人源化抗MUC1*抗体和切割酶的用途的制作方法
本申请涉及人源化和非人抗MUC1*抗体及其制备和使用方法。本申请还涉及使用用切割酶转染或转导的免疫细胞来治疗癌症。本发明还涉及使用用CAR和另一种蛋白转染或转导的免疫细胞来治疗癌症。
背景技术:
我们以前发现切割形式的MUC1(SEQ ID NOS:1)跨膜蛋白是生长因子受体,其驱动超过75%的全部人类癌症的生长。切割形式的MUC1,我们称之为MUC1*(发音为muk 1star),是一种强大的生长因子受体。MUC1的大部分细胞外结构域的切割和释放揭示了用于激活配体二聚体NME1、NME6、NME7、NME7AB、NME7-X1或NME8的结合位点。它是癌症药物的理想靶标,因为它在超过75%的全部癌症中异常表达,并且可能在更高比例的转移性癌症中过表达(Mahanta et al.(2008)A Minimal Fragment of MUC1Mediates Growth of Cancer Cells.PLoS ONE 3(4):e2054.doi:10.1371/journal.pone.0002054;Fessler et al.(2009),“MUC1*is a determinant of trastuzumab(Herceptin)resistance in breast cancer cells,”Breast Cancer Res Treat.118(1):113-124)。在MUC1切割后,其大部分细胞外结构域从细胞表面脱落。剩余部分具有截短的细胞外结构域,包含称为PSMGFR(SEQ ID NOS:2)的大部分或全部主要生长因子受体序列。
抗体越来越多地用于治疗人类疾病。在非人物种中产生的抗体历来被用作人类的治疗剂,例如马抗体。最近,对抗体进行工程化或选择,使得它们主要含有人序列,以避免外来抗体的广泛排斥。将非人抗体识别片段工程为人抗体的过程通常称为“人源化”。用于替换人抗体序列的非人序列的量决定它们被称为嵌合的、人源化的还是全人的。
存在能够产生人源化或全人抗体的替代技术。这些策略涉及筛选人抗体或抗体片段的文库并鉴定与靶抗原结合的那些,而不是用抗原免疫动物。另一种方法是将抗体的可变区设计到抗体样分子里面。另一种方法涉及免疫人源化动物。本发明还旨在包括这些用抗体识别片段的使用方法,发明人已确定这些片段与MUC1*的细胞外结构域结合。
除了用抗体治疗患者之外,最近已经显示癌症免疫疗法在治疗血癌方面是有效的。一种称为CAR T(嵌合抗原受体T细胞)疗法的癌症免疫疗法,设计一种T细胞,使其表达具有识别肿瘤抗原的细胞外结构域的嵌合受体,以及T细胞的跨膜和胞质尾区(Dai H,Wang Y,Lu X,Han W.(2016)Chimeric Antigen Receptors Modified T-Cells for Cancer Therapy.J Natl Cancer Inst.108(7):djv439)。这种受体由识别肿瘤抗原的单链抗体片段(scFv)组成,与T细胞跨膜和信号传导结构域连接。在受体与癌症相关抗原结合后,传递信号,导致T细胞激活、增殖和靶向杀死癌细胞。在实践中,将患者的T细胞分离并用CAR转导、扩增,然后注射回患者体内。当患者的CAR T细胞与癌细胞上的抗原结合时,CAR T细胞扩增并攻击癌细胞。该方法的缺点是,当大多数癌抗原在一些健康组织上表达但在癌组织上过表达时,激活患者的免疫系统而破坏携带靶抗原的细胞的风险。为了最小化肿瘤外/靶上作用的风险,癌抗原应该在健康组织上最低限度地表达。
另一种癌症免疫疗法涉及BiTE(双特异性T细胞接合剂(Engagers))。BiTE方法试图消除CAR T相关的肿瘤外/靶上效应风险。与CAR T不同,BiTE是双特异性抗体,不应该比常规的基于抗体的疗法造成更大的风险。然而,与结合并阻断癌抗原的典型抗癌抗体不同,BiTE被设计成与肿瘤细胞上的抗原结合并同时与免疫细胞(例如T细胞)上的抗原结合。以这种方式,BiTE将T细胞募集到肿瘤中。BiTE是工程化蛋白,其同时结合癌相关抗原和T细胞表面蛋白,例如CD3ε。BiTE是通过将结合T细胞抗原的抗体的scFv(如抗CD3ε)与结合癌抗原的治疗性单克隆抗体的scFv遗传连接而制备的抗体(Patrick A.Baeuerle,and Carsten Reinhardt(2009)Bispecific T-cell engaging antibodies for cancer therapy.Cancer Res.69(12):4941-4944)。
技术实现要素:
在一个方面,本发明涉及结合MUC1同种型的细胞外结构域或缺乏串联重复结构域的切割产物的非人、人或人源化抗MUC1*抗体或抗体片段或抗体样蛋白。非人、人或人源化抗MUC1*抗体或抗体片段或抗体样蛋白可以特异性结合
(i)MUC1的PSMGFR区域;
(ii)PSMGFR肽;
(iii)具有SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:620)的氨基酸序列的肽;
(iv)具有SVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:621)的氨基酸序列的肽;
(v)具有VQLTLAFREGTINVHDVETQFNQY(SEQ ID NOS:622)的氨基酸序列的肽;或
(vi)具有SNIKFRPGSVVVQLTLAFREGTIN(SEQ ID NOS:623)的氨基酸序列的肽。
非人、人或人源化抗体可以是IgG1、IgG2、IgG3、IgG4或IgM。人或人源化抗体片段或抗体样蛋白可以是scFv或scFv-Fc。
如上所述的人或人源化抗体、抗体片段或抗体样蛋白可包含重链可变区和轻链可变区,重链可变区和轻链可变区衍生自小鼠单克隆MN-E6抗体,并且与小鼠单克隆MN-E6抗体具有至少80%、90%或95%或98%序列同一性。重链可变区可以与SEQ ID NOS:13具有至少90%或95%或98%的序列同一性,并且轻链可变区可以与SEQ ID NOS:66具有至少90%或95%或98%的序列同一性。
根据上文的人或人源化抗体、抗体片段或抗体样蛋白可以包括重链可变区和轻链可变区中的互补决定区(CDR),所述互补决定区与具有如下序列的CDR1、CDR2或CDR3区具有至少90%或95%或98%序列同一性:
CDR1重链SEQ ID NOS:17
CDR1轻链SEQ ID NOS:70,
CDR2重链SEQ ID NOS:21
CDR2轻链SEQ ID NOS:74,
CDR3重链SEQ ID NOS:25
CDR3轻链SEQ ID NOS:78。
上述人或人源化抗体、抗体片段或抗体样蛋白可包括重链可变区和轻链可变区,重链可变区和轻链可变区衍生自小鼠单克隆MN-C2抗体并且与小鼠单克隆MN-C2抗体具有至少80%、90%或95%或98%的序列同一性。重链可变区可以与SEQ ID NOS:119具有至少90%或95%或98%的序列同一性,并且轻链可变区与SEQ ID NOS:169具有至少90%或95%或98%的序列同一性。重链可变区和轻链可变区中的互补决定区(CDR)可以与具有如下序列的CDR1、CDR2或CDR3区具有至少90%或95%或98%的序列同一性:
CDR1重链SEQ ID NOS:123
CDR1轻链SEQ ID NOS:173,
CDR2重链SEQ ID NOS:127
CDR2轻链SEQ ID NOS:177,
CDR3重链SEQ ID NOS:131
CDR3轻链SEQ ID NOS:181。
如上所述的人或人源化抗体、抗体片段或抗体样蛋白可包括重链可变区和轻链可变区,重链可变区和轻链可变区衍生自小鼠单克隆MN-C3抗体并且可与小鼠单克隆MN-C3抗体具有至少80%、90%或95%或98%的序列同一性。重链可变区可以与SEQ ID NOS:414具有至少90%或95%或98%的序列同一性,并且轻链可变区可以与SEQ ID NOS:459具有至少90%或95%或98%的序列同一性。重链可变区和轻链可变区中的互补决定区(CDR)可以与具有如下序列的CDR1、CDR2或CDR3区具有至少90%或95%或98%的序列同一性:
CDR1重链SEQ ID NOS:418
CDR1轻链SEQ ID NOS:463,
CDR2重链SEQ ID NOS:422
CDR2轻链SEQ ID NOS:467,
CDR3重链SEQ ID NOS:426,
CDR3轻链SEQ ID NOS:471。
上述人或人源化抗体、抗体片段或抗体样蛋白可包括重链可变区和轻链可变区,重链可变区和轻链可变区衍生自小鼠单克隆MN-C8抗体并且与小鼠单克隆MN-C8抗体具有至少80%、90%或95%或98%的序列同一性。重链可变区可以与SEQ ID NOS:506具有至少90%或95%或98%的序列同一性,并且轻链可变区可以与SEQ ID NOS:544具有至少90%或95%或98%的序列同一性。重链可变区和轻链可变区中的互补决定区(CDR)可以与具有如下序列的CDR1、CDR2或CDR3区具有至少90%或95%或98%的序列同一性:
CDR1重链SEQ ID NOS:508
CDR1轻链SEQ ID NOS:546,
CDR2重链SEQ ID NOS:510
CDR2轻链SEQ ID NOS:548,
CDR3重链SEQ ID NOS:512,
CDR3轻链SEQ ID NOS:550。
另一方面,本发明涉及抗MUC1*细胞外结构域抗体,包括人源化IgG2重链或人源化IgG1重链代表的人源化MN-E6序列,其与人源化κ轻链或人源化λ轻链配对。人源化IgG2重链可以是SEQ ID NOS:53,人源化IgG1重链可以是SEQ ID NOS:57,人源化κ轻链可以是SEQ ID NOS:108,并且人源化λ轻链可以是SEQ ID NOS:112,或与之具有90%、95%或98%序列同一性的序列。
另一方面,本发明涉及抗MUC1*细胞外结构域抗体,包括人源化IgG1重链、人源化IgG2重链代表的人源化MN-C2序列,其与人源化λ轻链和人源化κ轻链配对。人源化IgG1重链MN-C2可以是SEQ ID NOS:159或IgG2重链可以是SEQ ID NOS:164(与λ轻链(SEQ ID NOS:219)或κ轻链(SEQ ID NOS:213)配对),或与之具有90%、95%或98%的序列同一性的序列。
另一方面,本发明涉及抗MUC1*细胞外结构域抗体,其包含人源化IgG1重链或人源化IgG2重链代表的人源化MN-C3序列,其与人源化λ轻链或人源化κ轻链配对。人源化MN-C3IgG1重链可以是SEQ ID NOS:454,IgG2重链可以是SEQ ID NOS:456,λ轻链可以是SEQ ID NOS:501,并且κ轻链可以是SEQ ID NOS:503,或与之具有90%、95%或98%的序列同一性的序列。
另一方面,本发明涉及抗MUC1*细胞外结构域抗体,包括人源化IgG1重链或人源化IgG2重链代表的人源化MN-C8的序列,其与人源化λ轻链或人源化κ轻链配对。人源化MN-C8IgG1重链可以是SEQ ID NOS:540,IgG2重链可以是SEQ ID NOS:542,λ轻链可以是SEQ ID NOS:580,并且κ轻链可以是SEQ ID NOS:582,或与之具有90%、95%或98%的序列同一性的序列。
另一方面,本发明涉及如上所述的人或人源化抗MUC1*抗体或抗体片段或抗体样蛋白,其抑制NME蛋白与MUC1*的结合。NME可以是NME1、NME6、NME7AB、NME7-X1、NME7或NME8。
在另一方面,本发明涉及单链可变片段(scFv),其包含通过接头连接的重链和轻链可变区,还包含与MUC1*细胞外结构域结合的抗体的CDR。CDR可以衍生自MN-E6、MN-C2、MN-C3或MN-C8抗体或其人源化抗体。scFv可以是具有SEQ ID NOS:233、235和237(E6);SEQ ID NOS:239、241和243(C2);SEQ ID NOS:245、247和249(C3);或SEQ ID NOS:251、253和255(C8)的一个。
在另一个方面,本发明涉及嵌合抗原受体(CAR),包含scFv或人源化可变区,其结合没有串联重复、连接分子、跨膜结构域和细胞质结构域的MUC1的细胞外结构域。单链抗体片段可以结合
(i)MUC1的PSMGFR区域,
(ii)PSMGFR肽,
(iii)具有氨基酸序列SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:620)的肽;
(iv)具有SVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:621)的氨基酸序列的肽;
(v)具有VQLTLAFREGTINVHDVETQFNQY(SEQ ID NOS:622)的氨基酸序列的肽;或
(vi)具有SNIKFRPGSVVVQLTLAFREGTIN(SEQ ID NOS:623)的氨基酸序列的肽。
在如上所述的CAR中,上文阐述和描述的任何可变区的部分或其组合可用于CAR的细胞外结构域。CAR还包含跨膜区和包含信令免疫系统激活的序列基序的胞质尾区。细胞外结构域可以包含MN-E6 scFv、MN-C2 scFv、MN-C3 scFv或MN-C8 scFv的非人或人源化单链抗体片段。
在如上所述的CAR中,细胞外结构域可包括如SEQ ID NOS:233、235或237)、MN-C2 scFv(SEQ ID NOS:239、241或243)、MN-C3 scFv(SEQ ID NOS:245、247或249)或MN-C8 scFv(SEQ ID NOS:251、253或255)所示的MN-E6 scFv的非人或人源化单链抗体片段。
在上述任何CAR中,胞质尾区可以包含信号传导序列基序CD3-ζ、CD27、CD28、4-1BB、OX40、CD30、CD40、ICAm-1、LFA-1、ICOS、CD2、CD5或CD7中的一种或多种。
在上述任何CAR中,序列可以是CARMN-E6 CD3z(SEQ ID NOS:295)、CARMN-E6 CD28/CD3z(SEQ ID NOS:298);CARMN-E6 4-1BB/CD3z(SEQ ID NOS:301);CARMN-E6 OX40/CD3z(SEQ ID NOS:617);CARMN-E6 CD28/4-1BB/CD3z(SEQ ID NOS:304);CARMN-E6 CD28/OX40/CD3z(SEQ ID NOS:619);CAR MN-C2 CD3z(SEQ ID NOS:607);CAR MN-C2 CD28/CD3z(SEQ ID NOS:609);CAR MN-C2 4-1BB/CD3z(SEQ ID NOS:611和SEQ ID NOS:719);CAR MN-C2OX40/CD3z(SEQ ID NOS:613);CAR MN-C2CD28/4-1BB/CD3z(SEQ ID NOS:307);CAR MN-C2 CD28/OX40/CD3z(SEQ ID NOS:615)或CAR MN-C3 4-1BB/CD3z(SEQ ID NOS:601)。
在另一方面,CAR可具有识别肽的细胞外结构域单元。肽可以是PSMGFR(SEQ ID NOS:2)。肽可以是衍生自NME7的肽。肽可以是
NME7A肽1(A结构域):MLSRKEALDFHVDHQS(SEQ ID NOS:7);
NME7A肽2(A结构域):SGVARTDASES(SEQ ID NOS:8);
NME7B肽1(B结构域):DAGFEISAMQMFNMDRVNVE(SEQ ID NOS:9);
NME7B肽2(B结构域):EVYKGVVTEYHDMVTE(SEQ ID NOS:10);或
NME7B肽3(B结构域):AIFGKTKIQNAVHCTDLPEDGLLEVQYFF(SEQ ID NOS:11)。
另一方面,本发明涉及一种组合物,包含至少两种具有转染到相同细胞中的不同细胞外结构域单元的CAR。
所述至少两种CAR可具有一种不具有肿瘤抗原靶向识别单元的CAR,和另一种具有肿瘤抗原靶向识别单元的CAR。在本发明的另一个方面,细胞外结构域识别单元中的一种可以结合MUC1*细胞外结构域。在本发明的另一个方面,细胞外结构域识别单元中的一种可以是抗体片段并且另一种是肽,可以没有跨膜和信号传导基序;肽可以是单链抗体片段。在本发明的另一个方面,识别单元中的一种可以结合PD-1或PDL-1。在本发明的另一个方面,一种细胞外结构域识别单元是选自MN-E6抗体的scFv、MN-C2抗体的scFv、MN-C3抗体的scFv或MN-C8抗体的scFv的组中的抗MUC1*scFv,另一种是衍生自NME7或选自以下组成的组的肽:
NME7A肽1(A结构域):MLSRKEALDFHVDHQS(SEQ ID NOS:7);
NME7A肽2(A结构域):SGVARTDASES(SEQ ID NOS:8);
NME7B肽1(B结构域):DAGFEISAMQMFNMDRVNVE(SEQ ID NOS:9);
NME7B肽2(B结构域):EVYKGVVTEYHDMVTE(SEQ ID NOS:10);和
NME7B肽3(B结构域):AIFGKTKIQNAVHCTDLPEDGLLEVQYFF(SEQ ID NOS:11)。
另一方面,本发明涉及包含CAR的细胞,所述CAR具有细胞外结构域,所述细胞外结构域结合没有串联重复的MUC1分子的细胞外结构域。另一方面,本发明涉及包含CAR的细胞,所述CAR具有与MUC1*转染或转导的细胞结合的细胞外结构域。包含CAR的细胞可以是免疫系统细胞,优选T细胞、自然杀伤细胞(NK)、树突细胞或肥大细胞。
另一方面,本发明涉及工程化抗体样蛋白。
另一方面,本发明涉及筛选那些与如下结合的人抗体或抗体片段文库的方法:
(i)PSMGFR肽;
(ii)具有氨基酸序列SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:620)的肽;
(iii)具有SVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:621)的氨基酸序列的肽;
(iv)具有VQLTLAFREGTINVHDVETQFNQY(SEQ ID NOS:622)的氨基酸序列的肽;
(v)具有SNIKFRPGSVVVQLTLAFREGTIN(SEQ ID NOS:623)的氨基酸序列的肽;
(vi)NME7蛋白;或
(vii)NME7蛋白的肽片段。
另一方面,本发明涉及治疗受试者疾病的方法,包括向患有该疾病的人给予根据上述任一权利要求的抗体,其中所述受试者异常表达MUC1。该疾病可以是癌症,例如乳腺癌、卵巢癌、肺癌、结肠癌、胃癌或食道癌。
另一方面,本发明涉及治疗受试者疾病的方法,包括向患有该疾病的人给予NME肽,其中所述受试者异常表达MUC1。
另一方面,本发明涉及增殖或扩增干细胞群的方法,包括根据上述任何方法或组合物使细胞与抗体接触。
另一方面,本发明涉及促进干细胞附着于表面的方法,包括用人源化MN-C3或MN-C8抗体、其抗体片段或单链抗体包被表面并使干细胞与表面接触。
另一方面,本发明涉及体外或体内递送干细胞的方法,包括用人源化MN-C3或MN-C8抗体、其抗体片段或单链抗体包被表面,使干细胞与表面接触并将干细胞递送到特定位置的步骤。
另一方面,本发明涉及分离干细胞的方法,包括用人源化MN-C3或MN-C8抗体、其抗体片段或单链抗体包被表面,并使混合的细胞群与表面接触和分离干细胞的步骤。
另一方面,本发明涉及包含衍生自抗体的可变结构域片段的scFv,所述抗体结合MUC1同种型的细胞外结构域或缺乏串联重复结构域的切割产物。可变结构域片段可以衍生自小鼠单克隆抗体MN-E6(SEQ ID NOS:13和66)或衍生自人源化MN-E6(SEQ ID NOS:39和94),或衍生自MN-E6 scFv(SEQ ID NOS:233、235和237)。或者,可变结构域片段可以衍生自小鼠单克隆抗体MN-C2(SEQ ID NOS:119和169)或衍生自人源化的MN-C2(SEQ ID NOS:145和195),或衍生自MN-C2 scFv(SEQ ID NOS:239、241和243)。或者,可变结构域片段可以衍生自小鼠单克隆抗体MN-C3(SEQ ID NOS:414和459)或衍生自人源化的MN-C3(SEQ ID NOS:440和487),或衍生自MN-C3 scFv(SEQ ID NOS:245、247和249)。或者,可变结构域片段可以衍生自小鼠单克隆抗体MN-C8(SEQ ID NOS:505和544)或衍生自人源化的MN-C8(SEQ ID NOS:526和566),或衍生自MN-C8 scFv(SEQ ID NOS:251、253、255)。
另一方面,本发明涉及治疗被诊断患有、怀疑患有或有发展MUC1或MUC1*阳性癌症风险的人的方法,包括给予该人有效量的上述scFv。
另一方面,本发明涉及包含如上所述的scFv的scFv-Fc构建体。scFv-Fc可以二聚化。可以突变Fc组分以使scFv-Fc是单体的。突变可以包括突变或缺失Fc上的铰链区,在由SEQ ID NO:281、279、285和287表示的Fc上做F405Q、Y407R、T366W/L368W或T364R/L368R突变或其组合。
另一方面,本发明涉及包含至少两种不同scFv序列的多肽,其中scFv序列中的一种是结合MUC1同种型的细胞外结构域或缺乏串联重复结构域的切割产物的序列。多肽可以结合(i)MUC1的PSMGFR区域;
(ii)PSMGFR肽;
(iii)具有SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:620)的氨基酸序列的肽;
(iv)具有VQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:621)的氨基酸序列的肽;
(v)具有VQLTLAFREGTINVHDVETQFNQY(SEQ ID NOS:622)的氨基酸序列的肽;或
(vi)具有SNIKFRPGSVVVQLTLAFREGTIN(SEQ ID NOS:623)的氨基酸序列的肽。
多肽可以结合免疫细胞(例如T细胞)上的受体,特别是T细胞上的CD3。
另一方面,本发明涉及检测表达MUC1*异常的细胞的存在的方法,包括使细胞样品与上述scFv-Fc接触并检测scFv-Fc与细胞的结合的存在。细胞可以是癌细胞。
另一方面,本发明涉及一种用于测试受试者癌症与用包含MN-E6、MN-C2、MN-C3或MN-C8的可变区部分的组合物治疗的适用性,包括使来自患者的身体样本与相应的MN-E6 scFv-Fc、MN-C2 scFv-Fc、MN-C3 scFv-Fc或MN-C8 scFv-Fc接触的步骤。
另一方面,本发明涉及治疗患有疾病的受试者的方法,包括将来自受试者的T细胞暴露于MUC1*肽,其中通过多轮次的成熟,T细胞发育MUC1*特异性受体,产生适应的T细胞,并且将适应的T细胞扩增和给予于被诊断患有、怀疑患有或有发展MUC1*阳性癌症风险的供体患者。
在一个方面,本发明可以涉及用于治疗癌症的用切割酶转染或转导的免疫细胞。癌症可能是MUC1阳性癌症。免疫细胞可以是T细胞。免疫细胞可以衍生自待治疗的患者。切割酶可以是MMP或ADAM家族成员。切割酶可以是MMP2、MMP9、MMP3、MMP14、ADAM17、ADAM28或ADAM TS16。
另一方面,本发明可以涉及用CAR转染或转导的免疫细胞,其中其细胞外结构域包含与没有串联重复的MUC1分子的细胞外结构域结合的抗体scFv。
另一方面,本发明可以涉及用于治疗癌症的用切割酶转染或转导的免疫细胞。癌症可以是MUC1阳性癌症。免疫细胞可以是T细胞。免疫细胞可以是NK细胞。切割酶可以是切割MUC1使得串联重复结构域与跨膜结构域分离的任何酶。这种切割酶包括但不限于MMP1、MMP2、MMP3、MMP7、MMP8、MMP9、MMP11、MMP12、MMP13、MMP14、MMP16、ADAM9、ADAM10、ADAM17、ADAM19、ADAMTS16、ADAM28或其催化活性片段。可以用切割酶的激活剂进一步转染或转导免疫细胞。切割酶可以是但不限于MMP2或MMP9或ADAM17,并且切割酶MMP2和MMP9的激活剂可以分别是MMP14和MMP3。编码切割酶的核酸可以与诱导型启动子连接。切割酶的表达可以通过在免疫细胞对靶肿瘤细胞产生免疫应答时特异性地发生的事件诱导。在本发明的一个方面,切割酶切割MUC1,使得切割产物被特异性识别癌组织上切割的MUC1的抗体识别。在一个方面,特异性识别癌组织上的切割的MUC1的抗体与癌组织的结合将是至少两倍于抗体与健康组织的结合(当T细胞正常运输时)。
另一方面,本发明可以涉及用包含抗体片段的CAR和切割酶转染或转导的用于治疗癌症的免疫细胞。癌症可以是MUC1阳性癌症。免疫细胞可以是T细胞。T细胞上CAR的抗体片段可以将细胞导向MUC1*阳性肿瘤。T细胞上的CAR的抗体片段可以识别被特异性切割酶切割后的MUC1的形式。CAR的抗体片段可以衍生自MNC2或MNE6,并且切割酶可以是MMP9、MMP2或ADAM17,或MMP9、MMP2或ADAM17的激活形式。可以用切割酶的激活剂进一步转染或转导免疫细胞。切割酶可以是MMP2或MMP9或ADAM17,切割酶MMP2和MMP9的激活剂可以分别是MMP14和MMP3。编码切割酶的核酸可以与诱导型启动子连接。切割酶的表达可以通过在免疫细胞对靶肿瘤细胞产生免疫应答时特异性地发生的事件诱导。抗体片段可识别当切割酶切割MUC1或MUC1*时产生的MUC1或MUC1*形式。当CAR的抗体片段与肿瘤上的MUC1或MUC1*接合或结合时,可以诱导由诱导型启动子对切割酶的表达。
另一方面,本发明涉及治疗患者癌症的方法,包括给予患者任何上述免疫细胞,联合检查点抑制剂。
从以下对本发明的描述、所附的参考附图和所附的权利要求将更全面地理解本发明的这些和其它目的。
附图说明
从以下给出的详细描述和附图中将更全面地理解本发明,这些附图仅以说明的方式给出,因此不是对本发明的限制,并且其中:
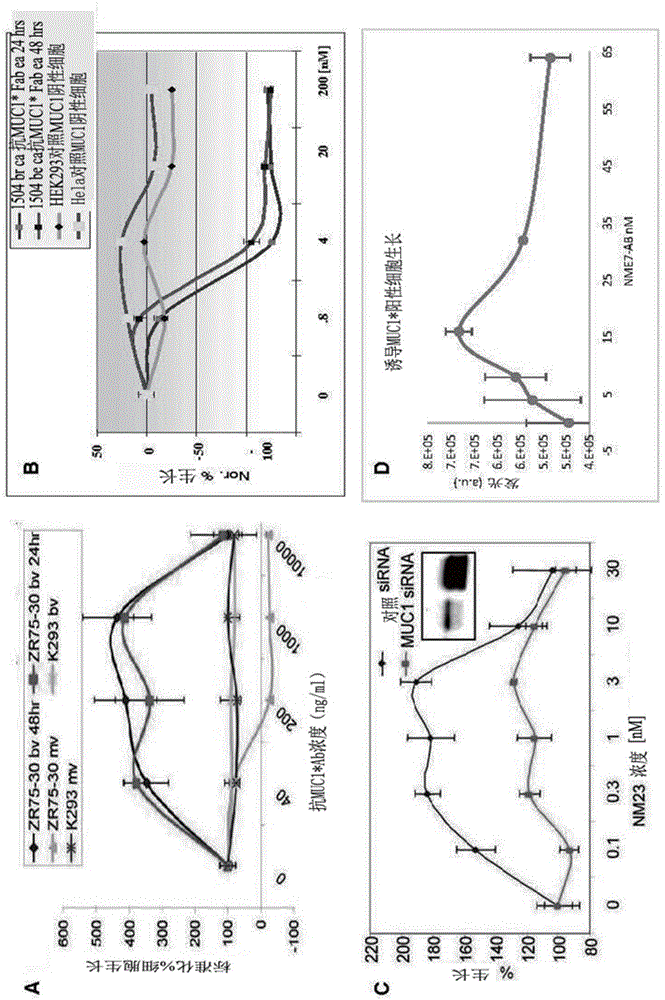
图1A-1D显示用二价'bv'抗MUC1*抗体、单价'mv'或Fab、NM23-H1二聚体或NME7-AB处理的MUC1*阳性细胞的细胞生长测定图。二价抗MUC1*抗体刺激癌细胞的生长,而单价Fab抑制生长(A、B)。经典的钟形曲线表明配体诱导的二聚化刺激生长。二聚体NM23-H1(又名NME1)刺激MUC1*阳性癌细胞的生长,但抑制MUC1表达的siRNA消除其作用(C)。NME7-AB还刺激MUC1*阳性细胞的生长(D)。
图2A-2F显示了ELISA测定的结果。MUC1*肽PSMGFR、从N末端减去10个氨基酸的PSMGFR(又名N-10)、或从C末端减去10个氨基酸的PSMGFR(又名C-10)固定在平板上,测定与以下的结合:NME7-AB(A)、MN-C2单克隆抗体(B)、MN-E6单克隆抗体(C)或二聚体NME1(D)。这些测定显示NME1、NME7-AB和单克隆抗体MN-C2和MN-E6都需要MUC1*细胞外结构域的第一膜近端10个氨基酸来结合。从N末端减去10个氨基酸的MUC1*肽PSMGFR(又名N-10)、或从C末端减去10个氨基酸的PSMGFR(又名C-10)固定在平板上,测定与以下的结合:MN-C3(E)和MN-C8(F)。
图3A-3C显示了竞争性ELISA测定的结果。将PSMGFR MUC1*肽固定在平板上,并且单独或在添加MN-E6抗体后添加二聚体NM23-H1(又名NME1)(A)。进行相同的实验,其中单独或在添加MN-E6后添加NM23-H7、NME7-AB(B)。结果显示MN-E6竞争性抑制MUC1*激活配体NME1和NME7的结合。在类似的实验(C)中,将PSMGFR或从N末端减去10个氨基酸的PSMGFR(又名N-10)固定在平板上。然后添加二聚体NM23-H1。然后测试抗MUC1*抗体MN-E6、MN-C2、MN-C3或MN-C8的竞争掉NM23-H1的能力。结果显示尽管所有三种抗体都与PSMGFR肽结合,但MN-E6和MN-C2竞争性地抑制MUC1*激活配体的结合。
图4A-4F显示特异性结合MUC1*阳性癌细胞和MUC1*转染细胞但不结合MUC1*或MUC1阴性细胞的抗MUC1*抗体的FACS扫描。ZR-75-1(又名1500)、MUC1*阳性乳腺癌细胞用1.5μg/ml人源化MN-C2的1:2或1:10稀释液染色。洗涤两次后,细胞用二抗,即缀合有Alexa 488(Qiagen)的抗5-His抗体的1:200(A)、1:50(B)或1:10(C)稀释液染色,以检测huMN-C2 scFv上的6x His标签。流式细胞术分析显示细胞亚群的浓度依赖性移位(表明特异性结合),这在没有MN-C2 scFv(A-C)的情况下是未见的。在另一种情况中,MN-E6用于染色用空载体转染的MUC1阴性HCT-116结肠癌细胞、单细胞克隆#8(D)、用MUC1*单细胞克隆#10转染的HCT-116结肠癌细胞(E)、或ZR-75-1(又名1500)、MUC1*阳性乳腺癌细胞。如FACS扫描所示,MN-C2和MN-E6均仅染色MUC1*阳性细胞而不染色MUC1或MUC1*阴性细胞。
图5显示ELISA的图,其中表面用MUC1*PSMGFR肽或对照肽包被。然后将人源化的MN-C2 scFv与表面一起温育,洗涤并根据标准方法检测。ELISA显示huMN-C2 scFv与MUC1*肽结合,其EC-50为约333nM。
图6A-6B显示了MUC1*抗体可变区片段人源化MN-C2 scFv对癌细胞生长抑制的图。hMN-C2 scFv有效抑制ZR-75-1(又名1500)、MUC1*阳性乳腺癌细胞(A)和T47D MUC1*阳性乳腺癌细胞(B)的生长,其具有与体外ELISA相似的EC-50。
图7A-7B显示免疫受损小鼠中肿瘤生长的图,所述小鼠已植入人肿瘤,然后用抗MUC1*抗体MN-E6 Fab处理或假处理。向植入90天雌激素颗粒的雌性nu/nu小鼠植入与Matrigel50/50混合的600万T47D人乳腺癌细胞。选择携带至少150mm3肿瘤并且肿瘤体积连续增加三次的小鼠进行治疗。用80mg/kg MN-E6 Fab每周两次皮下注射动物,并且单独用载体注射相同数量的符合相同选择标准的小鼠(A)。向雄性NOSD/SCID小鼠植入与Matrigel 50/50混合的600万个DU-145人前列腺癌细胞。选择携带至少150mm3肿瘤并且肿瘤体积连续增加三次的小鼠进行治疗。每隔48小时用160mg/kg MN-E6 Fab皮下注射动物,并且单独用载体注射相同数量的相同选择标准的小鼠(B)。两名研究人员每周两次独立测量肿瘤并记录。统计数据由独立统计人员盲算,每个人的P值给定为0.0001。抗MUC1*Fab抑制乳腺癌生长和前列腺癌生长。治疗对体重、骨髓细胞类型或数量没有影响。
图8是ELISA测定的图,显示人源化MN-E6抗MUC1*抗体的不同表达水平,这取决于轻链是κ还是λ以及可变部分是否与人IgG1或IgG2融合。
图9是比较亲本小鼠MN-E6抗体和人源化形式的MN-E6抗体与呈提衍生自MUC1*细胞外结构域的PSMGFR肽的表面的结合的ELISA测定图。
图10是ELISA测定的图,显示人源化MN-C2抗MUC1*抗体的不同表达水平,这取决于轻链是κ还是λ以及可变部分是否与人IgG1或IgG2融合。
图11是ELISA测定的图,其比较亲本小鼠MN-C2抗体和人源化形式的MN-C2抗体与呈提衍生自MUC1*细胞外结构域的PSMGFR肽的表面的结合。
图12是ELISA测定的图,显示人源化单链(scFv)MN-C2和MN-E6抗体与呈提衍生自MUC1*细胞外结构域的PSMGFR肽的表面的结合。
图13A-13C显示了在蛋白A亲和柱上在低IgG FBS中生长的MN-E6 scFv-Fc融合蛋白的纯化的FPLC迹线。A)是流过的迹线。B)是洗脱的迹线。C)显示在还原或非还原凝胶上的纯化蛋白。
图14A-14B显示纯化的MN-E6 scFv-Fc融合蛋白在非还原凝胶上的SDS-PAGE表征的照片,其中与MN-E6融合的Fc部分是野生型(wt)或突变为如下:A)F405Q、Y407R、T394D;B)T366W/L368W、T364R/L368R、T366W/L368W或T364R/L368R。Fc突变体F405Q、Y407R、T366W/L368W、T364R/L368R、T366W/L368W和T364R/L368R均有利于单体而非二聚体。所示突变的参考构建体氨基酸序列是SEQ ID NOS:273。
图15A-15B显示了在蛋白A亲和柱上在低IgG FBS中生长的MN-E6 scFv-Fc Y407Q融合蛋白的纯化的FPLC迹线。A)是流过的迹线。B)是洗脱的迹线。通过S200柱(C)上的尺寸排阻进一步纯化蛋白。(D)是SDS-PAGE凝胶的照片,显示哪些级分具有优势的单体。所示突变的参考构建体氨基酸序列是SEQ ID NOS:273。
图16显示纯化的MN-E6 scFv-Fc突变体融合蛋白在非还原凝胶上的SDS-PAGE表征的照片,其中与MN-E6 scFv融合的Fc部分是野生型(wt),或通过消除Fc的铰链区“脱铰链(DHinge)”或消除Fc的铰链区且还携带Y407R突变的突变型。所有Fc突变体都有利于单体而非二聚体形成。所示突变的参考构建体氨基酸序列是SEQ ID NOS:273。
图17A-17C。A和B显示了MN-E6 scFv-Fc无铰链突变体的大规模表达和纯化的非还原性SDS-PAGE表征的照片,表明它是单体。显示了MN-E6 scFv-Fc无铰链突变体的FPLC表征和纯化(C)。
图18A-18C显示纯化的MN-C3 scFv-Fc融合蛋白在非还原凝胶(A)或还原凝胶(B)上的SDS-PAGE表征的照片。通过尺寸排阻纯化蛋白。显示了FPLC迹线(C)。
图19A-19B显示了MN-C3或MN-E6 Fab、scFv、scFv-Fc的天然凝胶的照片,其中Fc部分是野生型,,或优选或仅为单体的突变体。天然凝胶显示Y407R Fc突变(A)和双突变体Y407R和缺失的铰链(B)最有利于单体而不是二聚体。注意,蛋白以比常规使用浓度高得多的浓度加载到凝胶上。其他Fc突变体的二聚体形成可能仅反映了加载浓度非常高的事实。
图20显示ELISA的图,其中表面用PSMGFR肽、从N末端减去10个氨基酸的PSMGFR或从C末端减去10个氨基酸的PSMGFR固定。hu MN-E6 scFv-Fc与PSMGFR肽和PSMGFRN-10肽结合但不与PSMGFR C-10肽结合。亲本MN-E6抗体和人源化MN-E6需要PSMGFR的C末端10个氨基酸来结合。
图21A-21B显示几种抗MUC1*scFv-Fc融合蛋白的ELISA图,其中Fc区已被消除或突变。显示了hu MN-E6 scFv-Fc-wt、hu MN-E6 scFv-Fc-Y407R、hu MN-E6 scFv-Fc-无铰链、和hu MN-E6 scFv-Fc-Y407R-无铰链。所有突变体都与MUC1*细胞外结构域的PSMGFR肽结合(A)。几种抗MUC1*scFv-Fc融合蛋白的ELISA图,其中Fc区是野生型或突变的。显示了hu MN-E6 scFv-Fc-wt、hu MN-E6 scFv-Fc-无铰链,并且显示了hu MN-C3 scFv-Fc(B)。全部结合MUC1*细胞外结构域的PSMGFR肽。
图22A-22C显示了ELISA的图,其中测定板表面用PSMGFR肽、从N末端减去10个氨基酸或从C末端减去10个氨基酸的PSMGFR固定。然后测定MN-C3抗体变体与各种MUC1*肽的结合。A)纯化的小鼠单克隆MN-C3抗体;B)不纯的人源化MN-C3抗体;C)人源化MN-C3 scFv-Fc。ELISA显示与PSMGFR肽以及某些缺失肽的结合。
图23显示ELISA测定的图,其定量人源化MN-E6 scFv-Fc-Δ铰链(又名脱铰链或无铰链)和人源化MN-E6 scFv与MUC1*肽PSMGFR的结合。
图24显示免疫荧光实验的照片,其中人源化MN-C2 scFv或MN-E6 scFv以相同的浓度依赖性方式特异性结合MUC1*阳性乳腺癌细胞。A-G:hu MN-C2 scFv以指示的浓度结合T47D乳腺癌细胞。H-N显示荧光标记的scFv和DAPI。O-U:hu MN-E6 scFv以指定的浓度结合T47D乳腺癌细胞。V-B'显示荧光标记的scFv和DAPI。C'是二抗对照。
图25A-25L显示已在正常培养基中或在人源化MN-E6 scFv存在下培养的1500个MUC1*阳性乳腺癌细胞的照片。A-D是以4X放大率拍摄的明视场图像。E-H是以4X放大率拍摄的钙黄绿素荧光图像。I-L是以10X放大率拍摄的钙黄绿素荧光图像。A、E、I显示在正常RPMI培养基中培养的对照细胞。B、F、J显示在正常RPMI培养基加PBS中培养的对照细胞,其中所述PBS等于添加到实验孔中的MN-E6 scFv的PBS溶液体积。C、G、K显示在正常RPMI培养基加500ug/mL MN-E6 scFv中培养的细胞。D、H、L显示在正常RPMI培养基加5μg/mL MN-E6 scFv中培养的细胞。照片显示MN-E6 scFv在5ug/mL下对MUC1*阳性细胞的杀伤和/或生长抑制,并且在500ug/mL时具有甚至更大的作用。在添加测试分子后96小时拍摄图像。
图26A-26L显示已在正常培养基中或在人源化MN-E6 scFv-Fc脱铰链存在下培养的1500个MUC1*阳性乳腺癌细胞的照片,所述人源化MN-E6 scFv-Fc脱铰链是无铰链或Δ铰链突变体。A-F是以20X放大率拍摄的明视场图像。G-L是以4X放大率拍摄的钙黄绿素荧光图像。A、G显示在正常RPMI培养基中培养的对照细胞。B、H显示在正常RPMI培养基加100μg/mL hMN-E6 scFv-Fc脱铰链中培养的细胞。C、I显示在正常RPMI培养基加50ug/mL hMN-E6 scFv-Fc脱铰链中培养的细胞。D、J显示在正常RPMI培养基加5μg/mL hMN-E6 scFv-Fc脱铰链中培养的细胞。E、K显示在正常RPMI培养基加0.5μg/mL hMN-E6 scFv-Fc脱铰链中培养的细胞。F、L显示在正常RPMI培养基加500μg/mL MN-E6 Fab中培养的细胞。照片显示hMN-E6 scFv-Fc脱铰链5ug/mL对MUC1*阳性细胞的杀伤和/或生长抑制,在50ug/mL时具有甚至更大的作用,并且在100ug/mL时还具有甚至更大的作用。将细胞形态与对照细胞进行比较,在MN-E6 Fab或有效量的hMN-E6 scFv-Fc脱铰链中生长的癌细胞显示细胞的圆形化,其在细胞死亡之前发生形态变化。在添加测试分子后96小时拍摄图像。
图27显示了图25和26的荧光图像的图像分析图。图像J用于量化在人源化MN-E6scFv或MN-E6 scFv-Fc-Δ铰链(又名脱铰链)中处理96小时后剩余的细胞数。分析软件使用像素计数和像素荧光强度来量化每张照片中的细胞数量。对整个图像(512X512像素、8位图像)进行分析。为了比较,还分析了小鼠单克隆MN-E6 Fab的抑制。
图28A-28C显示了CAR序列组分的示意图。
图29是测量Jurkat T细胞分泌IL-2细胞因子的实验图,所述Jurkat T细胞用一组CAR转导,包括MN-E6-CD8-3z、MN-E6-CD8-CD28-3z、MN-E6-CD8-41BB-3z、MN-E6-CD4-CD28-3z和MN-E6-CD4-CD28-41BB-3z,此时CAR T细胞暴露于K562-wt细胞或已用MUC1*转染的K562细胞。
图30是测量Jurkat T细胞分泌IL-2细胞因子的实验图,所述Jurkat T细胞用一组CAR转导,包括MN-E6-CD8-CD28-3z、MN-E6-CD8-41BB-3z、MN-E6-CD4-CD28-3z和MN-E6-CD4-41BB-3z,此时CAR T细胞暴露于K562-wt细胞或已用MUC1*转染的K562细胞。
图31是测量从血液样品中分离的原代人T细胞分泌IL-2细胞因子的实验图,所述原代人T细胞用一组CAR转导,包括MN-E6-CD8-CD28-3z、MN-E6-CD8-41BB-3z和MN-E6-CD4-41BB-3z,此时CAR T细胞暴露于K562-wt细胞或已经用MUC1*转染的K562细胞。
图32是测量从血液样品中分离的原代人T细胞分泌干扰素-γ(IFN-g)细胞因子的实验图,所述原代人T细胞用一组CAR转导,包括MN-E6-CD8-CD28-3z和MN-E6-CD4-41BB-3z,此时CAR T细胞暴露于K562-wt细胞或已用MUC1*转染的K562细胞。
图33是测量从血液样品中分离的原代人T细胞分泌干扰素-γ(IFN-g)细胞因子的实验图,所述原代人T细胞用一组CAR转导,包括MN-E6-CD8-CD28-3z、MN-E6-CD8-41BB-3z和MN-E6-CD8-CD28-41BB-3z,此时CAR T细胞暴露于K562-wt细胞、已用MUC1*转染的K562细胞,或前列腺癌、乳腺癌或胰腺癌的MUC1*阳性癌细胞。
图34是测量当从血液样品中分离的原代人T细胞时的靶细胞死亡的实验图,所述原代人T细胞用一组CAR转导,包括MN-E6-CD8-CD28-3z、MN-E6-CD8-41BB-3z和MN-E6-CD4-41BB-3z,此时CAR T细胞暴露于K562-wt细胞或已用MUC1*转染的K562细胞。T细胞与靶细胞的比例为1:1,将细胞共培养24小时。
图35A-35B是FACS测量从第1天到第3天的靶细胞存活的时间过程的图。从血液样品中分离的原代人T细胞用一组CAR转导,包括人源化MN-E6-CD8-3z、MN-E6-CD8-CD28-3z、MN-E6-CD8-41BB-3z和MN-E6-CD8-CD28-41BB-3z。然后将CAR T细胞暴露于天然表达低水平MUC1*的K562-wt细胞,或已用MUC1*高转染的K562细胞。MUC1*靶向CAR T细胞与靶细胞的比例为1:1、10:1或20:1。在第1天(A)或第3天(B)检测并测量存活细胞。
图36是共培养实验第3天的靶细胞存活的FACS测量图。用一组CAR转导原代人T细胞,包括人源化MN-E6-CD8-3z、MN-E6-CD8-CD28-3z、MN-E6-CD8-41BB-3z和MN-E6-CD8-CD28-41BB-3z。然后将CAR T细胞暴露于MUC1*阳性T47D乳腺癌细胞或MUC1*阳性1500(又名ZR-75-1)乳腺癌细胞。MUC1*靶向CAR T细胞与靶细胞的比例为1:1或10:1。从图中可以看出,用MUC1*靶向CAR转导的T细胞对MUC1*癌细胞的杀伤作用比未转导的对照T细胞高得多。此外,当T细胞:靶细胞的比例增加时,杀伤效果更大。
图37是共培养实验第1天的靶细胞存活的FACS测量图。用一组CAR转导原代人T细胞,包括人源化MN-E6-CD8-41BB-3z、MN-E6-CD4-41BB-3z和MN-E6-CD8-CD28-41BB-3z。然后将CAR T细胞暴露于以下MUC1*阳性癌细胞:T47D乳腺癌;capan2胰腺癌;或DU-145前列腺癌。MUC1*靶向CAR T细胞与靶细胞的比例为5:1。从图中可以看出,用MUC1*靶向CAR转导的T细胞对MUC1*癌细胞的杀伤作用比未转导的对照T细胞高得多。注意,在24小时后进行测量,仅具有5:1的T细胞与靶细胞的比率。还要注意,MUC1*靶向CAR具有与CD8构建体等效的CD4细胞外结构域-跨膜-胞质尾区。
图38是共培养实验第3天的靶细胞存活的FACS测量图。用一组CAR转导原代人T细胞,包括人源化MN-E6-CD8-41BB-3z、MN-E6-CD4-41BB-3z和MN-E6-CD8-CD28-41BB-3z。然后将CAR T细胞暴露于以下MUC1*阳性癌细胞:转染MUC1*的K562白血病细胞;T47D乳腺癌;1500(又名ZR-75-1)乳腺癌细胞;或CAPAN-2胰腺癌细胞。除了未转导的T细胞对照之外,在PC3MUC1*阴性前列腺癌细胞上进行测定。MUC1*靶向CAR T细胞与靶细胞的比例为1:1。从图中可以看出,用MUC1*靶向CAR转导的T细胞对MUC1*癌细胞的杀伤作用比未转导的对照T细胞高得多。此外,杀伤作用对MUC1*阳性细胞具有特异性。注意,MUC1*靶向CAR具有与CD8构建体等效的CD4细胞外结构域-跨膜-胞质尾区。
图39是与靶细胞共培养24小时后CAR T细胞扩增的FACS测量图,其中CAR T细胞与靶细胞的比例为5:1。用一组CAR转导原代人T细胞,包括人源化MN-E6-CD8-41BB-3z、MN-E6-CD4-41BB-3z和MN-E6-CD8-CD28-41BB-3z。将CAR T细胞与MUC1*阳性T47D乳腺癌细胞、MUC1*阳性Capan胰腺癌细胞和MUC1阴性细胞HCT-116结肠癌细胞和HEK-293人胚肾细胞共培养。从图中可以看出,在MUC1*阳性细胞存在下CAR T群增加。
图40显示MUC1*靶向CAR的的蛋白印迹的照片。从1到9是:
1:E6scFv-Fc-8-41BB-CD3z(人Fc作为与CD8TM的铰链区);
2:E6scFv-FcH-8-41BB-CD3z(人Fc无铰链作为与CD8TM的铰链区)
3:E6scFv-Fc-4-41BB-CD3z(人Fc作为与CD4TM的铰链区)
4:E6scFv-FcH-4-41BB-CD3z(人Fc作为与CD4TM的无铰链铰链区)
5:E6scFv-IgD-8-41BB-CD3z(来自人IgD的铰链区与CD8TM)
6:E6scFv-IgD-4-41BB-CD3z(来自人IgD的铰链区与CD4TM)
7:E6scFv-X4-8-41BB-CD3z(长柔性接头作为与CD8TM的铰链区)
8:E6scFv-X4-4-41BB-CD3z(长柔性接头作为与CD4TM的铰链区)
9:E6scFv-8-4-41BB-CD3z(来自CD8和CD4的铰链区与CD4TM)。
图41显示与人T细胞共培养的T47D乳腺癌细胞的FACS扫描图,所述人T细胞用MN-E6scFv-Fc-8-41BB-CD3z、MN-E6scFv-FcH-8-41BB-CD3z、MN-E6scFv-Fc-4-41BB-CD3z、MN-E6scFv-IgD-8-41BB-CD3z、MN-E6scFv-X4-8-41BB-CD3z和MN-E6scFv-X4-4-41BB-CD3z转导。将T细胞和癌细胞以1:1的比例共培养48小时。当与未转导的T细胞共培养时,将T细胞计数标准化为所有未转导的T细胞的平均值,并且将靶细胞标准化为每种特定细胞类型。该图显示当CAR T细胞与MUC1*阳性癌细胞共培养时,T细胞群扩增并且靶向癌细胞群减少。
图42显示与用MN-E6scFv-Fc-8-41BB-CD3z、MN-E6scFv-FcH-8-41BB-CD3z、MN-E6scFv-Fc-4-41BB-CD3z、MN-E6scFv-IgD-8-41BB-CD3z、MN-E6scFv-X4-8-41BB-CD3z和MN-E6scFv-X4-4-41BB-CD3z转导的人T细胞共培养的T47D乳腺癌细胞、Capan-2胰腺癌细胞、K562-MUC1*转染细胞和K562-wt细胞的FACS扫描图。将T细胞和癌细胞以1:1的比例共培养48小时。当与未转导的T细胞共培养时,将T细胞计数标准化为所有未转导的T细胞的平均值,并且将靶细胞标准化为每种特定细胞类型。该图显示当CAR T细胞与MUC1*阳性癌细胞共培养时,T细胞群扩增并且靶向癌细胞群减少。
图43A-43J。A、B是乳腺癌组织阵列的照片。A)用识别MUC1-FL(全长)的VU4H5染色;B)用识别癌性MUC1*的小鼠单克隆抗体MN-C2染色。在自动染色(Clarient Diagnostics)后,使用Allred评分方法对组织染色进行评分,该评分方法结合强度评分和分布评分。C、D、E、F是彩色编码图,显示了针对每个患者组织的MUC1全长染色计算的分数。G、H、I、J是彩色编码图,显示针对每个患者组织的MUC1*染色计算的分数。
图44A-44J。A、B是乳腺癌组织阵列的照片。A)用识别MUC1-FL(全长)的VU4H5染色;B)用识别癌性MUC1*的小鼠单克隆抗体MN-C2染色。在自动染色(Clarient Diagnostics)后,使用Allred评分方法对组织染色进行评分,该评分方法结合强度评分和分布评分。C、D、E、F是彩色编码图,显示了针对每个患者组织的MUC1全长染色计算的分数。G、H、I、J是彩色编码图,显示针对每个患者组织的MUC1*染色计算的分数。
图45A-45H显示用2.5μg/mL的人源化MN-E6-scFv-Fc生物素化抗MUC1*抗体染色,然后用第二链霉亲和素HRP抗体染色的正常乳腺和乳腺癌组织的照片。A)是正常的乳腺组织。B-D是来自患者的乳腺癌组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。
图46A-46F显示用2.5μg/mL的人源化MN-E6-scFv-Fc生物素化抗MUC1*抗体染色,然后用第二链霉亲和素HRP抗体染色的正常乳腺和乳腺癌组织的照片。A)是正常的乳腺组织。B-C是来自患者的乳腺癌组织,如图中所示。D-F是仅用二抗染色的相应连续切片的照片。
图47A-47H显示用10μg/mL的MN-E6抗MUC1*抗体染色,然后用兔抗小鼠第二HRP抗体染色的乳腺癌组织的照片。A-D是衍生自患者#300的乳腺癌组织。E-H是转移性患者#291的乳腺癌组织。
图48A-48F显示用2.5μg/mL的人源化MN-E6-scFv-Fc生物素化抗MUC1*抗体染色,然后用第二链霉亲和素HRP抗体染色的正常肺和肺癌组织的照片。A)是正常的肺组织。B、C是来自患者的肺癌组织,如图中所示。D-F是仅用二抗染色的相应连续切片的照片。
图49A-49F显示用2.5μg/mL的人源化MN-E6-scFv-Fc生物素化抗MUC1*抗体染色,然后用第二链霉亲和素HRP抗体染色的正常肺和肺癌组织的照片。A)是正常的肺组织。B、C是来自患者的肺癌组织,如图中所示。D-F是仅用二抗染色的相应连续切片的照片。
图50A-50F显示用25μg/mL的人源化MN-E6-scFv-Fc生物素化抗MUC1*抗体染色,然后用第二链霉亲和素HRP抗体染色的正常肺和肺癌组织的照片。A)是正常的肺组织。B、C是来自患者的肺癌组织,如图中所示。D-F是仅用二抗染色的相应连续切片的照片。
图51A-51F显示用25μg/mL的人源化MN-E6-scFv-Fc生物素化抗MUC1*抗体染色,然后用第二链霉亲和素HRP抗体染色的正常肺和肺癌组织的照片。A)是正常的肺组织。B、C是来自患者的肺癌组织,如图中所示。D-F是仅用二抗染色的相应连续切片的照片。
图52A-52D显示用5μg/mL的人源化MN-E6-scFv-Fc生物素化抗MUC1*抗体染色,然后用第二链霉亲和素HRP抗体染色的正常小肠和癌性小肠组织的照片。A)是正常的小肠组织。B)是来自患者的小肠癌,如图中所示。C、D是仅用二抗染色的相应连续切片的照片。
图53A-53H显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的正常小肠组织的照片。A-D是正常的小肠组织。E-H是仅用二抗染色的相应连续切片的照片。
图54A-54H显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的癌性小肠组织的照片。A-D是来自患者的癌性小肠组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。
图55A-55H显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的癌性小肠组织的照片。A-D是来自患者的癌性小肠组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。
图56A-56H显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的正常结肠组织的照片。A-D是正常结肠。E-H是仅用二抗染色的相应连续切片的照片。
图57A-57H显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的结肠癌组织的照片。A-D是来自转移患者的结肠癌组织,如图所示。E-H是仅用二抗染色的相应连续切片的照片。
图58A-58H显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的结肠癌组织的照片。A-D是来自2级患者的结肠癌组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。
图59A-59H显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的结肠癌组织的照片。A-D是来自转移患者的结肠癌组织,如图所示。E-H是仅用二抗染色的相应连续切片的照片。
图60A-60H显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的前列腺癌组织的照片。A-D是来自患者的前列腺癌组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。
图61A-61H显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的前列腺癌组织的照片。A-D是来自患者的前列腺癌组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。
图62A-62H显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的前列腺癌组织的照片。A-D是来自患者的前列腺癌组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。
图63显示用抗MUC1*单克隆抗体MNC3或MNE6或同种型对照抗体染色的人CD34+骨髓细胞的荧光激活细胞分选(FACS)测量。FACS测定的直方图和显示数据的柱状图显示骨髓的MUC1*阳性细胞被一种抗MUC1*抗体MNC3识别,但不被另一种MNE6识别。
图64显示已经用抗MUC1*抗体MNC2、MNE6、MNC3或MNC8的Fab处理的DU145前列腺癌细胞或T47D乳腺癌细胞的照片。图像显示癌症特异性抗体MNC2和MNE6有效杀死前列腺癌和乳腺癌细胞,而单克隆抗体MNC3和MNC8则不能。
图65显示PCR实验的图,其比较在不同细胞系中表达的多种切割酶的表达,其中所述值已经标准化为在乳腺癌细胞系T47D中表达的值。比较的细胞系是前列腺癌细胞系DU145、HCT-MUC1-41TR(用其细胞外结构域在41个串联重复单元后截短但未被切割成MUC1*形式的MUC1来转染的MUC1阴性结肠癌细胞系)、T47D乳腺癌细胞系和CD34+骨髓细胞。
图66显示了图65的PCR实验的图,但Y轴最大值设定为5。
图67A-67B显示了FACS实验的图,其中评估了一组切割酶抑制剂对乳腺癌细胞系T47D的作用。图67A显示了对全长MUC1抗体VU4H5或抗MUC1*单克隆抗体MNC2测试呈阳性的细胞百分比。图67B显示用抗体VU4H5与MNC2探测的细胞的平均荧光强度。可以看出,TAPI-1抑制剂和MMP2/9V抑制剂抑制MUC1的切割。
图68A-68B显示了FACS实验的图,其中评估了一组切割酶抑制剂对前列腺癌细胞系DU145的作用。图68A显示了对全长MUC1抗体VU4H5或抗MUC1*单克隆抗体MNC2测试呈阳性的细胞百分比。图68B显示用抗体VU4H5与MNC2探测的细胞的平均荧光强度。可以看出,没有一种切割酶抑制剂对MUC1切割有影响。
图69A-69B显示用全长抗体VU4H5(图69A)或抗MUC1*抗体MNC2(图69B)探测的乳腺癌阵列的连续切片的照片。每个组织标本的Allred评分显示在每个阵列照片下面的图表中,图69C-69D。抗体完全不染色或染色弱、中等或强的每个阵列的百分比绘制成饼图,如图S7E-S7F所示。
图70A-70F显示用抗MUC1*抗体huMNC2scFv染色的三阴性乳腺癌阵列的照片。显示的第一分数是Allred分数,第二分数是肿瘤分级。将得分为零、弱、中或强的阵列的百分比绘制成饼图。图70A显示了抗MUC1*抗体染色评分的饼图。图70B显示了用抗体染色的阵列的照片。图70C-70D显示来自阵列的两个乳腺癌样本的放大照片。图70C-70D显示了用框标记的样品部分的更放大的照片。
图71A-71F显示用抗MUC1*抗体huMNC2scFv染色的卵巢癌阵列的照片。显示的第一分数是Allred分数,第二分数是肿瘤分级。将得分为零、弱、中或强的阵列的百分比绘制成饼图。图71A显示了抗MUC1*抗体染色评分的饼图。图71B显示了用抗体染色的阵列的照片。图71C-71D显示来自阵列的两个乳腺癌样本的放大照片。图71C-71D显示了用框标记的样品部分的更放大的照片。
图72A-72F显示用抗MUC1*抗体huMNC2scFv染色的胰腺癌阵列的照片。显示的第一分数是Allred分数,第二分数是肿瘤分级。将得分为零、弱、中或强的阵列的百分比绘制成饼图。图72A显示抗MUC1*抗体染色评分的饼图。图72B显示了用抗体染色的阵列的照片。图72C-72D显示来自阵列的两个乳腺癌样本的放大照片。图72C-72D显示了用框标记的样品部分的更放大的照片。
图73A-73F显示用抗MUC1*抗体huMNC2scFv染色的肺癌阵列的照片。显示的第一分数是Allred分数,第二分数是肿瘤分级。将得分为零、弱、中或强的阵列的百分比绘制成饼图。图73A显示了抗MUC1*抗体染色评分的饼图。图73B显示用抗体染色的阵列的照片。图73C-73D显示来自阵列的两个乳腺癌样本的放大照片。图73C-73D显示了用框标记的样品部分的更放大的照片。
图74A-74I显示用抗MUC1*抗体huMNC2scFv染色的正常组织的照片。
图75A-75P显示了CAR T共培养测定的照片,其中CAR的靶向抗体片段是huMNC2scFv,其中CAR44具有CD8跨膜结构域,接着是41BB-3ζ,CAR50具有CD4跨膜结构域,接着是41BB-3ζ。目标癌细胞是:HCT-FLR(用MUC1*45转染的HCT-116细胞)和HCT-MUC1-41TR,其中HCT-MUC1-41TR是一种稳定的单细胞克隆HCT-116细胞系,表达其细胞外结构域在41个串联重复后截短但自己不切割成MUC1*形式的MUC1。在与CAR T细胞共培养之前,还将HCT-MUC1-41TR癌细胞与来自用MMP9或ADAM17转染的细胞的条件培养基一起温育。MMP9或ADAM17表达细胞的条件培养基也与APMA一起温育,APMA是那些切割酶的激活剂。所示图像是4X明视场图像的叠加图,并且显示了用红色CMTMR亲脂性染料染色的癌细胞的荧光图像。图75A、75E、75I、75M显示了与未转导的人T细胞共培养的细胞的照片。图75B、75F、75J、75N显示了与用抗MUC1*CAR44以10的MOI转导的人T细胞共培养的细胞的照片。图75C、75G、75K、75O显示了与用抗MUC1*CAR50以10的MOI转导的人T细胞共培养的细胞的照片。图75D、75H、75L、75P显示了与用抗MUC1*CAR44以50的MOI转导的人T细胞共培养的细胞的照片,其提高了转导效率。图75B、75C、75D显示CAR44和CAR50转导的T细胞都识别在这些癌细胞中表达的MUC1*,与它们结合,诱导聚集并杀死许多癌细胞。图75F、75G、75H显示CAR44和CAR50转导的T细胞均不识别HCT-MUC1-41TR癌细胞中表达的全长MUC1。没有T细胞诱导的聚集,并且癌细胞的数量没有减少。图75J、75K、75L显示激活的MMP9已将全长MUC1切割成MUC1*形式,MUC1*形式均被CAR44和CAR50转导的T细胞识别。存在明显可见的CAR T细胞诱导的聚集,并且当癌细胞被杀死时癌细胞的数量减少。图75N、75O、75P显示激活的ADAM17未切割MUC1或未在MNC2识别的位置处切割MUC1。huMNC2-CAR44和huMNC2-CAR50转导的T细胞均未识别这些癌细胞。
图76显示了CAR T共培养测定的照片,其中CAR的靶向抗体片段是MNC2 scFv,其中CAR44具有CD8跨膜结构域,接着是41BB-3ζ,CAR50具有CD4跨膜结构域,接着是41BB-3ζ。靶癌细胞是乳腺癌T47D细胞,其也与来自用MMP2、MMP9或ADAM17转染的细胞的条件培养基一起温育,然后与MNC2-CAR T细胞共培养。在一些情况下,MMP2和MMP9表达细胞的条件培养基也与APMA一起温育,APMA是这些切割酶的激活剂。所示图像是4X明视场图像的叠加图,并且显示了用红色CMTMR亲脂性染料染色的癌细胞的荧光图像。可以看出,MNC2-CAR T细胞仅结合并攻击表达切割形式MUC1*的靶癌细胞。
图77A-77I显示了与抗MUC1*CAR T细胞共培养的癌细胞的照片,其中一些癌细胞在与CAR T细胞共培养之前与激活的MMP9预温育。图77A-77C中显示的癌细胞是已稳定转染以表达MUC1*的MUC1阴性结肠癌细胞系HCT-116。图77D-77F中显示的癌细胞是表达高水平的MUC1全长和MUC1*的MUC1阳性乳腺癌细胞系T47D。图77G-77I中显示的癌细胞是与激活的MMP9预温育的MUC1阳性乳腺癌细胞系T47D。图77A、77D和77G中显示的细胞与未转导的人T细胞共培养,作为对照组。图77B、77E和77H中显示的细胞与用huMNC2-CAR44以10的MOI转导的人T细胞共培养,其中MOI代表感染的多重性,MOI越高,在T细胞上表达的CAR越多。图77C、77F和77I中显示的细胞与用huMNC2-CAR44以50的MOI转导人T细胞共培养。从照片中可以看出,CAR44T细胞与靶MUC1*阳性癌细胞结合,包围并杀死它们。比较图S15F的照片和图77I的照片,可以看出,当CAR的抗体靶向头识别MUC1*时,与MMP9预温育的细胞变得更容易受CAR T杀伤。还证明了MMP9切割的MUC1被huMNC2scFv识别。
图78显示T47D乳腺癌细胞的xCelligence图,其与未转导的T细胞(作为对照)或huMNC2-CAR44T细胞共培养45小时。在癌细胞生长18小时后,将催化亚单位MMP9添加一些细胞中。在25小时时,添加T细胞。可以看出,当T47D细胞与切割酶MMP9预温育时,huMNC2-CAR44T细胞杀伤得到极大改善。在xCelligence系统中,将粘附的靶癌细胞接种到电极阵列板上。粘附细胞使电极绝缘并增加阻抗。粘附癌细胞的数量与阻抗成正比。T细胞不粘附并且对阻抗没有贡献。因此,增加的阻抗反映了癌细胞的生长,并且阻抗的降低反映了癌细胞的杀伤。
图79显示DU145前列腺癌细胞的xCelligence图,所述DU145前列腺癌细胞与未转导的T细胞(作为对照)或huMNC2-CAR44T细胞共培养45小时段。在癌细胞生长18小时后,将催化亚单位MMP9添加一些细胞中。在25小时时,添加T细胞。可以看出,huMNC2-CAR44T细胞杀伤不受与切割酶MMP9预温育的影响。DU145癌细胞表达显著较低量的MUC1(包括全长形式以及MUC1*)。MUC1全长的较低密度不会在空间上阻碍T细胞接近膜近端MUC1*。
图80A-80F显示T47D mCherry转染乳腺癌细胞与正常人T细胞或用MUC1*靶向CAR转导的人T细胞(GFP阳性,绿色)共培养的照片,并且其中CAR的靶向头的抗体片段是huMNC2-scFv。图80A显示与正常人T细胞共培养的乳腺癌细胞(红色)。没有明显的T细胞诱导的聚集。图80B显示与用huMNC2-CAR18转导的人T细胞共培养的乳腺癌细胞(红色)。可以看到T细胞诱导的聚集。图80C显示与huMNC2-CAR19共培养的癌细胞,并且可见T细胞诱导的聚集。图80D显示了与huMNC2-CAR44和CAR49的混合物共培养的癌细胞,并且可以看到T细胞诱导的聚集。图80E显示了与huMNC2-CAR44共培养的癌细胞,并且可以看到T细胞诱导的聚集。图X1F显示与huMNC2-CAR50共培养的癌细胞,并且可见T细胞诱导的聚集。
图81A-81D显示人类huMNC2-CAR44T细胞的照片,其将颗粒酶B(黄色)注射到MUC1*阳性和GFP阳性(绿色)DU145前列腺癌细胞中。图81A是4X放大照片。图81B是20X放大的照片。图81C是20X放大的照片。图81D是40X放大的照片。
图82A-82B显示huMNC2-CAR44T细胞对T47D MUC1*阳性乳腺癌细胞的杀伤作用,其中乳腺癌细胞已用渐进量的另外的MUC1*转染。可以看出,随着在细胞上表达的靶MUC1*的量增加,huMNC2-CAR44T细胞的杀伤作用增加。图82A是通过FACS测量的靶细胞杀伤的图。图82B是ELISA测定的图,其中对来自与T47D细胞共培养的huMNC2-CAR44T细胞的上清液探测分泌的干扰素γ的存在(这是T细胞激活的标志)。
图83A-83D显示了与MUC1*阳性癌细胞共培养24小时后huMNC2-CAR44T细胞的FACS分析结果。图83A是FACS数据的图,显示与未转导的T细胞(红色条)相比,被huMNC2-CAR44T细胞(蓝色条)杀死的T47D癌细胞的百分比。X轴显示T细胞与癌细胞的比率。图83B是FACS数据的图,显示与未转导的T细胞(红色条)相比,被huMNC2-CAR44T细胞(蓝色条)杀死的K562-MUC1*癌细胞的百分比。图83C显示FACS扫描,其中T47D乳腺癌细胞用染料CMTMR染色。Sytox blue是死细胞染色剂。死癌细胞是象限2和3中的细胞。图83D显示FACS扫描,其中K562-MUC1*癌细胞用染料CMTMR染色。Sytox blue是死细胞染色剂。死癌细胞是象限2和3中的细胞。
图84A-84H显示了通过多种测定法测量的huMNC2-CAR44T细胞对MUC1*阳性DU145前列腺癌细胞的细胞毒性作用。图84A是与前列腺癌细胞共培养的未转导T细胞的荧光照片,其中颗粒酶B用红色荧光团染色。图84B显示DAPI和颗粒酶B的合并。图84C是与前列腺癌细胞共培养的huMNC2-CAR44T细胞的荧光照片,其中颗粒酶B用红色荧光团染色。图84D显示了DAPI和颗粒酶B的合并。图84E是用于与癌细胞一起温育的未转导的T细胞的荧光标记颗粒酶B的FACS扫描。图84F是FACS扫描,显示与癌细胞一起温育的huMNC2-CAR44T细胞荧光标记颗粒酶B的阳性增加。图84G是平均荧光强度的图。图84H是xCELLigence扫描,跟踪huMNC2-CAR44T细胞(蓝色迹线)对DU145癌细胞的实时杀伤,但未转导的T细胞(绿色)不杀伤。
图85A-85H显示了通过多种测定法测量的huMNC2-CAR44T细胞对MUC1*阳性CAPAN-2胰腺癌细胞的细胞毒性作用。图85A是与胰腺癌细胞共培养的未转导T细胞的荧光照片,其中颗粒酶B用红色荧光团染色。图85B显示DAPI和颗粒酶B的合并。图85C是与胰腺癌细胞共培养的huMNC2-CAR44T细胞的荧光照片,其中颗粒酶B用红色荧光团染色。图85D显示DAPI和颗粒酶B的合并。图85E是用于与癌细胞一起温育的未转导的T细胞的荧光标记的颗粒酶B的FACS扫描。图85F是FACS扫描,显示与癌细胞一起温育的huMNC2-CAR44T细胞的荧光标记的颗粒酶B的阳性增加。图85G是平均荧光强度的图。图85H是xCELLigence扫描,跟踪huMNC2-CAR44T细胞(蓝色迹线)对CAPAN-2癌细胞的实时杀伤,但未转导的T细胞(绿色)不杀伤。
图86A-86C显示xCELLigence扫描,跟踪huMNC2-CAR44T细胞对MUC1*阳性癌细胞而非MUC1*阴性细胞的实时杀伤。图86A显示huMNC2-CAR44T细胞有效杀死已用MUC1*稳定转染的HCT结肠癌细胞。图86B显示huMNC2-CAR44T细胞对HCT-MUC1-41TR几乎没有影响,HCT-MUC1-41TR是已用MUC1全长稳定转染的MUC1阴性癌细胞。在该细胞系中,仅约10%的细胞具有切割成MUC1*的MUC1。图86C显示huMNC2-CAR44T细胞对HCT-116细胞没有影响,HCT-116细胞是MUC1阴性结肠癌细胞系。
图87A-87L显示未经诱导的T细胞或huMNC2-scFv-CAR44T细胞,经受无刺激、1次带有MUC1*肽的珠刺激或2次MUC1*阳性癌细胞刺激的4X放大照片。图87A-87F显示了对未转导的T细胞的作用。图87G-87L显示对huMNC2-scFv-CAR44T细胞的作用。图87A和87G没有受到刺激。图87B和87H是在拍摄前24小时,用HCT-MUC1*癌细胞刺激两次,每次刺激24小时。图87C-87F和图87I-87L时在拍摄前24小时,用包被有PSMGFR MUC1*胞外结构域肽的1μm或4.5μm珠子刺激一次24小时。
图88A-88D显示了用huMNC2-scFv-CAR44转导人T细胞亚群的FACS分析,其是通过与携带MUC1*合成肽的珠共培养的1次刺激或通过与HCT-MUC1*癌细胞共培养的3次刺激的结果。图88A显示huMNC2-scFv-CAR44转导人T细胞的FACS扫描,没有刺激。图88B显示通过与MUC1*肽呈提珠共培养1次刺激的huMNC2-scFv-CAR44转导人T细胞的FACS扫描。图88C显示通过与HCT-MUC1*癌细胞共培养刺激3次的huMNC2-scFv-CAR44转导人T细胞的FACS扫描。图88D显示了FACS数据的图形表示。图88E-88J显示了对huMNC2-scFv-CAR44转导人T细胞进行1次MUC1*肽呈提珠刺激后,T细胞激活标志物的FACS分析图。图88E-88F显示激活标志物CD25的FACS。图88G-88H显示激活标志物CD69的FACS。图88I-88J显示激活标志物颗粒酶B的FACS。图88E、88G、88I显示huMNC2-scFv-CAR44转导人T细胞(没有珠子刺激)的FACS。图88F、88H、88J显示珠子刺激后huMNC2-scFv-CAR44转导人T细胞的FACS。
图89A-89C显示了在xCELLigence仪器上测量的实时CAR T诱导的癌细胞杀伤的图。该图显示了通过与MUC1*呈提珠共培养预刺激后huMNC2-scFv-CAR44T细胞的增强的杀伤作用。图89A显示肽珠刺激的huMNC2-CAR44T细胞对SKOV-3卵巢癌细胞的增强的杀伤作用,其中T细胞与癌细胞的比例为1:1。图89B显示肽珠刺激huMNC2-CAR44T细胞对BT-20三阴性乳腺癌细胞的增强杀伤作用,其中T细胞与癌细胞的比例为1:1。图89C显示肽珠刺激huMNC2-CAR44T细胞对HCT-MUC1*结肠癌细胞的增强杀伤作用,其中T细胞与癌细胞的比例为1:1。
图90A-90D显示了在xCELLigence仪器上测量的实时细胞生长与细胞死亡的关系图。显示了huMNC2-scFv-CAR44转导人T细胞的MUC1*癌细胞刺激对多种癌细胞的作用,其中一些癌细胞先前对CAR T细胞杀伤具有抗性。图90A显示了与靶T47D乳腺癌细胞共培养前24小时通过与HCT-MUC1*癌细胞共培养而预刺激的huMNC2-scFv-CAR44转导人T细胞的作用的xCELLigence图。图90B显示了与靶BT-20三阴性乳腺癌细胞共培养前24小时通过与HCT-MUC1*癌细胞共培养而预刺激的huMNC2-scFv-CAR44转导人T细胞的作用的xCELLigence图。图90C显示在与靶SKOV-3卵巢癌细胞共培养前24小时通过与HCT-MUC1*癌细胞共培养而预刺激的huMNC2-scFv-CAR44转导人T细胞的作用的xCELLigence图。图90D显示了与靶HCT-MUC1(有或没有预刺激的情况下有效杀死的)共培养前24小时通过与HCT-MUC1*癌细胞共培养而预刺激的huMNC2-scFv-CAR44转导人T细胞的作用的xCELLigence图。
图91A-91Y显示了在IVIS仪器上拍摄的小鼠的荧光照片。NSG(NOSD/SCID/GAMMA)免疫受损小鼠在第0天于胁腹皮下植入500,000个已用荧光素酶稳定转染的人MUC1*阳性癌细胞。允许肿瘤移植。在IVIS测量后第5天和第12天,给动物注射1000万个用huMNC2-scFv-CAR44转导的人T细胞、未转导的T细胞或PBS。肿瘤内注射500万个T细胞,尾静脉注射500万个T细胞。在IVIS拍照前10分钟,给小鼠腹膜内注射(IP)荧光素,荧光素在荧光素酶切割后发荧光,从而使肿瘤细胞发荧光。图91A、91E、91I、91M、91Q、91U显示用huMNC2-scFv-CAR44T细胞处理的小鼠的照片,所述huMNC2-scFv-CAR44T细胞通过与4μm珠子共培养24小时而预先刺激,所述珠子在施用前24小时附着合成的MUC1*(PSMGFR肽):方案1。图91B、91F、91J、91N、91R、91V显示用huMNC2-scFv-CAR44T细胞处理的小鼠的照片,所述huMNC2-scFv-CAR44T细胞在施用前24小时用MUC1*阳性癌细胞共培养24小时两次进行预刺激:方案2。图91C、91G、91K、91O、91S、91W显示用未转导的人T细胞处理的小鼠的照片。图91D、91H、91L、91P、91T、91X显示用PBS处理的小鼠的照片。图91A-91D显示在T细胞注射前第5天拍摄的IVIS照片。图91E-91H显示在第7天拍照的IVIS照片。图91I-91L显示在第11天拍照的IVIS照片。图91M-91P显示在第13天拍照的IVIS照片。图91Q-91T显示在第18天拍照的IVIS照片。图91U-91V显示在第21天拍照的IVIS照片。由于肿瘤体积过大,在第20天必须处死未转导T细胞和PBS组中的动物。图91W-91X显示切除的肿瘤的照片。图91Y是将光子/秒中的荧光与颜色相关联的色标。
图92A-92J显示了在IVIS仪器上拍摄的小鼠的荧光照片。NSG(NOSD/SCID/GAMMA)免疫受损小鼠在第0天于胁腹皮下注射500K人BT-20细胞,500K人BT-20细胞为MUC1*阳性三阴性乳腺癌细胞系。用荧光素酶稳定转染癌细胞。允许肿瘤移植。在IVIS测量后第6天,给动物一次性注射1000万个用huMNC2-scFv-CAR44转导的人T细胞或未转导的T细胞。肿瘤内注射500万个T细胞,尾静脉注射500万个T细胞。在IVIS拍照前10分钟,给小鼠IP注射荧光素,荧光素在荧光素酶切割后发荧光,从而使肿瘤细胞发荧光。图92A、92D、92G显示用huMNC2-scFv-CAR44T细胞处理的小鼠的照片,所述huMNC2-scFv-CAR44T细胞已经通过用4μm珠子共培养24小时进行预刺激,所述珠子在施用前24小时附着合成MUC1*(PSMGFR肽):方案1。图92B、92E、92H显示用huMNC2-scFv-CAR44T细胞处理的小鼠的照片,所述huMNC2-scFv-CAR44T细胞在施用前24小时通过与MUC1*阳性癌细胞共培养24小时两次进行预刺激:方案2。图92C、92F、92I显示用未转导的人T细胞处理的小鼠的照片。图92J是将光子/秒中的荧光与颜色相关联的色标。
图93A-93M显示了在IVIS仪器上拍摄的小鼠的荧光照片。NSG(NOSD/SCID/GAMMA)免疫受损小鼠在第0天将500K人SKOV-3细胞注射到腹膜腔(IP)中,所述SKOV-3细胞是MUC1*阳性卵巢癌细胞系。用荧光素酶稳定转染癌细胞。允许肿瘤移植。在第4天,用10M的huMNC2-scFv-CAR44转导人T细胞、未转导T细胞或PBS注射到动物的腹膜内空间。在第11天,再次注射动物,除了将一半细胞注射到尾静脉中,另一半IP注射。在第3、7、10和15天通过IVIS对动物成像。在IVIS照片前10分钟,给小鼠IP注射荧光素,荧光素在荧光素酶切割后发荧光,从而使肿瘤细胞发荧光。图93A、93D、93G和93J显示用huMNC2-scFv-CAR44T细胞处理的小鼠的照片,所述huMNC2-scFv-CAR44T细胞通过与1μm珠子共培养24小时而预先刺激,所述珠子在施用前24小时附着合成MUC1*(PSMGFR肽)。图93B、93E、93H和93K显示用未转导的人T细胞处理的小鼠的照片。图93C、93F、93I和93L显示用PBS处理的小鼠的照片。图93A、93B和93C是在CAR T、T细胞或PBS施用之前第3天拍摄的IVIS图像。图93D、93E和93F显示在第7天,即治疗后仅四(4)天的动物的IVIS图像。图93G、93H和93I显示第10天的动物的IVIS图像。图93J、93K和93L显示第15天的动物的IVIS图像。图93M是关联光子/秒中的荧光与颜色的IVIS色标。
图94A-94B是描绘MUC1全长阻碍T细胞接近生长因子受体MUC1*的空间位阻问题的动画。图94A是显示晚期癌细胞主要表达切割的MUC1,使得T细胞易于接近生长因子受体的动画。图94B是显示早期癌细胞表达MUC1*生长因子受体和全长MUC1的动画。全长MUC1比MUC1*长10倍,因此在空间上阻碍T细胞与MUC1*的结合。MMP9在这里描述为分子剪刀,在T细胞激活后,切割全长蛋白以使MUC1*更容易接近。
图95A-95D显示作为MUC1阴性结肠癌细胞系的HCT-116细胞的蛋白印迹和相应的FACs分析,然后用MUC1*或MUC1全长稳定转染。显示的单细胞克隆是HCT-MUC1-41TR和HCT-MUC1*。图95A显示亲本细胞系HCT-116、HCT-MUC1-41TR和HCT-MUC1*的蛋白印迹,其中凝胶已用仅识别切割的MUC1的兔多克隆抗体(SDIX)探测。在泳道6(加载有HCT-MUC1*)中可以很容易地看到25和35kDa之间的可见条带,而在泳道4和5中仅有微弱条带,表明在HCT-MUC1-41Tr细胞中仅有少量MUC1被切割。在加载到泳道2和3中的亲本细胞系HCT-116中不存在切割的MUC1。图95B是用识别全长MUC1的串联重复的小鼠单克隆抗体VU4H5探测的蛋白印迹。可见,只有HCT-MUC1-41TR含有全长MUC1。图95C显示FACS扫描,其显示了HCT-MUC1*对于SDIX是95.7%阳性,SDIX仅与MUC1*结合并且对于MUC1全长基本上完全不结合。图95D显示FACS扫描,其显示HCT-MUC1-41TR细胞对于全长MUC1为95%阳性,而对于切割形式MUC1*仅为约11%阳性。
图96A-96E显示免疫荧光实验的照片。HCT-MUC1-41TR癌细胞表达全长MUC1。值得注意的是,细胞系不会自然地将MUC1切割成MUC1*。仅约10-15%的MUC1被切割成MUC1*形式。在这里,我们显示MUC1全长暴露于MMP9催化结构域导致MUC1切割成被抗MUC1*抗体MNC2识别的MUC1*。MNC2与细胞的结合量与添加到细胞中的MMP9的量成比例,这表明MNC2在被MMP9切割时与MUC1结合。图96A是对照并显示未用MMP9温育但已用MNC2染色的HCT-MUC1-41TR细胞。图96B显示与12.5ng/mL MMP9催化结构域一起温育的HCT-MUC1-41TR细胞。图96C显示与25ng/mL MMP9催化结构域一起温育的HCT-MUC1-41TR细胞。图96D显示与50ng/mL MMP9催化结构域一起温育的HCT-MUC1-41TR细胞。图96E显示与100ng/mL MMP9催化结构域一起温育的HCT-MUC1-41TR细胞。
图97显示MMP9的荧光肽底物(OMNIMMP肽)在PBS(实线)或细胞培养基(虚线)中被两种浓度的MMP9催化结构域切割的图。
图98A-98F是用识别转染的MMP9构建体的抗体探测的细胞裂解物的蛋白印迹照片。构建质粒,然后转染到HEK293T细胞中,其中将MMP9催化结构域的基因插入3或4个NFAT应答元件的下游。通过添加10ng/mL的PMA和1uM或2uM的离子霉素激活NFAT途径,除了泳道1、2、5、6、9、10、13和14中的对照(ctl)细胞。将用含有3个重复的NFAT应答元件的质粒转染的细胞的裂解物加载到泳道1、3、5、7、9、11、13和15中。将用含有4个重复的NFAT应答元件的质粒转染的细胞的裂解物加载到泳道2、4、6、8、10、12、14和16中。图98A和图98C显示曝光1分钟的照片,而图98B和图98D显示曝光5分钟的照片。对于图98A和图98B的细胞裂解物,未添加蛋白酶抑制剂。向图98C和图98D的细胞裂解物中添加蛋白酶抑制剂。图98E显示蛋白印迹的照片,其中表达重复的NFAT应答元件的MMP9催化结构域从细胞的条件培养基中被捕获,所述细胞的裂解物显示在图98A和图98B(泳道7和8)中。使用珠子进行捕捉,所述珠子与识别Flag标签的抗体偶联,所述Flag标签掺入在MMP9构建体的C末端。泳道1显示分子量控制。泳道2、3、4和5显示从抗Flag标签珠洗脱的MMP9。泳道2和3是第一次洗脱,泳道4和5中显示的细胞是第二次洗脱。向泳道2和4中加载来自细胞的条件培养基,细胞中NFAT途径已经用10ng/mL PMA和1μM离子霉素激活。向泳道3和5中加载来自细胞的条件培养基,细胞中NFAT途径已用10ng/mL PMA和2μM离子霉素激活。图98F是构建体的示意图。
图99A-99C显示荧光肽(OMNIMMP肽),即MMP9的底物被HEK293T细胞的细胞裂解物或条件培养基切割的图,所述HEK293T细胞用含有MMP9基因的质粒转染,所述MMP9基因在4个重复的NFAT应答元件的下游。MMP9肽底物测定显示PMA/离子霉素激活NFAT途径导致MMP9表达和分泌,并且其活性由其切割肽底物的能力所证明。图99C是构建体的示意图。
图100A-100E显示在HEK293T细胞中表达的NFAT诱导的MMP9催化结构域,其中MMP9的天然前导序列已被IgK前导序列取代,MMP9催化结构域位于4个重复的NFAT应答元件的下游。图100A显示了在激活NFAT途径后检测细胞裂解物中MMP9表达的蛋白印迹的照片。图100B显示了在激活NFAT途径后检测在条件培养基中的MMP9表达的蛋白印迹的照片。图100C显示在HEK293T细胞的条件培养基中表达和分泌的MMP9催化结构域对MMP9荧光肽底物(OMNIMMP肽)切割的图,其中MMP9的天然前导序列已被IgK前导序列取代,MMP9催化结构域位于4个重复的NFAT应答元件的下游。图100D显示在HEK293T细胞的条件培养基中表达和分泌的MMP9催化结构域对MMP9荧光肽底物切割的图,其中MMP9的天然前导序列已被IgK前导序列取代,MMP9催化结构域位于4个重复的NFAT应答元件的下游。图100E是构建体的示意图。
图101A-101E显示MMP9可以用不同的前导序列表达,并且还显示各自的后续活性。图101A显示了检测细胞裂解物中MMP9蛋白的蛋白印迹,其中MMP9基因上游的前导序列是其天然序列或IgK序列。图101B显示了在条件培养基中检测MMP9的蛋白印迹,其中MMP9基因上游的前导序列是其天然序列或IgK序列。图101C显示了被表达的MMP9切割的MMP9肽底物的图。101D-101E是构建体的示意图。
图102A-102D显示了用产生NFAT诱导型MMP9的质粒转染的细胞的三(3)个克隆4、6和7,其中NFATc1启动子序列在MMP9基因的上游,在这种情况下是包含其催化结构域的截短的MMP9。还显示用于比较的细胞是用产生NFAT诱导型MMP9的质粒转染的细胞,其中4个重复的NFAT应答元件序列是MMP9基因的上游。图102A显示了检测细胞裂解物中MMP9蛋白的蛋白印迹。图102B显示了在条件培养基中检测MMP9的蛋白印迹。图102C-102D是构建体的示意图。
图103A-103D显示了MMP9肽底物切割测定的图。图103A显示了来自细胞的裂解物中的MMP9切割活性,所述细胞用具有NFATc1启动子或4个重复的NFAT应答元件所驱动的MMP9表达的质粒转染。图103B显示了来自细胞的条件培养基中的MMP9切割活性,所述细胞用具有NFATc1启动子或4个重复的NFAT应答元件所驱动的MMP9表达的质粒转染。图103C-103D是构建体的示意图。
图104A-104B显示了测量MMP9活性的OMNIMMP9荧光底物测定的结果。将来自单独或与CAR44组合的NFAT诱导型MMP9转导人T细胞的条件培养基添加到测定中,并测量MMP9底物切割作为时间的函数。图104A显示了在通过与HCT-MUC1*癌细胞共培养激活细胞后,用CAR44和NFAT诱导型MMP9转导人T细胞时的MMP9活性。未显示作为时间函数的增加的底物切割的迹线来自未被激活的细胞的条件培养基。图104B显示当通过与已知激活T细胞的抗CD3和抗CD28包被的珠子共培养细胞后,仅用NFAT诱导型MMP9转导人T细胞时的MMP9活性。未显示作为时间函数的增加的底物切割的迹线来自未被激活的细胞的条件培养基。
