一种构建超长连续DNA序列的基因组组装方法与流程
本发明涉及一种构建超长连续dna序列的基因组组装方法,属于基因组组装技术领域。
背景技术
测序仪通过对基因组片段的测序产生了随机的读出序列(read,读序)。这些read在基因组上的分布是随机的。基因组组装的过程就是把这些read按照正确的顺序排列和连接,组装成碱基连续的dna片段(contig),最终复原整条染色体及整个基因组的序列。这个组装的过程一般包括三步:连续片段(contig)的组装,有缺口的非连续片段(scaffold)的组装,缺口的补齐(gf)。基因组组装的困难来源于基因组存在的大量重复序列(即序列相似或一样的两个/段或多个/段序列)。重复序列在基因组中可分为两个大类:串联重复序列和散布重复序列。串联重复是一组头尾直接相连的非常相似的重复单位组成的序列,通过局部重复产生。典型的串联重复序列包括rdna、着丝粒重复序列等。散布重复序列是分布于基因组中不同位置的非局部重复序列。在有些重复序列中,串联重复和非串联重复序列都有,这些区域很长,形成复杂重复序列。测序产生的来源于不同重复序列拷贝的read具有序列上的相似性。目前单分子测序read的长度n50一般大于10-15kb,最长达到了100kb以上。若是一个重复序列加上其两端的单考贝序列一起被一条read全部覆盖,则这个区域不存在组装的问题。而当前需要解决的是超出了read平均或n50长度的重复序列的组装问题。
对于长单分子测序数据现在最常用的基因组组装方法采用了基于overlap-layout-consensus(olc)(myersetal.2000,science287,2196–2204)或stringgraph(sg)(myers2005,bioinformatics21suppl2,ii79-85)的策略。olc方法也可以简洁地用sg来描述,统称为sg类方法。现有的sg类方法常用软件包括pbcr(berlinetal.2015,nat.biotechnol.33,623–30)、canu(korenetal.2017,genomeres.27,722–736)、falcon(chinetal.2016,nat.methods13,1050–1054)、mecat(xiaoetal.2017,nat.methods.doi:10.1038/nmeth.4432)等。sg方法中的关键是利用可传递性简化路径(transitivereduction,tu)的方法来去除多余的read(所有的序列特别相似的read被压缩成一条)。即在构建所有read的重叠图后,利用tu将很多节点的进出边数简化到一条。这样在很多路径上就会没有分支。若是一个read节点在简化后图中的重叠边度数大于1,则称之为交叉节点,其他的节点为内部节点。没有交叉节点的一个通路就可以形成一条contig,在sg中可被进一步压缩到一起。交叉节点代表了单考贝序列区域和重复序列区域的连接之处(这个节点上的read包括了两种类型序列的各一部分);测序仪在测出read序列的时候会犯错误,导致其测出带有测序错误的read序列,这些序列错误包括碱基的插入、缺失、变异,或是来源于不同位置的序列的嵌合体,这些错误也可能导致额外的交叉节点序列。由于测序错误的存在,导致没有一个统一的标准来区分read序列之间的差异到底是由测序错误引起,还是来源于重复序列的不同拷贝而引起的。在这个路径简化的过程中,单考贝区域被简化成一长串read形成的单一路径,连接到一起形成单考贝序列contig;而一段重复序列也可以被压缩成一串read形成的单一路径,形成重复序列contig。由于序列比较时要允许错误,导致来源于不同重复序列拷贝的read会被压缩到一起,也导致不同拷贝的重复序列变成一个,因而不能区分开。但是由于交叉节点的存在,形成的重复序列contig在被压缩的起点和终点位置断开,导致组装出的contig的碎片化,进而导致无法真正复原整个原始基因组序列。
技术实现要素:
本发明的目的在于,提供一种构建超长连续dna序列的基因组组装方法,它可以有效解决现有技术中存在的问题,尤其是现有技术中将相似的多段重复序列压缩成一串read形成的单一路径;由于来源于不同重复序列拷贝的read会被压缩到一起,导致不同拷贝的重复序列变成一个,因而不能区分开;而且由于交叉节点的存在,形成的重复序列contig在被压缩的起点和终点位置断开,导致组装出的contig的碎片化的问题。
为解决上述技术问题,本发明采用如下的技术方案:一种构建超长连续dna序列的基因组组装方法,包括以下步骤:
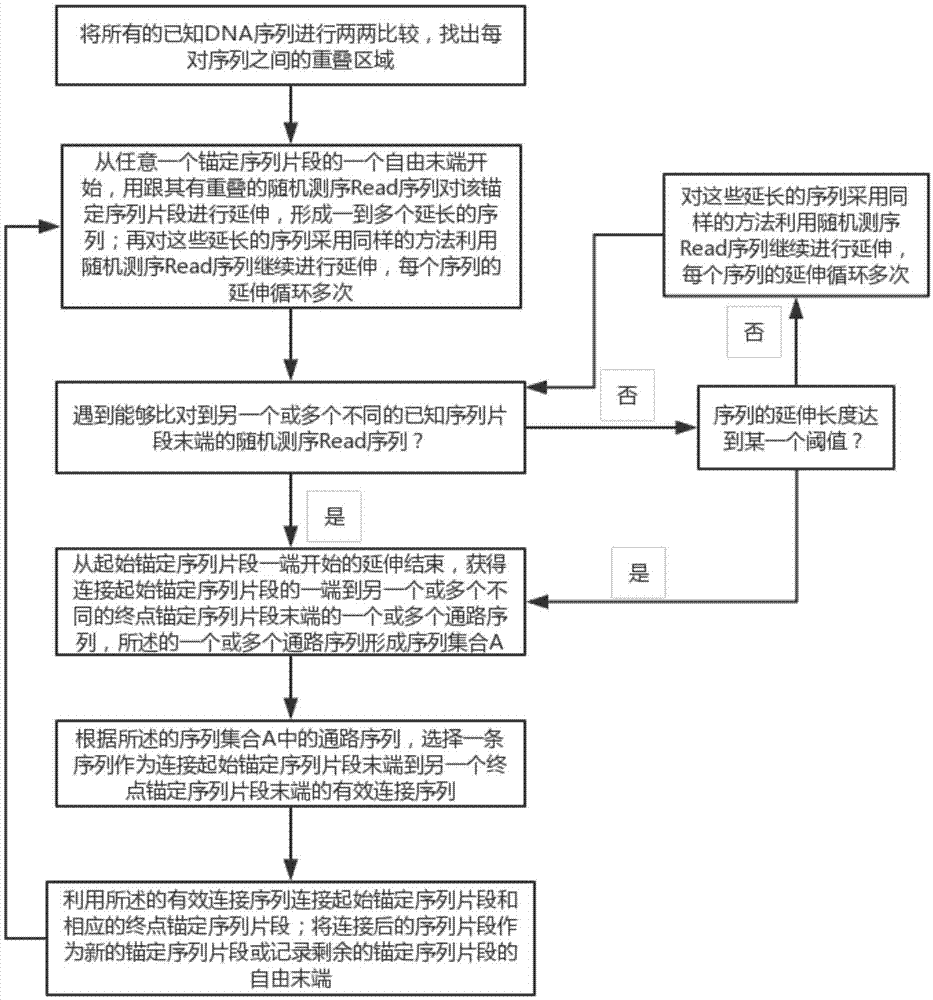
s1,将所有的已知dna序列进行两两比较,找出每对序列之间相似的重叠区域;其中,所述的已知dna序列包括锚定序列片段(即用于锚定的序列片段,可包括多种类型,比如从dna序列上截取的某一段或几段特定的序列片段,和/或已经组装好的某一段或几段特定的序列片段,和/或从随机测序read序列中选出的某一个或几个特定的read序列等)和随机测序read序列;所述的锚定序列片段至少包括两个;所述的将所有的已知dna序列进行两两比较,包括将所有的锚定序列片段与所有的随机测序read序列进行两两比较,以及将所有的随机测序read序列进行两两比较;
s2,从任意一个锚定序列片段的一个自由末端(如es)开始,用跟其有重叠的随机测序read序列对该锚定序列片段进行延伸,形成一到多个延长的序列;再对这些延长的序列采用同样的方法利用随机测序read序列继续进行延伸,每个序列的延伸循环多次,直至遇到能够比对到另一个不同的锚定序列片段末端的随机测序read序列,则从起始锚定序列片段一端开始的延伸结束,获得连接起始锚定序列片段的一端到另一个或多个不同的终点锚定序列片段末端的一个或多个通路序列,所述的一个或多个通路序列形成序列集合a(即序列集合a中的通路序列连接了起始锚定序列片段末端es到其它一或多个不同的终点锚定序列片段末端ee1,…,eek);
s3,根据所述的序列集合a中的通路序列,选择最多一条序列作为连接起始锚定序列片段末端(如es)到另一个终点锚定序列片段末端的有效连接序列(从一个起始锚定序列片段末端开始可以不存在有效连接序列);
