一种应用故障快速定位的方法及装置与流程
本发明涉及一种应用故障定位的方法及装置,尤其是指一种应用故障快速定位的方法及装置。
背景技术:
随着微服务技术的发展,当前主流企业应用架构从单体架构逐步向分布式架构转移;而分布式架构通常伴随着复杂、大规模的集群实现,部署在成百上千服务器上,横跨多个不同数据中心,在给应用带来架构便利的同时,挑战也随之产生。当系统出现问题时,如何在成百上千个相关的、依赖关系错综复杂的服务系统之中快速定位到出错的系统。
传统运维在出现故障时,完全靠维护人员的经验,故障解决效率低;故障出现后很难快速、准确地找到根本原因;没有系统级的历史数据可供查看,无法评估系统运行状态;传统运维虽然也有各个模块服务的日志记录,但分析单个组件查找系统故障点需要耗费大量的人力成本和时间成本,系统复杂度越高,就需要更长的时间来查找原因。在某些情况下我们甚至可能无法查找系统故障点,另外传统的监控都采用折线图/柱状图等形式来展现监控的指标信息,无法看出服务之间的关系等信息。
技术实现要素:
本发明所要解决的技术问题是:提供一种应用故障快速定位的方法及装置。
为了解决上述技术问题,本发明采用的技术方案为:一种应用故障快速定位的方法,包括步骤,
s10、在指定的采样时间内采集应用节点响应的总次数、满足满意时间要求的应用节点响应的次数以及满足可容忍时间要求的应用节点响应的次数;
s20、在指定的采样时间内统计发生应用响应的错误次数,计算出应用响应的错误率;
s30、根据应用节点响应的总次数、满足满意时间要求的应用节点响应的次数、满足可容忍时间要求的应用节点响应的次数以及应用响应的错误率,计算出应用节点的健康度;
s40、将各个应用节点的健康度转换为对应的颜色来表示不同的健康度;
s50、将各层级的应用节点的健康度级联。
进一步的,所述步骤s30具体包括:
根据应用节点响应的总次数、满足满意时间要求的应用节点响应的次数、满足可容忍时间要求的应用节点响应的次数,计算出应用节点的满意度;
根据应用节点的满意度、应用响应的错误率,计算出应用节点的健康度。
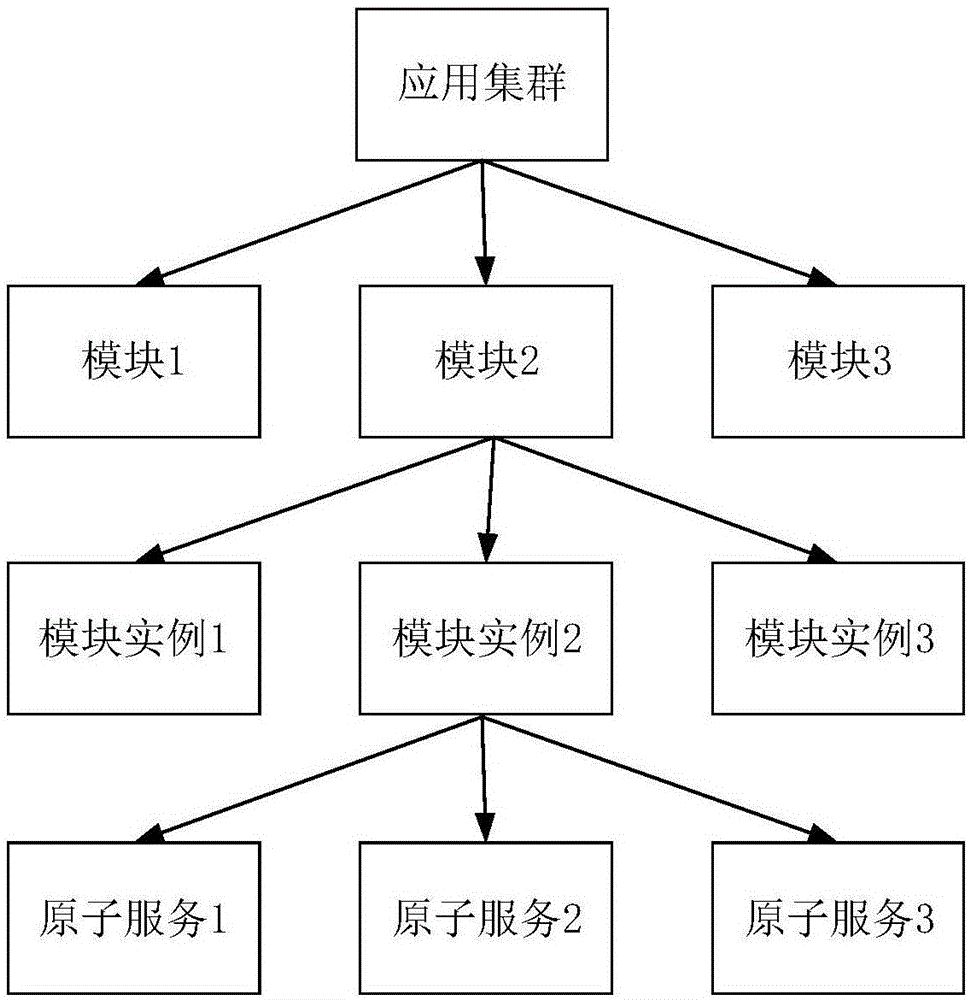
进一步的,所述应用节点按上级到下级的关系依次包括:应用集群节点、模块节点、模块实例节点、原子服务节点。
进一步的,所述方法还包括,当上级的应用节点的健康度出现问题时,点击对应的上级的应用节点往下查找出现性能问题的原子服务节点。
一种应用故障快速定位的装置,包括,
应用节点响应模块,用于在指定的采样时间内采集应用节点响应的总次数、满足满意时间要求的应用节点响应的次数以及满足可容忍时间要求的应用节点响应的次数;
错误率计算模块,用于在指定的采样时间内统计发生应用响应的错误次数,计算出应用响应的错误率;
健康度计算模块,用于根据应用节点响应的总次数、满足满意时间要求的应用节点响应的次数、满足可容忍时间要求的应用节点响应的次数以及应用响应的错误率,计算出应用节点的健康度;
健康度表示模块,用于将各个应用节点的健康度转换为对应的颜色来表示不同的健康度;
级联模块,用于将各层级的应用节点的健康度级联。
