GLP-1类似物-Fc融合蛋白及其制备方法和用途与流程
本发明属于生物技术领域,具体涉及一种glp-1类似物-fc融合蛋白及其制备方法和用途。
背景技术:
人们对胰高血糖素样肽-1(glp-1)的细胞水平进行了研究,结果发现在葡萄糖水平较低时,glp-1与受体结合仅引起钙离子的少量内流与胰岛素分泌,而当葡萄糖水平较高时,atp/adp比例升高,则atp依赖的钙离子通道开放时间延长,因此可引起大量钙离子内流与胰岛素分泌,由此引起的生理作用如下:
1、增加葡萄糖依赖性的胰岛素分泌;
2、抑制胰高血糖素分泌,增加葡萄糖清除;
3、延缓胃排空和诱发饱腹感、抑制食欲;
4、还可以改善外周胰岛素抵抗。
但在研究中,人们还发现天然glp-1存在局限性,即它的半衰期特别短,分泌2-3分钟后就会被二肽基肽酶(dpp-iv)降解,即使外源性给予glp-1,也同样很快会被dpp-vi降解。
因此生产一种生理作用与glp-1类似但不能很快被降解的物质即glp-1类似物成为急需解决的技术问题。
技术实现要素:
为了克服现有技术中所存在的问题,本发明的目的在于提供一种glp-1类似物-fc融合蛋白,及其制备方法和用途。
为了实现上述目的以及其他相关目的,本发明采用如下技术方案:
本发明的第一方面,提供一种glp-1类似物-fc融合蛋白,其结构包括:glp-1类似物和抗体fc片段。
所述glp-1类似物的氨基酸序列如seqidno.1所示,或者与seqidno.1所示序列具有80%以上的同源性,更优选地,具有90%以上的同源性,进一步优选为具有97%以上的同源性。
如seqidno.1所示的序列,具体为:hisglygluglythrphethrseraspvalsersertyrleuglugluglnalaalalysglupheilealatrpleuvallysglyglygly。
优选地,所述抗体fc片段为本领域的不具adcc效应子功能的非裂解性fc。
优选地,所述抗体fc片段的氨基酸序列如seqidno.3~8之任一所示。
优选地,所述glp-1类似物和抗体fc片段可直接连接或通过连接肽连接。
当所述glp-1类似物和抗体fc片段直接连接时,所述glp-1类似物的c端与抗体fc片段的n端以肽键相连。
当所述glp-1类似物和抗体fc片段通过连接肽连接时,所述连接肽的n端与所述glp-1类似物c末端以肽键相连,所述连接肽的c端与抗体fc片段的n端以肽键相连。
优选地,所述连接肽氨基酸数量为≥2个。所述连接肽以g4s为单位的多单位连接实现。
优选地,所述连接肽的氨基酸序列如seqidno.2所示,具体为:glyglyglyglyserglyglyglyglyser。
在本案的较佳案例中,所述glp-1类似物-fc融合蛋白的序列如seqidno.9~14之任一所示。
本发明的第二方面,提供一种多核苷酸,其编码所述glp-1类似物-fc融合蛋白。
本发明的第三方面,提供一种表达载体,其含有前述多核苷酸。
本发明的第四方面,提供一种宿主细胞,其被前述表达载体所转化。
本发明的第五方面,提供一种制备前述glp-1类似物-fc融合蛋白的方法,包括:构建含有glp-1类似物-fc融合蛋白基因序列的表达载体,然后将含glp-1类似物-fc融合蛋白基因序列的表达载体转化至宿主细胞中诱导表达,从表达产物中分离获得所述的glp-1类似物-fc融合蛋白。
本发明的较佳案例中,所述表达载体采用pcdna3.1。所述宿主细胞采用cho-s细胞。
本发明的第六方面,提供前述glp-1类似物-fc融合蛋白用于制备糖尿病及相关疾病治疗药物的用途。
本发明的第七方面,提供一种药物组合物,含有前述glp-1类似物-fc融合蛋白及至少一种药学可接受的载体或赋形剂。
本发明的第八方面,公开了一种治疗糖尿病及其相关疾病的方法,为向对象施用本发明的glp-1类似物-fc融合蛋白。
与现有技术相比,本发明具有如下有益效果:
(1)本发明的glp-1类似物-fc融合蛋白有效增加了glp-1类似物的体内循环半衰期,使其体内循环半衰期延长了0.8倍。
(2)本发明的glp-1类似物-fc融合蛋白增强glp-1类似物的体内和体外的活性及稳定性,使其活性提高1倍。
(3)本发明的glp-1类似物-fc融合蛋白提高与fcrn的亲和力,增强glp-1类似物体内组织系统的穿透性和跨细胞作用,提高药物的效果,减少药物的注射频次,减轻患者的疼痛和降低治疗成本。
附图说明
图1:构建重组融合蛋白表达质粒示意图。
图2a:纯化后的样品的组分分别进行非还原(non-reduced)的sds-page分析,用考马斯亮蓝(comasieblue)染色显影结果。
图2b:纯化后的样品的组分分别进行还原(reduced)的sds-page分析,用考马斯亮蓝(comasieblue)染色显影结果。
具体实施方式
一、glp-1类似物-fc融合蛋白
本发明的glp-1类似物-fc融合蛋白,其结构包括:glp-1类似物和抗体fc片段。
所述融合蛋白的结构中,第一区域为glp-1类似物。所述glp-1类似物可以是重组glp-1。所述glp-1类似物的氨基酸序列如seqidno.1所示,或者与seqidno.1所示序列具有80%以上的同源性,更优选地,具有90%以上的同源性,进一步优选为具有97%以上的同源性。对于本领域技术人员而言应当能够理解的是,当所述glp-1类似物的氨基酸序列与seqidno.1所示序列同源性≥80%(优选为≥90%,进一步优选为≥97%)都可以与fc融合,形成glp-1类似物-fc融合蛋白,效果是可以预期的。
所述融合蛋白的结构中,第二区域为抗体fc片段。所述抗体fc片段为本领域的不具adcc效应子功能的非裂解性fc。只要不对本发明的发明目的产生限制即可。由于与glp-1类似物相连的抗体fc片段来源于免疫球蛋白igg的恒定区,它在消灭病原体的免疫防御中起重要作用。在四种人igg亚型中,igg1和igg2,igg3,igg4均可以与glp-1类似物结合。fc融合主要是为了增加它的体内循环半衰期和降低生产成本,而fc介导的“抗体依赖细胞介导的细胞毒性作用”(antibody-dependentcell-mediatedcytotoxicity,adcc)功能是不必要的,甚至可能产生有害副作用。为了得到不具adcc效应子功能的非裂解性fc,本发明发明人对人的igg4的fc片段进行了修饰,突变或杂合。
本发明一优选实施例中,分别获得igg-fc、igg-fc(qa)、igg-fc(ql)、igg-fc(n434s)、hyfc、hyfcmutation。
igg-fc的氨基酸序列如seqidno.3所示,具体为:
gluserlystyrglyproprocysprosercysproalaproglupheleuglyglyproservalpheleupheproprolysprolysaspthrleumetileserargthrprogluvalthrcysvalvalvalaspvalserglngluaspprogluvalglnpheasntrptyrvalaspglyvalgluvalhisasnalalysthrlysproargglugluglnpheasnserthrtyrargvalvalargvalleuthrvalleuhisglnasptrpleuasnglylysglutyrlyscyslysvalserasnlysglyleuproserserileglulysthrileserlysalalysglyglnproarggluproglnvaltyrthrleuproproserglngluglumetthrlysasnglnvalserleuthrcysleuvallysglyphetyrproseraspilealavalglutrpgluserasnglyglnprogluaspasntyrlysthrthrproprovalleuaspseraspglyserphepheleutyrserargleuthrvalasplysserargtrpglngluglyasnvalphesercysservalmethisglualaleuhisasnhistyrthrglnlysserleuserleuserleuglylys。
igg-fc(qa)的氨基酸序列如seqidno.4所示,具体为:
gluserlystyrglyproprocysprosercysproalaproglupheleuglyglyproservalpheleupheproprolysprolysaspthrleumetileserargthrprogluvalthrcysvalvalvalaspvalserglngluaspprogluvalglnpheasntrptyrvalaspglyvalgluvalhisasnalalysthrlysproargglugluglnpheasnserthrtyrargvalvalargvalleuglnvalleuhisglnasptrpleuasnglylysglutyrlyscyslysvalserasnlysglyleuproserserileglulysthrileserlysalalysglyglnproarggluproglnvaltyrthrleuproproserglngluglumetthrlysasnglnvalserleuthrcysleuvallysglyphetyrproseraspilealavalglutrpgluserasnglyglnprogluaspasntyrlysthrthrproprovalleuaspseraspglyserphepheleutyrserargleuthrvalasplysserargtrpglngluglyasnvalphesercysservalmethisglualaleuhisalahistyrthrglnlysserleuserleuserleuglylys。
igg-fc(ql)的氨基酸序列如seqidno.5所示,具体为:
gluserlystyrglyproprocysprosercysproalaproglupheleuglyglyproservalpheleupheproprolysprolysaspglnleumetileserargthrprogluvalthrcysvalvalvalaspvalserglngluaspprogluvalglnpheasntrptyrvalaspglyvalgluvalhisasnalalysthrlysproargglugluglnpheasnserthrtyrargvalvalargvalleuglnvalleuhisglnasptrpleuasnglylysglutyrlyscyslysvalserasnlysglyleuproserserileglulysthrileserlysalalysglyglnproarggluproglnvaltyrthrleuproproserglngluglumetthrlysasnglnvalserleuthrcysleuvallysglyphetyrproseraspilealavalglutrpgluserasnglyglnprogluaspasntyrlysthrthrproprovalleuaspseraspglyserphepheleutyrserargleuthrvalasplysserargtrpglngluglyasnvalphesercysservalleuhisglualaleuhisasnhistyrthrglnlysserleuserleuserleuglylys。
igg-fc(n434s)的氨基酸序列如seqidno.6所示,具体为:
gluserlystyrglyproprocysprosercysproalaproglupheleuglyglyproservalpheleupheproprolysprolysaspthrleumetileserargthrprogluvalthrcysvalvalvalaspvalserglngluaspprogluvalglnpheasntrptyrvalaspglyvalgluvalhisasnalalysthrlysproargglugluglnpheasnserthrtyrargvalvalargvalleuglnvalleuhisglnasptrpleuasnglylysglutyrlyscyslysvalserasnlysglyleuproserserileglulysthrileserlysalalysglyglnproarggluproglnvaltyrthrleuproproserglngluglumetthrlysasnglnvalserleuthrcysleuvallysglyphetyrproseraspilealavalglutrpgluserasnglyglnprogluaspasntyrlysthrthrproprovalleuaspseraspglyserphepheleutyrserargleuthrvalasplysserargtrpglngluglyasnvalphesercysservalmethisglualaleuhisserhistyrthrglnlysserleuserleuserleuglylys。
hyfc的氨基酸序列如seqidno.7所示,具体为:
argasnthrglyargglyglygluglulyslyslysglulysglulysglugluglnglugluarggluthrlysthrproglucysproserhisthrglnproleuglyvalpheleupheproprolysprolysaspthrleumetileserargthrprogluvalthrcysvalvalvalaspvalserglngluaspprogluvalglnpheasntrptyrvalaspglyvalgluvalhisasnalalysthrlysproargglugluglnpheasnserthrtyrargvalvalargvalleuthrvalleuhisglnasptrpleuasnglylysglutyrlyscyslysvalserasnlysglyleuproserserileglulysthrileserlysalalysglyglnproarggluproglnvaltyrthrleuproproserglngluglumetthrlysasnglnvalserleuthrcysleuvallysglyphetyrproseraspilealavalglutrpgluserasnglyglnprogluaspasntyrlysthrthrproprovalleuaspseraspglyserphepheleutyrserargleuthrvalasplysserargtrpglngluglyasnvalphesercysservalmethisglualaleuhisasnhistyrthrglnlysserleuserleuserleuglylys。
hyfcmutation的氨基酸序列如seqidno.8所示,具体为:
argasnthrglyargglyglygluglulyslyslysglulysglulysglugluglnglugluarggluthrlysthrproglucysproserhisthrglnproleuglyvalpheleupheproprolysprolysaspthrleumetileserargthrprogluvalthrcysvalvalvalaspvalserglngluaspprogluvalglnpheasntrptyrvalaspglyvalgluvalhisasnalalysthrlysproargglugluglnpheasnserthrtyrargvalvalargvalleuglnvalleuhisglnasptrpleuasnglylysglutyrlyscyslysvalserasnlysglyleuproserserileglulysthrileserlysalalysglyglnproarggluproglnvaltyrthrleuproproserglngluglumetthrlysasnglnvalserleuthrcysleuvallysglyphetyrproseraspilealavalglutrpgluserasnglyglnprogluaspasntyrlysthrthrproprovalleuaspseraspglyserphepheleutyrserargleuthrvalasplysserargtrpglngluglyasnvalphesercysservalmethisglualaleuhisalahistyrthrglnlysserleuserleuserleuglylys。
所述glp-1类似物和抗体fc片段可直接连接或通过连接肽连接。当所述glp-1类似物和抗体fc片段直接连接时,所述glp-1类似物的c端与抗体fc片段的n端以肽键相连。当所述glp-1类似物和抗体fc片段通过连接肽连接时,所述连接肽的n端与所述glp-1类似物c末端以肽键相连,所述连接肽的c端与抗体fc片段的n端以肽键相连。
所述连接肽可以是本领域的各种连接肽,只要不对本发明的发明目的产生限制即可。优选地,所述连接肽普遍采用以g4s(即氨基酸序列ggggs)为单位的多单位连接实现,此类连接肽的设计原则已经是本领域人员的公知技术。具体可参见cn102875683b,cn102875683b,申请号201110193210.3等现有技术。连接肽的氨基酸数量为≥2个。
本发明一优选实施例中,所述连接肽的氨基酸序列如seqidno.2所示,具体为:glyglyglyglyserglyglyglyglyser。
在本案的较佳案例中,所述glp-1类似物-fc融合蛋白的序列如seqidno.9~14之任一所示。
二、编码glp-1类似物-fc融合蛋白的多核苷酸
编码所述glp-1类似物-fc融合蛋白的多核苷酸,可以是dna形式或rna形式。dna形式包括cdna、基因组dna或人工合成的dna。dna可以是单链的或是双链的。
编码所述glp-1类似物-fc融合蛋白的多核苷酸,可以通过本领域技术人员熟知的任何适当的技术制备。所述技术见于本领域的一般描述,如《分子克隆实验指南》(j.萨姆布鲁克等,科学出版社,1995)。包括但不限于重组dna技术、化学合成等方法;例如采用重叠延伸pcr法。
在本案的较佳实例中,如seqidno.9所示的glp-1类似物-fc融合蛋白的核苷酸编码序列如seqidno.15所示。
如seqidno.10所示的glp-1类似物-fc融合蛋白的核苷酸编码序列如seqidno.16所示。
如seqidno.11所示的glp-1类似物-fc融合蛋白的核苷酸编码序列如seqidno.17所示。
如seqidno.12所示的glp-1类似物-fc融合蛋白的核苷酸编码序列如seqidno.18所示。
如seqidno.13所示的glp-1类似物-fc融合蛋白的核苷酸编码序列如seqidno.19所示。
如seqidno.14所示的glp-1类似物-fc融合蛋白的核苷酸编码序列如seqidno.20所示。
三、表达载体
所述表达载体含有编码所述glp-1类似物-fc融合蛋白的多核苷酸。本领域的技术人员熟知的方法能用于构建所述表达载体。这些方法包括重组dna技术、dna合成技术等。可将编码所述融合蛋白的dna有效连接到载体中的多克隆位点上,以指导mrna合成进而表达蛋白,或者用于同源重组。
四、宿主细胞
所述宿主细胞被表达所述glp-1类似物-fc融合蛋白的表达载体所转化。宿主细胞可以是原核细胞,如细菌细胞;或是低等真核细胞,如酵母细胞;或是高等真核细胞,如哺乳动物细胞。代表性例子有:大肠杆菌,链霉菌属;鼠伤寒沙门菌、李斯特细菌;真菌细胞如酵母;植物细胞;果蝇s2或sf9的昆虫细胞;cho、cos.293细胞、或bowes黑素瘤细胞的动物细胞等。
五、制备glp-1类似物-fc融合蛋白的方法
制备前述glp-1类似物-fc融合蛋白的方法,包括:构建含有glp-1类似物-fc融合蛋白基因序列的表达载体,然后将含glp-1类似物-fc融合蛋白基因序列的表达载体转化至宿主细胞中诱导表达,从表达产物中分离获得所述的glp-1类似物-fc融合蛋白。本发明的较佳案例中,所述表达载体采用pcdna3.1。所述宿主细胞采用cho-s细胞。
六、glp-1类似物-fc融合蛋白的用途
本发明的glp-1类似物-fc融合蛋白可用于制备糖尿病及相关疾病治疗药物。
七、药物组合物
本发明的药物组合物,含有前述glp-1类似物-fc融合蛋白及至少一种药学可接受的载体或赋形剂。
所述药物组合物的主要用途为治疗糖尿病及相关疾病。所述相关疾病包括:ⅱ型糖尿病、ⅰ型糖尿病、肥胖、ⅱ型糖尿病患者严重心血管事件和其他严重并发症等(madsbads,kielgastu,asmarm,etal.diabetesobesmetab.2011may;13(5):394-407;issacm,azarst.currdiabrep,2012oct;12(5):560-567;nefflm,kushnerrf.diabetesmetabsyndrobes,2010jul20;3:263-273;sivertsenj,rosenmeierj,holstjj,etal.natrevcardiol,2012jan31;9(4):209-222)。
本领域枝术人员已知的治疗惰性的无机或有机的载体包括(但不限于)糖类或其衍生物、氨基酸类或其衍生物、表面活性剂,植物油、蜡、脂肪、多羟基化合物例如聚乙二醇、醇类、甘油,各种防腐剂、抗氧化剂、稳定剂、盐、缓冲液,水、诸如此类也可加入其中,这些物质根据需要用于帮助配方的稳定性或有助于提高活性或它的生物有效性。
本发明的药物组合物可以用本领域技术人员所熟知的技术配制,包括液体或凝胶体,冻干的或其他形式,以产生储存稳定的适合对人或动物给药的药物。
八、治疗糖尿病及其相关疾病的方法
可将本发明的glp-1类似物-fc融合蛋白施用于对象,用于治疗糖尿病及其相关疾病患者。
前述融合蛋白用于治疗包括患有非胰岛素依赖型和胰岛素依赖型糖尿病、肥胖及多种其他疾病患者的方法可参考现有的glp-1类药物制剂,如
本发明的蛋白质可以单独给药,或以各种组合给药,以及与其它治疗药剂一起结合形式给药。
在进一步描述本发明具体实施方式之前,应理解,本发明的保护范围不局限于下述特定的具体实施方案;还应当理解,本发明实施例中使用的术语是为了描述特定的具体实施方案,而不是为了限制本发明的保护范围。下列实施例中未注明具体条件的试验方法,通常按照常规条件,或者按照各制造商所建议的条件。
当实施例给出数值范围时,应理解,除非本发明另有说明,每个数值范围的两个端点以及两个端点之间任何一个数值均可选用。除非另外定义,本发明中使用的所有技术和科学术语与本技术领域技术人员通常理解的意义相同。除实施例中使用的具体方法、设备、材料外,根据本技术领域的技术人员对现有技术的掌握及本发明的记载,还可以使用与本发明实施例中所述的方法、设备、材料相似或等同的现有技术的任何方法、设备和材料来实现本发明。
除非另外说明,本发明中所公开的实验方法、检测方法、制备方法均采用本技术领域常规的分子生物学、生物化学、染色质结构和分析、分析化学、细胞培养、重组dna技术及相关领域的常规技术。这些技术在现有文献中已有完善说明,具体可参见sambrook等molecularcloning:alaboratorymanual,secondedition,coldspringharborlaboratorypress,1989andthirdedition,2001;ausubel等,currentprotocolsinmolecularbiology,johnwiley&sons,newyork,1987andperiodicupdates;theseriesmethodsinenzymology,academicpress,sandiego;wolffe,chromatinstructureandfunction,thirdedition,academicpress,sandiego,1998;methodsinenzymology,vol.304,chromatin(p.m.wassarmananda.p.wolffe,eds.),academicpress,sandiego,1999;和methodsinmolecularbiology,vol.119,chromatinprotocols(p.b.becker,ed.)humanapress,totowa,1999等。
实施例1重组融合蛋白表达载体的构建
运用基因合成技术,分别将glp-1类似物、fc的序列、连接肽按照动物细胞密码子偏好,翻译成dna序列进行全序列合成。
glp-1类似物的核苷酸编码序列如seqidno.21所示,具体为:
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaaggagttcatcgcctggctggtgaagggcggcggc。
一、将glp-1类似物的核苷酸编码序列与连接肽的核苷酸编码序列、igg-fc的核苷酸编码序列融合,获得glp-1类似物-igg-fc融合蛋白的核苷酸编码序列:
具体地,其中,连接肽的核苷酸编码序列如seqidno.22所示,具体为:
ggtggtggtggctccggaggcggcggctct。
igg-fc的核苷酸编码序列如seqidno.23所示,具体为:
gaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcggaccctcagttttcttgtttccaccgaagcctaaagatactcttatgatttcgcgtacccccgaagtcacatgtgtagtggttgacgtcagtcaagaggctccagaagtacagttcaattggtacgtggacggggttgaggtccataacgccaagacgaaaccgcgcgaagagcaatttaatagcacttatcgagtagtgcgggttctcaccgtcctacaccaggattggctgaacggtaaggaatacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagacaatatcgaaagcaaagggacaacccagagaaccacaggtgtatacgttgccgcctagtcaagaggaaatgactaaaaaccaggttagccttacctgtctcgtcaaggggttctacccctctgacattgcggtagagtgggaatccaatggtcaaccagaggataactataaaacaacgccgcctgtgctagactcagatggctcgtttttcctgtacagtaggttaactgttgacaagagccgttggcaggaaggaaatgtcttttcttgctccgtaatgcatgaggctttgcacaaccattatacccaaaaatcactttcgctcagtctagggaag。
glp-1类似物-igg-fc融合蛋白的核苷酸编码序列如seqidno.15所示,具体为:
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaaggagttcatcgcctggctggtgaagggcggcggcggtggtggtggctccggaggcggcggctctgaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcggaccctcagttttcttgtttccaccgaagcctaaagatactcttatgatttcgcgtacccccgaagtcacatgtgtagtggttgacgtcagtcaagaggctccagaagtacagttcaattggtacgtggacggggttgaggtccataacgccaagacgaaaccgcgcgaagagcaatttaatagcacttatcgagtagtgcgggttctcaccgtcctacaccaggattggctgaacggtaaggaatacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagacaatatcgaaagcaaagggacaacccagagaaccacaggtgtatacgttgccgcctagtcaagaggaaatgactaaaaaccaggttagccttacctgtctcgtcaaggggttctacccctctgacattgcggtagagtgggaatccaatggtcaaccagaggataactataaaacaacgccgcctgtgctagactcagatggctcgtttttcctgtacagtaggttaactgttgacaagagccgttggcaggaaggaaatgtcttttcttgctccgtaatgcatgaggctttgcacaaccattatacccaaaaatcactttcgctcagtctagggaag。
二、将glp-1类似物的核苷酸编码序列与连接肽的核苷酸编码序列、igg-fc(qa)的核苷酸编码序列融合,获得glp-1类似物-igg-fc(qa)融合蛋白的核苷酸编码序列:
具体地,其中,连接肽的核苷酸编码序列如seqidno.22所示,具体为:
ggtggtggtggctccggaggcggcggctct。
igg-fc(qa)的核苷酸编码序列如seqidno.24所示,具体为:
gaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcggaccctcagttttcttgtttccaccgaagcctaaagatactcttatgatttcgcgtacccccgaagtcacatgtgtagtggttgacgtcagtcaagaggctccagaagtacagttcaattggtacgtggacggggttgaggtccataacgccaagacgaaaccgcgcgaagagcaatttaatagcacttatcgagtagtgcgggttctccaggtcctacaccaagattggctgaacggtaaggaatacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagaccatatcgaaagcaaagggacagcccagagaaccacaagtgtatacattgccgcctagtcaggaggaaatgacgaaaaaccaagttagccttacttgtctcgtcaaggggttctacccctctgacattgcggtagagtgggaatccaatggtcagccagaggataactataaaaccacaccgcctgtgctagactcagatggctcgtttttcctgtacagtaggttaacggttgacaagagccgttggcaagaaggaaatgtcttttcttgctccgtaatgcatgaggctttgcacgcccattatactcagaaatcactttcgctcagtctagggaag。
