多设备之间的分组方法和装置与流程
本发明涉及智能控制技术领域,特别涉及一种多设备之间的分组方法和装置。
背景技术:
在智能家居中,当需要布置多个扬声器和多个麦克风时,虽然通过无线方式可以给布线带来方便,但同时也带来一个问题:由于扬声器或麦克风均可移动,因此会给用户配置带来巨大难度,大大降低用户体验。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本发明的第一个目的在于提出一种多设备之间的分组方法,该方法通过声波数据的发送和接收可以得到一个扬声器对应多个麦克风的关系,进而能够实现多个麦克风与多个扬声器之间的自动组网,降低用户配置难度,提高用户体验。
本发明的第二个目的在于提出一种多设备之间的分组装置。
为实现上述目的,本发明第一方面实施例提出了一种多设备之间的分组方法,包括以下步骤:获取第一扬声器以第一音量强度播放的第一声波数据;获取至少一个第一麦克风接收的第二声波数据;若所述第二声波数据和所述第一声波数据匹配,则确定所述第一扬声器和所述至少一个第一麦克风属于第一区域分组。
根据本发明实施例的多设备之间的分组方法,获取第一扬声器以第一音量强度播放的第一声波数据,并获取至少一个第一麦克风接收的第二声波数据。若第二声波数据和第一声波数据匹配,则确定第一扬声器和至少一个第一麦克风属于第一区域分组,从而可以得到一个扬声器对应多个麦克风的关系,进而能够实现多个麦克风与多个扬声器之间的自动组网,降低用户配置难度,提高用户体验。
根据本发明的一个实施例,若所述第二声波数据和所述第一声波数据不匹配,则确定所述第一扬声器和所述至少一个麦克风属于不同的区域分组。
根据本发明的一个实施例,第二扬声器和至少一个第二麦克风属于第二区域分组,当所述至少一个第一麦克风和所述至少一个第二麦克风的重叠率达到预设阈值时,所述分组方法还包括:获取所述第一扬声器和所述第二扬声器分别以第二音量强度播放的第三声波数据,其中,所述第二音量强度大于所述第一音量强度;获取重叠的麦克风接收的第四声波数据;若所述第四声波数据和所述第三声波数据匹配,则确定所述第一扬声器、所述第二扬声器和所述重叠的麦克风属于第三区域分组。
根据本发明的一个实施例,在确定所述第一扬声器、所述第二扬声器和所述重叠的麦克风属于第三区域分组之后,还包括:获取所述第一扬声器和所述第二扬声器同时以第三声音强度播放的第五声波数据,其中,所述第三声音强度小于所述第一声音强度;获取所述重叠的麦克风接收声音的第六声波数据;若所述第六声波数据和所述第五声波数据匹配,则判断所述第三区域分组验证通过。
根据本发明的一个实施例,在确定所述第一扬声器、所述第二扬声器和所述重叠的麦克风属于第三区域分组之后,还包括:获取所述第一扬声器和所述第二扬声器轮流以第四声音强度播放的第七声波数据,其中,所述第四声音强度小于所述第三声音强度;当判断所述第三区域分组中的一个麦克风接收的第八声波数据与所述第七声波数据匹配时,确定所述一个麦克风为与所述第一扬声器和所述第二扬声器距离最近的麦克风。
根据本发明的一个实施例,上述的分组方法,还包括:当任意一个麦克风接收到第九声波数据时,确定所述任意一个麦克风所属的区域分组;判断所述所属的区域分组中是否存在检测到人体的人体检测传感器;若存在检测到人体的所述人体检测传感器,则判断所述人体检测传感器和所述任意一个麦克风属于相同的区域分组。
为实现上述目的,本发明第二方面实施例提出了一种多设备之间的分组装置,包括:第一获取模块,用于获取第一扬声器以第一音量强度播放的第一声波数据;第二获取模块,用于获取至少一个第一麦克风接收的第二声波数据;匹配模块,用于在所述第二声波数据和所述第一声波数据匹配时,确定所述第一扬声器和所述至少一个第一麦克风属于第一区域分组。
