活体检测方法、系统、电子设备及计算机可读介质与流程
本发明实施例总体涉及身份认证技术领域,具体而言,涉及一种活体检测方法、系统、电子设备及计算机可读介质。
背景技术:
随着移动互联业务的广泛应用,用户身份认证的技术也不断改进。传统的用户身份认证方式基本上采用用户名加密码的方式,但是,简单的用户名加密码的方式在如今计算资源比较充足的情况下,很容易被黑客采用撞库或者简单的蛮力搜索方式破解。之后增加了随机认证码的方式,银行业还采用外部设备进行签名加密的方式,比如U盾,但是这些认证方式的安全性比较有限。
近年来,基于生物特征技术新型的用户身份认证方式的应用也越来越广泛,例如,可以基于用户的人脸、指纹等静态信息,或张嘴、眨眼等肢体动作对用户的身份进行验证。肢体动作这一类动态检测方式虽然相较于静态照片进行验证的安全性有所提高,但是仍然存在一定的安全隐患。
因此,现有技术方案中还存在有待改进之处。
在所述背景技术部分公开的上述信息仅用于加强对本发明实施例的背景的理解,因此它可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现要素:
本发明实施例提供一种活体检测方法、系统、电子设备及计算机可读介质,解决现有技术方案中身份认证存在漏检、误检的问题。
本发明实施例的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本发明实施例的实践而习得。
根据本发明实施例的第一方面,提供一种活体检测方法,包括:
对一段视频进行分割,得到多帧图像;
对所述图像进行人脸检测,得到人脸检测结果;
如果所述人脸检测结果为检测到人脸,则判断所述图像中的人脸是否为二次翻拍,得到二次翻拍结果;
如果所述二次翻拍结果为否,则向用户发出一动作指示,并获取所述用户完成所述动作指示过程中的反馈视频;
基于所述反馈视频进行语音和动作的识别,得到识别结果;
根据所述人脸检测结果、所述二次翻拍结果、所述识别结果中的至少一项,得到活体检测结果。
在本发明的一些实施例中,对所述图像进行人脸检测包括:
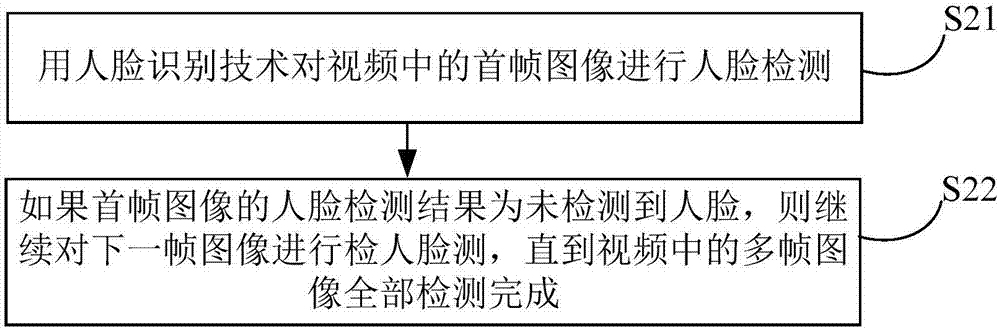
采用人脸识别技术对所述视频中的首帧图像进行人脸检测;
如果所述首帧图像的所述人脸检测结果为未检测到人脸,则继续对下一帧图像进行检人脸测,直到所述视频中的所述多帧图像全部检测完成。
在本发明的一些实施例中,所述判断所述图像中的人脸是否为二次翻拍,得到二次翻拍结果具体为:
从检测到人脸的图像中截取得到人脸图像;
对所述人脸图像进行同态滤波,得到同态滤波后的人脸图像;
对所述同态滤波后的人脸图像进行划分和特征处理,得到特征向量;
对所述特征向量进行归一化处理,得到归一化特征向量;
根据所述归一化特征向量计算所述人脸图像对应的抗翻拍特征值;
如果所述抗翻拍特征值大于第一阈值,则所述二次翻拍结果为否;如果所述抗翻拍特征值不大于第一阈值,则所述二次翻拍结果为是。
在本发明的一些实施例中,对所述人脸图像进行同态滤波,得到同态滤波后的人脸图像具体包括:
基于所述人脸图像获取得所述人脸图像的宽度和高度;
根据对所述人脸图像进行同态滤波构建高斯高通滤波器,所述高斯高通滤波器的宽度为所述人脸图像的宽度,所述高斯高通滤波器的高度为所述人脸图像的宽度;
将所述人脸图像从RGB模型或转换为HSV模型,并获取H分量、S分量、V分量;
基于所述V分量从时域变换到频域;
对频域的V分量和高斯高通滤波器进行卷积;
对卷积后的V分量进行频域到时域的反变换,得到新V分量;
根据所述H分量、所述S分量、所述新V分量还原成RGB模型,得到所述同态滤波后的人脸图像。
在本发明的一些实施例中,所述第一阈值为0.53。