s4,利用所述的有效连接序列连接起始锚定序列片段(如末端es)和相应的终点锚定序列片段;将连接后的序列片段作为新的锚定序列片段或记录剩余的锚定序列片段的自由末端,转到s2;不断重复步骤s2-s4,从而最终形成超长连续的dna序列。
本发明中,任意两个锚定序列片段都不完全相同,从而可以尽量避免冲突末端的出现。一个序列有两个末端,每个末端可定义为一段特定长度(比如1-50kb)的序列,那么所述末端对应的一段特定长度(比如1-50kb)的序列即为末端序列。实际操作中,可通过序列比对的方式去除相似的末端序列(比如一致性>98%),序列缩短后产生新的可用的末端。
优选的,步骤s2中,在选择候选延伸序列之前,还包括:设定一个全局序列相似性最低阈值simin;对任一序列x来说,首先判断跟其重叠的序列在重叠区域的序列相似性值是否大于等于所述最低阈值simin,如果是,则选用这些重叠序列来延伸序列x,否则放弃选用这些重叠序列来延伸序列x,从而可以去除噪音干扰,提高数据处理的效率和速度,并提高了结果的准确性。
优选的,所述的全局序列相似性最低阈值simin参考全基因组水平上的测序read序列准确率值α进行设定(比如设定simin=1-(1-α)*3),其中,所述的全基因组水平上的测序read序列准确率值α通过以下方式计算获得:取已知的每条序列的具有最高重叠分数的重叠序列,最多取平均测序深度的条数;计算所有重叠区域的平均序列一致性值,作为全基因组水平上的测序read序列准确率值α;利用估算出的测序精确度值来设定最低重叠的筛选阈值,可以提高此值设定的准确性,减少背景噪音,提高了结果的准确性和运算速度。
前述的构建超长连续dna序列的基因组组装方法中,步骤s2中,对序列末端(一个序列有两个末端,每个末端可定义为一段特定长度(比如1-50kb)的序列)进行延伸时,每一步都选择重叠分数最高的序列;或者延伸分数最高的序列;或者随机选择一个序列;或者为上述任意两种或上述三种方式的结合;其中,随机选择序列时,任意一个序列被选中的概率根据其重叠分数或延伸分数确定(比如所述的概率可以是:这条序列的分数/可以用作延伸的所有序列的分数总和);每一种延伸方式都是贪心算法,若是只有一条通路的情况下,并不能保证就是正确的,所以结合多种延伸方式得到多条通路可以提高找到正确结果的概率。
通过以上方法,从而在对序列进行延伸时,除了第一步外,每一步都只选择一个序列,而非利用所有的序列都去延伸,从而保证可以在有限或较短的时间内延伸出更长的连续的dna序列。而如果每一步都要用所有的序列进行延伸,那么随着延伸次数的增长,总的序列数就会呈指数式增长,最终导致进行对所有序列的延伸变得不具有可行性;第一步的多个read延伸保证最后能产生多条序列,增加了最后结果中包含正确结果的概率。
上述的构建超长连续dna序列的基因组组装方法中,对于末端重叠的两条序列x1和x2(其中一条序列没有被另一条序列完全覆盖),其重叠区域的重叠分数os为:os=(ol1+ol2)*si/2;其中,ol1,ol2分别为序列x1和x2中其重叠区域的长度,si为序列x1和x2之间的重叠区域的序列一致性值;x2对x1的延伸分数es2为:es2=os+el2/2-(oh1+oh2)/2,其中oh1,oh2分别是两条序列末端未配对悬空(overhang)区域的长度,el2是x2对x1的延伸长度(类似,x1对x2的延伸分数也可以用同样的方式计算出来);一般来说,重叠分数越高,则此重叠区域是来源于基因组上同一个位置的可能性越大;序列末端的未配对悬空部分少数是由于测序错误,多数是由于重复序列的不同拷贝造成,因此分数中减去这个值增加了找到正确序列的概率;延伸序列的长度也很重要,在延伸分数中包括了延伸序列的长度可以帮助优先选择长的序列,以便在后续的延伸中找到更长的重叠区域及更高的重叠分数;注意由于dna序列是双链互补的,但在序列比较时,只能用单链,所以序列重叠区域在两条链上都可以产生,通过链的调整,可以把二者统一起来,不会产生冗余或矛盾。
发明人经研究发现,序列之间重叠区域的产生,有两种方式:1、来源于基因组上的同一个位置,这些序列的一致性往往很高,但由于测序错误,导致序列的一致性不是100%;2、来源于重复序列的不同拷贝,但这些序列的一致性往往较低。
优选的,步骤s3包括:
s31,将所述的由起始锚定序列片段末端如es开始的通路序列集合a按照终点锚定序列片段的不同,划分为一或多个通路序列子集合a1,a2,…,ak(其中,子集合a1中所有的通路序列都连接到终点锚定序列片段末端ee1,其它的子集合以此类推),每个子集合中包括一条或多条通路序列;
s32,根据每个通路序列子集合ai中的通路序列获得一条序列作为这个子集合的代表性序列并计算这个子集合的有效通路序列数目,其中,1≤i≤k;
s33,在所有的通路序列子集合的代表性序列中,选择最多一条作为连接起始锚定序列片段末端(如es)到另一个终点锚定序列片段末端的有效连接序列。
通过以上方法,从而可以快速、准确的找出从一个起始锚定序列片段的一个自由末端开始,连接到一个或多个终点锚定序列片段一端的所有通路序列中最正确的那条(在多个连接到起始锚定序列末端的终点锚定序列末端中,只有一个终点序列末端是正确的,其他的终点序列末端都是背景噪音),然后利用正确的那条通路序列连接起始锚定序列片段和相应的终点锚定序列片段,从而提高了基因组组装的准确率;从一个起始锚定序列末端开始,找到的通路序列可以随机连接到一个或多个不同的终点锚定序列末端,由于在基因组上同一个区域产生的read序列相似性及重叠分数最高,而在延伸时,高分数的序列被优先选择,因而导致到达正确终点锚定序列末端的连接通路会最多;不根据末端分组,错误率高,不选有效通路数目最高的,错误率高;有冲突,说明到达两个终点的序列太过相似,一致性值太高,不解决冲突,容易选错。另外,通过上述方法,组装出的序列都是局部完整的片段,提高了组装序列的长度,而现有方法,组装出的多是局部的碎片;而长的序列包含的基因更完整,更容易排列到染色体上,更容易发现片段之间的共线性及结构变异;另外,在不需要输出序列的时候,本发明的这个方法还可以用于判断两个锚定序列之间的相邻关系,或是两个相邻锚定序列之间的距离。
优选的,步骤s32包括:
s321,将每个通路序列子集合ai分成一或多个组ai1,…aig,其中1≤i≤k;