根据本发明实施例的多设备之间的分组装置,通过第一获取模块获取第一扬声器以第一音量强度播放的第一声波数据,通过第二获取模块获取至少一个第一麦克风接收的第二声波数据,匹配模块在第二声波数据和第一声波数据匹配时,确定第一扬声器和至少一个第一麦克风属于第一区域分组,从而可以得到一个扬声器对应多个麦克风的关系,进而能够实现多个麦克风与多个扬声器之间的自动组网,降低用户配置难度,提高用户体验。
根据本发明的一个实施例,所述匹配模块还用于:在所述第二声波数据和所述第一声波数据不匹配时,确定所述第一扬声器和所述至少一个麦克风属于不同的区域分组。
根据本发明的一个实施例,第二扬声器和至少一个第二麦克风属于第二区域分组,当所述至少一个第一麦克风和所述至少一个第二麦克风的重叠率达到预设阈值时,所述第一获取模块还用于:获取所述第一扬声器和所述第二扬声器分别以第二音量强度播放的第三声波数据,其中,所述第二音量强度大于所述第一音量强度;所述第二获取模块还用于:获取重叠的麦克风接收的第四声波数据;所述匹配模块还用于:在所述第四声波数据和所述第三声波数据匹配时,确定所述第一扬声器、所述第二扬声器和所述重叠的麦克风属于第三区域分组。
根据本发明的一个实施例,所述第一获取模块还用于:获取所述第一扬声器和所述第二扬声器同时以第三声音强度播放的第五声波数据,其中,所述第三声音强度小于所述第一声音强度;所述第二获取模块还用于:获取所述重叠的麦克风接收声音的第六声波数据;所述分组装置还包括:验证模块,用于在所述第六声波数据和所述第五声波数据匹配时,判断所述第三区域分组验证通过。
根据本发明的一个实施例,所述第一获取模块还用于:获取所述第一扬声器和所述第二扬声器轮流以第四声音强度播放的第七声波数据,其中,所述第四声音强度小于所述第三声音强度;所述分组装置还包括:第一判断模块,用于当判断所述第三区域分组中的一个麦克风接收的第八声波数据与所述第七声波数据匹配时,确定所述一个麦克风为与所述第一扬声器和所述第二扬声器距离最近的麦克风。
根据本发明的一个实施例,上述的分组装置,还包括:确定模块,用于当任意一个麦克风接收到第九声波数据时,确定所述任意一个麦克风所属的区域分组;第二判断模块,用于判断所述所属的区域分组中是否存在检测到人体的人体检测传感器,并在判断存在检测到人体的所述人体检测传感器时,判断所述人体检测传感器和所述任意一个麦克风属于相同的区域分组。
附图说明
图1是根据本发明第一个实施例的多设备之间的分组方法的流程图;
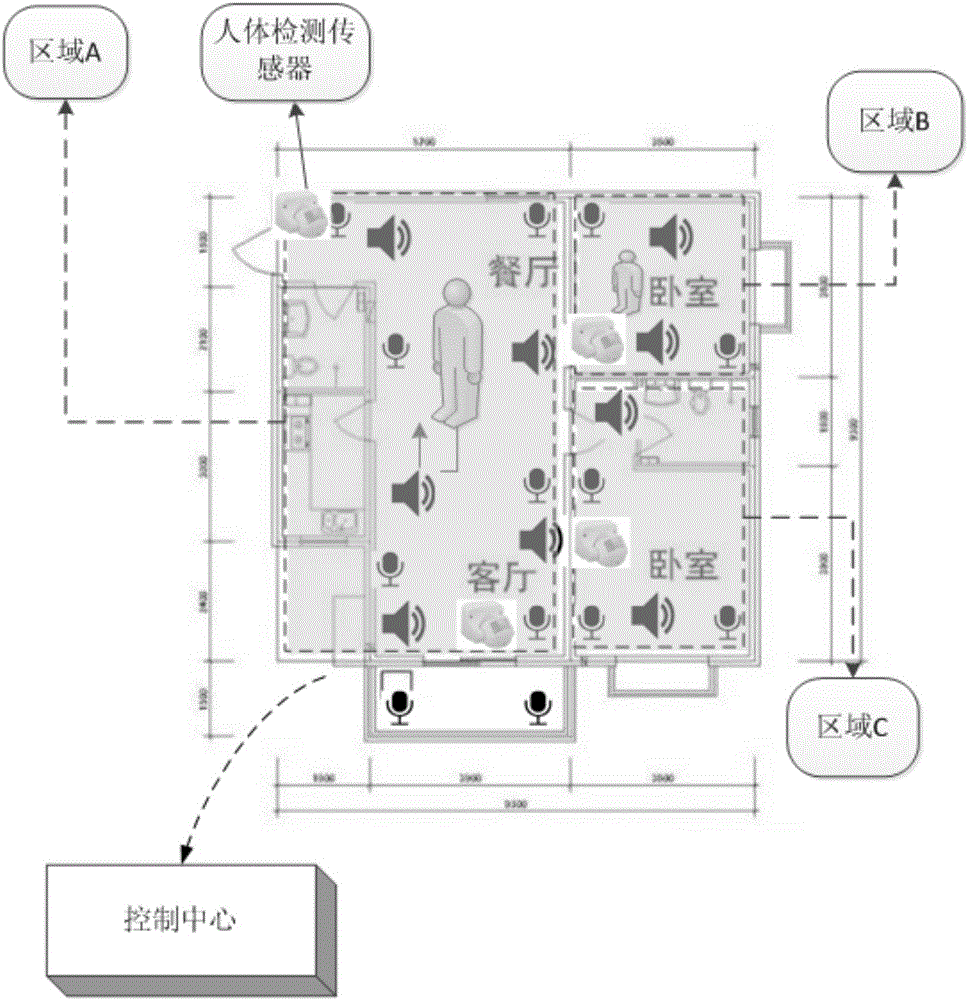
图2是根据本发明一个具体示例的麦克风、扬声器和人体检测传感器的布局示意图;
图3是根据本发明一个实施例的不同扬声器对应的多个麦克风之间发生重叠的示意图;
图4是根据本发明第二个实施例的多设备之间的分组方法的流程图;
图5是根据本发明第三个实施例的多设备之间的分组方法的流程图;
图6是根据本发明第四个实施例的多设备之间的分组方法的流程图;
图7是根据本发明第五个实施例的多设备之间的分组方法的流程图;
图8是根据本发明第六个实施例的多设备之间的分组方法的流程图;
图9是根据本发明一个实施例的多设备之间的分组装置的框图;以及
图10是根据本发明另一个实施例的多设备之间的分组装置的框图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
下面参照附图来描述根据本发明实施例提出的多设备之间的分组方法和装置。
