稳定表达抗TNF‑α单克隆抗体细胞表达体系的制作方法
本发明属于生物医药领域,是一种稳定表达抗tnf-α单克隆抗体细胞表达体系的构建及表达。
背景技术:
类风湿性关节炎(rheumatoidarthritis,ra)是一种原因不明的慢性全身免疫性炎症疾病,可引起全身的关节肿胀疼痛及功能障碍,是主要的致残性疾病之一,严重影响患者的生活质量。ra是一种世界范围的常见病,我国的患病率为0.3-0.4%,任何年龄均可发病,多见于30-50岁的女性。
目前治疗ra的药物主要包括非甾体类抗炎药(nonsteroidalantiinflammatorydrugs,nsaids)、改善病情抗风湿药(disease-modifyinganti-rheumaticdrugs,nmards)、肾上腺皮质激素、中药制剂及生物制剂等,由于ra的病因复杂,涉及细胞因子及免疫等作用,化学药物及中药制剂的治疗均对靶点缺乏针对性,而随着生物技术的飞速发展,特异性针对细胞因子作用的单克隆抗体等生物制剂已成为目前针对性最强,疗效最好的ra治疗药物,被视为根治ra的希望。其中,抗tnf-α单克隆抗体infliximab(商品名remicade)是已在美国广泛应用的ra一线治疗药物,疗效显著、起效快、药效持久。但该药物在国内的生产尚属空白,临床全部依赖于进口,治疗成本高昂。
另外,目前市售的抗tnf-α单克隆抗体是将轻链和重链通过两个质粒进行共表达,遗传稳定性相对较差。
技术实现要素:
本发明的目的在于克服现有技术的不足之处,通过在重链和轻链基因序列中间引入一个内部核糖体结合位点(ires),成功实现了轻链和重链双顺反独立共表达。同时,利用crispr-cas9技术,将抗tnfα单克隆抗体基因稳定的定点整合在宿主细胞的基因组中,在实现抗体稳定高效表达的同时灭活对细胞增殖及抗体表达生产具有潜在负面影响的基因,从而提升生产效能。
本发明的技术方案如下:
一种稳定表达抗tnf-α单克隆抗体细胞株,依照细胞密码子偏爱性优化的轻链、重链编码基因进行密码子,构建轻链、重链共表达的真核表达质粒,利用crispr-cas9技术实现抗体基因在宿主基因组的稳定定点整合,获得稳定表达抗tnf-α单克隆抗体的阳性细胞株。
而且,所述宿主细胞包括cho、ns0、sp2/0,cho细胞包括cho-k1、cho-s。
一种稳定表达抗tnf-α单克隆抗体细胞表达体系的构建方法,以不影响细胞基本存活能力、而对细胞增殖及抗体表达生产具有潜在负面影响的基因为靶标,构建特异性整合到靶基因位点的抗tnfα人鼠嵌合单克隆抗体同源重组质粒以及特异性切割靶基因的crispr/case9载体,通过将二者共同转染到宿主细胞中,经筛选成功获得稳定定点整合的抗tnf-α单克隆抗体lc与hc多顺反共表达细胞系。
而且,所述负面影响的基因包括bak1、bax、igfbp4、aqpi。
而且,所述抗体同源重组表达质粒是将轻链lc和重链hc以多顺反子形式通过内部核糖体结合位点ires串联在一起,从而实现独立共表达。
而且,构建方法如下:
(1)构建不影响细胞基本存活能力、而对细胞增殖及抗体表达生产具有潜在负面影响的基因为靶标的抗tnfα人鼠嵌合单克隆抗体同源重组载体,其中抗体轻链lc和重链hc以多顺反子形式通过内部核糖体结合位点ires串联在一起,从而实现独立共表达;
(2)针对负面影响的基因区域,构建了对靶基因位点具有特异性切割作用的crispr/case9载体;
(3)将上述两种表达质粒共转至宿主细胞中,经筛选成功获得稳定定点整合的抗tnf-α单克隆抗体lc与hc多顺反共表达细胞系。
而且,所述负面影响的基因包括bak1、bax、igfbp4、aqpi。
一种稳定表达抗tnf-α单克隆抗体的细胞表达体系在抗tnf-α单克隆抗体的生产等生物医药领域中的应用。
本发明的有益效果和优点是:
1、在克隆抗体轻链和重链序列时,对氨基酸密码子进行了优化,使目的序列中的密码子为cho细胞中的高效密码子。
2、通过在重链和轻链基因序列中间引入一个内部核糖体结合位点,成功实现了轻链和重链双顺反独立共表达,提高了其遗传稳定性。