s322,从每个组中选出序列长度的出现频率为最高值及小于最高值一定范围的序列(比如选出序列长度的出现频率最高值到最高值一半的所有序列),形成序列集合bi1,…,big,其中序列集合bi1与ai1对应,其他集合以此类推;
s323,将序列集合bij中的所有序列进行两两比较,若是两条序列之间短的序列被覆盖超过一定比例(比如90%以上),则此两条序列被认为是相似性序列;选出所有能比对到最多条相似性序列的序列;若有多条序列的相似性序列的数目最高且相同,则选择序列长度的出现频率为最高的任意一条序列,作为aij的代表性序列,并记录bij中与此代表性序列相似的序列数目作为序列组aij的有效通路序列数目;其中,1<=j<=g;
s324,将序列子集合ai中的各组按照序列长度从左到右、从短到长进行排列,从具有最高长度频率峰值的一个组开始,跟其右边通路序列更长的第一个组比较,若是左边组中总的有效通路序列数目高出右边组中总的有效通路序列数目一定比例(比如两倍以上),则设左边组的代表性序列为序列子集合ai的代表性序列,寻找序列子集合ai代表性序列的过程停止;否则,暂设右边组的代表性序列为序列子集合ai的代表性序列,然后设此组为左边组,跟其第一个右边组比较,重复上述过程,直到右边组中总的有效通路序列数目低于左边组中总的有效通路序列数目一定比例(比如50%以下)为止;从而确定了序列子集合ai的代表性序列和其所连接的一对相应的锚定序列片段末端(如es和eei)之间的有效通路序列数目(即对应序列组的有效通路序列数目,如npsi)。
本发明中,通过对通路序列子集合进行分组,从而可以在有多个重复单位的情况下,找出正确的通路序列(而不分组不能解决多个重复单位的复杂序列),进而实现了对包含多个重复单位的复杂重复区域的组装。若是一个重复序列内部不存在多个重复单位,则不需要进行分组,在分组时自动会只产生一个组。由于存在多个重复单位,在延伸时,容易形成具有错误重复单位数目的通路,这样,长度频率最高组或其右边的某个组代表了正确的通路集合,这个组中的有效通路数目不能太低(太低了则很可能是背景噪音)。通过本发明的方法选择这个有效通路数目不太低的组,从而提高了找到正确通路的概率。
更优选的,步骤s321中,通过以下方式进行分组:
s3211,将通路序列子集合ai中的通路序列按照从短到长、从左到右(左短右长)的顺序进行排列;
s3212,按照相同的长度差异(如1kb)将通路序列子集合ai中的通路序列划分成多个不重叠的小窗口,并计算每个窗口中包含的序列总数;
s3213,将每个窗口包含的序列总数与其直接相邻的两个窗口对应的序列总数分别进行比较;若比两边的数值都大,则该窗口为一个高峰窗口,若比两边的数值都小,则该窗口为一个谷底窗口;其中,若是一边没有窗口则此边的序列总数设为0;
s3214,计算出所有的高峰窗口和谷底窗口;若是一个谷底窗口中序列长度的出现频率最小值小于其右边最近的一个高峰窗口中序列长度的出现频率最大值的某一特定比例(比如4/5)时,则用此谷底窗口中的出现频率最低的序列长度把两边的通路序列分成两组;以此类推,通路序列子集合ai被分成一或多个组。
分组的关键是根据谷底值将多个峰值分开,若是通路长度的分布很窄,比如最短的通路和最长的通路之间的距离<10kb,则没有必要进行分组,当作一个组处理即可;所以按照窗口法分组时,每个窗口没有必要设定的太小,当然大了也没有必要,1kb即可。
优选的,步骤s33中,通过以下方式来选择最多一条序列作为连接起始锚定序列片段末端(如es)到另一个终点锚定序列片段末端的有效连接序列:
s331,从序列集合a的各个通路序列子集合的代表性序列(一条代表性序列连接起始锚定序列片段末端es到一个不同的终点锚定序列片段末端eei)所对应的有效通路序列数目中,选取有效通路序列数目的最大值与第二大值,计算相应的起始锚定序列片段末端的冲突指数为:cis=npsn/npsm,其中,cis表示相应的起始锚定序列片段末端es的冲突指数,npsm为从起始锚定序列片段末端es连接到其他不同的终点锚定序列片段末端的最大的有效通路序列数目,npsn为从起始锚定序列片段末端es连接到其他不同的终点锚定序列片段末端的第二大的有效通路序列数目;其中,npsm≥npsn;若是冲突指数超出了阈值(比如0.75),则相应的起始锚定序列片段末端被称之为一个冲突末端;
s332,对于不存在冲突的锚定序列片段末端,则在其通路序列集合a的所有子集合的代表性序列中,选择相应的有效通路序列数目的最大值所对应的通路序列子集合的代表性序列作为序列集合a最终的代表性序列,即获得了连接起始锚定序列片段末端(如es)到另一个终点锚定序列片段末端的有效连接序列;对于存在冲突的锚定序列片段末端,若是此冲突能够被解决,则选择由解决方法所决定的末端所对应的代表性序列作为连接起始锚定序列片段末端到另一个终点锚定序列片段的有效连接序列;若是此冲突不能被解决,则没有找到此锚定序列片段末端跟其它任一锚定序列片段连接的有效连接序列,转到步骤s2。
通过以上方法识别锚定序列片段的末端是否为冲突末端及进一步选择最多一条序列作为连接起始锚定序列片段末端(如es)到另一个终点锚定序列片段末端的有效连接序列,从而避免了将冲突末端进行错误的延伸(会导致dna序列嵌合体,即不同区域的序列被连接到了一起),保证形成更长的连续dna序列的同时正确率也更高。
上述的构建超长连续dna序列的基因组组装方法中,步骤s332中,解决冲突的方法包括:根据染色体分组的信息解决位于不同染色体上的锚定序列片段末端的冲突;或根据已知相邻的序列信息,从而解决锚定序列片段末端的冲突;或在构建超长连续dna序列的过程中,将引起某起始锚定序列片段末端冲突的两个终点锚定序列片段末端中的一个已经用于其他锚定序列片段的连接中,则对应的起始锚定序列片段末端的冲突也相应得到解决。这些解决冲突的方法基于的数据均比较容易得到,从而可以快速解决冲突,比如染色体分组数据有hi-c或遗传图谱,相邻信息有bionano基因组光学图谱,或是10xgenomics数据。少数冲突可根据自有的信息来解决。
与现有技术相比,本发明具有以下优点:
(1)本发明通过将所有的已知dna序列进行两两比较,找出每对序列之间相似的重叠区域,然后从任意一个锚定序列片段的一个自由末端(如es)开始,用跟其有重叠的随机测序read序列对该锚定序列片段进行延伸,形成一到多个延长的序列;再对这些延长的序列采用同样的方法利用随机测序read序列继续进行延伸,每个序列的延伸循环多次,直至遇到能够比对到另一个不同的锚定序列片段末端的随机测序read序列,则从起始锚定序列片段一端开始的延伸结束,获得连接起始锚定序列片段的一端到另一个或多个不同的终点锚定序列片段末端的一个或多个通路序列,所述的一个或多个通路序列形成序列集合a;根据所述的序列集合a中的通路序列,选择一条序列作为连接起始锚定序列片段末端到另一个终点锚定序列片段末端的有效连接序列;利用所述的有效连接序列连接起始锚定序列片段和相应的终点锚定序列片段;将连接后的序列片段作为新的锚定序列片段或记录剩余的锚定序列片段的自由末端,不断重复上述步骤,从而最终形成超长连续的dna序列;通过利用本发明的方法构建出超长连续的dna序列,更有利于复原整条染色体及整个基因组的序列;
(2)本发明将随机read序列形成通路序列,然后对所述的通路序列进行处理,从而大大提高了基因组组装的准确率。而现有技术仅仅进行了read水平上的处理,将相似的read序列进行了压缩,使得来源于不同重复区域的read序列被压缩成了一个,这样本来有差别的重复区域不能分开;而且由于种种原因,比如测序错误、校正错误等,read水平上的错误也很容易导致压缩错误;而本发明在通路水平上,虽然也有错误,但通路的序列长度比read序列的长度要长,更容易区分。在通路水平上,即使两个通路序列之间的差别只有1%-2%,也是有可能区分开的,大于2%的则很容易分开,因此本发明相对于现有的sg方法,可以进一步提高基因组组装的准确率;
(3)本发明通过设置序列一致性值或重叠分数或延伸分数,从而根据序列一致性值或重叠分数或延伸分数实现了将基因组中来源于同一个重复序列家庭的不同重复序列拷贝(各个重复序列的相似度大于85%,特别是相似度>98%)的reads尽可能多地分开,将每个重复序列来源的reads组装成一个独立的contig,并跟其两端的锚定序列片段连接起来,最终形成超长连续的dna序列,同时提高了基因组组装的准确率;
(4)通过本发明的方法,还实现了对包含多个重复单位的复杂重复区域的组装;
(5)本发明的基因组组装方法还可以用于基因组序列中空白区域的序列填充(将空白区域两端的序列作为锚定序列片段,通过本发明的方法来获得最终的有效连接序列);
(6)本发明的基因组组装方法,可以实现重复序列区域的基因组组装,也可以实现单拷贝序列区域的组装;
(7)为了验证本发明的效果,发明人还利用本发明的方案对水稻基因组、玉米基因组及人基因组进行了基因组组装试验,具体如下:
首先,发明人用一个高质量水稻基因组(组装基因组大小390.3mb,估算的真实大小不超过394mb)(duetal,2017)进行了测试。采用现有的基于olc的sg类型的组装方法进行组装的结果是:总基因组大小402.5mb;contign50大小1.3mb。而采用本发明的方法组装后,在总基因组大小略有减小(399.2mb)的情况下(基因组变小是因为基于olc的sg类型的组装的结果中有冗余),contign50的大小提高到了13.2mb;利用bionano(序列相邻信息)基因组光学图谱解决冲突的情况下,contign50进一步提高到了14.4mb,整条染色体8序列组装成了一个contig。过滤掉非水稻序列后,整个基因组大小是391.6mb,包含有40个contig,比原来组装出的参考基因组稍大,主要是着丝粒重复序列的增多造成。采用本发明方法组装的8号染色体序列中包含有以前参考基因组中漏掉的一段约387kb的序列(即采用现有的方法进行组装,碎片多,基因组不全,会漏掉了很多重复序列,难以排列到染色体上,不能组装复杂区域,如图10a、图10b和图10c所示)。在对已知的14个潜在的复杂重复序列区域进行的不完全测试中,本发明可以很容易地组装其中的7个(如图8e、图10b、图10c、图10e、图10f、图10g、和图10h所示)。水稻基因组中本发明方法组装的区域利用其它的二代测序短序列进行质量检测,发现97.21%的短序列能够比对到基因组上,且本发明组装的99.56%的序列能够被二代短序列覆盖,说明本发明组装的序列都是对的。
其次,如图11b所示,已发表的玉米的参考基因组b73refgen_v4(jiaoetal,2017)是用pbcr(基于olc的sg类)软件进行组装的,其包含有大量(总长90.55mb)的小contig序列没有锚定到染色体上,而染色体上的空白序列有约43mb。对于同样的数据,采用本发明的方法进行基因组组装后,contign50大小从1.3mb增加到61.2mb,最长的contig从7mb增加到140mb。定位到染色体上的长度从2075.6mb增加到2104.2mb(说明本发明的组装准确率更高),空白区域的总数从2,523个下降到76个,不能锚定到染色体上的序列只剩下2.8mb。除了组装空白序列之外,经过bionano基因组光学图谱验证发现,如图11c和图11d,本发明的组装结果中也校正了refgen_v4中的多处错误,包括两个序列方向错误和两个位置错误(现有的方法因为序列短,无法发现这样的错误,但是采用本发明的方法进行组装,序列变长后,以前的序列因为太短而造成的错误就消失了)。
再次,人的一个基因组hx1(shietal,2016)是用falcon(sg软件)组装的(hx1_falcon),经本发明的方法改进后,contign50从8.3mb增加到54.4mb。最长的contig从38mb增加到109.8mb。经比较发现,如图12f所示,在人的参考基因组grch38中,有多个空白区域在hx1_falcon中没有组装出来,但在本发明的组装结果中已得到填充;另外,由图12c和图12e所示,人的参考基因组本身是有缺口的,但是利用本发明的方法进行组装后,对所述缺口进行了填充;此外,由图12d可知,falcon组装的片段是一个嵌合体;而本发明的组装方法则构建出了正确的序列。
通过以上试验说明了:(1)本发明的基因组组装方法可以构建更长的连续dna序列;(2)本发明可以用于对基因组序列中的空白区域进行序列填充;(3)本发明的方法可以组装复杂重复序列区域;(4)本发明的基因组组装方法组装的基因组准确率较高。
