飞灰含碳量的测量方法及装置与流程
本发明涉及热工控制领域,具体地,涉及一种飞灰含碳量的测量方法及装置。
背景技术:
在燃煤电厂的实际生产过程中,由于技术或经济上的原因,许多重要技术参数和经济参数无法用常规的传感器直接测量,严重影响燃煤电厂经济运行。飞灰含碳量是火力发电厂燃煤锅炉燃烧效率的一个重要指标,它反映了燃煤机械未完全燃烧损失的大小。目前,飞灰含碳量在线检测方法有灼烧失重法和微波检测法。
灼烧法失重法测量技术是中国电力工业标准《飞灰和炉渣可然物测定方法》及《煤的工业分析方法》中的相关方法,当含有未燃尽碳的灰样在规定的高温下经灼烧后,由于灰样中残留的碳被燃尽后使灰样的质量出现了损失,利用灰样的烧失量作为依据计算出灰样中的含碳量,
含碳量的质量(%)=[灼烧前灰样加坩埚的质量(g)—灼烧后灰样加坩埚的质量(g)]/[灼烧前灰样加坩埚的质量(g)—收灰前坩埚的质量(g)]。
图1示出了采用灼烧失重法测量飞灰含碳量的装置结构框图。如图1所示,灼烧失重法的主要工作流程是将烟道中的灰样通过振动器和取样器收集到测量单元的坩埚中,由升降机构将坩埚放置于旋转托盘,再由测量单元内部的执行机构将装有灰样的坩埚送入灼烧装置(如,电炉加热器)进行高温灼烧,电子天平实时测量收灰前、收灰后及灼烧后的重量信号,控制单元对接收到的重量信号进行计算,获得飞灰的含碳量并在控制单元的显示屏上进行显示,其中可以使用手动控制盒控制控制单元进行计算或显示。灼烧后的灰样通过系统的排灰机构和真空发生器排放回烟道中。
然而灼烧失重法在现场应用中存在下列一些问题:
(1)取样问题。装置取样速度慢,所以取样时间长,灰样冷却较快,容易堵灰。
(2)微波炉加热问题。首先不能达到实验室加热温度(电力工业标准《飞灰和炉渣可然物测定方法》中提出应在810±10℃下进行灼烧,慢灰要1小时,快灰要30分钟),灼烧温度、时间不能达到要求,并且由于微波加热特性和坩埚盛灰的最低要求制约使得灰样厚度超出范围,因而只能对坩埚内的灰样外表面完全灼烧,而内部为原灰样。其次,不能按规程先烘干水分(因受烟道中温差变化因素,飞灰有时会出现结露现象),在灼烧测挥发量,所以失重变化数据中有水分变化因素。
(3)称重问题。电子天平安装在现场测量柜中进行实时称重,锅炉运行导致电子天平一直振动,无法保证正常测量精度。
(4)机械问题。此类装置一般有非常复杂的机械装置和电机、齿冷等转动部件,使用中经常出现坩埚破碎、机械故障、电机故障及坩埚工位错误等各种机械故障,由于设备故障会涉及到复杂的机械装置、电气电子装置、气路、灰路系统,即使有专人维护,也难以解决错综复杂的问题。
(5)时间滞后问题。装置取样速度慢,并需要机械运转、称重、灼烧,使得检测周期时间长。
所以,灼烧失重法的在线检测装置在现场使用中具有检测滞后时间长、灰样不能烧透、称重不准确、堵灰、机械故障率高的缺陷,维护要求高、难维护。
微波检测法的原理为:因为飞灰可燃物主要成份是碳及碳的介电常数,微波测试单元可利用固定频率发射能量衡定的微波信号,飞灰中可燃物的含量越高,吸收微波能量的作用就越强。
微波检测法的系统可采用无动力飞灰取样器,自动将烟道中的灰样收集到微波测试装置的测量管中,由灰位控制器自动判别收集灰位的高度。当收集到足够的灰样时,系统对飞灰含碳量进行微波谐振测量。控制装置打开电磁阀接入压缩空气吹扫已分析完的灰样,根据程序设定或手动设置,飞灰可以自动经采样管道吹回烟道或者送入收灰容器,以便于化学分析化验。
