中的数据,作为所述典型数据。其中,所述根据所述典型数据,采用概率分布算法计算所述上基线和所述下基线,包括:将所述典型数据从小到大排序;将所述典型数据的个数乘以预先设置的信度后向下取整,作为滑动窗口中数据的个数;取数据波动程度最小的滑动窗口中数据的最大值作为所述上基线,最小值作为所述下基线。依据本发明的另一个方面,本发明提供了一种性能指标监控装置,包括:数据存储模块以及分别与其连接的数据采集模块、数据选择模块、基线计算模块和告警模块;所述数据采集模块,用于采集一定时期内所述性能指标的历史性能数据,并将所述历史性能数据存储在第一数据表中;所述数据选择模块,用于从所述第一数据表中选取与所述性能指标的当前数据对应的同期历史性能数据,并存储在第二数据表中;所述基线计算模块,用于根据所述第二数据表中的历史性能数据计算上基线和下基线;所述告警模块,用于根据所述上基线、所述下基线和预先配置的相对容忍度比率计算出对应的上容忍度和下容忍度;当所述性能指标的当前数据大于所述上容忍度或小于所述下容忍度时,发出告警;所述数据存储模块,用于存储所述第一数据表和所述第二数据表。其中,所述装置还包括数据平滑模块;所述数据平滑模块分别连接所述数据选择模块与所述数据存储模块,用于当与所述性能指标的当前数据对应的同期历史性能数据不存在于所述第一数据表中时,选取与同期历史性能数据上下相邻的两个时间点的历史性能数据,做数据平滑,估计所述同期历史性能数据的近似值,放入所述第二数据表中。其中,所述基线计算模块包括去杂单元和计算单元;所述去杂单元,用于删除所述第二数据表中的异常数据,仅保留能反映所述性能指标变化规律的典型数据;所述计算单元,用于根据所述典型数据,采用概率分布算法计算所述上基线和所述下基线。其中,所述去杂单元具体用于:删除所述第二数据表中的最小值和最大值;将剩余数据分配到若干个区间中,每个区间的长度为所述剩余数据的最大值除以区间的个数再向上取整,且第一个区间的左端点为零;取数据个数最多的区间和与其相邻的区间中的数据,作为所述典型数据。其中,所述计算单元具体用于:将所述典型数据从小到大排序;将所述典型数据的个数乘以预先设置的信度后向下取整,作为滑动窗口中数据的个数;取数据波动程度最小的滑动窗口中数据的最大值作为所述上基线,最小值作为所述下基线。本发明实施例的有益效果是:本发明根据同期历史性能数据计算得到上下基线,相对于传统方法可以更快更准确的计算出基线数据,进而计算出告警条件对应的上下容忍度;由于告警条件是根据被监控性能指标的历史性能数据动态确定的,不需要人工确定和手动配置,降低了工作量,并且该监控方法具备一定的学习能力,可以适应变化的业务。优选方案中在计算上下基线之前,排除了历史数据中可能为异常数据的部分,使计算出的基线数据更精准;并且当被监控性能指标当前数据对应的同期历史数据没有采集到时,利用与该同期历史数据时间上相邻的历史性能数据进行估计,充分利用了采集到的数据,能更快更准确的确定告警条件。附图说明图1为本发明实施例提供的性能指标监控方法的具体流程图;图2为本发明实施例提供的性能指标监控装置的结构示意图。具体实施方式为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。本实施例的方法可以在服务器或用户端侧 执行,可以访问数据库获取历史性能数据。本发明的方法可以检测的性能可以为多种,具体可以包括任务或数据/应用的响应或执行时间、延时时间、执行次数、调用次数、URL调用次数、内存大小等。图1为本发明实施例提供的性能指标监控方法的具体流程图。如图1所示,本发明实施例提供的性能指标监控方法包括:步骤S110:采集一定时期内被监控的性能指标的历史性能数据,并将采集到的历史性能数据存储在第一数据表中。该步骤可以由采集机执行。数据获得的方式有多种方式:主动采集和被动采集,而主动采集又分为整点采集与等间隔采集,这些就导致采集机采集上来的时间并不一定是整点数据,而我们在动态基线计算的时候,又受到原动态基线获取整点数据进行计算的限制,所以我们就需要将采集的历史数据先进行平滑处理,将时间都换算为整点数据,以方便动态基线的计算。采用整点采集方式,例如,从0点开始采集,每5分钟采集一次,那么就是0点5分采集第1次、0点10分采集第2次,如果在0点10分的时候,第一次采集没有结束,那么就停止第一次采集而后启动第二次采集,作为5分开始采集的数据,虽然这些数据有些可能是0点5分30秒采集到的,但是统一认为这是0点5分的数据。