图105A-105E显示用单独的CAR44、单独的NFAT诱导型MMP9或用CAR44和NFAT诱导型MMP9转导的人T细胞的蛋白印迹的照片,其中所得T细胞未被激活、被PMA/离子霉素化学激活、通过与呈提合成MUC1*肽的珠子共培养或与MUC1*阳性癌细胞共培养而激活。用抗Flag标签(也称为DYK标签抗体)探测蛋白印迹。MMP9的催化结构域以约40kDa的表观分子量移动。图105A-105D显示了澄清的细胞裂解物的蛋白印迹的照片。图105A具有装载有以下的裂解物的泳道1-7:泳道1:用CAR44转导并且未激活的T细胞;泳道2:用CAR44转导并用呈提合成MUC1*胞外结构域肽的珠子激活的T细胞;泳道3:用CAR44转导并通过与HCT-MUC1*癌细胞共培养激活的T细胞;泳道4:用CAR44和NFAT诱导型MMP9转导但未激活的T细胞;泳道5:用CAR44和NFAT诱导型MMP9转导,并用呈提合成MUC1*胞外结构域肽的珠子激活的T细胞;泳道6:用CAR44和NFAT诱导型MMP9转导,并通过与HCT-MUC1*癌细胞共培养激活的T细胞;泳道7:也带有Flag DYK标签的无关蛋白。结果显示,当用PMA/离子霉素、MUC1*珠或MUC1*阳性癌细胞激活时,用NFAT诱导型MMP9转导的T细胞仅表达MMP9。当用MUC1*珠或MUC1*阳性癌细胞刺激而激活T细胞时,用CAR44和NFAT诱导型MMP9转导的T细胞仅表达MMP9。图105B具有装载有以下的裂解物的泳道1-7:泳道1:用CAR44转导并且未激活的T细胞;泳道2:用CAR44转导并用珠子激活的T细胞,所述珠子呈提已知激活T细胞的抗CD3和抗CD28抗体;泳道3:用CAR44转导,并通过与PMA/离子霉素共培养而激活的T细胞;泳道4:用NFAT诱导型MMP9转导但未激活的T细胞;泳道5:用NFAT诱导型MMP9转导,并用呈提抗CD3和抗CD28抗体的珠子激活的T细胞;泳道6:用NFAT诱导型MMP9转导并用PMA/离子霉素激活的T细胞;泳道7:也带有Flag DYK标签的无关蛋白。图105C和105D是图105A和105B中所示的相同蛋白印迹的较暗曝光。图105E是如下转导细胞的细胞上清液的蛋白印迹照片:泳道1:用CAR44转导并未激活的T细胞;泳道2:用CAR44转导并用珠子激活的T细胞,所述珠子呈提已知激活T细胞的抗CD3和抗CD28抗体;泳道3:用CAR44转导,并通过与PMA/离子霉素共培养激活的T细胞;泳道4:用NFAT诱导型MMP9转导但未激活的T细胞;泳道5:用NFAT诱导型MMP9转导,并用呈提抗CD3和抗CD28抗体的珠子激活的T细胞;泳道6:用NFAT诱导型MMP9转导,并用PMA/离子霉素激活的T细胞;泳道7:也带有Flag DYK标签的无关蛋白。结果显示,用NFAT诱导型MMP9转导的T细胞在被激活时表达MMP9。当CAR44和NFAT诱导型MMP9转导的T细胞与呈提或表达MUC1*的珠子或细胞共培养时,它们被特异性激活(图105A泳道5和泳道6)。
图106A-106B显示了产生的用以克服由全长MUC1引起的空间位阻的一系列“长臂”CAR的动画。图106A显示了在细胞膜和抗体scfv之间具有较长接头区的CAR的动画图。图106B显示了它们如何克服MUC1全长的空间位阻的动画。
图107A-107B显示与未转导的T细胞(作为对照)或几种不同的长臂CAR T细胞共培养的MUC1阳性乳腺癌T47D细胞的xCelligence图,其中抗体scFv和跨膜结构域之间的接头的长度和序列如所示变化。图107A显示了测试的各种CAR T细胞的阻抗随时间的函数。图107B示出了相同的数据,但是其中迹线的斜率是作为时间的函数的图形。
图108A-108P显示细胞结合测定的照片,其中细胞用在抗体片段和跨膜结构域之间具有可变长度接头区的CAR转导。CAR转导的细胞携带GFP荧光剂,因此是绿色的。然后将已经用CMTMR染料染成红色的MUC1*阳性癌细胞添加到CAR表达细胞中。CAR能够识别其癌细胞上的靶标的程度由黄色(绿色加红色)的量反映。图108A是对照的未转导细胞。图108B细胞用CAR44转导,其中接头区来自CD8细胞外结构域。图108C显示具有接头的CAR,所述接头是抗体Fc区的一部分。图108D显示具有接头的CAR,所述接头是抗体Fc区的一部分,减去其铰链区。图108E显示具有接头的CAR,所述接头是4-重复柔性接头序列。图108F显示具有接头的CAR,其是IgD抗体的一部分。图108G显示具有接头的CAR,所述接头是IgD抗体的一部分加上Fc区。图108H显示具有接头的CAR,所述接头是IgD抗体的一部分加上没有其铰链区的Fc区。图108I-108M显示在充分洗涤步骤后,与MUC1*表达癌细胞一起温育后的CAR表达细胞的照片。
表1显示了许多生成和测试的抗MUC1*CAR的细节。对于所示的每个构建体,显示了分配给该CAR的编号、使用的启动子、信号肽、抗体种类、scFv序列、铰链区、跨膜结构域和每个CAR中使用的信号基序、插入物的长度(以碱基对的数量计)、分子量和构建体的长度。
表2显示了转导入人T细胞并与多种癌细胞共培养后一些CAR的细胞因子释放数据。
具体实施方式
在本申请中,“一(a,an)”用于表示单个和多个对象。
如本文所用,偶尔,简言之,多肽是指“转导或转染”到细胞中的。在这些情况下,应理解编码多肽序列的核酸被转导或转染到细胞中,因为不可能将多肽转导或转染到细胞中。
如本文所用,偶尔当提及注射到动物中的细胞数量或在其中提及细胞数量的上下文中时,“M”指数百万,“K”指数千。
如本文所用,使用各种单克隆抗体的可互换名称,例如“MN-C2”,其可与“C2”、“Min-C2”和“MNC2”互换;“MN-E6”,可与“E6”、“Min-E6”和“MNE6”互换;“MN-C3”,可与“C3”、“Min-C3”和“MNC3”互换;和“MN-C8”,可与“C8”、“Min-C8”和“MNC8”互换。
如本文所用,置于抗体构建体之前的“h”或“hu”是人源化的缩写。
如本文所用,术语“抗体样”是指可以被工程化以使其含有抗体部分但不是含天然存在抗体的分子。实例包括但不限于CAR(嵌合抗原受体)T细胞技术和技术。CAR技术使用与T细胞的一部分融合的抗体表位,从而使身体的免疫系统攻击特定的靶蛋白或细胞。技术由“抗体样”文库组成,该文库是合成人Fab的集合,然后筛选其与靶蛋白的肽表位的结合。然后可以将选择的Fab区域工程化到支架或框架中,使得它们类似于抗体。
如本文所用,“PSMGFR”是MUC1生长因子受体的一级序列的缩写(由SEQ ID NOS:2表示),因此不与六氨基酸序列混淆。“PSMGFR肽”或“PSMGFR区”是指包含MUC1生长因子受体的一级序列(SEQ ID NOS:2)的肽或区域。
如本文所用,“MUC1*”细胞外结构域主要由PSMGFR序列(GTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGA(SEQ ID NOS:2))定义。因为MUC1切割的确切位点取决于剪切它的酶,并且切割酶根据细胞类型、组织类型或细胞进化的时间而变化,MUC1*细胞外结构域在N末端的确切序列可能不同。
其他修剪的氨基酸序列可包括SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:620);或SVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:621)。
如本文所用,术语“PSMGFR”是MUC1生长因子受体的一级序列的首字母缩写,如GTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGA(SEQ ID NOS:2)所示。在这方面,“N-10PSMGFR”、“N-15PSMGFR”或“N-20PSMGFR”中的“N-数”是指在PSMGFR的N末端缺失的氨基酸残基数。同样,“C-10PSMGFR”、“C-15PSMGFR”或“C-20PSMGFR”中的“C-数”是指在PSMGFR的C末端缺失的氨基酸残基的数目。
如本文所用,“MUC1*的细胞外结构域”是指缺乏串联重复结构域的MUC1蛋白的细胞外部分。在大多数情况下,MUC1*是切割产物,其中MUC1*部分由缺乏串联重复的短细胞外结构域、跨膜结构域和胞质尾区组成。MUC1切割的精确位置可能是未知的,因为它似乎可以被一种以上的酶切割。MUC1*的细胞外结构域将包括大部分PSMGFR序列,但可能具有另外的10-20个N末端氨基酸。
如本文所用,“序列同一性”是指特定多肽或核酸与核酸或氨基酸的参考序列的序列同源性,使得同源肽的功能与参考肽或核酸相同。这种同源性可以与参考肽如此接近,使得有时两个序列可以是90%、95%或98%相同但在结合或其他生物活性中具有相同的功能。
如本文所用,“MUC1阳性”细胞是指表达MUC1、MUC1-Y或MUC1-Z或其他MUC1变体的基因的细胞。
如本文所用,“MUC1阴性”细胞是指不表达MUC1基因的细胞。
如本文所用,“MUC1*阳性”细胞是指表达MUC1基因的细胞,其中该基因表达的蛋白是没有串联重复的跨膜蛋白,其可能是翻译后修饰、切割、选择性剪接的结果,或用缺乏串联重复的MUC1蛋白转染或转导细胞的结果。
如本文所用,“MUC1*阴性”细胞是指可以表达或不表达MUC1基因,但不表达缺乏串联重复的MUC1跨膜蛋白的细胞。
如本文所用,“MUC1阳性”癌细胞是指过表达MUC1基因的癌细胞,以异常模式表达MUC1,其中其表达不限于顶端边界和/或表达缺乏串联重复的MUC1。
如本文所用,“MUC1阴性”癌细胞是指可以表达或不表达MUC1基因,但不过表达MUC1或不过表达缺乏串联重复的MUC1跨膜蛋白的癌细胞。
如本文所用,“MUC1*阳性”癌细胞是指过表达缺乏串联重复的MUC1跨膜蛋白的癌细胞。
如本文所用,“MUC1*阴性”癌细胞是指可以表达或不表达MUC1基因,但不过表达缺乏串联重复的MUC1跨膜蛋白的癌细胞。
用于治疗或预防癌症的MUC1*抗体(抗PSMGFR)
我们发现切割形式的MUC1(SEQ ID NOS:1)跨膜蛋白是一种生长因子受体,其驱动超过75%的全部人类癌症的生长。切割形式的MUC1,我们称之为MUC1*(发音为muk 1star),是一种强大的生长因子受体。酶促切割释放大部分MUC1细胞外结构域。其余部分包含截短的细胞外结构域、跨膜结构域和胞质尾区,称为MUC1*。MUC1的大部分细胞外结构域的切割和释放揭示了用于激活配体二聚体NME1、NME6、NME8、NME7-AB、NME7-X1或NME7的结合位点。细胞生长测定显示,它是促进生长的MUC1*细胞外结构域的配体诱导二聚化(图1A-1D)。用二价'bv'抗MUC1*抗体、单价'mv'或Fab、NM23-H1二聚体或NME7-AB处理MUC1*阳性细胞。二价抗MUC1*抗体刺激癌细胞的生长,而单价Fab抑制生长。经典的钟形曲线表明配体诱导二聚化刺激生长。二聚体NM23-H1(又名NME1)刺激MUC1*阳性癌细胞的生长,但抑制MUC1表达的siRNA消除其作用(图1C)。NME7-AB还刺激MUC1*阳性细胞的生长(图1D)。
MUC1*是癌症药物的优秀靶标,因为它在超过75%的全部癌症中异常表达,并且可能在更高百分比的转移性癌症中过表达。在MUC1切割后,其大部分细胞外结构域从细胞表面脱落。剩余部分具有截短的细胞外结构域,其至少包含主要生长因子受体序列PSMGFR(SEQ ID NOS:2)。与PSMGFR序列结合的抗体,尤其那些竞争性抑制激活配体(如NME蛋白,包括NME1、NME6、NME8、NME7AB、NME7-X1和NME7)结合的抗体,是理想的治疗药物,可用于治疗或预防MUC1阳性或MUC1*阳性癌,作为独立抗体、掺入双特异性抗体中的抗体片段或可变区片段、或称为CAR的嵌合抗原受体,然后将其转染或转导到免疫细胞中,然后给予患者。
治疗性抗MUC1*抗体可以是单克隆、多克隆、抗体模拟物、工程化抗体样分子、全长抗体或抗体片段。抗体片段的实例包括但不限于Fab、scFv和scFv-Fc。人或人源化抗体优选用于治疗或预防癌症。在任何这些抗体样分子中,可以引入突变以防止或最小化二聚体形成。优选单价或双特异性的抗MUC1*抗体,因为MUC1*功能被配体诱导二聚化激活。典型的结合测定显示NME1和NME7-AB结合MUC1*的PSMGFR肽部分(图2A、2D)。此外,它们显示这些激活生长因子与MUC1*的膜近端部分结合,因为如果缺失10个C末端氨基酸,它们不与PSMGFR肽结合。类似地,如果仅存在10个C末端氨基酸,则抗MUC1*抗体MN-C2和MN-E6与PSMGFR肽结合(图2B、2C)。抗体MN-C3和MN-C8结合不同于MN-C2和MN-E6的表位,因为它们不依赖于PSMGFR肽的10个C末端氨基酸的存在(图2E、2F)。抗体MN-C2、MN-E6、MN-C3或MN-C8或衍生自它们的片段,作为独立抗体或掺入双特异性抗体之中、已被转导入免疫细胞的BiTE或嵌合抗原受体(也称为CAR),可以给予患者以治疗或预防癌症。竞争性抑制NME1和NME7-AB结合的MNC2和MNE6以及其他抗MUC1*抗体优选用作独立抗体治疗剂。
可以基于特定标准选择用作独立抗体治疗剂或用于掺入到BiTE或CAR中的治疗性抗MUC1*抗体。可以使用在动物中产生单克隆抗体的典型方法产生亲本抗体。或者,可以通过筛选抗体和抗体片段文库结合MUC1*肽的能力来对其进行选择,所述MUC1*肽可以是PSMGFR肽(SEQ ID NOS:2)、SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:620)或SVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:621)。
然后可以通过继续额外的筛选来进一步选择以这种方式产生或选择的所得抗体或抗体片段。例如,基于抗体或抗体片段结合MUC1*阳性癌细胞或组织但不结合MUC1阴性癌细胞或正常组织的能力,则更优选。此外,如果抗MUC1*抗体或抗体片段与干细胞或祖细胞结合,则可以将其取消选择作为抗癌治疗剂。如果抗MUC1*抗体或抗体片段具有竞争性抑制激活配体与MUC1*的结合的能力,则更优选。图3A-3C显示MN-E6和MN-C2竞争性地抑制激活配体NME1和NME7与MUC1*的结合。
选择用于治疗被诊断患有MUC1阳性癌症、有发生MUC1阳性癌症风险或怀疑患有MUC1阳性癌症的患者的抗MUC1*抗体的方法包括以下一个或多个选择抗体或抗体片段的步骤1)与PSMGFR肽结合;2)与N-10PSMGFR肽结合;3)与癌细胞结合;4)不与干细胞或祖细胞结合;5)竞争性抑制二聚体NME1或NME7-AB与PSMGFR肽的结合。例如,图3A-3C显示单克隆MN-E6和MN-C2满足所有五个标准,而单克隆MN-C3和MN-C8不竞争性地抑制激活配体NME1和NME7的结合(图3C)。然而,衍生自MN-C3和MN-C8的抗体或抗体片段在与这些方法中掺入到BiTE或CAR中作为抗癌剂时同样有效,免疫细胞的杀伤作用比抑制激活配体的结合能力更重要。此外,与MN-E6、MN-C2、MN-C3或MN-C8缀合的毒性剂是有效的抗癌治疗剂。回想一下,MUC1*生长因子受体被其细胞外结构域的配体诱导二聚化激活。因此,理想的抗体治疗剂不应使MUC1*细胞外结构域二聚化。优选地,在这方面,合适的抗体包括单价抗体,例如在羊驼和骆驼中产生的抗体,Fab、scFv、单结构域抗体(sdAb)、scFv-Fc,只要构建Fc部分使得它不同二聚化即可。
FACS扫描显示抗MUC1*抗体MN-C2和MN-E6特异性结合MUC1*阳性实体瘤癌细胞和MUC1*转染细胞,但不结合MUC1*阴性或MUC1阴性细胞。MNC3和MNC8与血液祖细胞以及血癌细胞结合,因为这些疾病的特征在于血液祖细胞不能最终分化。因此,MNC3和MNC8优选用于治疗血癌,作为独立治疗剂、BiTE或CAR T治疗剂。在一个实例中,显示人源化MN-C2 scFv结合ZR-75-1(又名1500)、MUC1*阳性乳腺癌细胞(图4A-4C)。如果仅用MUC1*转染,则显示MN-E6与MUC1阴性HCT-116结肠癌细胞结合。MN-E6还结合MUC1*阳性癌细胞,例如ZR-75-1(又名1500)、MUC1*阳性乳腺癌细胞(图4D-4F)。结合测定例如ELISA、免疫荧光等都证实MN-C2和MN-E6与PSMGFR肽结合,并与活MUC1阳性癌细胞结合。基于它们还结合PSMGFR肽或MUC1阳性癌细胞的能力来筛选人源化抗MUC1*抗体。图5显示人源化MN-C2 scFv以高亲和力结合MUC1*肽PSMGFR,其中EC-50为约333nM。人源化MN-C2 scFv,如Fabs,有效抑制MUC1*阳性癌细胞的生长,如图6A、6B中的一个实例所示。
MN-E6和MN-C2的Fab或衍生自它们的可比较的单链可变区在体外和体内有效抑制MUC1*阳性癌症的生长。在几个实例中,抗MUC1*抗体的Fab抑制体内人MUC1*阳性癌症的生长。在一种情况下,免疫受损小鼠植入人乳腺肿瘤,然后在肿瘤移植后用MN-E6 Fab处理。图7A显示MN-E6 Fab有效抑制MUC1*阳性乳腺癌的生长。向植入90天雌激素颗粒的雌性nu/nu小鼠植入与Matrigel 50/50混合的600万T47D人乳腺癌细胞。选择携带至少150mm3的肿瘤并且肿瘤体积连续增加三次的小鼠进行治疗。每周两次用80mg/kg MN-E6 Fab皮下注射动物,并且仅用载体注射相同数量的符合相同选择标准的小鼠(图7A)。
在另一方面,显示MN-E6停止前列腺癌的生长。图7B显示MN-E6 Fab有效抑制MUC1*阳性前列腺癌的生长。向雄性NOSD/SCID小鼠植入与Matrigel 50/50混合的600万个DU-145人前列腺癌细胞。选择携带至少150mm3的肿瘤并且肿瘤体积连续增加三次的小鼠进行治疗。每48小时用160mg/kg MN-E6 Fab皮下注射动物,并且仅用载体注射相同数量的符合相同选择标准的小鼠(图7B)。两名研究人员每周两次独立测量肿瘤并记录。统计数据由独立统计人员盲算,每个人的P值给定为0.0001。抗MUC1*Fab抑制乳腺癌生长和前列腺癌生长。治疗对体重、骨髓细胞类型或数量没有影响。MN-E6 Fab有效抑制肿瘤的生长,而对照组的肿瘤继续生长直至处死。没有观察到或检测到治疗的不良反应。
构建了MN-E6和MINERVA-C2的重组形式,其与Fab一样是单体的。在这种情况下,MN-E6被人源化并且MINERVA-C2被人源化。本领域技术人员已知许多方法用于人源化抗体。除人源化外,还可筛选人抗体文库以鉴定与PSMGFR结合的其他全长人抗体。图8是ELISA测定的图,其显示人源化MN-E6抗MUC1*抗体的不同表达水平,这取决于轻链是κ还是λ以及可变部分是否与人IgG1或IgG2融合。图9是ELISA测定的图,其比较亲本小鼠MN-E6抗体与人源化形式的MN-E6抗体与呈提衍生自MUC1*细胞外结构域的PSMGFR肽的表面的结合。图10是ELISA测定的图,显示人源化MN-C2抗MUC1*抗体的不同表达水平,这取决于轻链是κ还是λ以及可变部分是否与人IgG1或IgG2融合。图11是ELISA测定的图,其比较亲本小鼠MN-C2抗体与人源化形式的MN-C2抗体与呈提衍生自MUC1*细胞外结构域的PSMGFR肽的表面的结合。图12是ELISA测定的图,显示人源化单链(scFv)MN-C2和MN-E6抗体与呈提衍生自MUC1*细胞外结构域的PSMGFR肽的表面的结合。
将人源化MN-E6可变区的单链(称为scFv)进行基因工程改造,使其与抗体的Fc部分连接(SEQ ID NOS:256和257)。Fc区赋予抗体片段某些益处以用作治疗剂。抗体的Fc部分募集补体,其通常意味着它可以募集免疫系统的其他方面并因此扩增抗肿瘤反应而不仅仅是抑制靶标。Fc部分的添加也增加了抗体片段的半衰期(Czajkowsky DM,Hu J,Shao Z and Pleass RJ.(2012)Fe-fusion proteins:new developments and future perspectives.EMBO Mol Med.4(10):1015-1028)。
然而,抗体Fc部分同二聚化,这在基于抗MUC1*抗体的治疗剂的情况下不是最佳的,因为MUC1*受体的配体诱导二聚化刺激生长。如图13B中可见,人源化MN-E6 scFv-Fc是二聚体,部分是由于二硫键。因此,抗MUC1*抗癌治疗剂优选抵抗Fc二聚体形成的Fc区突变。删除铰链区域(在一些图和实例SEQ ID NOS:288和289中,无铰链也称为Δ铰链或脱铰链)和Fc区中的其他突变,使Fc突变体抵抗二聚化。在CH3结构域中进行以下突变以产生单体scFv-Fc融合蛋白:Y407R(SEQ ID NOS:278和279)、F405Q(SEQ ID NOS:280和281)、T394D(SEQ ID NOS:282和283)、T366W/L368W(SEQ ID NOS:284和285)、T364R/L368R(SE ID NOS:286和287)。图14显示纯化的MN-E6 scFv-Fc融合蛋白在非还原凝胶上的SDS-PAGE表征的照片,其中与MN-E6融合的Fc部分是野生型(wt)或如下突变:A)F405Q、Y407R、T394D;B)T366W/L368W、T364R/L368R、T366W/L368W或T364R/L368R。Fc突变体F405Q、Y407R、T366W/L368W、T364R/L368R、T366W/L368W和T364R/L368R均有利于单体而非二聚体形成。图15显示了在蛋白A亲和柱上在低IgG FBS中生长的MN-E6 scFv-Fc Y407Q融合蛋白的纯化的FPLC迹线。A)是流过的迹线。B)是洗脱的迹线。通过S200柱(C)上的尺寸排阻进一步纯化蛋白。(D)是SDS-PAGE凝胶的照片,显示哪些级分具有优势的单体。图16显示纯化的MN-E6 scFv-Fc-突变体融合蛋白在非还原凝胶上的SDS-PAGE表征的照片,其中与MN-E6 scFv融合的Fc部分是野生型(wt)、或通过消除Fc的铰链区(脱铰链)或消除Fc的铰链区并且还携带Y407R突变的突变型。所有Fc突变都有利于单体而非二聚体形成。所示突变的参考构建体氨基酸序列是SEQ ID NOS:273。其他相关序列是SEQ ID NOS:289和279。图17A和图17B显示了MN-E6 scFv-Fc无铰链突变的大规模表达和纯化的非还原性SDS-PAGE表征的照片,显示它是单体。显示了MN-E6 scFv-Fc无铰链突变体的FPLC表征和纯化(图17C)。图18A-18C显示纯化的MN-C3 scFv-Fc融合蛋白在非还原凝胶(图18A)或还原凝胶(图18B)上的SDS-PAGE表征的照片。通过尺寸排阻纯化蛋白。显示了FPLC迹线(图18C)。图19A-19B显示了MN-C3或MN-E6 Fab、scFv、scFv-Fc的天然凝胶的照片,其中Fc部分是野生型,或优选或仅为单体的突变。天然凝胶显示Y407R Fc突变(图19A)和双突变(Y407R和缺失的铰链)(图19B)最有利于单体而非二聚体。注意,蛋白以比常规使用浓度高得多的浓度加载到凝胶上。其他Fc突变体的二聚体形成可能仅反映了加载浓度非常高的事实。
一些突变或缺失是如此有效,即使以高浓度加载到凝胶上,它们也能抵抗二聚体的形成(图14A、14B)。Y407R突变导致几乎纯的二聚体scFv-Fc群体(图10)。类似地,Fc铰链区的缺失导致融合蛋白是单体而非二聚体。突变的组合可以导致更有效的二聚体形成抗性(图16和17)。将这些和其他突变及其组合引入CH2-CH3(SEQ ID NOS:274和275)和CH3(SEQ ID NOS:276和277)融合蛋白例如scFv,或无铰链Fc-融合蛋白中如scFv,显示消除或最小化二聚化。
与亲本小鼠单克隆抗体一样,人或人源化抗体以及单链构建体、scFv、scFv-Fc融合或scFv-Fc-突变与合成MUC1*肽特异性结合(图20-22)。图23显示ELISA测定的图,其定量人源化MN-E6 scFv-Fc-Δ铰链(又名脱铰链或无铰链)和人源化MN-E6 scFv与MUC1*肽PSMGFR的结合。
本文描述的人或人源化抗MUC1*抗体片段特异性结合MUC1和MUC1*阳性癌细胞。图24显示免疫荧光实验的照片,其中人源化MN-C2 scFv或MN-E6 scFv以相同的浓度依赖性方式特异性结合MUC1*阳性乳腺癌细胞。A-G:hu MN-C2 scFv以指示的浓度结合T47D乳腺癌细胞。H-N显示荧光标记的scFv和DAPI。O-U:hu MN-E6 scFv以指定的浓度结合T47D乳腺癌细胞。V-B'显示荧光标记的scFv和DAPI。C'是二抗对照。
除了与MUC1*阳性癌细胞结合外,抗MUC1*抗体可变区片段、scFv、scFv-Fc和scFv-Fc-突变抑制MUC1阳性癌细胞的生长。图25A-25L显示已在正常培养基中或在人源化MN-E6 scFv存在下培养的MUC1*阳性乳腺癌细胞的照片。照片显示5ug/mL的MN-E6 scFv对MUC1*阳性细胞的杀伤和/或生长抑制,并且在500ug/mL时具有甚至更大的作用。图26A-26L显示已在正常培养基中或在人源化MN-E6 scFv-Fc脱铰链(其是无铰链或Δ铰链突变体)存在下培养的MUC1*阳性乳腺癌细胞的照片。照片显示5ug/mL的hMN-E6 scFv-Fc脱铰链对MUC1*阳性细胞的杀伤和/或生长抑制,在50ug/mL时具有甚至更大的作用,并且在100ug/mL时还具有甚至更大的作用。图27显示了图25和26的荧光图像的图像分析图。图像J用于量化在人源化MN-E6scFv或MN-E6 scFv-Fc-Δ铰链(又名脱铰链)中处理96小时后剩余的细胞数。分析软件使用像素计数和像素荧光强度来量化每张照片中的细胞数量。对整个图像(512X512像素、8位图像)进行分析。为了比较,还分析了小鼠单克隆MN-E6 Fab的抑制。
这些数据显示人或人源化MN-E6抗体或抗体片段、Fab、MN-E6 scFv或hu MN-E6 scFv-Fcmut是有效的抗癌剂,可以给予被诊断患有MUC1或MUC1*阳性癌症、怀疑患有MUC1或MUC1*阳性癌症或有发展MUC1或MUC1*阳性癌症风险的人。
在这些具体实例中,融合到抗体片段或scFv上的二聚体抗性Fc是hu MN-E7scFv。然而,消除或最小化二聚化的任何这些Fc区突变或其组合可以融合到MN-E6、MN-C2、MN-C3或MN-C8的可变区片段或单链构建体上,或融合到鉴定为选择性结合MUC1*(当MUC1*存在于癌细胞或组织上)的其他抗体上。此外,这些抗体的Fab可用作抗癌治疗剂。在本发明的一个方面,用有效量的人或人源化MN-E6 scFv、MN-C2 scFv、MN-C3 scFv或MN-C8 scFv治疗被诊断患有、怀疑患有或有风险发生MUC1*或MUC1阳性癌症的人。在本发明的另一方面,用有效量的人或人源化MN-E6 scFv-FcY407R、MN-C2 scFv-FcY407R、MN-C3 scFv-FcY407R或MN-C8 scFv-FcY407R治疗被诊断患有、怀疑患有或有发展MUC1*或MUC1阳性癌症风险的人。在本发明的另一个方面,用有效量的人或人源化MN-E6 scFv-Fc突变脱铰链、MN-C2 scFv-Fc突变脱铰链、MN-C3 scFv-Fc突变体脱铰链、或MN-C8 scFv-Fc突变脱铰链治疗被诊断患有、怀疑患有或有发展MUC1*或MUC1阳性癌症风险的人。在本发明的另一个方面,用有效量的人或人源化MN-E6 scFv-Fc突变Y407R-脱铰链、MN-C2 scFv-Fc突变Y407R-脱铰链、MN-C3scFv-Fc突变Y407R-脱铰链、或MN-C8 scFv-Fc突变Y407R-脱铰链治疗被诊断患有、怀疑患有或有风险发展MUC1*或MUC1阳性癌症的人。本发明的一个方面是用于治疗被诊断患有、怀疑患有或有发展MUC1阳性或MUC1*阳性癌症的患者的方法,其中给予患者有效量的单体MN-E6 scFv、MN-C2 scFv、MN-C3 scFv、MN-C8 scFv或MN-E6 scFv-Fc、MN-C2 scFv-Fc、MN-C3 scFv-Fc、MN-C8 scFv-Fc,其中抗体样蛋白的Fc部分已被突变从而抵抗二聚体形成。
人源化
结合MUC1*的细胞外结构域的人源化抗体或抗体片段或全长人抗体优选用于治疗用途。本文描述的用于人源化抗体的技术仅是本领域技术人员已知的多种方法中的一些。本发明不受限于用于人源化抗体的技术。
人源化是在不改变其结合特异性和亲和力的情况下用人抗体替代治疗性抗体(通常是小鼠单克隆抗体)的非人区域的过程。人源化的主要目标是当向人给药时降低治疗性单克隆抗体的免疫原性。三种不同类型的人源化是可能的。首先,通过用人恒定区替换抗体的非人恒定区来制备嵌合抗体。这种抗体含有小鼠Fab区,含有约80-90%的人序列。其次,通过将小鼠CDR区(负责结合特异性)移植到人抗体的可变区上替代人CDR(CDR移植方法)来制备人源化抗体。这种抗体含有约90-95%的人序列。第三个也是最后一个,可以通过噬菌体展示产生全长人抗体(100%人序列),其中筛选人抗体文库以选择抗原特异性人抗体或通过免疫表达人抗体的转基因小鼠。
用于人源化抗体的大体技术大致如下实施。单克隆抗体在宿主动物中(通常在小鼠中)产生。然后筛选单克隆抗体的结合靶标的亲和力和特异性。一旦鉴定出具有所需效果和所需特征的单克隆抗体,就对其进行测序。然后将动物产生的抗体的序列与许多人抗体的序列比对,以便找到具有与动物抗体最同源的序列的人抗体。使用生物化学技术将人抗体序列和动物抗体序列粘合在一起。通常,将非人CDR移植到与非人抗体具有最高同源性的人抗体中。该过程可产生许多候选人源化抗体,需要进行测试以鉴定哪种或哪些抗体具有所需的亲和力和特异性。
一旦产生人抗体或人源化抗体,它可以进一步修饰用作Fab片段、作为全长抗体、或作为抗体样实体,例如含有可变区的单链分子,例如scFv或scFv-Fc。在某些情况下,希望使抗体或抗体样分子的Fc区突变,使得其不二聚化。
除了将人序列引入非人物种所产生的抗体中的方法之外,可以通过用抗原的肽片段筛选人抗体文库来获得全长人抗体。通过用具有PSMGFR N-10肽序列的肽筛选人抗体文库,产生功能如MN-E6或MN-C2的全长人抗体。通过用具有PSMGFR C-10肽序列的肽筛选人抗体文库,产生功能如MN-C3或MN-C8的全长人抗体。
基于小鼠单克隆抗体MN-E6、MN-C2、MN-C3和MN-C8的序列产生人源化抗MUC1*抗体。在本发明的一个方面,用有效量的人源化MN-E6、MN-C2、MN-C3或MN-C8治疗诊断患有MUC1*阳性癌症的患者。在优选的实施例中,用有效量的人源化MN-E6或MN-C2治疗诊断患有MUC1*阳性癌症的患者。在本发明的另一个方面,用有效量的人源化单价MN-E6、MN-C2、MN-C3或MN-C8治疗诊断患有MUC1*阳性癌症的患者,其中单价是指相应的Fab片段、相应的scFv或相应的scFv-Fc融合。在优选的实施例中,用有效量的人源化scFv、或MN-E6或MN-C2的单体人源化scFv-Fc治疗诊断患有MUC1*阳性癌症的患者。由于MUC1*生长因子受体被细胞外结构域的配体诱导二聚化而激活,并且因为抗体Fc部分同二聚化,优选包含使用预防或最小化二聚化的突变Fc区域的Fc部分的构建体。
与MUC1*受体的细胞外结构域的PSMGFR(SEQ ID NOS:2)肽结合的抗体是有效的抗癌治疗剂,其有效治疗或预防MUC1*阳性癌症。已经显示它们抑制激活配体二聚体NME1(SEQ ID NOS:3和4)和NME7(SEQ ID NOS:5和6)与MUC1*的细胞外结构域的结合。与PSMGFR序列结合的抗MUC1*抗体抑制MUC1*阳性癌细胞的生长,特别是如果它们抑制配体诱导的受体二聚化。已经证明抗MUC1*抗体的Fab阻断动物中的肿瘤生长。因此,结合MUC1*的细胞外结构域的抗体或抗体片段将有益于癌症(其中癌组织表达MUC1*)的治疗。
优选与MUC1*的PSMGFR区结合或与合成PSMGFR肽结合的抗体。我们已经鉴定了几种与MUC1*的细胞外结构域结合的单克隆抗体。在该组中,小鼠单克隆抗体MN-E6、MN-C2、MN-C3和MN-C8,其可变区被测序并给定为SEQ ID NOS:12-13和65-66(对于MN-E6)、SEQ ID NOS:118-119和168-169(对于MN-C2)、SEQ ID NOS:413-414和458-459(对于MN-C3)以及SEQ ID NOS:505-506和543-554(对于MN-C8)。这些抗体的CDR构成抗体的识别单位,并且是当移植入人抗体时应保留的小鼠抗体的最重要部分。每个小鼠单克隆的CDR序列如下,重链序列后面是轻链:MN-E6 CDR1(SEQ ID NOS:16-17和69-70)CDR2(SEQ ID NOS:20-21和73-74)CDR3(SEQ ID NOS:24-25和77-78)、MN-C2 CDR1(SEQ ID NOS:122-123和172-173)CDR2(SEQ ID NOS:126-127和176-177)CDR3(SEQ ID NOS:130-131和180-181)、MN-C3CDR1(SEQ ID NOS:417-418和462-463)CDR2(SEQ ID NOS:421-422和466-467)CDR3(SEQ ID NOS:425-426和470-471)、MN-C8CDR1(SEQ ID NOS:507-508和5B5-546)CDR2(SEQ ID NOS:509-510和547-548)CDR3(SEQ ID NOS:511-512和549-550)。在一些情况下,通过建模认为对于CDR的三维结构重要的框架区的部分也从小鼠序列导入。
单克隆抗体MN-E6和MN-C2对癌细胞上出现的MUC1*具有更大的亲和力。单克隆抗体MN-C3和MN-C8对干细胞上出现的MUC1*具有更大的亲和力。通过序列比对,选择以下人抗体与小鼠抗体充分同源,使得小鼠CDR的取代将导致保留识别靶标的能力的抗体。小鼠MN-E6重链可变区与人IGHV3-21*03重链可变区(SEQ ID NOS:26-27)同源,并且轻链可变区与人IGKV3-11*02轻链可变区(SEQ ID NOS:79-80)同源。小鼠MN-C2重链可变区与人IGHV3-21*04重链可变区(SEQ ID NOS:132-133)同源,轻链可变区与人IGKV7-3*01轻链可变区(SEQ ID NOS:182-183)同源。小鼠MN-C3重链可变区与人IGHV1-18*04重链可变区(SEQ ID NOS:427-428)同源,并且轻链可变区与人IGKV2-29*03轻链可变区(SEQ ID NOS:472-473)同源。小鼠MN-C8重链可变区与人IGHV3-21*04重链可变区(SEQ ID NOS:513-514)同源,并且轻链可变区与人Z00023轻链可变区(SEQ ID NOS:551-552)同源。
所有四种抗体都已人源化,该过程导致每种抗体的几种人源化形式。将衍生自小鼠抗体可变区的CDR生物化学移植到同源人抗体可变区序列中。MN-E6的人源化可变区(SEQ ID NOS:38-39和93-94)、MN-C2的人源化可变区(SEQ ID NOS:144-145和194-195)、MN-C3的人源化可变区(SEQ ID NOS:439-440和386-487)和MN-C8的人源化可变区(SEQ ID NOS:525-526和543-544)通过将小鼠CDR移植到同源人抗体的可变区中来产生。然后将人源化重链可变构建体融合到人IgG1重链恒定区(SEQ ID NOS:58-59)或人IgG2重链恒定区(SEQ ID NOS:54-55)的恒定区中,然后使其与融合到人κ链(SEQ ID NOS:109-110)或人λ链(SEQ ID NOS:113-114)恒定区的人源化轻链可变构建体配对。其他IgG同种型可以用作恒定区,包括IgG3或IgG4。
产生了人源化MN-E6可变区进入IgG2重链(SEQ ID NOS:52-53)和进入IgG1重链(SEQ ID NOS:56-57)、人源化MN-C2可变区进入IgG1重链(SEQ ID NOS:158-159)或进入IgG2重链(SEQ ID NOS:163-164)(配对有λ轻链(SEQ ID NO:111-112和216-219)或κ轻链(SEQ ID NO:107-108和210-213)),和人源化MN-C3(SEQ ID NOS:455-456、453-454和500-501、502-503)和MN-C8(SEQ ID NOS:541-542、539-540和579-580、581-582)抗体的实例。哪个IgG恒定区与人源化可变区融合取决于所需的效果,因为每个同种型具有其自身的特征活性。人恒定区的同种型是基于诸如是否需要抗体依赖性细胞毒性(ADCC)或补体依赖性细胞毒性(CDC)等因素来选择的,但也可取决于基于细胞蛋白表达系统中产生的抗体的产量。在优选的实施例中,将人源化抗MUC1*抗体或抗体片段给予诊断患有或有发展MUC1阳性癌症风险的人。
测试和选择最有用于治疗患有癌症或有患癌症风险的人的人源化抗MUC1*抗体的一种方法是测试它们抑制激活配体与MUC1*细胞外结构域结合的能力。二聚体NME1可以结合并二聚化MUC1*细胞外结构域,从而刺激癌细胞生长。因此,与NME1竞争结合MUC1*细胞外结构域的抗体和抗体片段是抗癌剂。NME7是MUC1*的另一种激活配体。在一些情况下,优选鉴定阻断NME7、或NME7截短或切割产物与MUC1*细胞外结构域结合的抗体。与NME7和NME7变体竞争结合MUC1*细胞外结构域的抗体和抗体片段作为抗癌治疗剂是有效的。这些抗体包括但不限于MN-E6、MN-C2、MN-C3、MN-C8以及这些抗体的单链形式(例如scFv)及其人源化形式。其他NME蛋白也结合MUC1或MUC1*,包括NME6和NME8。与这些蛋白竞争结合MUC1*的抗体也可用作治疗剂。在优选的实施例中,将人源化抗MUC1*抗体或抗体片段给予诊断患有或有发展MUC1阳性癌症风险的人。在更优选的实施例中,将衍生自MN-E6和MN-C2的人源化序列的单链抗体片段或单体scFv-Fc融合给予诊断患有或有发展MUC1阳性癌症风险的人。
单链可变片段、scFv或产生单价抗体或抗体样蛋白的其他形式也是有用的。在某些情况下,希望防止MUC1*细胞外结构域二聚化。已显示单链可变片段、Fab和其他单价抗体样蛋白有效结合MUC1*的细胞外结构域并阻断MUC1*二聚化。这些单链可变片段、Fab和其他单价抗体样分子在体外和用人MUC1阳性癌细胞异种移植的动物中有效阻断癌症生长。因此,人源化单链可变片段或单价抗MUC1*抗体或抗体样分子作为抗癌治疗剂将是非常有效的。因此,这种人源化单链抗体、Fab和与MUC1*细胞外结构域或PSMGFR肽结合的其他单价抗体样分子可用作抗癌治疗剂。通过将结合MUC1*的细胞外结构域或结合PSMGFR肽的抗体的非人CDR移植到同源可变区人抗体的框架中来产生抗MUC1*单链可变片段。然后通过合适的接头将得到的人源化重链和轻链可变区彼此连接,其中接头应该是柔性的并且其长度允许重链与轻链结合但是阻止一个分子的重链与另一个分子的轻链结合。例如,约10-15个残基的接头。优选地,接头包括[(甘氨酸)4(丝氨酸)1]3(SEQ ID NOS:401-402),但不限于该序列,因为其他序列也是可能的。
一方面,将MN-E6的人源化可变区(SEQ ID NOS:38-39和93-94),MN-C2的人源化可变区(SEQ ID NOS:144-145和194-195),MN-C3的人源化可变区(SEQ ID NOS:439-440和486-487)和MN-C8的人源化可变区(SEQ ID NOS:525-526和565-566)生物化学移植到通过接头连接的重链和轻链的构建体中。产生包含来自MN-E6、MN-C2、MN-C3和MN-C8的可变区的人源化序列的人源化单链抗MUC1*抗体的实例。产生几种人源化MN-E6单链蛋白(SEQ ID NOS:232-237)。产生几种人源化MN-C2单链蛋白(SEQ ID NOS:238-243)。产生几种人源化MN-C3单链蛋白(SEQ ID NOS:244-249)。产生几种人源化MN-C8单链蛋白(SEQ ID NOS:250-255)。在优选的实施例中,将人源化抗MUC1*抗体片段,包括可变片段、scFv抗体片段MN-E6 scFv、MN-C2 scFv、MN-C3 scFv或MN-C8 scFv给予诊断患有或有发展MUC1阳性癌症风险的人。在更优选的实施例中,将单链抗体片段(例如衍生自MN-E6和MN-C2的人源化序列的可变片段)给予诊断患有或有发展MUC1阳性癌症风险的人。
另一方面,将MN-E6的人源化可变区(SEQ ID NOS:38-39和93-94)、MN-C2的人源化可变区(SEQ ID NOS:144-145和194-195)、MN-C3的人源化可变区(SEQ ID NOS 439-440和486-487)和MN-C8的人源化可变区(SEQ ID NOS:525-526和565-566)生物化学移植到单链可变片段scFv中(其也含有抗体的Fc部分)。产生融合至抗体Fc区的MN-E6、MN-C2、MN-C3和MN-C8的人源化单链可变片段的实例(SEQ ID NOS:256-257、260-261、264-265和268-269)。包含Fc区有几个目的。它增加了抗体片段的分子量,从而减缓了降解并延长了半衰期。Fc区还募集免疫系统补体到肿瘤部位。另外,添加抗体Fc区使得scFv成为方便的诊断工具,因为二抗检测并标记Fc部分。然而,Fc部分是同源二聚体。因此,scFv-Fc将是二价的并且可以二聚化并激活MUC1*生长因子受体。为了获得使Fc附着于抗MUC1*scFv的益处,没有诱导MUC1*二聚化的缺点,突变Fc区以最小化或消除Fc同二聚化。在CH3结构域中进行以下突变以产生单体scFv-Fc融合蛋白:Y407R(SEQ ID NOS:278和279)、F405Q(SEQ ID NOS:280和281)、T394D(SEQ ID NOS:282和283)、T366W/L368W(SEQ ID NOD:284和285)、T364R/L368R(SEQ ID NOS:286和285)。可以测试这些突变的任何组合,并且可以将其引入Fc(SEQ ID NOS:272-273)、CH2-CH3(SEQ ID NOS:274-275)或CH3(SEQ ID NOS:276-277)融合蛋白或在无铰链Fc融合蛋白中(SEQ ID NOS:288-289)。
本发明的一个方面是用于治疗被诊断患有、怀疑患有或有发展MUC1阳性或MUC1*阳性癌症的患者的方法,其中给予患者有效量的单体MN-E6 scFv、MN-C2 scFv、MN-C3 scFv、MN-C8 scFv或MN-E6 scFv-Fc、MN-C2 scFv-Fc、MN-C3 scFv-Fc、MN-C8 scFv-Fc,其中抗体可变片段部分是人或已经人源化的并且其中抗体样蛋白的Fc部分已经突变,使得它抵抗二聚体形成。
CAR T和癌症免疫治疗技术
在本发明的另一个方面,使用几种不同的嵌合抗原受体(CAR)策略,将抗MUC1*抗体片段的一些或全部单链部分生物化学融合到免疫系统分子上。该想法是将抗体的识别部分(通常作为单链可变片段)融合至具有跨膜结构域和能够传递激活免疫系统信号的胞质尾区的免疫系统分子。识别单元可以是抗体片段、单链可变片段、scFv或肽。在一个方面,CAR细胞外结构域的识别部分包括来自MN-E6的人源化可变区(SEQ ID NOS:38-39和93-94)、MN-C2的人源化可变区(SEQ ID NOS:144-145和194-195)、MN-C3的人源化可变区(SEQ ID NOS:439-440和486-487)和MN-C8的人源化可变区(SEQ ID NOS:525-526和565-566)的序列。另一方面,它包括来自单链可变片段的序列。给出了单链构建体的实例。产生几种人源化MN-E6单链蛋白scFv(SEQ ID NOS:232-237)。产生几种人源化MN-C2单链蛋白scFv(SEQ ID NOS:238-243)。产生几种人源化MN-C3单链蛋白scFv(SEQ ID NOS:244-249)。产生几种人源化MN-C8单链蛋白scFv(SEQ ID NOS:250-255)。CAR的跨膜区可以衍生自CD8、CD4、抗体结构域或其他跨膜区,包括近端细胞质共刺激结构域的跨膜区,例如CD28、4-1BB或其他。CAR的胞质尾区可包括一个或多个信令免疫系统激活的基序。这组细胞质信号传导基序,有时称为共刺激细胞质结构域,包括但不限于CD3-ζ、CD27、CD28、4-1BB、OX40、CD30、CD40、ICAm-1、LFA-1、ICOS、CD2、CD5、CD7和Fc受体γ结构域。最小CAR可以具有CD3-ζ或Fc受体γ结构域,然后在胞质尾区串联一个或两个上述结构域。在一个方面,胞质尾区包含CD3-ζ、CD28、4-1BB和/或OX40。
表1列出了我们产生和测试的许多抗MUC1*CAR。产生几个MN-E6 CAR的实例:CAR MN-E6 CD3z(SEQ ID NOS:294-295)、CAR MN-E6 CD28/CD3z(SEQ ID NOS:297-298)、CAR MN-E6 4-1BB/CD3z(SEQ ID NOS:300-301)、CAR MN-E6 OX40/CD3z(SEQ ID NOS:616-617)、CAR MN-E6 CD28/OX40/CD3z(SEQ ID NOS:618-619)、CAR MN-E6 CD28/4-1BB/CD3z(SEQ ID NOS:303-304)。产生几个人源化MN-C2 CAR的实例:CAR MN-C2 CD3z(SEQ ID NOS:606-607)、CAR MN-C2 CD28/CD3z(SEQ ID NOS:608-609)、CAR MN-C2 4-1BB/CD3z(SEQ ID NOS:610-611)、CAR MN-C2OX40/CD3z(SEQ ID NOS:612-613)、CAR MN-C2 CD28/4-1BB/CD3z(SEQ ID NOS:306-307)、CAR MN-C2 CD28/OX40/CD3z(SEQ ID NOS:614-615)。产生人源化MN-C3CAR:CAR MN-C34-1BB/CD3z(SEQ ID NOS:600-601)。
产生具有不同铰链区(SEQ ID NOS:345-360)的人源化MN-E6 CAR的几个实例:CAR MN-E6-Fc/8/41BB/CD3z(SEQ ID NOS:310-311)、CAR MN-E6 FcH/8/41BB/CD3z(SEQ ID NOS:315-316)、CAR MN-E6 Fc/4/41BB/CD3z(SEQ ID NOS:318-319)、CAR MN-E6 FcH/4/41BB/CD3z(SEQ ID NOS:321-322)、CAR MN-E6 IgD/8/41BB/CD3z(SEQ ID NOS:323-324)、CAR MN-E6 IgD/4/41BB/CD3z(SEQ ID NOS:327-328)、CAR MN-E6 X4/8/41BB/CD3z(SEQ ID NOS:330-331)、CAR MN-E6 X4/4/41BB/CD3z(SEQ ID NOS:333-334)、CAR MN-E6 8+4/4/41BB/CD3z(SEQ ID NOS:336-337)。此外,还产生了几种人源化MN-C3单链可变片段和人源化MN-C8单链可变片段。
还产生并测试了几种CAR,其中CAR的靶向头来源于抗MUC1*抗体MNC2。CAR MN-C2-Fc/41BB/CD3z(SEQ ID NOS:732-733)、CAR-MN-C2IgD/Fc/4-1BB/CD3z(SEQ ID NOS:734-735)、CAR MN-C2FcH/41BB/CD3z(SEQ ID NOS:736-737)、CAR-MN-C2IgD/FcH/4-1BB/CD3z(SEQ ID NOS:738-739)、CAR MN-C2IgD/41BB/CD3z(SEQ ID NOS:740-741)、CAR MN-C2X4/41BB/CD3z(SEQ ID NOS:742-743)。
MUC1*靶向CAR的细胞外结构域识别单元可包含能够结合PSMGFR肽(SEQ ID NOS:2)的至少12个连续氨基酸的任何非人、人源化或人抗体的可变区。在一个方面,CAR的MUC1*靶向部分包含来自非人、人源化或人MN-E6、MN-C2、MN-C3或MN-C8的可变区。在一个方面,CAR的细胞外结构域识别单元基本上包括人源化MN-E6、MN-C2、MN-C3或MN-C8单链可变片段scFv。CAR的跨膜区可以衍生自CD8(SEQ ID NOS:363-364),或可以是CD3-ζ、CD28、41bb、OX40或其他跨膜区的跨膜结构域(SEQ ID NOS:361-372),具有靶向MUC1*细胞外结构域的抗体片段的CAR的细胞质结构域可以包含选自包含免疫系统共刺激细胞质结构域的组中的一种或多种。免疫系统共刺激结构域的组包括但不限于CD3-ζ、CD27、CD28、4-1BB、OX40、CD30、CD40、ICAm-1、LFA-1、ICOS、CD2、CD5、CD7和Fc受体γ结构域(SEQ ID NOS:373-382)。或者,CAR的识别单元部分可包含肽,其中肽与靶标结合。NME7结合并激活MUC1*。在本发明的一个方面,CAR的识别单元是衍生自NME7的肽(SEQ ID NOS:5-6)或衍生自NME7的肽,包括但不限于NME7肽A1(SEQ ID NOS:7)、NME7肽A2(SEQ ID NOS:8)、NME7肽B1(SEQ ID NOS:9)、NME7肽B2(SEQ ID NOS:10)和NME7肽B3(SEQ ID NOS:11)。
产生CAR的一些策略包括与其自身二聚化的分子的一部分。在某些情况下,靶标的二聚化是不希望的。因此,可以构建CAR以使它们异二聚化。在一种情况下,第一CAR的识别单元结合第一靶,而第二CAR的识别单元结合第二靶。两个识别单元可以是抗体片段,两者都可以是肽,或者一个可以是抗体片段另一个可以是肽。CAR的第一个靶标可以是MUC1*的细胞外结构域。CAR的识别单元将包括结合MUC1*细胞外结构域或PSMGFR肽的抗体片段。或者,CAR的识别单元将包括结合MUC1*细胞外结构域的肽,这些肽包括衍生自NME蛋白例如NME1或NME7的肽,更特别是如SEQ ID NOS:7-11所列的NME7衍生肽。异二聚体CAR的第二靶标可以是结合NME7的肽或抗体片段。或者,异二聚体CAR的第二靶标可以是与PD1或其同源配体PDL-1或靶癌细胞的其他靶配体结合的肽或抗体片段。第二靶标可以是结合NME1或NME7-AB的肽或抗体片段。因为期望防止由CAR诱导的MUC1的二聚化,可以构建异二聚体CAR,使得仅一个分子的细胞外结构域具有与靶标结合的细胞外识别单元(SEQ ID NOS:584-587)。另一个分子可具有缺乏靶识别单元或抗体片段的截短的细胞外结构域(SEQ ID NOS:588-599)。
所描述的CAR可以被转染或转导到免疫系统的细胞中。在优选的实施例中,将MUC1*靶向CAR转染或转导到T细胞中。在一个方面,T细胞是CD3+/CD28+T细胞。在另一种情况下,它是树突细胞。在另一种情况下,它是B细胞。在另一种情况下,它是肥大细胞。受体细胞可以来自患者或来自供体。如果来自供体,可以将其工程化为去除会引发排斥的分子。用本发明的CAR转染或转导的细胞可以离体或体外扩增,然后给予患者。给药途径选自包括但不限于骨髓移植、静脉内注射、原位注射或移植的组。在优选的实施例中,将MUC1*靶向CAR给予于被诊断患有或有发展MUC1阳性癌症风险的人。
有许多可能的抗MUC1*CAR构建体可以转导到T细胞或其他免疫细胞中,用于治疗或预防MUC1*阳性癌症。CAR由模块组成,一些模块的身份相对不重要,而其他模块的身份至关重要。
我们的实验证明,CAR最外部的抗体识别片段至关重要,因为它将带有CAR的免疫细胞靶向于肿瘤部位。细胞内信号传导基序也非常重要,但可以互换。图28显示了CAR的组分和可包含在CAR中的各种序列的示意图。参见图28,
R1是:什么都没有;或
癌症相关抗原的配体或配体片段;或
MUC1或MUC1*的配体或配体片段;或
抗体或抗体片段,其中抗体或抗体片段与MUC1或MUC1*结合;或抗体或抗体片段,其中所述抗体或抗体片段与PSMGFR*结合,其中所述抗体可以是人的或人源化的;或MN-E6、MN-C2、MN-C3或MN-C8的抗体或抗体片段或人源化的MN-E6、MN-C2、MN-C3或MN-C8;或抗体的单链可变片段scFv,其与切割的MUC1或MUC1*结合;或者可以人源化的MN-E6、MN-C2、MN-C3或MN-C8的scFv;或与MUC1*或PSMGFR肽结合的肽;或者是结合MUC1*的PSMGFR部分的抗体片段、scFv或肽;或者包括来自MN-E6(SEQ ID NOS:38-39和93-94)、MN-C2(SEQ ID NOS:144-145和194-195)、MN-C3(SEQ ID NOS:439-440和486-487)和MN-C8(SEQ ID NOS:525-526和565-566)的人源化可变区的序列。在一个方面,R1是结合MUC1*的PSMGFR部分的scFv,其包含来自人源化MN-E6 scFv(SEQ ID NOS:232-237)、人源化MN-C2 scFv(SEQ ID NOS:238-243)、人源化MN-C3 scFv(SEQ ID NOS:244-249)或人源化MN-C8 scFv(SEQ ID NOS:250-255)的序列。在另一个方面,R1是结合MUC1*的PSMGFR部分的scFv,其包含来自人源化MN-E6 scFv(SEQ ID NOS:232-237)或人源化MN-C2 scFv(SEQ ID NOS:238-243)的序列。在一个实例中,R1是结合MUC1*的PSMGFR部分的scFv,其包含来自人源化MN-E6 scFv(SEQ ID NOS:232-237)的序列。
R2是多肽柔性接头,其将识别部分连接至CAR的跨膜结构域。在一个方面,R2可以是5至250个氨基酸的不同长度的多肽接头。另一方面,R2是人源的多肽接头。在一个方面,R2可以由人免疫球蛋白(IgG、IgA、IgE、IgM或IgD)的Fc区构成或是其修饰。在另一方面,R2可以是人免疫球蛋白(IgG、IgA、IgE、IgM或IgD)的铰链区或铰链区的修饰。在一个方面,R2可以是T细胞受体(CD8a、CD28或CD4)的铰链区或铰链区的修饰。在一个实例中,R2是CD8a的铰链区、人IgD的铰链区或人IgG1的Fc结构域。
R3是跨膜结构域。在一个方面,R3可以是任何跨膜人蛋白的跨膜结构域或跨膜结构域的修饰。在另一个方面,R3可以是来自人细胞受体的跨膜结构域或跨膜结构域的修饰。在一个方面,R3可以是T细胞受体(CD8a,CD4,CD28,CD3z,OX40或41-BB)的跨膜结构域或跨膜结构域的修饰。在另一方面,R3是衍生自CAR的第一细胞质共刺激结构域的跨膜结构域。在一个方面,R3可以是T细胞受体的跨膜结构域或跨膜结构域的修饰,所述T细胞受体延伸有与跨膜结构域相关的细胞质结构域的1、2、3、4或5个氨基酸。在另一个方面,R3可以是T细胞受体的跨膜结构域或跨膜结构域的修饰,所述T细胞受体延伸有与跨膜结构域相关的细胞质结构域的1、2、3、4或5个氨基酸,随后是用于形成二硫键的半胱氨酸。在一个实例中,R3是CD8a或CD4的跨膜结构域。
R4是来自T细胞受体的信号传导结构域。在一个方面,R4可以是CD3-ζ、CD27、CD28、4-1BB、OX40、CD30、CD40、ICAm-1、LFA-1、ICOS、CD2、CD5、CD7和Fc受体γ结构域的细胞质信号传导结构域。在一个实例中,R4是CD3-ζ的细胞质结构域。再产生了几个具有单个信号传导结构域(CAR I)的人源化CAR的例子:CAR MN-E6 CD3z(SEQ ID NOS:294-295);CAR MN-C2 CD3z(SEQ ID NOS:606-607)
R5是来自T细胞受体的共刺激结构域。在一个方面,R5可以是CD27、CD28、4-1BB、OX40、CD30、CD40、ICAm-1、LFA-1、ICOS、CD2、CD5、CD7和Fc受体γ结构域的细胞质信号传导结构域。R5与R4和R6不同。在一个实例中,R5是CD28、4-1BB或OX40的细胞质结构域。再产生了几个具有两个信号传导结构域(CAR II)的人源化CAR的例子:CAR MN-E6 CD28/CD3z(SEQ ID NOS:297-298)、CAR MN-E6 4-1BB/CD3z(SEQ ID NOS:300-301)、CAR MN-E6 OX40/CD3z(SEQ ID NOS:616-617)、CAR MN-C2 CD28/CD3z(SEQID NOS:608-609)、CAR MN-C2 4-1BB/CD3z(SEQ ID NOS:610-611);CAR MN-C2OX40/CD3z(SEQ ID NOS:612-613)、MN-C3 4-1BB/CD3z(SEQ ID NOS:600-601)、CARMN-E6-Fc/8/41BB/CD3z(SEQ ID NOS:310-311)、CAR MN-E6-FcH/8/41BB/CD3z(SEQ IDNOS:315-316)、CAR MN-E6 Fc/4/41BB/CD3z(SEQ ID NOS:318-319)、CAR MN-E6 FcH/4/41BB/CD3z(SEQ ID NOS:321-322)、CAR MN-E6 IgD/8/41BB/CD3z(SEQ ID NOS:323-324)、CAR MN-E6 IgD/4/41BB/CD3z(SEQ ID NOS:327-328)、CAR MN-E6 X4/8/41BB/CD3z(SEQ ID NOS:330-331)、CAR MN-E6 X4/4/41BB/CD3z(SEQ ID NOS:333-334)、CAR MN-E6 8+4/4/41BB/CD3z(SEQ ID NOS:336-337)。
R6是来自T细胞受体的共刺激结构域。在一个方面,R6可以是CD27、CD28、4-1BB、OX40、CD30、CD40、ICAm-1、LFA-1、ICOS、CD2、CD5、CD7和Fc受体γ结构域的细胞质信号传导结构域。R6与R4和R5不同。在一个实例中,R5是CD28的细胞质结构域。再产生了几个具有两个信号传导结构域(CAR III)的人源化CAR的例子:CAR MN-E6 CD28/OX40/CD3z(SEQ ID NOS:618-619)、CAR MN-E6 CD28/4-1BB/CD3z(SEQ ID NOS:303-304)、CAR MN-C2 CD28/4-1BB/CD3z(SEQ ID NOS:306-307)、CAR MN-C2CD28/OX40/CD3z(SEQ ID NOS:614-615)
我们和其他人已经显示,细胞内信号传导模块,例如CD3-ζ(SEQ ID NOS:373-376)、CD28(SEQ ID NOS:377-378)和41BB(SEQ ID NOS:379-380),单独或组合刺激免疫细胞扩增、细胞因子分泌和免疫细胞介导的靶向肿瘤细胞的杀伤(Pulè MA,Straathof KC,Dotti G,Heslop HE,Rooney CM and Brenner MK(2005)A chimeric T cell antigen receptor that augments cytokine release and supports clonal expansion of primary human T cells.Mol Ther.12(5):933-941;Hombach AA,Heiders J,Foppe M,Chmielewski M and Abken H.(2012)OX40costimulation by a chimeric antigen receptor abrogates CD28and IL-2induced IL-10secretion by redirected CD4(+)T cells.Oncoimmunology.1(4):458-466;Kowolik CM,Topp MS,Gonzalez S,Pfeiffer T,Olivares S,Gonzalez N,Smith DD,Forman SJ,Jensen MC and Cooper LJ.(2006)CD28costimulation provided through a CD19-specific chimeric antigen receptor enhances in vivo persistence and antitumor efficacy of adoptively transferred T cells.Cancer Res.66(22):10995-11004;Loskog A,Giandomenico V,Rossig C,Pule M,Dotti G and Brenner MK.(2006)Addition of the CD28 signaling domain to chimeric T-cell receptors enhances chimeric T-cell resistance to T regulatory cells.Leukemia.20(10):1819-1828;Milone MC,Fish JD,Carpenito C,Carroll RG,Binder GK,Teachey D,Samanta M,Lakhal M,Gloss B,Danet-Desnoyers G,Campana D,Riley JL,Grupp SA and June CH.(2009)Chimeric receptors containing CD137signal transduction domains mediate enhanced survival of T cells and increased antileukemic efficacy in vivo.Mol Ther.17(8):1453-1464;Song DG,Ye Q,Carpenito C,Poussin M,Wang LP,Ji C,Figini M,June CH,Coukos G,Powell DJ Jr.(2011)In vivo persistence,tumor localization,and antitumor activity of CAR-engineered T cells is enhanced by costimulatory signaling through CD137(4-1BB).Cancer Res.71(13):4617-4627)。不太重要的是短细胞外片的特性,其呈提抗体片段、跨膜结构域和在细胞内信号传导基序之前出现的短胞质尾区。
将CAR靶向于肿瘤的识别抗体片段的身份至关重要。为了治疗MUC1阳性或MUC1*阳性癌症,抗体识别片段必须结合在切割和脱落大部分细胞外结构域(包含串联重复结构域)后保留的MUC1部分的细胞外结构域。在本发明的一个方面,保留的部分包含PSMGFR序列。在本发明的另一个方面,在切割和脱落后保留的MUC1部分含有PSMGFR序列加上在N末端延伸多达九(9)个以上的氨基酸。在本发明的另一个方面,在切割和脱落后保留的MUC1部分含有PSMGFR序列加上在N末端延伸的多达二十一(21)个以上的氨基酸。在一个方面,抗体识别片段结合PSMGFR肽的至少十二个连续氨基酸。在本发明的另一方面,抗体识别片段与包含以下序列的肽结合:SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:620);或者SVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:621)。
作为证明,将包含称为MN-E6或MN-C2的单克隆抗MUC1*抗体的可变结构域的单链抗体片段工程化到一组CAR中(表1)。然后将MUC1*靶向CAR分别或组合转导入免疫细胞。当用呈提MUC1*肽的表面(转染了MUC1*的抗原呈提细胞或MUC1*阳性癌细胞)攻击时,MUC1*靶向CAR转导的免疫细胞引发免疫应答,包括细胞因子释放、靶细胞杀伤和免疫细胞的扩增(表2)。
在一种情况中,用MUC1*靶向CAR转导人Jurkhat细胞,并且当暴露于呈提PSMGFR肽的表面(已经用MUC1*转染的K562抗原呈提细胞或MUC1*阳性癌细胞)时,Jurkhat细胞分泌IL-2。在另一种情况下,用MUC1*靶向CAR转导纯化的人T细胞,并且当暴露于呈提PSMGFR肽的表面(已经用MUC1*转染的K562抗原呈提细胞或MUC1*阳性癌细胞)时,T细胞分泌IL-2、干扰素γ,杀死靶向抗原呈提细胞和癌细胞,同时T细胞扩增。如所证明的,当包含抗体片段的CAR被转导入包括T细胞的免疫细胞时,引发免疫系统抗肿瘤细胞应答,其中抗体片段能够结合PSMGFR肽(跨膜结构域和带有共刺激结构域的胞质尾区)。因此,能够结合PSMGFR肽的其他抗体、抗体片段或抗体模拟物将会表现相似并且可用于治疗或预防癌症。本领域技术人员将认识到,有许多技术可用于用CAR转染或转导细胞,并且本发明不受用于使免疫细胞表达MUC1*靶向CAR的方法的限制。
例如,本文所述的编码CAR的基因和激活的T细胞诱导基因可以病毒转导到免疫细胞中,这可能会或可能不会导致CAR基因掺入到受体细胞的基因组中。可以使用病毒递送系统和病毒载体,包括但不限于逆转录病毒,包括γ-逆转录病毒、慢病毒、腺病毒、腺相关病毒、杆状病毒、痘病毒、单纯疱疹病毒、溶瘤病毒、HF10、T-Vec等。除病毒转导外,本文所述的CAR和激活的T细胞诱导基因可以使用诸如CRISPR技术、CRISPR-Cas9和-CPF1、TALEN、睡美人转座子系统和SB 100X等方法直接剪接到受体细胞的基因组中。
类似地,构成CAR的非靶向部分的分子身份(例如细胞外结构域、跨膜结构域和细胞质结构域的膜近端部分)对于MUC1*靶向CAR的功能不是必需的。例如,细胞外结构域,跨膜结构域和细胞质结构域的膜近端部分可以包含CD8、CD4、CD28的部分,或通用抗体结构域例如Fc、CH2CH3或CH3。此外,CAR的非靶向部分可以是这些分子中的一种或多种或其他家族成员的部分的复合物。
本发明的一个方面是用于治疗被诊断患有、怀疑患有或有发展MUC1阳性或MUC1*阳性癌症的患者的方法,其中给予患者有效量的已经用MUC1*靶向CAR转导的免疫细胞。在本发明的另一个方面,免疫细胞是从患者分离的T细胞,然后用CAR转导,其中CAR的靶向头结合MUC1*,并且在扩增转导的T细胞后,给予患者有效量CAR T细胞。在本发明的另一方面,免疫细胞是从患者分离的T细胞,然后用CAR转导,其中CAR的靶向头包含huMN-E6、huMN-C2、huMN-C3或huMN-C8的部分,在可选的扩增转导的T细胞后,给予患者有效量CAR T细胞。在本发明的另一个方面,转导到免疫细胞中并给予诊断患有MUC1或MUC1*阳性癌症的患者的CAR选自表1或表2中的CAR列表。
制备和测试CAR的细节
产生许多MUC1*靶向CAR,其中CAR远端的靶向抗体片段是MN-E6、MN-C2、MN-C3或MN-C8。对每个CAR的DNA进行测序以验证克隆是否正确完成。然后将每个构建体改组成表达质粒,转染到细胞中,然后通过蛋白印迹验证构建体已成功插入。通过FACS验证表面表达。然后将MUC1*靶向CAR病毒转导到免疫细胞中。在一个方面,将它们转导入Jurkat细胞。另一方面,将它们转导到从血液中纯化的原代人T细胞中。进行一系列功能测定并验证CAR是功能性的。功能测定显示,当用呈提MUC1*的细胞或表面攻击时,MUC1*靶向CAR转导的Jurkat细胞和原代T细胞都分泌细胞因子IL-2和干扰素γ(IFN-g)。表1列出了制备和测试的CAR。表2列出了一些CAR在转导入人T细胞并与多种癌细胞共培养后的细胞因子释放数据。图29是测量由用一组CAR转导的Jurkat细胞分泌IL-2细胞因子的实验图,所述一组CAR包括MN-E6 CD8/CD3z、MN-E6 CD8/CD28/CD3z、MN-E6 CD8/41BB/CD3z、MN-E6 CD4/CD28/CD3z和MN-E6 CD4/CD28/41BB/CD3z。仅当CAR Jurkat细胞暴露于K562-wt细胞或已经用MUC1*转染的K562细胞时,IL-2才被分泌。应注意,亲本K562-wt细胞表达非常低水平的MUC1*。对于转染到Jurkat细胞中的另一组CAR,类似地测试细胞因子分泌。图30显示用MN-E6 CD8/CD28/CD3z、MN-E6 CD8/41BB/CD3z、MN-E6 CD4/CD28/CD3z或MN-E6 CD4/41BB/CD3z转导的Jurkat T细胞的IL-2分泌,此时这些CAR T细胞暴露于K562-wt细胞或已用MUC1*转染的K562细胞。类似地,图31显示用MN-E6 CD8/CD28/CD3z、MN-E6 CD8/41BB/CD3z或MN-E6 CD4/41BB/CD3z转导的原代人T细胞的IL-2细胞因子分泌。仅当MUC1*靶向CAR T细胞暴露于K562-wt细胞或已经用MUC1*转染的K562细胞时,才发生细胞因子分泌。激活的T细胞在看到靶细胞时分泌的另一种细胞因子是干扰素-γ(IFN-g)。图32显示用一组CAR(包括MN-E6 CD8/CD28/CD3z和MN-E6 CD4/41BB/CD3z)转导的原代人T细胞的干扰素-γ分泌,此时这些CAR T细胞暴露于K562-wt细胞或已用MUC1*转染的K562细胞。干扰素-γ类似地由用一组CAR(包括MN-E6 CD8/CD28/CD3z、MN-E6 CD8/41BB/CD3z和MN-E6 CD8/CD28/41BB/CD3z)转导的原代人T细胞分泌,此时这些MUC1*靶向CAR T细胞暴露于K562-wt细胞、或已用MUC1*转染的K562细胞、或前列腺癌(DU145)、乳腺癌(1500)或胰腺癌(Capan)的MUC1*阳性细胞(图33)。
CAR T细胞功能的另一个衡量标准是它们是否诱导杀伤靶细胞。用多种包含与MUC1的PSMGFR序列结合的抗体片段的CAR所转染的T细胞,在共培养测定中杀伤MUC1*表达细胞。在一个测定中,将靶MUC1*表达细胞与钙黄绿素一起温育。当它们与CAR T细胞混合时,其中CAR包含抗体片段例如MN-E6、MN-C2、MN-C3或MN-C8,CAR T细胞杀死MUC1*呈提细胞,这导致靶细胞裂解并且将钙黄绿素释放到上清液中。图34是测量从血液样品中分离的原代人T细胞(用一组CAR转导,包括MN-E6 CD8/CD28/CD3z、MN-E6 CD8/41BB/CD3z和MN-E6 CD4/41BB/CD3z)的靶细胞死亡的实验图,此时这些CAR T细胞暴露于K562-wt细胞或已用MUC1*转染的K562细胞。T细胞与靶细胞的比例为1:1,将细胞共培养24小时。图35A-35B是FACS测量从第1天到第3天的靶细胞存活的时间过程的图。用一组CAR转导从血液样品中分离的原代人T细胞,包括人源化MN-E6-CD8-3z、MN-E6-CD8-CD28-3z、MN-E6-CD8-41BB-3z和MN-E6-CD8-CD28-41BB-3z。然后将CAR T细胞暴露于天然表达低水平MUC1*的K562-wt细胞、或已经用MUC1*高转染的K562细胞。MUC1*靶向CAR T细胞与靶细胞的比例为1:1、10:1或20:1。在第1天或第3天检测并测量存活细胞。
图36是共培养实验第3天的靶细胞存活的FACS测量图。用一组CAR转导原代人T细胞,包括人源化MN-E6-CD8-3z、MN-E6-CD8-CD28-3z、MN-E6-CD8-41BB-3z和MN-E6-CD8-CD28-41BB-3z。然后将CAR T细胞暴露于MUC1*阳性T47D乳腺癌细胞或MUC1*阳性1500(又名ZR-75-1)乳腺癌细胞。MUC1*靶向CAR T细胞与靶细胞的比例为1:1或10:1。从图中可以看出,用MUC1*靶向CAR转导的T细胞对MUC1*癌细胞的杀伤作用比未转导的对照T细胞高得多。此外,当T细胞:靶细胞的比例增加时,杀伤效果更大。图37是共培养实验第1天的靶细胞存活的FACS测量图。用一组CAR转导原代人T细胞,包括人源化MN-E6-CD8-41BB-3z、MN-E6-CD4-41BB-3z和MN-E6-CD8-CD28-41BB-3z。然后将CAR T细胞暴露于以下MUC1*阳性癌细胞:T47D乳腺癌、capan2胰腺癌、或DU-145前列腺癌。MUC1*靶向CAR T细胞与靶细胞的比例为5:1。从图中可以看出,用MUC1*靶向CAR转导的T细胞对MUC1*癌细胞的杀伤作用比未转导的对照T细胞高得多。注意,在24小时后进行测量,仅具有5:1的T细胞与靶细胞的比率。还要注意,MUC1*靶向CAR具有与CD8构建体等效的CD4细胞外结构域-跨膜-胞质尾区。
图38是共培养实验第3天的靶细胞存活的FACS测量图。用一组CAR转导原代人T细胞,包括人源化MN-E6-CD8-41BB-3z、MN-E6-CD4-41BB-3z和MN-E6-CD8-CD28-41BB-3z。然后将CAR T细胞暴露于以下MUC1*阳性癌细胞:MUC1*转染的K562白血病细胞、T47D乳腺癌、1500(又名ZR-75-1)乳腺癌细胞、或CAPAN-2胰腺癌细胞。除了未转导的T细胞对照之外,在PC3MUC1*阴性前列腺癌细胞上进行测定。MUC1*靶向CAR T细胞与靶细胞的比例为1:1。从图中可以看出,MUC1*靶向CAR转导的T细胞对MUC1*癌细胞的杀伤作用比未转导的对照T细胞高得多。此外,杀伤作用对MUC1*阳性细胞具有特异性。注意,具有CD4细胞外结构域-跨膜-胞质尾区的MUC1*靶向CAR与CD8构建体等效。图39是与靶细胞共培养24小时后CAR T细胞扩增的FACS测量图,其中CAR T细胞与靶细胞的比例为5:1。用一组CAR转导原代人T细胞,包括人源化MN-E6-CD8-41BB-3z、MN-E6-CD4-41BB-3z和MN-E6-CD8-CD28-41BB-3z。将CAR T细胞与MUC1*阳性T47D乳腺癌细胞、MUC1*阳性Capan胰腺癌细胞和MUC1阴性细胞HCT-116结肠癌细胞和HEK-293人胚肾细胞共培养。从图中可以看出,在MUC1*阳性细胞存在下,CAR T群增加。图40显示MUC1*靶向CAR的蛋白印迹照片。从1到9是:1.MN-E6scFv-Fc-8-41BB-CD3z(人Fc作为与CD8TM的铰链区);2:MN-E6scFv-FcH-8-41BB-CD3z(人Fc无铰链作为与CD8TM的铰链区);3:MN-E6scFv-Fc-4-41BB-CD3z(人Fc作为与CD4TM的铰链区);4:MN-E6scFv-FcH-4-41BB-CD3z(人Fc作为与CD4TM的无铰链铰链区);5:MN-E6scFv-IgD-8-41BB-CD3z(来自人IgD的铰链区与CD8TM);6:MN-E6scFv-IgD-4-41BB-CD3z(来自人IgD的铰链区与CD4TM);7:MN-E6scFv-X4-8-41BB-CD3z(长柔性接头作为与CD8TM的铰链区);8:MN-E6scFv-X4-4-41BB-CD3z(长柔性接头作为与CD4TM的铰链区);9:MN-E6scFv-8-4-41BB-CD3z(来自CD8和CD4的铰链区与CD4TM)。
图41显示了与用MN-E6scFv-Fc-8-41BB-CD3z、MN-E6scFv-FcH-8-41BB-CD3z(无铰链)、MN-E6scFv-Fc-4-41BB-CD3z、MN-E6scFv-IgD-8-41BB-CD3z、MN-E6scFv-X4-8-41BB-CD3z和MN-E6scFv-X4-4-41BB-CD3z转导的人T细胞共培养的T47D乳腺癌细胞的FACS扫描图。将T细胞和癌细胞以1:1的比例共培养48小时。将T细胞计数标准化为所有未转导的T细胞的平均值,并且当与未转导的T细胞共培养时,将靶细胞标准化为每种特定细胞类型。该图显示当CAR T细胞与MUC1*阳性癌细胞共培养时,T细胞群扩增,并且靶向癌细胞群减少。
图42显示了与用MN-E6scFv-Fc-8-41BB-CD3z、MN-E6scFv-FcH-8-41BB-CD3z、MN-E6scFv-Fc-4-41BB-CD3z、MN-E6scFv-IgD-8-41BB-CD3z、MN-E6scFv-X4-8-41BB-CD3z和MN-E6scFv-X4-4-41BB-CD3z转导的人T细胞共培养的T47D乳腺癌细胞、Capan-2胰腺癌细胞、K562-MUC1*转染细胞和K562-wt细胞的FACS扫描图。将T细胞和癌细胞以1:1的比例共培养48小时。将T细胞计数标准化为所有未转导的T细胞的平均值,并且当与未转导的T细胞共培养时,将靶细胞标准化为每种特定细胞类型。该图显示当CAR T细胞与MUC1*阳性癌细胞共培养时,T细胞群扩增,并且靶向癌细胞群减少。
抗MUC1*靶向抗体的特异性
如这些实验所示,CAR的关键部分是将免疫细胞导向肿瘤细胞的抗体片段。正如我们将在以下部分中所示,MN-E6和MN-C2特异于在肿瘤细胞上表达的MUC1*形式。CAR的下一个最重要的部分是带有免疫系统共刺激结构域的胞质尾区。这些结构域的身份调节免疫应答的程度,但不影响特异性。如图所示,CAR的跨膜部分的身份是最不重要的。似乎只要跨膜部分具有一定的柔韧性并且足够长以允许抗体片段到达其在肿瘤细胞上的同源受体,那就足够了。这在图40-42中示出。包含MN-E6靶向抗体片段和细胞内共刺激结构域41BB和CD3-ζ但具有多种不同细胞外、跨膜和短胞质尾区的CAR,均起到特异性地杀死靶细胞同时刺激宿主T细胞扩增的作用。
证明抗体特异性的最准确方法是测试与癌组织标本相比的正常人组织标本上的抗体。显示MN-C2和MN-E6特异性结合MUC1或MUC1*阳性癌细胞。使用几种抗MUC1或MUC1*抗体测定几种乳腺肿瘤阵列。基本上,涉及来自1200多名不同乳腺癌患者的乳腺癌组织标本的连续切片的研究表明,乳腺癌组织中仍然存在非常少的全长MUC1。表达的绝大多数MUC1是MUC1*并且被MN-C2染色。该分析由Clarient DiagNOStics进行,并使用Allred方法对组织染色进行评分。例如,图43显示了用VU4H5(市售的结合串联重复的抗MUC1抗体)或结合MUC1*的MN-C2染色的乳腺癌组织阵列的连续切片。图43和44是用识别MUC1-FL(全长)的VU4H5或识别癌性MUC1*的MN-C2染色的乳腺癌组织阵列的照片。使用Allred评分法对组织染色进行评分,该评分结合强度评分和分布评分。组织阵列的照片下方是显示结果的彩色编码图。可以看出,用VU4H5染色的阵列非常浅,并且许多组织根本不染色,尽管已发表的报道如基于核酸的诊断所证明的MUC1在超过96%的全部乳腺癌中异常表达。相反,用MN-C2染色的阵列非常深(图中红色与黄色或白色)。另外,许多组织用抗全长MUC1根本没有染色,但是用MN-C2染色非常深(参见图中的绿框)。类似地,我们用人源化MN-E6 scFv-Fc染色正常或癌性乳腺组织。抗体片段是生物素化的,因此可以通过基于第二链霉亲和素的二抗进行可视化。从图45中可以看出,hMN-E6 scFv-Fc不染色正常乳腺组织,但染色癌性乳腺组织。此外,染色的强度和均匀性随着患者的肿瘤等级和/或转移等级而增加(图45-46)。类似地,hMN-E6 scFv-Fc不染色正常肺组织但染色肺癌组织(图47-51),并且随着肿瘤等级或转移等级的增加,染色的强度和分布增加。图52显示用5μg/mL的人源化MN-E6-scFv-Fc生物素化抗MUC1*抗体染色,然后用第二链霉亲和素蛋白HRP抗体染色的正常小肠和癌性小肠组织的照片。A)是正常的小肠组织。B)是来自患者的小肠癌,如图中所示。C、D是仅用二抗染色的相应连续切片的照片。图53显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的正常小肠组织的照片。A-D是正常的小肠组织。E-H是仅用二抗染色的相应连续切片的照片。图54显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的癌性小肠组织的照片。A-D是来自患者的癌性小肠组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。图55显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的癌性小肠组织的照片。A-D是来自患者的癌性小肠组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。图56显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的正常结肠组织的照片。A-D是正常结肠。E-H是仅用二抗染色的相应连续切片的照片。图57显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的结肠癌组织的照片。A-D是来自转移患者的结肠癌组织,如图所示。E-H是仅用二抗染色的相应连续切片的照片。图58显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的结肠癌组织的照片。A-D是来自2级患者的结肠癌组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。图59显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的结肠癌组织的照片。A-D是来自转移患者的结肠癌组织,如图所示。E-H是仅用二抗染色的相应连续切片的照片。图60显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的前列腺癌组织的照片。A-D是来自患者的前列腺癌组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。图61显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的前列腺癌组织的照片。A-D是来自患者的前列腺癌组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。图62显示用50μg/mL的人源化MN-E6-scFv-Fc抗MUC1*抗体染色,然后用第二山羊抗人HRP抗体染色的前列腺癌组织的照片。A-D是来自患者的前列腺癌组织,如图中所示。E-H是仅用二抗染色的相应连续切片的照片。
本发明的一个方面是用于治疗被诊断患有、怀疑患有或有发展MUC1阳性或MUC1*阳性癌症风险的患者的方法,其中从患者的癌症获得样本并测试与结合PSMGFR SEQ ID NOS:2、SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:620)或SVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:621)的抗体的反应性。然后用scFv、scFv-Fc或CAR T处理患者,所述scFv、scFv-Fc或CAR T包含与其癌症样本反应的来自抗体的抗体可变片段。本发明的另一方面是治疗被诊断患有、怀疑患有或有发展MUC1阳性或MUC1*阳性癌症风险的患者的方法,其中从患者的癌症中获得样本并测试与MN-E6-scFv、MN-C2-scFv、MN-C3-scFv或MN-C8-scFv的反应性;然后用包含与其癌症样本反应的抗体部分的scFv、scFv-Fc-mut或CAR T治疗患者。
我们发现MUC1可被一种以上的切割酶切割成MUC1*,并且切割位点影响其折叠并因此影响哪种单克隆抗体能够识别MUC1*形式。不同的癌细胞或癌组织表达不同的切割酶。我们在不同的癌细胞系上测试了各种切割酶抑制剂,并发现抑制一种癌细胞系中MUC1切割的抑制剂不抑制其在另一种癌细胞系中的切割。类似地,PCR实验显示切割酶在不同细胞或细胞系中以不同水平表达。例如,骨髓的造血干细胞表达的MUC1*被单克隆抗体MNC3识别,但不被MNE6或MNC2识别(图63)。DU145前列腺癌细胞和T47D乳腺癌细胞的生长受到MNC2和MNE6的Fab的抑制,但不受MNC3或MNC8的Fab的抑制,表明癌细胞系表达MNE6和MNC2识别但MNC3或MNC8不识别的MUC1*(图64)。PCR实验表明,骨髓CD34阳性细胞比T47D乳腺癌细胞多表达约2,500倍MMP2、约350倍ADAM28,而DU145前列腺癌细胞比T47D乳腺癌细胞多表达约2,000倍ADAM TS16、约400倍MMP14和约100倍MMP1(图65和图66)。相反,T47D乳腺癌细胞表达的MMP9比骨髓细胞多80倍,是DU145前列腺癌细胞的两倍。测试了各种切割酶抑制剂在不同种类癌细胞中抑制切割的能力。抑制MMP2、MMP9和ADAM17的TAPI-1,以及抑制MMP2、MMP9、MMP14的MMP2/9V抑制剂,抑制T47D乳腺癌细胞中MUC1的切割(图67A、67B),但没有一种测试的切割酶抑制剂在DU145前列腺癌细胞中具有作用(图68A、68B)。这些实验表明,这些乳腺癌细胞中的MUC1被MMP2、MMP9、MMP14或ADAM17或这些酶的组合切割。
BiTE
可以通过连接两个scFv来工程化二价(或双价)单链可变片段(di-scFv、bi-scFv)。这可以通过产生具有两个VH和两个VL区的单个肽链来完成,产生串联scFv。另一种可能性是产生具有接头肽的scFv,所述接头肽(约5个氨基酸)对于两个可变区而言太短而不能折叠,迫使scFv二聚化。这种类型称为双抗体。已显示双抗体的解离常数比相应的scFv低至多40倍,这意味着它们对其靶标具有高得多的亲和力。因此,双抗体药物的剂量可以比其他治疗性抗体低得多,并且能够在体内高度特异性地靶向肿瘤。更短的接头(一个或两个氨基酸)导致形成三聚体,即所谓的三抗体或三体。还生产了四体。与双抗体相比,它们对靶标具有更高的亲和力。