由于不同物质的频率特性不同、飞灰中物质组成复杂,且煤种变化时主要是矿物质变化使得微波检测法在煤种变化时不能检测飞灰含碳量变化。
技术实现要素:
本发明实施例的目的是提供一种飞灰含碳量的测量方法及装置,用于实现飞灰含碳量的在线测量,提高机组运行的安全性和经济性。
为了实现上述目的,本发明实施例提供一种飞灰含碳量的测量方法,该方法包括:对飞灰含碳量的历史数据值所对应的辅助变量的历史值进行相空间重构以确定所述辅助变量所对应的相点;接收所述辅助变量的当前值;以及根据所述飞灰含碳量的历史数据值、所述辅助变量所对应的相点、所述辅助变量的当前值以及飞灰含碳量的预测模型来计算所述飞灰含碳量的当前值。
可选地,所述方法还包括:获取所述飞灰含碳量的历史数据值所对应的所述辅助变量中的主要辅助变量。
可选地,利用核主元分析方法来获取所述主要辅助变量。
可选地,利用C-C方法来执行所述相空间重构。
可选地,所述辅助变量包括:每一给煤机的给煤量、烟气含氧量、排烟温度、主蒸汽压力、主蒸汽流量、主蒸汽温度、总风量、省煤器入口流量值、省煤器入口压力、省煤器出口压力、发电负荷、煤质特性、一次风总压力、二次风门开度、燃尽风门开度、二次风总压与炉膛差压、空气预热器出口温度以及燃烧器摆角。
相应地,本发明实施例还提供一种飞灰含碳量的测量装置,该装置包括:相空间重构模块,用于对飞灰含碳量的历史数据值所对应的辅助变量的历史值进行相空间重构以确定所述辅助变量所对应的相点;接收模块,用于接收所述辅助变量的当前值;以及计算模块,用于根据所述飞灰含碳量的历史数据值、所述辅助变量所对应的相点、所述辅助变量的当前值以及飞灰含碳量的预测模型来计算所述飞灰含碳量的当前值。
可选地,所述装置还包括:获取模块,用于取所述飞灰含碳量的历史数据值所对应的所述辅助变量中的主要辅助变量。
可选地,所述获取模块利用核主元分析方法来获取所述主要辅助变量。
可选地,所述相空间重构模块利用C-C方法来执行所述相空间重构。
可选地,所述辅助变量包括:每一给煤机的给煤量、烟气含氧量、排烟温度、主蒸汽压力、主蒸汽流量、主蒸汽温度、总风量、省煤器入口流量值、省煤器入口压力、省煤器出口压力、发电负荷、煤质特性、一次风总压力、二次风门开度、燃尽风门开度、二次风总压与炉膛差压、空气预热器出口温度以及燃烧器摆角。
通过上述技术方案,根据飞灰含碳量的历史数据值、辅助变量所对应的相点、辅助变量的当前值以及飞灰含碳量的预测模型来计算飞灰含碳量的当前值,相比于现有技术,该方案简单易行且无需复杂的装置,并且能够提高机组运行的安全性和经济性。
本发明的其它特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但并不构成对本发明的限制。在附图中:
图1示出了采用灼烧失重法测量飞灰含碳量的装置结构框图;
图2示出了一实施例中飞灰含碳量的测量方法的流程图;
图3示出了另一实施例中飞灰含碳量的测量原理图;
图4示出了一实施例中飞灰含碳量的测量装置的结构框图。
附图标记说明
10 相空间重构模块 20 接收模块
30 计算模块
具体实施方式
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
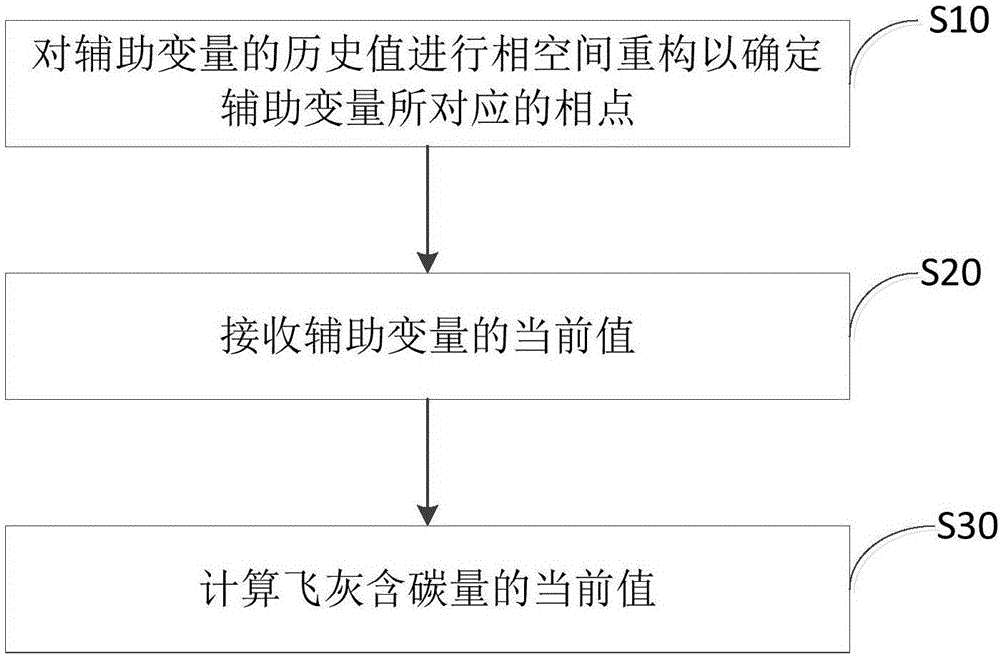