采用等间隔采集方式,例如,间隔5分钟采集1次,那么当采集机启动以后,采集机开始采集数据,一直到采集结束的时候,采集机开始计时,当计时达到5分钟的时候开始第2次采集。第1次采集的时间,是系统启动的时间,这个时间很难控制在整点上,除非程序中加了整点的时间的判断,即假设用户是0点2分的时候启动的采集机,采集机会等到0点5分开始采集,但就算开始的时间是整点的,在采集的时候,受到各种因素的影响,每次采集相同指标的数据,时间也是不等的,这就导致下次开始采集的时间和上次采集的时间间隔不相等。采用被动采集的方式,由其他系统发送历史性能数据,采集的时间和间隔无法控制,只能被动接收。步骤S120:从第一数据表中选取与被监控的性能指标的当前数据对应的同期历史性能数据,并存储在第二数据表中。在进行基线数据计算时,首先从历史性能数据表即上述的第一数据表中取到历史性能数据。在本发明的一个优选实施例中,该步骤S120具体包括:当该同期历史性能数据不存在于第一数据表中时,选取与其上下相邻的两个时间点的历史性能数据,做数据平滑,估计该同期历史性能数据的近似值,放入第二数据表中。例如,需要某一天8点的数据,该时间点的数据不存在与第一数据表中,但是7点55分和8点05分的数据存在,那么就选取这两个时间点的数据来估计8点的数据,进行数据平滑,然后将估计出的数据放入第二数据表中。这样就可以有效的利用已经采集的数据来确定告警条件。步骤S130:根据第二数据表中的历史性能数据计算上基线和下基线。动态基线数据计算主要分成两大步:第一步:区间取数去杂,该步骤的区间选数去杂主要是为了去掉那些特别大特别小的数据,在分布最多区间中抽取数据,并且保证最大最小数尽量平滑。第二步:采用概率分布算法(标准差)方法计算出上下基线,本步骤经过区间取数去杂之后,对去杂之后的这些数据再进行概率分布算法,取出上下基线数据。在本发明的一个优选实施例中,该步骤S130具体分解为如下步骤:删除第二数据表中的最小值和最大值;将剩余数据分配到若干个区间中,每个区间的长度为剩余数据的最大值减去最小值后除以区间的个数再向上取整,且第一个区间的左端点为零;取数据个数最多的区间和与其相邻的区间中的数据,作为能反映被监控指标变化规律的典型数据;将典型数据从小到大排序;将典型数据的个数乘以预先设置的信度后向下取整的数值作为滑动窗口数据个数;取数据波动程度最小的滑动窗口中数据的最大值作为上基线,最小值作为下基线。步骤S140:根据上基线、下基线和预先配置的相对容忍度比率计算出对应的上容忍度和下容忍度。在得到上基线值和下基线值之后,再根据配置的相对容忍度,计算得到上下容忍度。步骤S150:判断被监控的性能指标的当前数据是否大于上容忍度或小于下容忍度。若是,则执行步骤S160;否则结束性能指标监控或者返回步骤S110或者返回步骤S120,继续采集数据。步骤S160:向用户发出告警。告警条件是根据与被监控的性能指标的当前数据对应的同期历史性能数据来确定的,由于采用的数据采集方式或系统故障等原因,可能与被监控的性能指标的当前数据对应的某些历史性能数据不存在于第一数据表中,这样就会影响步骤S130中计算的上下基线的精准度。例如,采用整点采集的方式,从0点开始采集,每5分钟采集一次,如果想要判断0点3分的数据是否异常需要告警,由于没有采集该点对应的同期历史性能数据,所以无法办到。这样想要实时监控就必须采集每一个时间点的历史性能数据,这是很难办到的,并且维护如此大量的历史性能数据,不仅浪费资源、工作量大,而且性能也不高。下面,以监控某一性能指标2012年4月16日20点整是否需要告警为例,具体说明本发明实施例提供的性能指标监控方法。由于告警条件是根据历史数据动态确定的,因此首先要采集该性能指标在一定时期内的历史性能数据,具体的采集的期间和采集间隔可以根据被监控性能指标本身的特性来确定,例如某一性能指标大致上是以一天为周期变化的,那么就可以采集过去若干天的性能数据,与今天8点的数据对应的同期历史性能数据就是过去这些天8点的数据;再例如,某一性能指标大致上是以一小时为周期变化的,同样可以采集过去若干天的性能数据,与今天8点的数据对应的同期历史性能数据就是过去的每个整点的数据。在本例中,假设被监控的性能指标是以一天为周期变化的,采集了过去30天的历史性能数据,以表中数据为某一任务响应时间值为例,存储在第一数据表中,如表1所示。