所有这些形式可以由对两种不同抗原具有特异性的可变片段组成,在这种情况下它们是双特异性抗体的类型。其中研究最多的是双特异性串联di-scFv,称为双特异性T细胞接合剂(BiTE抗体构建体)。BiTE是在约55千道尔顿的单个肽链上由两种不同抗体的scFv组成的融合蛋白。其中一种scFv可以例如通过CD3受体与T细胞结合,另一种通过肿瘤特异性分子(例如异常表达的MUC1*)与肿瘤细胞结合。
本发明的另一方面是治疗被诊断患有、怀疑患有或有发展MUC1阳性或MUC1*阳性癌症风险的患者的方法,其中向患者给予有效量的BiTE,其中BiTE的一种抗体可变片段结合T细胞表面抗原,BiTE的另一抗体可变片段结合PSMGFR SEQ ID NOS:2,SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:620)或SVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:621)。在一种情况下,结合MUC1*的BiTE的抗体可变片段包含huMN-E6、huMN-C2、huMN-C3或huMN-C8的部分。
在本发明的另一方面,MUC1*肽用于过继性T细胞方案,所述MUC1*肽包括PSMGFR SEQ ID NOS:2,所述MUC1*肽大部分或全部是SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:620)或SVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:621)。在这种情况下,患者的T细胞暴露于MUC1*肽,并且通过多轮成熟,T细胞发育MUC1*特异性受体。然后将适应的T细胞扩增并给予于被诊断患有、怀疑患有或有发展MUC1*阳性癌症风险的供体患者。
还制备了一系列CAR,其具有MNC2和人源化MNC2作为额外的细胞外的CAR的靶向头。将这些CAR的构建体插入质粒中,然后将其插入Lenti病毒载体中。然后用携带MNC2CAR和huMNC2 CAR的慢病毒载体转导人T细胞。产生小鼠序列或人源化的MNC2-scFv-CAR。产生包含MNC2-scFv和多种跨膜和细胞内共刺激结构域的CAR,包括表1中列出的构建体。在本发明的一个方面,CAR包含衍生自CD8-短细胞内片段-4-1BB-3ζ的huMNC2-scFv-短铰链区-跨膜结构域。在另一方面,跨膜结构域衍生自CD4跨膜序列。另一方面,细胞内共刺激结构域是CD28-3ζ。在另一方面,细胞内共刺激结构域是CD28-4-1BB-3ζ。
有多种方法可用于评估T细胞是否识别靶细胞和处于产生免疫应答的过程中。T细胞在识别目标或外来细胞时聚集。这可以用肉眼或低放大率容易地看出。当与靶癌细胞共培养时CAR T细胞聚集的出现是以下的一种量度:a)它们是否将细胞识别为靶细胞;b)它们是否被激活以攻击靶细胞,在这种情况下为癌细胞。图80A-80F显示用mCherry稳定转染的MUC1*阳性T47D乳腺癌细胞的照片,因此是红色的,其与不含CAR的人T细胞或与huMNC2-scFv-CAR44、huMNC2-scFv-CAR49、huMNC2-scFv-CAR50、huMNC2-scFv-CAR18或huMNC2-scFv-CAR19转导的人T细胞共培养。在这种情况下,CAR构建体携带GFP标志物,因此CAR转导T细胞是绿色的。可以看出,当T细胞不携带CAR时,没有T细胞诱导的癌细胞聚集。然而,当T细胞携带MUC1*靶向CAR时,存在MUC1*阳性癌细胞的显著聚集。
在T细胞识别并聚集靶细胞后,它们过表达穿孔素和颗粒酶B。这两种分子一起激活靶细胞中的细胞死亡途径。认为穿孔素在靶细胞中形成孔,T细胞于孔中注射颗粒酶B,然后颗粒酶B激活凋亡蛋白酶,导致靶细胞裂解。图81A-81D显示huMNC2-scFV-CAR44T细胞与靶MUC1*阳性前列腺癌细胞结合并注射颗粒酶B。
T细胞是否已识别靶细胞并被激活以杀死该细胞的另一个量度是细胞因子(尤其是干扰素γ(IFN-g))的上调。表2列出了ELISA实验的结果,该实验测量了与多种不同癌细胞共培养后多种MUC1*靶向CAR T细胞分泌的干扰素γ的量。为了建立MUC1*表达和CAR T活性之间的联系,我们进行了实验以确定CAR T杀伤的量是否与癌细胞表达的MUC1*的量成比例。T47D是高度MUC1*阳性乳腺癌细胞。这些细胞也表达一些全长MUC1。用不同量的另外的MUC1*转染T47D细胞,然后与CAR T细胞共培养。结果显示,在低效应物(CAR T)与靶标(癌细胞)比例如1:1时,特异性CAR T杀伤随着MUC1*表达的增加而增加,并且分泌的干扰素γ的量也随着MUC1*的增加而增加(图82B)。测量CAR T应答的另一种方法是通过荧光激活细胞分选(FACS)。图X7A显示了用另外的MUC1*转染的T47D癌细胞的FACS分析图。在1:1的E:T比率下,CAR T介导的癌细胞杀伤随着在癌细胞上表达的MUC1*的量增加而增加。这很重要,因为我们之前表明,随着癌细胞对化疗剂产生抗药性,它们会增加它们表达的MUC1*的量(Fessler et al 2009)。因此,抗MUC1*CAR T作为晚期癌症患者或对化疗剂获得抗性的癌症患者的治疗尤其有益。将几种MNC2-scFv-CAR转导到人T细胞中并通过FACS分析以确定它们杀死靶MUC1*阳性癌细胞的能力。图83A-83D显示了与MUC1*阳性癌细胞共培养24小时后huMNC2-CAR44T细胞的FACS分析结果。图83A是FACS数据的图,显示与未转导的T细胞(红色条)相比,被huMNC2-CAR44T细胞(蓝色条)杀死的T47D癌细胞的百分比。X轴显示T细胞与癌细胞的比率。图83B是FACS数据的图,显示与未转导的T细胞(红色条)相比,被huMNC2-CAR44T细胞(蓝色条)杀死的K562-MUC1*癌细胞的百分比。图83C显示FACS扫描,其中T47D乳腺癌细胞用染料CMTMR染色。Sytox blue是死细胞染色剂。死癌细胞是象限2和3中的细胞。图83D显示FACS扫描,其中K562-MUC1*癌细胞用染料CMTMR染色。Sytox blue是死细胞染色剂。死癌细胞是象限2和3中的细胞。
除了FACS分析,许多研究人员现在使用xCELLigence仪器来测量CAR T对癌细胞的杀伤。FACS不是追踪T细胞诱导的细胞杀伤的最佳方法,因为T细胞裂解靶细胞。通过FACS,难以测量死细胞,因为它们被排除为细胞碎片,因此必须推断细胞杀伤的量,并且通过各种方法确定缺失的细胞是T细胞还是癌细胞。
xCELLigence仪器使用电极阵列,癌细胞在其上铺板。粘附的癌细胞使电极绝缘,因此随着它们的生长导致阻抗增加。相反,T细胞不粘附并保持悬浮状态,因此不会增加可加大阻抗的电极的绝缘性。然而,如果T细胞或CAR T细胞杀死电极板上的癌细胞,则癌细胞在它们死亡时会上升并漂浮,这导致阻抗降低。xCELLigence仪器测量阻抗作为时间的函数,其与癌细胞杀伤相关。此外,电极板还具有观察窗。当CAR T细胞有效杀死吸附的靶癌细胞时,阻抗降低,但也可以看到在板表面上没有留下癌细胞。
图84A-84H显示了通过多种测定法测量的huMNC2-CAR44T细胞对MUC1*阳性DU145前列腺癌细胞的细胞毒性作用。图84A是与前列腺癌细胞共培养的未转导T细胞的荧光照片,其中颗粒酶B用红色荧光团染色。图X4B是DAPI和颗粒酶B的合并。图84C是与前列腺癌细胞共培养的huMNC2-CAR44T细胞的荧光照片,其中颗粒酶B用红色荧光团染色。图84D是DAPI和颗粒酶B的合并。图84E是用于与癌细胞一起温育的未转导T细胞的荧光标记颗粒酶B的FACS扫描。图84F是FACS扫描,显示对于与癌细胞一起温育的huMNC2-CAR44T细胞,荧光标记颗粒酶B的阳性增加。图84G是平均荧光强度的图。图84H是xCELLigence扫描,跟踪huMNC2-CAR44T细胞(蓝色迹线)对DU145癌细胞的实时杀伤,但未转导的T细胞(绿色)不杀伤。图85A-85H显示了通过多种测定法测量的huMNC2-CAR44T细胞对MUC1*阳性CAPAN-2胰腺癌细胞的细胞毒性作用。图85A是与胰腺癌细胞共培养的未转导T细胞的荧光照片,其中颗粒酶B用红色荧光团染色。图85B是DAPI和颗粒酶B的合并。图85C是与胰腺癌细胞共培养的huMNC2-CAR44T细胞的荧光照片,其中颗粒酶B用红色荧光团染色。图85D是DAPI和颗粒酶B的合并。图85E是与癌细胞一起温育的未转导T细胞的荧光标记颗粒酶B的FACS扫描。图85F是FACS扫描,显示对于与癌细胞一起温育的huMNC2-CAR44T细胞,荧光标记颗粒酶B的阳性增加。图85G是平均荧光强度的图。图85H是xCELLigence扫描,跟踪huMNC2-CAR44T细胞(蓝色迹线)对CAPAN-2癌细胞的实时杀伤,但未转导的T细胞(绿色)不杀伤。图86A-86C显示xCELLigence扫描,跟踪huMNC2-CAR44T细胞对MUC1*阳性癌细胞而非MUC1*阴性细胞的实时杀伤。图86A显示huMNC2-CAR44T细胞有效杀死已用MUC1*稳定转染的HCT结肠癌细胞。图86B显示huMNC2-CAR44T细胞对HCT-MUC1-41TR几乎没有影响,HCT-MUC1-41TR是已用MUC1全长稳定转染的MUC1阴性癌细胞。在该细胞系中,仅约10%的细胞具有切割成MUC1*的MUC1。图86C显示huMNC2-CAR44T细胞对HCT-116细胞没有影响,HCT-116细胞是MUC1阴性结肠癌细胞系。
这些数据证明CAR转导的T细胞(其中靶向头的抗体片段是MNC2)有效杀死MUC1*阳性癌细胞。这些数据特异性地显示huMNC2-scFV-CAR44转导人T细胞有效杀死MUC1*阳性癌细胞。因为我们和其他人已经证明CAR T功能的最重要方面是靶向抗体片段,因此用任何具有抗体片段MNC2-scFV或huMNC2-scFV的CAR转导的免疫细胞或T细胞将具有针对MUC1或MUC1*阳性肿瘤的相似功效。例如,将scFv连接到跨膜部分的铰链区可以是任何柔性接头。细胞内共刺激结构域可以是CD28-3ζ、CD28-4-1BB-3ζ或免疫细胞共刺激结构域的任何组合。
还进行了实验,探索了预激活CAR T细胞以更有效地杀死靶癌细胞的方法。我们首先使用呈提抗CD3和抗CD28抗体的珠子测试对CAR T细胞的预刺激。这种预刺激增加了细胞杀伤的量,但这种增加并不特异于CAR的靶标。相反,CD3-CD28刺激CAR T细胞非特异性杀死MUC1*阳性和阴性细胞。我们接下来尝试用表达CAR抗体部分靶标的珠子或癌细胞预刺激CAR T细胞。将合成的MUC1*细胞外结构域肽连接到1μm或4.5μm珠子上。将抗MUC1*CAR T细胞与肽呈提珠子一起温育12-24小时。图87A-87L显示与MUC1*肽呈提珠子温育24小时后的未转导T细胞或CAR T细胞。可以看出,仅CAR转导T细胞显示出激活诱导的聚集。通过离心将CAR T细胞与珠子分离,然后通过FACS分析以测量T细胞激活标志物CD25、CD69和颗粒酶B的表达。如图88A-88D所示,当且仅当T细胞已用胞外结构域包含抗MUC1*抗体片段CAR转导时,T细胞激活标志物在与MUC1*呈提珠子温育后增加。与用CD3-CD28珠子预激活形成鲜明对比,用MUC1*肽珠子刺激仅增加特异性杀伤。MUC1*阴性细胞的杀伤没有增加。图89A-89C显示xCELLigence扫描,其显示珠子刺激抗MUC1*CAR T细胞对人卵巢癌细胞、三阴性乳腺癌细胞和用MUC1*稳定转染的MUC1阴性结肠癌细胞系的增强的杀伤。MUC1*肽珠子刺激CAR T细胞的增强的杀伤能力使CAR T细胞能够在更长的时间段内以更低的T细胞与癌细胞比率有效地杀死靶癌细胞。在本发明的一个方面,通过与呈提衍生自MUC1*细胞外结构域的肽的珠子或表面一起温育来预刺激CAR T细胞,然后给予诊断患有或有发展MUC1*阳性癌症风险的患者。
我们还通过将它们与呈提靶抗原的癌细胞一起温育来测试预激活CAR T细胞。我们将huMNC2-CAR44T细胞与HCT-MUC1*细胞温育12-24小时。该预刺激进行一次、两次、三次或四次。靶细胞预刺激也极大地增强了CAR T细胞的特异性杀伤。如图90A-90D所示,癌细胞刺激CAR T细胞的特异性细胞杀伤即使在低CAR T与癌细胞比率和更长的时间段内也增加了它们的杀伤潜力。图90A-90D显示癌细胞刺激huMNC2-scFv-CAR44转导人T细胞有效杀死T47D乳腺癌细胞、BT-20三阴性乳腺癌细胞、SKOV-3卵巢癌细胞和HCT-MUC1*癌细胞。在本发明的一个方面,通过与MUC1*表达细胞(可以是癌细胞)一起温育来预刺激CAR T细胞,然后给予诊断患有或有发展MUC1*阳性癌症风险的患者。在一个优选的实施例中,MUC1*刺激细胞在与CAR T细胞共培养之前UV或化学灭活。
测试了经过珠子刺激(方案1)或癌细胞刺激(方案2)的huMNC2-scFv-CAR44转导人T细胞抑制动物肿瘤生长的能力。将已经用荧光素酶稳定转染的人癌细胞注射到11至15周龄的雌性NOSD/SCID/GAMMA(NSG)小鼠中。在一个实验中,将500,000个HCT-MUC1*癌细胞皮下注射到后胁腹中。通过向动物注射荧光素然后使用IVIS仪器对荧光癌细胞成像来验证肿瘤植入。植入后第5天拍摄的IVIS图像显示存在肿瘤细胞。在第6天和第12天,向动物施用10M huMNC2-scFv-CAR44T细胞。通过肿瘤内注射施用5M的CAR T细胞,通过尾静脉注射施用另外的5M。对照组通过相同的给药途径注射相同数量的未转导T细胞或相同体积的PBS。在第7、11、13和21天进行IVIS肿瘤负荷测量。如图91A-91Y所示,两组对照小鼠具有连续生长的肿瘤,而用珠子刺激huMNC2-scFv-CAR44T细胞处理的小鼠在第21天没有可检测的癌细胞。在第21天,用癌细胞刺激huMNC2-scFv-CAR44T细胞处理的五(5)只小鼠中的三(3)只没有可检测的癌细胞。在第21天,其他两(2)只小鼠的癌细胞数量几乎无法检测到。
还测试了经过珠子刺激(方案1)或癌细胞刺激(方案2)的huMNC2-scFv-CAR44转导人T细胞抑制动物肿瘤生长的能力。将已经用荧光素酶稳定转染的人癌细胞注射到11至15周龄的雌性NOSD/SCID/GAMMA(NSG)小鼠中。在另一个实验中,将500,000个BT-20MUC1*阳性三阴性乳腺癌细胞皮下注射到后胁腹中。通过向动物注射荧光素然后使用IVIS仪器对荧光癌细胞成像来验证肿瘤植入。植入后第6天拍摄的IVIS图像显示存在肿瘤细胞。在第6天,在IVIS成像后,向动物施用10M huMNC2-scFv-CAR44T细胞。通过肿瘤内注射施用5M的CAR T细胞,通过尾静脉注射施用另外的5M。对照组通过相同给药途径注射相同数量的未转导T细胞。在第6天、第8天和第12天进行IVIS肿瘤负荷测量。如图92A-92J所示,与对照组相比,用huMNC2-CAR44T细胞处理的两组小鼠均显示肿瘤负荷降低。
还测试了受珠子刺激的huMNC2-scFv-CAR44转导人T细胞(方案1)在动物中抑制卵巢癌生长的能力。将已经用荧光素酶稳定转染的人SKOV-3MUC1*阳性卵巢癌细胞注射到11至15周龄的雌性NOSD/SCID/GAMMA(NSG)小鼠中。在一个实验中,将500,000个SKOV-3癌细胞注射到腹膜腔中以模拟人类的转移性卵巢癌。通过向动物注射荧光素然后使用IVIS仪器对荧光癌细胞成像来验证肿瘤植入。植入后第3天拍摄的IVIS图像显示存在肿瘤细胞。在肿瘤植入后第4天和第11天,将10M huMNC2-scFv-CAR44T细胞腹腔内施用于动物。在第4天,腹腔注射CAR T细胞。在第11天,将一半的CAR T细胞注射到腹膜内空间中,另一半注射到尾静脉中。对照组通过相同的给药途径注射相同数量的未转导T细胞或相同体积的PBS。在第7天、第10天和第15天进行随后的IVIS肿瘤负荷测量。如图93A-93L所示,对照小鼠具有以比huMNC2-CAR44T细胞处理的小鼠快得多的速率生长的肿瘤。图93M显示了将光子/秒与颜色相关联的IVIS彩条。
本发明的一个方面是用于治疗被诊断患有、怀疑患有或有发展MUC1阳性或MUC1*阳性癌症风险的患者的方法,其中给予患者有效量的已经用MUC1*靶向CAR转导的免疫细胞,其中CAR选自由以下组成的组:MN-E6-CD8-3z(SEQ ID NOS:294-295)、MN-E6-CD4-3z(SEQ ID NOS:746-747);MN-E6-CD8-CD28-3z(SEQ ID NOS:297-298)、MN-E6-CD4-CD28-3z(SEQ ID NOS:748-749)、MN-E6-CD8-41BB-3z(SEQ ID NOS:300-301)、MN-E6-CD4-41BB-3z(SEQ ID NOS:750-751)、MN-E6-CD8-CD28-41BB-3z(SEQ ID NOS:303-304)、MN-E6-CD4-CD28-41BB-3z(SEQ ID NOS:754-755)、MN-E6scFv-Fc-8-41BB-CD3z(SEQ ID NOS:310-311)、MN-E6scFv-IgD-Fc-8-41BB-CD3z(SEQ ID NOS:770-771)、MN-E6scFv-FcH-8-41BB-CD3z(SEQ ID NOS:315-316)、MN-E6scFv-IgD-FcH-8-41BB-CD3z(SEQ ID NOS:772-773)、MN-E6scFv-Fc-4-41BB-CD3z(SEQ ID NOS:318-319)、MN-E6scFv-FcH-4-41BB-CD3z(SEQ ID NOS:321-322);MN-E6scFv-IgD-8-41BB-CD3z(SEQ ID NOS:323-324)、MN-E6scFv-IgD-4-41BB-CD3z(SEQ ID NOS:327-328)、MN-E6scFv-X4-8-41BB-CD3z(SEQ ID NOS:330-331)、MN-E6scFv-X4-4-41BB-CD3z(SEQ ID NOS:333-334)、MN-E6scFv-8-4-41BB-CD3z(SEQ ID NOS:336-337);或其中的MN-E6被MN-C2、MN-C3或MN-C8取代的任何上述CAR,MN-C2-CD8-3z(SEQ ID NOS:606-607)、MN-C2-CD4-3z(SEQ ID NOS:758-759)、MN-C2-CD8-CD28-3z(SEQ ID NOS:608-609)、MN-C2-CD4-CD28-3z(SEQ ID NOS:760-761)、MN-C2-CD8-41BB-3z(SEQ ID NOS:610-611和SEQ ID NOS:718-719);MN-C2-CD4-41BB-3z(SEQ ID NOS:762-763)、MN-C2-CD8-CD28-41BB-3z(SEQ ID NOS:306-307)、MN-C2-CD4-CD28-41BB-3z(SEQ ID NOS:766-767)、MN-C2-Fc-8-41BB-CD3z(SEQ ID NOS:732-733)、MN-C2-IgD-Fc-8-41BB-CD3z(SEQ ID NOS:734-735)、MN-C2-FcH-8-41BB-CD3z(SEQ ID NOS:736-737)、MN-C2-IgD-FcH-8-41BB-CD3z(SEQ ID NOS:738-739)、MN-C2-IgD-8-41BB-CD3z(SEQ ID NOS:740-741)、MN-C2-X4-8-41BB-CD3z(SEQ ID NOS:742-743)。本发明的另一方面是治疗被诊断患有、怀疑患有癌症或有患癌症风险的患者的方法,其中向患者给予有效量的免疫细胞,所述免疫细胞已经用上述CAR之一转导,其中MN-E6被包含对癌抗原特异的抗体可变结构域片段的肽替代。在任何上述方法中,免疫细胞可以是T细胞,并且可以进一步从待治疗的患者中分离。
其他MUC1切割位点
已知除了癌细胞之外,MUC1在一些健康细胞上被切割成生长因子受体形式MUC1*。例如,MUC1在健康的干细胞和祖细胞上被切割成MUC1*。大部分骨髓细胞是MUC1*阳性。肠的部分是MUC1*阳性。
发明人已经发现MUC1可以在彼此相对接近的不同位置处被切割,但是切割的位置改变了细胞外结构域的剩余部分的折叠。结果,可以鉴定结合在第一位置切割的MUC1*但不结合在第二位置切割的MUC1*的单克隆抗体。该发现在2013年8月14日提交的WO2014/028668中公开,其内容通过引用整体并入本文。我们鉴定了一组抗MUC1*单克隆抗体,它们与癌细胞上出现的MUC1*结合,但不与出现在干细胞和祖细胞上的MUC1*结合。相反,我们鉴定了第二组单克隆抗体,它们与干细胞和祖细胞结合但不与癌细胞结合。用于鉴定干细胞特异性抗体的一种方法如下:将来自单克隆杂交瘤的上清液分别吸附到2个多孔板上。将作为非粘附细胞的干细胞放入一个平板中,将粘附的癌细胞放入相同的平板中。温育期后,将板冲洗并倒置。如果非粘附干细胞粘附在平板上,则该特定孔中的单克隆抗体识别干细胞并且不会识别癌细胞。未捕获干细胞的抗体或捕获癌细胞的抗体被鉴定为癌症特异性抗体。FACS分析证实该方法有效。
抗体MN-E6和MN-C2是癌症特异性抗体的实例。抗体MN-C3和MN-C8是干特异性抗体的实例。尽管两组抗体都能够与具有PSMGFR序列的肽结合,但FACS分析显示抗MUC1*多克隆抗体和MN-C3与MUC1*阳性骨髓细胞结合,但MN-E6不结合。通过用PSMGFR肽免疫兔子产生MUC1*多克隆抗体。类似地,MN-C3结合肠隐窝的干细胞,但MN-E6不结合。相反,MN-E6抗体结合癌组织,而干特异性MN-C3不结合。竞争ELISA实验表明,PSMGFR肽的C末端10个氨基酸是MN-E6和MN-C2结合所必需的,但不是MN-C3和MN-C8所必需的。因此,鉴定癌症特异性抗体的另一种方法是用具有PSMGFR肽减去10个N末端氨基酸的序列的肽进行免疫,或者使用该肽筛选将会是癌症特异性的抗体或抗体片段。与具有PSMGFR肽减去N末端10个氨基酸的序列的肽结合,但不与具有PSMGFR肽减去C末端10个氨基酸的序列的肽结合的抗体是用于治疗或预防癌症的癌症特异性抗体。
MUC1的细胞外结构域也在干细胞和一些祖细胞上切割,其中通过二聚体形式的配体NME1或NME7激活的切割MUC1促进生长和多能性并抑制分化。切割后剩余的MUC1的跨膜部分称为MUC1*,细胞外结构域基本上包括MUC1生长因子受体(PSMGFR)序列的一级序列。然而,切割的确切位点可以根据细胞类型、组织类型或特定人表达或过表达的切割酶而变化。除了我们先前鉴定的包含大部分或全部PSMGFR SEQ ID NOS:2的MUC1*的跨膜部分的切割位点之外,其他切割位点导致延伸的MUC1*,包括以下的大部分或全部:SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:620)、或SVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NOS:621)。MUC1切割的位点影响剩余的细胞外结构域如何折叠。我们已经鉴定出与癌细胞上的切割MUC1*结合但不与存在于健康的干细胞和祖细胞上的切割MUC1*结合的单克隆抗体。
抗MUC1*抗体或抗体样分子如果竞争性地抑制NME1、NME6、NME8或NME7或NME7-AB与MUC1*的结合,则可能是最有效的,例如与PSMGFR序列结合的抗体,特别是如果如果缺失10个C末端氨基酸,则所述抗体不能结合PSMGFR肽,携带负载的抗体或抗体样分子不需要竞争性地抑制作为抗癌剂起效的MUC1*配体的结合。例如,与毒素缀合的抗体或抗体样分子可有效杀死靶癌细胞而不必抑制激活配体的结合。例如,抗体或抗体样分子掺入CAR Ts或BiTE,这将患者的免疫系统募集到肿瘤中,即使抗体片段靶向MUC1*的一部分,使得即使抗体片段结合不竞争性地抑制NME1、NME6、NME8、NME7-AB或NME7的结合,也可以作为抗癌剂起效。在优选的实施例中,抗体片段掺入CAR、适应性T细胞受体或BiTE,竞争性地抑制NME1、NME6、NME8、NME7-AB或NME7与MUC1*的结合。
能够结合剩余跨膜部分的细胞外结构域的抗体阻断MUC1*细胞外结构域和激活配体之间的相互作用,并且以这种方式可以用作治疗剂,例如用于治疗癌症。抗MUC1*抗体也可用于体外和体内干细胞的生长、递送、鉴定或分离。
使用靶向MUC1*细胞外结构域的抗体、抗体片段和CAR的一般策略
单克隆抗体MN-C3和MN-C8对血细胞的结合亲和力高于实体肿瘤癌细胞。含有衍生自MN-C3和MN-C8可变区的序列的人源化抗体和抗体片段可以用作独立疗法或掺入到CAR T、BiTE、ADC中用于治疗血癌。
或者,含有衍生自MN-C3和MN-C8可变区的序列的人源化抗体和抗体片段可用于将干细胞递送至特定位置,例如用于原位人治疗剂。在一种情况下,向包被有人源化MN-C3或MN-C8衍生抗体或抗体片段的基质加载干细胞,然后插入患者体内。在另一种情况下,将包被有人源化MN-C3或MN-C8衍生抗体或抗体片段的基质插入患者体内,以将患者自身的干细胞募集到特定区域进行治疗。其中与人干细胞结合的抗体将具有治疗用途的人类疗法包括脊髓修复。用人源化MN-C3或MN-C8衍生抗体或抗体片段包被的底物也用于鉴定或分离人抗体。人源化MN-C3或MN-C8衍生抗体也可用于刺激干细胞的生长。
CAR和切割酶
CAR T疗法的许多应用受到T细胞膜和抗体片段之间细胞外结构域的长度或柔性的限制,所述抗体片段将T细胞引导至所需位置。例如,实体瘤癌细胞的表面充满了无数的细胞表面蛋白和生长因子受体。许多这些细胞表面蛋白具有庞大的细胞外结构域,限制免疫细胞(例如T细胞或CAR T细胞)接近肿瘤细胞表面。在一个实例中,MUC1和切割生长因子受体形式MUC1*在超过75%的实体瘤癌症和一些血癌上过表达。MUC1全长的细胞外结构域含有约1,500至2,500个氨基酸,而MUC1*的细胞外结构域仅含有约45至65个氨基酸。MUC1全长的长度的可变性是由于表达的串联重复单元的数量的可变性。当MUC1被不同的切割酶切割时,MUC1*长度的可变性是由于不同的切割位点。尽管最需要使T细胞接近癌细胞表面,但是邻近的蛋白(包括全长MUC1)可以在空间上阻碍接近,所述蛋白具有大而庞大的细胞外结构域。对于早期癌症尤其如此。组织研究表明,早期癌症具有比晚期癌症更多的全长MUC1,晚期癌症可以缺乏任何全长MUC1。在某些情况下,该问题可严重限制癌症免疫疗法的功效,包括CAR T、适应性T细胞疗法、BiTE和其他T细胞接合剂。
该问题的一个解决方案是在靶肿瘤细胞的区域中表达或激活切割酶,以切割限制T细胞接近肿瘤的大蛋白。图94A-94B显示了CAR T细胞的动画,其在肿瘤附近时表达切割酶,切割酶然后将MUC1切割成MUC1*。
在本发明的一个方面,切割酶和CAR被转导到相同的T细胞中。在本发明的另一方面,切割酶位于诱导型启动子上,使得当CAR与靶癌细胞接合时切割酶表达被激活。在一些情况下,切割酶的表达受诱导型启动子的控制。在本发明的一个方面,当免疫细胞被激活时,例如当其识别或接合其靶标时,诱导切割酶的表达。在一个实例中,用切割酶转染或转导T细胞,当T细胞识别靶癌细胞时,所述切割酶的表达被诱导。一种方法是在NFAT蛋白表达或易位至细胞核时或之后不久诱导切割酶的表达。例如,将衍生自NFAT启动子区的序列置于切割酶基因的上游。这样,当与NFAT蛋白的启动子结合的转录因子以足够的浓度存在以结合并诱导NFAT蛋白的转录时,它们也将会结合工程化在切割酶的转录序列前面的相同启动子。NFAT蛋白可以是NFAT1(也称为NFATc2),NFAT2(也称为NFATc或NFATc1),NFAT3(也称为NFATc4),NFAT4(也称为NFATc3)或NFAT5。在本发明的一个方面,NFAT是NFATc1、NFATc3或NFATc2。在本发明的一个方面,NFAT是NFAT2(也称为NFATc1)。SEQ ID NOS:646显示NFAT2的上游转录调节区的核酸序列。NFAT基因的启动子序列可包括SEQ ID NOS:781-783或SEQ ID NOS:815的核酸序列作为实例,但可以看出可以通过制备启动子的片段、延伸或突变并测试启动子相对于切割酶表达的强度,来获得表达切割酶的最佳序列或最小序列。在本发明的一个方面,工程化编码切割酶MMP9(SEQ ID NOS:647)或MMP9的催化亚单位(SEQ ID NOS:648)的基因上游的NFAT2转录调节区。在本发明的一个方面,NFAT是NFATc3,NFATc3的启动子序列包括来自SEQ ID NOS:816的核酸序列。在本发明的一个方面,工程化编码切割酶MMP9(SEQ ID NOS:647)或MMP9的催化亚单位(SEQ ID NOS:648)的基因上游的NFATc3转录调节区。在本发明的另一方面,NFAT是NFATc2。SEQ ID NOS:817-818显示了NFATc2的上游转录调节区的核酸序列。在本发明的一个方面,工程化编码切割酶MMP9(SEQ ID NOS:647)或MMP9的催化亚单位(SEQ ID NOS:648)的基因上游的NFATc2转录调节区。
当T细胞或CAR T细胞被激活时诱导切割酶表达的另一种方法是在诱导型启动子上具有切割酶的基因,其中NFAT蛋白本身结合并诱导切割酶的转录。在这种情况下,NFAT应答元件(NFAT RE)可以位于切割酶或切割酶片段的基因的上游。NFAT可以单独结合切割酶上游的其应答元件,或作为复合物的一部分结合其应答元件。NFAT蛋白可以是NFATc1、NFATc2、NFATc3、NFATc4或NFAT5。在优选的实施例中,NFAT蛋白是NFAT2(又名NFATc1,又名NFATc)。将切割酶或其片段的基因克隆到NFAT应答元件(SEQ ID NOS:649)(其可以是应答元件重复(SEQ ID NOS:650)和CMV最小启动子(mCMV)(SEQ ID NOS:651))的下游,通过NFAT蛋白诱导切割酶的表达。NFAT应答元件可包括NFAT共有序列的核酸序列(SEQ ID NOS:804)。NFAT应答元件可以包括SEQ ID NOS:805-814的核酸序列作为实例,但是可以看出,可以通过制备应答元件核酸的片段、延伸或突变并测试应答元件相对于切割酶表达的强度,来获得表达切割酶的最佳序列或最小序列。Foxp3的增强子区域还包含2079至2098的120bp(SEQ ID NOS:821)内的NFAT应答元件。NFAT应答元件可包括(5'-cattttttccat-3')(SEQ ID NOS:819)或(5'-tttttcca-3')(SEQ ID NOS:820)的核酸NFAT共有序列,其中NFATc1特异性结合所述共有序列(Xu et al.,Closely related T-memory stem cells correlate with in vivo expansion of CAR.CD19-T cells and are preserved by IL-7and IL-15,Blood 2014 123:3750-3759),或其重复。NFAT应答元件也可以通过核酸间隔序列分开。可以存在并且可以进一步发现其他NFAT应答元件,并且当涉及确定NFAT应答元件时,本领域技术人员在至少如SEQ ID NOS:804-814所述的应答元件的指导下(尽管仅仅作为一个例子),可以通过进行分子生物学测定来获得它。在本发明的一个方面,位于NFAT应答元件和CMV最小启动子下游的切割酶是MMP9(SEQ ID NOS:652)。在本发明的另一个方面,切割酶是MMP9的催化亚单位(SEQ ID NOS:653)。
由于NFATs 1-4受钙调神经磷酸酶途径调节,因此可以通过用阻止钙调神经磷酸酶活性并抑制NFAT易位至核的免疫抑制剂如FK506、环孢菌素、环孢菌素A或他克莫司治疗,从而阻止患者可能出现的毒性。用在诱导型启动子上的切割酶转导或转染的T细胞也可以用识别癌细胞上的蛋白或分子的CAR转染或转导。在具体实例中,切割酶是能够切割MUC1全长的切割酶,并且CAR具有将其引导至癌细胞表面上的MUC1*的抗体片段。
为了确定哪种切割酶切割癌细胞上的MUC1,我们测试了一系列MMP和ADAM酶抑制剂。这些实验指出MMP9是癌细胞中的重要切割酶。为了证实MMP9切割癌细胞上的MUC1,我们用具有41个串联重复结构域的全长MUC1模拟物转染HCT-116MUC1阴性结肠癌细胞:HCT-MUC1-41TR。通过单细胞克隆,我们能够建立这种细胞系,其中MUC1仅最低限度地切割成MUC1*。图95A-95D显示,蛋白印迹和FACS分析显示HCT-MUC1-41TR对于全长MUC1为95%阳性,对于切割形式MUC1*仅为5-10%阳性。将HCT-MUC1-41TR细胞与不同浓度的MMP9一起温育,然后通过免疫荧光测定以测量MNC2单克隆抗体与所得细胞的结合。如图96A-96E所示,随着添加到细胞中的MMP9浓度的增加,MNC2的结合增加。这些实验表明,MMP9将MUC1切割成MNC2识别的形式。我们进行的人癌组织阵列研究(图69A-69D、图70A-70F、图71A-71F、图72A-72F、图73A-73F)显示MNC2识别存在于癌组织上但不存在于健康细胞或组织上的切割MUC1的形式(图74A-74I)。重要的是,MNC2不识别在骨髓的健康造血干细胞上表达的切割MUC1的形式。
在本发明的一个方面,免疫细胞用将免疫细胞靶向于肿瘤的CAR,和切割酶转导。CAR和切割酶可以在相同的质粒上或在两种不同的质粒上编码。在一个方面,切割酶在诱导型启动子上。另一方面,切割酶的表达由免疫细胞被激活时表达的蛋白诱导。在一种情况下,切割酶的表达由NFAT蛋白诱导。另一方面,切割酶的表达由NFATc1诱导。另一方面,当一种NFAT蛋白结合NFAT应答元件时,诱导切割酶的表达,所述NFAT应答元件插入切割酶或其催化活性片段的基因的上游。在一个方面,切割酶是MMP9或具有催化活性的MMP9的片段。
在本发明的一个方面,切割酶是MMP9(SEQ ID NOS:643)。一些切割酶天然地表达为需要被激活的酶原。这可以通过生化方法,通过表达激活切割酶的辅酶或通过工程化活性形式的酶来实现。本发明预期通过共表达切割酶及其激活剂来克服该问题。在本发明的一个方面,切割酶是MMP9,共激活剂是MMP3。在本发明的另一方面,切割酶以已经激活的形式表达,例如通过表达仍具有催化功能的切割酶片段。在一种情况下,切割酶是具有催化活性的MMP9片段。MMP9催化片段的一个实例如SEQ ID NOS:645所示。
必须被MMP3激活的MMP9在大部分实体瘤中过表达。此外,已知MNC2抗MUC1*单克隆抗体识别被MMP9切割后的MUC1。如图69-73所示的乳腺癌、卵巢癌、胰腺癌和肺癌阵列用MNC2-scFv探测,进一步表明这些癌症中的MUC1被MMP9切割。为了观察MMP9对肿瘤的切割是否会增加接近肿瘤的T细胞,我们使用表达全长MUC1的细胞系即HCT-MUC1-41TR的细胞系进行了一系列实验,HCT-MUC1-41TR是一种高表达全长MUC1和MUC1*的乳腺癌细胞系,是我们用MUC1*45转染的MUC1阴性细胞系。我们用MMP9和MMP3转染细胞,其激活MMP9。我们取出含有激活的MMP9的那些细胞的上清液,并将其添加各种细胞中,然后将其与用抗MUC1*CAR:huMNC2-CAR44转导的T细胞共培养。与未用MUC1切割酶温育的对照细胞相比,结果是靶MUC1/MUC1*阳性癌细胞的CAR T细胞杀伤大大增加。
APMA是一种激活MMP的生物化学物质。我们使用APMA以及我们用MMP9或ADAM17转染的细胞的条件培养基来观察这些切割酶是否会切割仅表达全长MUC1的HCT-MUC1-41TR细胞系上的MUC1。作为对照,我们还测试了HCT-MUC1*细胞上的酶。MUC1和MUC1*表达细胞用红色染料CMTMR染色。将用抗MUC1*CAR(CAR44或CAR50)转导的人T细胞与癌细胞共培养。未转导的T细胞用作对照。如图75B、75C和75D所示,抗MUC1*CAR T细胞有效识别并聚集HCT-MUC1*癌细胞,这是T细胞激活和杀伤的信号。然而,在含有HCT-MUC1-41TR(表达全长MUC1的细胞)的孔中没有看到CAR T细胞诱导聚集(图75F、75G和75H)。然而,与激活MMP9一起温育的细胞显示出CAR T细胞诱导聚集的显著增加(图75J、75K和751),表明MMP9将全长MUC1切割成MUC1*形式,MUC1*形式被MNC2单克隆抗体识别,更具体地被huMNC2-scFv识别。ADAM17没有明显效果。ADAM17要么不切割MUC1,要么在MNC2无法识别的位置切割它(这更可能发生)。
我们进行了相同的实验,这次使用的是用抗MUC1*CAR T细胞难以杀死的T47D乳腺癌细胞,可能是因为它们表达高水平的全长MUC1以及MUC1*。如图76B,76C和76D所示,抗MUC1*CAR44和CAR50对T47D癌细胞几乎没有影响。仅在图76D中,其是CAR44即在T细胞中最高水平表达的CAR,我们看到少量CAR T细胞诱导的聚集。然而,激活的MMP2(图76J、76K、76L)或激活的MMP9(图76R、76S、76T)的存在显示CAR T细胞识别、聚集和杀伤的显著增加,表明全长MUC1的切割增加T细胞对癌细胞的接近。
在另一个实例中,将T47D MUC1阳性肿瘤细胞与100ng/mL或500ng/mL MMP9的重组催化结构域(Enzo Life Sciences,Inc.,Farmingdale,NY)温育。蛋白印迹分析显示MUC1/MUC1*阳性癌细胞经历MUC1向MUC1*的广泛切割。在另一个实例中,将T47D乳腺癌细胞与人重组MMP9催化结构域蛋白预温育,然后与抗MUC1*CAR44T细胞共培养。在xCelligence仪器上实时监测CAR44T细胞对T47D细胞的特异性杀伤,该仪器测量作为时间的函数的阻抗。该分析使用电极阵列,癌细胞在其上铺板。粘附癌细胞使电极绝缘并且随着它们的生长导致阻抗增加。相反,T细胞不粘附并保持悬浮状态,因此不会增加或减少阻抗。然而,如果T细胞或CAR T细胞杀死电极板上的癌细胞,则癌细胞在它们死亡时会上升并漂浮,这导致阻抗降低。MMP9催化结构域的添加显著增加了T47D癌细胞的杀伤。图78显示T47D乳腺癌细胞的xCelligence图,其与未转导T细胞(作为对照)或huMNC2-CAR44T细胞共培养45小时段。在癌细胞生长18小时后,将催化亚单位MMP9添加一些细胞中。在25小时时,添加T细胞。可以看出,当T47D细胞与切割酶MMP9预温育时,huMNC2-CAR44T细胞杀伤极大改进。在xCelligence系统中,将粘附的靶癌细胞平铺到电极阵列板上。粘附细胞使电极绝缘并增加阻抗。粘附癌细胞的数量与阻抗成正比。T细胞不粘附并且对阻抗没有贡献。因此,增加的阻抗反映了癌细胞的生长,并且降低的阻抗反映了癌细胞的杀伤。前列腺癌细胞系DU145表达MUC1和MUC1*,但表达水平远低于T47D细胞。在存在或不存在切割酶的情况下,DU145细胞被抗MUC1*CAR T细胞有效杀伤。
图79显示DU145前列腺癌细胞的xCelligence图,所述DU145前列腺癌细胞与未转导T细胞(作为对照)或huMNC2-CAR44T细胞共培养45小时段。在癌细胞生长18小时后,将催化亚单位MMP9添加一些细胞中。在25小时时,添加T细胞。可以看出,低密度MUC1/MUC1*阳性癌细胞的huMNC2-CAR44T细胞杀伤不受与切割酶MMP9预温育的影响。DU145癌细胞表达显著较低量的MUC1(包括全长形式以及MUC1*)。全长MUC1的较低密度不会在空间上阻碍T细胞接近膜近端MUC1*。DU145细胞代表早期癌症,早期癌症表达全长和切割的MUC1,但以较低水平表达使得T细胞接近不受空间位阻。T47D细胞代表中期癌症,中期癌症表达高水平的MUC1和MUC1*,其中MUC1全长密度空间阻碍T细胞接近肿瘤。HCT-MUC1*细胞是已经用MUC1*45稳定转染的MUC1阴性细胞系,并且它们代表晚期癌细胞。重要的是,由MMP9切割成MUC1*的MUC1被抗MUC1*抗体MNC2识别,抗MUC1*抗体MNC2是CAR的靶向头。癌细胞表面上的肿瘤抗原的免疫细胞接近可以通过庞大的细胞外结构域蛋白或其他阻碍元件(也称为肿瘤微环境)的存在而受到空间阻碍。上述用作可以扩展以提高靶向其他肿瘤抗原的CAR T疗法的功效的实例。在本发明的一个方面,用包含靶向肿瘤抗原的抗体片段的CAR和切割酶转染或转导免疫细胞。在本发明的另一个方面,用CAR和切割酶转染或转导免疫细胞,所述CAR包括靶向肿瘤抗原的抗体片段,所述切割酶将肿瘤抗原切割成CAR抗体片段识别的形式。在一个方面,用CAR和切割酶转染或转导免疫细胞,所述CAR包括靶向肿瘤抗原的抗体片段,所述切割酶将肿瘤抗原切割成CAR抗体片段识别的形式,其中CAR的抗体片段识别MUC1*细胞外结构域,切割酶将MUC1切割成MUC1*。在一个方面,用CAR和切割酶转染或转导免疫细胞(其可以是T细胞或NK细胞),所述CAR包含衍生自MNC2、MNE6、MNC3或MNC8的抗体片段,所述切割酶选自包括MMP1、MMP2、MMP3、MMP7、MMP8、MMP9、MMP11、MMP12、MMP13、MMP14、MMP16、ADAM9、ADAM10、ADAM17、ADAM19、ADAMTS16、ADAM28或其催化活性片段的组。
用于测试MMP9存在的便利方法是使用荧光测定法,例如使用OMNIMMP肽测定试剂盒。该试剂盒具有底物是MMP9的肽,其已经用掩蔽的荧光团衍生化。当将MMP9添加到含有肽的溶液中时,MMP9在暴露荧光团的位置切割肽,并且可以在读板器上读取荧光。以相对荧光单位(RFU)读取MMP-9活性,RFU是与由读板器组检测的光量相关的任意值,所述读板器组在328nm处激发包含样品的每个孔并测量393nm处的发射。RFU的增加表明Gly-Leu键的裂解、荧光团的暴露以及因此MMP-9的存在。OMNIMMP肽的序列是Mca-Pro-Leu-Gly-Leu-Dpa-Ala-Arg-NH2。AcOH[Mca=(7-甲氧基香豆素-4-基)乙酰基;Dpa=N-3-(2,4-二硝基苯基)-L-α,β-二氨基丙酰基]。图97显示MMP9的OMNIMMP荧光肽底物被MMP9催化结构域切割并发射荧光的图。将MMP9催化结构域以两种浓度添加到PBS(实线)或细胞培养基(虚线)中。该实验表明,OMNIMMP肽测定将测量细胞分泌的MMP9的活性,即使它们在细胞生长培养基中也是如此。
研究激活NFAT途径的方法是通过使用PMA和离子霉素来化学激活该途径(Lyakh et al.,Expression of NFAT-Family proteins in normal human T cells,MOLECULAR AND CELLULAR BIOLOGY,Vol.17,No.5,May 1997,p.2475–2484;Rao et al.,Transcription factors of the NFAT family-Regulation and function,Annu.Rev.Immunol.1997.15:707–47;Macian,NFAT proteins-Key regulators of T-cell development and function,Nature Reviews Immunology,Vol.5,pp 472-484June(2005))。已经证明PMA和离子霉素诱导NFAT蛋白的表达。以上引用的参考文献显示了NFAT激活的调节方案。离子霉素增加了激活钙调神经磷酸酶/钙调蛋白复合物的钙。钙调神经磷酸酶/钙调蛋白使NFAT去磷酸化,导致NFAT(尤其是NFATc1)易位至细胞核,在那里它与DNA结合以刺激靶基因的转录。NFATc1是T细胞激活后首先易位到细胞核的NFAT蛋白之一,在它离开细胞核之前它只是暂时存在于那里。因此,对我们用NFAT诱导型切割酶转染或转导的细胞的PMA加离子霉素激活是生理学相关的,并且模拟体内T细胞激活,从而开启本文所述的NFAT诱导型切割酶的表达。
HEK293T细胞系((人胚肾细胞),最初称为293tsA1609neo)是人胚胎肾293细胞的高度可转染的衍生物,并含有SV40T-抗原。该细胞系能够复制携带SV40复制区的载体。当用于产生逆转录病毒时,它具有高滴度。它已被广泛用于逆转录病毒生产、基因表达和蛋白生产。在将质粒插入慢病毒载体并转导入人T细胞之前,将HEK293T细胞用于一些早期实验中。
构建质粒,然后转染到HEK293T细胞中,其中MMP9催化结构域的基因插入3或4个NFAT应答元件的下游。通过添加10ng/mL的PMA和1μM或2μM的离子霉素激活NFAT途径。在蛋白印迹分析中测定来自细胞的裂解物、或来自细胞的条件培养基,以检测MMP9的存在,所述细胞用含有3或4个重复NFAT应答元件的质粒转染。如图98A-98E中,只有在MMP9上游含有NFAT应答元件并且其中NFAT途径被PMA/离子霉素激活的细胞可从裂解物和条件培养基中检测到MMP9。此外,表达或分泌的MMP9的量与NFAT途径激活剂的浓度成比例。接下来,我们测试了来自裂解物的MMP9以及分泌到条件培养基中的MMP9,看它是否具有活性并且是否能够切割MMP9底物。图99A-99B显示MMP9的荧光肽底物被HEK293T细胞的细胞裂解物或条件培养基切割的图,所述细胞用含有在4个重复的NFAT应答元件下游的MMP9基因的质粒转染。MMP9肽底物测定显示PMA/离子霉素激活NFAT途径导致MMP9表达和分泌,并且其活性如其切割肽底物的能力所证明。
我们还测试了MMP9基因前面的天然前导序列是否必需或者是否可以被其他可能增加其表达或从细胞分泌的前导序列取代。这些接下来的实验表明,天然MMP9前导序列可以被其他前导序列取代。图100A-100D显示在HEK293T细胞中表达的NFAT诱导型MMP9催化结构域,其中MMP9的天然前导序列已经被IgK前导序列取代,MMP9催化结构域在4个重复的NFAT应答元件的下游。图100A显示了在激活NFAT途径后检测细胞裂解物中MMP9表达的蛋白印迹的照片。图100B显示了在激活NFAT途径后检测条件培养基中MMP9表达的蛋白印迹的照片。图100C显示了在HEK293T细胞的条件培养基中由表达和分泌的MMP9催化结构域对MMP9荧光肽底物切割的图,其中MMP9的天然前导序列已被IgK前导序列取代,MMP9催化结构域在4个重复的NFAT应答元件的下游。图100D显示了在HEK293T细胞的条件培养基中由表达和分泌的MMP9催化结构域对MMP9荧光肽底物切割的图,其中MMP9的天然前导序列已被IgK前导序列取代,MMP9催化结构域在4个重复的NFAT应答元件的下游。图101A-101C显示MMP9可以用不同的前导序列表达,并且还显示各自的后续活性。图101A显示了检测细胞裂解物中MMP9蛋白的蛋白印迹,其中MMP9基因上游的前导序列是其天然序列或IgK序列。图101B显示了在条件培养基中检测MMP9的蛋白印迹,其中MMP9基因上游的前导序列是其天然序列或IgK序列。图101C显示了由表达的MMP9切割的MMP9肽底物的图。
为了设计具有由仅在T细胞激活后表达或易位至细胞核的蛋白诱导的切割酶表达的构建体,可以使酶基因位于应答元件的下游或该切割酶的启动子的下游。制备另一种质粒,其中MMP9催化结构域的基因插入NFATc1启动子的一部分的下游。如图102A-102B所示的实验比较了NFATc1启动子表达的MMP9或4个重复的NFAT应答元件表达的MMP9的表达水平。它们表明这两种方法都良好奏效。图102A-102B显示用产生NFAT诱导型MMP9的质粒转染的细胞的3个克隆(4,6和7),其中NFATc1启动子序列在MMP9基因(在这种情况下是包含其催化结构域的截短的MMP9)的上游。还显示用于比较的细胞是用产生NFAT诱导型MMP9的质粒转染的细胞,其中4个重复的NFAT应答元件序列在MMP9基因的上游。图102A显示了检测细胞裂解物中MMP9蛋白的蛋白印迹。图102B显示了在条件培养基中检测MMP9的蛋白印迹。图103A-103B显示澄清裂解物中的MMP9和条件培养基中的MMP9也是有活性的,因为它们在肽荧光测定中切割MMP9底物。
我们接下来测试了NFAT诱导型MMP9是否在人T细胞中起作用,以及它是否在T细胞激活后特异性地表达和分泌。为了测试这一点,将具有4个重复的NFAT应答元件的构建体掺入慢病毒载体中。用单独的NFAT诱导型MMP9、单独的CAR44、或CAR44和NFAT诱导型MMP9转导人T细胞。在一些情况下,通过将转导T细胞与涂有抗CD3和抗CD28的珠子一起温育来将其激活,已知所述抗CD3和抗CD28激活T细胞。在其他情况下,通过将转导T细胞与呈提合成MUC1*肽的珠子共培养或通过与MUC1*阳性癌细胞如HCT-MUC1*细胞共培养来激活。
图104A-104B显示了测量MMP9活性的OMNIMMP9荧光底物测定的结果。将来自单独的或与CAR44组合的NFAT诱导型MMP9转导的人T细胞的条件培养基添加到测定中,并测量MMP9底物切割作为时间的函数。图104A显示了在通过与HCT-MUC1*癌细胞共培养激活细胞后,用CAR44和NFAT诱导型MMP9转导人T细胞时的MMP9活性。未显示作为时间函数的增加的底物切割的迹线是来自未被激活的细胞的条件培养基。图104B显示当通过与已知激活T细胞的抗CD3和抗CD28包被的珠子共培养而激活细胞后,仅用NFAT诱导型MMP9转导人T细胞时的MMP9活性。未显示作为时间函数的增加的底物切割的迹线是来自未被激活的细胞的条件培养基。图105A-105E显示用单独的CAR44、单独的NFAT诱导型MMP9或用CAR44和NFAT诱导型MMP9转导的人T细胞的蛋白印迹的照片,其中所得T细胞未被激活、被PMA/离子霉素化学激活、通过与呈提合成MUC1*肽的珠子共培养或与MUC1*阳性癌细胞共培养而激活。用抗Flag标签(也称为DYK标签抗体)探测蛋白印迹。MMP9的催化结构域以约40kDa的表观分子量移动。图105A-105D显示了澄清的细胞裂解物的蛋白印迹的照片。图105A具有装载有以下裂解物的泳道1-7:泳道1:用CAR44转导但未激活的T细胞;泳道2:用CAR44转导,并用呈提合成MUC1*胞外结构域肽的珠子激活的T细胞;泳道3:用CAR44转导,并通过与HCT-MUC1*癌细胞共培养而激活的T细胞;泳道4:用CAR44和NFAT诱导型MMP9转导但未激活的T细胞;泳道5:用CAR44和NFAT诱导型MMP9转导,并用呈提合成MUC1*胞外结构域肽的珠子激活的T细胞;泳道6:用CAR44和NFAT诱导型MMP9转导,并通过与HCT-MUC1*癌细胞共培养而激活的T细胞;泳道7:也携带Flag DYK标签的无关蛋白。结果显示,当用PMA/离子霉素、MUC1*珠子或MUC1*阳性癌细胞激活时,用NFAT诱导型MMP9转导的T细胞仅表达MMP9。当用MUC1*珠子或MUC1*阳性癌细胞刺激T细胞时,用CAR44和NFAT诱导型MMP9转导的T细胞仅表达MMP9。图105B具有装载有以下裂解物的泳道1-7:泳道1:用CAR44转导但未激活的T细胞;泳道2:用CAR44转导,并用呈提已知激活T细胞的抗CD3和抗CD28抗体的珠子激活的T细胞;泳道3:用CAR44转导,并通过与PMA/离子霉素共培养而激活的T细胞;泳道4:用NFAT诱导型MMP9转导但未激活的T细胞;泳道5:用NFAT诱导型MMP9转导,并用呈提抗CD3和抗CD28抗体的珠子激活的T细胞;泳道6:用NFAT诱导型MMP9转导,并通过PMA/离子霉素激活的T细胞;泳道7:也携带Flag DYK标签的无关蛋白。图105C和105D分别是图105A和105B中所示的相同蛋白印迹的较深曝光。图105E是如下转导的细胞的细胞上清液的蛋白印迹照片:泳道1:用CAR44转导但未激活的T细胞;泳道2:用CAR44转导并用珠子激活的T细胞,所述珠子提呈已知激活T细胞的抗CD3和抗CD28抗体;泳道3:用CAR44转导,并通过与PMA/离子霉素共培养激活的T细胞;泳道4:用NFAT诱导型MMP9转导但未激活的T细胞;泳道5:用NFAT诱导型MMP9转导,并用提呈抗CD3和抗CD28抗体的珠子激活的T细胞;泳道6:用NFAT诱导型MMP9转导并用PMA/离子霉素激活的T细胞;泳道7:也带有Flag DYK标签的无关蛋白。结果显示,用NFAT诱导型MMP9转导的T细胞在被激活时表达MMP9。当CAR44和NFAT诱导型MMP9转导的T细胞与呈提或表达MUC1*的珠子或细胞共培养时,它们被特异性激活(图105A泳道5和泳道6)。
在本发明的一个方面,给予被诊断患有癌症或有患癌风险的人足量的用CAR和切割酶转导的免疫细胞。在本发明的另一方面,给予诊断患有癌症或有患癌风险的人足量的用CAR和切割酶转导的免疫细胞,其中切割酶在诱导型启动子上,当免疫细胞激活时由表达的蛋白激活该启动子。在本发明的另一方面,给予诊断患有癌症或有患癌风险的人足量的用CAR和切割酶转导的免疫细胞,其中切割酶在诱导型启动子上,该启动子被一个或多个NFAT激活。在一种情况下,NFAT是NFATc1。在另一方面,NFAT是NFATc3。在另一方面,NFAT是NFATc2。在上述任何情况下,CAR的细胞外结构域包含抗MUC1*抗体的片段。在一个方面,抗MUC1*抗体是MNC2scFv或人源化形式的MNC2scFv。另一方面,抗MUC1*抗体是MNE6scFv或人源化形式的MNE6scFv。在上述任何情况中,免疫细胞可以是T细胞、NK细胞、肥大细胞或树突细胞。
并不意味着本发明限于一种或两种具有由激活的T细胞诱导的切割酶表达的特定方法。我们已经证明了,通过构建具有NFAT启动子序列下游或一个或多个重复的NFAT应答元件的下游的切割酶基因的质粒,仅在T细胞激活时切割酶特异性表达。在本发明的另一方面,通过构建质粒诱导切割酶的表达,其中切割酶基因插入IL-2启动子序列的下游或IL-2应答元件的下游,然后将质粒插入免疫细胞中。在本发明的另一方面,通过构建质粒诱导切割酶的表达,其中将切割酶基因插入钙调神经磷酸酶启动子序列的下游或钙调神经磷酸酶应答元件的下游,然后将质粒插入免疫细胞中然后给予患者进行治疗或预防癌症。还存在药物诱导型质粒,其可用于诱导切割酶的表达或用于停止由激活的T细胞的元件诱导的表达。这些药物诱导系统可包括四环素诱导型系统、Tet-on、Tet-off、四环素应答元件、多西环素、他莫昔芬诱导型系统、蜕皮激素诱导型系统等。
本发明不限于在编码CAR或诱导型切割酶的质粒中使用的一种或两种特异性启动子。如本领域技术人员所知,许多启动子可以互换,包括SV40、PGK1、Ubc、CAG、TRE、UAS、Ac5、多面体、CaMKIIa、GAL1、GAL10、TEF1、GDS、ADH1、CaMV35S、Ubi、H1和U6。由庞大体积细胞表面蛋白如MUC1-FL引起的CAR T细胞进入的空间位阻问题的另一种解决方案是增加由T细胞表达的CAR接头区域的长度。在标准设计CAR中,跨膜部分和抗体片段之间的细胞外接头区域的长度为约45-50个氨基酸。我们制造了长臂CAR,其中细胞外接头的长度从大约50个氨基酸延伸到217-290个氨基酸。共培养测定显示具有较长细胞外接头的CAR具有改善的对靶癌细胞上肿瘤相关抗原的接近。这种策略的动画如图106A-106E所示。
已公布的CAR报告通常使用跨膜结构域和抗体片段、scFv之间的接头,其长度为45-50个氨基酸,并且通常是CD8的细胞外结构域的序列。CAR44是抗MUC1*CAR,其接头衍生自CD8细胞外结构域,长度为45个氨基酸。为了证明长臂CAR使得T细胞能够更多地接近细胞表面附近的肿瘤相关抗原,我们制备了一系列CAR,其中抗MUC1*抗体片段是MNC2scFv(SEQ ID NOS:655),其通过一组可变长度和柔性的接头连接至跨膜结构域,其中跨膜结构域是CD8(SEQ ID NOS:657),然后是共刺激结构域4-1BB(SEQ ID NOS:659),然后是CD3-ζ(SEQ ID NOS:661)。将一组接头掺入到该模型CAR中。使用长度为232个氨基酸的IgG1Fc结构域(SEQ ID NOS:663)作为MNC2 CAR的接头(SEQ ID NOS:665)。使用长度为290个氨基酸的IgD Fc结构域(SEQ ID NOS:667)作为MNC2 CAR的接头(SEQ ID NOS:669)。使用长度为217个氨基酸的IgG1无铰链Fc结构域接头(SEQ ID NOS:671)作为MNC2 CAR的接头(SEQ ID NOS:673)。使用长度为275个氨基酸的IgD无铰链Fc结构域接头(SEQ ID NOS:675)作为MNC2 CAR的接头(SEQ ID NOS:677)。使用长度为58个氨基酸的IgD接头(SEQ ID NOS:679)作为MNC2 CAR的接头(SEQ ID NOS:681)。使用长度为43个氨基酸的X4接头(SEQ ID NOS:683)作为MNC2 CAR的接头(SEQ ID NOS:685)。
这些在scFv和跨膜结构域之间具有可变长度接头的CAR是:CAR15:huE6-IgD-CD8-41BB-3z(SEQ ID NOS:324);CAR16:muE6-IgD-CD8-41BB-3z(SEQ ID NOS:823);CAR17:muC2IgD-CD8-41BB-3z(SEQ ID NOS:825);CAR18:huE6-Fc-CD8-41BB-3z(SEQ ID NOS:311);CAR19:huE6-FcH-CD8-41BB-3z(SEQ ID NOS:316);CAR20:huE6-X4-CD8-41BB-3z(SEQ ID NOS:330);CAR33:huE6-IgD-CD441BB-3z(SEQ ID NOS:327);CAR34:huE6-Fc-CD441BB-3z(SEQ ID NOS:319);CAR35:huE6-FcH-CD441BB-3z(SEQ ID NOS:321);CAR36:huE6-X4-CD441BB-3z(SEQ ID NOS:334);CAR39:muE6-CD28-CD28-CD28-3z(SEQ ID NOS:827);CAR40:muC2-CD28-CD28-CD28-3z(SEQ ID NOS:829);CAR53:huC2-Fc-CD8-41BB-3z(SEQ ID NOS:665和733);CAR54:huC2-IgD+Fc-CD8-41BB-3z(SEQ ID NOS:669和735);CAR55:huC2-FcH-CD8-41BB-3z(SEQ ID NOS:673和737);CAR56:huC2-IgD+FcH-CD8-41BB-3z(SEQ ID NOS:677和739);CAR57:huC2-IgD-CD8-41BB-3z(SEQ ID NOS:681和741);CAR58:huC2-X4-CD8-41BB-3z(SEQ ID NOS:685和743);CAR63:huE6-IgD+Fc-CD8-41BB-3z(SEQ ID NOS:771);CAR64:huE6-IgD+FcH-CD8-41BB-3z(SEQ ID NOS:773);CAR42:huα-CD19-IgD-CD8-41BB-3z(SEQ ID NOS:831)。关于这些长接头CAR的其他细节显示在表1中。表2显示了当转导入人T细胞并与癌细胞共培养时,一些CAR的实验活性。
在共培养实验中,测试具有不同长度的细胞外结构域接头的抗MUC1*CAR的特异性杀死靶MUC1/MUC1*阳性癌细胞的能力。xCELLigence扫描显示在图107A-107B中,显示了一个实验的结果。在该实验中,将长接头CAR转导入人T细胞,然后与T47D乳腺癌细胞共培养。然而,似乎不能有效杀伤靶癌细胞的一些CAR可能只是没被有效表达。进行另一个实验以将CAR表达与CAR功效分开。用一组CAR转导HEK293粘附细胞,每个CAR具有不同长度的接头。CAR质粒还携带GFP标志物,因此每个CAR的表达可以通过绿色细胞的量来测量。向这些细胞中添加已用MUC1*稳定转染的K562悬浮细胞。用红色染料CMTMR染色K562-MUC1*细胞。在洗涤步骤之后,黄色(绿色加红色)的细胞量表明每种CAR识别癌细胞上的靶肿瘤抗原的能力。如图108A-108H所示,CAR的表达水平变化很大。但是,表达水平很容易优化,因此不构成问题。看图108I-108P,显示为黄色的细胞数量与保持绿色的细胞数量,提供了更多关于哪些CAR连接体最能克服靶癌细胞上其他表面分子的空间位阻的信息。显著量的靶癌细胞结合CAR表达细胞,所述CAR具有衍生自CD8、IgG1FcH(无铰链)、IgD和IgDFcH(无铰链)的接头。除长度外,预计在这些CAR中测试的接头的刚性也不同。
表2显示了用一些长接头CAR转染的人T细胞的细胞因子释放数据。
我们注意到,具有增强的针对实体瘤癌症的功效的“长臂”CAR可以由识别肿瘤相关抗原的任何抗体片段指导,包括MNE6 scFv、MNC2-scFv和其他抗MUC1*抗体片段。类似地,长臂CAR的跨膜部分可以衍生自CD8、CD4或其他跨膜结构域。CAR的细胞内尾部可由CD3-ζ和任何其他共刺激结构域(包括CD28、4-1BB和OX40)或其组合组成。
另一方面,本发明涉及一种组合物,其包括至少两种转染到相同免疫细胞中的不同质粒,其中第一种编码包含与肿瘤抗原结合的抗体片段、scFv或肽的CAR,另一种编码非CAR基因,其中非CAR基因由被激活的免疫细胞的元件激活的诱导型启动子表达。在一个方面,免疫细胞是T细胞或NK细胞。在一个方面,CAR包含结合MUC1*的细胞外结构域的抗体片段、scFv或肽。在一个方面,CAR包含衍生自MNC2、MNE6、MNC3或MNC8的scFv。在一个方面,非CAR物质是切割酶。在一个方面,切割酶是MMP2、MMP3、MMP9、MMP13、MMP14、MMP16、ADAM10、ADAM17、ADAM28或其催化活性片段。另一方面,非CAR物质是细胞因子。在一个方面,细胞因子是IL-7。在一个方面,细胞因子是IL-15。另一方面,细胞因子是IL-7和IL-15。在一种情况下,非CAR物质的表达由激活的免疫细胞的元件诱导。在一个方面,激活的免疫细胞的元件是NFAT。在一个方面,NFAT是NFATc1、NFATc3或NFATc2。已知细胞因子IL-7和IL-15促进T细胞持久性。在本发明的一个方面,将上述免疫细胞给予于患者以治疗或预防癌症。在本发明的一个方面,癌症是MUC1阳性癌症或MUC1*阳性癌症。
另一方面,本发明涉及一种组合物,其包括至少两种转染到相同免疫细胞中的不同质粒,其中第一种编码包含与B细胞表面上的抗原的细胞外结构域结合的抗体片段、scFv或肽的CAR,另一种编码非CAR基因,其中非CAR基因由被激活的免疫细胞的元件激活的诱导型启动子表达。在一个方面,免疫细胞是T细胞或NK细胞。在一个方面,CAR包含结合CD19的抗体片段、scFv或肽。在一个方面,CAR包含衍生自SEQ ID NOS:830-831的序列。另一方面,抗体片段、scFv或肽结合B细胞或B细胞前体的表面抗原,或结合CD19、CD20、CD22、BCMA、CD30、CD138、CD123、CD33或LeY抗原。在一个方面,非CAR物质是切割酶。另一方面,非CAR物质是细胞因子。在一个方面,细胞因子是IL-7。在一个方面,细胞因子是IL-15。另一方面,细胞因子是IL-7和IL-15。在一种情况下,非CAR物质的表达由激活的免疫细胞的元件诱导。在一个方面,激活的免疫细胞的元件是NFAT。在一个方面,NFAT是NFATc1、NFATc3或NFATc2。此非CAR,其中非CAR基因由诱导型启动子表达,其中表达由激活的免疫细胞的元件诱导。在一个方面,将用组合物转染或转导的免疫细胞给予于患者以治疗或预防癌症。在一种情况下,癌症是白血病、淋巴瘤或血癌。
本发明不受限于用于插入基因或质粒的特定方法或技术,所述基因或质粒包含编码CAR或其中编码激活的T细胞诱导蛋白或肽的序列。例如,编码本文所述的CAR的基因和激活的T细胞诱导基因可以使用病毒而病毒转导到免疫细胞中,这可能会或可能不会导致CAR基因掺入到受体细胞的基因组中。病毒递送系统和病毒载体包括但不限于逆转录病毒,包括γ-逆转录病毒、慢病毒、腺病毒、腺相关病毒、杆状病毒、痘病毒、单纯疱疹病毒、溶瘤病毒、HF10、T-Vec等。除病毒转导外,本文所述的CAR和激活的T细胞诱导基因可以使用如CRISPR技术、CRISPR-Cas9和-CPF1、TALEN、睡美人转座子系统和SB 100X的方法直接剪接到受体细胞的基因组中。
庞大的细胞表面蛋白如MUC1-FL也可引起BiTE的空间位阻问题。BiTE是双头双特异性抗体,其中一个头部结合T细胞而另一个头部结合肿瘤相关抗原。以这种方式,BiTE将T细胞和肿瘤细胞连接在一起。结合T细胞的抗体应该是激活T细胞的抗体,例如针对CD3的抗体,例如OKT3 scFv(SEQ ID NOS:687)或CD28。为了解决空间位阻问题,延长了T细胞特异性抗体和肿瘤特异性抗体之间的接头。具有延伸的接头的BiTE的实例抗CD3-接头-抗MUC1*显示为SEQ ID NOS:689、691、693、695、697和699。
在本发明的另一方面,抗MUC1*单链分子与切割酶或切割酶的催化活性片段融合。在本发明的一个方面,切割酶是MMP9(SEQ ID NOS:701)。在本发明的另一个方面,酶是MMP9的催化活性片段(SEQ ID NOS:703)。在一些情况下,选择CAR的抗体片段是根据其识别MUC1*(当特异性切割酶切割时)的能力。在一个实施例中,切割酶是MMP9、MMP3、MMP14、MMP2、ADAM17、ADAM TS16和/或ADAM28。在一个实施例中,抗体或抗体片段结合于具有SEQ ID NOS:2(PSMGFR)GTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGA、PSMGFR N-10即QFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGA、或PSMGFR N+18即SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGA序列的肽。“PSMGFR N+18”是指MUC1受体的片段,其中在SEQ ID NOS:1的MUC1受体内的PSMGFR区段的N末端添加了18个氨基酸残基。在另一个实施例中,将切割酶MMP9和MMP3转导到T细胞中,该T细胞也用具有抗体片段的CAR转导,其中抗体片段是MNC2的片段。
用于进行与本发明有关的实验的方法
1.慢病毒产生和免疫细胞的病毒转导
HEK293或HEK293T细胞(ATCC)用于产生慢病毒。前一天,用聚D-赖氨酸包被转染平板(6孔板),接种细胞使细胞密度在转染时达到90-95%,并在5%CO2气氛中培养。第二天,根据制造商说明用Lipofectamine 3000(life technologies)和Opti-I还原血清培养基转染细胞(使用0.75ug慢病毒表达载体和2.25ug pPACKH1包装混合物)。温育6小时后,更换培养基并在24和48小时后收获含有慢病毒的培养基。用Lenti-X concentrator(Clontech)浓缩慢病毒,并使用Lenti-X4Rapid Titer Kit(Clontech)计算滴度。慢病毒以单次使用等分试样储存在-80℃。
用包含CAR的构建体转导免疫细胞
将人T细胞(如果冷冻)解冻并在100-200单位IL-2和TexMACS培养基(20ml)中预热,并离心沉淀。将细胞重悬于10ml培养基中,并以1×106细胞/ml在含有抗CD3/抗CD28珠子(TransAct试剂盒)的完全培养基中于37℃,5%CO2中培养。
培养4天后,对细胞进行计数,将450μl细胞悬浮液以约1×106个细胞/ml的密度置于24孔板的单孔中。使细胞沉降。从每个孔的顶部小心地除去150μl。向每个孔中添加在普通TexMACS培养基中与硫酸鱼精蛋白一起适当稀释的慢病毒载体(以终浓度10μg/ml、150μl体积添加,最终总体积为450μl/孔),并温育24小时。除去转导的细胞,离心沉淀,并重新悬浮于新鲜培养基中,调节细胞密度不超过1.0×106个细胞/ml。转导T细胞可以扩增和冷冻或直接使用。通常用IL-2和TransAct培养基在激活后第7天和第20天之间使用或冷冻转导的T细胞。
2.比较几种抗MUC1*CAR中的CAR T细胞活性
用抗MUC1*CAR18、CAR19、CAR44、CAR49、CAR44和CAR49或CAR50转导人T细胞(ALLCELLS)。CAR构建体都具有GFP标志物,使得CAR T细胞是绿色的并且未转导T细胞(图80A)是清楚的。CAR18是huMNE6scFv-Fc-CD8-41BB-3z。CAR19是相同的,除了代替scFv和跨膜区之间的接头的Fc区的一部分,CAR19具有带有铰链部分突变的Fc区。CAR44是huMNC2-scFv-CD8-CD8(跨膜-41BB-3z)。CAR49与CAR44相同,除了CAR44具有CD8前导序列且CAR49具有IgK前导序列。CAR50与CAR44相同,除了CAR50具有鼠MNC2-scFv和CD4跨膜结构域。表1给出了每种CAR构建体的细节。然后将CAR T细胞与已用mCherry(红色)稳定转染的HCT-MUC1*癌细胞一起温育18小时。当T细胞识别靶细胞时,它们聚集靶细胞并开始杀伤它们。从图80A-80F中可以看出,绿色CAR T细胞有效地聚集并杀伤靶MUC1*阳性癌细胞。
3.给予MUC1*阳性癌细胞“死亡之吻”的CAR T细胞的共聚焦成像。
将用CAR44转导的人T细胞与用GFP(绿色)稳定转染的MUC1*阳性癌细胞共培养24小时。所有细胞用DAPI(蓝色)染色。颗粒酶B用荧光团染色。在T细胞激活后,它们表达被认为在靶癌细胞中形成孔的穿孔素。然后T细胞向癌细胞注射颗粒酶B(黄色),颗粒酶B然后诱导凋亡途径,导致癌细胞裂解。图81A-81D显示人huMNC2-CAR44T细胞的照片,其将颗粒酶B(黄色)注射到MUC1*阳性和GFP阳性(绿色)DU145前列腺癌细胞中。图81A是4X放大照片。图81B是20X放大的照片。图81C是20X放大的照片。图81D是40X放大的照片。
5.通过FACS分析分析CAR T细胞诱导MUC1*阳性癌细胞的杀伤
图82A-82B显示huMNC2-CAR44T细胞对T47D MUC1*阳性乳腺癌细胞的杀伤作用,其中乳腺癌细胞已用渐进量的另外的MUC1*转染。可以看出,随着在细胞上表达的靶MUC1*的量增加,huMNC2-CAR44T细胞的杀伤作用增加。图82A是通过FACS测量的靶细胞杀伤的图。图82B是ELISA测定的图,其中探测来自与T47D细胞共培养的huMNC2-CAR44T细胞的上清液分泌的干扰素γ的存在,这是T细胞激活的信号。
有许多通过FACS分析细胞毒性的方法。在该实施例中,根据标准方案从全血中分离人T细胞。然后用携带CAR构建体的慢病毒分别转导T细胞两次,其中CAR构建体携带GFP标签。在RPMI 10%FBS和IL-2中培养2-3天后,用F(ab')2染色细胞以标记MN-E6、MN-C2、MN-C3和MN-C8的表面表达。然后通过流式细胞术对细胞进行Fab阳性、GFP阳性细胞分选。这意味着双阳性群体插入了CAR并且CAR暴露了正确的抗体片段。然后CAR T细胞准备好与MUC1*阴性对照细胞或靶MUC1*阳性癌细胞混合。
靶细胞如下制备:收获靶细胞并在含有15uM CMTMr染料(Cell Tracker Orange,5-和-6-4-氯甲基苯甲酰氨基四甲基罗丹明,Thermo Fisher)的无血清培养基中以1-1.5×106个细胞/mL重悬细胞。在适合特定细胞类型的生长条件下温育30分钟。在培养基中洗涤并将染色的细胞转移到新管中并在培养基中温育细胞60分钟。在培养基中再洗涤2次以除去所有多余的染料。在具有0.5ml培养基总体积的24孔板中设置测定。重悬靶细胞(和控制靶细胞),使每孔总共有20,000个细胞(20,000个细胞/250ul)。每孔加250ul。添加250ul T细胞,使T细胞:靶细胞的比例=20:1、10:1、5:1或1:1。24h和72h后分析细胞。对于悬浮靶细胞,从孔中取出0.5ml培养基并置于管中,用0.5ml培养基或PBS洗涤孔。对于粘附靶细胞,从孔中取出0.5ml培养基并置于管中,用0.5ml PBS洗涤孔。将PBS添加相同的管中,并向孔中添加120ul胰蛋白酶。温育4分钟,然后添加0.5ml培养基来中和胰蛋白酶并也将其置于试管中。旋转细胞并在100ul FACS缓冲液中重悬沉淀。再次旋转细胞。将细胞重悬于100ul缓冲液+5ul抗CD3抗体,在冰上30分钟(以染色T细胞)。30分钟后,用FACS缓冲液洗涤染色的细胞2次,并重悬于250μl缓冲液中。使细胞穿过FACS管的过滤器盖。在分析前10分钟,向每个管中添加10ul 7AAD染料,并用Fortessa在细胞毒性模板下分析。图83A-83D显示了与MUC1*阳性癌细胞共培养24小时后huMNC2-CAR44T细胞的FACS分析结果。图83A是FACS数据的图,显示与未转导T细胞(红色条)相比,被huMNC2-CAR44T细胞(蓝色条)杀死的T47D癌细胞的百分比。X轴显示T细胞与癌细胞的比率。图83B是FACS数据的图,显示与未转导T细胞(红色条)相比,被huMNC2-CAR44T细胞(蓝色条)杀死的K562-MUC1*癌细胞的百分比。图83C显示FACS扫描,其中T47D乳腺癌细胞用染料CMTMR染色。Sytox blue是死细胞染色剂。死癌细胞是象限2和3中的细胞。图83D显示FACS扫描,其中K562-MUC1*癌细胞用染料CMTMR染色。Sytox blue是死细胞染色剂。死癌细胞是象限2和3中的细胞。
使用人IFN-γELISA试剂盒(Biolegend)测量培养基中的IFN-γ分泌。用抗IFN-γ抗体(捕获抗体,在包被缓冲液中1X)包被平板。在4℃温育过夜后,用PBS-T洗涤板4次,添加封闭溶液以阻断孔上剩余的结合位点。在室温下1小时(以500rpm振荡)后,用PBS-T洗涤板4次,并添加条件培养基(CM)和IFN-γ标准品。在室温振荡2小时后,用PBS-T洗涤板4次,并添加检测抗体(1x)。在室温振荡1小时后,用PBS-T洗涤板4次,并添加亲和素蛋白-HRP(1x)。在室温振荡30分钟后,用PBS-T洗涤板5次(每次洗涤浸泡1分钟)并添加TMB底物溶液。20分钟后,通过添加终止溶液终止反应,并在停止15分钟内在450nm处读取吸光度(减去570nm处的吸光度)。
6.通过xCELLigence分析CAR T细胞诱导MUC1*阳性癌细胞的杀伤
除了FACS分析,许多研究人员现在使用xCELLigence仪器来测量癌细胞的CAR T杀伤。xCELLigence仪器使用电极阵列,癌细胞在其上铺板。粘附癌细胞使电极绝缘,因此随着它们的生长导致阻抗增加。相反,T细胞不粘附并保持悬浮状态,因此不会导致将会增加阻抗的电极的绝缘性。然而,如果T细胞或CAR T细胞杀死电极板上的癌细胞,则癌细胞在它们死亡时会上升并漂浮,这导致阻抗降低。xCELLigence仪器测量阻抗作为时间的函数,这与癌细胞杀伤相关。此外,电极板还具有观察窗。当CAR T细胞有效杀死吸附的靶癌细胞时,阻抗降低,但也可以看到在板表面上没有留下癌细胞。
在大多数XCELLigence实验中,在96孔电极阵列板的每个孔中接种5,000个癌细胞。使细胞粘附并生长24小时。然后添加CAR T细胞,效应物与靶标的比例(E:T)为0.5:1、1:1、2:1、5:1、10:1,有时为20:1。当实际转导效率为40%时,E:T比率假定CAR 100%转导到T细胞中。
xCELLigence仪器将阻抗记录为时间的函数,实验可持续长达7天。
图78、图79、图84H、图85H、图86A-86C、图89A-89C、图90A-90D和图107A-107B均显示在xCELLigence仪器上进行的CAR T和癌细胞实验的结果。
7.携带人类肿瘤的小鼠中的抗MUC1*CAR T细胞疗法
向8-12周龄之间的雌性NOSD/SCID/GAMMA(NSG)小鼠植入500,000个人癌细胞,其中癌细胞先前已用荧光素酶稳定转染。携带荧光素酶阳性细胞的小鼠可以在成像之前注射酶的底物荧光素,这使得癌细胞发出荧光。注射荧光素后10-15分钟内在IVIS仪器上在活小鼠中对癌细胞成像。读数是每秒光通量或光子数。允许肿瘤移植直至通过IVIS清楚地看到肿瘤。
图91A-91Y显示了在IVIS仪器上拍摄的小鼠的荧光照片。NSG(NOSD/SCID/GAMMA)免疫受损小鼠在第0天于胁腹皮下植入500,000个已用萤光素酶稳定转染的人MUC1*阳性癌细胞。允许肿瘤移植。在IVIS测量后第5天和第12天,给动物注射1000万个用huMNC2-scFv-CAR44转导的人T细胞、未转导T细胞或PBS。肿瘤内注射500万个T细胞,尾静脉注射500万个T细胞。在IVIS拍照前10分钟,给小鼠腹膜内注射(IP)荧光素,荧光素在荧光素酶切割后发荧光,从而使肿瘤细胞发荧光。
图92A-92J显示了在IVIS仪器上拍摄的小鼠的荧光照片。NSG(NOSD/SCID/GAMMA)免疫受损小鼠在第0天于胁腹皮下注射500K人BT-20细胞,其为MUC1*阳性三阴性乳腺癌细胞系。用荧光素酶稳定转染癌细胞。允许肿瘤移植。在IVIS测量后第6天,给动物一次性注射1000万个用huMNC2-scFv-CAR44转导的人T细胞或未转导T细胞。肿瘤内注射500万个T细胞,尾静脉注射500万个。在IVIS拍照前10分钟,给小鼠IP注射荧光素。
图93A-93H显示了在IVIS仪器上拍摄的小鼠的荧光照片。NSG(NOSD/SCID/GAMMA)对免疫受损小鼠在第0天将500K人SKOV-3细胞注射到腹膜腔(IP)中,所述SKOV-3细胞是MUC1*阳性卵巢癌细胞系。用荧光素酶稳定转染癌细胞。允许肿瘤移植。在IVIS测量后第3天,给动物IP注射10M用huMNC2-scFv-CAR44转导的人T细胞、未转导T细胞或PBS。在第7天再次对动物进行IVIS成像。在IVIS拍照前10分钟,给小鼠IP注射荧光素。
8.MMP9处理细胞的共聚焦分析
将稳定表达MUC1全长的HCT-MUC1-41TR(也称为HCT-MUC1-18)细胞接种于DMEM+10%FCS的6通道u-slide VI 0.4(Ibidi,WI)中。48小时后,用120uL PBS pH 7.4洗涤细胞,以不同浓度(40uL,在0、12.5、25、50和100ng/mL)添加稀释于无血清培养基(DMEM)中的MMP9催化结构域(Enzo Life Sciences,NY)。在37℃下在CO2培养箱中1小时后,用120uL冷PBS pH 7.4洗涤细胞两次,并在4%PFA(30uL)中固定8分钟。用冷PBS pH 7.4洗涤细胞3次,并用PBS pH 7.4(5μL)中的5%BSA溶液在4℃下封闭30分钟(振荡)。用冷PBS pH 7.4(1次)洗涤细胞后,将细胞在4℃下(振荡)与125μg/mL在PBS pH 7.4(100uL)中稀释的MNC2一起温育过夜。第二天,将细胞用120uL PBS pH 7.4洗涤3次,并在4℃下(振荡)与稀释于PBS pH 7.4(100uL,1:200)中的山羊抗小鼠IgG PE(Biolegend,CA)一起温育2小时。温育后,用120μLPBS pH7.4洗涤细胞1次,用120μL PBS pH 7.4+2.5μM Hoechst 33342洗涤2次。最后,用Ibidi封固剂(Ibidi,WI)固定细胞。结果显示,添加MMP9诱导全长MUC1切割成被抗MUC1*单克隆抗体MNC2识别的MUC1*形式(图96A-96E)。这表明MMP9在MNC2识别的位点切割MUC1。
9.NFAT诱导型MMP9催化结构域表达
根据制造商手册,用Lipofectamine 3000(ThermoFisher Scientific,MA)将含有4个重复的NFAT应答元件或NFATc1启动子以及随后MMP9催化结构域的载体瞬时转染到HEK293TN细胞(System Biosciences,CA)中。24-30小时后,将培养基更换为DMEM+1%FBS+10ng/mL PMA(Cayman Chemical,MI)和离子霉素(1-6uM,Cayman Chemical,MI)。温育18小时后收集培养基和细胞用于分析。
根据以下方案,通过细胞裂解物和条件培养基的蛋白印迹分析证实MMP9的表达和分泌。用裂解缓冲液(50mM Tris,150mM NaCl和1%Triton X100)在冰上裂解细胞20分钟。对于蛋白印迹,通过凝胶电泳(4-15%Mini-TGXTM Precast Protein Gels,BioRad,CA)分离100ug蛋白,然后转移至PVDF膜(BioRad,CA)。用PBS-T简单冲洗膜,然后在室温下用3%脱脂乳溶液(BioRad,CA)封闭1小时。对于Flag标记蛋白,快速洗涤膜并与稀释于1%脱脂乳(1:2000)中的兔抗DYKDDDDK表位标签抗体(Biolegend,CA)在室温下温育2小时。对于His标记蛋白,快速洗涤膜并与稀释于1%脱脂乳(1:10000)中的兔抗6X His标签抗体HRP(Abcam,MA)在室温下温育1小时。对于Flag标记蛋白,然后用PBS-T洗涤膜3次10分钟,并与稀释于1%脱脂乳(1:2500)中的山羊抗兔HRP抗体在室温下温育1小时。对于His标记的蛋白,在Flag标记蛋白的二抗温育后,使用ClarityTMWestern ECL Substrate(BioRad,CA)用PBS-T洗涤3次10分钟后处理膜。
在某些情况下,蛋白在分析前首先进行免疫沉淀。根据制造商手册,使用抗-DYKDDDDKTag(L5)亲和凝胶(Biolegend,CA)从条件培养基(~2mL)中免疫沉淀Flag标记MMP9催化结构域。捕捉蛋白用于蛋白印迹分析或切割测定。
图98A-98F是用识别转染的MMP9构建体的抗体探测的细胞裂解物的蛋白印迹的照片。构建质粒,然后转染到HEK293T细胞中,其中MMP9催化结构域的基因插入3或4个NFAT应答元件的下游。除对照(ctl)细胞外,通过添加10ng/mL的PMA和1μM或2μM的离子霉素激活NFAT途径。使用珠子进行捕捉,所述珠子与识别Flag标签的抗体偶联,所述Flag标签掺入MMP9构建体的C末端。泳道1显示分子量对照。泳道2、3、4和5显示从抗Flag标签珠子洗脱的MMP9。泳道2和3是第一洗脱,泳道4和5中显示的细胞是第二洗脱。向泳道2和4中加载来自细胞的条件培养基,其中NFAT途径已经用10ng/mL PMA和1μM离子霉素激活。向泳道3和5中加载来自细胞的条件培养基,其中NFAT途径已用10ng/mL PMA和2μM离子霉素激活。
图100A-100E显示在HEK293T细胞中表达的NFAT诱导型MMP9催化结构域,其中MMP9的天然前导序列已被IgK前导序列取代,MMP9催化结构域位于4个重复的NFAT应答元件的下游。图100A显示了在激活NFAT途径后检测细胞裂解物中MMP9表达的蛋白印迹的照片。图100B显示了在激活NFAT途径后检测条件培养基中MMP9表达的蛋白印迹的照片。
图101A-101E显示MMP9可以用不同的前导序列表达,并且还显示各自的后续活性。图101A显示了检测细胞裂解物中MMP9蛋白的蛋白印迹,其中MMP9基因上游的前导序列是其天然序列或IgK序列。图101B显示了在条件培养基中检测MMP9的蛋白印迹,其中MMP9基因上游的前导序列是其天然序列或IgK。
图102A-102D显示了用产生NFAT诱导型MMP9的质粒转染的细胞的三(3)个克隆4、6和7,其中NFATc1启动子序列在MMP9基因的上游,在这种情况下是包含其催化结构域的截短的MMP9。还显示用于比较的细胞是用产生NFAT诱导型MMP9的质粒转染的细胞,其中4个重复的NFAT应答元件序列在MMP9基因的上游。图102A显示了检测细胞裂解物中MMP9蛋白的蛋白印迹。图102B显示了检测条件培养基中MMP9的蛋白印迹。
图105A-105E显示用单独的CAR44、单独的NFAT诱导型MMP9或用CAR44和NFAT诱导型MMP9转导的人T细胞的蛋白印迹的照片,其中所得T细胞未被激活、被PMA/离子霉素化学激活、通过与呈提合成MUC1*肽的珠子共培养或与MUC1*阳性癌细胞共培养而激活。用抗Flag标签(也称为DYK标签抗体)探测蛋白印迹。MMP9的催化结构域以约40kDa的表观分子量移动。图105A-105D显示了澄清的细胞裂解物的蛋白印迹的照片。结果显示,当用PMA/离子霉素、MUC1*珠子或MUC1*阳性癌细胞激活时,用NFAT诱导型MMP9转导的T细胞仅表达MMP9。当用MUC1*珠或MUC1*阳性癌细胞刺激T细胞时,用CAR44和NFAT诱导型MMP9转导的T细胞仅表达MMP9。
结果显示,用NFAT诱导型MMP9转导的T细胞在被激活时表达MMP9。当CAR44和NFAT诱导型MMP9转导的T细胞与呈提或表达MUC1*的珠子或细胞共培养时,它们被特异性激活(图105A泳道5和泳道6)。
10.荧光MMP肽底物切割测定
将OMNIMMP荧光底物(Enzo life sciences,NY)在测定缓冲液(50mM Tris pH 7.5,300mM NaCl,1mM CaCl2,5μM Zncl2,0.1%Brj-35和15%甘油)中稀释至20uM,并保持在冰上并保护其免受光照直到使用。肽也可以在PBS pH 7.4或培养基中稀释。细胞裂解物稀释至0.4mg/mL便为测定缓冲液(或PBS pH 7.4或培养基)。对于该测定,将50uL重组MMP9催化结构域(以1-2μg/mL在测定缓冲液、PBS pH 7.4或培养基)、50uL稀释的细胞裂解物、50uL条件培养基或50uL捕捉蛋白添加到与荧光计兼容的96孔板的孔中。在开始测定之前,向每个孔中添加50uL稀释的肽并快速混合(最终肽浓度为10μM)。在37℃下每10分钟记录荧光持续约6小时(Ex.:328nm,Em.:393nm)。