图2示出了一实施例中飞灰含碳量的测量方法的流程图。如图2所示,本发明实施例提供一种飞灰含碳量的测量方法,该方法可以包括步骤S10-步骤S30:
步骤S10,对飞灰含碳量的历史数据值所对应的辅助变量的历史值进行相空间重构以确定所述辅助变量所对应的相点。
其中,飞灰含碳量与现场工况的多个变量之间存在关系,为了反映提取飞灰含碳量的多方面信息,这里可以选取与飞灰含碳量相关性大的辅助变量。该辅助变量可以包括:每一给煤机的给煤量(假设有五个给煤机,则应当包括给煤机A给煤量、给煤机B给煤量、给煤机C给煤量、给煤机D给煤量、给煤机E给煤量)、烟气含氧量、排烟温度、主蒸汽压力、主蒸汽流量、主蒸汽温度、总风量、省煤器入口流量值、省煤器入口压力、省煤器出口压力、发电负荷、煤质特性、一次风总压力、二次风门开度、燃尽风门开度、二次风总压与炉膛差压、空气预热器出口温度、燃烧器摆角等。
可以针对上述例举的每一辅助变量来确定该每一辅助变量所对应的相点,可选地,可以使用C-C方法来执行所述相空间重构。C-C方法的具有以下优点:容易操作,计算量小,对小数据组可靠,效果和互信息方法一致,具有较强的抗噪声能力(30%以下)。尽管C-C方法是利用统计结果得到的。没有雄厚的理论基础,但它仍在实际计算中工作得很好,表现出它独特的优点。
C-C方法既能有效减少互信息法的计算量,又能保持时间序列非线性特征,其核心思想是应用关联积分同时估计出延迟时间τ和时间窗口Γ,τ确保各辅助变量相互依赖,但却不依赖于m;时间窗口Γ依赖于m,且τ随m而变化。其中,Γ是数据依赖的最大时间,是一种比τ估计维数的更好的量。C-C方法利用重构吸引子几何上的重复性和不相关性来评价重构吸引子的质量,其具有较强的相关性和较低的重复性。
以上述辅助变量中的第i个辅助变量xi为例,在使用C-C方法的重构相空间中该xi的相点Xi可以表示为:
Xi=[xi(0),xi(τ),…,xi((m-1)τ)] (1)
嵌入时间序列的关联积分可以定义为以下函数:
其中:m表示嵌入维且m≥2,N表示数据组的大小,M=N-(m-1)τ,r表示定义的相点半径,k为自然数,
dij=||Xi-Xj|| (3)
因此,关联维可以定义为:
其中:
这里,关联维可以用一个线性区域的斜率来近似代替,即
对于长度为N的时间序列{xi}(i=1,2,...N),将其分成k个子时间序列。对于一般的自然数k,N=kl,l=N/k是长度。将时间序列分成k个不相交的子序列,定义每个子序列S(m,N,r,k)为:
其中
令N→∞,则公式(7)可以变换为:
若时间序列是独立同分布的,那么对于固定的m、k,当N→∞时,对于所有的r均有S(m,r,k)恒等于零。但实际序列是有限的,并且序列元素间可能相关,实际得到的S(m,r,k)一般不等于零。选择对应值最大和最小的两个半径r,定义差量为:
ΔS(m,k)=max{S(m,rj,k)}-min{S(m,rj,k)} (9)
公式(19)表示出了半径r的最大偏差。
可选地,采用BDS统计可以得到N、m和r的恰当估计。当2≤m≤5,σ/2≤r≤2σ,N≥500时,渐进分布可以通过有限序列很好的近似,并且S(m,n,r,1)能代表序列的相关性。σ指时间序列的均方差或标准差。在重构时间序列时一般取N=3000。
时间变量k可以选取小于等于200的自然数,Δt为采样时间,延迟时间τ的值及时间窗口Γ分别为:
①针对ΔS(m,k),0≤k≤200,ΔS'(k)的第一个极小值t对应τ=kΔt。