表1时间历史性能数据2012-3-1720:00562012-3-1820:00912012-3-1920:00792012-3-2020:00342012-3-2120:00542012-3-2220:00512012-3-2320:00532012-3-2420:00632012-3-2520:00392012-3-2620:00382012-3-2720:00242012-3-2820:00392012-3-2920:00412012-3-3020:00412012-3-3120:00392012-4-120:00782012-4-220:00792012-4-320:00672012-4-420:00662012-4-520:00692012-4-720:00632012-4-820:00872012-4-920:00812012-4-1021:00942012-4-1120:00992012-4-1220:00732012-4-1320:001032012-4-1420:001022012-4-15200079与2012年4月16日20点对应的同期历史性能数据为过去30天每天20点的历史性能数据。这些数据基本都存在,因此可以直接取这些历史性能数据放入第二数据表中。由于2012-4-620:00:00的数据不存在,需要取该时间点的上下相邻时间的历史性能数据,做数据平滑,假如2012-4-619:55:00的历史性能数据为85、2012-4-620:05:00的历史性能数据为94,平滑后得到2012-4-620:00:00的历史性能数据为89,放入第二数据表中,如表2所示。表2第二数据表中的数据如下:[56,91,79,34,54,51,53,63,39,38,24,39,41,41,39,78,79,67,66,69,89,63,87,81,94,99,73,103,102,79]。按从小到大排序,删除其中最小的数和最大的数,因为这些数据有可能是异常大的数或异常小的数,剩余的28个数为:[34,38,39,39,39,41,41,51,53,54,56,63,63,66,67,69,73,78,79,79,79,81,87,89,91,94,99,102]。在本例中,确定5个区间,每个区间的长度为102/5=21,五个区间分别是[0,21)、[21,42)、[42,63)、[63,84)、[84,105),将剩余数据分配到这些区间中,得到:区间1=[]区间2=[34,38,39,39,39,41,41]区间3=[51,53,54,56]区间4=[63,63,66,67,69,73,78,79,79,79,81]区间5=[87,89,91,94,99,102]区间4中的数据个数最多,所以取区间4以及上邻区间3和下邻区间5的数据,如果它上、下邻区间没有数据,可不取,取完的数为:[51,53,54,56,63,63,66,67,69,73,78,79,79,79,81,87,89,91,94,99,102],剩下21个数。通过以上步骤,第二数据表中可能存在的异常历史性能数据被排除,仅保留了能反映被监控的性能指标的变化规律的典型数据,然后利用这些典型数据计算上下基线。在本例中,设置信度为0.8,信度可以根据需要任意设定,大小在0到1之间,通过置信度求出剩余的21个数据的滑动窗口的大小,即滑动窗口中数据的个数为21*0.8=16.8取整为16。将滑动窗口从左到右滑动,依次计算每一个窗口中数据的标准差,计算结果如下:第1个数到第16个数:[51,53,54,56,63,63,66,67,69,73,78,79,79,79,81,87]的标准差为:10.95944227595547;第2个数到第17个数:[53,54,56,63,63,66,67,69,73,78,79,79,79,81,87,89]标准差为:11;第3个数到第18个数:[54,56,63,63,66,67,69,73,78,79,79,79,81,87,89,91]标准差为:10.95944227595547第4个数到第19个数:[56,63,63,66,67,69,73,78,79,79,79,81,87,89,91,94]标准差为:10.815931536395745;第5个数到第20个数:[63,63,66,67,69,73,78,79,79,79,81,87,89,91,94,99]标准差为:10.885591107055234;第6个数到第21个数:[63,66,67,69,73,78,79,79,79,81,87,89,91,94,99,102]标准差为:11.478240283248997。标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。