图1是根据本发明一个实施例的多设备之间的分组方法的流程图。如图1所示,多设备之间的分组方法包括以下步骤:
S110,获取第一扬声器以第一音量强度播放的第一声波数据。
S120,获取至少一个第一麦克风接收的第二声波数据。
S130,若第二声波数据和第一声波数据匹配,则确定第一扬声器和至少一个第一麦克风属于第一区域分组。
根据本发明的一个实施例,若第二声波数据和第一声波数据不匹配,则确定第一扬声器和至少一个麦克风属于不同的区域分组。
具体地,如图2所示,在用户家中,当进行区域分组时,可以先关闭所有房间门,然后一键控制进入自动配置模式,此时控制中心先控制用户家中的第一扬声器发出第一音量强度V1的第一声波数据,然后控制中心控制用户家中的各个麦克风接收该声波数据,各个麦克风将接收到的声波数据(第二声波数据)上传至控制中心。控制中心判断各个麦克风接收到的声波数据是否与第一扬声器发出的第一声波数据相匹配,即判断各个麦克风接收到的声音波形与第一扬声器发出的声音波形是否相同,如果是,则确定该麦克风与第一扬声器属于同一区域,即属于第一区域分组;如果否,则确定该麦克风与第一扬声器属于不同的区域分组,从而得到第一扬声器与多个麦克风之间的关系。然后,控制中心关闭第一扬声器,并按照上述方法逐个判断剩余扬声器与各个麦克风之间的关系,从而得到房间中每个扬声器与各个麦克风之间的关系,进而实现多个麦克风与多个扬声器之间的自动组网,降低用户配置难度,提高用户体验。
根据本发明实施例的多设备之间的分组方法,获取第一扬声器以第一音量强度播放的第一声波数据,并获取至少一个第一麦克风接收的第二声波数据。若第二声波数据和第一声波数据匹配,则确定第一扬声器和至少一个第一麦克风属于第一区域分组,从而可以得到一个扬声器对应多个麦克风的关系,进而能够实现多个麦克风与多个扬声器之间的自动组网,降低用户配置难度,提高用户体验。
根据本发明的一个实施例,如图3和图4所示,第二扬声器和至少一个第二麦克风属于第二区域分组,当至少一个第一麦克风和至少一个第二麦克风的重叠率达到预设阈值时,分组方法还包括:
S140,获取第一扬声器和第二扬声器分别以第二音量强度播放的第三声波数据,其中,第二音量强度大于第一音量强度。
S150,获取重叠的麦克风接收的第四声波数据。
S160,若第四声波数据和第三声波数据匹配,则确定第一扬声器、第二扬声器和重叠的麦克风属于第三区域分组。
具体地,如图3所示,当两个不同的扬声器(如第一扬声器和第二扬声器)所对应的麦克风的重叠率达到预设阈值n%时,则认为有可能是两个扬声器在同一个区域内,此时控制中心将两个扬声器的音量强度调大,然后判断重叠的麦克风是否能够接收到正确的声波数据。即,控制中心分别控制第一扬声器和第二扬声器发出第二音量强度V2的第三声波数据,并控制重叠的麦克风接收该声波数据,麦克风将接收到的声波数据(第四声波数据)上传至控制中心。控制中心判断重叠的麦克风接收到的声波数据是否与第三声波数据相匹配,如果是,则确定重叠的麦克风与第一扬声器和第二扬声器属于同一区域,即属于第三区域分组。
进一步地,为了保证区域分组的准确性,在本发明的一个实施例中,如图5所示,在确定第一扬声器、第二扬声器和重叠的麦克风属于第三区域分组之后,还包括:
S170,获取第一扬声器和第二扬声器同时以第三声音强度播放的第五声波数据,其中,第三声音强度小于第一声音强度。
S180,获取重叠的麦克风接收声音的第六声波数据。
S190,若第六声波数据和第五声波数据匹配,则判断第三区域分组验证通过。
