分布式块存储的IO请求的处理方法和装置与流程
本发明涉及分布式块存储领域,尤其涉及一种分布式块存储的IO请求的处理方法和装置。
背景技术:
在并发程序设计中,如何进行共享资源的同步访问是个关键的设计问题,影响到最终系统的架构、可靠性和性能。在高性能网络服务器中,有各种同步机制,如信号量、读写锁、自旋锁,但是都严重地影响到程序的并发处理能力。因为都可以处理并发IO操作,但是当并发触发锁时,存在IO在排队但是CPU资源没有发挥到最大的情况,导致资源浪费、性能不优。
例如,在并发IO发起时候,先做同步机制,如卷锁,让每个IO做排队。然后,顺序每一个IO来随机选择CPU核来处理,待CPU核处理完毕,释放下一个IO的锁来处理下一个IO。这样,在上一个IO处理完,下一个IO释放锁之前的间隔,CPU核就存在空闲情况。因此,存在资源浪费,CPU核不能发挥最大处理能力,导致性能不优。
技术实现要素:
本发明的实施例提供了一种分布式块存储的IO请求的处理方法和装置,能够提高系统处理效率。
为了实现上述目的,本发明采取了如下技术方案。
一种分布式块存储的IO请求的处理方法,包括:
接收到客户端的IO请求;所述IO请求携带待访问的数据卷以及对所述数据卷的操作指令;
获取所述数据卷所在的至少两个节点;
在所述至少两个节点中,选择一个节点,作为卷控制器节点;
获取所述卷控制器节点对应的至少两个可用CPU;
在所述至少两个可用CPU中,选择一个CPU;
将所述IO请求发送给选择的所述CPU,使得所述IO请求加入到选择的所述CPU的任务队列中,等待选择的所述CPU根据所述IO请求进行处理。
一种分布式块存储的IO请求的处理装置,包括:
接收单元,接收到客户端的IO请求;所述IO请求携带待访问的数据卷以及对所述数据卷的操作指令;
第一获取单元,获取所述数据卷所在的至少两个节点;
第一选择单元,在所述至少两个节点中,选择一个节点,作为卷控制器节点;
第二获取单元,获取所述卷控制器节点对应的至少两个可用CPU;
第二选择单元,在所述至少两个可用CPU中,选择一个CPU;
发送单元,将所述IO请求发送给选择的所述CPU,使得所述IO请求加入到选择的所述CPU的任务队列中,等待选择的所述CPU根据所述IO请求进行处理。
由上述本发明的实施例提供的技术方案可以看出,本发明实施例中,在分布式块存储系统中,引入卷控制器和CPU调度器的处理,来控制每个卷的并发访问,不再使用卷锁来处理IO操作排序,而是交由CPU来处理,CPU会按照接收请求的顺序来处理,这样就不需要同步机制,可以提高系统的IO处理能力,进而优化性能。
本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例一提供的一种分布式块存储的IO请求的处理方法的处理流程图;
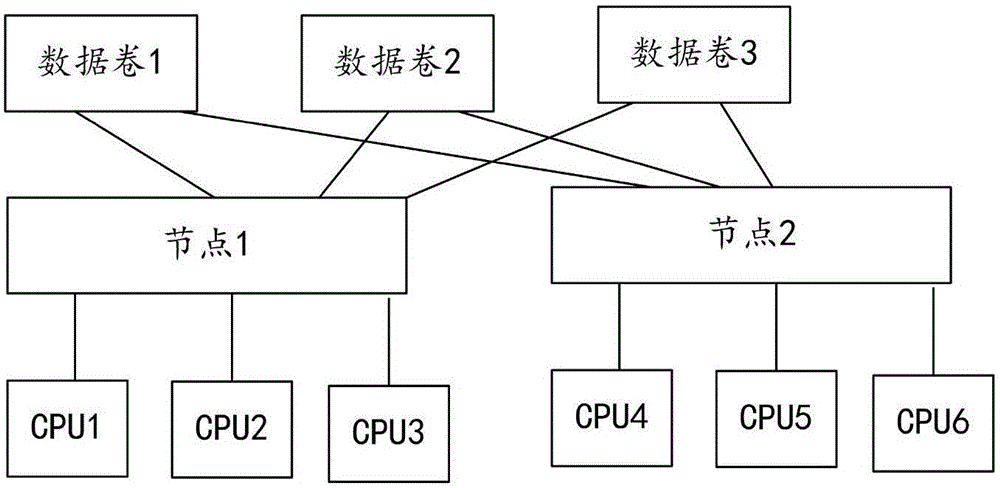
图2为本发明实施例中分布式块存储的IO请求的处理方法中的系统的架构示意图;
图3为本发明实施例二提供的一种分布式块存储的IO请求的处理方法的处理流程图;
图4为本发明实施例三提供的一种分布式块存储的IO请求的处理方法的处理流程图;
图5为本发明实施例提供的一种分布式块存储的IO请求的处理装置的连接示意图。
具体实施方式
下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
如图1所示,为本发明所述的一种分布式块存储的IO请求的处理方法,,包括:
步骤11,接收到客户端的IO请求;所述IO请求携带待访问的数据卷以及对所述数据卷的操作指令;
步骤12,获取所述数据卷所在的至少两个节点;
步骤13,在所述至少两个节点中,选择一个节点,作为卷控制器节点;
步骤14,获取所述卷控制器节点对应的至少两个可用CPU;
步骤15,在所述至少两个可用CPU中,选择一个CPU;
步骤16,将所述IO请求发送给选择的所述CPU,使得所述IO请求加入到选择的所述CPU的任务队列中,等待选择的所述CPU根据所述IO请求进行处理。
本发明实施例中,在分布式块存储系统中,引入卷控制器和CPU调度器的处理,来控制每个卷的并发访问,不再使用卷锁来处理IO操作排序,而是交由CPU来处理,CPU按照接收请求的顺序来处理,这样就不需要同步机制,可以提高系统的IO处理能力,进而优化性能。
具体的,步骤15包括:通过HASH算法,在所述至少两个可用CPU中,选择一个CPU。具体可以为:core_hash(volume):=volume.id%cpuset_usable;
其中,core_hash(volume)为选择出的所述CPU的ID;volume.id为数据卷的ID;%表示取模运算;cpuset_usable表示卷控制器节点对应的可用CPU的总数量。上述算法为现有技术,因此此处不赘述。当然,也可以使用别的算法进行处理。