glp-1类似物-igg-fc(qa)融合蛋白的核苷酸编码序列如seqidno.16所示,具体为:
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaaggagttcatcgcctggctggtgaagggcggcggcggtggtggtggctccggaggcggcggctctgaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcggaccctcagttttcttgtttccaccgaagcctaaagatactcttatgatttcgcgtacccccgaagtcacatgtgtagtggttgacgtcagtcaagaggctccagaagtacagttcaattggtacgtggacggggttgaggtccataacgccaagacgaaaccgcgcgaagagcaatttaatagcacttatcgagtagtgcgggttctccaggtcctacaccaagattggctgaacggtaaggaatacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagaccatatcgaaagcaaagggacagcccagagaaccacaagtgtatacattgccgcctagtcaggaggaaatgacgaaaaaccaagttagccttacttgtctcgtcaaggggttctacccctctgacattgcggtagagtgggaatccaatggtcagccagaggataactataaaaccacaccgcctgtgctagactcagatggctcgtttttcctgtacagtaggttaacggttgacaagagccgttggcaagaaggaaatgtcttttcttgctccgtaatgcatgaggctttgcacgcccattatactcagaaatcactttcgctcagtctagggaag。
三、将glp-1类似物的核苷酸编码序列与连接肽的核苷酸编码序列、igg-fc(ql)的核苷酸编码序列融合,获得glp-1类似物-igg-fc(ql)融合蛋白的核苷酸编码序列:
具体地,其中,连接肽的核苷酸编码序列如seqidno.22所示,具体为:
ggtggtggtggctccggaggcggcggctct。
igg-fc(ql)的核苷酸编码序列如seqidno.25所示,具体为:
gaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcggaccctcagttttcttgtttccaccgaagcctaaagatcaacttatgatttcgcgtactcccgaagtcacctgtgtagtggttgacgtcagtcaggaggctccagaagtacaattcaattggtacgtggacggggttgaggtccataacgccaagacaaaaccgcgcgaagagcagtttaatagcacgtatcgagtagtgcgggttctccaagtcctacaccaggattggctgaacggtaaggaatacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagactatatcgaaagcaaagggacaacccagagaaccacaggtgtataccttgccgcctagtcaagaggaaatgacaaaaaaccaggttagccttacgtgtctcgtcaaggggttctacccctctgacattgcggtagagtgggaatccaatggtcaaccagaggataactataaaactaccccgcctgtgctagactcagatggctcgtttttcctgtacagtaggttaacagttgacaagagccgttggcaggaaggaaatgtcttttcttgctccgtattgcatgaggctcttcacaaccattatacgcaaaaatcactctcgctaagtctggggaag。
glp-1类似物-igg-fc(ql)融合蛋白的核苷酸编码序列如seqidno.17所示,具体为:
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaaggagttcatcgcctggctggtgaagggcggcggcggtggtggtggctccggaggcggcggctctgaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcggaccctcagttttcttgtttccaccgaagcctaaagatcaacttatgatttcgcgtactcccgaagtcacctgtgtagtggttgacgtcagtcaggaggctccagaagtacaattcaattggtacgtggacggggttgaggtccataacgccaagacaaaaccgcgcgaagagcagtttaatagcacgtatcgagtagtgcgggttctccaagtcctacaccaggattggctgaacggtaaggaatacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagactatatcgaaagcaaagggacaacccagagaaccacaggtgtataccttgccgcctagtcaagaggaaatgacaaaaaaccaggttagccttacgtgtctcgtcaaggggttctacccctctgacattgcggtagagtgggaatccaatggtcaaccagaggataactataaaactaccccgcctgtgctagactcagatggctcgtttttcctgtacagtaggttaacagttgacaagagccgttggcaggaaggaaatgtcttttcttgctccgtattgcatgaggctcttcacaaccattatacgcaaaaatcactctcgctaagtctggggaag。
四、将glp-1类似物的核苷酸编码序列与连接肽的核苷酸编码序列、igg-fc(n434s)的核苷酸编码序列融合,获得glp-1类似物-igg-fc(n434s)融合蛋白的核苷酸编码序列:
具体地,其中,连接肽的核苷酸编码序列如seqidno.22所示,具体为:
ggtggtggtggctccggaggcggcggctct。
igg-fc(n434s)的核苷酸编码序列如seqidno.26所示,具体为:
gaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcggaccctcagttttcttgtttccaccgaagcctaaagatactcttatgatttcgcgtacccccgaagtcacatgtgtagtggttgacgtcagtcaagaggctccagaagtacagttcaattggtacgtggacggggttgaggtccataacgccaagacgaaaccgcgcgaagagcaatttaatagcacttatcgagtagtgcgggttctccaggtcctacaccaagattggctgaacggtaaggaatacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagaccatatcgaaagcaaagggacagcccagagaaccacaagtgtatacattgccgcctagtcaggaggaaatgacgaaaaaccaagttagccttacttgtctcgtcaaggggttctacccctctgacattgcggtagagtgggaatccaatggtcagccagaggataactataaaaccacaccgcctgtgctagactcagatggctcgtttttcctgtacagtaggttaacggttgacaagagccgttggcaagaaggaaatgtcttttcttgctccgtaatgcatgaggctttgcactcacattatactcagaaatcgcttagtctcagcctagggaag。
glp-1类似物-igg-fc(n434s)融合蛋白的核苷酸编码序列如seqidno.18所示,具体为:
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaaggagttcatcgcctggctggtgaagggcggcggcggtggtggtggctccggaggcggcggctctgaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcggaccctcagttttcttgtttccaccgaagcctaaagatactcttatgatttcgcgtacccccgaagtcacatgtgtagtggttgacgtcagtcaagaggctccagaagtacagttcaattggtacgtggacggggttgaggtccataacgccaagacgaaaccgcgcgaagagcaatttaatagcacttatcgagtagtgcgggttctccaggtcctacaccaagattggctgaacggtaaggaatacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagaccatatcgaaagcaaagggacagcccagagaaccacaagtgtatacattgccgcctagtcaggaggaaatgacgaaaaaccaagttagccttacttgtctcgtcaaggggttctacccctctgacattgcggtagagtgggaatccaatggtcagccagaggataactataaaaccacaccgcctgtgctagactcagatggctcgtttttcctgtacagtaggttaacggttgacaagagccgttggcaagaaggaaatgtcttttcttgctccgtaatgcatgaggctttgcactcacattatactcagaaatcgcttagtctcagcctagggaag。
五、将glp-1类似物的核苷酸编码序列与hyfc的核苷酸编码序列融合,获得glp-1类似物-hyfc融合蛋白的核苷酸编码序列:
具体地,其中,hyfc的核苷酸编码序列如seqidno.27所示,具体为:
cgtaatactggtcgcggcggagaagagaaaaagaaagaaaaggagaaagaagagcaagaagagcgagaaaccaagacacctgagtgtccctctcatacgcagccattaggggtttttttgttcccgcctaaacccaaggatactcttatgatttcccggaccccagaagtcacatgcgtagtggttgacgtctcacaagaggctccggaagtacagtttaactggtatgtggacggtgttgaggtccacaatgctaaaacgaagcctagagaagagcaattcaactcgacttacagggtagtgcgtgttctcaccgtcctacatcaggattggctgaatggcaaagaatataagtgtaaagtaagtaacaagggattacccagctctatcgagaaaacaatatccaaggccaaagggcaaccacgcgaaccgcaggtgtacacgttgcctccctcacaagaggaaatgactaagaatcaggtttcgcttacctgcctcgtcaaaggtttttatccaagtgacattgcagtagagtgggaaagcaacggccaaccggaggataattacaagacaacgcctcccgtgctagactctgatggctccttctttctgtattcacgattaactgttgacaaatcgcggtggcaggaagggaacgtcttcagttgtagcgtaatgcacgaggcgttgcataatcactacacccaaaagtctctttccctctcactaggtaaa。
glp-1类似物-igg-hyfc融合蛋白的核苷酸编码序列如seqidno.19所示,具体为:
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaaggagttcatcgcctggctggtgaagggcggcggccgtaatactggtcgcggcggagaagagaaaaagaaagaaaaggagaaagaagagcaagaagagcgagaaaccaagacacctgagtgtccctctcatacgcagccattaggggtttttttgttcccgcctaaacccaaggatactcttatgatttcccggaccccagaagtcacatgcgtagtggttgacgtctcacaagaggctccggaagtacagtttaactggtatgtggacggtgttgaggtccacaatgctaaaacgaagcctagagaagagcaattcaactcgacttacagggtagtgcgtgttctcaccgtcctacatcaggattggctgaatggcaaagaatataagtgtaaagtaagtaacaagggattacccagctctatcgagaaaacaatatccaaggccaaagggcaaccacgcgaaccgcaggtgtacacgttgcctccctcacaagaggaaatgactaagaatcaggtttcgcttacctgcctcgtcaaaggtttttatccaagtgacattgcagtagagtgggaaagcaacggccaaccggaggataattacaagacaacgcctcccgtgctagactctgatggctccttctttctgtattcacgattaactgttgacaaatcgcggtggcaggaagggaacgtcttcagttgtagcgtaatgcacgaggcgttgcataatcactacacccaaaagtctctttccctctcactaggtaaa。
六、将glp-1类似物的核苷酸编码序列与hyfcmutation的核苷酸编码序列融合,获得glp-1类似物-hyfcmutation融合蛋白的核苷酸编码序列:
具体地,其中,hyfcmutation的核苷酸编码序列如seqidno.28所示,具体为:
cgtaatactggtcgcggcggagaagagaaaaagaaagaaaaggagaaagaagagcaagaagagcgagaaaccaagacacctgagtgtccctctcatacgcagccattaggggtttttttgttcccgcctaaacccaaggatactcttatgatttcccggaccccagaagtcacatgcgtagtggttgacgtctcacaagaggctccggaagtacagtttaactggtatgtggacggtgttgaggtccacaatgctaaaacgaagcctagagaagagcaattcaactcgacttacagggtagtgcgtgttctccaggtcctacatcaagattggctgaatggcaaagaatataagtgtaaagtaagtaacaagggattacccagctctatcgagaaaaccatatccaaggccaaagggcagccacgcgaaccgcaagtgtacacattgcctccctcacaggaggaaatgacgaagaatcaagtttcgcttacttgcctcgtcaaaggtttttatccaagtgacattgcagtagagtgggaaagcaacggccagccggaggataattacaagaccacacctcccgtgctagactctgatggctccttctttctgtattcacgattaacggttgacaaatcgcggtggcaagaagggaacgtcttcagttgtagcgtaatgcacgaggcgttgcatgctcactacactcagaagtctctttccctctcactaggtaaa。
glp-1类似物-hyfcmutation融合蛋白的核苷酸编码序列如seqidno.20所示,具体为:
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaaggagttcatcgcctggctggtgaagggcggcggccgtaatactggtcgcggcggagaagagaaaaagaaagaaaaggagaaagaagagcaagaagagcgagaaaccaagacacctgagtgtccctctcatacgcagccattaggggtttttttgttcccgcctaaacccaaggatactcttatgatttcccggaccccagaagtcacatgcgtagtggttgacgtctcacaagaggctccggaagtacagtttaactggtatgtggacggtgttgaggtccacaatgctaaaacgaagcctagagaagagcaattcaactcgacttacagggtagtgcgtgttctccaggtcctacatcaagattggctgaatggcaaagaatataagtgtaaagtaagtaacaagggattacccagctctatcgagaaaaccatatccaaggccaaagggcagccacgcgaaccgcaagtgtacacattgcctccctcacaggaggaaatgacgaagaatcaagtttcgcttacttgcctcgtcaaaggtttttatccaagtgacattgcagtagagtgggaaagcaacggccagccggaggataattacaagaccacacctcccgtgctagactctgatggctccttctttctgtattcacgattaacggttgacaaatcgcggtggcaagaagggaacgtcttcagttgtagcgtaatgcacgaggcgttgcatgctcactacactcagaagtctctttccctctcactaggtaaa。
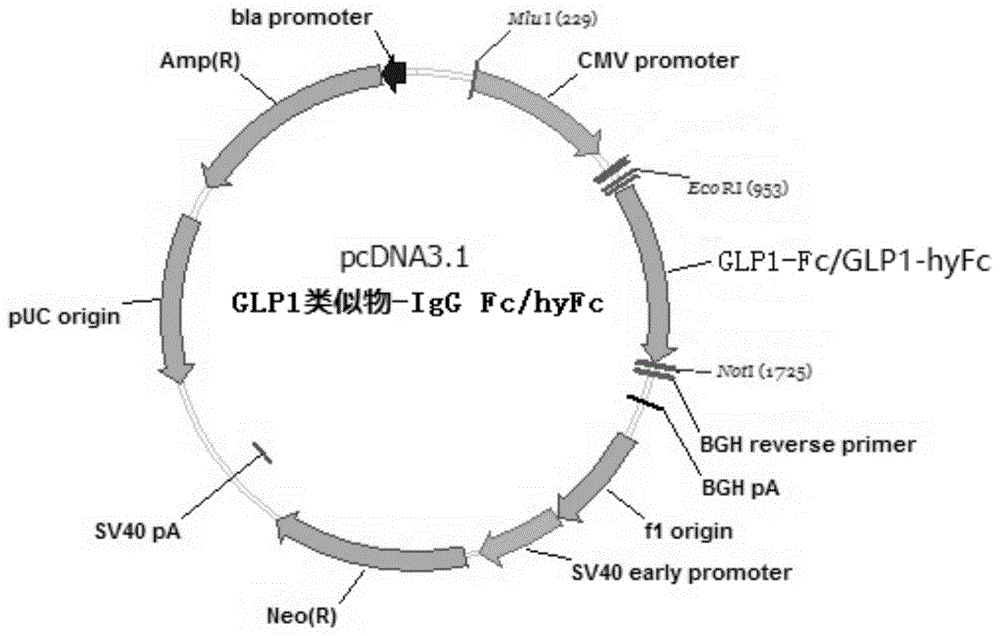
如图1所示,将编码上述各融合蛋白的cdna分别连接到表达载体pcdna3.1的ecori和noti位点之间,构建重组融合蛋白表达质粒。经测序验证各融合蛋白的核苷酸编码序列正确,符合预期。
实施例2重组融合蛋白的表达纯化
一、重组融合蛋白的cho表达
将实施例1中所构建的各重组融合蛋白表达质粒分别转染到cho-s细胞中。为建立稳定表达各重组融合蛋白的cho-s细胞,将在6孔细胞培养板(2.5×105个细胞/孔)上生长的细胞用4μg线性化的各重组融合蛋白表达质粒转染。转染24h后,细胞在含有g418(500μg/ml)的dmem培养液分裂和培养,以筛选那些已经将重组融合蛋白表达质粒稳定整合到其基因组内的细胞。培养过程中,每3天换培养液一次直至细胞克隆形成。分离单克隆细胞并扩展成稳定的细胞系并将这些细胞系在24孔板上生长的组织培养的上清液用人glp1类似物试剂盒检测融合蛋白,选择能分泌融合蛋白的细胞用作以后的特性分析。
二、从哺乳动物细胞培养液中纯化重组融合蛋白
应用a蛋白葡聚糖凝胶柱进行中规模的重组融合蛋白纯化。50ml的柱体积的a蛋白葡聚糖凝胶柱可以纯化15cm培养皿中生长有已转染cho-s细胞的条件培养液。收集细胞转染后48h的50mldmem培养液,或是收集稳定表达各重组融合蛋白的细胞,将其加入a蛋白葡聚糖凝胶1ml满体积(amersham-pharmacia)。加入1%tritonx-100在4℃下培养过夜。然后用含1%tritonx-100的pbs缓冲液洗涤,然后用150mmnacl洗涤,最后用1mmnacl氨基乙酸(ph2.7)将各重组融合蛋白从树脂上洗脱。洗脱液立即用tris缓冲液(ph9.0)中和并且纯化的蛋白用pd-10凝胶柱除盐(amersham-pharmacia)并用pbs洗脱。
两步洗脱方法可以将大部分重组融合蛋白由葡聚糖凝胶柱上洗脱下来。
如图2a和图2b所示,纯化后的样品的组分分别进行还原(reduced)和非还原(non-reduced)的sds-page分析,用考马斯亮蓝(comasieblue)染色显影以评估产率和纯化率,结果显示每ml培养液接种1.25×105细胞培养2d后,重组融合蛋白得率约为10μg/ml;纯化率为85%。
将纯化获得的各重组融合蛋白进行n端测序以及分析检测,n端测序结果表明所表达的各重组融合蛋白均读框无误。每个融合蛋白的氨基酸序列,且与预期一致。
具体地,glp-1类似物-igg-fc融合蛋白的氨基酸序列如seqidno.9所示,具体为:
hisglygluglythrphethrseraspvalsersertyrleuglugluglnalaalalysglupheilealatrpleuvallysglyglyglyglyglyglyglyserglyglyglyglysergluserlystyrglyproprocysprosercysproalaproglupheleuglyglyproservalpheleupheproprolysprolysaspthrleumetileserargthrprogluvalthrcysvalvalvalaspvalserglngluaspprogluvalglnpheasntrptyrvalaspglyvalgluvalhisasnalalysthrlysproargglugluglnpheasnserthrtyrargvalvalargvalleuthrvalleuhisglnasptrpleuasnglylysglutyrlyscyslysvalserasnlysglyleuproserserileglulysthrileserlysalalysglyglnproarggluproglnvaltyrthrleuproproserglngluglumetthrlysasnglnvalserleuthrcysleuvallysglyphetyrproseraspilealavalglutrpgluserasnglyglnprogluaspasntyrlysthrthrproprovalleuaspseraspglyserphepheleutyrserargleuthrvalasplysserargtrpglngluglyasnvalphesercysservalmethisglualaleuhisasnhistyrthrglnlysserleuserleuserleuglylys。
glp-1类似物-igg-fc(qa)融合蛋白的氨基酸序列如seqidno.10所示,具体为:
hisglygluglythrphethrseraspvalsersertyrleuglugluglnalaalalysglupheilealatrpleuvallysglyglyglyglyglyglyglyserglyglyglyglysergluserlystyrglyproprocysprosercysproalaproglupheleuglyglyproservalpheleupheproprolysprolysaspthrleumetileserargthrprogluvalthrcysvalvalvalaspvalserglngluaspprogluvalglnpheasntrptyrvalaspglyvalgluvalhisasnalalysthrlysproargglugluglnpheasnserthrtyrargvalvalargvalleuglnvalleuhisglnasptrpleuasnglylysglutyrlyscyslysvalserasnlysglyleuproserserileglulysthrileserlysalalysglyglnproarggluproglnvaltyrthrleuproproserglngluglumetthrlysasnglnvalserleuthrcysleuvallysglyphetyrproseraspilealavalglutrpgluserasnglyglnprogluaspasntyrlysthrthrproprovalleuaspseraspglyserphepheleutyrserargleuthrvalasplysserargtrpglngluglyasnvalphesercysservalmethisglualaleuhisalahistyrthrglnlysserleuserleuserleuglylys。
glp-1类似物-igg-fc(ql)融合蛋白的氨基酸序列如seqidno.11所示,具体为:
hisglygluglythrphethrseraspvalsersertyrleuglugluglnalaalalysglupheilealatrpleuvallysglyglyglyglyglyglyglyserglyglyglyglysergluserlystyrglyproprocysprosercysproalaproglupheleuglyglyproservalpheleupheproprolysprolysaspthrleumetileserargthrprogluvalthrcysvalvalvalaspvalserglngluaspprogluvalglnpheasntrptyrvalaspglyvalgluvalhisasnalalysthrlysproargglugluglnpheasnserthrtyrargvalvalargvalleuglnvalleuhisglnasptrpleuasnglylysglutyrlyscyslysvalserasnlysglyleuproserserileglulysthrileserlysalalysglyglnproarggluproglnvaltyrthrleuproproserglngluglumetthrlysasnglnvalserleuthrcysleuvallysglyphetyrproseraspilealavalglutrpgluserasnglyglnprogluaspasntyrlysthrthrproprovalleuaspseraspglyserphepheleutyrserargleuthrvalasplysserargtrpglngluglyasnvalphesercysservalleuhisglualaleuhisasnhistyrthrglnlysserleuserleuserleuglylys。
glp-1类似物-igg-fc(n434s)融合蛋白的氨基酸序列如seqidno.12所示,具体为:
hisglygluglythrphethrseraspvalsersertyrleuglugluglnalaalalysglupheilealatrpleuvallysglyglyglyglyglyglyglyserglyglyglyglysergluserlystyrglyproprocysprosercysproalaproglupheleuglyglyproservalpheleupheproprolysprolysaspthrleumetileserargthrprogluvalthrcysvalvalvalaspvalserglngluaspprogluvalglnpheasntrptyrvalaspglyvalgluvalhisasnalalysthrlysproargglugluglnpheasnserthrtyrargvalvalargvalleuthrvalleuhisglnasptrpleuasnglylysglutyrlyscyslysvalserasnlysglyleuproserserileglulysthrileserlysalalysglyglnproarggluproglnvaltyrthrleuproproserglngluglumetthrlysasnglnvalserleuthrcysleuvallysglyphetyrproseraspilealavalglutrpgluserasnglyglnprogluaspasntyrlysthrthrproprovalleuaspseraspglyserphepheleutyrserargleuthrvalasplysserargtrpglngluglyasnvalphesercysservalmethisglualaleuhisserhistyrthrglnlysserleuserleuserleuglylys。
glp-1类似物-hyfc融合蛋白的氨基酸序列如seqidno.13所示,具体为:
hisglygluglythrphethrseraspvalsersertyrleuglugluglnalaalalysglupheilealatrpleuvallysglyglyglyargasnthrglyargglyglygluglulyslyslysglulysglulysglugluglnglugluarggluthrlysthrproglucysproserhisthrglnproleuglyvalpheleupheproprolysprolysaspthrleumetileserargthrprogluvalthrcysvalvalvalaspvalserglngluaspprogluvalglnpheasntrptyrvalaspglyvalgluvalhisasnalalysthrlysproargglugluglnpheasnserthrtyrargvalvalargvalleuthrvalleuhisglnasptrpleuasnglylysglutyrlyscyslysvalserasnlysglyleuproserserileglulysthrileserlysalalysglyglnproarggluproglnvaltyrthrleuproproserglngluglumetthrlysasnglnvalserleuthrcysleuvallysglyphetyrproseraspilealavalglutrpgluserasnglyglnprogluaspasntyrlysthrthrproprovalleuaspseraspglyserphepheleutyrserargleuthrvalasplysserargtrpglngluglyasnvalphesercysservalmethisglualaleuhisasnhistyrthrglnlysserleuserleuserleuglylys。