也就是说,在实现第三区域分组后,控制中心还控制第一扬声器和第二扬声器同时发出温和音量V3的声波数据,然后判断重叠的麦克风是否都能够正确接收到,如果是,则判断第三区域分组成功,即第三区域分组验证通过,从而实现了多个麦克风与多个扬声器之间的自动组网,降低了用户配置难度,提高了用户体验。
根据本发明实施例的多设备之间的分组方法,在得到每个扬声器与各个麦克风之间的对应关系之后,还根据各个扬声器所对应的麦克风之间的重叠率对麦克风和扬声器进一步执行区域分组和确认,从而进一步实现了多个麦克风与多个扬声器之间的自动组网,降低了用户配置难度,提高了用户体验。
另外,在区域分组成功的情况下,为了日后给用户提供更人性化的声音服务,还可以进一步确认哪些麦克风与哪些扬声器距离最近,为此,在本发明的一个实施例中,如图6所示,在确定第一扬声器、第二扬声器和重叠的麦克风属于第三区域分组之后,还包括:
S210,获取第一扬声器和第二扬声器轮流以第四声音强度播放的第七声波数据,其中,第四声音强度小于第三声音强度。
S220,当判断第三区域分组中的一个麦克风接收的第八声波数据与第七声波数据匹配时,确定一个麦克风为与第一扬声器和第二扬声器距离最近的麦克风。
也就是说,控制中心通过控制同一区域分组内的各个扬声器轮流发出微弱音量V4的声波数据,同时控制同一区域分组内的各个麦克风接收该声波数据,并判断各个麦克风接收到的声波数据是否正确,如果判断麦克风接收到的声波数据正确,则说明该麦克风与发声的扬声器距离较近,否则,该麦克风与发声的扬声器距离较远,从而有效判断出与各个扬声器最接近的麦克风,为人性化的声音服务奠定基础。
此外,如图7所示,上述的多设备之间的分组方法还包括:
S230,当任意一个麦克风接收到第九声波数据时,确定任意一个麦克风所属的区域分组。
S240,判断所属的区域分组中是否存在检测到人体的人体检测传感器。
S250,若存在检测到人体的人体检测传感器,则判断人体检测传感器和任意一个麦克风属于相同的区域分组。
也就是说,人体检测传感器的分组可以是在日后人与控制中心进行交互时自动匹配分组。具体地,当人与控制中心发生语音交互时,控制中心会检测多个人体检测传感器中有哪些传感器感应到人的存在,从而暂时认为检测到人存在的人体检测传感器属于同一组。如图8所示,多设备之间的分组方法可包括以下步骤:
S801,人与控制中心发生语音指令的交互。
S802,控制中心判断人的声音来自麦克风x,麦克风x在区域A内。
S803,同时控制中心判断哪个人体检测传感器检测到人体。
S804,判断第一人体检测传感器是否检测到人体。如果是,执行步骤S805;如果否,执行步骤S806。
S805,该传感器与麦克风x可能在同一组。
S806,判断第二人体检测传感器是否检测到人体。如果是,执行步骤S807;如果否,执行步骤S808。
S807,该传感器与麦克风x可能在同一组。
S808,判断第N人体检测传感器是否检测到人体。如果是,执行步骤S809;如果否,判断结束。
S809,该传感器与麦克风x可能在同一组。
当多次不同时间发生的语音交互都能够检测到同一人体检测传感器有效时,则认为该传感器与麦克风属于相同的区域分组,从而避免了误判。
根据本发明实施例的多设备之间的分组方法,首先通过声波的发送和接收进行麦克风与扬声器的分组,再通过日后与人的交互进行人体检测传感器的自学习分组,分组内容包括哪些麦克风、扬声器、人体检测传感器属于同一组,以及对应某个扬声器相对较近的麦克风有哪些,从而在多个扬声器、多个麦克风和多个人体检测传感器的情况下,通过自学习的方法自动将扬声器、麦克风、人体检测传感器进行区域分组,进而实现多个麦克风、多个扬声器和多个人体检测传感器之间的自动组网,降低了用户配置难度,提高了用户体验。