图97显示MMP9的荧光肽底物(OMNIMMP肽)被两种浓度的MMP9催化结构域在PBS(实线)或细胞培养基(虚线)中切割的图。
图99A-99C显示荧光肽(OMNIMMP肽)即MMP9的底物被HEK293T细胞的细胞裂解物或条件培养基切割的图,所述HEK293T细胞用含有在4个重复的NFAT应答元件下游的MMP9基因的质粒转染。MMP9肽底物测定显示PMA/离子霉素激活NFAT途径导致MMP9表达和分泌,并且其活性如其切割肽底物的能力所证明。
图100C显示MMP9荧光肽底物(OMNIMMP肽)在HEK293T细胞的条件培养基中由表达和分泌的MMP9催化结构域切割的图,其中MMP9的天然前导序列已被IgK前导序列取代,MMP9催化结构域位于4个重复的NFAT应答元件的下游。图100D显示了在HEK293T细胞的条件培养基中由表达和分泌的MMP9催化结构域对MMP9荧光肽底物切割的图,其中MMP9的天然前导序列已被IgK前导序列取代,MMP9催化结构域位于4个重复的NFAT应答元件的下游。
图101C显示了被表达的MMP9切割的MMP9肽底物的图。
图103A-103D显示了MMP9肽底物切割测定的图。图103A显示了来自用质粒所转染的细胞的裂解物的MMP9切割活性,所述质粒具有NFATc1启动子或4个重复的NFAT应答元件驱动的MMP9表达。图103B显示了来自用质粒所转染的细胞的条件培养基中的MMP9切割活性,所述质粒具有NFATc1启动子或4个重复的NFAT应答元件驱动的MMP9表达。
图104A-104B显示了测量MMP9活性的OMNIMMP9荧光底物测定的结果。将来自单独的或与CAR44组合的NFAT诱导型MMP9转导的人T细胞的条件培养基添加到测定中,并测量MMP9底物切割作为时间的函数。图104A显示了在通过与HCT-MUC1*癌细胞共培养激活细胞后,用CAR44和NFAT诱导型MMP9转导人T细胞时的MMP9活性。未显示作为时间函数的增加的底物切割的迹线是来自未被激活的细胞的条件培养基。图104B显示当通过与已知激活T细胞的抗CD3和抗CD28包被的珠子共培养而激活细胞后,仅用NFAT诱导型MMP9转导人T细胞时的MMP9活性。未显示作为时间函数的增加的底物切割的迹线是来自未被激活的细胞的条件培养基。
11.克隆
将MMP9催化结构域克隆到NFAT应答元件的慢病毒载体下游:
合成了两个序列(pNFAT-MMP9cat-1和pNFAT-MMP9cat-2(SEQ ID NOS:784和SEQ ID NOS:785))。用SpeI和KpnI限制酶(New England Biolabs)消化慢病毒载体pGreenFire1-4x NFAT(System Biosciences,CA)。使用Gibson assembly cloning kit(New England Biolab)组装纯化的片段和2个合成的序列。所得的构建体(pGreenFire1-4x NFAT-MMP9cat)含有4个重复的NFAT应答元件、随后的最小启动子(mCMV)和具有其天然前导序列的MMP9催化结构域。
将NFAT应答元件克隆到pGL4-14[luc2/Hygro]中:
使用以下引物通过聚合酶链反应(PCR)从慢病毒载体pGreenFire1-4x NFAT扩增4X NFAT结构域:5'-tagatggtaccaagaggaaaatttgtttcatacag-3'(SEQ ID NOS:786)和5'-tagataagcttgctggatcggtcccggtgtc-3'(SEQ ID NOS:787)。用KpnI和HindIII限制酶(New England Biolabs)消化后,将纯化的片段克隆到用相同限制酶消化的无启动子载体pGL4-14[luc2/Hygro](Promega)中以产生构建体pGL4-14-4xNFAT。
将MMP9催化结构域克隆到pGL4-14-4xNFAT中:
使用以下引物,通过聚合酶链反应(PCR)从慢病毒载体pGreenFire1-4x NFAT-MMP9cat扩增含有最小启动子(mCMV)和随后的MMP9天然前导序列以及MMP9催化结构域的片段:5'-tcatacagaaggcgttactagttaggcgtgtacggtgg-3'(SEQ ID NOS:788)和5'-acagtaccggattgccaagcttttatcacttatcgtcgtcatccttg-3'(SEQ ID NOS:789)。用SpeI和HindIII限制酶(New England Biolabs)消化pGL4-14-4xNFAT。使用Gibson assembly cloning kit(New England Biolab)组装纯化的PCR片段和消化的pGL4-14-4xNFAT以产生构建体pGL4-14-4xNFAT-MMP9cat。
将MMP9催化结构域克隆到pSECTag2中:
使用以下引物,通过聚合酶链反应(PCR)从慢载体pGreenFire1-4x NFAT-MMP9cat扩增不含其天然前导序列的MMP9催化结构域:5'-aagttggtaccgttccaaacctttgagggcgacc-3'(SEQ ID NOS:790)和5'-aagttctcgagcaggttcagggcgaggaccatag-3'(SEQ ID NOS:791)。用KpnI和XhoI限制酶(New England Biolabs)消化后,将纯化的片段克隆到用相同的限制酶消化的载体pSECTag2A(ThermoFisher Scientific)中以产生构建体pSECTag2MMP9cat His。在该构建体中,MMP9催化结构域将在IgK前导序列(如果有)下游。
将带有IgK前导序列的MMP9催化结构域克隆到pGL4-14-4xNFAT中:
使用以下引物,通过聚合酶链式反应(PCR)从pGL4-14-4xNFAT-MMP9cat扩增具有其天然前导序列的MMP9催化结构域:5'-attgactcgagctctcgacattcgtttctagagc-3'(SEQ ID NOS:792)和5'-attgaaagcttttatcacttatcgtcgtcatccttg-3'(SEQ ID NOS:793)。用XhoI和HindIII限制酶(New England Biolabs)消化后,将纯化的片段克隆到用相同的限制酶消化的载体pGL4-14[luc2/Hygro](Promega)中以产生构建体pGL4-14MMP9cat XH。
使用以下引物,通过聚合酶链反应(PCR)从pGL4-14-4xNFAT-MMP9cat扩增含有4x NFAT应答元件和随后的最小启动子(mCMV)的片段:5'-tagcaaaataggctgtccc-3'(SEQ ID NOS:794)和5'-attgactcgaggctggatcggtcccggtgtc-3'(SEQ ID NOS:795)。用KpnI和XhoI限制酶(New England Biolabs)消化后,将纯化的片段克隆到用相同限制酶消化的载体pGL4-14MMP9cat XH中以产生构建体pGL4-14 4xNFAT-MMP9cat KXH
使用以下引物,通过聚合酶链式反应(PCR)从pSECTag2MMP9cat扩增含有IgK前导序列和随后的MMP9催化结构域的片段:5'-aagacaccgggaccgatccagcctcgagagacccaagctggctagccacc-3'(SEQ ID NOS:796)和5'-ttaccaacagtaccggattgccaagcttttatcacttatcgtcgtcatcc-3'(SEQ ID NOS:797)。用XhoI和HindIII限制酶(New England Biolabs)消化pGL4-14 4xNFAT-MMP9cat KXH。使用Gibson assembly cloning kit(New England Biolab)组装纯化的PCR片段和消化的pGL4-14 4xNFAT-MMP9cat KXH以产生构建体pGL4-14-4xNFAT-IgK MMP9cat。
将MMP9催化结构域克隆到NFATc1启动子下游的pEZX-PG02.1中:
0440使用以下引物,通过聚合酶链式反应(PCR)从慢病毒载体pGreenFire1-4x NFAT-MMP9cat扩增具有其天然前导序列的MMP9催化结构域:5'-attgaaagcttctctcgacattcgtttctagagc-3'(SEQ ID NOS:798)和5'-attgagagctcttatcacttatcgtcgtcatc-3'(SEQ ID NOS:799)。用HindIII和SacI限制酶(New England Biolabs)消化后,将纯化的片段克隆到NFACTc1启动子(GeneCopoeia,MD)下游的载体pEZX-PG02.1中以产生构建体pEZX-NFATc1-MMP9cat。
pEZX-NFATc1-MMP9cat的修饰:
修饰pEZX-NFATc1-MMP9cat以引入NFATc1启动子的5'的SpeI和KpnI限制性位点以及MMP9催化结构域的NheI和EcoRV限制性位点3'。我们根据IDT、IA的要求合成了两个gBLOCK。(NFAT modif 1和NFAT modif 2,SEQ ID NOS:800和SEQ ID NOS:801)。用NheI、EcoRI、SacI和XhoI限制酶(New England Biolabs)消化pEZX-NFATc1-MMP9cat载体。使用Gibson assembly cloning kit(New England Biolab)纯化两个片段并与两个合成gBLOCK组装。
将NFATc1启动子/MMP9催化结构域克隆到慢病毒载体pCDH-CMV-MCS-EF1α-Hygro中:
用SpeI和NheI限制酶(New England Biolabs)消化修饰的pEZX-NFATc1-MMP9cat载体,并且将含有NFATc1启动子和随后的MMP9催化结构域的片段纯化并克隆到用相同限制酶消化的慢病毒载体pCDH-CMV-MCS-EF1α-Hygro(System Biosciences)中。
将NFAT应答元件/MMP9催化结构域克隆到慢病毒载体pCDH-CMV-MCS-EF1α-Hygro中:
使用以下引物,通过聚合酶链式反应(PCR)从载体pGL4-14-4xNFAT-MMP9cat扩增含有4个重复的NFAT应答元件和随后的具有其天然前导序列的MMP9催化结构域的片段:5'-acaaaattcaaaattttatcgatactagttggcctaactggccggtaccaag-3'(SEQ ID NOS:802)和5'-atccgatttaaattcgaattcgctagcttatcacttatcgtcgtcatcc-3'(SEQ ID NOS:803)。使用Gibson assembly cloning kit(New England Biolab)组装纯化的PCR片段和消化的pCDH-CMV-MCS-EF1α-Hygro(SpeI和NheI)。
本文引用的所有参考文献都通过引用整体并入。
序列表自由文本
关于除a、g、c、t以外的核苷酸符号的使用,它们遵循WIPO标准ST.25、附录2、表1中所述的惯例,其中k代表t或g;n代表a,c,t或g;m代表a或c;r代表a或g;s代表c或g;w代表a或t、y代表c或t。
MUC1受体
(粘蛋白1前体,Genbank Accession number:P15941)
MTPGTQSPFFLLLLLTVLTVVTGSGHASSTPGGEKETSATQRSSVPSSTEKNAVSMTSSVLSSHSPGSGSSTTQGQDVTLAPATEPASGSAATWGQDVTSVPVTRPALGSTTPPAHDVTSAPDNKPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDTRPAPGSTAPPAHGVTSAPDNRPALGSTAPPVHNVTSASGSASGSASTLVHNGTSARATTTPASKSTPFSIPSHHSDTPTTLASHSTKTDASSTHHSSVPPLTSSNHSTSPQLSTGVSFFFLSFHISNLQFNSSLEDPSTDYYQELQRDISEMFLQIYKQGGFLGLSNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGAGVPGWGIALLVLVCVLVALAIVYLIALAVCQCRRKNYGQLDIFPARDTYHPMSEYPTYHTHGRYVPPSSTDRSPYEKVSAGNGGSSLSYTNPAVAAASANL(SEQ ID NO:1)
PSMGFR
GTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGA(SEQ ID NO:2)
人NME1
(DNA)
atggccaactgtgagcgtaccttcattgcgatcaaaccagatggggtccagcggggtcttgtgggagagattatcaagcgttttgagcagaaaggattccgccttgttggtctgaaattcatgcaagcttccgaagatcttctcaaggaacactacgttgacctgaaggaccgtccattctttgccggcctggtgaaatacatgcactcagggccggtagttgccatggtctgggaggggctgaatgtggtgaagacgggccgagtcatgctcggggagaccaaccctgcagactccaagcctgggaccatccgtggagacttctgcatacaagttggcaggaacattatacatggcagtgattctgtggagagtgcagagaaggagatcggcttgtggtttcaccctgaggaactggtagattacacgagctgtgctcagaactggatctatgaatga(SEQ IDNO:3)
(氨基酸)
MANCERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVGLKFMQASEDLLKEHYVDLKDRPFFAGLVKYMHSGPVVAMVWEGLNVVKTGRVMLGETNPADSKPGTIRGDFCIQVGRNIIHGSDSVESAEKEIGLWFHPEELVDYTSCAQNWIYE-(SEQ ID NO:4)
人NME7
(DNA)
atgaatcatagtgaaagattcgttttcattgcagagtggtatgatccaaatgcttcacttcttcgacgttatgagcttttattttacccaggggatggatctgttgaaatgcatgatgtaaagaatcatcgcacctttttaaagcggaccaaatatgataacctgcacttggaagatttatttataggcaacaaagtgaatgtcttttctcgacaactggtattaattgactatggggatcaatatacagctcgccagctgggcagtaggaaagaaaaaacgctagccctaattaaaccagatgcaatatcaaaggctggagaaataattgaaataataaacaaagctggatttactataaccaaactcaaaatgatgatgctttcaaggaaagaagcattggattttcatgtagatcaccagtcaagaccctttttcaatgagctgatccagtttattacaactggtcctattattgccatggagattttaagagatgatgctatatgtgaatggaaaagactgctgggacctgcaaactctggagtggcacgcacagatgcttctgaaagcattagagccctctttggaacagatggcataagaaatgcagcgcatggccctgattcttttgcttctgcggccagagaaatggagttgttttttccttcaagtggaggttgtgggccggcaaacactgctaaatttactaattgtacctgttgcattgttaaaccccatgctgtcagtgaaggactgttgggaaagatcctgatggctatccgagatgcaggttttgaaatctcagctatgcagatgttcaatatggatcgggttaatgttgaggaattctatgaagtttataaaggagtagtgaccgaatatcatgacatggtgacagaaatgtattctggcccttgtgtagcaatggagattcaacagaataatgctacaaagacatttcgagaattttgtggacctgctgatcctgaaattgcccggcatttacgccctggaactctcagagcaatctttggtaaaactaagatccagaatgctgttcactgtactgatctgccagaggatggcctattagaggttcaatacttcttcaagatcttggataattag(SEQ ID NO:5)
(氨基酸)
MNHSERFVFIAEWYDPNASLLRRYELLFYPGDGSVEMHDVKNHRTFLKRTKYDNLHLEDLFIGNKVNVFSRQLVLIDYGDQYTARQLGSRKEKTLALIKPDAISKAGEIIEIINKAGFTITKLKMMMLSRKEALDFHVDHQSRPFFNELIQFITTGPIIAMEILRDDAICEWKRLLGPANSGVARTDASESIRALFGTDGIRNAAHGPDSFASAAREMELFFPSSGGCGPANTAKFTNCTCCIVKPHAVSEGLLGKILMAIRDAGFEISAMQMFNMDRVNVEEFYEVYKGVVTEYHDMVTEMYSGPCVAMEIQQNNATKTFREFCGPADPEIARHLRPGTLRAIFGKTKIQNAVHCTDLPEDGLLEVQYFFKILDN-(SEQ ID NO:6)
NME7肽
NME7A肽1(A结构域):MLSRKEALDFHVDHQS(SEQ ID NO:7)
NME7A肽2(A结构域):SGVARTDASES(SEQ ID NO:8)
NME7B肽1(B结构域):DAGFEISAMQMFNMDRVNVE(SEQ ID NO:9)
NME7B肽2(B结构域):EVYKGVVTEYHDMVTE(SEQ ID NO:10)
NME7B肽3(B结构域):AIFGKTKIQNAVHCTDLPEDGLLEVQYFF(SEQ ID NO:11)
小鼠E6重链可变区序列:
(DNA)
gaggtgaaggtggtggagtctgggggagacttagtgaagcctggagggtccctgaaactctcctgtgtagtctctggattcactttcagtagatatggcatgtcttgggttcgccagactccaggcaagaggctggagtgggtcgcaaccattagtggtggcggtacttacatctactatccagacagtgtgaaggggcgattcaccatctccagagacaatgccaagaacaccctgtacctgcaaatgagcagtctgaagtctgaggacacagccatgtatcactgtacaagggataactacggtaggaactacgactacggtatggactactggggtcaaggaacctcagtcaccgtctcctca(SEQ ID NO:12)
(氨基酸)
EVKVVESGGDLVKPGGSLKLSCVVSGFTFSRYGMSWVRQTPGKRLEWVATISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMSSLKSEDTAMYHCTRDNYGRNYDYGMDYWGQGTSVTVSS(SEQ ID NO:13)
小鼠E6重链可变框架区1(FWR1)序列:
(DNA)
gaggtgaaggtggtggagtctgggggagacttagtgaagcctggagggtccctgaaactctcctgtgtagtctct(SEQ ID NO:14)
(氨基酸)
EVKVVESGGDLVKPGGSLKLSCVVSGFTFS(SEQ ID NO:15)
小鼠E6重链可变互补决定区1(CDR1)序列:
(DNA)
ggattcactttcagtagatatggcatgtct(SEQ ID NO:16)
(氨基酸)
RYGMS(SEQ ID NO:17)
小鼠E6重链可变框架区2(FWR2)序列:
(DNA)
tgggttcgccagactccaggcaagaggctggagtgggtcgca(SEQ ID NO:18)
(氨基酸)
WVRQTPGKRLEWVA(SEQ ID NO:19)
小鼠E6重链可变互补决定区2(CDR2)序列:
(DNA)
accattagtggtggcggtacttacatctactatccagacagtgtgaagggg(SEQ ID NO:20)
(氨基酸)
TISGGGTYIYYPDSVKG(SEQ ID NO:21)
小鼠E6重链可变框架区3(FWR3)acid序列:
(DNA)
cgattcaccatctccagagacaatgccaagaacaccctgtacctgcaaatgagcagtctgaagtctgaggacacagccatgtatcactgtacaagg(SEQ ID NO:22)
(氨基酸)
RFTISRDNAKNTLYLQMSSLKSEDTAMYHCTR(SEQ ID NO:23)
小鼠E6重链可变互补决定区3(CDR3)序列:
(DNA)
gataactacggtaggaactacgactacggtatggactac(SEQ ID NO:24)
(氨基酸)
DNYGRNYDYGMDY(SEQ ID NO:25)
IGHV3-21*03重链可变区序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtagctatagcatgaactgggtccgccaggctccagggaaggggctggagtgggtctcatccattagtagtagtagtagttacatatactacgcagactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtgcgaga(SEQ ID NO:26)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYSMNWVRQAPGKGLEWVSSISSSSSYIYYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAR(SEQ ID NO:27)
IGHV3-21*01重链可变框架区1(FWR1)序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagt(SEQ ID NO:28)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFS(SEQ ID NO:29)
IGHV3-21*01重链可变互补决定区1(CDR1)序列:
(DNA)
agctatagcatgaac(SEQ ID NO:30)
(氨基酸)
SYSMN(SEQ ID NO:31)
IGHV3-21*01重链可变框架区2(FWR2)序列:
(DNA)
tgggtccgccaggctccagggaaggggctggagtgggtctca(SEQ ID NO:32)
(氨基酸)
WVRQAPGKGLEWVS(SEQ ID NO:33)
IGHV3-21*01重链可变互补决定区2(CDR2)序列:
(DNA)
tccattagtagtagtagtagttacatatactacgcagactcagtgaagggc(SEQ ID NO:34)
(氨基酸)
SISSSSSYIYYADSVKG(SEQ ID NO:35)
IGHV3-21*01重链可变框架区3(FWR3)序列:
(DNA)
cgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtgcgaga(SEQ ID NO:36)
(氨基酸)
RFTISRDNAKNSLYLQMNSLRAEDTAVYYCAR(SEQ ID NO:37)
人源化E6重链可变区序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtaggtatggcatgagctgggtccgccaggctccagggaagaggctggagtgggtctcaaccattagtggcggaggcacctacatatactacccagactcagtgaagggccgattcaccatctccagagacaacgccaagaacaccctgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtaccagagataactatggccgcaactatgattatggcatggattattggggccagggcaccctggtgaccgtgagcagc(SEQ ID NO:38)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSS(SEQ ID NO:39)
人源化E6重链可变框架区1(FWR1)acid序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagt(SEQ ID NO:40)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFS(SEQ ID NO:41)
人源化E6重链可变互补决定区1(CDR1)序列:
(DNA)
aggtatggcatgagc(SEQ ID NO:42)
(氨基酸)
RYGMS(SEQ ID NO:43)
人源化E6重链可变框架区2(FWR2)酸序列:
(DNA)
tgggtccgccaggctccagggaagaggctggagtgggtctca(SEQ ID NO:44)
(氨基酸)
WVRQAPGKRLEWVS(SEQ ID NO:45)
人源化E6重链可变互补决定区2(CDR2)序列:
(DNA)
accattagtggcggaggcacctacatatactacccagactcagtgaagggc(SEQ ID NO:46)
(氨基酸)
TISGGGTYIYYPDSVKG(SEQ ID NO:47)
人源化E6重链可变框架区3(FWR3)酸序列:
(DNA)
cgattcaccatctccagagacaacgccaagaacaccctgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtaccaga(SEQ ID NO:48)
(氨基酸)
RFTISRDNAKNTLYLQMNSLRAEDTAVYYCTR(SEQ ID NO:49)
人源化E6重链可变互补决定区3(CDR3)序列:
(DNA)
gataactatggccgcaactatgattatggcatggattat(SEQ ID NO:50)
(氨基酸)
DNYGRNYDYGMDY(SEQ ID NO:51)
人源化E6 IgG2重链(由Genescript合成):
(DNA)
gaattctaagcttgggccaccatggaactggggctccgctgggttttccttgttgctattttagaaggtgtccagtgtgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtaggtatggcatgagctgggtccgccaggctccagggaagaggctggagtgggtctcaaccattagtggcggaggcacctacatatactacccagactcagtgaagggccgattcaccatctccagagacaacgccaagaacaccctgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtaccagagataactatggccgcaactatgattatggcatggattattggggccagggcaccctggtgaccgtgagcagcgcctccaccaagggcccatcggtcttccccctggcgccctgctccaggagcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgctctgaccagcggcgtgcacaccttcccagctgtcctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcaacttcggcacccagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaagacagttgagcgcaaatgttgtgtcgagtgcccaccgtgcccagcaccacctgtggcaggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacgtgcgtggtggtggacgtgagccacgaagaccccgaggtccagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccacgggaggagcagttcaacagcacgttccgtgtggtcagcgtcctcaccgttgtgcaccaggactggctgaacggcaaggagtacaagtgcaaggtctccaacaaaggcctcccagcccccatcgagaaaaccatctccaaaaccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctaccccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacacctcccatgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatagtaagtttaaactctaga(SEQ ID NO:52)
(氨基酸)
EF*AWATMELGLRWVFLVAILEGVQCEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSNFGTQTYTCNVDHKPSNTKVDKTVERKCCVECPPCPAPPVAGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTFRVVSVLTVVHQDWLNGKEYKCKVSNKGLPAPIEKTISKTKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPMLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**V*TLX(SEQ ID NO:53)
人IgG2重链恒定区序列:
(DNA)
gcctccaccaagggcccatcggtcttccccctggcgccctgctccaggagcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgctctgaccagcggcgtgcacaccttcccagctgtcctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcaacttcggcacccagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaagacagttgagcgcaaatgttgtgtcgagtgcccaccgtgcccagcaccacctgtggcaggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacgtgcgtggtggtggacgtgagccacgaagaccccgaggtccagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccacgggaggagcagttcaacagcacgttccgtgtggtcagcgtcctcaccgttgtgcaccaggactggctgaacggcaaggagtacaagtgcaaggtctccaacaaaggcctcccagcccccatcgagaaaaccatctccaaaaccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctaccccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacacctcccatgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatag(SEQ ID NO:54)
(氨基酸)
ASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSNFGTQTYTCNVDHKPSNTKVDKTVERKCCVECPPCPAPPVAGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTFRVVSVLTVVHQDWLNGKEYKCKVSNKGLPAPIEKTISKTKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPMLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQ ID NO:55)
人源化E6 IgG1重链序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtaggtatggcatgagctgggtccgccaggctccagggaagaggctggagtgggtctcaaccattagtggcggaggcacctacatatactacccagactcagtgaagggccgattcaccatctccagagacaacgccaagaacccactgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtcccagagataactatggccgcaactatgattatggcatggattattggggccagggcaccctggtgaccgtgagcagcgctagcaccaagggcccatcggtcttccccctggcaccctcctccaagagcacctctgggggcacagcggccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtcctacagtcctcaggactctactccctcagcagcgtggtgacagtgccctccagcagcttgggcacccagacctacatctgcaacgtgaatcacaagcccagcaacaccaaggtggacaagaaagttgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:56)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNPLYLQMNSLRAEDTAVYYCPRDNYGRNYDYGMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:57)
人IgG1重链恒定区序列:
(DNA)
gctagcaccaagggcccatcggtcttccccctggcaccctcctccaagagcacctctgggggcacagcggccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtcctacagtcctcaggactctactccctcagcagcgtggtgacagtgccctccagcagcttgggcacccagacctacatctgcaacgtgaatcacaagcccagcaacaccaaggtggacaagaaagttgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:58)
(氨基酸)
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:59)
人IgG1重链恒定区gBLOCK#1序列:
(DNA)
atggcatggattattggggccagggcaccctggtgaccgtgagcagcgctagcaccaagggcccatcggtcttccccctggcaccctcctccaagagcacctctgggggcacagcggccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtcctacagtcctcaggactctactccctcagcagcgtggtgacagtgccctccagcagcttgggcacccagacctacatctgcaacgtgaatcacaagcccagcaacaccaaggtggacaagaaagttgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaag(SEQ ID NO:60)
人IgG1重链恒定区gBLOCK#2序列:
(DNA)
tacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataagtttaaacccgctgatcagcctcgactgtgccttctagttg(SEQ ID NO:61)
E6重链可变区重叠序列:
(DNA)
atggcatggattattggggccagggcaccct(SEQ ID NO:62)
IgG1重链恒定区重叠区序列:
(DNA)
tacgtggacggcgtggaggtgcataatgccaag(SEQ ID NO:63)
pCDNA3.1 V5和pSECTag2重叠序列:
(DNA)
ccgctgatcagcctcgactgtgccttctagttg(SEQ ID NO:64)
小鼠E6轻链可变区序列:
(DNA)
caaattgttctcacccagtctccagcaatcatgtctgcatctccaggggaggaggtcaccctaacctgcagtgccacctcaagtgtaagttacatacactggttccagcagaggccaggcacttctcccaaactctggatttatagcacatccaacctggcttctggagtccctgttcgcttcagtggcagtggatatgggacctcttactctctcacaatcagccgaatggaggctgaagatgctgccacttattactgccagcaaaggagtagttccccattcacgttcggctcggggacaaagttggaaataaaa(SEQ ID NO:65)
(氨基酸)
QIVLTQSPAIMSASPGEEVTLTCSATSSVSYIHWFQQRPGTSPKLWIYSTSNLASGVPVRFSGSGYGTSYSLTISRMEAEDAATYYCQQRSSSPFTFGSGTKLEIK(SEQ ID NO:66)
小鼠E6轻链可变框架区1(FWR1)序列:
(DNA)
caaattgttctcacccagtctccagcaatcatgtctgcatctccaggggaggaggtcaccctaacctgc(SEQ ID NO:67)
(氨基酸)
QIVLTQSPAIMSASPGEEVTLTC(SEQ ID NO:68)
小鼠E6轻链可变互补决定区1(CDR1)序列:
(DNA)
AGTGCCACCTCAAGTGTAAGTTACATACAC(SEQ ID NO:69)
(氨基酸)
SATSSVSYIH(SEQ ID NO:70)
小鼠E6轻链可变框架区2(FWR2)序列:
(DNA)
tggttccagcagaggccaggcacttctcccaaactctggatttat(SEQ ID NO:71)
(氨基酸)
WFQQRPGTSPKLWIY(SEQ ID NO:72)
小鼠E6轻链可变互补决定区2(CDR2)序列:
(DNA)
agcacatccaacctggcttct(SEQ ID NO:73)
(氨基酸)
STSNLAS(SEQ ID NO:74)
小鼠E6轻链可变框架区3(FWR3)序列:
(DNA)
ggagtccctgttcgcttcagtggcagtggatatgggacctcttactctctcacaatcagccgaatggaggctgaagatgctgccacttattactgc(SEQ ID NO:75)
(氨基酸)
GVPVRFSGSGYGTSYSLTISRMEAEDAATYYC(SEQ ID NO:76)
小鼠E6轻链可变互补决定区3(CDR3)序列:
(DNA)
cagcaaaggagtagttccccattcacg(SEQ ID NO:77)
(氨基酸)
QQRSSSPFT(SEQ ID NO:78)
IGKV3-11*02轻链可变区序列:
(DNA)
gaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctctcctgcagggccagtcagagtgttagcagctacttagcctggtaccaacagaaacctggccaggctcccaggctcctcatctatgatgcatccaacagggccactggcatcccagccaggttcagtggcagtgggtctgggagagacttcactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcaactggcctcc(SEQ ID NO:79)
(氨基酸)
EIVLTQSPATLSLSPGERATLSCRASQSVSSYLAWYQQKPGQAPRLLIYDASNRATGIPARFSGSGSGRDFTLTISSLEPEDFAVYYCQQRSNWPP(SEQ ID NO:80)
IGKV3-11*02轻链可变框架区1(FWR1)酸序列:
(DNA)
gaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctctcctgc(SEQ ID NO:81)
(氨基酸)
EIVLTQSPATLSLSPGERATLSC(SEQ ID NO:82)
IGKV3-11*02轻链可变互补决定区1(CDR1)序列:
(DNA)
agggccagtcagagtgttagcagctacttagcc(SEQ ID NO:83)
(氨基酸)
RASQSVSSYLA(SEQ ID NO:84)
IGKV3-11*02轻链可变框架区2(FWR2)序列:
(DNA)
tggtaccaacagaaacctggccaggctcccaggctcctcatctat(SEQ ID NO:85)
(氨基酸)
WYQQKPGQAPRLLIY(SEQ ID NO86)
IGKV3-11*02轻链可变互补决定区2(CDR2)序列:
(DNA)
gatgcatccaacagggccact(SEQ ID NO:87)
(氨基酸)
DASNRAT(SEQ ID NO:88)
IGKV3-11*02轻链可变框架区3(FWR3)序列:
(DNA)
ggcatcccagccaggttcagtggcagtgggtctgggagagacttcactctcaccatcagcagcctagagcctgaagattttgcagtttattactgt(SEQ ID NO:89)
(氨基酸)
GIPARFSGSGSGTDFTLTISSLEPEDFAVYYC(SEQ ID NO:90)
IGKV3-11*02轻链可变互补决定区3(CDR3)序列:
(DNA)
cagcagcgtagcaactggcctcc(SEQ ID NO:91)
(氨基酸)
QQRSNWPP(SEQ ID NO:92)
人源化E6轻链可变区序列:
(DNA)
gaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctcacctgcagcgccaccagcagtgttagctacatccactggtaccaacagaggcctggccagagccccaggctcctcatctatagcacctccaacctggccagcggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcagctcccctttcacctttggcagcggcaccaaagtggaaattaaa(SEQ ID NO:93)
(氨基酸)
EIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIK(SEQ ID NO:94)
人源化E6轻链可变框架区1(FWR1)酸序列:
(DNA)
gaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctcacctgc(SEQ ID NO:95)
(氨基酸)
EIVLTQSPATLSLSPGERATLTC(SEQ ID NO:96)
人源化E6轻链可变互补决定区1(CDR1)序列:
(DNA)
agcgccaccagcagtgttagctacatccac(SEQ ID NO:97)
(氨基酸)
SATSSVSYIH(SEQ ID NO:98)
人源化E6重链可变框架区2(FWR2)酸序列:
(DNA)
tggtaccaacagaggcctggccagagccccaggctcctcatctat(SEQ ID NO:99)
(氨基酸)
WYQQRPGQSPRLLIY(SEQ ID NO:100)
人源化E6轻链可变互补决定区2(CDR2)序列:
(DNA)
agcacctccaacctggccagc(SEQ ID NO:101)
(氨基酸)
STSNLAS(SEQ ID NO:102)
人源化E6轻链可变框架区3(FWR3)酸序列:
(DNA)
ggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgt(SEQ ID NO:103)
(氨基酸)
GIPARFSGSGSGSDYTLTISSLEPEDFAVYYC(SEQ ID NO:104)
人源化E6轻链可变互补决定区3(CDR3)序列:
(DNA)
cagcagcgtagcagctcccctttcacc(SEQ ID NO:105)
(氨基酸)
QQRSSSPFT(SEQ ID NO:106)
人源化E6κ轻链(由Genescript合成):
(DNA)
gaattctaagcttgggccaccatggaagccccagcgcagcttctcttcctcctgctactctggctcccagataccactggagaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctcacctgcagcgccaccagcagtgttagctacatccactggtaccaacagaggcctggccagagccccaggctcctcatctatagcacctccaacctggccagcggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcagctcccctttcacctttggcagcggcaccaaagtggaaattaaaaggacggtggctgcaccatctgtcttcatcttcccgccatctgatgagcagttgaaatctggaactgcctctgttgtgtgcctgctgaataacttctatcccagagaggccaaagtacagtggaaggtggataacgccctccaatcgggtaactcccaggagagtgtcacagagcaggacagcaaggacagcacctacagcctcagcagcaccctgacgctgagcaaagcagactacgagaaacacaaagtctacgcctgcgaagtcacccatcagggcctgagctcgcccgtcacaaagagcttcaacaggggagagtgttagtaagtttaaactctaga(SEQ ID NO:107)
(氨基酸)
EF*AWATMEAPAQLLFLLLLWLPDTTGEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC**V*TLX(SEQ ID NO:108)
人κ轻链恒定区序列:
(DNA)
aggacggtggctgcaccatctgtcttcatcttcccgccatctgatgagcagttgaaatctggaactgcctctgttgtgtgcctgctgaataacttctatcccagagaggccaaagtacagtggaaggtggataacgccctccaatcgggtaactcccaggagagtgtcacagagcaggacagcaaggacagcacctacagcctcagcagcaccctgacgctgagcaaagcagactacgagaaacacaaagtctacgcctgcgaagtcacccatcagggcctgagctcgcccgtcacaaagagcttcaacaggggagagtgttag(SEQ ID NO:109)
(氨基酸)
RTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC(SEQ ID NO:110)
人源化E6λ轻链序列:
(DNA)
gaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctcacctgcagcgccaccagcagtgttagctacatccactggtaccaacagaggcctggccagagccccaggctcctcatctatagcacctccaacctggccagcggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcagctcccctttcacctttggcagcggcaccaaagtggaaattaaaggtcagcccaaggctgccccctcggtcactctgttcccgccctcctctgaggagcttcaagccaacaaggccacactggtgtgtctcataagtgacttctacccgggagccgtgacagtggcctggaaggcagatagcagccccgtcaaggcgggagtggagaccaccacaccctccaaacaaagcaacaacaagtacgcggccagcagctatctgagcctgacgcctgagcagtggaagtcccacagaagctacagctgccaggtcacgcatgaagggagcaccgtggagaagacagtggcccctacagaatgttcatagtaa(SEQ ID NO:111)
(氨基酸)
EIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKADSSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGSTVEKTVAPTECS**(SEQ ID NO:112)
人源化λ轻链恒定区序列:
(DNA)
ggtcagcccaaggctgccccctcggtcactctgttcccgccctcctctgaggagcttcaagccaacaaggccacactggtgtgtctcataagtgacttctacccgggagccgtgacagtggcctggaaggcagatagcagccccgtcaaggcgggagtggagaccaccacaccctccaaacaaagcaacaacaagtacgcggccagcagctatctgagcctgacgcctgagcagtggaagtcccacagaagctacagctgccaggtcacgcatgaagggagcaccgtggagaagacagtggcccctacagaatgttcatagtaa(SEQ ID NO:113)
(氨基酸)
GQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKADSSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGSTVEKTVAPTECS**(SEQ ID NO:114)
人λ轻链恒定区gBLOCK#3序列:
(DNA)
agcgccaccagcagtgttagctacatccactggtaccaacagaggcctggccagagccccaggctcctcatctatagcacctccaacctggccagcggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcagctcccctttcacctttggcagcggcaccaaagtggaaattaaaggtcagcccaaggctgccccctcggtcactctgttcccgccctcctctgaggagcttcaagccaacaaggccacactggtgtgtctcataagtgacttctacccgggagccgtgacagtggcctggaaggcagatagcagccccgtcaaggcgggagtggagaccaccacaccctccaaacaaagcaacaacaagtacgcggccagcagctatctgagcctgacgcctgagcagtggaagtcccacagaagctacagctgccaggtcacgcatgaagggagcaccgtggagaagacagtggcccctacagaatgttcatagtaagtttaaacccgctgatcagcctcgactgtgccttctagttg(SEQ ID NO:115)
E6轻链可变区重叠序列:
(DNA)
agcgccaccagcagtgttagctacatccact(SEQ ID NO:116)
pCDNA3.1 V5和pSECTag2重叠序列:
(DNA)
ccgctgatcagcctcgactgtgccttctagttg(SEQ ID NO:117)
小鼠C2重链可变区序列:
(DNA)
gaggtccagctggaggagtcagggggaggcttagtgaagcctggagggtccctgaaactctcctgtgcagcctctggattcactttcagtggctatgccatgtcttgggttcgccagactccggagaagaggctggagtgggtcgcaaccattagtagtggtggtacttatatctactatccagacagtgtgaaggggcgattcaccatctccagagacaatgccaagaacaccctgtacctgcaaatgagcagtctgaggtctgaggacacggccatgtattactgtgcaagacttgggggggataattactacgaatacttcgatgtctggggcgcagggaccacggtcaccgtctcctccgccaaaacgacacccccatctgtctat(SEQ ID NO:118)
(氨基酸)
EVQLEESGGGLVKPGGSLKLSCAASGFTFSGYAMSWVRQTPEKRLEWVATISSGGTYIYYPDSVKGRFTISRDNAKNTLYLQMSSLRSEDTAMYYCARLGGDNYYEYFDVWGAGTTVTVSSAKTTPPSVY(SEQ ID NO:119)
小鼠C2重链可变框架区1(FWR1)序列:
(DNA)
gaggtccagctggaggagtcagggggaggcttagtgaagcctggagggtccctgaaactctcctgtgcagcctctggattcactttcagt(SEQ ID NO:120)
(氨基酸)
EVQLEESGGGLVKPGGSLKLSCAASGFTFS(SEQ ID NO:121)
小鼠C2重链可变互补决定区1(CDR1)序列:
(DNA)
ggctatgccatgtct(SEQ ID NO:122)
(氨基酸)
GYAMS(SEQ ID NO:123)
小鼠C2重链可变框架区2(FWR2)序列:
(DNA)
tgggttcgccagactccggagaagaggctggagtgggtcgca(SEQ ID NO:124)
(氨基酸)
WVRQTPEKRLEWVA(SEQ ID NO:125)
小鼠C2重链可变互补决定区2(CDR2)序列:
(DNA)
accattagtagtggtggtacttatatctactatccagacagtgtgaagggg(SEQ ID NO:126)
(氨基酸)
TISSGGTYIYYPDSVKG(SEQ ID NO:127)
小鼠C2重链可变框架区3(FWR3)序列:
(DNA)
cgattcaccatctccagagacaatgccaagaacaccctgtacctgcaaatgagcagtctgaggtctgaggacacggccatgtattactgtgcaaga(SEQ ID NO:128)
(氨基酸)
RFTISRDNAKNTLYLQMSSLRSEDTAMYYCAR(SEQ ID NO:129)
小鼠C2重链可变互补决定区3(CDR3)序列:
(DNA)
cttgggggggataattactacgaatacttcgatgtc(SEQ ID NO:130)
(氨基酸)
LGGDNYYEYFDV(SEQ ID NO:131)
IGHV3-21*04重链可变区序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtagctatagcatgaactgggtccgccaggctccagggaaggggctggagtgggtctcatccattagtagtagtagtagttacatatactacgcagactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgaga(SEQ ID NO:132)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYSMNWVRQAPGKGLEWVSSISSSSSYIYYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAR(SEQ ID NO:133)
IGHV3-21*04重链可变框架区1(FWR1)序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagt(SEQ ID NO:134)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFS(SEQ ID NO:135)
IGHV3-21*04重链可变互补决定区1(CDR1)序列:
(DNA)
agctatagcatgaac(SEQ ID NO:136)
(氨基酸)
SYSMN(SEQ ID NO:137)
IGHV3-21*04重链可变框架区2(FWR2)序列:
(DNA)
gggtccgccaggctccagggaaggggctggagtgggtctca(SEQ ID NO:138)
(氨基酸)
WVRQAPGKGLEWVS(SEQ ID NO:139)
IGHV3-21*04重链可变互补决定区2(CDR2)序列:
(DNA)
tccattagtagtagtagtagttacatatactacgcagactcagtgaagggc(SEQ ID NO:140)
(氨基酸)
SISSSSSYIYYADSVKG(SEQ ID NO:141)
IGHV3-21*04重链可变框架区3(FWR3)序列:
(DNA)
cgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgaga(SEQ ID NO:142)
(氨基酸)
RFTISRDNAKNSLYLQMNSLRAEDTAVYYCAR(SEQ ID NO:143)
人源化C2重链可变区序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctcc(SEQID NO:144)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSS(SEQ ID NO:145)
人源化C2重链可变框架区1(FWR1)序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagt(SEQ ID NO:146)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFS(SEQ ID NO:147)
人源化C2重链可变互补决定区1(CDR1)序列:
(DNA)
ggctatgccatgagc(SEQ ID NO:148)
(氨基酸)
GYAMS(SEQ ID NO:149)
人源化C2重链可变框架区2(FWR2)序列:
(DNA)
tgggtccgccaggctccagggaaggggctggagtgggtctcaa(SEQ ID NO:150)
(氨基酸)
WVRQAPGKGLEWVS(SEQ ID NO:151)
人源化C2重链可变互补决定区2(CDR2)序列:
(DNA)
accattagtagtggcggaacctacatatactaccccgactcagtgaagggc(SEQ ID NO:152)
(氨基酸)
TISSGGTYIYYPDSVKG(SEQ ID NO:153)
人源化C2重链可变框架区3(FWR3)序列:
(DNA)
cgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgaga(SEQ ID NO:154)
(氨基酸)
RFTISRDNAKNSLYLQMNSLRAEDTAVYYCAR(SEQ ID NO:155)
人源化C2重链可变互补决定区3(CDR3)序列:
(DNA)
cttgggggggataattactacgaatacttcgatgtc(SEQ ID NO:156)
(氨基酸)
LGGDNYYEYFDV(SEQ ID NO:157)
人源化C2IgG1重链序列
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccgctagcaccaagggcccatcggtcttccccctggcaccctcctccaagagcacctctgggggcacagcggccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtcctacagtcctcaggactctactccctcagcagcgtggtgacagtgccctccagcagcttgggcacccagacctacatctgcaacgtgaatcacaagcccagcaacaccaaggtggacaagaaagttgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:157)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:158)
人源化C2 gBLOCK#4序列:
(DNA)
actcactatagggagacccaagctggctagttaagcttgggccaccatggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgacgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccgctagcaccaagggcccatcggtcttccccctggcaccctcctccaagagcacctctgggggcacagcggccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgccctgaccagc(SEQ ID NO:160)
pCDNA3.1 V5重叠序列:
(DNA)
actcactatagggagacccaagctggctagtt(SEQ ID NO:161)
人IgG1恒定区重叠序列:
(DNA)
gacggtgtcgtggaactcaggcgccctgaccagc(SEQ ID NO:162)
人源化C2 IgG2重链序列
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccgcctccaccaagggcccatcggtcttccccctggcgccctgctccaggagcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgctctgaccagcggcgtgcacaccttcccagctgtcctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcaacttcggcacccagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaagacagttgagcgcaaatgttgtgtcgagtgcccaccgtgcccagcaccacctgtggcaggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacgtgcgtggtggtggacgtgagccacgaagaccccgaggtccagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccacgggaggagcagttcaacagcacgttccgtgtggtcagcgtcctcaccgttgtgcaccaggactggctgaacggcaaggagtacaagtgcaaggtctccaacaaaggcctcccagcccccatcgagaaaaccatctccaaaaccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctaccccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacacctcccatgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatagtaa(SEQ ID NO:163)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSNFGTQTYTCNVDHKPSNTKVDKTVERKCCVECPPCPAPPVAGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTFRVVSVLTVVHQDWLNGKEYKCKVSNKGLPAPIEKTISKTKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPMLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:164)
人源化C2 gBLOCK#5序列:
(DNA)
tgctctgggttccaggttccactggtgacgcggcccagccggccgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccgcctccaccaagggcccatcggtcttccccctggcgccctgctccaggagcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgctctgacca(SEQ ID NO:165)
pSEC Tag2重叠序列:
(DNA)
tgctctgggttccaggttccactggtgacgc(SEQ ID NO:166)
人IgG2恒定区重叠序列:
(DNA)
gacggtgtcgtggaactcaggcgctctgacca(SEQ ID NO:167)
小鼠C2轻链可变区序列:
(DNA)
gacattgtgatcacacagtctacagcttccttaggtgtatctctggggcagagggccaccatctcatgcagggccagcaaaagtgtcagtacatctggctatagttatatgcactggtaccaacagagaccaggacagccacccaaactcctcatctatcttgcatccaacctagaatctggggtccctgccaggttcagtggcagtgggtctgggacagacttcaccctcaacatccatcctgtggaggaggaggatgctgcaacctattactgtcagcacagtagggagcttccgttcacgttcggaggggggaccaagctggagataaaacgggctgatgctgcaccaactgtatcc(SEQ ID NO:168)
(氨基酸)
DIVITQSTASLGVSLGQRATISCRASKSVSTSGYSYMHWYQQRPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLNIHPVEEEDAATYYCQHSRELPFTFGGGTKLEIKRADAAPTVS(SEQ ID NO:169)
小鼠C2轻链可变框架区1(FWR1)序列:
(DNA)
gacattgtgatcacacagtctacagcttccttaggtgtatctctggggcagagggccaccatctcatgc(SEQ ID NO:170)
(氨基酸)
DIVITQSTASLGVSLGQRATISC(SEQ ID NO:171)
小鼠C2轻链可变互补决定区1(CDR1)序列:
(DNA)
agggccagcaaaagtgtcagtacatctggctatagttatatgcac(SEQ ID NO:172)
(氨基酸)
RASKSVSTSGYSYMH(SEQ ID NO:173)
小鼠C2轻链可变框架区2(FWR2)序列:
(DNA)
tggtaccaacagagaccaggacagccacccaaactcctcatctat(SEQ ID NO:174)
(氨基酸)
WYQQRPGQPPKLLIY(SEQ ID NO:175)
小鼠C2轻链可变互补决定区2(CDR2)序列:
(DNA)
cttgcatccaacctagaatc(SEQ ID NO:176)
(氨基酸)
LASNLES(SEQ ID NO:177)
小鼠C2轻链可变框架区3(FWR3)序列:
(DNA)
tggggtccctgccaggttcagtggcagtgggtctgggacagacttcaccctcaacatccatcctgtggaggaggaggatgctgcaacctattactgt(SEQ ID NO:178)
(氨基酸)
GVPARFSGSGSGTDFTLNIHPVEEEDAATYYC(SEQ ID NO:179)
小鼠C2轻链可变互补决定区3(CDR3)序列:
(DNA)
cagcacagtagggagcttccgttcacg(SEQ ID NO:180)
(氨基酸)
QHSRELPFT(SEQ ID NO:181)
IGKV7-3*01轻链可变区序列:
(DNA)
gacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtgagagtgtcagtttcttgggaataaacttaattcactggtatcagcagaaaccaggacaacctcctaaactcctgatttaccaagcatccaataaagacactggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtctgcagagtaagaattttcctcccaca(SEQ ID NO:182)
(氨基酸)
DIVLTQSPASLAVSPGQRATITCRASESVSFLGINLIHWYQQKPGQPPKLLIYQASNKDTGVPARFSGSGSGTDFTLTINPVEANDTANYYCLQSKNFPPT(SEQ ID NO:183)
IGKV7-3*01轻链可变框架区1(FWR1)序列:
(DNA)
gacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgc(SEQ ID NO:184)
(氨基酸)
DIVLTQSPASLAVSPGQRATITC(SEQ ID NO:185)
IGKV7-3*01轻链可变互补决定区1(CDR1)序列:
(DNA)
agagccagtgagagtgtcagtttcttgggaataaacttaattcac(SEQ ID NO:186)
(氨基酸)
RASESVSFLGINLIH(SEQ ID NO:187)
IGKV7-3*01轻链可变框架区2(FWR2)序列:
(DNA)
tggtatcagcagaaaccaggacaacctcctaaactcctgatttac(SEQ ID NO:188)
(氨基酸)
WYQQKPGQPPKLLIY(SEQ ID NO:189)
IGKV7-3*01轻链可变互补决定区2(CDR2)序列:
(DNA)
caagcatccaataaagacact(SEQ ID NO:190)
(氨基酸)
QASNKDT(SEQ ID NO:191)
IGKV7-3*01轻链可变框架区3(FWR3)序列:
(DNA)
ggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgt(SEQ ID NO:192)
(氨基酸)
GVPARFSGSGSGTDFTLTINPVEANDTANYYC(SEQ ID NO:193)
人源化C2轻链可变区序列:
(DNA)
gacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaact(SEQ ID NO:194)
(氨基酸)
DIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRT(SEQ IDNO:195)
人源化C2轻链可变框架区1(FWR1)酸序列:
(DNA)
gacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgc(SEQ ID NO:196)
(氨基酸)
DIVLTQSPASLAVSPGQRATITC(SEQ ID NO:197)
人源化C2轻链可变互补决定区1(CDR1)序列:
(DNA)
agagccagtaagagtgtcagtaccagcggatactcctacatgcac(SEQ ID NO:198)
(氨基酸)
RASKSVSTSGYSYMH(SEQ ID NO:199)
人源化C2重链可变框架区2(FWR2)酸序列:
(DNA)
tggtatcagcagaaaccaggacaacctcctaaactcctgatttac(SEQ ID NO:200)
(氨基酸)
WYQQKPGQPPKLLIY(SEQ ID NO:201)
人源化C2轻链可变互补决定区2(CDR2)序列:
(DNA)
ctggcatccaatctggagagc(SEQ ID NO:202)
(氨基酸)
LASNLES(SEQ ID NO:203)
人源化C2轻链可变框架区3(FWR3)酸序列:
(DNA)
ggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgt(SEQ ID NO:204)
(氨基酸)
GVPARFSGSGSGTDFTLTINPVEANDTANYYC(SEQ ID NO:205)
人源化C2轻链可变互补决定区3(CDR3)序列:
(DNA)
cagcacagtagggagctgcctttcaca(SEQ ID NO:206)
(氨基酸)
QHSRELPFT(SEQ ID NO:207)
人源化C2轻链可变互补决定区3(CDR3)序列:
(DNA)
ctgcagagtaagaattttcctcccaca(SEQ ID NO:208)
(氨基酸)
LQSKNFPPT(SEQ ID NO:209)
人源化C2 gBLOCK#6序列(pCDNA3.1 V5中的κ轻链):
(DNA)
actcactatagggagacccaagctggctagttaagcttgggccaccatggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgacgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactacggtggctgcaccatctgtcttcatcttcccgccatctgatgagcagttgaaatctggaactgcctctgttgtgtgcctgctgaataacttctatcccagagaggccaaagtacagtggaaggtggataacgccctccaatcgggtaactcccaggagagtgtcacagagcaggacagcaaggacagcacctacagcctcagcagcaccctgacgctgagcaaagcagactacgagaaacacaaagtctacgcctgcgaagtcacccatcagggcctgagctcgcccgtcacaaagagcttcaacaggggagagtgttagtaagtttaaacccgctgatcagcctcgactgtgccttctagttg(SEQ ID NO:210)
pCDNA3.1 V5 5’重叠序列:
(DNA)
actcactatagggagacccaagctggctagtt(SEQ ID NO:211)
pCDNA3.1 V5 3’重叠序列:
(DNA)
ccgctgatcagcctcgactgtgccttctagttg(SEQ ID NO:212)
人源化C2 gBLOCK#7序列(pSEC Tag2中的κ轻链):
(DNA)
tgctctgggttccaggttccactggtgacgcggcccagccggccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactacggtggctgcaccatctgtcttcatcttcccgccatctgatgagcagttgaaatctggaactgcctctgttgtgtgcctgctgaataacttctatcccagagaggccaaagtacagtggaaggtggataacgccctccaatcgggtaactcccaggagagtgtcacagagcaggacagcaaggacagcacctacagcctcagcagcaccctgacgctgagcaaagcagactacgagaaacacaaagtctacgcctgcgaagtcacccatcagggcctgagctcgcccgtcacaaagagcttcaacaggggagagtgttagtaagtttaaacccgctgatcagcctcgactgtgccttctagttg(SEQ ID NO:213)
pSEC Tag2 5’重叠序列:
(DNA)
tgctctgggttccaggttccactggtgacgc(SEQ ID NO:214)
pSEC Tag2 3’重叠序列:
(DNA)
ccgctgatcagcctcgactgtgccttctagttg(SEQ ID NO:215)
人源化C2 gBLOCK#8序列(pCDNA3.1 V5中的λ轻链):
(DNA)
actcactatagggagacccaagctggctagttaagcttgggccaccatggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgacgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactggtcagcccaaggctgccccctcggtcactctgttcccgccctcctctgaggagcttcaagccaacaaggccacactggtgtgtctcataagtgacttctacccgggagccgtgacagtggcctggaaggcagatagcagccccgtcaaggcgggagtggagaccaccacaccctccaaacaaagcaacaacaagtacgcggccagcagctatctgagcctgacgcctgagcagtggaagtcccacagaagctacagctgccaggtcacgcatgaagggagcaccgtggagaagacagtggcccctacagaatgttcatagtaagtttaaacccgctgatcagcctcgactgtgccttctagttg(SEQ ID NO:216)
pCDNA3.1 V5 5’重叠序列:
(DNA)
actcactatagggagacccaagctggctagtt(SEQ ID NO:217)
pCDNA3.1 V5 3’重叠序列:
(DNA)
ccgctgatcagcctcgactgtgccttctagttg(SEQ ID NO:218)
人源化C2 gBLOCK#9序列(pSEC Tag2中的λ轻链):
(DNA)
tgctctgggttccaggttccactggtgacgcggcccagccggccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactggtcagcccaaggctgccccctcggtcactctgttcccgccctcctctgaggagcttcaagccaacaaggccacactggtgtgtctcataagtgacttctacccgggagccgtgacagtggcctggaaggcagatagcagccccgtcaaggcgggagtggagaccaccacaccctccaaacaaagcaacaacaagtacgcggccagcagctatctgagcctgacgcctgagcagtggaagtcccacagaagctacagctgccaggtcacgcatgaagggagcaccgtggagaagacagtggcccctacagaatgttcatagtaagtttaaacccgctgatcagcctcgactgtgccttctagttg(SEQ ID NO:219)
pSEC Tag2 5’重叠序列:
(DNA)
tgctctgggttccaggttccactggtgacgc(SEQ ID NO:220)
pSEC Tag2 3’重叠序列:
(DNA)
ccgctgatcagcctcgactgtgccttctagttg(SEQ ID NO:221)
小鼠Igκ链前导序列
(DNA)
atggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgac(SEQ ID NO:222)
(氨基酸)
METDTLLLWVLLLWVPGSTGD(SEQ ID NO:223)
白细胞介素2(IL-2)前导序列
(DNA)
atgtacaggatgcaactcctgtcttgcattgcactaagtcttgcacttgtcacaaacagt(SEQ ID NO:224)
(氨基酸)
MYRMQLLSCIALSLALVTNS(SEQ ID NO:225)
CD33前导序列
(DNA)
atgcctcttctgcttctgcttcctctgctttgggctggagctcttgct(SEQ ID NO:226)
(氨基酸)
MPLLLLLPLLWAGALA(SEQ ID NO:227)
IGHV3-21*03前导序列
(DNA)
atggaactggggctccgctgggttttccttgttgctattttagaaggtgtccagtgt(SEQ ID NO:228)
(氨基酸)
MELGLRWVFLVAILEGVQC(SEQ ID NO:229)
IGHV3-11*02前导序列
(DNA)
atggaagccccagcgcagcttctcttcctcctgctactctggctcccagataccactgga(SEQ ID NO:230)
(氨基酸)
MEAPAQLLFLLLLWLPDTTG(SEQ ID NO:231)
人源化E6单链GS3