glp-1类似物-hyfcmutation融合蛋白的氨基酸序列如seqidno.14所示,具体为:
hisglygluglythrphethrseraspvalsersertyrleuglugluglnalaalalysglupheilealatrpleuvallysglyglyglyargasnthrglyargglyglygluglulyslyslysglulysglulysglugluglnglugluarggluthrlysthrproglucysproserhisthrglnproleuglyvalpheleupheproprolysprolysaspthrleumetileserargthrprogluvalthrcysvalvalvalaspvalserglngluaspprogluvalglnpheasntrptyrvalaspglyvalgluvalhisasnalalysthrlysproargglugluglnpheasnserthrtyrargvalvalargvalleuglnvalleuhisglnasptrpleuasnglylysglutyrlyscyslysvalserasnlysglyleuproserserileglulysthrileserlysalalysglyglnproarggluproglnvaltyrthrleuproproserglngluglumetthrlysasnglnvalserleuthrcysleuvallysglyphetyrproseraspilealavalglutrpgluserasnglyglnprogluaspasntyrlysthrthrproprovalleuaspseraspglyserphepheleutyrserargleuthrvalasplysserargtrpglngluglyasnvalphesercysservalmethisglualaleuhisalahistyrthrglnlysserleuserleuserleuglylys。
实施例3重组融合蛋白的生物活性以及药代动力学研究
一、重组融合蛋白的生物活性研究
当重组基因工程glp-1r/hek293细胞表达的glp-1r受体蛋白具有生理活性时,在其受激动剂glp-1或其功能类似物的刺激时,glp-1r/hek293细胞的生理代谢活动增强,表现为细胞内camp含量增加。因此,通过测定受到glp-1等激动剂刺激后glp-1r/hek293细胞内camp含量的变化,即可判定glp-1r/hek293细胞表达的glp-1r受体蛋白是否具有生理活性。具体方法如下:glp-1r/hek293细胞按100μl/孔(30,000细胞/孔)培养于96孔培养板,用dmem培养基,37℃、5%co2条件下培养24小时。第二天撤去完全培养基,加入基础培养基培养过夜(15小时左右)。移弃基础培养基,加入待测定样本glp-1,37℃,5%co2条件下培养1小时。用camp试剂检测盒,测定上述glp-1刺激glp-1r/hek293细胞后胞内的camp含量。结果表明,glp-1r/hek293细胞的camp含量显著增加,而未转染glp-1r基因的hek293细胞未有任何剂量效应趋势。以上实验结果证实重组glp-1r/hek293细胞表达的glp-1r受体蛋白具有天然glp-1r受体蛋白相似的生理活性,且具有特异性。
称取不同浓度的各重组融合蛋白,用上述方法分别用于刺激生长中的glp-1r/hek293细胞,测定各样本刺激glp-1r/hek293细胞后产生的camp的数量。以样本浓度为横坐标,以camp的数量为纵坐标,作曲线。结果显示,经exendin-4、glp-1刺激后胞内的camp含量曲线呈典型的反“s”型,不同浓度的glp-1、exendin-4刺激glp-1r/hek293细胞产生的camp含量存在剂量效应相关性,并通过标准曲线可以测定未知样品刺激glp-1r/hek293细胞产生的camp的数量,以此camp的数量查标准曲线,从而可确定未知样品中glp-1及其功能类似物的生物活性。本发明的各重组融合蛋白的生物活性数据如表1所示。
二、重组融合蛋白的药代动力学研究
在第0天,称量所有受试鼠的体重,并作相应的记录。随后静脉注射1mg/kg(4ml/kg)的各重组融合蛋白。在注射后的20min,60min,6hr,24hr,48hr,3day,6,10,14,21和28天采集血样。为了获得血样,先将鼠用co2进行麻醉,用细玻璃在眼眶取血300ul。血液通过离心机离心,分离血清。将分离后的血清储存在–80℃冰箱内。血清中的重组融合蛋白使用elisa双抗体夹心法进行检测。上述检测过程按照已有的方法操作(bugelskipj等2008,jbiotechnol134:171-180),在鼠的血浆中使用羊抗人fc捕获/羊抗人fc检测和使用抗glp1类似物fab捕获/羊抗人fc检测融合蛋白的含量。使用非房室法通过血清浓度数据来估计重组融合蛋白的标准药代动力学参数。上述过程参照(bugelskipj等2008,jbiotechnol.134:171-180)方法进行。实验过程严格遵守实验动物伦理道德规范的要求进行操作。本发明的各重组融合蛋白的药代动力学数据如表1所示。
表1重组融合蛋白体外活性及药代动力学特点
由表1实验数据可知,本发明的glp-1类似物-fc融合蛋白增强glp1类似物的体外的活性,使其活性提高1倍。
本发明的glp-1类似物-fc融合蛋白有效增加了glp-1类似物的体内循环半衰期,使其体内循环半衰期延长了0.8倍。
实施例4重组融合蛋白的体内药效研究
本实施例研究各重组融合蛋白样品对ⅱ型糖尿病gk大鼠血糖水平的影响:ⅱ型糖尿病gk大鼠每组7只,随机分为礼来制药的度拉糖肽(dulaglutide)实验组、各融合蛋白实验组和生理盐水对照组,大鼠每次皮下注射量0.5ml;所有glp1融合蛋白样品每次剂量均为25ug/kg。三组给药前采血测血糖值,每天给药1次,持续给药3周,停药后第2天采血测血糖值。sd大鼠7只为正常对照组,皮下注射生理盐水,方法同实验组。
对ⅱ型糖尿病gk大鼠血糖的影响结果。ⅱ型糖尿病gk大鼠连续皮下注射glp1融合蛋白样品(25ug/kg)、度拉糖肽(25ug/kg)或生理盐水3周后,给药组大鼠血糖值均恢复到正常水平,且均明显低于生理盐水对照组(p<0.01),随后间隔2d给药1次,2周后发现glp1融合蛋白样品(25ug/kg)组能够明显降低ⅱ型糖尿病gk大鼠血糖值,空腹血糖值稳定的控制在正常范围内;而皮下注射25ug/kg度拉糖肽虽能够使血清葡萄糖水平降低,但明显不如各融合蛋白实验组(例如,glp1-hyfc和glp1-hyfcm组);当剂量为50ug/kg,l周给药2次,继续用药4周和停药3周后2次测定血糖水平,各融合蛋白实验组(例如,glp1-hyfc和glp1-hyfcm组)表明具有更好的血糖控制能力。
以上所述,仅为本发明的较佳实施例,并非对本发明任何形式上和实质上的限制,应当指出,对于本技术领域的普通技术人员,在不脱离本发明方法的前提下,还将可以做出若干改进和补充,这些改进和补充也应视为本发明的保护范围。凡熟悉本专业的技术人员,在不脱离本发明的精神和范围的情况下,当可利用以上所揭示的技术内容而做出的些许更动、修饰与演变的等同变化,均为本发明的等效实施例;同时,凡依据本发明的实质技术对上述实施例所作的任何等同变化的更动、修饰与演变,均仍属于本发明的技术方案的范围内。
序列表
<110>上海凯茂生物医药有限公司
<120>glp-1类似物-fc融合蛋白及其制备方法和用途
<130>194169
<160>28
<170>siposequencelisting1.0
<210>1
<211>31
<212>prt
<213>人工序列(artificialsequence)
<400>1
hisglygluglythrphethrseraspvalsersertyrleugluglu
151015
glnalaalalysglupheilealatrpleuvallysglyglygly
202530
<210>2
<211>10
<212>prt
<213>人工序列(artificialsequence)
<400>2
glyglyglyglyserglyglyglyglyser
1510
<210>3
<211>229
<212>prt
<213>人工序列(artificialsequence)
<400>3
gluserlystyrglyproprocysprosercysproalaprogluphe
151015
leuglyglyproservalpheleupheproprolysprolysaspthr
202530
leumetileserargthrprogluvalthrcysvalvalvalaspval
354045
serglngluaspprogluvalglnpheasntrptyrvalaspglyval
505560
gluvalhisasnalalysthrlysproargglugluglnpheasnser
65707580
thrtyrargvalvalargvalleuthrvalleuhisglnasptrpleu
859095
asnglylysglutyrlyscyslysvalserasnlysglyleuproser
100105110
serileglulysthrileserlysalalysglyglnproargglupro
115120125
glnvaltyrthrleuproproserglngluglumetthrlysasngln
130135140
valserleuthrcysleuvallysglyphetyrproseraspileala
145150155160
valglutrpgluserasnglyglnprogluaspasntyrlysthrthr
165170175
proprovalleuaspseraspglyserphepheleutyrserargleu
180185190
thrvalasplysserargtrpglngluglyasnvalphesercysser
195200205
valmethisglualaleuhisasnhistyrthrglnlysserleuser
210215220
leuserleuglylys
225
<210>4
<211>229
<212>prt
<213>人工序列(artificialsequence)
<400>4
gluserlystyrglyproprocysprosercysproalaprogluphe
151015
leuglyglyproservalpheleupheproprolysprolysaspthr
202530
leumetileserargthrprogluvalthrcysvalvalvalaspval
354045
serglngluaspprogluvalglnpheasntrptyrvalaspglyval
505560
gluvalhisasnalalysthrlysproargglugluglnpheasnser
65707580
thrtyrargvalvalargvalleuglnvalleuhisglnasptrpleu
859095
asnglylysglutyrlyscyslysvalserasnlysglyleuproser
100105110
serileglulysthrileserlysalalysglyglnproargglupro
115120125
glnvaltyrthrleuproproserglngluglumetthrlysasngln
130135140
valserleuthrcysleuvallysglyphetyrproseraspileala
145150155160
valglutrpgluserasnglyglnprogluaspasntyrlysthrthr
165170175
proprovalleuaspseraspglyserphepheleutyrserargleu
180185190
thrvalasplysserargtrpglngluglyasnvalphesercysser
195200205
valmethisglualaleuhisalahistyrthrglnlysserleuser
210215220
leuserleuglylys
225
<210>5
<211>229
<212>prt
<213>人工序列(artificialsequence)
<400>5
gluserlystyrglyproprocysprosercysproalaprogluphe
151015
leuglyglyproservalpheleupheproprolysprolysaspgln
202530
leumetileserargthrprogluvalthrcysvalvalvalaspval
354045
serglngluaspprogluvalglnpheasntrptyrvalaspglyval
505560
gluvalhisasnalalysthrlysproargglugluglnpheasnser
65707580
thrtyrargvalvalargvalleuglnvalleuhisglnasptrpleu
859095
asnglylysglutyrlyscyslysvalserasnlysglyleuproser
100105110
serileglulysthrileserlysalalysglyglnproargglupro
115120125
glnvaltyrthrleuproproserglngluglumetthrlysasngln
130135140
valserleuthrcysleuvallysglyphetyrproseraspileala
145150155160
valglutrpgluserasnglyglnprogluaspasntyrlysthrthr
165170175
proprovalleuaspseraspglyserphepheleutyrserargleu
180185190
thrvalasplysserargtrpglngluglyasnvalphesercysser
195200205
valleuhisglualaleuhisasnhistyrthrglnlysserleuser
210215220
leuserleuglylys
225
<210>6
<211>229
<212>prt
<213>人工序列(artificialsequence)
<400>6
gluserlystyrglyproprocysprosercysproalaprogluphe
151015
leuglyglyproservalpheleupheproprolysprolysaspthr
202530