进一步的,所述健康度计算模块包括:
满意度计算单元,用于根据应用节点响应的总次数、满足满意时间要求的应用节点响应的次数、满足可容忍时间要求的应用节点响应的次数,计算出应用节点的满意度;
健康度计算单元,用于根据应用节点的满意度、应用响应的错误率,计算出应用节点的健康度。
进一步的,所述应用节点按上级到下级的关系依次包括:应用集群节点、模块节点、模块实例节点、原子服务节点。
进一步的,所述装置还包括故障定位模块,用于当上级的应用节点的健康度出现问题时,点击对应的上级的应用节点往下查找出现性能问题的原子服务节点。
本发明的技术效果在于:通过计算应用节点的健康度,将健康度转换为颜色来表示,并将各层级应用节点的健康度级联,以方便运维人员更快地发现异常的应用节点,当上级的健康度出现异常时,运维人员可通过点击该节点向下查找到具体出现异常的节点,实现应用异常的快速定位。
附图说明
下面结合附图详述本发明的具体结构。
图1为本发明的级联层级示意图;
图2为本发明的实时计算引擎结构图。
具体实施方式
为详细说明本发明的技术内容、构造特征、所实现目的及效果,以下结合实施方式并配合附图详予说明。
技术方案关键术语定义:
应用集群:代表应用全部运行的服务节点,是拓扑图的顶层视图,能够直观看到整体应用的性能情况。
模块:代表某个功能模块,同一个模块提供相同的功能服务。
模块实例:模块部署到具体的物理主机上,形成模块实例,一个模块可以部署多个实例,一般可以用ip+port就代表一个唯一的服务实例。
原子服务:应用程序或组件开放的原子能力,能够被外部或内部感知和调用,对应具体一个api接口。
节点:代表模型分层中的模型节点,可以是集群、模块、实例、服务中的任何一种。
apdex:用于衡量应用性能满意度。apdex定义了应用响应时间的最优门槛为t,另外根据应用响应时间结合t定义了三种不同的性能表现:
满意时间:应用响应时间低于或等于t(t由性能评估人员根据预期性能要求确定),比如t为1.5s,则一个耗时1s的响应结果则可以认为是满足满意要求的。
可容忍时间:应用响应时间大于t,但同时小于或等于4t。假设应用设定的t值为1s,则4*1=4秒极为应用响应时间的容忍上限。
frustrated(烦躁期):应用响应时间大于4t。
一种应用故障快速定位的方法,包括步骤,
s10、在指定的采样时间内采集应用节点响应的总次数、满足满意时间要求的应用节点响应的次数以及满足可容忍时间要求的应用节点响应的次数;
s20、在指定的采样时间内统计发生应用响应的错误次数,计算出应用响应的错误率;
s30、根据应用节点响应的总次数、满足满意时间要求的应用节点响应的次数、满足可容忍时间要求的应用节点响应的次数以及应用响应的错误率,计算出应用节点的健康度;
s40、将各个应用节点的健康度转换为对应的颜色来表示不同的健康度;
s50、将各层级的应用节点的健康度级联。
本技术方案中,本发明通过多级有向图实现应用快速故障定位,通过多个维度来系统的展示整个应用的性能健康程度,局部小的性能问题通过模型关系反应到整体性能监控拓扑图形中,并支持逐级展开从而快速定位到具体的故障点。