附图说明
图1是本发明的一种实施例的方法流程图;
图2是获取通路序列子集合的代表性序列及这个子集合的有效通路序列数目的方法流程图;
图3是通路序列子集合的分组方法示意图;
图4是选择连接起始锚定序列片段末端(如es)到另一个终点锚定序列片段末端的有效连接序列的方法示意图;
图5是来源于不同区域的重复序列拷贝的示意图;基因组上的两个相似的重复序列片段r1、r2,跟其比对的上半部分序列是本地产生的测序read序列,序列一致性很高,而跟其比对的下半部分序列是另一个重复序列拷贝来源的测序read序列,带有未配对悬空末端和碱基变异;
图6是是重叠的序列及图5对应的重叠图示意图;a,两个重叠的序列,ol,重叠的序列部分;oh,末端未配对悬空的序列部分;el,延伸的序列部分;b,由重叠的序列组成的一条通路;c,图5中重叠序列的连接示意图(重叠图);c1-c4是锚定序列片段;r1、r2是重复序列;每个序列有两个末端;u,单考贝序列,ur,单考贝和重复区域的边界序列;
图7是从多个通路序列中选择一条有效性序列及解决冲突的示意图和举例;c,一个起始锚定序列片段末端到多个终点锚定序列片段末端的连接通路序列示意图;d,显示了不同锚定序列片段末端的有效通路序列数目;e,显示了有冲突的末端;f,显示了e中序列之间的关系;g,利用序列之间的相邻关系(bionano光学图谱)解决e中的冲突;
图8为含有多个重复单位的复杂重复序列区域举例;a-b,bionano基因组光学图谱显示此区域含有两个重复单位,在每对比较的横柱中,下面的横柱是光学图谱,上面的横柱是参考基因组,二者的比较显示了在参考基因组上漏掉了一段序列;c-d,通路序列长度频率分布图,分别对应了a/b中的两个序列;e,显示了b/d中的序列结构,cns1,cns2是两条不同长度的代表性序列,其中两端的线段代表了锚定序列,中间的方框和三角代表了组装出的序列;
图9是针对同一重复序列家庭中的两个重复序列,采用背景技术和本发明两种不同的方法进行处理的结果示意图;
图10是水稻基因组组装结果举例;a-c,表示采用现有方法和本发明方法分别进行水稻基因组组装的结果对比示意图;在每对比较的横柱中,下面的横柱是bionano光学图谱,上面的横柱是参考基因组;上部的一对代表了采用现有方法组装的结果示意图,下部的一对代表了采用本发明方法组装的结果示意图;e/f/g/h,分别表示多个复杂重复序列区域的通路序列长度频率分布图;
图11是玉米基因组组装举例;b-d,在每对比较的横柱中,下面的横柱是bionano光学图谱,上面的横柱是参考基因组,上部显示了采用已有软件pbcr(基于sg方法)对玉米基因组进行组装的结果,下部显示了同一区域采用本发明方法的组装结果;b,pbcr结果中漏掉(中间缺失竖线条的区域)或多出了序列;c,pbcr序列的方向错误在本发明的组装结果中得到改正;d,pbcr序列中的位置错误在本发明的组装结果中得到改正;
图12是人的基因组组装结果举例;c/e,上部横条代表了人的参考基因组(有缺口),下部横条代表了本发明的方法进行组装的结果(没有缺口);d,falcon中是一个嵌合体,本发明组装的结果中不包含嵌合体;f,falcon结果中有多个空白区域没有组装出来,但在本发明(即heracontig629)的组装结果中已得到填充。
下面结合附图和具体实施方式对本发明作进一步的说明。
具体实施方式
本发明的实施例:一种构建超长连续dna序列的基因组组装方法,如图1所示,包括以下步骤:
s1,将所有的已知dna序列进行两两比较,找出每对序列之间相似的重叠区域;其中,所述的已知dna序列包括锚定序列片段(即用于锚定的序列片段,比如从dna序列上截取的某一段或几段特定的序列片段,和/或已经组装好的某一段或几段特定的序列片段,和/或从随机测序read序列中选出的某一个或几个特定的read序列等)和随机测序read序列(为了提高read序列的准确率,可以先对该read序列进行校正,也可以不进行校正,直接采用原始的随机测序read序列;校正的方法包括用其他测序平台得到的测序错误率很低的测序read序列来校正,也包括利用这个集合中的其他的read序列来校正;为了提高基因组组装的效率,这里的随机测序read序列可以部分用组装好的短的contig序列(而组装好的长的contig序列则作为锚定序列片段,所述的长短比如可以以50kb为界进行划分)来替代);所述的锚定序列片段至少包括两个;所述的将所有的已知dna序列进行两两比较,包括将所有的锚定序列片段与所有的随机测序read序列进行两两比较,以及将所有的随机测序read序列进行两两比较;具体实施时,可以构建一个重叠图,是由代表已知序列的节点和他们两两之间的序列重叠作为边构建的无向简单图。每条已知序列用两个节点来表示,每个节点代表了一个序列片段末端,而这两个节点之间由一条无向边(在此称之为耦合边)连接;在这个重叠图中,若是两个节点之间有非耦合边的连接,则说明此两个末端之间有重叠,其中的一个可以用来延伸另一个;在遍历图中的通路时,有一个基本要求:在任何时候,进入了一个节点,则必须通过这个节点的耦合边出来(即到达一条已知序列的一个末端节点以后,不能从连接到同一末端节点的其他序列的末端节点出来,而必须从同一序列的另一个末端节点出来,以保证序列的线性延伸);在这个图中,识别两个不同锚定序列的两个末端之间是不是有连接可以通过深度搜索或广度搜索来实现;
s2,从任意一个锚定序列片段的一个自由末端(如es)节点开始,用跟其有重叠的随机测序read序列节点对该锚定序列片段进行通路延伸,形成一到多个延长的通路序列;再对这些延长的通路序列采用同样的方法利用随机测序read序列继续进行延伸,每个序列的延伸循环多次,直至遇到能够连接到另一个不同的锚定序列片段末端节点的随机测序read序列末端节点,则从起始锚定序列片段一端开始的延伸结束,获得连接起始锚定序列片段的一端到另一个或多个不同的终点锚定序列片段末端的一个或多个通路序列(如图7c的例子所示),所述的一个或多个通路序列形成序列集合a(即序列集合a中的通路序列连接了起始锚定序列片段末端es到其它一或多个不同的终点锚定序列片段末端ee1,…,eek);