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtaggtatggcatgagctgggtccgccaggctccagggaagaggctggagtgggtctcaaccattagtggcggaggcacctacatatactacccagactcagtgaagggccgattcaccatctccagagacaacgccaagaacaccctgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtaccagagataactatggccgcaactatgattatggcatggattattggggccagggcaccctggtgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctcacctgcagcgccaccagcagtgttagctacatccactggtaccaacagaggcctggccagagccccaggctcctcatctatagcacctccaacctggccagcggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcagctcccctttcacctttggcagcggcaccaaagtggaaattaaa(SEQ ID NO:232)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIK(SEQ ID NO:233)
人源化E6单链IgG1noC
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtaggtatggcatgagctgggtccgccaggctccagggaagaggctggagtgggtctcaaccattagtggcggaggcacctacatatactacccagactcagtgaagggccgattcaccatctccagagacaacgccaagaacaccctgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtaccagagataactatggccgcaactatgattatggcatggattattggggccagggcaccctggtgaccgtgagcagcgataaaacccatactaaaccgccaaaaccggcgccggaactgctgggtggtcctggtaccggtgaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctcacctgcagcgccaccagcagtgttagctacatccactggtaccaacagaggcctggccagagccccaggctcctcatctatagcacctccaacctggccagcggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcagctcccctttcacctttggcagcggcaccaaagtggaaattaaa(SEQ ID NO:234)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSDKTHTKPPKPAPELLGGPGTGEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIK(SEQ ID NO:235)
人源化E6单链X4(接头是IgG1和IgG2修饰铰链区)
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtaggtatggcatgagctgggtccgccaggctccagggaagaggctggagtgggtctcaaccattagtggcggaggcacctacatatactacccagactcagtgaagggccgattcaccatctccagagacaacgccaagaacaccctgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtaccagagataactatggccgcaactatgattatggcatggattattggggccagggcaccctggtgaccgtgagcagcgataaaacccatactaaaccgccaaaaccggcgccggaactgctgggtggtcctggtaccggtactggtggtccgactattaaacctccgaaacctccgaaacctgctccgaacctgctgggtggtccggaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctcacctgcagcgccaccagcagtgttagctacatccactggtaccaacagaggcctggccagagccccaggctcctcatctatagcacctccaacctggccagcggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcagctcccctttcacctttggcagcggcaccaaagtggaaattaaa(SEQ ID NO:236)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSDKTHTKPPKPAPELLGGPGTGTGGPTIKPPKPPKPAPNLLGGPEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIK(SEQ ID NO:237)
人源化C2单链GS3
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaact(SEQ ID NO:238)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRT(SEQ ID NO:239)
人源化C2单链IgG(无半胱氨酸)
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccgataaaacccatactaaaccgccaaaaccggcgccggaactgctgggtggtcctggtaccggtgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaact(SEQ ID NO:240)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSDKTHTKPPKPAPELLGGPGTGDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRT(SEQ ID NO:241)
人源化C2单链X4(接头是IgG1和IgG2修饰铰链区)
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccgataaaacccatactaaaccgccaaaaccggcgccggaactgctgggtggtcctggtaccggtactggtggtccgactattaaacctccgaaacctccgaaacctgctccgaacctgctgggtggtccggacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaact(SEQ IDNO:242)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSDKTHTKPPKPAPELLGGPGTGTGGPTIKPPKPPKPAPNLLGGPDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRT(SEQ ID NO:243)
人源化C3单链GS3
(DNA)
caggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttaccgactacgccatgaactgggtgcgacaggcccctggacaagggcttgagtggatgggagtgatcagcaccttcagcggtaacacaaacttcaaccagaagttcaagggcagagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgagaagcgactactacggcccatacttcgactactggggccagggcaccaccctgaccgtgtccagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgcaggtctagtcagaccattgtccatagtaatggaaacacctatttggagtggtacctgcagaagccaggccagtctccacagctcctgatctataaggtttccaaccggttctctggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgcttccaaggtagccacgtgcctttcaccttcggcggagggaccaaggtggagatcaaacgaact(SEQ ID NO:244)
(氨基酸)
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYAMNWVRQAPGQGLEWMGVISTFSGNTNFNQKFKGRVTMTTDTSTSTAYMELRSLRSDDTAVYYCARSDYYGPYFDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIVMTQTPLSLSVTPGQPASISCRSSQTIVHSNGNTYLEWYLQKPGQSPQLLIYKVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPFTFGGGTKVEIKRT(SEQ ID NO:245)
人源化C3单链IgG1(无半胱氨酸)
(DNA)
caggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttaccgactacgccatgaactgggtgcgacaggcccctggacaagggcttgagtggatgggagtgatcagcaccttcagcggtaacacaaacttcaaccagaagttcaagggcagagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgagaagcgactactacggcccatacttcgactactggggccagggcaccaccctgaccgtgtccagcgataaaacccatactaaaccgccaaaaccggcgccggaactgctgggtggtcctggtaccggtgatattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgcaggtctagtcagaccattgtccatagtaatggaaacacctatttggagtggtacctgcagaagccaggccagtctccacagctcctgatctataaggtttccaaccggttctctggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgcttccaaggtagccacgtgcctttcaccttcggcggagggaccaaggtggagatcaaacgaact(SEQ ID NO:246)
(氨基酸)
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYAMNWVRQAPGQGLEWMGVISTFSGNTNFNQKFKGRVTMTTDTSTSTAYMELRSLRSDDTAVYYCARSDYYGPYFDYWGQGTTLTVSSDKTHTKPPKPAPELLGGPGTGDIVMTQTPLSLSVTPGQPASISCRSSQTIVHSNGNTYLEWYLQKPGQSPQLLIYKVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPFTFGGGTKVEIKRT(SEQ ID NO:247)
人源化C3单链X4(接头是IgG1和IgG2修饰铰链区)
(DNA)
caggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttaccgactacgccatgaactgggtgcgacaggcccctggacaagggcttgagtggatgggagtgatcagcaccttcagcggtaacacaaacttcaaccagaagttcaagggcagagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgagaagcgactactacggcccatacttcgactactggggccagggcaccaccctgaccgtgtccagcgataaaacccatactaaaccgccaaaaccggcgccggaactgctgggtggtcctggtaccggtactggtggtccgactattaaacctccgaaacctccgaaacctgctccgaacctgctgggtggtccggatattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgcaggtctagtcagaccattgtccatagtaatggaaacacctatttggagtggtacctgcagaagccaggccagtctccacagctcctgatctataaggtttccaaccggttctctggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgcttccaaggtagccacgtgcctttcaccttcggcggagggaccaaggtggagatcaaacgaact(SEQ IDNO:248)
(氨基酸)
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYAMNWVRQAPGQGLEWMGVISTFSGNTNFNQKFKGRVTMTTDTSTSTAYMELRSLRSDDTAVYYCARSDYYGPYFDYWGQGTTLTVSSDKTHTKPPKPAPELLGGPGTGTGGPTIKPPKPPKPAPNLLGGPDIVMTQTPLSLSVTPGQPASISCRSSQTIVHSNGNTYLEWYLQKPGQSPQLLIYKVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPFTFGGGTKVEIKRT(SEQ ID NO:249)
人源化C8单链GS3(接头是[Gly4Ser1]3)
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccctgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagactgggcggcgataactattatgaatattggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacatcgtgatgacccagtctccagactccctggctgtgtctctgggcgagagggccaccatcaactgcagggccagcaagagtgttagcaccagcggctacagctacatgcactggtaccagcagaaaccaggacagcctcctaagctgctcatttacctggtgtctaacctggaatccggggtccctgaccgattcagtggcagcgggtctgggacagatttcactctcaccatcagcagcctgcaggctgaagatgtggcagtttattactgtcaacacattcgggaactgaccaggagtgaattcggcggagggaccaaggtggagatcaaacgaact(SEQ ID NO:250)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYWGKGTTVTVSSGGGGSGGGGSGGGGSDIVMTQSPDSLAVSLGERATINCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLVSNLESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCQHIRELTRSEFGGGTKVEIKRT(SEQ ID NO:251)
人源化C8单链IgG1(无半胱氨酸)
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccctgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagactgggcggcgataactattatgaatattggggcaaagggaccacggtcaccgtctcctccgataaaacccatactaaaccgccaaaaccggcgccggaactgctgggtggtcctggtaccggtgacatcgtgatgacccagtctccagactccctggctgtgtctctgggcgagagggccaccatcaactgcagggccagcaagagtgttagcaccagcggctacagctacatgcactggtaccagcagaaaccaggacagcctcctaagctgctcatttacctggtgtctaacctggaatccggggtccctgaccgattcagtggcagcgggtctgggacagatttcactctcaccatcagcagcctgcaggctgaagatgtggcagtttattactgtcaacacattcgggaactgaccaggagtgaattcggcggagggaccaaggtggagatcaaacgaact(SEQ ID NO:252)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYWGKGTTVTVSSDKTHTKPPKPAPELLGGPGTGDIVMTQSPDSLAVSLGERATINCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLVSNLESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCQHIRELTRSEFGGGTKVEIKRT(SEQ ID NO:253)
人源化C8单链X4(接头是IgG1和IgG2修饰铰链区)
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactacccagactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagactgggcggcgacaattactatgagtattggggcaaagggaccacggtcaccgtctcctccgataaaacccatactaaaccgccaaaaccggcgccggaactgctgggtggtcctggtaccggtactggtggtccgactattaaacctccgaaacctccgaaacctgctccgaacctgctgggtggtccggacatcgtgatgacccagtctccagactccctggctgtgtctctgggcgagagggccaccatcaactgcagggccagcaagagtgttagcaccagcggctacagctacatgcactggtaccagcagaaaccaggacagcctcctaagctgctcatttacctggtgtctaacctggaatccggggtccctgaccgattcagtggcagcgggtctgggacagatttcactctcaccatcagcagcctgcaggctgaagatgtggcagtttattactgtcaacacattcgggaactgaccaggagtgaattcggcggagggaccaaggtggagatcaaacgaact(SEQ ID NO:254)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYWGKGTTVTVSSDKTHTKPPKPAPELLGGPGTGTGGPTIKPPKPPKPAPNLLGGPDIVMTQSPDSLAVSLGERATINCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLVSNLESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCQHIRELTRSEFGGGTKVEIKRT(SEQ ID NO:255)
pSECTag2 E6 scFV-FC
(DNA)
atggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgacgcggcccagccggccgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtaggtatggcatgagctgggtccgccaggctccagggaagaggctggagtgggtctcaaccattagtggcggaggcacctacatatactacccagactcagtgaagggccgattcaccatctccagagacaacgccaagaacaccctgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtaccagagataactatggccgcaactatgattatggcatggattattggggccagggcaccctggtgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctcacctgcagcgccaccagcagtgttagctacatccactggtaccaacagaggcctggccagagccccaggctcctcatctatagcacctccaacctggccagcggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcagctcccctttcacctttggcagcggcaccaaagtggaaattaaagagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:256)
(氨基酸)
METDTLLLWVLLLWVPGSTGDAAQPAEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:257)
E6 scFC-FC 1 gBLOCk序列:
tgctctgggttccaggttccactggtgacgcggcccagccggccgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtaggtatggcatgagctgggtccgccaggctccagggaagaggctggagtgggtctcaaccattagtggcggaggcacctacatatactacccagactcagtgaagggccgattcaccatctccagagacaacgccaagaacaccctgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtaccagagataactatggccgcaactatgattatggcatggattattggggccagggcaccctggtgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgaaattgtgttgacacagtctccagccaccctgtctttgtc(SEQ ID NO:258)
E6 scFC-FC 2 gBLOCk序列:
aattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctcacctgcagcgccaccagcagtgttagctacatccactggtaccaacagaggcctggccagagccccaggctcctcatctatagcacctccaacctggccagcggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcagctcccctttcacctttggcagcggcaccaaagtggaaattaaagagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagc(SEQ ID NO:259)
pSECTag2 C2 scFV-FC
(DNA)
atggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgacgcggcccagccggccgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:260)
(氨基酸)
METDTLLLWVLLLWVPGSTGDAAQPAEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:261)
C2 scFV-FC 1 gBLOCk序列:
(DNA)
tgctctgggttccaggttccactggtgacgcggcccagccggccgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggc(SEQ ID NO:262)
C2 scFV-FC 2 gBLOCk序列:
(DNA)
cattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagc(SEQ ID NO:263)
pSECTag2 C3 scFV-FC
(DNA)
atggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgacgcggcccagccggcccaggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttaccgactacgccatgaactgggtgcgacaggcccctggacaagggcttgagtggatgggagtgatcagcaccttcagcggtaacacaaacttcaaccagaagttcaagggcagagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgagaagcgactactacggcccatacttcgactactggggccagggcaccaccctgaccgtgtccagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgcaggtctagtcagaccattgtccatagtaatggaaacacctatttggagtggtacctgcagaagccaggccagtctccacagctcctgatctataaggtttccaaccggttctctggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgcttccaaggtagccacgtgcctttcaccttcggcggagggaccaaggtggagatcaaacgaactgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:264)
(氨基酸)
METDTLLLWVLLLWVPGSTGDAAQPAQVQLVQSGAEVKKPGASVKVSCKASGYTFTDYAMNWVRQAPGQGLEWMGVISTFSGNTNFNQKFKGRVTMTTDTSTSTAYMELRSLRSDDTAVYYCARSDYYGPYFDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIVMTQTPLSLSVTPGQPASISCRSSQTIVHSNGNTYLEWYLQKPGQSPQLLIYKVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPFTFGGGTKVEIKRTEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:265)
C3 GS scFV FC 1 gBLOCk序列:
(DNA)
tgctctgggttccaggttccactggtgacgcggcccagccggcccaggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttaccgactacgccatgaactgggtgcgacaggcccctggacaagggcttgagtggatgggagtgatcagcaccttcagcggtaacacaaacttcaaccagaagttcaagggcagagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgagaagcgactactacggcccatacttcgactactggggccagggcaccaccctgaccgtgtccagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattgtgatgacccagactccactctctctgt(SEQ ID NO:266)
C3 scFV FC2 gBLOCk序列:
(DNA)
tattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgcaggtctagtcagaccattgtccatagtaatggaaacacctatttggagtggtacctgcagaagccaggccagtctccacagctcctgatctataaggtttccaaccggttctctggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgcttccaaggtagccacgtgcctttcaccttcggcggagggaccaaggtggagatcaaacgaactgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagc(SEQ ID NO:267)
pSECTag2 C8 scFV-FC
(DNA)
atggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgacgcggcccagccggccgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccctgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagactgggcggcgataactattatgaatattggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacatcgtgatgacccagtctccagactccctggctgtgtctctgggcgagagggccaccatcaactgcagggccagcaagagtgttagcaccagcggctacagctacatgcactggtaccagcagaaaccaggacagcctcctaagctgctcatttacctggtgtctaacctggaatccggggtccctgaccgattcagtggcagcgggtctgggacagatttcactctcaccatcagcagcctgcaggctgaagatgtggcagtttattactgtcaacacattcgggaactgaccaggagtgaattcggcggagggaccaaggtggagatcaaacgaactgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:268)
(氨基酸)
METDTLLLWVLLLWVPGSTGDAAQPAEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYWGKGTTVTVSSGGGGSGGGGSGGGGSDIVMTQSPDSLAVSLGERATINCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLVSNLESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCQHIRELTRSEFGGGTKVEIKRTEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:269)
C8 scFV FC 1 gBLOCk序列:
(DNA)
tgctctgggttccaggttccactggtgacgcggcccagccggccgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccctgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagactgggcggcgataactattatgaatattggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacatcgtgatgacccagtctccagactccctgg(SEQ ID NO:270)
C8 scFV FC2 gBLOCk序列:
(DNA)
catcgtgatgacccagtctccagactccctggctgtgtctctgggcgagagggccaccatcaactgcagggccagcaagagtgttagcaccagcggctacagctacatgcactggtaccagcagaaaccaggacagcctcctaagctgctcatttacctggtgtctaacctggaatccggggtccctgaccgattcagtggcagcgggtctgggacagatttcactctcaccatcagcagcctgcaggctgaagatgtggcagtttattactgtcaacacattcgggaactgaccaggagtgaattcggcggagggaccaaggtggagatcaaacgaactgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagc(SEQ ID NO:271)
人IgG1 Fc序列:
(DNA)
gagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:272)
(氨基酸)
EPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:273)
人IgG1 CH2-CH3结构域序列:
(DNA)
ccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:274)
(氨基酸)
PCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:275)
人IgG1 CH3结构域序列:
(DNA)
gggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:276)
(氨基酸)
GQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:277)
人IgG1 Fc Y407R序列:
(DNA)
gagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctcaggagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:278)
(氨基酸)
EPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLRSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:279)
人IgG1 Fc F405Q序列:
(DNA)
gagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttccagctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:280)
(氨基酸)
EPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFQLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:281)
人IgG1 Fc T394D序列:
(DNA)
gagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccgaccctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:282)
(氨基酸)
EPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTDPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:283)
人IgG1 Fc T366W/L368W序列:
(DNA)
gagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgtggtgctgggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:284)
(氨基酸)
EPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLWCWVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:285)
人IgG1 Fc T364R/L368R序列:
(DNA)
gagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcaggctgacctgcagggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:286)
(氨基酸)
EPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVRLTCRVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:287)
人IgG1 Fc无铰链序列:
(DNA)
gcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:288)
(氨基酸)
APELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:289)
人IgG1 G237A FC序列:
(DNA)
gagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctgggggccccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaa(SEQ ID NO:290)
(氨基酸)
EPKSCDKTHTCPPCPAPELLGAPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQ ID NO:291)
人IgG1 L234A/L235A FC序列:
(DNA)
gagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaagccgccgggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaa(SEQ ID NO:292)
(氨基酸)
EPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQ ID NO:293)
CAR-T E6 CD8/CD8/CD3z序列:
N-CD8ls-huMNE6scFv-CD8ecd片段-CD8跨膜-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaaacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:294)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**
**(SEQ ID NO:295)
CAR-T E6 CD3z gBLOCK序列:
(DNA)
tggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataagtttaaacccgctgatcagcctcgactgtgc(SEQ ID NO:296)
CAR-T E6 CD8/CD8/CD28/CD3z序列:
N-CD8ls-huMNE6scFv-CD8ecd片段-CD8跨膜-CD28-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaaacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa
(SEQ ID NO:297)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:298)
CAR-T E6 CD28/CD3z g BLOCK序列:
(DNA)
tggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataagtttaaacccgctgatcagcctcgactgtgc(SEQ ID NO:299)
CAR-T E6 CD8/CD8/4-1BB/CD3z序列:
N-CD8ls-huMNE6scFv-CD8ecd片段-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaaacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa
(SEQ ID NO:300)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**
(SEQ ID NO:301)
CAR-T E6 4-1BB/CD3z gBLOCK序列:
(DNA)
tggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataagtttaaacccgctgatcagcctcgactgtgc(SEQ ID NO:302)
CAR-T E6 CD8/CD8/CD28/4-1BB/CD3z序列:
N-CD8ls-huMNE6scFv-CD8ecd片段-CD8跨膜-CD28-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaaacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtccaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa
(SEQ ID NO:303)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:304)
CAR-T E6 CD28/4-1BB/CD3z gBLOCK序列:
(DNA)
atagggagacccaagctggctagttaagcttggtaccgagggccaccatggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaaacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtccaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataagtttaaacccgctgatcagcctcgactgtgc(SEQ ID NO:305)
CAR-T C2 CD8/CD8/CD28/4-1BB/CD3z序列:
N-CD8ls-huMNC2scFv-CD8ecd片段-CD8跨膜-CD28-4-1BB-CD3ζ-C
(DNA)
atggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaaccacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtccaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:306)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:307)
CAR-T C2-1 gBLOCK序列:
(DNA)
atagggagacccaagctggctagttaagcttggtaccgagggccaccatggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggc(SEQ ID NO:308)
CAR-T C2-2 gBLOCK序列:
(DNA)
aagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaaccacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgc(SEQ ID NO:309)
CAR E6 Fc/8/4-1BB/CD3z序列:
N-CD8ls-huMNE6scFv-人IgG1Fc-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:310)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:311)
E6 CAR pCDH gBLOCK序列:
(DNA)
acgctgttttgacctccatagaagattctagagctagctgtagagcttggtaccgagggccaccatggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgc(SEQ ID NO:312)
E6 CAR Fc pCDH gBLOCK序列:
(DNA)
agtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctg(SEQ ID NO:313)
E6 CAR 8BB3 pCDH gBLOCK序列:
(DNA)
agaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataagtttaaacccgctgatcaggcggccgcgaaggatctgcgatcgctccggtgcccgtcag(SEQ ID NO:314)
CAR E6 FcH/8/4-1BB/CD3z序列:
N-CD8ls-huMNE6scFv-人IgG1无铰链Fc Y407R-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:315)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ IDNO:316)
E6 CAR FcH pCDH gBLOCK序列:
(DNA)
agtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctg(SEQ ID NO:317)
CAR E6 Fc/4/4-1BB/CD3z序列:
N-CD8ls-huMNE6scFv-人IgG1 Fc-CD4跨膜-CD28-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:318)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKMALIVLGGVAGLLLFIGLGIFFKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:319)
E6 CAR 44BB3 pCDH gBLOCK序列:
(DNA)
agaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataagtttaaacccgctgatcaggcggccgcgaaggatctgcgatcgctccggtgcccgtcag(SEQ ID NO:320)
CAR E6 FcH/4/4-1BB/CD3z序列:
N-CD8ls-huMNE6scFv-人IgG1无铰链Fc Y407R-CD4跨膜-CD28-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:321)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKMALIVLGGVAGLLLFIGLGIFFKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:322)
CAR E6 IgD/8/4-1BB/CD3z序列:
N-CD8ls-huMNE6scFv-IgD铰链区-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccaatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:323)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:324)
E6 CAR IgD8 pcDH gBLOCK序列:
(DNA)
agtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccaatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccag(SEQ ID NO:325)
E6 CAR BB 3 pCDH gBLOCK序列:
(DNA)
acatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataagtttaaacccgctgatcaggcggccgcgaaggatctgcgatcgctccggtgcccgtcag(SEQ ID NO:326)
CAR E6 IgD/4/4-1BB/CD3z序列:
N-CD8ls-huMNE6scFv-IgD铰链区-CD4跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:327)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPMALIVLGGVAGLLLFIGLGIFFKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:328)
E6 CAR IgD4 pcDH gBLOCK序列:
(DNA)
agtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccag(SEQ ID NO:329)
CAR E6 X4/8/4-1BB/CD3z序列:
N-CD8ls-huMNE6scFv-X4接头-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagacaagacgcacaccaagccacctaaaccagctccagaactgctcggaggtcctggcaccggaaccggaggacctaccatcaaaccacctaagccacctaagcctgctcctaacctgctcggaggacctatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:330)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKDKTHTKPPKPAPELLGGPGTGTGGPTIKPPKPPKPAPNLLGGPIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:331)
E6 CAR X48 pCDH gBLOCK序列:
(DNA)
agtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagacaagacgcacaccaagccacctaaaccagctccagaactgctcggaggtcctggcaccggaaccggaggacctaccatcaaaccacctaagccacctaagcctgctcctaacctgctcggaggacctatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccag(SEQ ID NO:332)
CAR E6 X4/4/4-1BB/CD3z序列:
N-CD8ls-huMNE6scFv-X4接头-CD4跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagacaagacgcacaccaagccacctaaaccagctccagaactgctcggaggtcctggcaccggaaccggaggacctaccatcaaaccacctaagccacctaagcctgctcctaacctgctcggaggacctatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:333)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKDKTHTKPPKPAPELLGGPGTGTGGPTIKPPKPPKPAPNLLGGPMALIVLGGVAGLLLFIGLGIFFKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:334)
E6 CAR X44 pCDH gBLOCK序列:
(DNA)
agtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagacaagacgcacaccaagccacctaaaccagctccagaactgctcggaggtcctggcaccggaaccggaggacctaccatcaaaccacctaagccacctaagcctgctcctaacctgctcggaggacctatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccag(SEQ ID NO:335)
CAR E6 8+4/4/4-1BB/CD3z序列:
N-CD8ls-huMNE6scFv-CD8ecd+CD4ecd片段–CD4跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaaacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:336)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDMALIVLGGVAGLLLFIGLGIFFKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:337)
E6 CAR CD844 pCDH gBLOCK序列:
(DNA)
agtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaaacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccag(SEQ ID NO:338)
CAR中的人源化C2 scFV序列:
(DNA)
gagggccaccatggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaacc(SEQ ID NO:339)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRT(SEQ ID NO:340)
CAR中的人源化E6 scFV序列:
(DNA)
gaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaa(SEQ ID NO:341)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIK(SEQ ID NO:342)
CD8前导序列:
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggcca(SEQ ID NO:343)
(氨基酸)
MALPVTALLLPLALLLHAARP(SEQ ID NO:344)
CD8铰链结构域序列:
(DNA)
acgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgat(SEQ ID NO:345)
(氨基酸)
TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACD(SEQ ID NO:346)
CD4铰链结构域序列:
(DNA)
tcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagcca(SEQ ID NO:347)
(氨基酸)
SGQVLLESNIKVLPTWSTPVQP(SEQ ID NO:348)
CD28铰链结构域序列:
(DNA)
aaacacctttgtccaagtcccctatttcccggaccttctaagccc(SEQ ID NO:349)
(氨基酸)
KHLCPSPLFPGPSKP(SEQ ID NO:350)
CD8+CD4铰链结构域序列:
(DNA)
acgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgattcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagcca(SEQ ID NO:351)
(氨基酸)
TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDSGQVLLESNIKVLPTWSTPVQP(SEQ ID NO:352)
CD8+CD28铰链结构域序列:
(DNA)
acgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgataaacacctttgtccaagtcccctatttcccggaccttctaagccc(SEQ ID NO:353)
(氨基酸)
TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDKHLCPSPLFPGPSKP(SEQ ID NO:354)
CD28+CD4铰链结构域序列:
(DNA)
aaacacctttgtccaagtcccctatttcccggaccttctaagccctcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagcca(SEQ ID NO:355)
(氨基酸)
KHLCPSPLFPGPSKPSGQVLLESNIKVLPTWSTPVQP(SEQ ID NO:356)
人IgD铰链结构域序列:
(DNA)
gagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacacca(SEQ ID NO:357)
(氨基酸)
ESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTP(SEQ ID NO:358)
X4接头(IgG1和IgG2修饰铰链区)序列:
(DNA)
gacaagacgcacaccaagccacctaaaccagctccagaactgctcggaggtcctggcaccggaaccggaggacctaccatcaaaccacctaagccacctaagcctgctcctaacctgctcggaggacct(SEQ ID NO:359)
(氨基酸)
DKTHTKPPKPAPELLGGPGTGTGGPTIKPPKPPKPAPNLLGGP(SEQ ID NO:360)
CD3ζ跨膜结构域序列:
(DNA)
ctctgctacctgctggatggaatcctcttcatctatggtgtcattctcactgccttgttcctg(SEQ ID NO:361)
(氨基酸)
LCYLLDGILFIYGVILTALFL(SEQ ID NO:362)
CD8跨膜结构域序列:
(DNA)
atctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgc(SEQ ID NO:363)
(氨基酸)
IYIWAPLAGTCGVLLLSLVITLYC(SEQ ID NO:364)
CD4跨膜结构域序列:
(DNA)
atggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttc(SEQ ID NO:365)
(氨基酸)
MALIVLGGVAGLLLFIGLGIFF(SEQ ID NO:366)
CD28跨膜结构域序列:
(DNA)
ttttgggtgctggtggtggttggtggagtcctggcttgctatagcttgctagtaacagtggcctttattattttctgggtg(SEQ IDNO:367)
(氨基酸)
FWVLVVVGGVLACYSLLVTVAFIIFWV(SEQ ID NO:368)
4-1BB跨膜结构域序列:
(DNA)
atcatctccttctttcttgcgctgacgtcgactgcgttgctcttcctgctgttcttcctcacgctccgtttctctgttgtt(SEQ ID NO:369)
(氨基酸)
IISFFLALTSTALLFLLFFLTLRFSVV(SEQ ID NO:370)
OX40跨膜结构域序列:
(DNA)
gttgccgccatcctgggcctgggcctggtgctggggctgctgggccccctggccatcctgctggccctgtacctgctc(SEQ ID NO:371)
(氨基酸)
VAAILGLGLVLGLLGPLAILLALYLL(SEQ ID NO:372)
CD3ζ结构域序列:
(DNA)
cgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacgg(SEQ ID NO:373)
(氨基酸)
RVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR(SEQ ID NO:374)
CD3ζ结构域变体序列:
(DNA)
agagtgaagttcagcaggagcgcagacgcccccgcgtaccagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgc(SEQ ID NO:375)
(氨基酸)
RVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR(SEQ ID NO:376)
CD28结构域序列:
(DNA)
agaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcc(SEQ ID NO:377)
(氨基酸)
RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS(SEQ ID NO:378)
4-1BB结构域序列:
(DNA)
aaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactg(SEQ ID NO:379)
(氨基酸)
KRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL(SEQ ID NO:380)
OX40结构域序列:
(DNA)
cggagggaccagaggctgccccccgatgcccacaagccccctgggggaggcagtttccggacccccatccaagaggagcaggccgacgcccactccaccctggccaagatc(SEQ ID NO:381)
(氨基酸)
RRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKI(SEQ ID NO:382)
人源化抗CD3 scFV克隆12F6(VH-VL)序列:
(DNA)
caggtgcagctggtgcagagcggaggtggagtggtccaacctggaagatctctgagactgagctgtaaggctagcgggtacacgttcacatcttacacgatgcactgggtgaggcaagcccccggtaagggcctggaatggatcggatatataaaccccagctcagggtataccaaatataatcagaagttcaaagatcggttcacgatttctgctgataaaagtaagtccaccgctttcctgcagatggactcactcaggccagaagatactggtgtttatttctgtgcaaggtggcaggactacgacgtgtactttgactattgggggcaggggacgcctgtaacagtatcaagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattcagatgacccagagcccgagcagcctgagcgcgagcgtgggcgatcgcgtgaccatgacctgccgcgcgagcagcagcgtgagctatatgcattggtatcagcagaccccgggcaaagcgccgaaaccgtggatttatgcgaccagcaacctggcgagcggcgtgccgagccgctttagcggcagcggcagcggcaccgattataccctgaccattagcagcctgcagccggaagatattgcgacctattattgccagcagtggagcagcaacccgccgacctttggccagggcaccaaactgcagattacccgc(SEQ ID NO:383)
(氨基酸)
QVQLVQSGGGVVQPGRSLRLSCKASGYTFTSYTMHWVRQAPGKGLEWIGYINPSSGYTKYNQKFKDRFTISADKSKSTAFLQMDSLRPEDTGVYFCARWQDYDVYFDYWGQGTPVTVSSGGGGSGGGGSGGGGSDIQMTQSPSSLSASVGDRVTMTCRASSSVSYMHWYQQTPGKAPKPWIYATSNLASGVPSRFSGSGSGTDYTLTISSLQPEDIATYYCQQWSSNPPTFGQGTKLQITR(SEQ ID NO:384)
人源化抗CD3 scFV克隆12F6(VL-VH)序列:
(DNA)
gatattcagatgacccagagcccgagcagcctgagcgcgagcgtgggcgatcgcgtgaccatgacctgccgcgcgagcagcagcgtgagctatatgcattggtatcagcagaccccgggcaaagcgccgaaaccgtggatttatgcgaccagcaacctggcgagcggcgtgccgagccgctttagcggcagcggcagcggcaccgattataccctgaccattagcagcctgcagccggaagatattgcgacctattattgccagcagtggagcagcaacccgccgacctttggccagggcaccaaactgcagattacccgcggcggtggcggatccggcggtggcggatccggcggtggcggatcccaggtgcagctggtgcagagcggaggtggagtggtccaacctggaagatctctgagactgagctgtaaggctagcgggtacacgttcacatcttacacgatgcactgggtgaggcaagcccccggtaagggcctggaatggatcggatatataaaccccagctcagggtataccaaatataatcagaagttcaaagatcggttcacgatttctgctgataaaagtaagtccaccgctttcctgcagatggactcactcaggccagaagatactggtgtttatttctgtgcaaggtggcaggactacgacgtgtactttgactattgggggcaggggacgcctgtaacagtatcaagc(SEQ ID NO:385)
(氨基酸)
DIQMTQSPSSLSASVGDRVTMTCRASSSVSYMHWYQQTPGKAPKPWIYATSNLASGVPSRFSGSGSGTDYTLTISSLQPEDIATYYCQQWSSNPPTFGQGTKLQITRGGGGSGGGGSGGGGSQVQLVQSGGGVVQPGRSLRLSCKASGYTFTSYTMHWVRQAPGKGLEWIGYINPSSGYTKYNQKFKDRFTISADKSKSTAFLQMDSLRPEDTGVYFCARWQDYDVYFDYWGQGTPVTVSS(SEQ ID NO:386)
人源化抗CD3 scFV克隆OKT3(VH-VL)序列:
(DNA)
caggtgcagctggtgcagagcggaggcggagtggtgcagcctggaagaagcctgcgcctgagctgcaaagcgagcggctatacctttacccgctataccatgcattgggtgcgccaggcgccgggcaaaggcctggaatggattggctatattaacccgagccgcggctataccaactataaccagaaagtgaaagatcgctttaccattagcaccgataaaagcaaaagcaccgcgtttctgcagatggatagcctgcgcccggaagataccgcggtgtattattgcgcgcgctattatgatgatcattattgcctggattattggggccagggcaccaccctgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattcagatgacccagagcccgagcagcctgagcgcgagcgtgggcgatcgcgtgaccattacctgcagcgcgagcagcagcgtgagctatatgaactggtatcagcagaccccgggcaaagcgccgaaacgctggatttatgataccagcaaactggcgagcggcgtgccgagccgctttagcggcagcggcagcggcaccgattatacctttaccattagcagcctgcagccggaagatattgcgacctattattgccagcagtggagcagcaacccgtttacctttggccagggcaccaaactgcagattacccgc(SEQ ID NO:387)
(氨基酸)
QVQLVQSGGGVVQPGRSLRLSCKASGYTFTRYTMHWVRQAPGKGLEWIGYINPSRGYTNYNQKVKDRFTISTDKSKSTAFLQMDSLRPEDTAVYYCARYYDDHYCLDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIQMTQSPSSLSASVGDRVTITCSASSSVSYMNWYQQTPGKAPKRWIYDTSKLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSNPFTFGQGTKLQITR(SEQ ID NO:388)
人源化抗CD3 scFV克隆OKT3(VH-VL)序列:
(DNA)
gatattcagatgacccagagcccgagcagcctgagcgcgagcgtgggcgatcgcgtgaccattacctgcagcgcgagcagcagcgtgagctatatgaactggtatcagcagaccccgggcaaagcgccgaaacgctggatttatgataccagcaaactggcgagcggcgtgccgagccgctttagcggcagcggcagcggcaccgattatacctttaccattagcagcctgcagccggaagatattgcgacctattattgccagcagtggagcagcaacccgtttacctttggccagggcaccaaactgcagattacccgcggcggtggcggatccggcggtggcggatccggcggtggcggatcccaggtgcagctggtgcagagcggaggcggagtggtgcagcctggaagaagcctgcgcctgagctgcaaagcgagcggctatacctttacccgctataccatgcattgggtgcgccaggcgccgggcaaaggcctggaatggattggctatattaacccgagccgcggctataccaactataaccagaaagtgaaagatcgctttaccattagcaccgataaaagcaaaagcaccgcgtttctgcagatggatagcctgcgcccggaagataccgcggtgtattattgcgcgcgctattatgatgatcattattgcctggattattggggccagggcaccaccctgaccgtgagcagc(SEQ ID NO:389)
(氨基酸)
DIQMTQSPSSLSASVGDRVTITCSASSSVSYMNWYQQTPGKAPKRWIYDTSKLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSNPFTFGQGTKLQITRGGGGSGGGGSGGGGSQVQLVQSGGGVVQPGRSLRLSCKASGYTFTRYTMHWVRQAPGKGLEWIGYINPSRGYTNYNQKVKDRFTISTDKSKSTAFLQMDSLRPEDTAVYYCARYYDDHYCLDYWGQGTTLTVSS(SEQ ID NO:390)
人源化E6 scFV(VH-VL)序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtaggtatggcatgagctgggtccgccaggctccagggaagaggctggagtgggtctcaaccattagtggcggaggcacctacatatactacccagactcagtgaagggccgattcaccatctccagagacaacgccaagaacaccctgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtaccagagataactatggccgcaactatgattatggcatggattattggggccagggcaccctggtgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctcacctgcagcgccaccagcagtgttagctacatccactggtaccaacagaggcctggccagagccccaggctcctcatctatagcacctccaacctggccagcggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcagctcccctttcacctttggcagcggcaccaaagtggaaattaaa(SEQ ID NO:391)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIK(SEQ ID NO:392)
人源化E6 scFV(VL-VH)序列:
(DNA)
gaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctcacctgcagcgccaccagcagtgttagctacatccactggtaccaacagaggcctggccagagccccaggctcctcatctatagcacctccaacctggccagcggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcagctcccctttcacctttggcagcggcaccaaagtggaaattaaaggcggtggcggatccggcggtggcggatccggcggtggcggatccgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtaggtatggcatgagctgggtccgccaggctccagggaagaggctggagtgggtctcaaccattagtggcggaggcacctacatatactacccagactcagtgaagggccgattcaccatctccagagacaacgccaagaacaccctgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtaccagagataactatggccgcaactatgattatggcatggattattggggccagggcaccctggtgaccgtgagcagc(SEQ ID NO:393)
(氨基酸)
EIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKGGGGSGGGGSGGGGSEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSS(SEQ ID NO:394)
人源化C2 scFV(VH-VL)序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaact(SEQ ID NO:395)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRT(SEQ ID NO:396)
人源化E6 scFV(VL-VH)序列:
(DNA)
gacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactggcggtggcggatccggcggtggcggatccggcggtggcggatccgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctcc(SEQ ID NO:397)
(氨基酸)
DIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTGGGGSGGGGSGGGGSEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSS(SEQ ID NO:398)
G4S1接头序列:
(DNA)
ggcggtggcggatcc(SEQ ID NO:399)
(氨基酸)
GGGGS(SEQ ID NO:400)
[G4S1]x3接头序列:
(DNA)
ggcggtggcggatccggcggtggcggatccggcggtggcggatcc(SEQ ID NO:401)
(氨基酸)
GGGGSGGGGSGGGGS(SEQ ID NO:402)
8aa GS接头序列:
(DNA)
ggcggttccggcggtggatccgga(SEQ ID NO:403)
(氨基酸)
GGSGGGSG(SEQ ID NO:404)
12aa GS接头序列:
(DNA)
ggcggttccggcggtggatccggcggtggcggatccgga(SEQ ID NO:405)
(氨基酸)
GGSGGGSGGGSG(SEQ ID NO:406)
13aa GS接头序列:
(DNA)
ggcggtggatccggcggtggcggatccggcggtggatcc(SEQ ID NO:407)
(氨基酸)
GGGSGGGGSGGGS(SEQ ID NO:408)
22aa GS接头序列:
(DNA)
ggcggtggaagcggcggtggcggatccggcagcggcggaagcggcggtggcggatccggcggtgga(SEQ ID NO:409)
(氨基酸)
GGGSGGGGSGSGGSGGGGSGGG(SEQ ID NO:4110)
24aa GS接头序列:
(DNA)
ggcggttccggcggtggatccggcggtggcggatccggaggcggttccggcggtggatccggcggtggcggatccgga(SEQID NO:411)
(氨基酸)
GGSGGGSGGGSGGGSGGGSGGGSG(SEQ ID NO:412)
小鼠C3重链可变区序列:
(DNA)
caggtccagctgcagcagtctgggcctgagctggtgaggcctggggtctcagtgaagatttcctgcaagggttccggctacagattcactgattatgctatgaactgggtgaagcagagtcatgcaaagagtctagagtggattggagttattagtactttctctggtaatacaaacttcaaccagaagtttaagggcaaggccacaatgactgtagacaaatcctccagcacagcctatatggaacttgccagattgacatctgaggattctgccatgtattactgtgcaagatcggattactacggcccatactttgactactggggccaaggcaccactctcacagtctcctca(SEQ ID NO:413)
(氨基酸)
QVQLQQSGPELVRPGVSVKISCKGSGYRFTDYAMNWVKQSHAKSLEWIGVISTFSGNTNFNQKFKGKATMTVDKSSSTAYMELARLTSEDSAMYYCARSDYYGPYFDYWGQGTTLTVSS(SEQ ID NO:414)
小鼠C3重链可变框架区1(FWR1)序列:
(DNA)
caggtccagctgcagcagtctgggcctgagctggtgaggcctggggtctcagtgaagatttcctgcaagggttccggctacagattcact(SEQ ID NO:415)
(氨基酸)
QVQLQQSGPELVRPGVSVKISCKGSGYRFT(SEQ ID NO:416)
小鼠C3重链可变互补决定区1(CDR1)序列:
(DNA)
gattatgctatgaac(SEQ ID NO:417)
(氨基酸)
DYAMN(SEQ ID NO:418)
小鼠C3重链可变框架区2(FWR2)序列:
(DNA)
tgggtgaagcagagtcatgcaaagagtctagagtggattgga(SEQ ID NO:419)
(氨基酸)
WVKQSHAKSLEWIG(SEQ ID NO:420)
小鼠C3重链可变互补决定区2(CDR2)序列:
(DNA)
gttattagtactttctctggtaatacaaacttcaaccagaagtttaagggc(SEQ ID NO:421)
(氨基酸)
VISTFSGNTNFNQKFKG(SEQ ID NO:422)
小鼠C3重链可变框架区3(FWR3)酸序列:
(DNA)
aaggccacaatgactgtagacaaatcctccagcacagcctatatggaacttgccagattgacatctgaggattctgccatgtattactgtgcaaga(SEQ ID NO:423)
(氨基酸)
KATMTVDKSSSTAYMELARLTSEDSAMYYCAR(SEQ ID NO:424)
小鼠C3重链可变互补决定区3(CDR3)序列:
(DNA)
tcggattactacggcccatactttgactac(SEQ ID NO:425)
(氨基酸)
SDYYGPYFDY(SEQ ID NO:426)
IGHV1-18*04重链可变区序列:
(DNA)
caggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttaccagctacggtatcagctgggtgcgacaggcccctggacaagggcttgagtggatgggatggatcagcgcttacaatggtaacacaaactatgcacagaagctccagggcagagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgagaga(SEQ ID NO:427)
(氨基酸)
QVQLVQSGAEVKKPGASVKVSCKASGYTFTSYGISWVRQAPGQGLEWMGWISAYNGNTNYAQKLQGRVTMTTDTSTSTAYMELRSLRSDDTAVYYCAR(SEQ ID NO:428)
IGHV1-18*04重链可变框架区1(FWR1)序列:
(DNA)
caggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttacc(SEQ ID NO:429)
(氨基酸)
QVQLVQSGAEVKKPGASVKVSCKASGYTFT(SEQ ID NO:430)
IGHV1-18*04重链可变互补决定区1(CDR1)序列:
(DNA)
agctacggtatcagc(SEQ ID NO:431)
(氨基酸)
SYGIS(SEQ ID NO:432)
IGHV1-18*04重链可变框架区2(FWR2)序列:
(DNA)
tgggtgcgacaggcccctggacaagggcttgagtggatggga(SEQ ID NO:433)
(氨基酸)
WVRQAPGQGLEWMG(SEQ ID NO:434)
IGHV1-18*04重链可变互补决定区2(CDR2)序列:
(DNA)
tggatcagcgcttacaatggtaacacaaactatgcacagaagctccagggc(SEQ ID NO:435)
(氨基酸)
WISAYNGNTNYAQKLQG(SEQ ID NO:436)
IGHV1-18*04重链可变框架区3(FWR3)序列:
(DNA)
agagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgaga(SEQ ID NO:437)
(氨基酸)
RVTMTTDTSTSTAYMELRSLRSDDTAVYYCAR(SEQ ID NO:438)
人源化C3重链可变区序列:
(DNA)
caggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttaccgactacgccatgaactgggtgcgacaggcccctggacaagggcttgagtggatgggagtgatcagcaccttcagcggtaacacaaacttcaaccagaagttcaagggcagagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgagaagcgactactacggcccatacttcgactactggggccagggcaccaccctgaccgtgtccagc(SEQ IDNO:439)
(氨基酸)
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYAMNWVRQAPGQGLEWMGVISTFSGNTNFNQKFKGRVTMTTDTSTSTAYMELRSLRSDDTAVYYCARSDYYGPYFDYWGQGTTLTVSS(SEQ ID NO:440)
人源化C3重链可变框架区1(FWR1)酸序列:
(DNA)
caggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttacc(SEQ ID NO:441)
(氨基酸)
QVQLVQSGAEVKKPGASVKVSCKASGYTFT(SEQ ID NO:442)
人源化C3重链可变互补决定区1(CDR1)序列:
(DNA)
gactacgccatgaac(SEQ ID NO:443)
(氨基酸)
DYAMN(SEQ ID NO:444)
人源化C3重链可变框架区2(FWR2)酸序列:
(DNA)
tgggtgcgacaggcccctggacaagggcttgagtggatggga(SEQ ID NO:445)
(氨基酸)
WVRQAPGQGLEWMG(SEQ ID NO:446)
人源化C3重链可变互补决定区2(CDR2)序列:
(DNA)
gtgatcagcaccttcagcggtaacacaaacttcaaccagaagttcaagggc(SEQ ID NO:447)
(氨基酸)
VISTFSGNTNFNQKFKG(SEQ ID NO:448)
人源化C3重链可变框架区3(FWR3)酸序列:
(DNA)
agagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgaga(SEQ ID NO:449)
(氨基酸)
RVTMTTDTSTSTAYMELRSLRSDDTAVYYCAR(SEQ ID NO:450)
人源化C3重链可变互补决定区3(CDR3)序列:
(DNA)
agcgactactacggcccatacttcgactac(SEQ ID NO:451)
(氨基酸)
SDYYGPYFDY(SEQ ID NO:452)
人源化C3IgG1重链序列
(DNA)
caggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttaccgactacgccatgaactgggtgcgacaggcccctggacaagggcttgagtggatgggagtgatcagcaccttcagcggtaacacaaacttcaaccagaagttcaagggcagagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgagaagcgactactacggcccatacttcgactactggggccagggcaccaccctgaccgtgtccagcgctagcaccaagggcccatcggtcttccccctggcaccctcctccaagagcacctctgggggcacagcggccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtcctacagtcctcaggactctactccctcagcagcgtggtgacagtgccctccagcagcttgggcacccagacctacatctgcaacgtgaatcacaagcccagcaacaccaaggtggacaagaaagttgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:453)
(氨基酸)
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYAMNWVRQAPGQGLEWMGVISTFSGNTNFNQKFKGRVTMTTDTSTSTAYMELRSLRSDDTAVYYCARSDYYGPYFDYWGQGTTLTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:454)
人源化C3 IgG2重链序列
(DNA)
caggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttaccgactacgccatgaactgggtgcgacaggcccctggacaagggcttgagtggatgggagtgatcagcaccttcagcggtaacacaaacttcaaccagaagttcaagggcagagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgagaagcgactactacggcccatacttcgactactggggccagggcaccaccctgaccgtgtccagcgcctccaccaagggcccatcggtcttccccctggcgccctgctccaggagcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgctctgaccagcggcgtgcacaccttcccagctgtcctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcaacttcggcacccagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaagacagttgagcgcaaatgttgtgtcgagtgcccaccgtgcccagcaccacctgtggcaggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacgtgcgtggtggtggacgtgagccacgaagaccccgaggtccagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccacgggaggagcagttcaacagcacgttccgtgtggtcagcgtcctcaccgttgtgcaccaggactggctgaacggcaaggagtacaagtgcaaggtctccaacaaaggcctcccagcccccatcgagaaaaccatctccaaaaccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctaccccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacacctcccatgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatagtaa(SEQ ID NO:455)
(氨基酸)
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYAMNWVRQAPGQGLEWMGVISTFSGNTNFNQKFKGRVTMTTDTSTSTAYMELRSLRSDDTAVYYCARSDYYGPYFDYWGQGTTLTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSNFGTQTYTCNVDHKPSNTKVDKTVERKCCVECPPCPAPPVAGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTFRVVSVLTVVHQDWLNGKEYKCKVSNKGLPAPIEKTISKTKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPMLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:456)
人源化C3重链IgG1 gBLOCK序列:
(DNA)
tgctctgggttccaggttccactggtgacgcggcccagccggcccaggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttaccgactacgccatgaactgggtgcgacaggcccctggacaagggcttgagtggatgggagtgatcagcaccttcagcggtaacacaaacttcaaccagaagttcaagggcagagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgagaagcgactactacggcccatacttcgactactggggccagggcaccaccctgaccgtgtccagcgctagcaccaagggcccatcggtcttccccctggcaccctcctccaagagcacctctgggggcacagcggccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgccctgaccagc(SEQ ID NO:457)
小鼠C3轻链可变区序列:
(DNA)
gatgttttgatgacccaaactccactctccctgcctgtcagtcttggagatcaagcctccatctcttgcagatctagtcagaccattgtacatagtaatggaaacacctatttagaatggtacctgcagaaaccaggccagtctccaaagctcctgatctacaaagtttccaaccgattttctggggtcccagacaggttcagtggcagtggatcagggacagatttcacactcaagatcaacagagtggaggctgaggatctgggagtttattactgctttcaaggttcacatgttccattcacgttcggctcggggacaaagttggaaataaaa(SEQ ID NO:458)
(氨基酸)
DVLMTQTPLSLPVSLGDQASISCRSSQTIVHSNGNTYLEWYLQKPGQSPKLLIYKVSNRFSGVPDRFSGSGSGTDFTLKINRVEAEDLGVYYCFQGSHVPFTFGSGTKLEIK(SEQ ID NO:459)
小鼠C3轻链可变框架区1(FWR1)序列:
(DNA)
gatgttttgatgacccaaactccactctccctgcctgtcagtcttggagatcaagcctccatctcttgc(SEQ ID NO:460)
(氨基酸)
DVLMTQTPLSLPVSLGDQASISC(SEQ ID NO:461)
小鼠C3轻链可变互补决定区1(CDR1)序列:
(DNA)
agatctagtcagaccattgtacatagtaatggaaacacctatttagaa(SEQ ID NO:462)
(氨基酸)
RSSQTIVHSNGNTYLE(SEQ ID NO:463)
小鼠C3轻链可变框架区2(FWR2)序列:
(DNA)
tggtacctgcagaaaccaggccagtctccaaagctcctgatctac(SEQ ID NO:464)
(氨基酸)
WYLQKPGQSPKLLIY(SEQ ID NO:465)
小鼠C3轻链可变互补决定区2(CDR2)序列:
(DNA)
aaagtttccaaccgattttct(SEQ ID NO:466)
(氨基酸)
KVSNRFS(SEQ ID NO:467)
小鼠C3轻链可变框架区3(FWR3)序列:
(DNA)
ggggtcccagacaggttcagtggcagtggatcagggacagatttcacactcaagatcaacagagtggaggctgaggatctgggagtttattactgc(SEQ ID NO:468)
(氨基酸)
GVPDRFSGSGSGTDFTLKINRVEAEDLGVYYC(SEQ ID NO:469)
小鼠C3轻链可变互补决定区3(CDR3)序列:
(DNA)
tttcaaggttcacatgttccattcacg(SEQ ID NO:470)
(氨基酸)
FQGSHVPFT(SEQ ID NO:471)
IGKV2-29*03轻链可变区序列:
(DNA)
gatattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgcaagtctagtcagagcctcctgcatagtgatggaaagacctatttgtattggtacctgcagaagccaggccagtctccacagctcctgatctatgaagtttccagccggttctctggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgcatgcaaggtatacaccttcct(SEQ ID NO:472)
(氨基酸)
DIVMTQTPLSLSVTPGQPASISCKSSQSLLHSDGKTYLYWYLQKPGQSPQLLIYEVSSRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCMQGIHLP(SEQ ID NO:473)
IGKV2-29*03轻链可变框架区1(FWR1)酸序列:
(DNA)
gatattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgc(SEQ ID NO:474)
(氨基酸)
DIVMTQTPLSLSVTPGQPASISC(SEQ ID NO:475)
IGKV2-29*03轻链可变互补决定区1(CDR1)序列:
(DNA)
aagtctagtcagagcctcctgcatagtgatggaaagacctatttgtat(SEQ ID NO:476)
(氨基酸)
KSSQSLLHSDGKTYLY(SEQ ID NO:477)
IGKV2-29*03轻链可变框架区2(FWR2)序列:
(DNA)
tggtacctgcagaagccaggccagtctccacagctcctgatctat(SEQ ID NO:478)
(氨基酸)
WYLQKPGQSPQLLIY(SEQ ID NO:479)
IGKV2-29*03轻链可变互补决定区2(CDR2)序列:
(DNA)
gaagtttccagccggttc(SEQ ID NO:480)
(氨基酸)
EVSSRFS(SEQ ID NO:481)
IGKV2-29*03轻链可变框架区3(FWR3)序列:
(DNA)
ggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgc(SEQ ID NO:482)
(氨基酸)
GVPDRFSGSGSGTDFTLKISRVEAEDVGVYYC(SEQ ID NO:483)
IGKV2-29*03轻链可变互补决定区3(CDR3)序列:
(DNA)
atgcaaggtatacaccttcct(SEQ ID NO:484)
(氨基酸)
MQGIHLP(SEQ ID NO:485)
人源化C3轻链可变区序列:
(DNA)
gatattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgcaggtctagtcagaccattgtccatagtaatggaaacacctatttggagtggtacctgcagaagccaggccagtctccacagctcctgatctataaggtttccaaccggttctctggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgcttccaaggtagccacgtgcctttcaccttcggcggagggaccaaggtggagatcaaacgaact(SEQ ID NO:486)
(氨基酸)
DIVMTQTPLSLSVTPGQPASISCRSSQTIVHSNGNTYLEWYLQKPGQSPQLLIYKVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPFTFGGGTKVEIKRT(SEQ ID NO:487)
人源化C3轻链可变框架区1(FWR1)酸序列:
(DNA)
gatattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgc(SEQ ID NO:488)
(氨基酸)
DIVMTQTPLSLSVTPGQPASISC(SEQ ID NO:489)
人源化C3轻链可变互补决定区1(CDR1)序列:
(DNA)
ggtctagtcagaccattgtccatagtaatggaaacacctatttggag(SEQ ID NO:490)
(氨基酸)
RSSQTIVHSNGNTYLE(SEQ ID NO:491)
人源化C3轻链可变框架区2(FWR2)酸序列:
(DNA)
tggtacctgcagaagccaggccagtctccacagctcctgatctat(SEQ ID NO:492)
(氨基酸)
WYLQKPGQSPQLLIY(SEQ ID NO:493)
人源化C3轻链可变互补决定区2(CDR2)序列:
(DNA)
aaggtttccaaccggttctct(SEQ ID NO:494)
(氨基酸)
KVSNRFS(SEQ ID NO:495)
人源化C3轻链可变框架区3(FWR3)酸序列:
(DNA)
ggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgc(SEQ ID NO:496)
(氨基酸)
GVPDRFSGSGSGTDFTLKISRVEAEDVGVYYC(SEQ ID NO:497)
人源化C3轻链可变互补决定区3(CDR3)序列:
(DNA)
ttccaaggtagccacgtgcctttcacc(SEQ ID NO:498)
(氨基酸)
FQGSHVPFT(SEQ ID NO:499)
人源化C3λ轻链序列
(DNA)
gatattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgcaggtctagtcagaccattgtccatagtaatggaaacacctatttggagtggtacctgcagaagccaggccagtctccacagctcctgatctataaggtttccaaccggttctctggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgcttccaaggtagccacgtgcctttcaccttcggcggagggaccaaggtggagatcaaacgaactggtcagcccaaggctgccccctcggtcactctgttcccgccctcctctgaggagcttcaagccaacaaggccacactggtgtgtctcataagtgacttctacccgggagccgtgacagtggcctggaaggcagatagcagccccgtcaaggcgggagtggagaccaccacaccctccaaacaaagcaacaacaagtacgcggccagcagctatctgagcctgacgcctgagcagtggaagtcccacagaagctacagctgccaggtcacgcatgaagggagcaccgtggagaagacagtggcccctacagaatgttcatagtaa(SEQ ID NO:500)
(氨基酸)
DIVMTQTPLSLSVTPGQPASISCRSSQTIVHSNGNTYLEWYLQKPGQSPQLLIYKVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPFTFGGGTKVEIKRTGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKADSSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGSTVEKTVAPTECS**(SEQ ID NO:501)
人源化C3κ轻链
(DNA)
gatattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgcaggtctagtcagaccattgtccatagtaatggaaacacctatttggagtggtacctgcagaagccaggccagtctccacagctcctgatctataaggtttccaaccggttctctggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgcttccaaggtagccacgtgcctttcaccttcggcggagggaccaaggtggagatcaaacgaactacggtggctgcaccatctgtcttcatcttcccgccatctgatgagcagttgaaatctggaactgcctctgttgtgtgcctgctgaataacttctatcccagagaggccaaagtacagtggaaggtggataacgccctccaatcgggtaactcccaggagagtgtcacagagcaggacagcaaggacagcacctacagcctcagcagcaccctgacgctgagcaaagcagactacgagaaacacaaagtctacgcctgcgaagtcacccatcagggcctgagctcgcccgtcacaaagagcttcaacaggggagagtgttagtaa(SEQ ID NO:502)
(氨基酸)
DIVMTQTPLSLSVTPGQPASISCRSSQTIVHSNGNTYLEWYLQKPGQSPQLLIYKVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPFTFGGGTKVEIKRTTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC**(SEQ ID NO:503)
人源化C3κ轻gBLOCK序列:
(DNA)
agctggctaggtaagcttggtaccgagctcggatccacgccaccatggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgacgatattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgcaggtctagtcagaccattgtccatagtaatggaaacacctatttggagtggtacctgcagaagccaggccagtctccacagctcctgatctataaggtttccaaccggttctctggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgcttccaaggtagccacgtgcctttcaccttcggcggagggaccaaggtggagatcaaacgaactacggtggctgcaccatctgtcttcatcttcccgccatctgatgagcagttgaaatctggaactgcctctgttgtgtgcctgctgaataacttctatcccagagaggccaaagtacagtggaaggtggataacgccctccaatcgggtaactcccaggagagtgtcacagagcaggacagcaaggacagcacctacagcctcagcagcaccctgacgctgagcaaagcagactacgagaaacacaaagtctacgcctgcgaagtcacccatcagggcctgagctcgcccgtcacaaagagcttcaacaggggagagtgttagtaagtttaaacccgctgatcagcctcgactgtgccttctagttgc(SEQ ID NO:504)
小鼠C8重链可变区序列
(DNA)
gaagtgatggtcgtggaaagcggcggtggtctggtaaagccggggggatcccttaagctttcttgcgccgcatccgggttcacgttctccggctatgccatgtcctgggtccgacagactcccgaaaagcgcttggaatgggtggccactatctcctccggggggacgtacatctactaccccgacagtgtgaaaggaagatttacaatatctcgcgacaacgcaaaaaataccttgtatcttcaaatgagctccctgcggtcagaggacactgccatgtactattgcgcccgcctgggcggcgacaattactatgagtat(SEQ ID NO:505)
(氨基酸)
EVMVVESGGGLVKPGGSLKLSCAASGFTFSGYAMSWVRQTPEKRLEWVATISSGGTYIYYPDSVKGRFTISRDNAKNTLYLQMSSLRSEDTAMYYCARLGGDNYYEY(SEQ ID NO:506)
小鼠C8重链可变互补决定区1(CDR1)序列:
(DNA)
ggctatgccatgtcc(SEQ ID NO:507)
(氨基酸)
GYAMS(SEQ ID NO:508)
小鼠C8重链可变互补决定区2(CDR2)序列:
(DNA)
actatctcctccggggggacgtacatctactaccccgacagtgtgaaagga(SEQ ID NO:509)
(氨基酸)
TISSGGTYIYYPDSVKG(SEQ ID NO:510)
小鼠C8重链可变互补决定区3(CDR3)序列:
(DNA)
ctgggcggcgacaattactatgagtat(SEQ ID NO:511)
(氨基酸)
LGGDNYYEY(SEQ ID NO:512)
IGHV3-21*04重链可变区序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtagctatagcatgaactgggtccgccaggctccagggaaggggctggagtgggtctcatccattagtagtagtagtagttacatatactacgcagactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcga(SEQ ID NO:513)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYSMNWVRQAPGKGLEWVSSISSSSSYIYYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAR(SEQ ID NO:514)
IGHV3-21*04重链可变框架区1(FWR1)序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagt(SEQ ID NO:515)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFS(SEQ ID NO:516)
IGHV3-21*04重链可变互补决定区1(CDR1)序列:
(DNA)
agctatagcatgaac(SEQ ID NO:517)
(氨基酸)
SYSMN(SEQ ID NO:518)
IGHV3-21*04重链可变框架区2(FWR2)序列:
(DNA)
tgggtccgccaggctccagggaaggggctggagtgggtc(SEQ ID NO:519)
(氨基酸)
WVRQAPGKGLEWV(SEQ ID NO:520)
IGHV3-21*04重链可变互补决定区2(CDR2)序列:
(DNA)
tcatccattagtagtagtagtagttacatatactacgcagactcagtgaagggc(SEQ ID NO:521)
(氨基酸)
SSISSSSSYIYYADSVKG(SEQ ID NO:522)
IGHV3-21*04重链可变框架区3(FWR3)序列:
(DNA)
cgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcga(SEQ ID NO:523)
(氨基酸)
RFTISRDNAKNSLYLQMNSLRAEDTAVYYCAR(SEQ ID NO:524)
人源化C8重链可变区序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccctgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagactgggcggcgataactattatgaatattggggcaaagggaccacggtcaccgtctcctcc(SEQ ID NO:525)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYWGKGTTVTVSS(SEQ ID NO:526)
人源化C8重链可变框架区1(FWR1)序列:
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagt(SEQ ID NO:527)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFS(SEQ ID NO:528)
人源化C8重链可变互补决定区1(CDR1)序列:
(DNA)
ggctatgccatgagc(SEQ ID NO:529)
(氨基酸)
GYAMS(SEQ ID NO:530)
人源化C8重链可变框架区2(FWR2)序列:
(DNA)
tgggtccgccaggctccagggaaggggctggagtgggtctca(SEQ ID NO:531)
(氨基酸)
WVRQAPGKGLEWVS(SEQ ID NO:532)
人源化C8重链可变互补决定区2(CDR2)序列:
(DNA)
accattagtagtggcggaacctacatatactaccctgactcagtgaagggc(SEQ ID NO:533)
(氨基酸)
TISSGGTYIYYPDSVKG(SEQ ID NO:534)
人源化C8重链可变框架区3(FWR3)序列:
(DNA)
cgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgaga(SEQ ID NO:535)
(氨基酸)
RFTISRDNAKNSLYLQMNSLRAEDTAVYYCAR(SEQ ID NO:536)
人源化C8重链可变互补决定区3(CDR3)序列:
(DNA)
ctgggcggcgataactattatgaatat(SEQ ID NO:537)
(氨基酸)
LGGDNYYEY(SEQ ID NO:538)
人源化C8IgG1重链序列
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccctgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagactgggcggcgataactattatgaatattggggcaaagggaccacggtcaccgtctcctccgctagcaccaagggcccatcggtcttccccctggcaccctcctccaagagcacctctgggggcacagcggccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgccctgaccagcggcgtgcacaccttcccggctgtcctacagtcctcaggactctactccctcagcagcgtggtgacagtgccctccagcagcttgggcacccagacctacatctgcaacgtgaatcacaagcccagcaacaccaaggtggacaagaaagttgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgataa(SEQ ID NO:539)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYWGKGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:540)
人源化C8 IgG2重链序列
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccctgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagactgggcggcgataactattatgaatattggggcaaagggaccacggtcaccgtctcctccgcctccaccaagggcccatcggtcttccccctggcgccctgctccaggagcacctccgagagcacagccgccctgggctgcctggtcaaggactacttccccgaaccggtgacggtgtcgtggaactcaggcgctctgaccagcggcgtgcacaccttcccagctgtcctacagtcctcaggactctactccctcagcagcgtggtgaccgtgccctccagcaacttcggcacccagacctacacctgcaacgtagatcacaagcccagcaacaccaaggtggacaagacagttgagcgcaaatgttgtgtcgagtgcccaccgtgcccagcaccacctgtggcaggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacgtgcgtggtggtggacgtgagccacgaagaccccgaggtccagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccacgggaggagcagttcaacagcacgttccgtgtggtcagcgtcctcaccgttgtgcaccaggactggctgaacggcaaggagtacaagtgcaaggtctccaacaaaggcctcccagcccccatcgagaaaaccatctccaaaaccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctaccccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacacctcccatgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatagtaa(SEQ ID NO:541)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYWGKGTTVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSNFGTQTYTCNVDHKPSNTKVDKTVERKCCVECPPCPAPPVAGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTFRVVSVLTVVHQDWLNGKEYKCKVSNKGLPAPIEKTISKTKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPMLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK**(SEQ ID NO:542)
小鼠C8轻链可变区序列
(DNA)
gacatcgtcattacgcagacccctgccagtcttgccgtttctctgggccagagggccactatcagttacagggcgagtaagtctgtgagtaccagcggctatagttacatgcattggaaccagcagaaaccgggacagccaccacgcctgcttatttatctggtgtctaatcttgagtccggggtgcccgccaggttcagcggcagcggctctgggaccgacttcacactcaacattcatccagtggaagaagaggacgctgctacatactactgtcaacacattcgggaactgaccaggagtgaa(SEQ ID NO:543)
(氨基酸)
DIVITQTPASLAVSLGQRATISYRASKSVSTSGYSYMHWNQQKPGQPPRLLIYLVSNLESGVPARFSGSGSGTDFTLNIHPVEEEDAATYYCQHIRELTRSE(SEQ ID NO:544)
小鼠C8轻链可变互补决定区1(CDR1)序列:
(DNA)
agggcgagtaagtctgtgagtaccagcggctatagttacatgcat(SEQ ID NO:545)
(氨基酸)
RASKSVSTSGYSYMH(SEQ ID NO:546)
小鼠C8轻链可变互补决定区2(CDR2)序列:
(DNA)
ctggtgtctaatcttgagtcc(SEQ ID NO:547)
(氨基酸)
LVSNLES(SEQ ID NO:548)
小鼠C8轻链可变互补决定区3(CDR3)序列:
(DNA)
caacacattcgggaactgaccaggagtgaa(SEQ ID NO:549)
(氨基酸)
QHIRELTRSE(SEQ ID NO:550)
NCBI种系z00023轻链可变区序列:
(DNA)
gacatcgtgatgacccagtctccagactccctggctgtgtctctgggcgagagggccaccatcaactgcaagtccagccagagtgttttatacagctccaacaataagaactacttagcttggtaccagcagaaaccaggacagcctcctaagctgctcatttactgggcatctacccgggaatccggggtccctgaccgattcagtggcagcgggtctgggacagatttcactctcaccatcagcagcctgcaggctgaagatgtggcagtttattactgtcagcaatattatagtactcct(SEQ ID NO:551)
(氨基酸)
DIVMTQSPDSLAVSLGERATINCKSSQSVLYSSNNKNYLAWYQQKPGQPPKLLIYWASTRESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCQQYYSTP(SEQ ID NO:552)
NCBI种系z00023轻链可变框架区1(FWR1)酸序列:
(DNA)
gacatcgtgatgacccagtctccagactccctggctgtgtctctgggcgagagggccaccatcaactgc(SEQ ID NO:553)
(氨基酸)
DIVMTQSPDSLAVSLGERATINC(SEQ ID NO:554)
NCBI种系z00023轻链可变互补决定区1(CDR1)序列:
(DNA)
aagtccagccagagtgttttatacagctccaacaataagaactacttagct(SEQ ID NO:555)
(氨基酸)
KSSQSVLYSSNNKNYLA(SEQ ID NO:556)
NCBI种系z00023轻链可变框架区2(FWR2)序列:
(DNA)
tggtaccagcagaaaccaggacagcctcctaagctgctcatttac(SEQ ID NO:557)
(氨基酸)
WYQQKPGQPPKLLIY(SEQ ID NO:558)
NCBI种系z00023轻链可变互补决定区2(CDR2)序列:
(DNA)
tgggcatctacccgggaatcc(SEQ ID NO:559)
(氨基酸)
WASTRES(SEQ ID NO:560)
NCBI种系z00023轻链可变框架区3(FWR3)序列:
(DNA)
ggggtccctgaccgattcagtggcagcgggtctgggacagatttcactctcaccatcagcagcctgcaggctgaagatgtggcagtttattactgt(SEQ ID NO:561)
(氨基酸)
GVPDRFSGSGSGTDFTLTISSLQAEDVAVYYC(SEQ ID NO:562)
NCBI种系z00023轻链可变互补决定区3(CDR3)序列:
(DNA)
cagcaatattatagtactcct(SEQ ID NO:563)
(氨基酸)
QQYYSTP(SEQ ID NO:564)
人源化C8轻链可变区序列
(DNA)
gacatcgtgatgacccagtctccagactccctggctgtgtctctgggcgagagggccaccatcaactgcagggccagcaagagtgttagcaccagcggctacagctacatgcactggtaccagcagaaaccaggacagcctcctaagctgctcatttacctggtgtctaacctggaatccggggtccctgaccgattcagtggcagcgggtctgggacagatttcactctcaccatcagcagcctgcaggctgaagatgtggcagtttattactgtcaacacattcgggaactgaccaggagtgaattcggcggagggaccaaggtggagatcaaacgaact(SEQ ID NO:565)
(氨基酸)
DIVMTQSPDSLAVSLGERATINCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLVSNLESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCQHIRELTRSEFGGGTKVEIKRT(SEQ ID NO:566)
人源化C8轻链可变框架区1(FWR1)序列:
(DNA)
gacatcgtgatgacccagtctccagactccctggctgtgtctctgggcgagagggccaccatcaactgc(SEQ ID NO:567)
(氨基酸)
DIVMTQSPDSLAVSLGERATINC(SEQ ID NO:568)
人源化C8轻链可变互补决定区1(CDR1)序列:
(DNA)
agggccagcaagagtgttagcaccagcggctacagctacatg(SEQ ID NO:569)
(氨基酸)
RASKSVSTSGYSYM(SEQ ID NO:570)
人源化C8轻链可变框架区2(FWR2)序列:
(DNA)
cactggtaccagcagaaaccaggacagcctcctaagctgctcatttac(SEQ ID NO:571)
(氨基酸)
HWYQQKPGQPPKLLIY(SEQ ID NO:572)
人源化C8轻链可变互补决定区2(CDR2)序列:
(DNA)
ctggtgtctaacctggaatcc(SEQ ID NO:573)
(氨基酸)
LVSNLES(SEQ ID NO:574)
人源化C8轻链可变框架区3(FWR3)序列:
(DNA)
ggggtccctgaccgattcagtggcagcgggtctgggacagatttcactctcaccatcagcagcctgcaggctgaagatgtggcagtttattactgt(SEQ ID NO:575)
(氨基酸)
GVPDRFSGSGSGTDFTLTISSLQAEDVAVYYC(SEQ ID NO:576)
人源化C8轻链可变互补决定区3(CDR3)序列:
(DNA)
caacacattcgggaactgaccaggagtgaa(SEQ ID NO:577)
(氨基酸)
QHIRELTRSE(SEQ ID NO:578)
人源化C8λ轻链序列
(DNA)
gacatcgtgatgacccagtctccagactccctggctgtgtctctgggcgagagggccaccatcaactgcagggccagcaagagtgttagcaccagcggctacagctacatgcactggtaccagcagaaaccaggacagcctcctaagctgctcatttacctggtgtctaacctggaatccggggtccctgaccgattcagtggcagcgggtctgggacagatttcactctcaccatcagcagcctgcaggctgaagatgtggcagtttattactgtcaacacattcgggaactgaccaggagtgaattcggcggagggaccaaggtggagatcaaacgaactggtcagcccaaggctgccccctcggtcactctgttcccgccctcctctgaggagcttcaagccaacaaggccacactggtgtgtctcataagtgacttctacccgggagccgtgacagtggcctggaaggcagatagcagccccgtcaaggcgggagtggagaccaccacaccctccaaacaaagcaacaacaagtacgcggccagcagctatctgagcctgacgcctgagcagtggaagtcccacagaagctacagctgccaggtcacgcatgaagggagcaccgtggagaagacagtggcccctacagaatgttcatagtaa(SEQ ID NO:579)
(氨基酸)
DIVMTQSPDSLAVSLGERATINCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLVSNLESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCQHIRELTRSEFGGGTKVEIKRTGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKADSSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGSTVEKTVAPTECS**(SEQ ID NO:580)
人源化C8κ轻链序列
(DNA)
gacatcgtgatgacccagtctccagactccctggctgtgtctctgggcgagagggccaccatcaactgcagggccagcaagagtgttagcaccagcggctacagctacatgcactggtaccagcagaaaccaggacagcctcctaagctgctcatttacctggtgtctaacctggaatccggggtccctgaccgattcagtggcagcgggtctgggacagatttcactctcaccatcagcagcctgcaggctgaagatgtggcagtttattactgtcaacacattcgggaactgaccaggagtgaattcggcggagggaccaaggtggagatcaaacgaactacggtggctgcaccatctgtcttcatcttcccgccatctgatgagcagttgaaatctggaactgcctctgttgtgtgcctgctgaataacttctatcccagagaggccaaagtacagtggaaggtggataacgccctccaatcgggtaactcccaggagagtgtcacagagcaggacagcaaggacagcacctacagcctcagcagcaccctgacgctgagcaaagcagactacgagaaacacaaagtctacgcctgcgaagtcacccatcagggcctgagctcgcccgtcacaaagagcttcaacaggggagagtgttagtaa(SEQ ID NO:581)
(氨基酸)
DIVMTQSPDSLAVSLGERATINCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLVSNLESGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCQHIRELTRSEFGGGTKVEIKRTTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC**(SEQ ID NO:582)
人源化C8K轻链gBLOCK序列:
(DNA)
agctggctaggtaagcttggtaccgagctcggatccacgccaccatggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgacgacatcgtgatgacccagtctccagactccctggctgtgtctctgggcgagagggccaccatcaactgcagggccagcaagagtgttagcaccagcggctacagctacatgcactggtaccagcagaaaccaggacagcctcctaagctgctcatttacctggtgtctaacctggaatccggggtccctgaccgattcagtggcagcgggtctgggacagatttcactctcaccatcagcagcctgcaggctgaagatgtggcagtttattactgtcaacacattcgggaactgaccaggagtgaattcggcggagggaccaaggtggagatcaaacgaactacggtggctgcaccatctgtcttcatcttcccgccatctgatgagcagttgaaatctggaactgcctctgttgtgtgcctgctgaataacttctatcccagagaggccaaagtacagtggaaggtggataacgccctccaatcgggtaactcccaggagagtgtcacagagcaggacagcaaggacagcacctacagcctcagcagcaccctgacgctgagcaaagcagactacgagaaacacaaagtctacgcctgcgaagtcacccatcagggcctgagctcgcccgtcacaaagagcttcaacaggggagagtgttagtaagtttaaacccgctgatcagcctcgactgtgccttctagttgc(SEQ ID NO:583)
CAR-T E6 CD8序列:
(DNA)
gaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaaacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgctgataa(SEQ ID NO:584)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYC**(SEQ ID NO:585)
CAR-T C2 CD8 CD8序列:
N-CD8ls-huMNC2scFv-CD8ecd片段-CD8跨膜-C
(DNA)
gaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaaccacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgctgataa(SEQ ID NO:586)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYC**(SEQ ID NO:587)
CD8/4-1BB序列
N-CD8跨膜-4-1BB-C
(DNA)
acgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgtgataa(SEQ ID NO:588)
(氨基酸)
TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL**(SEQ ID NO:589)
CD8/CD28序列
N-CD8跨膜-CD28-C
(DNA)
acgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcctgataa(SEQ ID NO:590)
(氨基酸)
TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS**(SEQ ID NO:591)
CD8/CD3z序列:
N-CD8跨膜-CD3ζ-C
(DNA)
acgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:592)
(氨基酸)
TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:593)
CD8/CD28/CD3z序列:
N-CD8跨膜-CD28-CD3ζ-C
(DNA)
acgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:594)
(氨基酸)
TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:595)
CD8/4-1BB/CD3z序列:
N-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
acgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:596)
(氨基酸)
TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:597)
CD8/CD28/4-1BB/CD3z序列:
N-CD8跨膜-CD28-4-1BB-CD3ζ-C
(DNA)
acgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtccaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:598)
(氨基酸)
TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:599)
CAR-T C3CD8/CD8/4-1BB/CD3z序列:
N-CD8ls-huMNC3scFv-CD8ecd片段-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccacaggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttaccgactacgccatgaactgggtgcgacaggcccctggacaagggcttgagtggatgggagtgatcagcaccttcagcggtaacacaaacttcaaccagaagttcaagggcagagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgagaagcgactactacggcccatacttcgactactggggccagggcaccaccctgaccgtgtccagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgcaggtctagtcagaccattgtccatagtaatggaaacacctatttggagtggtacctgcagaagccaggccagtctccacagctcctgatctataaggtttccaaccggttctctggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgcttccaaggtagccacgtgcctttcaccttcggcggagggaccaaggtggagatcaaacgaactacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:600)
(氨基酸)
QVQLVQSGAEVKKPGASVKVSCKASGYTFTDYAMNWVRQAPGQGLEWMGVISTFSGNTNFNQKFKGRVTMTTDTSTSTAYMELRSLRSDDTAVYYCARSDYYGPYFDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIVMTQTPLSLSVTPGQPASISCRSSQTIVHSNGNTYLEWYLQKPGQSPQLLIYKVSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDVGVYYCFQGSHVPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:601)
C3 CAR gBLOCK 1序列:
(DNA)
atccacgctgttttgacctccatagaagattctagagctagctgtagagcttggtaccgagggccaccatggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccacaggttcagctggtgcagtctggagctgaggtgaagaagcctggggcctcagtgaaggtctcctgcaaggcttctggttacacctttaccgactacgccatgaactgggtgcgacaggcccctggacaagggcttgagtggatgggagtgatcagcaccttcagcggtaacacaaacttcaaccagaagttcaagggcagagtcaccatgaccacagacacatccacgagcacagcctacatggagctgaggagcctgagatctgacgacacggccgtgtattactgtgcgagaagcgactactacggcccatacttcgactactggggccagggcaccaccctgaccgtgtccagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattgtgatgacccagactccactctctctgt(SEQ ID NO:602)
C3 CAR gBLOCK 2序列:
(DNA)
tattgtgatgacccagactccactctctctgtccgtcacccctggacagccggcctccatctcctgcaggtctagtcagaccattgtccatagtaatggaaacacctatttggagtggtacctgcagaagccaggccagtctccacagctcctgatctataaggtttccaaccggttctctggagtgccagataggttcagtggcagcgggtcagggacagatttcacactgaaaatcagccgggtggaggctgaggatgttggggtttattactgcttccaaggtagccacgtgcctttcaccttcggcggagggaccaaggtggagatcaaacgaactacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtg(SEQ ID NO:603)
E6 scFV gBLOCK 1序列:
(DNA)
tgctctgggttccaggttccactggtgacgcggcccagccggccgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtaggtatggcatgagctgggtccgccaggctccagggaagaggctggagtgggtctcaaccattagtggcggaggcacctacatatactacccagactcagtgaagggccgattcaccatctccagagacaacgccaagaacaccctgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtaccagagataactatggccgcaactatgattatggcatggattattggggccagggcaccctggtgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatcc(SEQ ID NO:604)
E6 scFV gBLOCK 2序列:
(DNA)
ggcggtggcggatccggcggtggcggatccggcggtggcggatccgaaattgtgttgacacagtctccagccaccctgtctttgtctccaggggaaagagccaccctcacctgcagcgccaccagcagtgttagctacatccactggtaccaacagaggcctggccagagccccaggctcctcatctatagcacctccaacctggccagcggcatcccagccaggttcagtggcagtgggtctgggagcgactacactctcaccatcagcagcctagagcctgaagattttgcagtttattactgtcagcagcgtagcagctcccctttcacctttggcagcggcaccaaagtggaaattaaaaccggtcatcatcaccatcaccactgataagtttaaacccgctgatcagcctcgactgtgccttctagt(SEQ ID NO:605)
CAR-T C2 CD8/CD8/CD3z序列:
N-CD8ls-huMNC2scFv-CD8ecd片段-CD8跨膜-CD3ζ-C
(DNA)
atggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaaccacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:606)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:607)
CAR-T C2 CD8/CD8/CD28/CD3z序列:
N-CD8ls-huMNC2scFv-CD8ecd片段-CD8跨膜-CD28-CD3ζ-C
(DNA)
atggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaaccacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ IDNO:608)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:609)
CAR-T C2 CD8/CD8/4-1BB/CD3z序列#13:
N-CD8ls-huMNC2scFv-CD8ecd片段-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaaccacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:610)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:611)
CAR-T C2 CD8/CD8/OX40/CD3z序列:
N-CD8ls-huMNC2scFv-CD8ecd片段-CD8跨膜-OX40-CD3ζ-C
(DNA)
atggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaaccacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgccggagggaccagaggctgccccccgatgcccacaagccccctgggggaggcagtttccggacccccatccaagaggagcaggccgacgcccactccaccctggccaagatccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:612)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKIRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:613)
CAR-T C2 CD8/CD8/CD28/OX40/CD3z序列:
N-CD8ls-huMNC2scFv-CD8ecd片段-CD8跨膜-CD28-OX40-CD3ζ-C
(DNA)
atggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaaccacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcccggagggaccagaggctgccccccgatgcccacaagccccctgggggaggcagtttccggacccccatccaagaggagcaggccgacgcccactccaccctggccaagatccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:614)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKIRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:615)
CAR-T E6 CD8/CD8/OX40/CD3z序列:
N-CD8ls-huMNE6scFv-CD8ecd片段-CD8跨膜-OX40-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaaacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgccggagggaccagaggctgccccccgatgcccacaagccccctgggggaggcagtttccggacccccatccaagaggagcaggccgacgcccactccaccctggccaagatccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:616)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKIRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:617)
CAR-T E6 CD8/CD8/CD28/OX40/CD3z序列:
N-CD8ls-huMNC2scFv-CD8ecd片段-CD8跨膜-CD28-OX40-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaaacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcccggagggaccagaggctgccccccgatgcccacaagccccctgggggaggcagtttccggacccccatccaagaggagcaggccgacgcccactccaccctggccaagatccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:618)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKIRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:619)
MUC1截短细胞质序列
(氨基酸)
SNIKFRPGSVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NO:620)
MUC1截短细胞质序列
(氨基酸)
SVVVQLTLAFREGTINVHDVETQFNQYKTEAASRY(SEQ ID NO:621)
MUC1截短细胞质序列
(氨基酸)
VQLTLAFREGTINVHDVETQFNQY(SEQ ID NO:622)
MUC1截短细胞质序列
(氨基酸)
SNIKFRPGSVVVQLTLAFREGTIN(SEQ ID NO:623)
引物
attctaagcttgggccaccatggaactg(SEQ ID NO:624)tctagagtttaaacttactatttacccggagacagggagag(SEQ ID NO:625)
agtatggcccagccggccgaggtgcagctggtggagtctgg(SEQ ID NO:626)
tagaaggcacagtcgaggctgatcag(SEQ ID NO:627)
attctaagcttgggccaccatggaagc(SEQ ID NO:628)
tctagagtttaaacttactaacactctcccctgttgaagc(SEQ ID NO:629)
agtatggcccagccggccgaaattgtgttgacacagtctccag(SEQ ID NO:630)
tagaaggcacagtcgaggctgatcag(SEQ ID NO:631)
actgtcatatggaggtgcagctggtggagtctg(SEQ ID NO:632)actgtctcgagtttaatttccactttggtgccgctgc(SEQ ID NO:633)
actgtcatatggaggtgcagctggtggagtctg(SEQ ID NO:634)actgtaccggttttaatttccactttggtgccgctgc(SEQ ID NO:635)
cttcttcctcaggagcaagctcaccgtgg(SEQ ID NO:636)
gagccgtcggagtccagc(SEQ ID NO:637)
gcacctgaactcctgggg(SEQ ID NO:638)
tttaatttccactttggtgccg(SEQ ID NO:639)
cgcggctagcttaagcttggtaccgagggcca(SEQ ID NO:640)
cgcggcggccgcctgatcagcgggtttaaacttatc(SEQ ID NO:641)
MMP9
(DNA)
atgagcctctggcagcccctggtcctggtgctcctggtgctgggctgctgctttgctgcccccagacagcgccagtccacccttgtgctcttccctggagacctgagaaccaatctcaccgacaggcagctggcagaggaatacctgtaccgctatggttacactcgggtggcagagatgcgtggagagtcgaaatctctggggcctgcgctgctgcttctccagaagcaactgtccctgcccgagaccggtgagctggatagcgccacgctgaaggccatgcgaaccccacggtgcggggtcccagacctgggcagattccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgagccacggcctccaaccaccaccacaccgcagcccacggctcccccgacggtctgccccaccggaccccccactgtccacccctcagagcgccccacagctggccccacaggtcccccctcagctggccccacaggtccccccactgctggcccttctacggccactactgtgcctttgagtccggtggacgatgcctgcaacgtgaacatcttcgacgccatcgcggagattgggaaccagctgtatttgttcaaggatgggaagtactggcgattctctgagggcagggggagccggccgcagggccccttccttatcgccgacaagtggcccgcgctgccccgcaagctggactcggtctttgaggagcggctctccaagaagcttttcttcttctctgggcgccaggtgtgggtgtacacaggcgcgtcggtgctgggcccgaggcgtctggacaagctgggcctgggagccgacgtggcccaggtgaccggggccctccggagtggcagggggaagatgctgctgttcagcgggcggcgcctctggaggttcgacgtgaaggcgcagatggtggatccccggagcgccagcgaggtggaccggatgttccccggggtgcctttggacacgcacgacgtcttccagtaccgagagaaagcctatttctgccaggaccgcttctactggcgcgtgagttcccggagtgagttgaaccaggtggaccaagtgggctacgtgacctatgacatcctgcagtgccctgaggacgattacaaggatgacgacgataagtgataa(SEQ ID NO:642)
(氨基酸)
MSLWQPLVLVLLVLGCCFAAPRQRQSTLVLFPGDLRTNLTDRQLAEEYLYRYGYTRVAEMRGESKSLGPALLLLQKQLSLPETGELDSATLKAMRTPRCGVPDLGRFQTFEGDLKWHHHNITYWIQNYSEDLPRAVIDDAFARAFALWSAVTPLTFTRVYSRDADIVIQFGVAEHGDGYPFDGKDGLLAHAFPPGPGIQGDAHFDDDELWSLGKGVVVPTRFGNADGAACHFPFIFEGRSYSACTTDGRSDGLPWCSTTANYDTDDRFGFCPSERLYTQDGNADGKPCQFPFIFQGQSYSACTTDGRSDGYRWCATTANYDRDKLFGFCPTRADSTVMGGNSAGELCVFPFTFLGKEYSTCTSEGRGDGRLWCATTSNFDSDKKWGFCPDQGYSLFLVAAHEFGHALGLDHSSVPEALMYPMYRFTEGPPLHKDDVNGIRHLYGPRPEPEPRPPTTTTPQPTAPPTVCPTGPPTVHPSERPTAGPTGPPSAGPTGPPTAGPSTATTVPLSPVDDACNVNIFDAIAEIGNQLYLFKDGKYWRFSEGRGSRPQGPFLIADKWPALPRKLDSVFEERLSKKLFFFSGRQVWVYTGASVLGPRRLDKLGLGADVAQVTGALRSGRGKMLLFSGRRLWRFDVKAQMVDPRSASEVDRMFPGVPLDTHDVFQYREKAYFCQDRFYWRVSSRSELNQVDQVGYVTYDILQCPEDDYKDDDDK**(SEQ ID NO:643)
MMP9催化结构域
(DNA)
atgttccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgattacaaggatgacgacgataagtgataa(SEQ ID NO:644)
(氨基酸)
MFQTFEGDLKWHHHNITYWIQNYSEDLPRAVIDDAFARAFALWSAVTPLTFTRVYSRDADIVIQFGVAEHGDGYPFDGKDGLLAHAFPPGPGIQGDAHFDDDELWSLGKGVVVPTRFGNADGAACHFPFIFEGRSYSACTTDGRSDGLPWCSTTANYDTDDRFGFCPSERLYTQDGNADGKPCQFPFIFQGQSYSACTTDGRSDGYRWCATTANYDRDKLFGFCPTRADSTVMGGNSAGELCVFPFTFLGKEYSTCTSEGRGDGRLWCATTSNFDSDKKWGFCPDQGYSLFLVAAHEFGHALGLDHSSVPEALMYPMYRFTEGPPLHKDDVNGIRHLYGPRPEPDYKDDDDK**(SEQ ID NO:645)
NFATc1启动子(NFATc1P)
(DNA)
aggcaggaggaagaggaaaggggcgcagggcgctcggggagcagagccgggggcccgcggtggccgcagaggccgggccggggcgcagaggccgggcgagctggccgcgctctgggccgccgcctccggaactccctgcgcctggcgcgcggccaccgtggtcccggcaacggcattaaacagagggaaacagacccgggattccgtcacccgggcggggggataaggacggctttgagagcagacaggaaaagggagcttttctgcatggggtgaaaaaattatttattgaaggaggaggaggcggcagcggaggaaggggaggggcgggaggaggaggaagagccggccgcccccgccccggccccggctcctcaggagccaagggcagcctcgccaggtcggtcccgggctcgaggaccgcggctggggtcgaggggctcagtctcccacgtgaccggctgggcgcgccccgccagacccggcctcgggattccctcctcccggcgagtctccgcccgccccgtcctggaggtggggagaaggagggcggggcgggggggacggaaactctccccgccaaatcctggccccaggcctggggacactcgcggcgggaagatttggaggggaggggagggggaggggcgtgggggcgcggcctcgctggagtccccctgaccccccgacccccgcccaccggcctgggcgtcctcccgcggcccctcctcccctcccggcgcccggtgctctggggcgcgtgccacgcctggctcggcgccgtaggggcccccgcaggtagagacccctggaaatggcctcgacgccgcaggagcgaggcggccaccaccccgctaatccgggcacgtctctccaggccgaggcctgcggtggaaaagccggggttccatttgtgctgagtcggggcggccgaatggagccaggcctcgggacgcgggacggacgggctctggccgcgcaccttcgcgggctctgcagcgcccgaccgcctcccccggcagggaggaggcgcttgtggggggcacccacggggcacagtgatccctgggggtctgcggacctcctgggccccgcagcagacacgagtttagcctttgggtttagtttaaatcacataagggtgtcgtgcaatcgatttatggtttctacacaccagacactttaacctccaaccccccccatccaagccaacaagaaaatgcggtgccgtgttggcagctgagctgcgcccgaagagacgcagggagacgtaagagaggaaagtgtgagtggccggggggcctccccccgtcagaagtcgcgcagtcgcgcccataaaacgccccctccgggcggctagggcaggtgagcgcgtccccgggcctccccacgccggcccctgccacagagccgtctaggtcgagcagatatttacagaataaaaatgacaataactcgacgtcccgggacggccacgcaatctgttagtaatttagcgggatgggaatttcctttctagggcctgccagtgaagcgcttttccaaatttccacagcgggggaagcctgcgattttacataatgacttcagcatgccgggctttctcgacacccctccccggcccccggcccccgccccccgccccttttccagcagggccgggctccctccggacacccgcgtggactcaggcgtcccgtctggcccgttcgcccccgtttcccccgccagccccagcgcccccctgcccggcccccggattccccgttcccgcccctacgcccccatcccctccccgtgcgcccctccccgtgcgcccccctccccgtgcgccccccctccccgtgcgcccccctccccgtgcgccccccctccccgggcgcccccctccccgggcgccccccctccccgtgcgcccccccctccccgtgcgccccccctccccgtgcgcgccccgcctcttgcgcccctgcccccaggcgagcggctgccgcggcgcggggaggggcgggcgctcggcgactcgtccccggggccccgcgcgggcccgggcagcaggggcgtgatgtcacggcagggagggggcgcgggagccgccgggccggcggggaggcgggggaggtgttttccagctttaaaaaggcaggaggcagagcgcggccctgcgtcagagcgagactcagagg(SEQ ID NO:646)
NFATc1P-MMP9
(DNA)