在本发明的一些实施例中,所述动作指示包括命令用户完成眨眼、张嘴以及朗读一段随机文本中至少一种动作的指示,所述动作指示以文本和/或语音的形式发出。
在本发明的一些实施例中,当所述动作指示为张嘴动作时,基于所述反馈视频进行动作的识别包括:
根据所述反馈视频的图像部分对所述用户的张嘴动作进行检测,得到的识别结果为张嘴检测结果。
在本发明的一些实施例中,当所述动作指示为朗读一段随机文本的动作时,基于所述反馈视频进行语音和动作的识别包括:
根据所述反馈视频的图像部分对所述用户的张嘴动作进行检测,得到的识别结果为张嘴检测结果;
根据所述反馈视频的语音部分进行语音识别,得到的识别结果为语音文本检测结果。
在本发明的一些实施例中,所述对所述用户的张嘴动作进行检测具体包括:
对所述反馈视频的多帧图像中进行人脸检测,得到检测到人脸的连续图像;
从所述连续图像的前一帧图像中定位出嘴巴所在的特征区域为第一区域,从所述连续图像的当前帧图像中定位出嘴巴所在的特征区域为第二区域,所述第一区域和所述第二区域均为矩形;
计算所述第一区域的高度为第一高度,所述第二区域的高度为第二高度;
根据所述第一高度和所述第二高度计算得到张嘴特征值,计算公式为:
β=abs(MouthH-prevMouthH)/(min(prevMouthH,MouthH)+0.01)
其中β为所述张嘴特征值,MouthH为所述第二高度,prevMouthH为所述第一高度;
如果所述张嘴特征值大于第二阈值,则所述张嘴检测结果为通过;如果所述张嘴特征值不大于第二阈值,则所述张嘴检测结果为不通过。
在本发明的一些实施例中,所述第二阈值为0.23。
在本发明的一些实施例中,根据所述反馈视频的语音部分进行语音识别具体为:
采用语音识别技术从所述语音部分中提取得到识别文本;
将所述识别文本与所述随机文本进行对比,如果所述识别文本与所述随机文本相同,则所述语音文本检测结果为通过;如果所述识别文本与所述随机文本不相同,则所述语音文本检测结果为不通过。
在本发明的一些实施例中,根据所述人脸检测结果、所述二次翻拍结果、所述识别结果中的至少一项,得到活体检测的结果具体为:
如果所述视频的多帧图像的人脸检测结果均为未检测到人脸、所述二次翻拍结果为是、所述张嘴检测结果为不通过以及所述语音文本检测结果为不通过中至少一项成立,则所述活体检测结果为检测失败;
如果所述视频的至少一帧图像的人脸检测结果均为检测到人脸、所述二次翻拍结果为否、所述张嘴检测结果为通过以及所述语音文本检测结果为通过中全部成立,则所述活体检测结果为检测成功。
根据本发明实施例的第二方面,提供一种活体检测系统,包括:
视频分割单元,配置为对一段视频进行分割,得到多帧图像;
人脸检测单元,配置为对所述图像进行人脸检测,得到人脸检测结果;
二次翻拍检测单元,配置为如果所述人脸检测结果为检测到人脸,则判断所述图像中的人脸是否为二次翻拍,得到二次翻拍结果;
动作指示单元,配置为如果所述二次翻拍结果为否,则向用户发出一动作指示,并获取所述用户完成所述动作指示过程中的反馈视频;
反馈识别单元,配置为基于所述反馈视频进行语音和动作的识别,得到识别结果;
检测结果单元,配置为根据所述人脸检测结果、所述二次翻拍结果、所述识别结果中的至少一项,得到活体检测结果。
根据本发明实施例的第三方面,提供一种电子设备,包括:存储器;处理器及存储在该存储器上并可在该处理器上运行的计算机程序,该程序被该处理器执行时实现上述的方法步骤的指令。
根据本公开实施例的第四方面,提供一种计算机可读介质,其上存储有计算机可执行指令,所述可执行指令被处理器执行时实现上述的方法步骤。