leumetileserargthrprogluvalthrcysvalvalvalaspval
354045
serglngluaspprogluvalglnpheasntrptyrvalaspglyval
505560
gluvalhisasnalalysthrlysproargglugluglnpheasnser
65707580
thrtyrargvalvalargvalleuglnvalleuhisglnasptrpleu
859095
asnglylysglutyrlyscyslysvalserasnlysglyleuproser
100105110
serileglulysthrileserlysalalysglyglnproargglupro
115120125
glnvaltyrthrleuproproserglngluglumetthrlysasngln
130135140
valserleuthrcysleuvallysglyphetyrproseraspileala
145150155160
valglutrpgluserasnglyglnprogluaspasntyrlysthrthr
165170175
proprovalleuaspseraspglyserphepheleutyrserargleu
180185190
thrvalasplysserargtrpglngluglyasnvalphesercysser
195200205
valmethisglualaleuhisserhistyrthrglnlysserleuser
210215220
leuserleuglylys
225
<210>7
<211>245
<212>prt
<213>人工序列(artificialsequence)
<400>7
argasnthrglyargglyglygluglulyslyslysglulysglulys
151015
glugluglnglugluarggluthrlysthrproglucysproserhis
202530
thrglnproleuglyvalpheleupheproprolysprolysaspthr
354045
leumetileserargthrprogluvalthrcysvalvalvalaspval
505560
serglngluaspprogluvalglnpheasntrptyrvalaspglyval
65707580
gluvalhisasnalalysthrlysproargglugluglnpheasnser
859095
thrtyrargvalvalargvalleuthrvalleuhisglnasptrpleu
100105110
asnglylysglutyrlyscyslysvalserasnlysglyleuproser
115120125
serileglulysthrileserlysalalysglyglnproargglupro
130135140
glnvaltyrthrleuproproserglngluglumetthrlysasngln
145150155160
valserleuthrcysleuvallysglyphetyrproseraspileala
165170175
valglutrpgluserasnglyglnprogluaspasntyrlysthrthr
180185190
proprovalleuaspseraspglyserphepheleutyrserargleu
195200205
thrvalasplysserargtrpglngluglyasnvalphesercysser
210215220
valmethisglualaleuhisasnhistyrthrglnlysserleuser
225230235240
leuserleuglylys
245
<210>8
<211>245
<212>prt
<213>人工序列(artificialsequence)
<400>8
argasnthrglyargglyglygluglulyslyslysglulysglulys
151015
glugluglnglugluarggluthrlysthrproglucysproserhis
202530
thrglnproleuglyvalpheleupheproprolysprolysaspthr
354045
leumetileserargthrprogluvalthrcysvalvalvalaspval
505560
serglngluaspprogluvalglnpheasntrptyrvalaspglyval
65707580
gluvalhisasnalalysthrlysproargglugluglnpheasnser
859095
thrtyrargvalvalargvalleuglnvalleuhisglnasptrpleu
100105110
asnglylysglutyrlyscyslysvalserasnlysglyleuproser
115120125
serileglulysthrileserlysalalysglyglnproargglupro
130135140
glnvaltyrthrleuproproserglngluglumetthrlysasngln
145150155160
valserleuthrcysleuvallysglyphetyrproseraspileala
165170175
valglutrpgluserasnglyglnprogluaspasntyrlysthrthr
180185190
proprovalleuaspseraspglyserphepheleutyrserargleu
195200205
thrvalasplysserargtrpglngluglyasnvalphesercysser
210215220
valmethisglualaleuhisalahistyrthrglnlysserleuser
225230235240
leuserleuglylys
245
<210>9
<211>270
<212>prt
<213>人工序列(artificialsequence)
<400>9
hisglygluglythrphethrseraspvalsersertyrleugluglu
151015
glnalaalalysglupheilealatrpleuvallysglyglyglygly
202530
glyglyglyserglyglyglyglysergluserlystyrglypropro
354045
cysprosercysproalaproglupheleuglyglyproservalphe
505560
leupheproprolysprolysaspthrleumetileserargthrpro
65707580
gluvalthrcysvalvalvalaspvalserglngluaspprogluval
859095
glnpheasntrptyrvalaspglyvalgluvalhisasnalalysthr
100105110
lysproargglugluglnpheasnserthrtyrargvalvalargval
115120125
leuthrvalleuhisglnasptrpleuasnglylysglutyrlyscys
130135140
lysvalserasnlysglyleuproserserileglulysthrileser
145150155160
lysalalysglyglnproarggluproglnvaltyrthrleupropro
165170175
serglngluglumetthrlysasnglnvalserleuthrcysleuval
180185190
lysglyphetyrproseraspilealavalglutrpgluserasngly
195200205
glnprogluaspasntyrlysthrthrproprovalleuaspserasp
210215220
glyserphepheleutyrserargleuthrvalasplysserargtrp
225230235240
glngluglyasnvalphesercysservalmethisglualaleuhis
245250255
asnhistyrthrglnlysserleuserleuserleuglylys
260265270
<210>10
<211>270
<212>prt
<213>人工序列(artificialsequence)
<400>10
hisglygluglythrphethrseraspvalsersertyrleugluglu
151015
glnalaalalysglupheilealatrpleuvallysglyglyglygly
202530
glyglyglyserglyglyglyglysergluserlystyrglypropro
354045
cysprosercysproalaproglupheleuglyglyproservalphe
505560
leupheproprolysprolysaspthrleumetileserargthrpro
65707580
gluvalthrcysvalvalvalaspvalserglngluaspprogluval
859095
glnpheasntrptyrvalaspglyvalgluvalhisasnalalysthr
100105110
lysproargglugluglnpheasnserthrtyrargvalvalargval
115120125
leuglnvalleuhisglnasptrpleuasnglylysglutyrlyscys
130135140
lysvalserasnlysglyleuproserserileglulysthrileser
145150155160
lysalalysglyglnproarggluproglnvaltyrthrleupropro
165170175
serglngluglumetthrlysasnglnvalserleuthrcysleuval
180185190
lysglyphetyrproseraspilealavalglutrpgluserasngly
195200205
glnprogluaspasntyrlysthrthrproprovalleuaspserasp
210215220
glyserphepheleutyrserargleuthrvalasplysserargtrp
225230235240
glngluglyasnvalphesercysservalmethisglualaleuhis
245250255
alahistyrthrglnlysserleuserleuserleuglylys
260265270
<210>11
<211>270
<212>prt
<213>人工序列(artificialsequence)
<400>11
hisglygluglythrphethrseraspvalsersertyrleugluglu
151015
glnalaalalysglupheilealatrpleuvallysglyglyglygly
202530
glyglyglyserglyglyglyglysergluserlystyrglypropro
354045
cysprosercysproalaproglupheleuglyglyproservalphe
505560
leupheproprolysprolysaspthrleumetileserargthrpro
65707580
gluvalthrcysvalvalvalaspvalserglngluaspprogluval
859095
glnpheasntrptyrvalaspglyvalgluvalhisasnalalysthr
100105110
lysproargglugluglnpheasnserthrtyrargvalvalargval
115120125
leuglnvalleuhisglnasptrpleuasnglylysglutyrlyscys
130135140
lysvalserasnlysglyleuproserserileglulysthrileser
145150155160
lysalalysglyglnproarggluproglnvaltyrthrleupropro
165170175
serglngluglumetthrlysasnglnvalserleuthrcysleuval
180185190
lysglyphetyrproseraspilealavalglutrpgluserasngly
195200205
glnprogluaspasntyrlysthrthrproprovalleuaspserasp
210215220
glyserphepheleutyrserargleuthrvalasplysserargtrp
225230235240
glngluglyasnvalphesercysservalleuhisglualaleuhis
245250255
asnhistyrthrglnlysserleuserleuserleuglylys
260265270
<210>12
<211>270
<212>prt
<213>人工序列(artificialsequence)
<400>12
hisglygluglythrphethrseraspvalsersertyrleugluglu
151015
glnalaalalysglupheilealatrpleuvallysglyglyglygly
202530
glyglyglyserglyglyglyglysergluserlystyrglypropro
354045
cysprosercysproalaproglupheleuglyglyproservalphe
505560
leupheproprolysprolysaspthrleumetileserargthrpro
65707580
gluvalthrcysvalvalvalaspvalserglngluaspprogluval
859095
glnpheasntrptyrvalaspglyvalgluvalhisasnalalysthr
100105110
lysproargglugluglnpheasnserthrtyrargvalvalargval
115120125
leuthrvalleuhisglnasptrpleuasnglylysglutyrlyscys
130135140
lysvalserasnlysglyleuproserserileglulysthrileser
145150155160
lysalalysglyglnproarggluproglnvaltyrthrleupropro
165170175
serglngluglumetthrlysasnglnvalserleuthrcysleuval
180185190
lysglyphetyrproseraspilealavalglutrpgluserasngly
195200205