3、利用crispr-cas9技术,将抗tnfα人鼠嵌合单克隆抗体基因插入到bak1、bax、igfbp4、aqpi等不影响细胞基本存活能力、对细胞增殖及抗体表达生产具有潜在负面影响的基因位置,一方面实现了抗体基因的稳定定点整合,提高重组细胞系的遗传稳定性,有利于产生的稳定高效使,另一方面使bak1、bax、igfbp4、aqpi等负面基因被插入失活,提高了细胞的增殖速度及抗体产生性能。
4、本发明以不影响细胞基本存活能力、对细胞增殖及抗体表达生产具有潜在负面影响的基因为靶标,构建特异性整合到靶基因位点的抗tnfα人鼠嵌合单克隆抗体同源重组质粒以及特异性切割靶基因的crispr/case9载体,通过将二者共同转染到宿主细胞中,经筛选成功获得稳定定点整合的抗tnf-α单克隆抗体lc与hc多顺反共表达细胞系。
附图说明
图1为px330-case9质粒图谱;
图2为本发明筛选的抗体重组细胞阳性克隆的rt-pcr结果。泳道1、2分别是抗体重组细胞及阴性对照细胞中提出的mrna反转录成的cdna为模板。图2a图是以lf和lr为引物,扩增出的lc基因片段。图2b图是以if和ir为引物,扩增出的ires基因片段。图2c图是以hf和hr为引物,扩增出的hc基因片段。三幅图中泳道2中均没有条带,而泳道1在大约720bp(a图)、600bp(b图)、1400bp(c图)处均有一条条带。分别与轻链基因、ires基因、重链基因大小是一样的。表明轻链基因、ires基因、重链基因已在cho-k1细胞中成功转录为mrna,为下一步合成蛋白奠定了基础。
图3为本发明筛选的抗体重组细胞阳性克隆的抗tnfα抗体与抗原结合的elisa结果。纵坐标24代表阴性对照,即转入空载质粒的cho细胞上清。横坐标是指阳性克隆荧光强度/细胞/天:阴性对照荧光强度/细胞/天。筛选出比值大于16的六株单克隆,分别是g1c3、g1f3、g2g1、g2h4、g2c5、g2f5。即是一天中单个细胞anti-tnf-αmab表达量最高的六株单克隆。
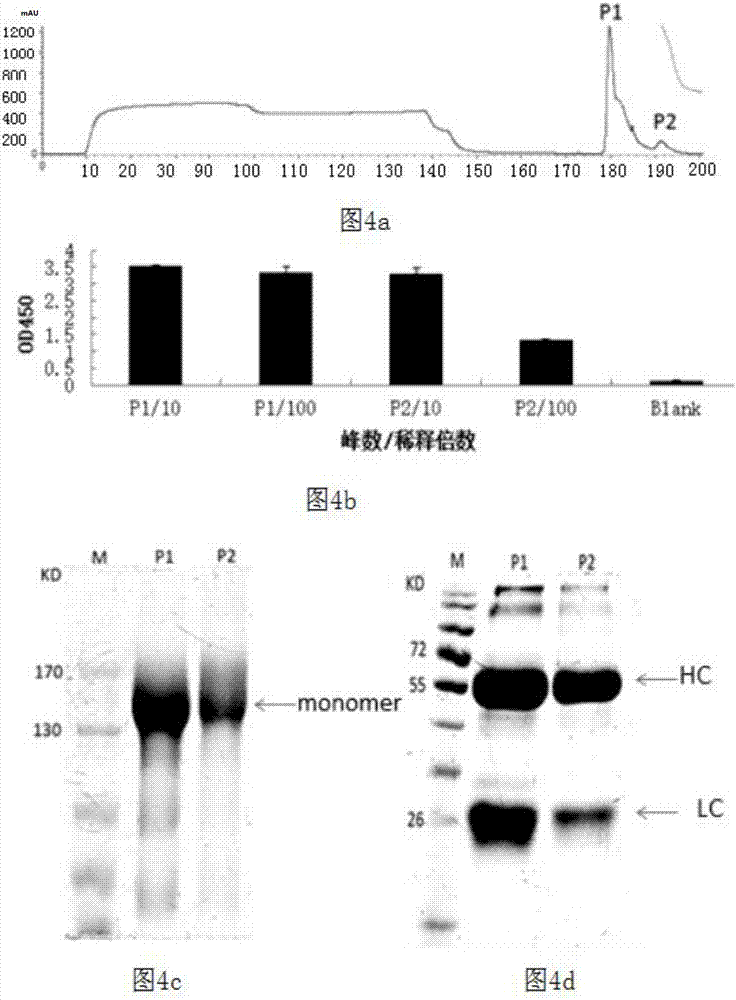
图4为本发明筛选的抗tnf-α抗体重组细胞表达生产抗tnf-α单抗的纯化及电泳检测。图4a.抗体纯化p1、p2代表两个洗脱峰;图4b.elisa检测p1和p2两洗脱峰中抗tnf-α单抗的含量;图4c、图4d.将纯化后的样品进行sds-page检测,图4c为不加还原剂条件下的电泳,图4d为加入还原剂dtt条件下的电泳
具体实施方式
下面通过具体实施例对本发明作进一步详述,以下实施例只是描述性的,不是限定性的,不能以此限定本发明的保护范围。
本发明提供一种稳定表达抗tnf-α单克隆抗体的细胞表达体系及构建方法和应用,具体内容包括:
一种稳定表达抗tnf-α单克隆抗体的细胞表达体系,依照细胞密码子偏爱性优化的轻、重链编码基因进行密码子,构建轻重链共表达的真核表达质粒,在此基础上构建以不影响细胞基本存活能力、对细胞增殖及抗体表达生产具有潜在负面影响的基因(bak1和bax)为靶标的抗体同源重组载体,同时针对靶基因构建具有特异性切割作用的crispr/case9载体,釆用脂质体转染的方式将两种载体共同导入cho-k1等宿主细胞并整合到细胞基因组上,筛选获得稳定表达抗tnf-α单克隆抗体的阳性细胞株。
以不影响细胞基本存活能力、而对细胞增殖及抗体表达生产具有潜在负面影响的基因为靶标,构建特异性整合到靶基因位点的抗tnfα人鼠嵌合单克隆抗体同源重组质粒以及特异性切割靶基因的crispr/case9载体,通过将二者共同转染到宿主细胞中,经筛选成功获得稳定定点整合的抗tnf-α单克隆抗体lc与hc多顺反共表达细胞系。
所述负面影响的基因包括bak1、bax、igfbp4、aqpi等抑制细胞高密度培养、无血清培养、悬浮培养等过程的基因。
一种稳定表达抗tnf-α单克隆抗体的细胞表达体系的构建方法,其特征在于:构建方法如下:
(1)构建以bak1、bax、igfbp4、aqpi等不影响细胞基本存活能力、而对细胞增殖及抗体表达生产具有潜在负面影响的基因为靶标的抗tnfα人鼠嵌合单克隆抗体同源重组载体,其中抗体轻链lc和重链hc以多顺反子形式通过内部核糖体结合位点(ires)串联在一起,从而实现独立共表达;