②针对ΔS'(k),0≤k≤200,ΔS'(k)的第一个极小值t对应τ=kΔt。针对S'(k),0≤k≤200,S'(k)的第一个极小值t对应τ=kΔt。
③针对Scor(k),0≤k≤200,最小值k对应时间窗口Γ=kΔt。
最佳的维数m和延迟时间τ最佳配比满足,Γ=(m+1)τ/3,可以用此式验证C-C方法的有效性。
通过上述公式(1)至公式(13)以及辅助变量的历史数据值即可计算出每一辅助变量的对应相点。
步骤S20,接收所述辅助变量的当前值。每一辅助变量的当前值可以从当前工况中测得。
步骤S30,根据所述飞灰含碳量的历史数据值、所述辅助变量所对应的相点、所述辅助变量的当前值以及飞灰含碳量的预测模型来计算所述飞灰含碳量的当前值。
其中,可以利用非参数回归模型来建立所述预测模型。非参数回归模型具有这样的特点:回归函数的形式可以任意,没有任何约束,解释变量和被解释变量也很少限制,因而有较大的适应性,非参数规划模型较经典假设模型有更好的拟合效果。下文将对所述预测模型的建立过程进行详细描述。
a、非参数模型的估计
这里首先对非参数模型的估计进行讨论,设Y为解释变量,X=(X1,…Xd)为解释变量向量,是影响Y的d个因素。给定样本观测值(Y1,X1),(Y2,X2),…,(Yn,Xn),假定(Yi,Xi)独立同分布,建立非参数回归模型:
Yi=m(Xi)+σ(Xi)εi,i=1,…,n (14)
其中m(Xi)是未知的函数,m(Xi)=E(Yi|Xi),εi是均值为零、方差为1且与Xi独立的序列,随机误差项ui=σ(Xi)εi,其条件方差为
则非参数模型的核估计表达式为
其中窗宽hn>0,核权函数核函数K(u)>0,x为输入变量。
容易推得
所以核估计可以等价于局部加权最小二乘估计。
b、核估计的参数选择
核估计的核心问题就是核权函数和窗宽的选择。核权函数在核估计中起光滑的作用,即消除扰动的随机因素。窗宽是控制核估计精度的重要参数,最佳的窗宽既不宜过小也不宜过大。
①核函数的选择
选择核权函数的关键是选择核函数,在核函数确定后,核权函数也被确定。
可选地,在这类核函数中,最优的核函数是
其中,d表示影响元素的总个数,xi表示第i个影响元素
可选地,在这类核函数中,最优的核函数为:
其中,d表示影响元素的总个数,xi表示第i个影响元素,Sd=2πd/2/Γ(d/2)。
②窗宽的选择
可选地可以采用交错鉴定选择方法来对窗宽进行选择。其基本思路是:在每个局部观察点x=Xi,首先在样本中剔除观测点(Xi,Yi),其次将剩下的n-1个观察点在x=Xi处进行核估计
最后,通过比较平均拟合误差
的大小,选择使平方拟合误差达到最小的窗宽hn。在公式(20)中,w(x)≥0为一权值,该方法的关键是在样本中剔除观测点(Xi,Yi),如果不这样的话,由于核权函数Wni(x)在观察点x=Xi处达到最大值,就会使得x=Xi的重要程度过大夸大而其他观察点数据的重要程度降低,所以采用交错鉴定方法就避免了因没剔除观察点(Xi,Yi)而将有用的数据排除到外的情况。
c、飞灰含碳量的预测模型
根据公式(14)至公式(20)可知,基于非参数估计模型的飞灰含碳量的预测模型可以表示为:
其中表示飞灰含碳量的预测值,x=(x1,…xd)表示当前工况的d个辅助变量的值,X=(X1,…Xd)为历史工况的d个辅助变量所对应的相点,Xi表示第i组辅助变量中的d个辅助变量所对应的相点,Xj表示第j组辅助变量中的d个辅助变量所对应的相点,Yi表示每一组辅助变量所分别对应的飞灰含碳量的历史数值,由公式(16)至公式(20)可获得核权函数的值,进而可以在线测得预测值
在一可选实施例中,在执行步骤S10之前,可以首先获取上述辅助变量中的主要辅助变量,即,获取工况中影响飞灰含碳量的主要因素,然后利用该获得的主要辅助变量执行步骤S10至步骤S30。优选地,可以采用核主元分析方法来获得所述主要辅助变量。
核主元分析是一种新的非线性特征提取方法,它通过某种事先选择的非线性映射将输入矢量映射到一个高维特征空间,使输入矢量具有更好的可分性,然后对高维空间中的映射数据做线性主元分析,而得到数据的非线性主元,下面将详细介绍核主元分析方法的执行过程。
考虑n维m个变量对变量X进行标准化处理得到X=(x1,x2,…,xm)T:
其中,为X*的均值,为的方差。用非线性映射ψ(.)把输入数据从原空间映射到高维特征空间有然后在这个高维特征空间进行线性主元分析。高维特征空间中映射数据的协方差为:
求解特征值
λV=CV (24)
其中,特征值λ>0,特征向量V∈ψ(.)。式两边左乘可得
由于特征值λ≠0所对应的特征向量V是由高维特征空间的向量组成,所以存在
其中ai为系数。由式(24)-(26)可得:
定义m×m矩阵K:
则式(27)简化为:
mλKa=K2a (28)
求解式(28),只需求解下式即可
mλa=Ka,a=(a1,…,am)T (29)
特征值λk和相应的特征向量ak(k=1,…,l)可由上式求得,可以采用保留前p个特征向量的方法使系统降维。
影响飞灰含碳量的主要辅助变量yk可通过映射到特征空间的特征向量V得到,即
图3示出了另一实施例中飞灰含碳量的测量原理图。如图3所示,首先获得飞灰含碳量的历史数据,该历史数据中可以包括飞灰含碳量的历史值,及每一历史值所对应的辅助变量的值。然后采用核主元分析方法,得到影响飞灰含碳量的主要辅助变量,采用C-C方法对每个主要辅助变量的变化量进行相空间的重构,将每个主要辅助变量变化量的相点以及当前时刻主要辅助变量的测量值作为预测模型的输入,从而可以在线获得当前工况下飞灰含碳量的预测值。优选地,可以将离线人工测得的当前时刻的飞灰含碳量与所计算的飞灰含碳量的预测值进行比较,根据比较结果对预测模型的参数进行修正。
图4示出了一实施例中飞灰含碳量的测量装置的结构框图。如图4所示,本发明实施例还提供一种飞灰含碳量的测量装置,该装置可以包括:相空间重构模块10,用于对飞灰含碳量的历史数据值所对应的辅助变量的历史值进行相空间重构以确定所述辅助变量所对应的相点;接收模块20,用于接收所述辅助变量的当前值;以及计算模块30,用于根据所述飞灰含碳量的历史数据值、所述辅助变量所对应的相点、所述辅助变量的当前值以及飞灰含碳量的预测模型来计算所述飞灰含碳量的当前值。通过利用历史数据值以及当前工况下辅助变量的值来实现变工况条件下的飞灰含碳量的在线测量,其原理简单、可靠、实用性强、没有大量的计算并且可以连续给出飞灰含碳量读数,方便现场工作人员实时了解当前工况。
本发明实施例提供的飞灰含碳量的测量装置的具体工作原理与上述飞灰含碳量的测量方法的具体工作原理类似,这里将不再赘述。
以上结合附图详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!