整体模型图主要从模型层级关系、健康度、调用关系、时间段四个维度来展示:
如图1所示应用节点层级,模型层级主要分为四层,应用集群->模块->实例(进程)->原子服务,上级将反应下级节点的整体性能健康状态,当某个下级的原子服务出现性能问题时,将反向向上传递状态信息。同一个时刻只能看到某一层级的图形,通过点击上级节点实现模型层级的逐步展开,比如当发现某个集群存在健康问题时,我们可以双击该集群节点,图形将展开显示该集群节点下的各个模块,如果发现某个模块有问题,双击该模块就会展开显示该模块下的实例信息。
健康度主要通过颜色来区分,当前系统健康度主要分为绿色、蓝色、红色、灰色四种颜色。其中绿色表示当前节点运行状态良好;蓝色表示当前节点无数据请求,但节点是正常运行的;红色表示当前节点存在性能问题,其中红色内部又分为1-9个档位,类似交通拥堵图,颜色越深表示当前节点性能问题越严重;灰色表示当前节点已宕机。
调用关系是分布式架构应用的重要特性,系统通过有向图来展示整个应用调用关系,当某个服务出现故障异常时,通过观察图形中的调用关系来追踪故障的根源。
时间维度主要是能追踪应用当前和历史的性能状况,当前时间主要关注应用的实时状态,图形显示当前点的性能状态;历史时间主要关注应用的环比状态,图形显示一段时间的统计性能状态。
实施例一
在一具体实施例中,所述步骤s30具体包括:
根据应用节点响应的总次数、满足满意时间要求的应用节点响应的次数、满足可容忍时间要求的应用节点响应的次数,计算出应用节点的满意度;
根据应用节点的满意度、应用响应的错误率,计算出应用节点的健康度。
本实施例中,应用节点的满意度计算公式为:
apdex=(satisfiedcount+toleratingcount/2)/totalsamples;
应用节点的满意度计算公式为:
健康度=(apdex+(1-错误率))/2;
其中satisfiedcount就是指定采样时间内响应时间满足satisfied要求的应用响应次数;而toleratingcount就是指定采样时间内响应时间满足tolerating要求的应用响应次数;最后的totalsamples就是总的采样次数总数。从公式可以看出,应用的apdex得分与采样持续时间无关,与目标响应时间t相关(在采用总数固定的情况下,t通过影响satisfiedcount以及toleratingcount的值间接影响最终的得分)。
从上述公式可以推断为了更准确的表达应用节点的健康度,需要事先准确的设置好t值,本系统通过统计各个原子服务的历史平均响应时间来自动设置t值,并根据最新采集的响应时间实时灵活的调整t值,实现一种自我调优的策略。
在计算出健康度后,我们通过性能档位表来衡量用何种颜色表达该节点的状态,档位越大,颜色越深。其中档位如下所示:
健康度>=90%:1档
80%<=健康度<90%:2档
70%<=健康度<80%:3档
60%<=健康度<70%:4档
50%<=健康度<60%:5档
40%<=健康度<50%:6档
30%<=健康度<40%:7档
20%<=健康度<30%:8档