(2)针对bak1、bax、igfbp4、aqpi等不影响细胞基本存活能力、对细胞增殖及抗体表达生产具有潜在负面影响的基因区域,构建了对靶基因位点具有特异性切割作用的crispr/case9载体;
(3)将上述两种表达质粒共转至宿主细胞中,经筛选成功获得稳定定点整合的抗tnf-α单克隆抗体lc与hc多顺反共表达细胞系。
该稳定表达抗tnf-α单克隆抗体的细胞表达体系主要用于在生物医药领域进行tnf-α单克隆抗体的生产。
具体过程如下:
一、稳定表达抗tnf-α单克隆抗体重组质粒的构建(以靶向bak1为代表性过程),步骤如下:
1、重组质粒pcdna3.1-lc-ires-hc的构建
通过人工合成方法合成得到抗tnf-α单克隆抗体轻链(lc)、内部核糖体进入位点(ires)及抗体重链(hc)基因以此串联的lc-iers-hc基因,在两端分别引入酶切位点,经酶切、连接后插入到pcdna3.1载体上,从而构建了重组质粒pcdna3.1-lc-ires-hc。
2、以bak1基因为靶标的抗tnfα人鼠嵌合单克隆抗体同源重组载体的构建,步骤如下:
(1)在重组质粒pcdna3.1-lc-ires-hc构建的基础上,经bglii和bstz17i双酶切并回收能到两个片段,分别为片段1和片段2。
(2)在bak1靶点序列的上下游各选取一段序列作为同源重组质粒的同源模板,经过pcr扩增得到两个片段,分别为同源臂1和同源臂2。(引物分别含有片段1和片段2的同源序列)
其引物信息如下:
pcr反应条件见下表:
(3)将片段1、片段2、同源臂1、同源臂2进行同源重组,得到以bak1基因为靶标的抗tnfα人鼠嵌合单克隆抗体同源重组载体。
3、以bak1基因为靶标的crispr/cas9载体的构建,步骤如下:通过人工合成方法,合成针对靶基因的sgrna基因,并通过酶切bbs1连入px330-case9(氨苄抗性)质粒中得到靶向切割靶基因的crispr/cas9质粒。
4、抗tnf-α单克隆抗体的cho细胞表达体系的建立,步骤如下:
(1)质粒的大量提取:采用碱裂解法
(2)转染(将同源重组质粒与crispr/cas9质粒共转)
(3)g418方法筛选稳定细胞系
①转染24小时后,以一定稀释比例(根据细胞的生长情况)接种到10cm培养板上,加最佳筛选浓度培养基,每隔一天换一次液。
②培养6天左右细胞大量死亡时,可以增加血清浓度培养,例如原来用10%血清,此时则可以采用20%血清。
③培养10天后将g418浓度减半,维持筛选压力。
④筛选约12-14天左右时可见有抗性克隆出现。
⑤提基因组,进行pcr检测目的基因是否整合到基因组上。提取总rna,rt-pcr检测目的基因是否转录。
⑥验证目的基因已经整合到基因组上并转录后,应用有限稀释法筛选阳性克隆,将单克隆转入96孔板培养,尽量达到1个细胞/孔。
⑦单克隆鉴定:挑出1个细胞/孔的孔,做好标记,后面elisa只检测这些孔中的细胞。细胞大量扩增后,elisa检测目的基因是否表达并确定表达量。
⑧根据elisa测定蛋白表达量的结果,挑选表达量高的几株单克隆转移到六孔板中扩大培养,此时应为筛选培养基。
⑨待细胞汇集度达到80-90%左右时,细胞传代到10cm培养皿中,此时应为筛选培养基,待细胞汇集度达到80-90%左右时冻存。
二、elisa检测抗tnf-α单克隆抗体
(1)包被液溶解可溶性tnf-α抗原,加入50μl/孔的抗原包被混合液,终浓度为1μg/ml,37℃孵育2小时或4℃孵育过夜。
(2)去除板孔中的包被混合液,洗液(pbst)洗板三次,去除板孔中的洗液。
(3)加入200μl/孔封闭液到酶标板孔中,37℃孵育1h,孵育结束后去除板孔中的封闭液,用洗液洗板三次,去除板孔中的洗液。
(4)取细胞上清液,以50μl/孔加到酶标板孔中,设置阴性对照。37℃孵育1.5h。孵育结束后去除板孔中的细胞上清液,用洗液洗板三次,去除板孔中的洗液。
(5)二抗用封闭液稀释到1:5000-1:8000,将稀释到工作浓度的二抗,以50μl/孔加到酶标板孔中,37℃孵育1h。孵育结束后去除板孔中的二抗,用洗液洗板三次,去除板孔中的洗液。
(6)tmb显色,将配制的底物50μl/孔加到板中,37℃孵育,一旦显色立即加1mhcl50μl/孔终止反应。打开酶标仪,调整到od450nm读数,记录相关的数据。