图9是根据本发明一个实施例的多设备之间的分组装置的框图。如图9所示,多设备之间的分组装置包括:第一获取模块10、第二获取模块20和匹配模块30。
其中,第一获取模块10用于获取第一扬声器以第一音量强度播放的第一声波数据,第二获取模块20用于获取至少一个第一麦克风接收的第二声波数据,匹配模块30用于在第二声波数据和第一声波数据匹配时,确定第一扬声器和至少一个第一麦克风属于第一区域分组。
根据本发明的一个实施例,匹配模块30还用于:在第二声波数据和第一声波数据不匹配时,确定第一扬声器和至少一个麦克风属于不同的区域分组。
具体地,如图2所示,在用户家中,当进行区域分组时,可以先关闭所有房间门,然后一键控制多设备之间的分组装置进入自动配置模式,此时可先控制用户家中的第一扬声器发出第一音量强度V1的第一声波数据,第一获取模块10获取该声波数据并发送给匹配模块30,然后控制用户家中的各个麦克风接收该声波数据,各个麦克风将接收到的声波数据(第二声波数据)上传至分组装置中的第二获取模块20,第二获取模块20将获取的第二声波数据发送给匹配模块30。匹配模块30判断各个麦克风接收到的声波数据是否与第一扬声器发出的第一声波数据相匹配,即判断各个麦克风接收到的声音波形与第一扬声器发出的声音波形是否相同,如果是,匹配模块30则确定该麦克风与第一扬声器属于同一区域,即属于第一区域分组;如果否,匹配模块30则确定该麦克风与第一扬声器属于不同的区域分组,从而得到第一扬声器与多个麦克风之间的关系。然后关闭第一扬声器,并逐个判断剩余扬声器与各个麦克风之间的关系,从而得到房间中每个扬声器与各个麦克风之间的关系,进而实现多个麦克风与多个扬声器之间的自动组网,降低用户配置难度,提高用户体验。
根据本发明实施例的多设备之间的分组装置,通过第一获取模块获取第一扬声器以第一音量强度播放的第一声波数据,通过第二获取模块获取至少一个第一麦克风接收的第二声波数据,匹配模块在第二声波数据和第一声波数据匹配时,确定第一扬声器和至少一个第一麦克风属于第一区域分组,从而可以得到一个扬声器对应多个麦克风的关系,进而能够实现多个麦克风与多个扬声器之间的自动组网,降低用户配置难度,提高用户体验。
根据本发明的一个实施例,第二扬声器和至少一个第二麦克风属于第二区域分组,当至少一个第一麦克风和至少一个第二麦克风的重叠率达到预设阈值时,第一获取模块10还用于获取第一扬声器和第二扬声器分别以第二音量强度播放的第三声波数据,其中,第二音量强度大于第一音量强度;第二获取模块20还用于获取重叠的麦克风接收的第四声波数据;匹配模块30还用于在第四声波数据和第三声波数据匹配时,确定第一扬声器、第二扬声器和重叠的麦克风属于第三区域分组。
具体地,如图3所示,当两个不同的扬声器(如第一扬声器和第二扬声器)所对应的麦克风的重叠率达到预设阈值n%时,则认为有可能是两个扬声器在同一个区域内,此时将两个扬声器的音量强度调大,然后判断重叠的麦克风是否能够接收到正确的声波数据。即,分别控制第一扬声器和第二扬声器发出第二音量强度V2的第三声波数据,第一获取模块10获取该声波数据,同时控制重叠的麦克风接收该声波数据,麦克风将接收到的声波数据(第四声波数据)上传至第二获取模块20。匹配模块30判断重叠的麦克风接收到的声波数据是否与第三声波数据相匹配,如果是,匹配模块30则确定重叠的麦克风与第一扬声器和第二扬声器属于同一区域,即属于第三区域分组。
进一步地,为了保证区域分组的准确性,在本发明的一个实施例中,如图10所示,第一获取模块10还用于获取第一扬声器和第二扬声器同时以第三声音强度播放的第五声波数据,其中,第三声音强度小于第一声音强度;第二获取模块20还用于获取重叠的麦克风接收声音的第六声波数据;分组装置还包括验证模块40,验证模块40用于在第六声波数据和第五声波数据匹配时,判断第三区域分组验证通过。