健康度<20%:9档。
如图2所示的引擎架构,为了提升图形展现的效率,系统在采集原始性能指标的同时会实时的计算应用各个节点和各级别节点的健康度,实时计算引擎主要是采用开源的kafka和apachestorm来实现。
实施例二
在一具体实施例中,所述应用节点按上级到下级的关系依次包括:应用集群节点、模块节点、模块实例节点、原子服务节点。
进一步的,所述方法还包括,当上级的应用节点的健康度出现问题时,点击对应的上级的应用节点往下查找出现性能问题的原子服务节点。
本实施例中,应用节点包括四个层级,将四个层级的应用节点健康度对应的颜色级联起来;点击上一层级应用节点,能够打下下一层级,如果发现某个模块有问题,双击该模块就会展开显示该模块下的实例信息。
一种应用故障快速定位的装置,包括,
应用节点响应模块,用于在指定的采样时间内采集应用节点响应的总次数、满足满意时间要求的应用节点响应的次数以及满足可容忍时间要求的应用节点响应的次数;
错误率计算模块,用于在指定的采样时间内统计发生应用响应的错误次数,计算出应用响应的错误率;
健康度计算模块,用于根据应用节点响应的总次数、满足满意时间要求的应用节点响应的次数、满足可容忍时间要求的应用节点响应的次数以及应用响应的错误率,计算出应用节点的健康度;
健康度表示模块,用于将各个应用节点的健康度转换为对应的颜色来表示不同的健康度;
级联模块,用于将各层级的应用节点的健康度级联。
实施例三
在一具体实施例中,所述健康度计算模块包括:
满意度计算单元,用于根据应用节点响应的总次数、满足满意时间要求的应用节点响应的次数、满足可容忍时间要求的应用节点响应的次数,计算出应用节点的满意度;
健康度计算单元,用于根据应用节点的满意度、应用响应的错误率,计算出应用节点的健康度。
实施例四
在一具体实施例中,所述应用节点按上级到下级的关系依次包括:应用集群节点、模块节点、模块实例节点、原子服务节点。
进一步的,所述装置还包括故障定位模块,用于当上级的应用节点的健康度出现问题时,点击对应的上级的应用节点往下查找出现性能问题的原子服务节点。
本发明装置的实施例包含方法实施例的全部内容,具有与方法实施例相同的技术效果,因此不再对此进行赘述。
综上所述,本发明通过整合多维信息,模型层级关系、健康度、调用关系、时间段到一张拓扑图里,通过图形下钻来逐级展开模型层级,通过颜色来标示健康度,通过节点之间的连线标示调用关系,通过节点上的tps/rt等指标来标示时间段的指标统计信息,并结合实时分析引擎对原始数据进行汇聚计算,通过汇总的拓扑图就能完成系统异常的发现和定位;通过该图形,运维人员不需要做任何数据/日志的分析,便能通过观察拓扑图就能确定异常位置。同时通过有向关系图,应用管理人员或开发人员便能快速掌握并梳理出模块、服务之间的调用关系,有利于后续服务的治理优化工作。
此处第一、第二……只代表其名称的区分,不代表它们的重要程度和位置有什么不同。
此处,上、下、左、右、前、后只代表其相对位置而不表示其绝对位置。以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!