aggcaggaggaagaggaaaggggcgcagggcgctcggggagcagagccgggggcccgcggtggccgcagaggccgggccggggcgcagaggccgggcgagctggccgcgctctgggccgccgcctccggaactccctgcgcctggcgcgcggccaccgtggtcccggcaacggcattaaacagagggaaacagacccgggattccgtcacccgggcggggggataaggacggctttgagagcagacaggaaaagggagcttttctgcatggggtgaaaaaattatttattgaaggaggaggaggcggcagcggaggaaggggaggggcgggaggaggaggaagagccggccgcccccgccccggccccggctcctcaggagccaagggcagcctcgccaggtcggtcccgggctcgaggaccgcggctggggtcgaggggctcagtctcccacgtgaccggctgggcgcgccccgccagacccggcctcgggattccctcctcccggcgagtctccgcccgccccgtcctggaggtggggagaaggagggcggggcgggggggacggaaactctccccgccaaatcctggccccaggcctggggacactcgcggcgggaagatttggaggggaggggagggggaggggcgtgggggcgcggcctcgctggagtccccctgaccccccgacccccgcccaccggcctgggcgtcctcccgcggcccctcctcccctcccggcgcccggtgctctggggcgcgtgccacgcctggctcggcgccgtaggggcccccgcaggtagagacccctggaaatggcctcgacgccgcaggagcgaggcggccaccaccccgctaatccgggcacgtctctccaggccgaggcctgcggtggaaaagccggggttccatttgtgctgagtcggggcggccgaatggagccaggcctcgggacgcgggacggacgggctctggccgcgcaccttcgcgggctctgcagcgcccgaccgcctcccccggcagggaggaggcgcttgtggggggcacccacggggcacagtgatccctgggggtctgcggacctcctgggccccgcagcagacacgagtttagcctttgggtttagtttaaatcacataagggtgtcgtgcaatcgatttatggtttctacacaccagacactttaacctccaaccccccccatccaagccaacaagaaaatgcggtgccgtgttggcagctgagctgcgcccgaagagacgcagggagacgtaagagaggaaagtgtgagtggccggggggcctccccccgtcagaagtcgcgcagtcgcgcccataaaacgccccctccgggcggctagggcaggtgagcgcgtccccgggcctccccacgccggcccctgccacagagccgtctaggtcgagcagatatttacagaataaaaatgacaataactcgacgtcccgggacggccacgcaatctgttagtaatttagcgggatgggaatttcctttctagggcctgccagtgaagcgcttttccaaatttccacagcgggggaagcctgcgattttacataatgacttcagcatgccgggctttctcgacacccctccccggcccccggcccccgccccccgccccttttccagcagggccgggctccctccggacacccgcgtggactcaggcgtcccgtctggcccgttcgcccccgtttcccccgccagccccagcgcccccctgcccggcccccggattccccgttcccgcccctacgcccccatcccctccccgtgcgcccctccccgtgcgcccccctccccgtgcgccccccctccccgtgcgcccccctccccgtgcgccccccctccccgggcgcccccctccccgggcgccccccctccccgtgcgcccccccctccccgtgcgccccccctccccgtgcgcgccccgcctcttgcgcccctgcccccaggcgagcggctgccgcggcgcggggaggggcgggcgctcggcgactcgtccccggggccccgcgcgggcccgggcagcaggggcgtgatgtcacggcagggagggggcgcgggagccgccgggccggcggggaggcgggggaggtgttttccagctttaaaaaggcaggaggcagagcgcggccctgcgtcagagcgagactcagaggtctagagccaccatgagcctctggcagcccctggtcctggtgctcctggtgctgggctgctgctttgctgcccccagacagcgccagtccacccttgtgctcttccctggagacctgagaaccaatctcaccgacaggcagctggcagaggaatacctgtaccgctatggttacactcgggtggcagagatgcgtggagagtcgaaatctctggggcctgcgctgctgcttctccagaagcaactgtccctgcccgagaccggtgagctggatagcgccacgctgaaggccatgcgaaccccacggtgcggggtcccagacctgggcagattccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgagccacggcctccaaccaccaccacaccgcagcccacggctcccccgacggtctgccccaccggaccccccactgtccacccctcagagcgccccacagctggccccacaggtcccccctcagctggccccacaggtccccccactgctggcccttctacggccactactgtgcctttgagtccggtggacgatgcctgcaacgtgaacatcttcgacgccatcgcggagattgggaaccagctgtatttgttcaaggatgggaagtactggcgattctctgagggcagggggagccggccgcagggccccttccttatcgccgacaagtggcccgcgctgccccgcaagctggactcggtctttgaggagcggctctccaagaagcttttcttcttctctgggcgccaggtgtgggtgtacacaggcgcgtcggtgctgggcccgaggcgtctggacaagctgggcctgggagccgacgtggcccaggtgaccggggccctccggagtggcagggggaagatgctgctgttcagcgggcggcgcctctggaggttcgacgtgaaggcgcagatggtggatccccggagcgccagcgaggtggaccggatgttccccggggtgcctttggacacgcacgacgtcttccagtaccgagagaaagcctatttctgccaggaccgcttctactggcgcgtgagttcccggagtgagttgaaccaggtggaccaagtgggctacgtgacctatgacatcctgcagtgccctgaggacgattacaaggatgacgacgataagtgataa(SEQ ID NO:647)
NFATc1P-MMP9cat
(DNA)
aggcaggaggaagaggaaaggggcgcagggcgctcggggagcagagccgggggcccgcggtggccgcagaggccgggccggggcgcagaggccgggcgagctggccgcgctctgggccgccgcctccggaactccctgcgcctggcgcgcggccaccgtggtcccggcaacggcattaaacagagggaaacagacccgggattccgtcacccgggcggggggataaggacggctttgagagcagacaggaaaagggagcttttctgcatggggtgaaaaaattatttattgaaggaggaggaggcggcagcggaggaaggggaggggcgggaggaggaggaagagccggccgcccccgccccggccccggctcctcaggagccaagggcagcctcgccaggtcggtcccgggctcgaggaccgcggctggggtcgaggggctcagtctcccacgtgaccggctgggcgcgccccgccagacccggcctcgggattccctcctcccggcgagtctccgcccgccccgtcctggaggtggggagaaggagggcggggcgggggggacggaaactctccccgccaaatcctggccccaggcctggggacactcgcggcgggaagatttggaggggaggggagggggaggggcgtgggggcgcggcctcgctggagtccccctgaccccccgacccccgcccaccggcctgggcgtcctcccgcggcccctcctcccctcccggcgcccggtgctctggggcgcgtgccacgcctggctcggcgccgtaggggcccccgcaggtagagacccctggaaatggcctcgacgccgcaggagcgaggcggccaccaccccgctaatccgggcacgtctctccaggccgaggcctgcggtggaaaagccggggttccatttgtgctgagtcggggcggccgaatggagccaggcctcgggacgcgggacggacgggctctggccgcgcaccttcgcgggctctgcagcgcccgaccgcctcccccggcagggaggaggcgcttgtggggggcacccacggggcacagtgatccctgggggtctgcggacctcctgggccccgcagcagacacgagtttagcctttgggtttagtttaaatcacataagggtgtcgtgcaatcgatttatggtttctacacaccagacactttaacctccaaccccccccatccaagccaacaagaaaatgcggtgccgtgttggcagctgagctgcgcccgaagagacgcagggagacgtaagagaggaaagtgtgagtggccggggggcctccccccgtcagaagtcgcgcagtcgcgcccataaaacgccccctccgggcggctagggcaggtgagcgcgtccccgggcctccccacgccggcccctgccacagagccgtctaggtcgagcagatatttacagaataaaaatgacaataactcgacgtcccgggacggccacgcaatctgttagtaatttagcgggatgggaatttcctttctagggcctgccagtgaagcgcttttccaaatttccacagcgggggaagcctgcgattttacataatgacttcagcatgccgggctttctcgacacccctccccggcccccggcccccgccccccgccccttttccagcagggccgggctccctccggacacccgcgtggactcaggcgtcccgtctggcccgttcgcccccgtttcccccgccagccccagcgcccccctgcccggcccccggattccccgttcccgcccctacgcccccatcccctccccgtgcgcccctccccgtgcgcccccctccccgtgcgccccccctccccgtgcgcccccctccccgtgcgccccccctccccgggcgcccccctccccgggcgccccccctccccgtgcgcccccccctccccgtgcgccccccctccccgtgcgcgccccgcctcttgcgcccctgcccccaggcgagcggctgccgcggcgcggggaggggcgggcgctcggcgactcgtccccggggccccgcgcgggcccgggcagcaggggcgtgatgtcacggcagggagggggcgcgggagccgccgggccggcggggaggcgggggaggtgttttccagctttaaaaaggcaggaggcagagcgcggccctgcgtcagagcgagactcagaggtctagagccaccatgttccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgattacaaggatgacgacgataagtgataa(SEQ ID NO:648)
NFAT应答元件
(DNA)
ggaggaaaaactgtttcatacagaaggcgt(SEQ ID NO:649)
NFAT应答元件重复
(DNA)
ggaggaaaaactgtttcatacagaaggcgtggaggaaaaactgtttcatacagaaggcgtggaggaaaaactgtttcatacagaaggcgt(SEQ ID NO:650)
CMV最小启动子
(DNA)
aggtaggcgtgtacggtgggaggtctatataagcagagctggtttagtgaaccgtcagatc(SEQ ID NO:651)
NFATREmCMV-MMP9
(DNA)
ggaggaaaaactgtttcatacagaaggcgtggaggaaaaactgtttcatacagaaggcgtggaggaaaaactgtttcatacagaaggcgtagatctagactcaggtaggcgtgtacggtgggaggtctatataagcagagctggtttagtgaaccgtcagatctctagagccaccatgagcctctggcagcccctggtcctggtgctcctggtgctgggctgctgctttgctgcccccagacagcgccagtccacccttgtgctcttccctggagacctgagaaccaatctcaccgacaggcagctggcagaggaatacctgtaccgctatggttacactcgggtggcagagatgcgtggagagtcgaaatctctggggcctgcgctgctgcttctccagaagcaactgtccctgcccgagaccggtgagctggatagcgccacgctgaaggccatgcgaaccccacggtgcggggtcccagacctgggcagattccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgagccacggcctccaaccaccaccacaccgcagcccacggctcccccgacggtctgccccaccggaccccccactgtccacccctcagagcgccccacagctggccccacaggtcccccctcagctggccccacaggtccccccactgctggcccttctacggccactactgtgcctttgagtccggtggacgatgcctgcaacgtgaacatcttcgacgccatcgcggagattgggaaccagctgtatttgttcaaggatgggaagtactggcgattctctgagggcagggggagccggccgcagggccccttccttatcgccgacaagtggcccgcgctgccccgcaagctggactcggtctttgaggagcggctctccaagaagcttttcttcttctctgggcgccaggtgtgggtgtacacaggcgcgtcggtgctgggcccgaggcgtctggacaagctgggcctgggagccgacgtggcccaggtgaccggggccctccggagtggcagggggaagatgctgctgttcagcgggcggcgcctctggaggttcgacgtgaaggcgcagatggtggatccccggagcgccagcgaggtggaccggatgttccccggggtgcctttggacacgcacgacgtcttccagtaccgagagaaagcctatttctgccaggaccgcttctactggcgcgtgagttcccggagtgagttgaaccaggtggaccaagtgggctacgtgacctatgacatcctgcagtgccctgaggacgattacaaggatgacgacgataagtgataa(SEQ ID NO:652)
NFATREmCMV-MMP9cat
(DNA)
ggaggaaaaactgtttcatacagaaggcgtggaggaaaaactgtttcatacagaaggcgtggaggaaaaactgtttcatacagaaggcgtagatctagactcaggtaggcgtgtacggtgggaggtctatataagcagagctggtttagtgaaccgtcagatctctagagccaccatgttccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgattacaaggatgacgacgataagtgataa(SEQ ID NO:653)
C2 scFv
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaact(SEQ ID NO:654)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRT(SEQ ID NO:655)
CD8跨膜结构域
(DNA)
atctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgc(SEQ ID NO:656)
(氨基酸)
IYIWAPLAGTCGVLLLSLVITLYC(SEQ ID NO:657)
4-1BB结构域
(DNA)
aaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactg(SEQ ID NO:658)
(氨基酸)
KRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL(SEQ ID NO:659)
CD3ζ结构域
(DNA)
agagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgc(SEQ ID NO:660)
(氨基酸)
RVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR(SEQ ID NO:661)
人IgG1Fc接头
(DNA)
gagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaa(SEQ ID NO:662)
(氨基酸)
EPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQ ID NO:663)
C2 CAR FC接头
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:664)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ IDNO:665)
IgD/Fc接头
(DNA)
gagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccagagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaa(SEQ ID NO:666)
(氨基酸)
ESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQ ID NO:667)
C2 CAR IgD/FC接头
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccagagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:668)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ IDNO:669)
Fc无铰链Y407R接头
(DNA)
gcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctcaggagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaa(SEQ ID NO:670)
(氨基酸)
APELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLRSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQ ID NO:671)
C2 CAR FC无铰链/Y407R接头
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctcaggagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:672)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLRSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:673)
IgD/FC无铰链/Y407R接头
(DNA)
gagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctcaggagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaa(SEQ ID NO:674)
(氨基酸)
ESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLRSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQ ID NO:675)
C2 CAR IgD/FC无铰链/Y407R接头
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctcaggagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQID NO:676)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLRSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:677)
IgD接头
(DNA)
gagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacacca(SEQ ID NO:678)
(氨基酸)
ESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTP(SEQ ID NO:679)
C2 CAR IgD接头
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccaatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:680)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:681)
X4接头
(DNA)
gacaagacgcacaccaagccacctaaaccagctccagaactgctcggaggtcctggcaccggaaccggaggacctaccatcaaaccacctaagccacctaagcctgctcctaacctgctcggaggacct(SEQ ID NO:682)
(氨基酸)
DKTHTKPPKPAPELLGGPGTGTGGPTIKPPKPPKPAPNLLGGP(SEQ ID NO:683)
C2 CAR X4接头
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgacaagacgcacaccaagccacctaaaccagctccagaactgctcggaggtcctggcaccggaaccggaggacctaccatcaaaccacctaagccacctaagcctgctcctaacctgctcggaggacctatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:684)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTDKTHTKPPKPAPELLGGPGTGTGGPTIKPPKPPKPAPNLLGGPIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:685)
OKT3 scFv
(DNA)
caggtgcagctggtgcagagcggaggcggagtggtgcagcctggaagaagcctgcgcctgagctgcaaagcgagcggctatacctttacccgctataccatgcattgggtgcgccaggcgccgggcaaaggcctggaatggattggctatattaacccgagccgcggctataccaactataaccagaaagtgaaagatcgctttaccattagcaccgataaaagcaaaagcaccgcgtttctgcagatggatagcctgcgcccggaagataccgcggtgtattattgcgcgcgctattatgatgatcattattgcctggattattggggccagggcaccaccctgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattcagatgacccagagcccgagcagcctgagcgcgagcgtgggcgatcgcgtgaccattacctgcagcgcgagcagcagcgtgagctatatgaactggtatcagcagaccccgggcaaagcgccgaaacgctggatttatgataccagcaaactggcgagcggcgtgccgagccgctttagcggcagcggcagcggcaccgattatacctttaccattagcagcctgcagccggaagatattgcgacctattattgccagcagtggagcagcaacccgtttacctttggccagggcaccaaactgcagattacccgctgataa(SEQ IDNO:686)
(氨基酸)
QVQLVQSGGGVVQPGRSLRLSCKASGYTFTRYTMHWVRQAPGKGLEWIGYINPSRGYTNYNQKVKDRFTISTDKSKSTAFLQMDSLRPEDTAVYYCARYYDDHYCLDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIQMTQSPSSLSASVGDRVTITCSASSSVSYMNWYQQTPGKAPKRWIYDTSKLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSNPFTFGQGTKLQITR**(SEQ ID NO:687)
C2-FC-OKT3
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaggcggtggcggatcccaggtgcagctggtgcagagcggaggcggagtggtgcagcctggaagaagcctgcgcctgagctgcaaagcgagcggctatacctttacccgctataccatgcattgggtgcgccaggcgccgggcaaaggcctggaatggattggctatattaacccgagccgcggctataccaactataaccagaaagtgaaagatcgctttaccattagcaccgataaaagcaaaagcaccgcgtttctgcagatggatagcctgcgcccggaagataccgcggtgtattattgcgcgcgctattatgatgatcattattgcctggattattggggccagggcaccaccctgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattcagatgacccagagcccgagcagcctgagcgcgagcgtgggcgatcgcgtgaccattacctgcagcgcgagcagcagcgtgagctatatgaactggtatcagcagaccccgggcaaagcgccgaaacgctggatttatgataccagcaaactggcgagcggcgtgccgagccgctttagcggcagcggcagcggcaccgattatacctttaccattagcagcctgcagccggaagatattgcgacctattattgccagcagtggagcagcaacccgtttacctttggccagggcaccaaactgcagattacccgctgataa(SEQ ID NO:688)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSQVQLVQSGGGVVQPGRSLRLSCKASGYTFTRYTMHWVRQAPGKGLEWIGYINPSRGYTNYNQKVKDRFTISTDKSKSTAFLQMDSLRPEDTAVYYCARYYDDHYCLDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIQMTQSPSSLSASVGDRVTITCSASSSVSYMNWYQQTPGKAPKRWIYDTSKLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSNPFTFGQGTKLQITR**(SEQ ID NO:689)
C2-IgD/FC-OKT3
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccagagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaggcggtggcggatcccaggtgcagctggtgcagagcggaggcggagtggtgcagcctggaagaagcctgcgcctgagctgcaaagcgagcggctatacctttacccgctataccatgcattgggtgcgccaggcgccgggcaaaggcctggaatggattggctatattaacccgagccgcggctataccaactataaccagaaagtgaaagatcgctttaccattagcaccgataaaagcaaaagcaccgcgtttctgcagatggatagcctgcgcccggaagataccgcggtgtattattgcgcgcgctattatgatgatcattattgcctggattattggggccagggcaccaccctgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattcagatgacccagagcccgagcagcctgagcgcgagcgtgggcgatcgcgtgaccattacctgcagcgcgagcagcagcgtgagctatatgaactggtatcagcagaccccgggcaaagcgccgaaacgctggatttatgataccagcaaactggcgagcggcgtgccgagccgctttagcggcagcggcagcggcaccgattatacctttaccattagcagcctgcagccggaagatattgcgacctattattgccagcagtggagcagcaacccgtttacctttggccagggcaccaaactgcagattacccgctgataa(SEQ ID NO:690)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSQVQLVQSGGGVVQPGRSLRLSCKASGYTFTRYTMHWVRQAPGKGLEWIGYINPSRGYTNYNQKVKDRFTISTDKSKSTAFLQMDSLRPEDTAVYYCARYYDDHYCLDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIQMTQSPSSLSASVGDRVTITCSASSSVSYMNWYQQTPGKAPKRWIYDTSKLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSNPFTFGQGTKLQITR**(SEQID NO:691)
C2-FC无铰链/Y407R-OKT3
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctcaggagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaggcggtggcggatcccaggtgcagctggtgcagagcggaggcggagtggtgcagcctggaagaagcctgcgcctgagctgcaaagcgagcggctatacctttacccgctataccatgcattgggtgcgccaggcgccgggcaaaggcctggaatggattggctatattaacccgagccgcggctataccaactataaccagaaagtgaaagatcgctttaccattagcaccgataaaagcaaaagcaccgcgtttctgcagatggatagcctgcgcccggaagataccgcggtgtattattgcgcgcgctattatgatgatcattattgcctggattattggggccagggcaccaccctgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattcagatgacccagagcccgagcagcctgagcgcgagcgtgggcgatcgcgtgaccattacctgcagcgcgagcagcagcgtgagctatatgaactggtatcagcagaccccgggcaaagcgccgaaacgctggatttatgataccagcaaactggcgagcggcgtgccgagccgctttagcggcagcggcagcggcaccgattatacctttaccattagcagcctgcagccggaagatattgcgacctattattgccagcagtggagcagcaacccgtttacctttggccagggcaccaaactgcagattacccgctgataa(SEQ ID NO:692)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLRSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSQVQLVQSGGGVVQPGRSLRLSCKASGYTFTRYTMHWVRQAPGKGLEWIGYINPSRGYTNYNQKVKDRFTISTDKSKSTAFLQMDSLRPEDTAVYYCARYYDDHYCLDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIQMTQSPSSLSASVGDRVTITCSASSSVSYMNWYQQTPGKAPKRWIYDTSKLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSNPFTFGQGTKLQITR**(SEQ ID NO:693)
C2-IgD/FC无铰链/Y407R-OKT3
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctcaggagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaggcggtggcggatcccaggtgcagctggtgcagagcggaggcggagtggtgcagcctggaagaagcctgcgcctgagctgcaaagcgagcggctatacctttacccgctataccatgcattgggtgcgccaggcgccgggcaaaggcctggaatggattggctatattaacccgagccgcggctataccaactataaccagaaagtgaaagatcgctttaccattagcaccgataaaagcaaaagcaccgcgtttctgcagatggatagcctgcgcccggaagataccgcggtgtattattgcgcgcgctattatgatgatcattattgcctggattattggggccagggcaccaccctgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattcagatgacccagagcccgagcagcctgagcgcgagcgtgggcgatcgcgtgaccattacctgcagcgcgagcagcagcgtgagctatatgaactggtatcagcagaccccgggcaaagcgccgaaacgctggatttatgataccagcaaactggcgagcggcgtgccgagccgctttagcggcagcggcagcggcaccgattatacctttaccattagcagcctgcagccggaagatattgcgacctattattgccagcagtggagcagcaacccgtttacctttggccagggcaccaaactgcagattacccgctgataa(SEQ ID NO:694)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLRSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSQVQLVQSGGGVVQPGRSLRLSCKASGYTFTRYTMHWVRQAPGKGLEWIGYINPSRGYTNYNQKVKDRFTISTDKSKSTAFLQMDSLRPEDTAVYYCARYYDDHYCLDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIQMTQSPSSLSASVGDRVTITCSASSSVSYMNWYQQTPGKAPKRWIYDTSKLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSNPFTFGQGTKLQITR**(SEQ ID NO:695)
C2-IgD-OKT3
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccaggcggtggcggatcccaggtgcagctggtgcagagcggaggcggagtggtgcagcctggaagaagcctgcgcctgagctgcaaagcgagcggctatacctttacccgctataccatgcattgggtgcgccaggcgccgggcaaaggcctggaatggattggctatattaacccgagccgcggctataccaactataaccagaaagtgaaagatcgctttaccattagcaccgataaaagcaaaagcaccgcgtttctgcagatggatagcctgcgcccggaagataccgcggtgtattattgcgcgcgctattatgatgatcattattgcctggattattggggccagggcaccaccctgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattcagatgacccagagcccgagcagcctgagcgcgagcgtgggcgatcgcgtgaccattacctgcagcgcgagcagcagcgtgagctatatgaactggtatcagcagaccccgggcaaagcgccgaaacgctggatttatgataccagcaaactggcgagcggcgtgccgagccgctttagcggcagcggcagcggcaccgattatacctttaccattagcagcctgcagccggaagatattgcgacctattattgccagcagtggagcagcaacccgtttacctttggccagggcaccaaactgcagattacccgctgataa(SEQ ID NO:696)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPGGGGSQVQLVQSGGGVVQPGRSLRLSCKASGYTFTRYTMHWVRQAPGKGLEWIGYINPSRGYTNYNQKVKDRFTISTDKSKSTAFLQMDSLRPEDTAVYYCARYYDDHYCLDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIQMTQSPSSLSASVGDRVTITCSASSSVSYMNWYQQTPGKAPKRWIYDTSKLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSNPFTFGQGTKLQITR**(SEQ ID NO:697)
C2-X4-OKT3
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgacaagacgcacaccaagccacctaaaccagctccagaactgctcggaggtcctggcaccggaaccggaggacctaccatcaaaccacctaagccacctaagcctgctcctaacctgctcggaggacctggcggtggcggatcccaggtgcagctggtgcagagcggaggcggagtggtgcagcctggaagaagcctgcgcctgagctgcaaagcgagcggctatacctttacccgctataccatgcattgggtgcgccaggcgccgggcaaaggcctggaatggattggctatattaacccgagccgcggctataccaactataaccagaaagtgaaagatcgctttaccattagcaccgataaaagcaaaagcaccgcgtttctgcagatggatagcctgcgcccggaagataccgcggtgtattattgcgcgcgctattatgatgatcattattgcctggattattggggccagggcaccaccctgaccgtgagcagcggcggtggcggatccggcggtggcggatccggcggtggcggatccgatattcagatgacccagagcccgagcagcctgagcgcgagcgtgggcgatcgcgtgaccattacctgcagcgcgagcagcagcgtgagctatatgaactggtatcagcagaccccgggcaaagcgccgaaacgctggatttatgataccagcaaactggcgagcggcgtgccgagccgctttagcggcagcggcagcggcaccgattatacctttaccattagcagcctgcagccggaagatattgcgacctattattgccagcagtggagcagcaacccgtttacctttggccagggcaccaaactgcagattacccgctgataa(SEQ ID NO:698)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTDKTHTKPPKPAPELLGGPGTGTGGPTIKPPKPPKPAPNLLGGPGGGGSQVQLVQSGGGVVQPGRSLRLSCKASGYTFTRYTMHWVRQAPGKGLEWIGYINPSRGYTNYNQKVKDRFTISTDKSKSTAFLQMDSLRPEDTAVYYCARYYDDHYCLDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIQMTQSPSSLSASVGDRVTITCSASSSVSYMNWYQQTPGKAPKRWIYDTSKLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSNPFTFGQGTKLQITR**(SEQ ID NO:699)
C2-MMP9
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactggcggtggcggatccagcctctggcagcccctggtcctggtgctcctggtgctgggctgctgctttgctgcccccagacagcgccagtccacccttgtgctcttccctggagacctgagaaccaatctcaccgacaggcagctggcagaggaatacctgtaccgctatggttacactcgggtggcagagatgcgtggagagtcgaaatctctggggcctgcgctgctgcttctccagaagcaactgtccctgcccgagaccggtgagctggatagcgccacgctgaaggccatgcgaaccccacggtgcggggtcccagacctgggcagattccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgagccacggcctccaaccaccaccacaccgcagcccacggctcccccgacggtctgccccaccggaccccccactgtccacccctcagagcgccccacagctggccccacaggtcccccctcagctggccccacaggtccccccactgctggcccttctacggccactactgtgcctttgagtccggtggacgatgcctgcaacgtgaacatcttcgacgccatcgcggagattgggaaccagctgtatttgttcaaggatgggaagtactggcgattctctgagggcagggggagccggccgcagggccccttccttatcgccgacaagtggcccgcgctgccccgcaagctggactcggtctttgaggagcggctctccaagaagcttttcttcttctctgggcgccaggtgtgggtgtacacaggcgcgtcggtgctgggcccgaggcgtctggacaagctgggcctgggagccgacgtggcccaggtgaccggggccctccggagtggcagggggaagatgctgctgttcagcgggcggcgcctctggaggttcgacgtgaaggcgcagatggtggatccccggagcgccagcgaggtggaccggatgttccccggggtgcctttggacacgcacgacgtcttccagtaccgagagaaagcctatttctgccaggaccgcttctactggcgcgtgagttcccggagtgagttgaaccaggtggaccaagtgggctacgtgacctatgacatcctgcagtgccctgaggacgattacaaggatgacgacgataagtgataa(SEQ ID NO:700)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTGGGGSSLWQPLVLVLLVLGCCFAAPRQRQSTLVLFPGDLRTNLTDRQLAEEYLYRYGYTRVAEMRGESKSLGPALLLLQKQLSLPETGELDSATLKAMRTPRCGVPDLGRFQTFEGDLKWHHHNITYWIQNYSEDLPRAVIDDAFARAFALWSAVTPLTFTRVYSRDADIVIQFGVAEHGDGYPFDGKDGLLAHAFPPGPGIQGDAHFDDDELWSLGKGVVVPTRFGNADGAACHFPFIFEGRSYSACTTDGRSDGLPWCSTTANYDTDDRFGFCPSERLYTQDGNADGKPCQFPFIFQGQSYSACTTDGRSDGYRWCATTANYDRDKLFGFCPTRADSTVMGGNSAGELCVFPFTFLGKEYSTCTSEGRGDGRLWCATTSNFDSDKKWGFCPDQGYSLFLVAAHEFGHALGLDHSSVPEALMYPMYRFTEGPPLHKDDVNGIRHLYGPRPEPEPRPPTTTTPQPTAPPTVCPTGPPTVHPSERPTAGPTGPPSAGPTGPPTAGPSTATTVPLSPVDDACNVNIFDAIAEIGNQLYLFKDGKYWRFSEGRGSRPQGPFLIADKWPALPRKLDSVFEERLSKKLFFFSGRQVWVYTGASVLGPRRLDKLGLGADVAQVTGALRSGRGKMLLFSGRRLWRFDVKAQMVDPRSASEVDRMFPGVPLDTHDVFQYREKAYFCQDRFYWRVSSRSELNQVDQVGYVTYDILQCPEDDYKDDDDK**
(SEQ ID NO:701)
C2-MMP9cat
(DNA)
gaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactggcggtggcggatccttccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgattacaaggatgacgacgataagtgataa(SEQ ID NO:702)
(氨基酸)
EVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTGGGGSFQTFEGDLKWHHHNITYWIQNYSEDLPRAVIDDAFARAFALWSAVTPLTFTRVYSRDADIVIQFGVAEHGDGYPFDGKDGLLAHAFPPGPGIQGDAHFDDDELWSLGKGVVVPTRFGNADGAACHFPFIFEGRSYSACTTDGRSDGLPWCSTTANYDTDDRFGFCPSERLYTQDGNADGKPCQFPFIFQGQSYSACTTDGRSDGYRWCATTANYDRDKLFGFCPTRADSTVMGGNSAGELCVFPFTFLGKEYSTCTSEGRGDGRLWCATTSNFDSDKKWGFCPDQGYSLFLVAAHEFGHALGLDHSSVPEALMYPMYRFTEGPPLHKDDVNGIRHLYGPRPEPDYK
DDDDK**(SEQ ID NO:703)
在BiTE的两个scFv之间的,和在C2与MMP9之间的其它接头包括但不限于如SEQ IDNOS:705、707、709、711、713、715和717示出的那些。
[G4S1]x2接头序列:
(DNA)
ggcggtggcggatccggcggtggcggatcc(SEQ ID NO:704)
(氨基酸)
GGGGSGGGGS(SEQ ID NO:705)
[G4S1]x3接头序列:
(DNA)
ggcggtggcggatccggcggtggcggatccggcggtggcggatcc(SEQ ID NO:706)
(氨基酸)
GGGGSGGGGSGGGGS(SEQ ID NO:707)
Long GS接头序列:
(DNA)
ggcggtggaagcggcggtggcggatccggcagcggcggaagcggcggtggcggatccggcggtgga(SEQ ID NO:708)(氨基酸)
GGGSGGGGSGSGGSGGGGSGGG(SEQ ID NO:709)
13aa GS接头序列:
(DNA)
ggcggtggatccggcggtggcggatccggcggtggatcc(SEQ ID NO:710)
(氨基酸)
GGGSGGGGSGGGS(SEQ ID NO:711)
8aa GS接头序列:
(DNA)
ggcggttccggcggtggatccgga(SEQ ID NO:712)
(氨基酸)
GGSGGGSG(SEQ ID NO:713)
12aa GS接头序列:
(DNA)
ggcggttccggcggtggatccggcggtggcggatccgga(SEQ ID NO:714)
(氨基酸)
GGSGGGSGGGSG(SEQ ID NO:715)
24aa GS接头序列:
(DNA)
ggcggttccggcggtggatccggcggtggcggatccggaggcggttccggcggtggatccggcggtggcggatccgga(SEQID NO:716)
(氨基酸)
GGSGGGSGGGSGGGSGGGSGGGSG(SEQ ID NO:717)
CAR-T C2 CD8/CD8/4-1BB/CD3z#44
N-CD8ls-huMNC2scFv-CD8ecd片段-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccaggccggaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactacaacaacccctgcccccagacctcctaccccagcccctacaattgccagccagcctctgagcctgaggcccgaggcttgtagacctgctgctggcggagccgtgcacaccagaggactggatttcgcctgcgacatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:718)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:719)
CAR-T IgK C2 CD8/CD8/4-1BB/CD3z#45
N-IgKls-huMNC2scFv-CD8ecd片段-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactacaacaacccctgcccccagacctcctaccccagcccctacaattgccagccagcctctgagcctgaggcccgaggcttgtagacctgctgctggcggagccgtgcacaccagaggactggatttcgcctgcgacatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:720)
(氨基酸)
METDTLLLWVLLLWVPGSTGEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:721)
CAR-T C2 op CD8/CD8/4-1BB/CD3z#46
N-CD8ls-huMNC2scFv密码子优化-CD8ecd片段-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccaggccggaagtgcagctggtggaatctggcggcggactcgtgaagcctggcggctctctgagactgagctgtgccgccagcggcttcacctttagcggctacgccatgagctgggtgcgccaggctcctggcaaaggcctggaatgggtgtccaccatctctagcggcggcacctacatctactaccccgacagcgtgaagggccggttcaccatcagccgggacaacgccaagaacagcctgtacctgcagatgaactccctgcgggccgaggacaccgccgtgtactattgtgctagactgggcggcgacaactactacgagtacttcgacgtgtggggcaagggcaccaccgtgacagtgtctagcggaggcggaggatcaggcggcggaggaagtggcggagggggatctgatatcgtgctgacccagagccctgccagcctggctgtgtctcctggacagagggccaccatcacctgtcgggccagcaagagcgtgtccacctccggctacagctacatgcactggtatcagcagaagcccggccagccccccaagctgctgatctacctggccagcaacctggaaagcggcgtgcccgctagattttccggctctggcagcggcaccgacttcaccctgaccatcaaccccgtggaagccaacgacaccgccaattactactgccagcacagcagagagctgcccttcaccttcggcggaggcaccaaggtggaaatcaagcggaccacaacaacccctgcccccagacctcctaccccagcccctacaattgccagccagcctctgagcctgaggcccgaggcttgtagacctgctgctggcggagccgtgcacaccagaggactggatttcgcctgcgacatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:722)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:723)
CAR-T IgK C2op CD8/CD8/4-1BB/CD3z#47
N-IgKls-huMNC2scFv密码子优化-CD8ecd片段-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgaagtgcagctggtggaatctggcggcggactcgtgaagcctggcggctctctgagactgagctgtgccgccagcggcttcacctttagcggctacgccatgagctgggtgcgccaggctcctggcaaaggcctggaatgggtgtccaccatctctagcggcggcacctacatctactaccccgacagcgtgaagggccggttcaccatcagccgggacaacgccaagaacagcctgtacctgcagatgaactccctgcgggccgaggacaccgccgtgtactattgtgctagactgggcggcgacaactactacgagtacttcgacgtgtggggcaagggcaccaccgtgacagtgtctagcggaggcggaggatcaggcggcggaggaagtggcggagggggatctgatatcgtgctgacccagagccctgccagcctggctgtgtctcctggacagagggccaccatcacctgtcgggccagcaagagcgtgtccacctccggctacagctacatgcactggtatcagcagaagcccggccagccccccaagctgctgatctacctggccagcaacctggaaagcggcgtgcccgctagattttccggctctggcagcggcaccgacttcaccctgaccatcaaccccgtggaagccaacgacaccgccaattactactgccagcacagcagagagctgcccttcaccttcggcggaggcaccaaggtggaaatcaagcggaccacaacaacccctgcccccagacctcctaccccagcccctacaattgccagccagcctctgagcctgaggcccgaggcttgtagacctgctgctggcggagccgtgcacaccagaggactggatttcgcctgcgacatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:724)
(氨基酸)
METDTLLLWVLLLWVPGSTGEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:725)
CAR-T C2 CD8/CD8/4-1BB/CD3z op#48
N-CD8ls-huMNC2scFv-CD8ecd片段-CD8跨膜-4-1BB-CD3ζ(全部结构域密码子优化)-C
(DNA)
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccaggccggaagtgcagctggtggaatctggcggcggactcgtgaagcctggcggctctctgagactgagctgtgccgccagcggcttcacctttagcggctacgccatgagctgggtgcgccaggctcctggcaaaggcctggaatgggtgtccaccatctctagcggcggcacctacatctactaccccgacagcgtgaagggccggttcaccatcagccgggacaacgccaagaacagcctgtacctgcagatgaactccctgcgggccgaggacaccgccgtgtactattgtgctagactgggcggcgacaactactacgagtacttcgacgtgtggggcaagggcaccaccgtgacagtgtctagcggaggcggaggatcaggcggcggaggaagtggcggagggggatctgatatcgtgctgacccagagccctgccagcctggctgtgtctcctggacagagggccaccatcacctgtcgggccagcaagagcgtgtccacctccggctacagctacatgcactggtatcagcagaagcccggccagccccccaagctgctgatctacctggccagcaacctggaaagcggcgtgcccgctagattttccggctctggcagcggcaccgacttcaccctgaccatcaaccccgtggaagccaacgacaccgccaattactactgccagcacagcagagagctgcccttcaccttcggcggaggcaccaaggtggaaatcaagcggaccacaacaacccctgcccccagacctcctaccccagcccctacaattgccagccagcctctgagcctgaggcccgaggcttgtagacctgctgctggcggagccgtgcacaccagaggactggatttcgcctgcgacatctacatctgggcccctctggccggcacatgtggcgtgctgctgctgagcctcgtgatcaccctgtactgcaagcggggcagaaagaagctgctgtacatcttcaagcagcccttcatgcggcccgtgcagaccacccaggaagaggacggctgctcctgcagattccccgaggaagaagaaggcggctgcgagctgagagtgaagttcagcagatccgccgacgcccctgcctacaagcagggccagaaccagctgtacaacgagctgaacctgggcagacgggaagagtacgacgtgctggacaagcggagaggcagggaccctgagatgggcggcaagcccagaagaaagaacccccaggaaggcctgtataacgaactgcagaaagacaagatggccgaggcctacagcgagatcggaatgaagggcgagcggagaagaggcaagggccacgatggcctgtaccagggcctgagcaccgccaccaaggacacctatgacgccctgcacatgcaggccctgcctcccagatgataa(SEQ ID NO:726)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:727)
CAR-T IgK C2 CD8/CD8/4-1BB/CD3z op#49
N-IgKls-huMNC2scFv-CD8ecd片段-CD8跨膜-4-1BB-CD3ζ(全部结构域密码子优化)-C
(DNA)
atggagacagacacactcctgctatgggtactgctgctctgggttccaggttccactggtgaagtgcagctggtggaatctggcggcggactcgtgaagcctggcggctctctgagactgagctgtgccgccagcggcttcacctttagcggctacgccatgagctgggtgcgccaggctcctggcaaaggcctggaatgggtgtccaccatctctagcggcggcacctacatctactaccccgacagcgtgaagggccggttcaccatcagccgggacaacgccaagaacagcctgtacctgcagatgaactccctgcgggccgaggacaccgccgtgtactattgtgctagactgggcggcgacaactactacgagtacttcgacgtgtggggcaagggcaccaccgtgacagtgtctagcggaggcggaggatcaggcggcggaggaagtggcggagggggatctgatatcgtgctgacccagagccctgccagcctggctgtgtctcctggacagagggccaccatcacctgtcgggccagcaagagcgtgtccacctccggctacagctacatgcactggtatcagcagaagcccggccagccccccaagctgctgatctacctggccagcaacctggaaagcggcgtgcccgctagattttccggctctggcagcggcaccgacttcaccctgaccatcaaccccgtggaagccaacgacaccgccaattactactgccagcacagcagagagctgcccttcaccttcggcggaggcaccaaggtggaaatcaagcggaccacaacaacccctgcccccagacctcctaccccagcccctacaattgccagccagcctctgagcctgaggcccgaggcttgtagacctgctgctggcggagccgtgcacaccagaggactggatttcgcctgcgacatctacatctgggcccctctggccggcacatgtggcgtgctgctgctgagcctcgtgatcaccctgtactgcaagcggggcagaaagaagctgctgtacatcttcaagcagcccttcatgcggcccgtgcagaccacccaggaagaggacggctgctcctgcagattccccgaggaagaagaaggcggctgcgagctgagagtgaagttcagcagatccgccgacgcccctgcctacaagcagggccagaaccagctgtacaacgagctgaacctgggcagacgggaagagtacgacgtgctggacaagcggagaggcagggaccctgagatgggcggcaagcccagaagaaagaacccccaggaaggcctgtataacgaactgcagaaagacaagatggccgaggcctacagcgagatcggaatgaagggcgagcggagaagaggcaagggccacgatggcctgtaccagggcctgagcaccgccaccaaggacacctatgacgccctgcacatgcaggccctgcctcccagatgataa(SEQ ID NO:728)
(氨基酸)
METDTLLLWVLLLWVPGSTGEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:729)
CAR-T C2 CD4/CD4/4-1BB/CD3z#50
N-CD8ls-huMNC2scFv-CD4ecd片段-CD4跨膜-4-1BB-CD3ζ-C
(DNA)
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccaggccggaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaacttcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:730)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:731)
CAR-T C2FC/CD8/4-1BB/CD3z“Fc”CAR53
N-CD8ls-huMNC2scFv-人IgG1Fc-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccaggccggaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:732)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:733)
CAR-T C2IgD/FC/CD8/4-1BB/CD3z“IgD-Fc”CAR54
N-CD8ls-huMNC2scFv-IgD铰链-人IgG1Fc-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccaggccggaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccagagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:734)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:735)
CAR-T C2FC无铰链Y407R/CD8/4-1BB/CD3z“FcH”CAR55
N-CD8ls-huMNC2scFv-人IgG1无铰链Fc Y407R-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccaggccggaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctcaggagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:736)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLRSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:737)
CAR-T C2 IgD/FC无铰链Y407R/CD8/4-1BB/CD3z“IgD FcH”CAR56
N-CD8ls-huMNC2scFv-IgD铰链-人IgG1无铰链Fc Y407R-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccaggccggaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctcaggagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:738)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLRSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:739)
CAR-T C2IgD/CD8/4-1BB/CD3z“IgD”CAR57
N-CD8ls-huMNC2scFv-IgD铰链-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccaggccggaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccaatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:740)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:741)
CAR-T C2X4/CD8/4-1BB/CD3z“X4”CAR58
N-CD8ls-huMNC2scFv-X4接头-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccaggccggaggtgcagctggtggagtctgggggaggcctggtcaagcctggggggtccctgagactctcctgtgcagcctctggattcaccttcagtggctatgccatgagctgggtccgccaggctccagggaaggggctggagtgggtctcaaccattagtagtggcggaacctacatatactaccccgactcagtgaagggccgattcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggccgtgtattactgtgcgagacttgggggggataattactacgaatacttcgatgtctggggcaaagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgctgacccagtctccagcctccttggccgtgtctccaggacagagggccaccatcacctgcagagccagtaagagtgtcagtaccagcggatactcctacatgcactggtatcagcagaaaccaggacaacctcctaaactcctgatttacctggcatccaatctggagagcggggtcccagccaggttcagcggcagtgggtctgggaccgatttcaccctcacaattaatcctgtggaagctaatgatactgcaaattattactgtcagcacagtagggagctgcctttcacattcggcggagggaccaaggtggagatcaaacgaactgacaagacgcacaccaagccacctaaaccagctccagaactgctcggaggtcctggcaccggaaccggaggacctaccatcaaaccacctaagccacctaagcctgctcctaacctgctcggaggacctatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:742)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTDKTHTKPPKPAPELLGGPGTGTGGPTIKPPKPPKPAPNLLGGPIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:743)
CAR-T E6 CD8/CD4/41BB/CD3z CAR37
N-CD8ls-huMNE6scFv-CD8ecd-CD4跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaaacgacaaccccggcccccagaccaccaacgccagcccccaccatcgccagccaacccctgtctctgagaccagaagcctgtaggcctgccgccggtggagctgtgcacacaagaggactggatttcgcctgtgatatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:744)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDMALIVLGGVAGLLLFIGLGIFFKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:745)
CAR-T E6 CD4/CD4/CD3z序列CAR23:
N-CD8ls-huMNE6scFv-CD4ecd-CD4跨膜-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaatcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:746)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQID NO:747)
CAR-T E6 CD4/CD4/CD28/CD3z序列CAR25:
N-CD8ls-huMNE6scFv-CD4ecd-CD4跨膜-CD28-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaatcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ IDNO:748)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:749)
CAR-T E6 CD4/CD4/4-1BB/CD3z序列CAR31:
N-CD8ls-huMNE6scFv-CD4ecd-CD4跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaatcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ IDNO:750)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:751)
CAR-T E6 CD4/CD4/OX40/CD3z序列:
N-CD8ls-huMNE6scFv-CD4ecd-CD4跨膜-OX40-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaatcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttccggagggaccagaggctgccccccgatgcccacaagccccctgggggaggcagtttccggacccccatccaagaggagcaggccgacgcccactccaccctggccaagatccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:752)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFRRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKIRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:753)
CAR-T E6 CD4/CD4/CD28/4-1BB/CD3z序列CAR38:
N-CD8ls-huMNE6scFv-CD4ecd-CD4跨膜-CD28-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaatcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtccaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:754)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:755)
CAR-T E6 CD4/CD4/CD28/OX40/CD3z序列:
N-CD8ls-huMNE6scFv-CD4ecd-CD4跨膜-CD28-OX40-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggggggggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaatcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcccggagggaccagaggctgccccccgatgcccacaagccccctgggggaggcagtttccggacccccatccaagaggagcaggccgacgcccactccaccctggccaagatccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:756)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKIRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:757)
CAR-T C2 CD4/CD4/CD3z序列:
N-CD8ls-huMNC2scFv-CD4ecd-CD4跨膜-CD3ζ-C
(DNA)
atggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaacctcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:758)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:759)
CAR-T C2 CD4/CD4/CD28/CD3z序列:
N-CD8ls-huMNC2scFv-CD4ecd-CD4跨膜-CD28-CD3ζ-C
(DNA)
atggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaacctcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa
(氨基酸)(SEQ ID NO:760)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:761)
CAR-T C2 CD4/CD4/4-1BB/CD3z序列:
N-CD8ls-huMNC2scFv-CD4ecd-CD4跨膜-4-1BB-CD3ζ-C
(DNA)
atggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaacctcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:762)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:763)
CAR-T C2 CD4/CD4/OX40/CD3z序列:
N-CD8ls-huMNC2scFv-CD4ecd-CD4跨膜-OX40-CD3ζ-C
(DNA)
atggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaacctcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttccggagggaccagaggctgccccccgatgcccacaagccccctgggggaggcagtttccggacccccatccaagaggagcaggccgacgcccactccaccctggccaagatccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:764)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFRRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKIRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:765)
CAR-T C2 CD4/CD4/CD28/4-1BB/CD3z序列:
N-CD8ls-huMNC2scFv-CD4ecd-CD4跨膜-CD28-4-1BB-CD3ζ-C
(DNA)
atggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaacctcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtccaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:766)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:767)
CAR-T C2 CD4/CD4/CD28/OX40/CD3z序列:
N-CD8ls-huMNC2scFv-CD4ecd-CD4跨膜-CD28-OX40-CD3ζ-C
(DNA)