三、抗tnf-α单克隆抗体的纯化与检测
①将抗体分泌细胞培养三天;
②第四天收集细胞培养上清,离心,10000g,5分钟,取上清并用0.45μm的聚醚砜(pes)滤膜过滤;
③将滤液与proteina的上样缓冲液按1:1的比例稀释;
④通过ge公司的aktapurifier10蛋白纯化仪和hitraprproteinaff亲和柱进行抗体纯化;
⑤近上样、漂洗之后进行洗脱,并收集洗脱峰;
⑥将收集到的洗脱液用截留分子尺寸为10kd透析袋于ph8.0的pbs缓冲液进行透析24小时;
⑦透析完成后,用聚乙二醇peg20000进行浓缩处理。
⑧配置一块6%的和一块12%的聚丁烯酰胺凝胶;
⑨制备两份样品,在电泳前,一份用还原剂巯基乙醇处理,一份不用还原剂处理;
⑩将用未还原剂处理的样品加载到6%丙烯酰胺凝胶中,而将用还原剂处理的样品加载到12%的聚丙烯酰胺凝胶中,开始电泳;
sequencelisting
<110>天津科技大学
<120>稳定表达抗tnf-α单克隆抗体细胞表达体系
<130>2017-03-27
<160>9
<170>patentinversion3.3
<210>1
<211>705
<212>dna
<213>本发明抗tnf-α单克隆抗体的轻链(lc)序列
<400>1
atggagaccgacaccctcctgctgtgggtgctgctgctctgggttcctggctccactggc60
gacatcctgctgacccagtctcctgctatcctgtctgtatctcctggcgagagggtgtct120
ttctcttgccgggccagccagttcgtgggctcttctatccattggtaccagcagaggacc180
aacggctctcccaggctcctcatcaaatatgcctccgagtctatgtctggcatcccttct240
cggttcagtggcagtggctctggcaccgacttcaccctctccatcaacaccgtggagtct300
gaggatatcgccgactattactgtcagcagagtcactcttggcctttcaccttcggctcc360
ggcaccaacctggaggtcaagcgaaccgtggctgccccatctgtgttcatcttccctcca420
tctgatgagcagctcaagtctggcactgcctctgtggtgtgcctgctgaataacttctat480
cccagagaggccaaagtacagtggaaggtggataacgccctccagtctggcaactcccag540
gagagtgtgaccgagcaggacagcaaggacagcacctacagcctcagcagcaccctgacc600
ctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccatcagggc660
ctgagctctcccgtgaccaagagcttcaacaggggcgagtgttga705
<210>2
<211>1410
<212>dna
<213>本发明抗tnf-α单克隆抗体的重链(hc)序列
<400>2
atggactggacctggagggtcttctgcttgctggctgtggcaccaggtgcccactccgag60
gtgaagctggaggagtctggcggcggcctggtgcagcctggcggctctatgaagctgtct120
tgcgtggcttccggcttcatcttctctaatcactggatgaactgggtgcgccagtctcct180
gagaagggcctggagtgggtggccgagatccggtctaagtccatcaattccgccacccac240
tatgctgagtccgtgaagggccgcttcaccatctctcgggacgactctaagtctgccgtc300
tacctgcagatgaccgacctgaggaccgaggacaccggcgtgtattactgttccagaaac360