s3,根据所述的序列集合a中的通路序列,选择最多一条序列作为连接起始锚定序列片段末端(如es)到另一个终点锚定序列片段末端的有效连接序列(从一个起始锚定序列片段末端开始可以不存在有效连接序列);
s4,利用所述的有效连接序列连接起始锚定序列片段(如末端es)和相应的终点锚定序列片段;将连接后的序列片段作为新的锚定序列片段或记录剩余的锚定序列片段的自由末端,转到s2;不断重复步骤s2-s4,从而最终形成超长连续的dna序列。
对于上述的锚定序列片段,所述的从随机测序read序列中选出的某一个或几个特定的read序列,可通过以下方法之一进行筛选:
1)将所有的随机测序read序列进行两两比较,若是某一个read序列跟其他多个read序列(比如平均测序深度的1/3以上)有重叠,但没有末端未配对悬空序列,另外也跟多个其他read序列有重叠(比如平均测序深度的1/3以上),但在此序列的同一端有末端未配对悬空序列,说明这个序列是一个位于单考贝和重复序列边界上的序列。把能够比对到此边界序列的单考贝端的所有read序列去重,保留一条单考贝端所有重叠区域的平均重叠分数最高的read序列,作为锚定序列片段。
2)根据每个read序列的末端重叠的read序列数目,把高于平均深度的序列作为重复序列,把低于或等于平均深度的序列作为单考贝序列;取一条其所有重叠区域平均重叠分数最高的单考贝序列,向两边延伸,直到遇到一个标记为重复序列的read序列停止。将此延伸后的序列离末端最近的两个单考贝read序列作为锚定序列片段。
3)将比对到参考基因组上任意一个区域的read序列作为锚定序列片段。
为了提高基因组组装的效率和准确度,步骤s2中,在选择候选延伸序列之前,还可包括:设定一个全局序列相似性最低阈值simin;对任一序列x来说,首先判断跟其重叠的序列在重叠区域的序列相似性值是否大于等于所述最低阈值simin,如果是,则选用这些重叠序列来延伸序列x,否则放弃选用这些重叠序列来延伸序列x。
所述的全局序列相似性最低阈值simin可参考全基因组水平上的测序read序列准确率值α进行设定(比如设定simin=1-(1-α)*3),其中,所述的全基因组水平上的测序read序列准确率值α通过以下方式计算获得:取已知的每条序列的具有最高重叠分数的重叠序列,最多取平均测序深度的条数;计算所有重叠区域的平均序列一致性值,作为全基因组水平上的测序read序列准确率值α。
具体实施时,所述的全局序列相似性最低阈值simin也可凭经验设定或是随意设定。比如,采用校正后的随机read序列作为延伸序列,采用组装好的contig作为锚定序列。因此在实施时,可采用一个固定的simin值97%,效果已足够好。因为一般校正后的随机测序read序列的准确率在99%左右。
为了可以延伸出更长的连续的dna序列,步骤s2中,对序列末端(一个序列有两个末端,每个末端可定义为一段特定长度(比如1-50kb)的序列)进行延伸时,每一步都可选择重叠分数最高的序列;或者延伸分数最高的序列;或者随机选择一个序列;或者为上述任意两种或上述三种方式的结合;其中,随机选择序列时,任意一个序列被选中的概率根据其重叠分数或延伸分数确定(比如所述的概率可以是:这条序列的分数/可以用作延伸的所有序列的分数总和)。
对于末端重叠的两条序列x1和x2(其中一条序列没有被另一条序列完全覆盖),其重叠区域的重叠分数os为:os=(ol1+ol2)*si/2;其中,ol1,ol2分别为序列x1和x2中其重叠区域的长度,si为序列x1和x2之间的重叠区域的序列一致性值(sequenceidentity);序列一致性值的计算一般包括错配和插入及缺失的碱基,但若是没有经过校正的原始read序列,计算此值时,可以是:错配的碱基数目/(配对的碱基数目+错配的碱基数目);x2对x1的延伸分数es2为:es2=os+el2/2-(oh1+oh2)/2,其中oh1,oh2分别是两条序列末端未配对悬空(overhang)区域的长度,el2是x2对x1的延伸长度(类似,x1对x2的延伸分数也可以用同样的方式计算出来)。
具体实施时,对于延伸分数的定义,也可以只考虑延伸长度,但效果不一定好。
步骤s3包括:
s31,将所述的序列集合a按照终点锚定序列片段的不同,划分为一或多个通路序列子集合a1,a2,…,ak(其中,子集合a1中所有的通路序列都连接到起始锚定序列片段末端如es和终点锚定序列片段末端如ee1,其它的子集合以此类推),每个子集合中包括一条或多条通路序列;
s32,根据每个通路序列子集合ai中的通路序列获得一条序列作为这个子集合的代表性序列并计算这个子集合的有效通路序列数目,其中,1≤i≤k;
s33,在所有的通路序列子集合的代表性序列中,选择最多一条作为连接起始锚定序列片段末端(如es)到另一个终点锚定序列片段末端的有效连接序列。
具体实施时,还可以:将所述的序列集合a按照终点锚定序列片段的不同,划分为一或多个通路序列子集合a1,a2,…,ak(其中,子集合a1中所有的通路序列都连接到起始锚定序列片段末端如es和终点锚定序列片段末端如ee1,其它的子集合以此类推),每个子集合中包括一条或多条通路序列;然后直接选取最大子集合中长度出现频率最高的任意一条通路序列作为连接起始锚定序列片段末端(如es)到相应终点锚定序列片段末端的有效连接序列;如果最大的子集合有多个时,则随机选一个最大的子集合。
在所有的有连接通路的锚定序列末端对之间的有效通路序列数目都确定了后,可以用所有的锚定序列末端作为节点,用节点之间的代表性序列作为边,构建一个无向连接图,用有效通路数作为边的长度。
步骤s32可包括(如图2所示):
s321,将每个通路序列子集合ai分成一或多个组ai1,…aig,其中1≤i≤k;
s322,从每个组中选出序列长度的出现频率为最高值及小于最高值一定范围的序列(比如选出序列长度的出现频率最高值到最高值一半的所有序列),形成序列集合bi1,…,big,其中序列集合bi1与ai1对应,其他集合以此类推;
s323,将序列集合bij中的所有序列进行两两比较,若是两条序列之间短的序列被覆盖超过一定比例(比如90%以上),则此两条序列被认为是相似性序列;选出所有能比对到最多条相似性序列的序列;若有多条序列的相似性序列的数目最高且相同,则选择序列长度的出现频率为最高的任意一条序列,作为aij的代表性序列,并记录bij中与此代表性序列相似的序列数目作为序列组aij的有效通路序列数目;其中,1<=j<=g;