在一个实施例中,步骤13包括:采用租约leases算法,在所述至少两个节点中,选择一个节点,作为卷控制器节点。上述算法为现有技术,因此此处不赘述。当然,也可以使用别的算法进行处理。
在一个实施例中,步骤13包括:
步骤131,获取分布式块存储的集群中的所有节点;
步骤132,在所述所有节点中,选择一个租约主节点;
步骤133,所述租约主节点采用租约leases算法,在所述至少两个节点中,选择一个节点,作为卷控制器节点。
以下描述本发明的设计思想。
在分布式块存储系统中,卷是最基本的处理单元。因此,可以对处理资源按卷进行划分。本发明的核心思想是,每一个卷的处理,被调度到唯一的控制节点上,然后被调度到某个特定的CPU上。对每一个CPU而言,是顺序执行的,如此就不需要再使用同步机制。这样并发IO可以让对应的CPU核发挥最大的处理能力,来提高存储系统处理能力。
在分布式块存储系统中,卷是最基本的处理单元,对卷的所有IO处理,引入卷控制器和CPU调度器的处理,来控制每个卷的并发访问,不再使用卷锁来处理IO操作排序,而是交由CPU来处理,CPU会自动实现排序处理,这样就不需要同步机制,可以极大的提高系统的IO处理能力,进而优化性能。
图2为本发明所述的系统的架构图,本发明基于这个架构来设计。系统有多个数据卷,多个节点,每个数据卷分布存储在多个节点上,每个节点对应多个CPU,CPU用于处理对应的节点中的数据操作。本发明中,获取客户端当前准备操作的数据卷,然后查找到保存所述数据卷的多个节点,从所述多个节点中,选择一个节点,作为卷控制器节点,再选择获取所述卷控制器节点对应的至少两个可用CPU;在所述至少两个可用CPU中,选择一个CPU,使得所述IO请求加入到选择的所述CPU的任务队列中,等待选择的所述CPU根据所述IO请求进行处理。由于CPU处理的速度比较快,因此相比于现有的锁机制,提高了处理速度。
1、卷控制器
采用mini paxos(分布式一致性)算法,选举lease master(租约主控制)节点,全局唯一。上述算法为现有技术,因此此处不赘述。
采用lease算法,选举卷控制器。
2、调度器
Hash算法,计算卷处理绑定的CPU核
core_hash(volume):=volume.id%CPUset_usable。
(并发)卷IO发起后,存储系统选出唯一的卷控制器节点,IO交给卷控制器节点,然后按照调度器的算法,计算在卷控制器节点处理当前卷IO的CPU核,将IO交由选出的CPU核来处理。这样并发任务会在选出的CPU核处排队,CPU核会发挥最大的处理能力来处理排队的所有IO。
如图3所述,本发明的处理流程包括:
首先,接收到IO请求;
然后,选择卷控制器节点;
然后,按照调度器算法,获取本次IO的处理CPU核是哪一个;
然后,IO交给CPU核处理;
然后,并发IO在对应CPU核排队。
如图4所述,本发明的处理流程包括:
首先,接收Client客户端的IO指令;
然后,客户端连接服务端;先连接target(客户端连接服务端的连接点),再访问卷。
然后,选择Controller节点控制器;
然后,选择Controller节点控制器的CPU核1。
如图5所述,为本发明所述的一种分布式块存储的IO请求的处理装置,包括:
接收单元41,接收到客户端的IO请求;所述IO请求携带待访问的数据卷以及对所述数据卷的操作指令;
第一获取单元42,获取所述数据卷所在的至少两个节点;
第一选择单元43,在所述至少两个节点中,选择一个节点,作为卷控制器节点;
第二获取单元44,获取所述卷控制器节点对应的至少两个可用CPU;
第二选择单元45,在所述至少两个可用CPU中,选择一个CPU;
发送单元46,将所述IO请求发送给选择的所述CPU,使得所述IO请求加入到选择的所述CPU的任务队列中,等待选择的所述CPU根据所述IO请求进行处理。
其中,所述第二选择单元45具体为:通过HASH算法,在所述至少两个可用CPU中,选择一个CPU。具体为:所述第二选择单元具体为:core_hash(volume):=volume.id%cpuset_usable;其中,core_hash(volume)为选择出的所述CPU的ID;volume.id为数据卷的ID;%表示取模运算;cpuset_usable表示卷控制器节点对应的可用CPU的总数量。
所述第一选择单元43具体为:
采用租约leases算法,在所述至少两个节点中,选择一个节点,作为卷控制器节点。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!