tattatggctctacctatgattactggggccagggcaccaccctcaccgtgtctagcgcc420
tccaccaagggcccatctgtgttccccctggccccctcttccaagtccacttctggcggc480
acagctgccctgggctgcctggtcaaggactacttccccgagcctgtgaccgtgtcttgg540
aactctggcgccctgaccagcggcgtgcacaccttccctgcagtgctccagtcttccggc600
ctgtactccctgtcctctgtggtgaccgtgccctccagcagcctgggcacccagacctac660
atctgcaacgtgaatcacaagcccagcaacaccaaggtggacaagaaggtggagcccaag720
tcttgtgacaagacccacacctgcccaccctgcccagcccctgagctgctgggcggccct780
tctgtgttcctgttccccccaaagcccaaggacaccctgatgatctcccggacccctgag840
gtgacctgcgtggtggtggacgtgagccacgaggaccctgaggtgaagttcaactggtat900
gttgacggagttgaggtgcataatgccaagaccaagcctcgggaggagcagtacaacagc960
acctaccgggtggtgagcgtgctgaccgtgctgcaccaggactggctgaatggcaaggag1020
tacaagtgcaaggtgtccaacaaggccctgccagcccccatcgagaagaccatctccaag1080
gccaagggccagccccgagagccacaggtgtacaccctgcccccatcccgggatgagctg1140
accaagaatcaagtgtccctgacctgcctggtgaagggcttctatcccagcgacatcgcc1200
gtggagtgggagagcaatggccagcctgagaacaactacaagaccacccctcccgtgctg1260
gactccgacggctccttcttcctgtactccaagctgaccgtggacaagagcaggtggcag1320
cagggcaacgtgttctcttgctccgtgatgcatgaggctctgcacaaccactacacccag1380
aagagcctgtccctgtctcccggcaagtga1410
<210>3
<211>576
<212>dna
<213>本发明抗tnf-α单克隆抗体的ires序列
<400>3
cccccccccctaacgttactggccgaagccgcttggaataaggccggtgtgcgtttgtct60
atatgttattttccaccatattgccgtcttttggcaatgtgagggcccggaaacctggcc120
ctgtcttcttgacgagcattcctaggggtctttcccctctcgccaaaggaatgcaaggtc180
tgttgaatgtcgtgaaggaagcagttcctctggaagcttcttgaagacaaacaacgtctg240
tagcgaccctttgcaggcagcggaaccccccacctggcgacaggtgcctctgcggccaaa300
agccacgtgtataagatacacctgcaaaggcggcacaaccccagtgccacgttgtgagtt360
ggatagttgtggaaagagtcaaatggctctcctcaagcgtattcaacaaggggctgaagg420
atgcccagaaggtaccccattgtatgggatctgatctggggcctcggtgcacatgcttta480
catgtgtttagtcgaggttaaaaaaacgtctaggccccccgaaccacggggacgtggttt540
tcctttgaaaaacacgatgataatatggccacaacc576
<210>4