其中标准差最小为4~19窗口的10.815931536395745,因此该滑动窗口中的数据波动程度最小,取该窗口[56,63,63,66,67,69,73,78,79, 79,79,81,87,89,91,94]的最大值94作为上基线,56作为下基线。样本置信度在概率算法中,为所选取的样本空间中的历史数据的可信程度,用来对要进行基线计算的样本数据的选取进行扩大或缩小。样本置信度默认为0.8,取值范围为0.1~1。推荐使用默认的值0.8。置信度越大,取最大值也会越大,最小值也会越小。置信度取决于对于损失的容忍度,在本例中,相对容忍度配置为20%,该相对容忍度是根据需要设定的,大小在0到1之间,通过计算得到上下容忍度分别为:上容忍度=上基线值94*(1+20%)=112.8下容忍度=下基线值56*(1-20%)=44.8根据上下容忍度数据来判断当前数据是否正常、是否需要告警,若当前数据的大小在上下容忍度之间,则认为当前数据是正常的;若当前数据大于上容忍度112.8或小于下容忍度44.8,则认为当前数据异常,发出告警。基于相同的发明构思,本发明还提供了一种性能指标监控装置实施例。本实施例中的装置可以设置在服务器或用户端侧,与数据库连接,可以访问数据库获取历史数据。本发明中的装置可以检测的性能可以为多种,具体可以包括任务或数据/应用的响应或执行时间、执行次数、调用次数、URL调用次数、内存大小等。图2为本发明实施例提供性能指标监控装置的结构示意图。如图2所示,本发明实施例提供性能指标监控装置包括:数据存储模块210以及与其连接的数据采集模块220、数据选择模块230、基线计算模块240和告警模块250;数据采集模块220,用于采集一定时期内被监控性能指标的历史性能数据,并将采集到的历史性能数据存储在第一数据表中。数据选择模块230,用于从第一数据表中选取与被监控的性能指标的当前数据对应的同期历史性能数据,并存储在第二数据表中;基线计算模块240,用于根据第二数据表中的历史性能数据计算上基线和下基线;告警模块250,用于根据计算出的上下基线和预先配置的相对容忍度比率计算出对应的上容忍度和下容忍度;当被监控的性能指标当前数据大于上容忍度或小于下容忍度时,判断当前数据异常,发出告警;数据存储模块210,用于存储第一数据表和第二数据表。上述的数据采集模块220和数据选择模块230可以由采集机执行。在本发明提供的一个优选实施例中,数据选择模块230包括平滑单元231。若与被监控的性能指标的当前数据对应的某一个同期历史性能数据不存在于第一数据表中,则平滑单元231选取与该同期历史性能数据上下相邻的两个时间点的历史性能数据,做数据平滑,估计该同期历史性能数据的近似值,放入第二数据表中。在另一优选实施例中,仍如图2所示,基线计算模块240包括去杂单元241和计算单元242;去杂单元241用于删除第二数据表的异常历史性能数据,仅保留能反映被监控的性能指标变化规律的典型数据。作为优选方案,去杂单元241具体用于删除第二数据表中的最小值和最大值,并将剩余数据分配到若干个区间中,其中每个区间的长度为剩余数据的最大值除以区间的个数再向上取整,且第一个区间的左端点为零,取数据个数最多的区间和与其相邻的区间中的数据,作为保留的典型数据。计算单元242用于根据保留的典型数据,采用概率分布算法计算上下基线。作为优选方案,计算单元242具体用于:将剩余的典型数据从小到大排序;将剩余数据的个数乘以预先设置的信度后向下取整的数值作为滑动窗口数据个数;取数据波动程度最小的滑动窗口中数据的最大值作为上基线,最小值作为下基线。在一优选实施例中,采用计算滑动窗口中数据的标准差的方法来判断数据波动程度,标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。综上所述,本发明提供的性能指标监控方法和装置,根据同期历史性能 数据计算得到上下基线,相对于传统方法可以更快更准确的计算出基线数据,进而计算出告警条件对应的上下容忍度;与现有技术相比,具有以下有益效果:1、告警条件是根据被监控性能指标的历史性能数据动态确定的,不需要人工确定和手动配置,降低了工作量,并且该监控方法具备一定的学习能力,可以适应变化的业务。2、在计算上下基线之前,排除了历史数据中可能为异常数据的部分,使计算出的基线数据更精准。3、当被监控性能指标当前数据对应的同期历史性能数据没有采集到时,利用与该同期历史性能数据时间上相邻的历史性能数据进行估计,充分利用了采集到的数据,更快更准确的确定告警条件。以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1