s324,将序列子集合ai中的各组按照序列长度从左到右、从短到长进行排列,从具有最高长度频率峰值的一个组开始,跟其右边通路序列更长的第一个组比较,若是左边组中总的有效通路序列数目高出右边组中总的有效通路序列数目一定比例(比如两倍以上),则设左边组的代表性序列为序列子集合ai的代表性序列,寻找序列子集合ai代表性序列的过程停止;否则,暂设右边组的代表性序列为序列子集合ai的代表性序列,然后设此组为左边组,跟其第一个右边组比较,重复上述过程,直到右边组中总的有效通路序列数目低于左边组中总的有效通路序列数目一定比例(比如50%以下)为止;从而确定了序列子集合ai的代表性序列和其所连接的一对相应的锚定序列片段末端(如es和eei)之间的有效通路序列数目(即对应序列组的有效通路序列数目,如npsi,如图7d的举例所示)
在具体实施时,也可以不分组,选择长度出现频率最高的任意一条,或是长度的出现频率最高且跟别的序列的相似性最高的任意一条作为序列子集合的代表性序列;有效通路序列数可以直接选所有的通路,不看相似性。
本发明中,可以通过以下方式进行分组(如图3所示):
s3211,将通路序列子集合ai中的通路序列按照从短到长、从左到右(左短右长)的顺序进行排列;
s3212,按照相同的长度差异(如1kb)将通路序列子集合ai中的通路序列划分成多个不重叠的小窗口,并计算每个窗口中包含的序列总数;
s3213,将每个窗口包含的序列总数与其直接相邻的两个窗口对应的序列总数分别进行比较;若比两边的数值都大,则该窗口为一个高峰窗口,若比两边的数值都小,则该窗口为一个谷底窗口;其中,若是一边没有窗口则此边的序列总数设为0;
s3214,计算出所有的高峰窗口和谷底窗口;若是一个谷底窗口中序列长度的出现频率最小值小于其右边最近的一个高峰窗口中序列长度的出现频率最大值的某一特定比例(比如4/5)时,则用此谷底窗口中的出现频率最低的序列长度把两边的通路序列分成两组;以此类推,通路序列子集合ai被分成一或多个组。
分组的关键是根据谷底值将多个峰值分开,若是通路长度的分布很窄,比如最短的通路和最长的通路之间的距离<10kb,则没有必要进行分组,当作一个组处理即可;所以按照窗口法分组时,每个窗口没有必要设定的太小,当然大了也没有必要,1kb即可。谷底窗口中长度频率最小值和高峰窗口中长度频率最高值的比例很重要,若是分组太多,会造成背景干扰,若是分组太少,会导致找不到正确的通路。
步骤s33中,通过以下方式来选择最多一条序列作为连接起始锚定序列片段末端(如es)到另一个终点锚定序列片段末端的有效连接序列(如图4所示):
s331,从序列集合a的各个通路序列子集合的代表性序列(一条代表性序列连接起始锚定序列片段末端es到一个不同的终点锚定序列片段末端eei)所对应的有效通路序列数目中,选取有效通路序列数目的最大值与第二大值,计算相应的起始锚定序列片段末端的冲突指数为:cis=npsn/npsm,其中,cis表示相应的起始锚定序列片段末端es的冲突指数,npsm为从起始锚定序列片段末端es连接到其他不同的终点锚定序列片段末端的最大的有效通路序列数目,npsn为从起始锚定序列片段末端es连接到其他不同的终点锚定序列片段末端的第二大的有效通路序列数目;其中,npsm≥npsn;若是冲突指数超出了阈值(比如0.75),则相应的起始锚定序列片段末端被称之为一个冲突末端(如图7e的例子所示的冲突末端,图7f显示了图7e中序列之间的关系);
s332,对于不存在冲突的锚定序列片段末端,则在其通路序列集合a的所有子集合的代表性序列中,选择相应的有效通路序列数目的最大值所对应的通路序列子集合的代表性序列作为序列集合a最终的代表性序列,即获得了连接起始锚定序列片段末端(如es)到另一个终点锚定序列片段末端的有效连接序列;对于存在冲突的锚定序列片段末端,若是此冲突能够被解决,则选择由解决方法所决定的末端所对应的代表性序列作为连接起始锚定序列片段末端到另一个终点锚定序列片段的有效连接序列(如图7g即利用序列之间的相邻关系解决如图7e中序列末端的冲突);若是此冲突不能被解决,则没有找到此锚定序列片段末端跟其它任一锚定序列片段连接的有效连接序列,转到步骤s2。
具体实施时,也可以不计算冲突值,总是选取具有最高有效通路数目的代表性序列进行连接,若是有两个最高有效通路数目一样的,则随机连接一个代表性序列。这样会造成一些嵌合体,但也有很多正确的序列。
在具体实施时,可以利用连接图进行判断,若是一个起始锚定序列末端连接到多个不同终点锚定序列的末端,其中最长的两条边长度(有效通路数)相似,则说明这个起始锚定序列末端通过相似的重复序列连接到了两个其他的终点起始锚定序列末端;非冲突的末端可以按照通路数目的多少从大到小连接起来;而冲突末端不用于连接到其他末端,直到这个冲突能够得到解决。
步骤s332中,解决冲突的方法包括:根据染色体分组的信息解决位于不同染色体上的锚定序列片段末端的冲突;或根据已知相邻的序列信息,从而解决锚定序列片段末端的冲突;或在构建超长连续dna序列的过程中,将引起某起始锚定序列片段末端冲突的两个终点锚定序列片段末端中的一个已经用于其他锚定序列片段的连接中,则对应的起始锚定序列片段末端的冲突也相应得到解决。
本发明通过对通路序列子集合进行分组,从而可以在有多个重复单位的情况下,找出正确的通路序列(而不分组不能解决多个重复单位的复杂序列),进而实现了对包含多个重复单位的复杂重复区域的组装。如图8所示,为含有多个重复单位的复杂重复序列区域举例;由图8a、图8b可知,基因组光学图谱显示此区域含有两个重复单位,而参考基因组序列中只含有一个重复单位;图8c和图8d,分别为采用本发明的上述方法获得的对应的通路序列长度频率分布图,分别对应了图8a和图8b中的两个序列;图8e中显示了对于图8b/图8d中的序列结构,采用本发明的方法所获得的cns1,cns2两条不同长度的代表性序列,其中的线段代表了锚定序列,中间的方框和三角代表了组装出的序列,说明了本发明可以实现对包含多个重复单位的复杂序列进行组装,而现有的方法组装出的序列不完整,会漏掉一些。
本发明的一种实施例的工作原理:
如图5(基因组上的两个重复序列片段r1、r2序列一致性很高,但还是有些碱基差异导致他们不完全一致;上半部分比对的序列是本地产生的测序read序列,跟所比较的序列之间的差异很小;下半部分比对的序列带有未配对悬空末端,是不同的重复序列拷贝来源的测序read序列,跟所比较的序列之间差异较大)、图6(一个重叠图(部分)举例,对应了图5中的序列区域及测序read;c1-c4是锚定序列片段;r1、r2是重复序列;每个序列有两个末端;u:单考贝序列,ur,单考贝和重复区域的边界序列)所示,来源于不同区域的重复序列拷贝(所述的重复序列拷贝为相似的序列,属于同一个重复序列家庭)是有差别的。本发明可以实现将来源于上述有差异的重复序列拷贝的read序列分别进行组装,形成单独的contig序列,然后再与两端的锚定序列片段进行连接,最终形成一个超长连续的dna序列。
本发明的基因组组装方法和现有的sg组装方法之间最关键的区别是本发明把一个重复序列区域完整地来处理,而sg方法是把重复区域进行了read水平上的处理,相似的read进行了压缩,不同的重复区域被压成了一个,这样本来有差别的重复区域不能分开。因为种种原因,比如测序错误,校正错误,等等,read水平上的错误很容易导致压缩错误,而在通路水平上,虽然也有错误,但通路的代表性序列比read要长,更容易区分。在通路水平上,即使两个通路之间序列差别只有1%-2%,也是有可能区分开的,大于2%的则很容易分开。read之间的重叠已包含了可能的序列上的差异。在延伸时,不同重复拷贝来源的read不容易连接到一起。反过来说,若是在阈值之上,他们还连接到了一起,则说明这些read无法区分,这两个区域就会产生冲突。若是只是部分重复区域相似,也会造成冲突,但可以通过解决冲突的方法来解决。
若是两个重复序列(或是长于read长度的某个区域)之间的相似度非常高,比如>99%,从两个地区产生的read之间很难区分,这样就会导致连接一对contig的path会混杂不同来源的reads。然而,若是在相似度低的重复序列之间,比如<97%,来源于同一地区的read之间序列相似度高,重叠分数就高,而不同来源的read之间相似度低,重叠分数就低,这样不同重复拷贝之间形成的通路就可以区分开来。若是限定了每个重叠的最低序列一致性,比如97%,则在寻找通路时,低于这个值的重叠会被滤掉,这样形成的通路就会只包括正确的通路,不会形成其他重复拷贝形成的通路。举例来说,对于长read来说,read之间的重叠可以设定一个最低值,比如1kb。若是两个重复拷贝之间的序列相似性<=99%,且序列上的差异是均匀分布的,这样在1kb的重叠区域内若是不同拷贝之间的read就会有至少10个单核苷酸多态性位点(snp),而同一拷贝之间的read就会没有snp。这些read是很容易区分的。在实践中,由于序列之间的差异不是完全均匀分布的,或是由于测序错误没有得到全部校正,会导致误差,但总的来说,绝大多数<99%的重复序列拷贝是很容易区分的。目前单分子测序产生的原始read的平均错误率在10%-15%。通过自我校正后的read平均错误率大大降低,比如很多read的错误率能降低到1%以下。对于绝大多数基因组上相似度小于95%的重复序列来说,其产生的read在校正后相似度都不会高于95%(少数情况下由于校正错误,会产生更相似的序列),因而在序列比对及组装的过程中都很容易区分,因此利用现有软件进行组装时基本上不会造成问题。本发明需要处理的主要是这些相似度大于95%的序列。对所有的跟某个congtig(ni)有连接的所有contig来说,只有一个contig(nj)是其相邻的。本发明的目的就是通过比较ni到nj的通路数量及质量来判断ni跟哪个nj是相邻的。若是只比较一条通路,较易受到偶然因素的影响。
在连接两个contig的通路序列中,并不是所有的序列都是一致的,因此,本发明需要找到一条代表性序列来代表这些通路,并作为连接两个contig的潜在序列。代表性序列也可以是这些通路中取长度为最高出现频率中的一条作为参考序列,把其他所有的序列比对上,然后计算这些序列的共识序列。若是两个contig之间存在一条共识序列,则若是比对到这条共识序列的通路序列占总数的50%以上,则确认这两个contig之间存有有效共识序列,其连接数为比上通路序列的数目。若是不到50%,则认为这两个contig之间的重复序列太复杂,其连接数可设为0。含有多个重复单位的重复区域,因为在延伸时可以跨过或是重复某个重复单位,导致代表性序列变短或变长,呈现有规律的多个长度频率峰值分布。
如图9所示,其中图9(a)中所示的2条序列表示:在原始基因组序列中,序列a通过某重复序列的一个拷贝与d序列连接,c序列通过该重复序列的另一个拷贝(即与上述重复序列属于同一个重复序列家庭)与序列b连接。采用现有的sg方法进行组装时,图9(a)中所示的重复序列的两个拷贝(也可以说是两条相似的序列)被压缩成了一条,如图9(b)所示;注意在压缩的过程中,由于两条原始的序列之间是有差异的,压缩成一条后,很可能会跟两条都不一样,造成组装出的序列错误;根据图9(b),根本无法确定序列a通过重复序列应该与d序列连接还是应该与b序列连接,也无法确定序列c通过重复序列应该与b序列进行连接还是应该与d序列进行连接,也就是说,由于交叉节点的存在,形成的重复序列组装后的contig在被压缩的起点和终点位置附近断开,导致组装出的contig的碎片化,无法真正复原整个原始基因组序列。而采用本发明后,如图9(c)所示,本发明将相似的重复序列分别组装成两条不同的contig序列,通过本发明的方法寻找从某一序列的末端出发到所有未知序列末端的所有通路序列的代表性序列,然后再从这些代表性序列中找出从该末端出发连接最正确的一条通路,也即,通过本发明的方法可以正确的判断出序列a通过重复序列(即本发明中所需寻找的最终的有效连接序列)与序列d连接,序列c通过该重复序列的相似序列(也是本发明中所需寻找的最终的有效连接序列)与序列b连接,从而可以正确还原整个原始基因组序列,而且利用本发明的方法,可以将大部分的重复序列或其相似重复序列都组装起来,最终形成超长连续的dna序列。
采用本发明的方法同样可以组装单拷贝区域,因为在组装前,并不知道该序列是来源于重复序列还是单拷贝序列。
- 还没有人留言评论。精彩留言会获得点赞!