<211>2810
<212>dna
<213>本发明抗tnf-α单克隆抗体重组细胞系扩增后的lc-ires-hc序列
<400>4
taatacgactcactatagggagacccaagctggctagttaagcttccaccatggagaccg60
acaccctcctgctgtgggtgctgctgctctgggttcctggctccactggcgacatcctgc120
tgacccagtctcctgctatcctgtctgtatctcctggcgagagggtgtctttctcttgcc180
gggccagccagttcgtgggctcttctatccattggtaccagcagaggaccaacggctctc240
ccaggctcctcatcaaatatgcctccgagtctatgtctggcatcccttctcggttcagtg300
gcagtggctctggcaccgacttcaccctctccatcaacaccgtggagtctgaggatatcg360
ccgactattactgtcagcagagtcactcttggcctttcaccttcggctccggcaccaacc420
tggaggtcaagcgaaccgtggctgccccatctgtgttcatcttccctccatctgatgagc480
agctcaagtctggcactgcctctgtggtgtgcctgctgaataacttctatcccagagagg540
ccaaagtacagtggaaggtggataacgccctccagtctggcaactcccaggagagtgtga600
ccgagcaggacagcaaggacagcacctacagcctcagcagcaccctgaccctgagcaagg660
ccgactacgagaagcacaaggtgtacgcctgcgaggtgacccatcagggcctgagctctc720
ccgtgaccaagagcttcaacaggggcgagtgttgagaattcgcccctctccctccccccc780
ccctaacgttactggccgaagccgcttggaataaggccggtgtgcgtttgtctatatgtt840
attttccaccatattgccgtcttttggcaatgtgagggcccggaaacctggccctgtctt900
cttgacgagcattcctaggggtctttcccctctcgccaaaggaatgcaaggtctgttgaa960
tgtcgtgaaggaagcagttcctctggaagcttcttgaagacaaacaacgtctgtagcgac1020
cctttgcaggcagcggaaccccccacctggcgacaggtgcctctgcggccaaaagccacg1080
tgtataagatacacctgcaaaggcggcacaaccccagtgccacgttgtgagttggatagt1140
tgtggaaagagtcaaatggctctcctcaagcgtattcaacaaggggctgaaggatgccca1200
gaaggtaccccattgtatgggatctgatctggggcctcggtgcacatgctttacatgtgt1260
ttagtcgaggttaaaaaaacgtctaggccccccgaaccacggggacgtggttttcctttg1320
aaaaacacgatgataatatggccacaaccatggactggacctggagggtcttctgcttgc1380
tggctgtggcaccaggtgcccactccgaggtgaagctggaggagtctggcggcggcctgg1440
tgcagcctggcggctctatgaagctgtcttgcgtggcttccggcttcatcttctctaatc1500
actggatgaactgggtgcgccagtctcctgagaagggcctggagtgggtggccgagatcc1560
ggtctaagtccatcaattccgccacccactatgctgagtccgtgaagggccgcttcacca1620