glnprogluaspasntyrlysthrthrproprovalleuaspserasp
210215220
glyserphepheleutyrserargleuthrvalasplysserargtrp
225230235240
glngluglyasnvalphesercysservalmethisglualaleuhis
245250255
serhistyrthrglnlysserleuserleuserleuglylys
260265270
<210>13
<211>276
<212>prt
<213>人工序列(artificialsequence)
<400>13
hisglygluglythrphethrseraspvalsersertyrleugluglu
151015
glnalaalalysglupheilealatrpleuvallysglyglyglyarg
202530
asnthrglyargglyglygluglulyslyslysglulysglulysglu
354045
gluglnglugluarggluthrlysthrproglucysproserhisthr
505560
glnproleuglyvalpheleupheproprolysprolysaspthrleu
65707580
metileserargthrprogluvalthrcysvalvalvalaspvalser
859095
glngluaspprogluvalglnpheasntrptyrvalaspglyvalglu
100105110
valhisasnalalysthrlysproargglugluglnpheasnserthr
115120125
tyrargvalvalargvalleuthrvalleuhisglnasptrpleuasn
130135140
glylysglutyrlyscyslysvalserasnlysglyleuproserser
145150155160
ileglulysthrileserlysalalysglyglnproarggluprogln
165170175
valtyrthrleuproproserglngluglumetthrlysasnglnval
180185190
serleuthrcysleuvallysglyphetyrproseraspilealaval
195200205
glutrpgluserasnglyglnprogluaspasntyrlysthrthrpro
210215220
provalleuaspseraspglyserphepheleutyrserargleuthr
225230235240
valasplysserargtrpglngluglyasnvalphesercysserval
245250255
methisglualaleuhisasnhistyrthrglnlysserleuserleu
260265270
serleuglylys
275
<210>14
<211>276
<212>prt
<213>人工序列(artificialsequence)
<400>14
hisglygluglythrphethrseraspvalsersertyrleugluglu
151015
glnalaalalysglupheilealatrpleuvallysglyglyglyarg
202530
asnthrglyargglyglygluglulyslyslysglulysglulysglu
354045
gluglnglugluarggluthrlysthrproglucysproserhisthr
505560
glnproleuglyvalpheleupheproprolysprolysaspthrleu
65707580
metileserargthrprogluvalthrcysvalvalvalaspvalser
859095
glngluaspprogluvalglnpheasntrptyrvalaspglyvalglu
100105110
valhisasnalalysthrlysproargglugluglnpheasnserthr
115120125
tyrargvalvalargvalleuglnvalleuhisglnasptrpleuasn
130135140
glylysglutyrlyscyslysvalserasnlysglyleuproserser
145150155160
ileglulysthrileserlysalalysglyglnproarggluprogln
165170175
valtyrthrleuproproserglngluglumetthrlysasnglnval
180185190
serleuthrcysleuvallysglyphetyrproseraspilealaval
195200205
glutrpgluserasnglyglnprogluaspasntyrlysthrthrpro
210215220
provalleuaspseraspglyserphepheleutyrserargleuthr
225230235240
valasplysserargtrpglngluglyasnvalphesercysserval
245250255
methisglualaleuhisalahistyrthrglnlysserleuserleu
260265270
serleuglylys
275
<210>15
<211>810
<212>dna
<213>人工序列(artificialsequence)
<400>15
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaag60
gagttcatcgcctggctggtgaagggcggcggcggtggtggtggctccggaggcggcggc120
tctgaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcgga180
ccctcagttttcttgtttccaccgaagcctaaagatactcttatgatttcgcgtaccccc240
gaagtcacatgtgtagtggttgacgtcagtcaagaggctccagaagtacagttcaattgg300
tacgtggacggggttgaggtccataacgccaagacgaaaccgcgcgaagagcaatttaat360
agcacttatcgagtagtgcgggttctcaccgtcctacaccaggattggctgaacggtaag420
gaatacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagacaatatcg480
aaagcaaagggacaacccagagaaccacaggtgtatacgttgccgcctagtcaagaggaa540
atgactaaaaaccaggttagccttacctgtctcgtcaaggggttctacccctctgacatt600
gcggtagagtgggaatccaatggtcaaccagaggataactataaaacaacgccgcctgtg660
ctagactcagatggctcgtttttcctgtacagtaggttaactgttgacaagagccgttgg720
caggaaggaaatgtcttttcttgctccgtaatgcatgaggctttgcacaaccattatacc780
caaaaatcactttcgctcagtctagggaag810
<210>16
<211>810
<212>dna
<213>人工序列(artificialsequence)
<400>16
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaag60
gagttcatcgcctggctggtgaagggcggcggcggtggtggtggctccggaggcggcggc120
tctgaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcgga180
ccctcagttttcttgtttccaccgaagcctaaagatactcttatgatttcgcgtaccccc240
gaagtcacatgtgtagtggttgacgtcagtcaagaggctccagaagtacagttcaattgg300
tacgtggacggggttgaggtccataacgccaagacgaaaccgcgcgaagagcaatttaat360
agcacttatcgagtagtgcgggttctccaggtcctacaccaagattggctgaacggtaag420
gaatacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagaccatatcg480
aaagcaaagggacagcccagagaaccacaagtgtatacattgccgcctagtcaggaggaa540
atgacgaaaaaccaagttagccttacttgtctcgtcaaggggttctacccctctgacatt600
gcggtagagtgggaatccaatggtcagccagaggataactataaaaccacaccgcctgtg660
ctagactcagatggctcgtttttcctgtacagtaggttaacggttgacaagagccgttgg720
caagaaggaaatgtcttttcttgctccgtaatgcatgaggctttgcacgcccattatact780
cagaaatcactttcgctcagtctagggaag810
<210>17
<211>810
<212>dna
<213>人工序列(artificialsequence)
<400>17
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaag60
gagttcatcgcctggctggtgaagggcggcggcggtggtggtggctccggaggcggcggc120
tctgaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcgga180
ccctcagttttcttgtttccaccgaagcctaaagatcaacttatgatttcgcgtactccc240
gaagtcacctgtgtagtggttgacgtcagtcaggaggctccagaagtacaattcaattgg300
tacgtggacggggttgaggtccataacgccaagacaaaaccgcgcgaagagcagtttaat360
agcacgtatcgagtagtgcgggttctccaagtcctacaccaggattggctgaacggtaag420
gaatacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagactatatcg480
aaagcaaagggacaacccagagaaccacaggtgtataccttgccgcctagtcaagaggaa540
atgacaaaaaaccaggttagccttacgtgtctcgtcaaggggttctacccctctgacatt600
gcggtagagtgggaatccaatggtcaaccagaggataactataaaactaccccgcctgtg660
ctagactcagatggctcgtttttcctgtacagtaggttaacagttgacaagagccgttgg720
caggaaggaaatgtcttttcttgctccgtattgcatgaggctcttcacaaccattatacg780
caaaaatcactctcgctaagtctggggaag810
<210>18
<211>810
<212>dna
<213>人工序列(artificialsequence)
<400>18
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaag60
gagttcatcgcctggctggtgaagggcggcggcggtggtggtggctccggaggcggcggc120
tctgaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcgga180
ccctcagttttcttgtttccaccgaagcctaaagatactcttatgatttcgcgtaccccc240
gaagtcacatgtgtagtggttgacgtcagtcaagaggctccagaagtacagttcaattgg300
tacgtggacggggttgaggtccataacgccaagacgaaaccgcgcgaagagcaatttaat360
agcacttatcgagtagtgcgggttctccaggtcctacaccaagattggctgaacggtaag420
gaatacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagaccatatcg480
aaagcaaagggacagcccagagaaccacaagtgtatacattgccgcctagtcaggaggaa540
atgacgaaaaaccaagttagccttacttgtctcgtcaaggggttctacccctctgacatt600
gcggtagagtgggaatccaatggtcagccagaggataactataaaaccacaccgcctgtg660
ctagactcagatggctcgtttttcctgtacagtaggttaacggttgacaagagccgttgg720
caagaaggaaatgtcttttcttgctccgtaatgcatgaggctttgcactcacattatact780
cagaaatcgcttagtctcagcctagggaag810
<210>19
<211>828
<212>dna
<213>人工序列(artificialsequence)
<400>19
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaag60
gagttcatcgcctggctggtgaagggcggcggccgtaatactggtcgcggcggagaagag120
aaaaagaaagaaaaggagaaagaagagcaagaagagcgagaaaccaagacacctgagtgt180
ccctctcatacgcagccattaggggtttttttgttcccgcctaaacccaaggatactctt240
atgatttcccggaccccagaagtcacatgcgtagtggttgacgtctcacaagaggctccg300
gaagtacagtttaactggtatgtggacggtgttgaggtccacaatgctaaaacgaagcct360
agagaagagcaattcaactcgacttacagggtagtgcgtgttctcaccgtcctacatcag420