atggccttgccagtgacggccctgctgctgccattggctcttctgttgcacgctgccaggcctgaagtgcagctcgtagagagtggcgggggactggtgaagcccggtggaagcctcagactcagttgcgccgcctcaggtttcactttttcaggttacgccatgtcctgggtaagacaggcaccggggaaaggactcgagtgggtgtctactatcagctcaggaggcacttatatatattatcctgactctgtaaaaggccgatttacgatttctcgcgacaatgcaaagaactccctctacctccaaatgaacagtcttagggcagaagacactgctgtatactattgtgcacgcctcggcggcgacaactactacgagtactttgacgtgtgggggaaagggactaccgtgacagtttcaagcggaggaggtggctcaggtggaggcgggtcaggggggggaggaagtgatattgtgctcacacaatccccagcctccctggctgtgtctcccggccaacgcgctacaattacatgtcgggcctccaaaagcgtgagcaccagcggctacagctacatgcactggtatcaacagaaaccaggacaaccccccaaactgttgatttatctcgcttcaaacttggagtccggcgtgcctgcgcgcttttcagggagtgggagcggcacagattttacgctgactatcaaccccgtagaagcaaacgatacagcgaattattattgtcaacattcccgggaactcccctttacgttcggcgggggcacaaaggtcgaaattaagagaacctcgggacaggtcctgctggaatccaacatcaaggttctgcccacatggtccaccccggtgcagccaatggccctgattgtgctggggggcgtcgccggcctcctgcttttcattgggctaggcatcttcttcagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcccggagggaccagaggctgccccccgatgcccacaagccccctgggggaggcagtttccggacccccatccaagaggagcaggccgacgcccactccaccctggccaagatccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:768)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSGYAMSWVRQAPGKGLEWVSTISSGGTYIYYPDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARLGGDNYYEYFDVWGKGTTVTVSSGGGGSGGGGSGGGGSDIVLTQSPASLAVSPGQRATITCRASKSVSTSGYSYMHWYQQKPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLTINPVEANDTANYYCQHSRELPFTFGGGTKVEIKRTSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKIRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:769)
CAR-T E6 IgD/FC/CD8/4-1BB/CD3z
N-CD8ls-huMNE6scFv-IgD铰链-人IgG1Fc-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccagagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:770)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:771)
CAR-T E6 IgD/FC无铰链Y407R/CD8/4-1BB/CD3z
N-CD8ls-huMNE6scFv-IgD铰链-人IgG1无铰链Fc Y407R-CD8跨膜-4-1BB-CD3ζ-C
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggttgagagtggcggtgggctggttaagcctggcggctccctgcggctgagctgcgccgcgagtggatttactttcagccgatatgggatgagttgggtgcggcaagctcccgggaagaggctggaatgggtctcaacaatctccggggggggcacttacatctattaccccgactcagtcaaggggagatttaccatttcacgagacaacgctaagaataccctgtatttgcagatgaattctctgagagcagaggacacagctgtttactattgtacccgcgacaactatggcaggaactacgactacggtatggactattggggacaagggacattggttacagtgagcagtggcggcgggggcagcggaggaggaggcagcggtggcggaggcagcgagatagtgctcacgcagtcacccgcgactctcagtctctcacctggggaacgagctaccctgacgtgctctgctacctcctcagtgtcatatattcactggtatcagcaacggcccgggcagtcccctagattgctcatttatagtacctctaatctggcctcaggtatccctgcacgattttctggatctggttcaggttctgattacaccctcactatctctagcctggagcctgaagactttgccgtttattactgccagcagaggtctagctccccattcacctttgggagtgggaccaaggttgaaattaaagagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctcaggagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaaatctacatctgggcgcccttggccgggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgcccttcacatgcaggccctgccccctcgctgataa(SEQ ID NO:772)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLVESGGGLVKPGGSLRLSCAASGFTFSRYGMSWVRQAPGKRLEWVSTISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMNSLRAEDTAVYYCTRDNYGRNYDYGMDYWGQGTLVTVSSGGGGSGGGGSGGGGSEIVLTQSPATLSLSPGERATLTCSATSSVSYIHWYQQRPGQSPRLLIYSTSNLASGIPARFSGSGSGSDYTLTISSLEPEDFAVYYCQQRSSSPFTFGSGTKVEIKESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLRSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:773)
NFATc1P2-MMP9
(DNA)
caggcctggggacactcgcggcgggaagatttggaggggaggggagggggaggggcgtgggggcgcggcctcgctggagtccccctgaccccccgacccccgcccaccggcctgggcgtcctcccgcggcccctcctcccctcccggcgcccggtgctctggggcgcgtgccacgcctggctcggcgccgtaggggcccccgcaggtagagacccctggaaatggcctcgacgccgcaggagcgaggcggccaccaccccgctaatccgggcacgtctctccaggccgaggcctgcggtggaaaagccggggttccatttgtgctgagtcggggcggccgaatggagccaggcctcgggacgcgggacggacgggctctggccgcgcaccttcgcgggctctgcagcgcccgaccgcctcccccggcagggaggaggcgcttgtggggggcacccacggggcacagtgatccctgggggtctgcggacctcctgggccccgcagcagacacgagtttagcctttgggtttagtttaaatcacataagggtgtcgtgcaatcgatttatggtttctacacaccagacactttaacctccaaccccccccatccaaagccaacaagaaaatgcggtgccgtgttggcagctgagctgcgcccgaagagacgcagggagacgtaagagaggaaagtgtgagtggccggggggcctccccccgtcagaagtcgcgcagtcgcgcccataaaacgccccctccgggcggctagggcaggtgagcgcgtccccgggcctccccacgccggcccctgccacaggccgtctaggtcgagcagatatttacagaataaaaatgacaataactcgacgtcccgggacggccacgcaatctgttagtaatttagcgggatgggaatttcctttctagggcctgccagtgaagcgcttttccaaatttccacagcgggggaagcctgcgattttacataatgacttcagcatgccgggctttctcgacacccctccccggcccccggcccccgccccccgccccttttccagcagggccgggctccctccggacacccgcgtggactcaggcgtcccgtctggcccgttcgcccccgtttcccccgccagccccagcgcccccctgcccggcccccggattccccgttcccgcccctacgcccccatcccctccccgtgcgcccctccccgtgcgcccccctccccgtgcgccccccctccccgtgcgcccccctccccgtgcgccccccctccccgggcgcccccctccccgggcgccccccctccccgtgcgcccccccctccccgtgcgccccccctccccgtgcgcgccccgcctcttgcgcccctgcccccaggcgagcggctgccgcggcgcggggaggggcgggcgctcggcgactcgtccccggggccccgcgcgggcccgggcagcaggggcgtgatgtcacggcagggagggggcgcgggagccgccgggccggcggggaggcgggggaggtgttttccagctttaaaaaggcaggaggcagagcgcggccctgcgtcagagcgagactcagaggctccgaactcgccggcggagtcgccgcgccagatcccagcagcagggcgcggaagcttctctcgacattcgtttctagagccaccatgagcctctggcagcccctggtcctggtgctcctggtgctgggctgctgctttgctgcccccagacagcgccagtccacccttgtgctcttccctggagacctgagaaccaatctcaccgacaggcagctggcagaggaatacctgtaccgctatggttacactcgggtggcagagatgcgtggagagtcgaaatctctggggcctgcgctgctgcttctccagaagcaactgtccctgcccgagaccggtgagctggatagcgccacgctgaaggccatgcgaaccccacggtgcggggtcccagacctgggcagattccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgagccacggcctccaaccaccaccacaccgcagcccacggctcccccgacggtctgccccaccggaccccccactgtccacccctcagagcgccccacagctggccccacaggtcccccctcagctggccccacaggtccccccactgctggcccttctacggccactactgtgcctttgagtccggtggacgatgcctgcaacgtgaacatcttcgacgccatcgcggagattgggaaccagctgtatttgttcaaggatgggaagtactggcgattctctgagggcagggggagccggccgcagggccccttccttatcgccgacaagtggcccgcgctgccccgcaagctggactcggtctttgaggagcggctctccaagaagcttttcttcttctctgggcgccaggtgtgggtgtacacaggcgcgtcggtgctgggcccgaggcgtctggacaagctgggcctgggagccgacgtggcccaggtgaccggggccctccggagtggcagggggaagatgctgctgttcagcgggcggcgcctctggaggttcgacgtgaaggcgcagatggtggatccccggagcgccagcgaggtggaccggatgttccccggggtgcctttggacacgcacgacgtcttccagtaccgagagaaagcctatttctgccaggaccgcttctactggcgcgtgagttcccggagtgagttgaaccaggtggaccaagtgggctacgtgacctatgacatcctgcagtgccctgaggacgattacaaggatgacgacgataagtgataa(SEQ ID NO:774)
NFATc1P2-MMP9cat
(DNA)
caggcctggggacactcgcggcgggaagatttggaggggaggggagggggaggggcgtgggggcgcggcctcgctggagtccccctgaccccccgacccccgcccaccggcctgggcgtcctcccgcggcccctcctcccctcccggcgcccggtgctctggggcgcgtgccacgcctggctcggcgccgtaggggcccccgcaggtagagacccctggaaatggcctcgacgccgcaggagcgaggcggccaccaccccgctaatccgggcacgtctctccaggccgaggcctgcggtggaaaagccggggttccatttgtgctgagtcggggcggccgaatggagccaggcctcgggacgcgggacggacgggctctggccgcgcaccttcgcgggctctgcagcgcccgaccgcctcccccggcagggaggaggcgcttgtggggggcacccacggggcacagtgatccctgggggtctgcggacctcctgggccccgcagcagacacgagtttagcctttgggtttagtttaaatcacataagggtgtcgtgcaatcgatttatggtttctacacaccagacactttaacctccaaccccccccatccaaagccaacaagaaaatgcggtgccgtgttggcagctgagctgcgcccgaagagacgcagggagacgtaagagaggaaagtgtgagtggccggggggcctccccccgtcagaagtcgcgcagtcgcgcccataaaacgccccctccgggcggctagggcaggtgagcgcgtccccgggcctccccacgccggcccctgccacaggccgtctaggtcgagcagatatttacagaataaaaatgacaataactcgacgtcccgggacggccacgcaatctgttagtaatttagcgggatgggaatttcctttctagggcctgccagtgaagcgcttttccaaatttccacagcgggggaagcctgcgattttacataatgacttcagcatgccgggctttctcgacacccctccccggcccccggcccccgccccccgccccttttccagcagggccgggctccctccggacacccgcgtggactcaggcgtcccgtctggcccgttcgcccccgtttcccccgccagccccagcgcccccctgcccggcccccggattccccgttcccgcccctacgcccccatcccctccccgtgcgcccctccccgtgcgcccccctccccgtgcgccccccctccccgtgcgcccccctccccgtgcgccccccctccccgggcgcccccctccccgggcgccccccctccccgtgcgcccccccctccccgtgcgccccccctccccgtgcgcgccccgcctcttgcgcccctgcccccaggcgagcggctgccgcggcgcggggaggggcgggcgctcggcgactcgtccccggggccccgcgcgggcccgggcagcaggggcgtgatgtcacggcagggagggggcgcgggagccgccgggccggcggggaggcgggggaggtgttttccagctttaaaaaggcaggaggcagagcgcggccctgcgtcagagcgagactcagaggctccgaactcgccggcggagtcgccgcgccagatcccagcagcagggcgcggaagcttctctcgacattcgtttctagagccaccatgagcctctggcagcccctggtcctggtgctcctggtgctgggctgctgctttgctttccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgattacaaggatgacgacgataagtgataa(SEQ ID NO:775)
NFAT应答元件2
(DNA)
aagaggaaaatttgtttcatacagaaggcgtt(SEQ ID NO:776)
NFAT应答元件2重复
(DNA)
aagaggaaaatttgtttcatacagaaggcgttaagaggaaaatttgtttcatacagaaggcgttaagaggaaaatttgtttcatacagaaggcgttaagaggaaaatttgtttcatacagaaggcgtt(SEQ ID NO:777)
CMV最小启动子2
(DNA)
taggcgtgtacggtgggaggcctatataagcagagctcgtttagtgaaccgtcagatcgcctggagacgccatccacgctgttttgacctccatagaagacaccgggaccgatccagc(SEQ ID NO:778)
NFATRE2mCMV2-MMP9
(DNA)
aagaggaaaatttgtttcatacagaaggcgttaagaggaaaatttgtttcatacagaaggcgttaagaggaaaatttgtttcatacagaaggcgttaagaggaaaatttgtttcatacagaaggcgttactagttaggcgtgtacggtgggaggcctatataagcagagctcgtttagtgaaccgtcagatcgcctggagacgccatccacgctgttttgacctccatagaagacaccgggaccgatccagcctctcgacattcgtttctagagccaccatgagcctctggcagcccctggtcctggtgctcctggtgctgggctgctgctttgctgcccccagacagcgccagtccacccttgtgctcttccctggagacctgagaaccaatctcaccgacaggcagctggcagaggaatacctgtaccgctatggttacactcgggtggcagagatgcgtggagagtcgaaatctctggggcctgcgctgctgcttctccagaagcaactgtccctgcccgagaccggtgagctggatagcgccacgctgaaggccatgcgaaccccacggtgcggggtcccagacctgggcagattccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgagccacggcctccaaccaccaccacaccgcagcccacggctcccccgacggtctgccccaccggaccccccactgtccacccctcagagcgccccacagctggccccacaggtcccccctcagctggccccacaggtccccccactgctggcccttctacggccactactgtgcctttgagtccggtggacgatgcctgcaacgtgaacatcttcgacgccatcgcggagattgggaaccagctgtatttgttcaaggatgggaagtactggcgattctctgagggcagggggagccggccgcagggccccttccttatcgccgacaagtggcccgcgctgccccgcaagctggactcggtctttgaggagcggctctccaagaagcttttcttcttctctgggcgccaggtgtgggtgtacacaggcgcgtcggtgctgggcccgaggcgtctggacaagctgggcctgggagccgacgtggcccaggtgaccggggccctccggagtggcagggggaagatgctgctgttcagcgggcggcgcctctggaggttcgacgtgaaggcgcagatggtggatccccggagcgccagcgaggtggaccggatgttccccggggtgcctttggacacgcacgacgtcttccagtaccgagagaaagcctatttctgccaggaccgcttctactggcgcgtgagttcccggagtgagttgaaccaggtggaccaagtgggctacgtgacctatgacatcctgcagtgccctgaggacgattacaaggatgacgacgataagtgataa(SEQ ID NO:779)
NFATRE2mCMV2-MMP9cat
(DNA)
aagaggaaaatttgtttcatacagaaggcgttaagaggaaaatttgtttcatacagaaggcgttaagaggaaaatttgtttcatacagaaggcgttaagaggaaaatttgtttcatacagaaggcgttactagttaggcgtgtacggtgggaggcctatataagcagagctcgtttagtgaaccgtcagatcgcctggagacgccatccacgctgttttgacctccatagaagacaccgggaccgatccagcctcgagctctcgacattcgtttctagagccaccatgagcctctggcagcccctggtcctggtgctcctggtgctgggctgctgctttgctttccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgattacaaggatgacgacgataagtgataa(SEQID NO:780)
NFATc1启动子片段(P1)
(DNA)
aggcaggaggaagaggaaaggggcgcagggcgctcggggagcagagccgggggcccgcggtggccgcagaggccgggccggggcgcagaggccgggcgagctggccgcgctctgggccgccgcctccggaactccctgcgcctggcgcgcggccaccgtggtcccggcaacggcattaaacagagggaaacagacccgggattccgtcacccgggcggggggataaggacggctttgagagcagacaggaaaagggagcttttctgcatggggtgaaaaaattatttattgaaggaggaggaggcggcagcggaggaaggggaggggcgggaggaggaggaagagccggccgcccccgccccggccccggctcctcaggagccaagggcagcctcgccaggtcggtcccgggctcgaggaccgcggctggggtcgaggggctcagtctcccacgtgaccggctgggcgcgccccgccagacccggcctcgggattccctcctcccggcgagtctccgcccgccccgtcctggaggtggggagaaggagggcggggcgggggggacggaaactctccccgccaaatcctggccccaggcctggggacactcgcggcgggaagatttggaggggaggggagggggaggggcgtgggggcgcggcctcgctggagtccccctgaccccccgacccccgcccaccggcctgggcgtcctcccgcggcccctcctcccctcccggcgcccggtgctctggggcgcgtgccacgcctggctcggcgccgtaggggcccccgcaggtagagacccctggaaatggcctcgacgccgcaggagcgaggcggccaccaccccgctaatccgggcacgtctctccaggccgaggcctgcggtggaaaagccggggttccatttgtgctgagtcggggcggccgaatggagccaggcctcgggacgcgggacggacgggctctggccgcgcaccttcgcgggctctgcagcgcccgaccgcctcccccggcagggaggaggcgcttgtggggggcacccacggggcacagtgatccctgggggtctgcggacctcctgggccccgcagcagacacgagtttagcctttgggtttagtttaaatcacataagggtgtcgtgcaatcgatttatggtttctacacaccagacactttaacctccaaccccccccatccaagccaacaagaaaatgcggtgccgtgttggcagctgagctgcgcccgaagagacgcagggagacgtaagagaggaaagtgtgagtggccggggggcctccccccgtcagaagtcgcgcagtcgcgcccataaaacgccccctccgggcggctagggcaggtgagcgcgtccccgggcctccccacgccggcccctgccacagagccgtctaggtcgagcagatatttacagaataaaaatgacaataactcgacgtcccgggacggccacgcaatctgttagtaatttagcgggatgggaatttcctttctagggcctgccagtgaagcgcttttccaaatttccacagcgggggaagcctgcgattttacataatgacttcagcatgccgggctttctcgacacccctccccggcccccggcccccgccccccgccccttttccagcagggccgggctccctccggacacccgcgtggactcaggcgtcccgtctggcccgttcgcccccgtttcccccgccagccccagcgcccccctgcccggcccccggattccccgttcccgcccctacgcccccatcccctccccgtgcgcccctccccgtgcgcccccctccccgtgcgccccccctccccgtgcgcccccctccccgtgcgccccccctccccgggcgcccccctccccgggcgccccccctccccgtgcgcccccccctccccgtgcgccccccctccccgtgcgcgccccgcctcttgcgcccctgcccccaggcgagcggctgccgcggcgcggggaggggcgggcgctcggcgactcgtccccggggccccgcgcgggcccgggcagcaggggcgtgatgtcacggcagggagggggcgcgggagccgccgggccggcggggaggcgggggaggtgttttccagctttaaaaaggcaggaggcagagcgcggccctgcgtcagagcgagactcagaggctccgaactcgccggcggagtcgccgcgccagatcccagcagcagggcgcgg(SEQ ID NO:781)
NFATc1启动子片段(P2)
(DNA)
aggcaggaggaagaggaaaggggcgcagggcgctcggggagcagagccgggggcccgcggtggccgcagaggccgggccggggcgcagaggccgggcgagctggccgcgctctgggccgccgcctccggaactccctgcgcctggcgcgcggccaccgtggtcccggcaacggcattaaacagagggaaacagacccgggattccgtcacccgggcggggggataaggacggctttgagagcagacaggaaaagggagcttttctgcatggggtgaaaaaattatttattgaaggaggaggaggcggcagcggaggaaggggaggggcgggaggaggaggaagagccggccgcccccgccccggccccggctcctcaggagccaagggcagcctcgccaggtcggtcccgggctcgaggaccgcggctggggtcgaggggctcagtctcccacgtgaccggctgggcgcgccccgccagacccggcctcgggattccctcctcccggcgagtctccgcccgccccgtcctggaggtggggagaaggagggcggggcgggggggacggaaactctccccgccaaatcctggccccaggcctggggacactcgcggcgggaagatttggaggggaggggagggggaggggcgtgggggcgcggcctcgctggagtccccctgaccccccgacccccgcccaccggcctgggcgtcctcccgcggcccctcctcccctcccggcgcccggtgctctggggcgcgtgccacgcctggctcggcgccgtaggggcccccgcaggtagagacccctggaaatggcctcgacgccgcaggagcgaggcggccaccaccccgctaatccgggcacgtctctccaggccgaggcctgcggtggaaaagccggggttccatttgtgctgagtcggggcggccgaatggagccaggcctcgggacgcgggacggacgggctctggccgcgcaccttcgcgggctctgcagcgcccgaccgcctcccccggcagggaggaggcgcttgtggggggcacccacggggcacagtgatccctgggggtctgcggacctcctgggccccgcagcagacacgagtttagcctttgggtttagtttaaatcacataagggtgtcgtgcaatcgatttatggtttctacacaccagacactttaacctccaaccccccccatccaagccaacaagaaaatgcggtgccgtgttggcagctgagctgcgcccgaagagacgcagggagacgtaagagaggaaagtgtgagtggccggggggcctccccccgtcagaagtcgcgcagtcgcgcccataaaacgccccctccgggcggctagggcaggtgagcgcgtccccgggcctccccacgccggcccctgccacagagccgtctaggtcgagcagatatttacagaataaaaatgacaataactcgacgtcccgggacggccacgcaatctgttagtaatttagcgggatgggaatttcctttctagggcctgccagtgaagcgcttttccaaatttccacagcgggggaagcctgcgattttacataatgacttcagcatgccgggctttctcgacacccctccccggcccccggcccccgccccccgccccttttccagcagggccgggctccctccggacacccgcgtggactcaggcgtcccgtctggcccgttcgcccccgtttcccccgccagccccagcgcccccctgcccggcccccggattccccgttcccgcccctacgcccccatcccctccccgtgcgcccctccccgtgcgcccccctccccgtgcgccccccctccccgtgcgcccccctccccgtgcgccccccctccccgggcgcccccctccccgggcgccccccctccccgtgcgcccccccctccccgtgcgccccccctccccgtgcgcgccccgcctcttgcgcccctgcccccaggcgagcggctgccgcggcgcggggaggggcgggcgctcggcgactcgtccccggggccccgcgcgggcccgggcagcaggggcgtgatgtcacggcagggagggggcgcgggagccgccgggccggcggggaggcgggggaggtgttttccagctttaaaaaggcaggaggcagagcgcggccctgcgtcagagcgagactcagagg(SEQ ID NO:782)
NFATc1启动子片段(P3)
(DNA)
caggcctggggacactcgcggcgggaagatttggaggggaggggagggggaggggcgtgggggcgcggcctcgctggagtccccctgaccccccgacccccgcccaccggcctgggcgtcctcccgcggcccctcctcccctcccggcgcccggtgctctggggcgcgtgccacgcctggctcggcgccgtaggggcccccgcaggtagagacccctggaaatggcctcgacgccgcaggagcgaggcggccaccaccccgctaatccgggcacgtctctccaggccgaggcctgcggtggaaaagccggggttccatttgtgctgagtcggggcggccgaatggagccaggcctcgggacgcgggacggacgggctctggccgcgcaccttcgcgggctctgcagcgcccgaccgcctcccccggcagggaggaggcgcttgtggggggcacccacggggcacagtgatccctgggggtctgcggacctcctgggccccgcagcagacacgagtttagcctttgggtttagtttaaatcacataagggtgtcgtgcaatcgatttatggtttctacacaccagacactttaacctccaaccccccccatccaaagccaacaagaaaatgcggtgccgtgttggcagctgagctgcgcccgaagagacgcagggagacgtaagagaggaaagtgtgagtggccggggggcctccccccgtcagaagtcgcgcagtcgcgcccataaaacgccccctccgggcggctagggcaggtgagcgcgtccccgggcctccccacgccggcccctgccacaggccgtctaggtcgagcagatatttacagaataaaaatgacaataactcgacgtcccgggacggccacgcaatctgttagtaatttagcgggatgggaatttcctttctagggcctgccagtgaagcgcttttccaaatttccacagcgggggaagcctgcgattttacataatgacttcagcatgccgggctttctcgacacccctccccggcccccggcccccgccccccgccccttttccagcagggccgggctccctccggacacccgcgtggactcaggcgtcccgtctggcccgttcgcccccgtttcccccgccagccccagcgcccccctgcccggcccccggattccccgttcccgcccctacgcccccatcccctccccgtgcgcccctccccgtgcgcccccctccccgtgcgccccccctccccgtgcgcccccctccccgtgcgccccccctccccgggcgcccccctccccgggcgccccccctccccgtgcgcccccccctccccgtgcgccccccctccccgtgcgcgccccgcctcttgcgcccctgcccccaggcgagcggctgccgcggcgcggggaggggcgggcgctcggcgactcgtccccggggccccgcgcgggcccgggcagcaggggcgtgatgtcacggcagggagggggcgcgggagccgccgggccggcggggaggcgggggaggtgttttccagctttaaaaaggcaggaggcagagcgcggccctgcgtcagagcgagactcagaggctccgaactcgccggcggagtcgccgcgccagatcccagcagcagggcgcgg(SEQ ID NO:783)
pNFAT-MMP9cat-1 gBLOCK序列
(DNA)
aagaggaaaatttgtttcatacagaaggcgttactagttaggcgtgtacggtgggaggcctatataagcagagctcgtttagtgaaccgtcagatcgcctggagacgccatccacgctgttttgacctccatagaagacaccgggaccgatccagcctctcgacattcgtttctagagccaccatgagcctctggcagcccctggtcctggtgctcctggtgctgggctgctgctttgctttccaaacctttgagggcgacctcaagtggcaccaccacaacatcacctattggatccaaaactactcggaagacttgccgcgggcggtgattgacgacgcctttgcccgcgccttcgcactgtggagcgcggtgacgccgctcaccttcactcgcgtgtacagccgggacgcagacatcgtcatccagtttggtgtcgcggagcacggagacgggtatcccttcgacgggaaggacgggctcctggcacacgcctttcctcctggccccggcattcagggagacgcccatttcgacgatgacgagttgtggtccctgggcaagggcgtcgtggttccaactcggtttggaaacgcagatggcgcggcctgccacttccccttcatcttcgagggccgctcctactctgcctgcaccaccgacggtcgctccgacggcttgccctggtgcagtaccacggccaactacgacaccgacgaccggtttggcttctgccccagcgagagactctacacccaggacggcaatgctgatgggaaaccctgccagtttccattcatcttccaaggccaatcctactccgcctgcaccacggacggtcgctccgacggctaccgctggtgcgccaccaccgccaactacgaccgggacaagctcttcggcttctgcccgacccgagctgactcg(SEQ IDNO:784)
pNFAT-MMP9cat-2 gBLOCK序列:
(DNA)
ttcggcttctgcccgacccgagctgactcgacggtgatggggggcaactcggcgggggagctgtgcgtcttccccttcactttcctgggtaaggagtactcgacctgtaccagcgagggccgcggagatgggcgcctctggtgcgctaccacctcgaactttgacagcgacaagaagtggggcttctgcccggaccaaggatacagtttgttcctcgtggcggcgcatgagttcggccacgcgctgggcttagatcattcctcagtgccggaggcgctcatgtaccctatgtaccgcttcactgaggggccccccttgcataaggacgacgtgaatggcatccggcacctctatggtcctcgccctgaacctgattacaaggatgacgacgataagtgataagctagctcgactcgacaatcaacctctggattacaaaatttgtgaaagattgactggtattcttaactatgttgctccttttacgctatgtggatacgctgctttaatgcctttgtatcatgctattgcttcccgtatggctttcattttctcctccttgtataaatcctggttgctgtctctttatgaggagttgtggcccgttgtcaggcaacgtggcgtggtgtgcactgtgtttgctgacgcaacccccactggttggggcattgccaccacctgtcagctcctttccgggactttcgctttccccctccctattgccacggcggaactcatcgccgcctgccttgcccgctgctggacaggggctcggctgttgggcactgacaattccgtggtgttgtcggggaaatcatcgtcctttccttggctgctcgcctgtgttgccacctggattctgcgcgggacgtccttctgctacgtcccttcggccctcaatccagcggaccttccttcccgcggcctgctgccggctctgcggcctcttccgcatcttcgccttcgccctcagacgagtcggatctccctttgggccgcctccccgcctggaattaattcgagctcggtacctttaagaccaatgacttacaaggcagctgtag(SEQ ID NO:785)
引物
(DNA)
tagatggtaccaagaggaaaatttgtttcatacag(SEQ ID NO:786)
引物
(DNA)
tagataagcttgctggatcggtcccggtgtc(SEQ ID NO:787)
引物
(DNA)
tcatacagaaggcgttactagttaggcgtgtacggtgg(SEQ ID NO:788)
引物
(DNA)
acagtaccggattgccaagcttttatcacttatcgtcgtcatccttg(SEQ ID NO:789)引物
(DNA)
aagttggtaccgttccaaacctttgagggcgacc(SEQ ID NO:790)
引物
(DNA)
aagttctcgagcaggttcagggcgaggaccatag(SEQ ID NO:791)
引物
(DNA)
attgactcgagctctcgacattcgtttctagagc(SEQ ID NO:792)
引物
(DNA)
attgaaagcttttatcacttatcgtcgtcatccttg(SEQ ID NO:793)
引物
(DNA)
tagcaaaataggctgtccc(SEQ ID NO:794)
引物
(DNA)
attgactcgaggctggatcggtcccggtgtc(SEQ ID NO:795)
引物
(DNA)
aagacaccgggaccgatccagcctcgagagacccaagctggctagccacc(SEQ ID NO:796)引物
(DNA)
ttaccaacagtaccggattgccaagcttttatcacttatcgtcgtcatcc(SEQ ID NO:797)
引物
(DNA)
attgaaagcttctctcgacattcgtttctagagc(SEQ ID NO:798)
引物
(DNA)
attgagagctcttatcacttatcgtcgtcatc(SEQ ID NO:799)
NFAT modif 1 gBLOCK序列:
(DNA)
attctgtggataaccgtattaccgctagcatggatctcggggacgtctaactactaagcgagagtagggaactgccaggcatcaaataaaacgaaaggctcagtcggaagactgggcctttcgttttatctgttgtttgtcggtgaacgctctcctgagtaggacaaatccgccgggagcggatttgaacgttgtgaagcaacggcccggagggtggcgggcaggacgcccgccataaactgccaggcatcaaactaagcagaaggccatcctgacggatggcctttttgcgtttctacaaactcttcctgttagttagttacttaagctcgggccccaaattatgattttgttctgactgatagtgacctgttcgttgcaacaaattgataagcaatgcttttttataatgccaactttgtacaaaaaagcaggcttcgctgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattgggaagacaatagcaggcatgctggggatgcggtgggctctatggttcgaaggagatagaaccagatcttgactagtggtaccgaattccaggcctggggacactcgcggcgggaa(SEQ ID NO:800)
NFAT modif 2 gBLOCK序列:
(DNA)
acaaggatgacgacgataagtgataagagctcgctagcgatatcgccaccatgggggtaaaagttcttttcgcgcttatctgtatcgcggttgcagaagctaaaccaacagaaaataatgaagactttaacattgttgccgtggcatcgaacttcgccacaaccgatttggacgctgatcgcgggaaactgcccggcagccaccacggctcgcaaagctcggtttgcccggacttgcaccgttgtgggcgcgggcaagcgcatcgtgagcagcgtcgcttgcagcaccgtgggcgcggccagcaattacgcgaccacggaagccgttgttaaccacgcgaagtagcacgtcaagaagctgccgctggaggtgctcaaagagctggaagccaatgcccggaaagctggctgcaccaggggctgtctgatctgcctgtcccacatcaagtgcacgcccaagatgaagaagttcatcccaggacgctgccacacctacgaaggcgacaaagagtccgcacagggcggcataggcgaggcgatcgtcgacattcctgagattcctgggttcaaggacttggagcccctggagcagttcatcgcacaggtcgatctgtgtgtggactgcacaactggctgcctcaaagggcttgccaacgtgcagtgttctgacctgctcaagaagtggctgccgcaacgctgtgcgacctttgccagcaagatccagggccaggtggacaagatcaagggggccggtggtgactaagcggccgctcgagcatgcatctagaaataattcttactgt(SEQ ID NO:801)
引物
(DNA)
acaaaattcaaaattttatcgatactagttggcctaactggccggtaccaag(SEQ ID NO:802)
引物
(DNA)
atccgatttaaattcgaattcgctagcttatcacttatcgtcgtcatcc(SEQ ID NO:803)
NFAT共有序列:
(A/T)GGAAA(A/N)(A/T/C)N(SEQ ID NO:804)
当前的NFAT RE(Form System Biosciences.序列来自小鼠IL2启动子
(DNA)
aagaggaaaatttgtttcatacagaaggcgtt(SEQ ID NO:805)
小鼠IL2启动子(NFAT RE使用绿色高亮,黄色高亮是起始密码子)
(DNA)
aactagagacatataaaataacaccaacatccttagatacaacccttcctgagaatttattggacatcatactctttttaaaaagcataataaacatcaagacacttacacaaaatatgttaaattaaatttaaaacaacaacgacaaaatagtacctcaagctcaacaagcattttaggtgtccttagcttactatttctctggctaactgtatgaagccatctatcaccctgtgtgcaattagctcattgtgtagataagaaggtaaaaccatcttgaaacaggaaaccaatatccttcctgtctaatcaacaaatctaaaagatttattcttttcatctatctcctcttgcgtttgtccaccacaacaggctgcttacaggttcaggatggttttgacaaagagaacattttcatgagttacttttgtgtctccaccccaaagaggaaaatttgtttcatacagaaggcgttcattgtatgaattaaaactgccacctaagtgtgggctaacccgaccaagagggatttcacctaaatccattcagtcagtgtatgggggtttaaagaaattccagagagtcatcagaagaggaaaaacaaaaggtaatgctttctgccacacaggtagactctttgaaaatatgtgtaatatgtaaaacatcgtgacacccccatattatttttccagcattaacagtataaattgcctcccatgctgaagagctgcctatcacccttgctaatcactcctcacagtgacctcaagtcctgcaggcatgtacagcatgcagctcgcatcctgtgtcac(SEQ ID NO:806)
NFAT RE(Form PRomega.序列来自人IL2启动子
(DNA)
ggaggaaaaactgtttcatacagaaggcgt(SEQ ID NO:807)
可能的NFAT RE(来自ET-1启动子)
(DNA)
tccagggaaaatcggagtagaacaagagggatg(SEQ ID NO:808)
可能的NFAT RE(来自ET-1启动子)
(DNA)
actgttggaaaacgtaaacacgttattaaacggt(SEQ ID NO:809)
可能的NFAT RE(来自人CD3γ)
(DNA)
tccttaacggaaaaacaaaa(SEQ ID NO:810)
可能的NFAT RE(来自人CD3γ)
(DNA)
aaaggaaaaagtatatgttc(SEQ ID NO:811)
可能的NFAT RE(来自人IL3启动子)
(DNA)
atgccatggaaagggtg(SEQ ID NO:812)
可能的NFAT RE(来自人GPC6)
(DNA)
aaggggaaatgttgagtctaga(SEQ ID NO:813)
可能的NFAT RE(来自人生长激素释放激素)
(DNA)
AACTTGGAAAAGCATAG(SEQ ID NO:814)
NFATc1启动子大
(DNA)
ttatgccgtctagaggagacatactttctactcaaagctacacacatagactacaacgatgggaaaagacgacacaccaacagcgacttcaggaaagctggagtggctgctaatgttagacaaaataggctttttaaaaaaggttttattaaagaggaatgtttcgtaatgataaaagcactaatctgtgagaaagatacaacaatgataaacatacgtgcagctaataagagagctccaaaatctatgaagcaaaaactcacagaatgaggggagaagcagttctacaacagagaatggggacttcgatactccactttcaataatggatacaacaaccaggcagataacaaggcaacagaaggcctgaacaacagtataaaccaattagacctaccagatatctatagctagcacactccacccaacgacagcagaatacacattcttctcaagcgcacaagtaacatcctccaggatgggccatgttctaggccatcaaacaaactcaggtggtttgaggccagaggcctctcttttaaccaccacactagggccttcggaggaggcaagcagagagttgtcaaagaggccctcaggactgggtgcagtggctcatgactgtaatcccagcactttagaaggctgaggcacaaggatcttttgagctcaggagttcaagaaatgagcacttatccactgggcgcggtggctcacgccagtaatccagcactttgggaggcttaggcgggcggatcaagaggtcagaagctcaagaccagcctgaccaacatggtgaaaccccgtctctactaaaagtacaaaaattagccgggcgtggtggcgcacacctgtaatcccagctacttgggaggctgaggcaggagaatcacttgaacccgggaggtggaggttgcagtgagtggagatcacaccattgcaccccagcctgggcaacagagcgagactccgtctcaaaaaaaaaaaaaaaaaaaaagaaagaaagaaaaagaaaaaaaaagtgagcatgtattttgccagagtctggagattagaattaaattagcaaaccagaattatagaaaaagctatttacttttaagtaaacagctgagatttttttttttaagtcagtgtgaatgaagctcacagccatggttggagctgagaaagaaggatttccctttagttatgcacctgtgtcagcaccttctgactttccttctaaagtctggggtgttcctgaggatccgtaagtttggggttcagggtttctacagcatgctgttacttgtgaaacatctctttaaccatgtcccagagttgcccaggagtttaagaccagcctgagcaacatagcaagacctcatctcaacaacaacaaaaattagaaataaattagccaggtgtggtgacatgtgcctgtagtcccagctactcagaaggctgaggcatgaggatcacttgggcccaggaagttggggctgcagggagccctgttcatgccgctgcactccagcctgcaagacagagcagaaaaaaagaatcaggatcctgggcagagggaggagaggggaccggggtccagcaagcacttggggattgactgaatggcgttggggagagatgactccaaagtcctggagtgggtgagaatgactgcgagtggcttttaggtggggaggttcctgcctggccactccgggaggggacgtggggctgaagggtatcaggtgccgtgctgagcagtttggccttgatcctaatgccctggacacacgtctagggtaggaaagttgactgatccattggtgatctgagtttttagacatggtggtagtccatgaggtgggtgttcatgctaagagtttagacagggaaacctatgaagcccttagcaaccctccagggaaggggcgtggttaaagagatgtttcataagtaacagcatggtatagaaactctgaaccccaaatgtatgggtcctcaggaacaccccagactttagaaggaaagtcagaaggtgctgacacgggtgtataactaaagggaaatccttctttctcagctccaaccatggctgtgaggttcattcacactgacttaaaaaaaaaaatctcagtttacttaaaagtaaatagctttttctataattctggtttgctaatttaatcctagtctccagaccctggctaaataaatgcccatttctccagatggtctcaagagtctctggacatcgtgggggcccttccctgttggttggaaggtgcctcaggaagaagggggtggattctgagttgagtcaaaacctcaaagacccctgatgggaaaagctctcaagtgaccaccgctgtgggccagaatgcaaaactgcaggaacagaacattcgcaggaacagaacacagtcgtattaagtgattttcccgagcaggaagtggcatctggcctgcggttcagtagggggaggaaagggtgggcgcacctgcccctggctggcgcacctgccaggtagccccacgcggcaccgcgtgtgccgagcgcccctgaggatggaaagccccacgcggggcaggtggcacccaccctccgaagacgggacgggatggagcgttgagcttcggggcagctccggcccggcccgcgctggagacgcccgcatctgccaggatggcgtctcatagccctggtgctcacacatgacgccaggaagccccagcaacagtgaccgcccaggctctagaaaatattggacggggtggatgaacacccaagtgcgctccaggagaagggatttggcaccccaaggggcttttaaaacggtaagcttctaggggtgtctttgcccccaataatccatagaaacaacagtcatctaaaaatagtcttgttttctgtcctaagctccttttaactttgttagtcatcaccaatcctaaaataaaacccgtgtaacgtctcccctagtagcggctataaacaaacctacgaggaggcaggaggaagaggaaaggggcgcagggcgctcggggagcagagccgggggcccgcggtggccgcagaggccgggccggggcgcagaggccgggcgagctggccgcgctctgggccgccgcctccggaactccctgcgcctggcgcgcggccaccgtggtcccggcaacggcattaaacagagggaaacagacccgggattccgtcacccgggcggggggataaggacggctttgagagcagacaggaaaagggagcttttctgcatggggtgaaaaaattatttattgaaggaggaggaggcggcagcggaggaaggggaggggcgggaggaggaggaagagccggccgcccccgccccggccccggctcctcaggagccaagggcagcctcgccaggtcggtcccgggctcgaggaccgcggctggggtcgaggggctcagtctcccacgtgaccggctgggcgcgccccgccagacccggcctcgggattccctcctcccggcgagtctccgcccgccccgtcctggaggtggggagaaggagggcggggcgggggggacggaaactctccccgccaaatcctggccccaggcctggggacactcgcggcgggaagatttggaggggaggggagggggaggggcgtgggggcgcggcctcgctggagtccccctgaccccccgacccccgcccaccggcctgggcgtcctcccgcggcccctcctcccctcccggcgcccggtgctctggggcgcgtgccacgcctggctcggcgccgtaggggcccccgcaggtagagacccctggaaatggcctcgacgccgcaggagcgaggcggccaccaccccgctaatccgggcacgtctctccaggccgaggcctgcggtggaaaagccggggttccatttgtgctgagtcggggcggccgaatggagccaggcctcgggacgcgggacggacgggctctggccgcgcaccttcgcgggctctgcagcgcccgaccgcctcccccggcagggaggaggcgcttgtggggggcacccacggggcacagtgatccctgggggtctgcggacctcctgggccccgcagcagacacgagtttagcctttgggtttagtttaaatcacataagggtgtcgtgcaatcgatttatggtttctacacaccagacactttaacctccaaccccccccatccaaagccaacaagaaaatgcggtgccgtgttggcagctgagctgcgcccgaagagacgcagggagacgtaagagaggaaagtgtgagtggccggggggcctccccccgtcagaagtcgcgcagtcgcgcccataaaacgccccctccgggcggctagggcaggtgagcgcgtccccgggcctccccacgccggcccctgccacaggccgtctaggtcgagcagatatttacagaataaaaatgacaataactcgacgtcccgggacggccacgcaatctgttagtaatttagcgggatgggaatttcctttctagggcctgccagtgaagcgcttttccaaatttccacagcgggggaagcctgcgattttacataatgacttcagcatgccgggctttctcgacacccctccccggcccccggcccccgccccccgccccttttccagcagggccgggctccctccggacacccgcgtggactcaggcgtcccgtctggcccgttcgcccccgtttcccccgccagccccagcgcccccctgcccggcccccggattccccgttcccgcccctacgcccccatcccctccccgtgcgcccctccccgtgcgcccccctccccgtgcgccccccctccccgtgcgcccccctccccgtgcgccccccctccccgggcgcccccctccccgggcgccccccctccccgtgcgcccccccctccccgtgcgccccccctccccgtgcgcgccccgcctcttgcgcccctgcccccaggcgagcggctgccgcggcgcggggaggggcgggcgctcggcgactcgtccccggggccccgcgcgggcccgggcagcaggggcgtgatgtcacggcagggagggggcgcgggagccgccgggccggcggggaggcgggggaggtgttttccagctttaaaaaggcaggaggcagagcgcggccctgcgtcagagcgagactcagaggctccgaactcgccggcggagtcgccgcgccagatcccagcagcagggcgcgggcaccggggcgcgggcagggctcggagccaccgcgcaggtcctagggccgcggccgggccccgccacgcgcgcacacgcccctcgatg(SEQ ID NO:815)
NFATc3引物序列
(DNA)
gcagccaggcagggtgggcgcgcgtagggggcggggccgggcgcgcggcagggcgcgagagcgcacccgcggcggcggtggcggcgactgtgggggggcggcggggaacattggctaagccgacagtggaggcttaggcaccggtggcgggcggctgcggttcctggtgctgctcggcgcgcggccagctttcggaacggaacgctcggcgtcgcgggccccgcccggaaagtttgccgtggagtcgcgacctcttggcccgcgcggcccggcatgaagcggcgttgaggagctgctgccgccgcttgccgctgccgccgccgccgcctgaggaggagctgcagcaccctgggccacgccg(SEQ ID NO:816)
NFATc2引物序列1
(DNA)
cagagagaggctgcgttcagactggggcactgccatcccctccgcatcatggggtctgtggaccaaggtaactgactctcgatcccttccagccttttccgctcgctcctcccggccctttcctgctgctcccgtcccgggcagcactttcagctcccggcagaggtcggtgcgggaggcctggggaccccgctcgccctcggcgcacaggtagcggggcccgcggaggggcgcccgcgccccggccagggaagggacacttgggaaggcgactttggacaactttacgcgggggcagggaagtgtcccaggccgggattccctaggccagtctgtcgggaggattttcctctccacgggacaccgggagggattctcgctactaaccgctggctgtttaaccgtttcagcactcggcttttgacagcaa(SEQ ID NO:817)
NFATc2引物序列2
(DNA)
catcatggggtctgtggaccaaggtaactgactctcgatcccttccagccttttccgctcgctc(SEQ ID NO:818)
NFATc1应答元件共序
(DNA)
cattttttccat(SEQ ID NO:819)
NFATc1应答元件共序
(DNA)
tttttcca(SEQ ID NO:820)
被包含在Foxp3增强区内的NFAT应答元件
(DNA)
acttgaaaatgagataaatgttcacctatgttggcttctagtctcttttatggcttcattttttccatttactatagaggttaagagtgtgggtactggagccagactgtctgggacaa(SEQ ID NO:821)
muE6 IgD/CD8/41BB/CD3z
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtgaaggtggtggagtctgggggagacttagtgaagcctggagggtccctgaaactctcctgtgtagtctctggattcactttcagtagatatggcatgtcttgggttcgccagactccaggcaagaggctggagtgggtcgcaaccattagtggtggcggtacttacatctactatccagacagtgtgaaggggcgattcaccatctccagagacaatgccaagaacaccctgtacctgcaaatgagcagtctgaagtctgaggacacagccatgtatcactgtacaagggataactacggtaggaactacgactacggtatggactactggggtcaaggaacctcagtcaccgtctcctcaggcggtggcggatccggcggtggcggatccggcggtggcggatcccaaattgttctcacccagtctccagcaatcatgtctgcatctccaggggaggaggtcaccctaacctgcagtgccacctcaagtgtaagttacatacactggttccagcagaggccaggcacttctcccaaactctggatttatagcacatccaacctggcttctggagtccctgttcgcttcagtggcagtggatatgggacctcttactctctcacaatcagccgaatggaggctgaagatgctgccacttattactgccagcaaaggagtagttccccattcacgttcggctcggggacaaagttggaaataaaagagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccaatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:822)
(氨基酸)
MALPVTALLLPLALLLHAARPEVKVVESGGDLVKPGGSLKLSCVVSGFTFSRYGMSWVRQTPGKRLEWVATISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMSSLKSEDTAMYHCTRDNYGRNYDYGMDYWGQGTSVTVSSGGGGSGGGGSGGGGSQIVLTQSPAIMSASPGEEVTLTCSATSSVSYIHWFQQRPGTSPKLWIYSTSNLASGVPVRFSGSGYGTSYSLTISRMEAEDAATYYCQQRSSSPFTFGSGTKLEIKESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:823)
muC2IgD/CD8/41BB/CD3z
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggaggagtcagggggaggcttagtgaagcctggagggtccctgaaactctcctgtgcagcctctggattcactttcagtggctatgccatgtcttgggttcgccagactccggagaagaggctggagtgggtcgcaaccattagtagtggtggtacttatatctactatccagacagtgtgaaggggcgattcaccatctccagagacaatgccaagaacaccctgtacctgcaaatgagcagtctgaggtctgaggacacggccatgtattactgtgcaagacttgggggggataattactacgaatacttcgatgtctggggcgcagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgatcacacagtctacagcttccttaggtgtatctctggggcagagggccaccatctcatgcagggccagcaaaagtgtcagtacatctggctatagttatatgcactggtaccaacagagaccaggacagccacccaaactcctcatctatcttgcatccaacctagaatctggggtccctgccaggttcagtggcagtgggtctgggacagacttcaccctcaacatccatcctgtggaggaggaggatgctgcaacctattactgtcagcacagtagggagcttccgttcacgttcggaggggggaccaagctggagataaaagagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccaatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:824)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLEESGGGLVKPGGSLKLSCAASGFTFSGYAMSWVRQTPEKRLEWVATISSGGTYIYYPDSVKGRFTISRDNAKNTLYLQMSSLRSEDTAMYYCARLGGDNYYEYFDVWGAGTTVTVSSGGGGSGGGGSGGGGSDIVITQSTASLGVSLGQRATISCRASKSVSTSGYSYMHWYQQRPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLNIHPVEEEDAATYYCQHSRELPFTFGGGTKLEIKESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:825)
muE6 CD28/CD28/CD28/CD3z
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtgaaggtggtggagtctgggggagacttagtgaagcctggagggtccctgaaactctcctgtgtagtctctggattcactttcagtagatatggcatgtcttgggttcgccagactccaggcaagaggctggagtgggtcgcaaccattagtggtggcggtacttacatctactatccagacagtgtgaaggggcgattcaccatctccagagacaatgccaagaacaccctgtacctgcaaatgagcagtctgaagtctgaggacacagccatgtatcactgtacaagggataactacggtaggaactacgactacggtatggactactggggtcaaggaacctcagtcaccgtctcctcaggcggtggcggatccggcggtggcggatccggcggtggcggatcccaaattgttctcacccagtctccagcaatcatgtctgcatctccaggggaggaggtcaccctaacctgcagtgccacctcaagtgtaagttacatacactggttccagcagaggccaggcacttctcccaaactctggatttatagcacatccaacctggcttctggagtccctgttcgcttcagtggcagtggatatgggacctcttactctctcacaatcagccgaatggaggctgaagatgctgccacttattactgccagcaaaggagtagttccccattcacgttcggctcggggacaaagttggaaataaaaaaacacctttgtccaagtcccctatttcccggaccttctaagcccttttgggtgctggtggtggttggtggagtcctggcttgctatagcttgctagtaacagtggcctttattattttctgggtgagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:826)
(氨基酸)
MALPVTALLLPLALLLHAARPEVKVVESGGDLVKPGGSLKLSCVVSGFTFSRYGMSWVRQTPGKRLEWVATISGGGTYIYYPDSVKGRFTISRDNAKNTLYLQMSSLKSEDTAMYHCTRDNYGRNYDYGMDYWGQGTSVTVSSGGGGSGGGGSGGGGSQIVLTQSPAIMSASPGEEVTLTCSATSSVSYIHWFQQRPGTSPKLWIYSTSNLASGVPVRFSGSGYGTSYSLTISRMEAEDAATYYCQQRSSSPFTFGSGTKLEIKKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:827)
muC2 CD28/CD28/CD28/CD3z
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagaggtccagctggaggagtcagggggaggcttagtgaagcctggagggtccctgaaactctcctgtgcagcctctggattcactttcagtggctatgccatgtcttgggttcgccagactccggagaagaggctggagtgggtcgcaaccattagtagtggtggtacttatatctactatccagacagtgtgaaggggcgattcaccatctccagagacaatgccaagaacaccctgtacctgcaaatgagcagtctgaggtctgaggacacggccatgtattactgtgcaagacttgggggggataattactacgaatacttcgatgtctggggcgcagggaccacggtcaccgtctcctccggcggtggcggatccggcggtggcggatccggcggtggcggatccgacattgtgatcacacagtctacagcttccttaggtgtatctctggggcagagggccaccatctcatgcagggccagcaaaagtgtcagtacatctggctatagttatatgcactggtaccaacagagaccaggacagccacccaaactcctcatctatcttgcatccaacctagaatctggggtccctgccaggttcagtggcagtgggtctgggacagacttcaccctcaacatccatcctgtggaggaggaggatgctgcaacctattactgtcagcacagtagggagcttccgttcacgttcggaggggggaccaagctggagataaaaaaacacctttgtccaagtcccctatttcccggaccttctaagcccttttgggtgctggtggtggttggtggagtcctggcttgctatagcttgctagtaacagtggcctttattattttctgggtgagaagcaagcggtctcggctcctgcattctgattacatgaacatgaccccaagaagaccaggccccaccaggaaacattaccagccctacgctccgccacgcgacttcgctgcctaccggtcccgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:828)
(氨基酸)
MALPVTALLLPLALLLHAARPEVQLEESGGGLVKPGGSLKLSCAASGFTFSGYAMSWVRQTPEKRLEWVATISSGGTYIYYPDSVKGRFTISRDNAKNTLYLQMSSLRSEDTAMYYCARLGGDNYYEYFDVWGAGTTVTVSSGGGGSGGGGSGGGGSDIVITQSTASLGVSLGQRATISCRASKSVSTSGYSYMHWYQQRPGQPPKLLIYLASNLESGVPARFSGSGSGTDFTLNIHPVEEEDAATYYCQHSRELPFTFGGGTKLEIKKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:829)
CD19 IgD/CD8/41BB/CD3z
(DNA)
atggccctgcccgtgaccgctttgctgctccccctggcgctgctgctgcacgccgccaggccagacatacagatgacgcagacgaccagcagcctttccgcttccctgggcgaccgagtaaccattagttgtagagcatctcaggatatttctaagtatctgaattggtaccaacagaaacctgatggcactgtcaagctcttgatatatcacaccagtcgactccattcaggcgtcccttccagattcagtgggagtggcagcgggactgattactccctcactatctctaacctggaacaggaagacatcgctacatacttctgtcagcagggaaacactctcccctatacctttgggggaggaaccaagttggaaataacaggcggtggcggatccggcggtggcggatccggcggtggcggatccgaggtgaaactgcaggagtcaggacctggcctggtggcgccctcacagagcctgtccgtcacatgcactgtctcaggggtctcattacccgactatggtgtaagctggattcgccagcctccacgaaagggtctggagtggctgggagtaatatggggtagtgaaaccacatactataattcagctctcaaatccagactgaccatcatcaaggacaactccaagagccaagttttcttaaaaatgaacagtctgcaaactgatgacacagccatttactactgtgccaaacattattactacggtggtagctatgctatggactactggggccaaggaacctcagtcaccgtctcctcagagtctccaaaggcacaggcctcctcagtgcccactgcacaaccccaagcagagggcagcctcgccaaggcaaccacagccccagccaccacccgtaacacaggaagaggcggcgaagagaagaaaaaggagaaggagaaagaggaacaagaagagagagagacaaagacaccaatctacatttgggccccgctcgcaggcacatgtggagtgctcctcctctccctggtgattaccctgtactgcaaaaggggccgcaaaaaactcctttacatttttaagcagccttttatgaggccagtacagacgactcaagaggaagacgggtgctcatgccgctttcctgaggaggaggaaggagggtgcgaactgcgcgttaagttctcccgatcagccgacgcgcctgcttacaagcagggccagaaccaactgtacaacgagctgaatctcggtagacgggaagagtacgacgtgttggacaaacggagaggccgcgacccagaaatgggcggcaagcctcgcaggaaaaacccccaggagggactgtacaatgagttgcagaaagataagatggcagaagcttatagcgagatcggaatgaagggggaaaggagacgagggaaaggacacgacggcctttatcagggcctgtccacagcaacaaaagatacgtatgacgccctccatatgcaggcacttccaccacggtgataa(SEQ ID NO:830)
(氨基酸)
MALPVTALLLPLALLLHAARPDIQMTQTTSSLSASLGDRVTISCRASQDISKYLNWYQQKPDGTVKLLIYHTSRLHSGVPSRFSGSGSGTDYSLTISNLEQEDIATYFCQQGNTLPYTFGGGTKLEITGGGGSGGGGSGGGGSEVKLQESGPGLVAPSQSLSVTCTVSGVSLPDYGVSWIRQPPRKGLEWLGVIWGSETTYYNSALKSRLTIIKDNSKSQVFLKMNSLQTDDTAIYYCAKHYYYGGSYAMDYWGQGTSVTVSSESPKAQASSVPTAQPQAEGSLAKATTAPATTRNTGRGGEEKKKEKEKEEQEERETKTPIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR**(SEQ ID NO:831)
本领域技术人员将认识到或能够在不超过常规实验范围内确定本文具体描述的本发明具体实施例的许多等同物。
- 还没有人留言评论。精彩留言会获得点赞!