tctctcgggacgactctaagtctgccgtctacctgcagatgaccgacctgaggaccgagg1680
acaccggcgtgtattactgttccagaaactattatggctctacctatgattactggggcc1740
agggcaccaccctcaccgtgtctagcgcctccaccaagggcccatctgtgttccccctgg1800
ccccctcttccaagtccacttctggcggcacagctgccctgggctgcctggtcaaggact1860
acttccccgagcctgtgaccgtgtcttggaactctggcgccctgaccagcggcgtgcaca1920
ccttccctgcagtgctccagtcttccggcctgtactccctgtcctctgtggtgaccgtgc1980
cctccagcagcctgggcacccagacctacatctgcaacgtgaatcacaagcccagcaaca2040
ccaaggtggacaagaaggtggagcccaagtcttgtgacaagacccacacctgcccaccct2100
gcccagcccctgagctgctgggcggcccttctgtgttcctgttccccccaaagcccaagg2160
acaccctgatgatctcccggacccctgaggtgacctgcgtggtggtggacgtgagccacg2220
aggaccctgaggtgaagttcaactggtatgttgacggagttgaggtgcataatgccaaga2280
ccaagcctcgggaggagcagtacaacagcacctaccgggtggtgagcgtgctgaccgtgc2340
tgcaccaggactggctgaatggcaaggagtacaagtgcaaggtgtccaacaaggccctgc2400
cagcccccatcgagaagaccatctccaaggccaagggccagccccgagagccacaggtgt2460
acaccctgcccccatcccgggatgagctgaccaagaatcaagtgtccctgacctgcctgg2520
tgaagggcttctatcccagcgacatcgccgtggagtgggagagcaatggccagcctgaga2580
acaactacaagaccacccctcccgtgctggactccgacggctccttcttcctgtactcca2640
agctgaccgtggacaagagcaggtggcagcagggcaacgtgttctcttgctccgtgatgc2700
atgaggctctgcacaaccactacacccagaagagcctgtccctgtctcccggcaagtgac2760
tcgagtctagagggcccttcgaacaaaaactcatctcagaagaggatctg2810
<210>5
<211>23
<212>dna
<213>靶基因的sgrna基因序列
<400>5
ccccgagatggacaatttgctcc23
<210>6
<211>50
<212>dna
<213>同源臂1上游
<400>6
gccacctgacgtcgacggatcgggaggacttggggttcgtatcccaggtc50
<210>7
<211>50
<212>dna
<213>同源臂1下游
<400>7
gagagtgcaccataggggatcgggaccccctgggtctcttgttcctgatg50
<210>8
<211>50
<212>dna
<213>同源臂2上游
<400>8
atcaatgtatcttatcatgtctgtagggagggggactggacttatctctg50
<210>9
<211>50
<212>dna
<213>同源臂2下游
<400>9
aagctctagctagaggtcgacggtagggtgtggtttgaaagtgtgaaccc50
- 还没有人留言评论。精彩留言会获得点赞!