gattggctgaatggcaaagaatataagtgtaaagtaagtaacaagggattacccagctct480
atcgagaaaacaatatccaaggccaaagggcaaccacgcgaaccgcaggtgtacacgttg540
cctccctcacaagaggaaatgactaagaatcaggtttcgcttacctgcctcgtcaaaggt600
ttttatccaagtgacattgcagtagagtgggaaagcaacggccaaccggaggataattac660
aagacaacgcctcccgtgctagactctgatggctccttctttctgtattcacgattaact720
gttgacaaatcgcggtggcaggaagggaacgtcttcagttgtagcgtaatgcacgaggcg780
ttgcataatcactacacccaaaagtctctttccctctcactaggtaaa828
<210>20
<211>828
<212>dna
<213>人工序列(artificialsequence)
<400>20
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaag60
gagttcatcgcctggctggtgaagggcggcggccgtaatactggtcgcggcggagaagag120
aaaaagaaagaaaaggagaaagaagagcaagaagagcgagaaaccaagacacctgagtgt180
ccctctcatacgcagccattaggggtttttttgttcccgcctaaacccaaggatactctt240
atgatttcccggaccccagaagtcacatgcgtagtggttgacgtctcacaagaggctccg300
gaagtacagtttaactggtatgtggacggtgttgaggtccacaatgctaaaacgaagcct360
agagaagagcaattcaactcgacttacagggtagtgcgtgttctccaggtcctacatcaa420
gattggctgaatggcaaagaatataagtgtaaagtaagtaacaagggattacccagctct480
atcgagaaaaccatatccaaggccaaagggcagccacgcgaaccgcaagtgtacacattg540
cctccctcacaggaggaaatgacgaagaatcaagtttcgcttacttgcctcgtcaaaggt600
ttttatccaagtgacattgcagtagagtgggaaagcaacggccagccggaggataattac660
aagaccacacctcccgtgctagactctgatggctccttctttctgtattcacgattaacg720
gttgacaaatcgcggtggcaagaagggaacgtcttcagttgtagcgtaatgcacgaggcg780
ttgcatgctcactacactcagaagtctctttccctctcactaggtaaa828
<210>21
<211>93
<212>dna
<213>人工序列(artificialsequence)
<400>21
catggcgagggcaccttcacctccgacgtgtcctcctatctggaggagcaggccgccaag60
gagttcatcgcctggctggtgaagggcggcggc93
<210>22
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>22
ggtggtggtggctccggaggcggcggctct30
<210>23
<211>687
<212>dna
<213>人工序列(artificialsequence)
<400>23
gaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcggaccc60
tcagttttcttgtttccaccgaagcctaaagatactcttatgatttcgcgtacccccgaa120
gtcacatgtgtagtggttgacgtcagtcaagaggctccagaagtacagttcaattggtac180
gtggacggggttgaggtccataacgccaagacgaaaccgcgcgaagagcaatttaatagc240
acttatcgagtagtgcgggttctcaccgtcctacaccaggattggctgaacggtaaggaa300
tacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagacaatatcgaaa360
gcaaagggacaacccagagaaccacaggtgtatacgttgccgcctagtcaagaggaaatg420
actaaaaaccaggttagccttacctgtctcgtcaaggggttctacccctctgacattgcg480
gtagagtgggaatccaatggtcaaccagaggataactataaaacaacgccgcctgtgcta540
gactcagatggctcgtttttcctgtacagtaggttaactgttgacaagagccgttggcag600
gaaggaaatgtcttttcttgctccgtaatgcatgaggctttgcacaaccattatacccaa660
aaatcactttcgctcagtctagggaag687
<210>24
<211>687
<212>dna
<213>人工序列(artificialsequence)
<400>24
gaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcggaccc60
tcagttttcttgtttccaccgaagcctaaagatactcttatgatttcgcgtacccccgaa120
gtcacatgtgtagtggttgacgtcagtcaagaggctccagaagtacagttcaattggtac180
gtggacggggttgaggtccataacgccaagacgaaaccgcgcgaagagcaatttaatagc240
acttatcgagtagtgcgggttctccaggtcctacaccaagattggctgaacggtaaggaa300
tacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagaccatatcgaaa360
gcaaagggacagcccagagaaccacaagtgtatacattgccgcctagtcaggaggaaatg420
acgaaaaaccaagttagccttacttgtctcgtcaaggggttctacccctctgacattgcg480
gtagagtgggaatccaatggtcagccagaggataactataaaaccacaccgcctgtgcta540
gactcagatggctcgtttttcctgtacagtaggttaacggttgacaagagccgttggcaa600
gaaggaaatgtcttttcttgctccgtaatgcatgaggctttgcacgcccattatactcag660
aaatcactttcgctcagtctagggaag687
<210>25
<211>687
<212>dna
<213>人工序列(artificialsequence)
<400>25
gaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcggaccc60
tcagttttcttgtttccaccgaagcctaaagatcaacttatgatttcgcgtactcccgaa120
gtcacctgtgtagtggttgacgtcagtcaggaggctccagaagtacaattcaattggtac180
gtggacggggttgaggtccataacgccaagacaaaaccgcgcgaagagcagtttaatagc240
acgtatcgagtagtgcgggttctccaagtcctacaccaggattggctgaacggtaaggaa300
tacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagactatatcgaaa360
gcaaagggacaacccagagaaccacaggtgtataccttgccgcctagtcaagaggaaatg420
acaaaaaaccaggttagccttacgtgtctcgtcaaggggttctacccctctgacattgcg480
gtagagtgggaatccaatggtcaaccagaggataactataaaactaccccgcctgtgcta540
gactcagatggctcgtttttcctgtacagtaggttaacagttgacaagagccgttggcag600
gaaggaaatgtcttttcttgctccgtattgcatgaggctcttcacaaccattatacgcaa660
aaatcactctcgctaagtctggggaag687
<210>26
<211>687
<212>dna
<213>人工序列(artificialsequence)
<400>26
gaatctaaatatggtcctccctgtccatcctgcccggctcctgagtttttaggcggaccc60
tcagttttcttgtttccaccgaagcctaaagatactcttatgatttcgcgtacccccgaa120
gtcacatgtgtagtggttgacgtcagtcaagaggctccagaagtacagttcaattggtac180
gtggacggggttgaggtccataacgccaagacgaaaccgcgcgaagagcaatttaatagc240
acttatcgagtagtgcgggttctccaggtcctacaccaagattggctgaacggtaaggaa300
tacaaatgcaaggtatctaataaaggcttaccttcctcaatcgagaagaccatatcgaaa360
gcaaagggacagcccagagaaccacaagtgtatacattgccgcctagtcaggaggaaatg420
acgaaaaaccaagttagccttacttgtctcgtcaaggggttctacccctctgacattgcg480
gtagagtgggaatccaatggtcagccagaggataactataaaaccacaccgcctgtgcta540
gactcagatggctcgtttttcctgtacagtaggttaacggttgacaagagccgttggcaa600
gaaggaaatgtcttttcttgctccgtaatgcatgaggctttgcactcacattatactcag660
aaatcgcttagtctcagcctagggaag687
<210>27
<211>735
<212>dna
<213>人工序列(artificialsequence)
<400>27
cgtaatactggtcgcggcggagaagagaaaaagaaagaaaaggagaaagaagagcaagaa60
gagcgagaaaccaagacacctgagtgtccctctcatacgcagccattaggggtttttttg120
ttcccgcctaaacccaaggatactcttatgatttcccggaccccagaagtcacatgcgta180
gtggttgacgtctcacaagaggctccggaagtacagtttaactggtatgtggacggtgtt240
gaggtccacaatgctaaaacgaagcctagagaagagcaattcaactcgacttacagggta300
gtgcgtgttctcaccgtcctacatcaggattggctgaatggcaaagaatataagtgtaaa360
gtaagtaacaagggattacccagctctatcgagaaaacaatatccaaggccaaagggcaa420
ccacgcgaaccgcaggtgtacacgttgcctccctcacaagaggaaatgactaagaatcag480
gtttcgcttacctgcctcgtcaaaggtttttatccaagtgacattgcagtagagtgggaa540
agcaacggccaaccggaggataattacaagacaacgcctcccgtgctagactctgatggc600
tccttctttctgtattcacgattaactgttgacaaatcgcggtggcaggaagggaacgtc660
ttcagttgtagcgtaatgcacgaggcgttgcataatcactacacccaaaagtctctttcc720
ctctcactaggtaaa735
<210>28
<211>735
<212>dna
<213>人工序列(artificialsequence)
<400>28
cgtaatactggtcgcggcggagaagagaaaaagaaagaaaaggagaaagaagagcaagaa60
gagcgagaaaccaagacacctgagtgtccctctcatacgcagccattaggggtttttttg120
ttcccgcctaaacccaaggatactcttatgatttcccggaccccagaagtcacatgcgta180
gtggttgacgtctcacaagaggctccggaagtacagtttaactggtatgtggacggtgtt240
gaggtccacaatgctaaaacgaagcctagagaagagcaattcaactcgacttacagggta300
gtgcgtgttctccaggtcctacatcaagattggctgaatggcaaagaatataagtgtaaa360
gtaagtaacaagggattacccagctctatcgagaaaaccatatccaaggccaaagggcag420
ccacgcgaaccgcaagtgtacacattgcctccctcacaggaggaaatgacgaagaatcaa480
gtttcgcttacttgcctcgtcaaaggtttttatccaagtgacattgcagtagagtgggaa540
agcaacggccagccggaggataattacaagaccacacctcccgtgctagactctgatggc600
tccttctttctgtattcacgattaacggttgacaaatcgcggtggcaagaagggaacgtc660
ttcagttgtagcgtaatgcacgaggcgttgcatgctcactacactcagaagtctctttcc720
ctctcactaggtaaa735
- 还没有人留言评论。精彩留言会获得点赞!