根据本发明实施例提供的活体检测方法、系统、电子设备及计算机可读介质,通过对视频中的图像进行人脸检测、抗二次翻拍以及图像中的人对于动作指示的反馈情况确定活体检测的结果,与仅仅依靠抗二次翻拍以及仅仅依靠眨眼、张嘴等指令式的动作交互方式进行活体检测的技术方案相比,检测的准确率更高。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性的,并不能限制本发明实施例。
附图说明
通过参照附图详细描述其示例实施例,本发明实施例的上述和其它目标、特征及优点将变得更加显而易见。
图1示出本发明实施例提供的一种活体检测方法的流程图。
图2示出本发明实施例图1中步骤S12的流程图。
图3示出本发明实施例图1中步骤S13的流程图。
图4示出本发明实施例图3中步骤S32的流程图。
图5示出本发明实施例图3中步骤S33对人脸图像进行划分处理的示意图。
图6示出本发明实施例图3中步骤S33八方向Sobel梯度算子模板的示意图。
图7示出本发明实施例图4中步骤S42的流程图。
图8示出本发明实施例图1中步骤S15的流程图。
图9示出本发明实施例图8中步骤S81的流程图。
图10示出本发明实施例图8中步骤S82的流程图。
图11示出本发明一实施例提供的一种活体检测方法的步骤流程图。
图12示出本发明一实施例图11中步骤S113进行人脸检测以及嘴巴定位的实例示意图。
图13示出本发明一实施例图11中步骤S114二次翻拍检测的实例示意图。
图14示出本发明一实施例图11中步骤S115处理的实例示意图。
图15示出本发明一实施例图11中步骤S116张嘴动作检测的实例示意图。
图16示出本发明实施例提供的一种活体检测系统的示意图。
图17示出本发明再一实施例提供的适于用来实现本申请实施例的电子设备的计算机系统的结构示意图。
具体实施方式
现在将参考附图更全面地描述示例实施方式。然而,示例实施方式能够以多种形式实施,且不应被理解为限于在此阐述的范例;相反,提供这些实施方式使得本发明实施例将更加全面和完整,并将示例实施方式的构思全面地传达给本领域的技术人员。附图仅为本发明实施例的示意性图解,并非一定是按比例绘制。图中相同的附图标记表示相同或类似的部分,因而将省略对它们的重复描述。
此外,所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施方式中。在下面的描述中,提供许多具体细节从而给出对本发明实施例的实施方式的充分理解。然而,本领域技术人员将意识到,可以实践本发明实施例的技术方案而省略所述特定细节中的一个或更多,或者可以采用其它的方法、组元、装置、步骤等。在其它情况下,不详细示出或描述公知结构、方法、装置、实现、材料或者操作以避免喧宾夺主而使得本发明实施例的各方面变得模糊。
附图中所示的一些方框图是功能实体,不一定必须与物理或逻辑上独立的实体相对应。可以采用软件形式来实现这些功能实体,或在一个或多个硬件模块或集成电路中实现这些功能实体,或在不同网络和/或处理器装置和/或微控制器装置中实现这些功能实体。
为使本发明实施例的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明实施例进一步详细说明。
在活体检测相关行业中,基于红外摄像头或者3Ds摄像头对三维图像进行活体检测,例如可以通过红外摄像头获取深度信息,重建三维图像判定参与检测的是否为“真人”。但是该技术方案的缺点是对设备硬件条件要求较高,而且红外摄像头较普通摄像头的设备成本也较高,不适用于手机等移动终端设备,也不具有广泛应用的意义。