也就是说,在实现第三区域分组后,还控制第一扬声器和第二扬声器同时发出温和音量V3的声波数据,然后验证模块40判断重叠的麦克风是否都能够正确接收到,如果是,验证模块40则判断第三区域分组成功,即第三区域分组验证通过,从而实现了多个麦克风与多个扬声器之间的自动组网,降低了用户配置难度,提高了用户体验。
根据本发明实施例的多设备之间的分组装置,在得到每个扬声器与各个麦克风之间的对应关系之后,还根据各个扬声器所对应的麦克风之间的重叠率对麦克风和扬声器进一步执行区域分组和确认,从而进一步实现了多个麦克风与多个扬声器之间的自动组网,降低了用户配置难度,提高了用户体验。
另外,在区域分组成功的情况下,为了日后给用户提供更人性化的声音服务,还可以进一步确认哪些麦克风与哪些扬声器距离最近,为此,在本发明的一个实施例中,如图10所示,第一获取模块10还用于获取第一扬声器和第二扬声器轮流以第四声音强度播放的第七声波数据,其中,第四声音强度小于第三声音强度;分组装置还包括第一判断模块50,第一判断模块50用于当判断第三区域分组中的一个麦克风接收的第八声波数据与第七声波数据匹配时,确定一个麦克风为与第一扬声器和第二扬声器距离最近的麦克风。
也就是说,通过控制同一区域分组内的各个扬声器轮流发出微弱音量V4的声波数据,同时控制同一区域分组内的各个麦克风接收该声波数据,并通过第一判断模块50判断各个麦克风接收到的声波数据是否正确,如果第一判断模块50判断麦克风接收到的声波数据正确,则说明该麦克风与发声的扬声器距离较近,否则,该麦克风与发声的扬声器距离较远,从而有效判断出与各个扬声器最接近的麦克风,为人性化的声音服务奠定基础。
此外,在本发明的一个实施例中,上述的分组装置还包括:确定模块和第二判断模块(图中均未具体示出),其中,确定模块用于当任意一个麦克风接收到第九声波数据时,确定任意一个麦克风所属的区域分组,第二判断模块用于判断所属的区域分组中是否存在检测到人体的人体检测传感器,并在判断存在检测到人体的人体检测传感器时,判断人体检测传感器和任意一个麦克风属于相同的区域分组。
也就是说,人体检测传感器的分组可以是在人与分组装置进行交互时自动匹配分组。具体地,如图8所示,当人与分组装置发生语音交互时,分组装置的第二判断模块会检测多个人体检测传感器中有哪些传感器感应到人的存在,从而暂时认为检测到人存在的人体检测传感器属于同一组。当多次不同时间发生的语音交互都能够检测到同一人体检测传感器有效时,则认为该传感器与麦克风属于相同的区域分组,从而避免了误判。
根据本发明实施例的多设备之间的分组装置,首先通过声波的发送和接收进行麦克风与扬声器的分组,再通过日后与人的交互进行人体检测传感器的自学习分组,分组内容包括哪些麦克风、扬声器、人体检测传感器属于同一组,以及对应某个扬声器相对较近的麦克风有哪些,从而在多个扬声器、多个麦克风和多个人体检测传感器的情况下,通过自学习的方法自动将扬声器、麦克风、人体检测传感器进行区域分组,进而实现多个麦克风、多个扬声器和多个人体检测传感器之间的自动组网,降低了用户配置难度,提高了用户体验。
在本发明的描述中,需要理解的是,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系,除非另有明确的限定。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!