在本发明相关实施例中,提供一种基于张嘴、眨眼等肢体运动进行活体检测的技术方案。首先检测当前图像中是否存在人脸,然后在人脸图像中定位嘴、眼睛等关键特征点的位置信息,最后根据连续的视频帧中嘴、眼睛等特征区域的形状或者位置是否发生变化来判定参与检测的是否是“真人”,及是否为活体的人。此类动态检查虽然可以有效解决某些利用静态照片参与人脸检测带来的安全隐患,但是该技术方案对于二次翻拍视频中录制好的人脸图像,例如在预先录制好的一段人脸视频中,也会含眨眼等动态信息,如果用这样的动态视频人脸代替静态人脸参与检测,就可以欺骗人脸识别系统,因此该技术方案对于二次翻拍视频的情况并不能有效的将其检测出来,仍然存在漏检或误检的问题。
基于上述问题,本发明提供一种活体检测方法及系统,采用人脸识别叠加抗二次翻拍以及随机语音识别的方式来检测视频采集的人脸图像来确定是否为活体的人,防止网络欺诈,提高身份认证的安全性。
图1示出本发明实施例提供的一种活体检测方法的流程图,用于解决现有技术中通过活体检测进行身份验证存在的漏检、误检的问题。
如图1所示,在步骤S11中,对一段视频进行分割,得到多帧图像,其中这多帧图像构成一图像序列。
如图1所示,在步骤S12中,对图像进行人脸检测,得到人脸检测结果。
如图1所示,在步骤S13中,如果人脸检测结果为检测到人脸,则判断图像中的人脸是否为二次翻拍,得到二次翻拍结果。
如图1所示,在步骤S14中,如果二次翻拍结果为否,则向用户发出一动作指示,并获取用户完成动作指示过程中的反馈视频。
如图1所示,在步骤S15中,基于反馈视频进行语音和动作的识别,得到识别结果。
如图1所示,在步骤S16中,根据人脸检测结果、二次翻拍结果、识别结果中的至少一项,得到活体检测结果。
基于本发明实施例提供的活体检测方法,一方面,通过对视频中的图像进行人脸检测、抗二次翻拍以及图像中的人对于动作指示的反馈情况确定活体检测的结果,与仅仅依靠抗二次翻拍以及仅仅依靠眨眼、张嘴等指令式的动作交互方式进行活体检测的技术方案相比,检测的准确率更高。另一方面,该方法对设备要求不是很高,无需使用红外摄像头或3Ds摄像头等高成本的硬件设备,因此可以降低设备成本,也更加便于广泛的应用。
以下,将对上述活体检测方法进行详细的解释以及说明。
如图1所示,在步骤S11中,对一段视频进行分割,得到多帧图像,其中这多帧图像构成一图像序列。
在本发明一实施例中,可以按照视频的帧率对视频进行分割,例如,对于一段帧率为15帧/秒,分辨率为640*480的视频而言,可以将其分割成15帧连续的图像,且这15帧连续的图像可以构成一图像序列,每一帧图像的分辨率均为640*480。
如图1所示,在步骤S12中,对图像进行人脸检测,得到人脸检测结果。
图2示出步骤S12对图像进行人脸检测的流程图。
如图2所示,在步骤S21中,采用人脸识别技术对视频中的首帧图像进行人脸检测。
在本发明一实施例中,采用人脸识别技术对上述步骤S11得到的图像序列依序进行人脸检测,这一步骤主要是对图像中的人脸进行检测,如果检测出人脸,则针对这一帧图像的人脸检测结果为检测到人脸;如果没有检测出人脸,则针对这一帧图像的人脸检测结果为未检测到人脸。通过从分割的图像中定位出人脸的位置和大小,例如可以采用Adaboost学习算法或其他分类器完成人脸检测。人脸图像中包含的模式特征十分丰富,如直方图特征、颜色特征、模板特征、结构特征及Haar特征等,人脸检测就是把这其中有用的信息挑选出来,并利用这些特征实现人脸检测。
如图2所示,在步骤S22中,如果首帧图像的人脸检测结果为未检测到人脸,则继续对下一帧图像进行检人脸测,直到视频中的多帧图像全部检测完成。
由于人脸主要由眼睛、鼻子、嘴、下巴等局部构成,对这些局部和它们之间结构关系的几何描述,可作为识别人脸的重要特征,因此对于检测出人脸的图像,进一步的,还需在检测到人脸的图像中定位出嘴巴或眼睛所在的特征区域,这一特征区域可以用以矩形框表示,以便在后续步骤中能够根据特征区域嘴巴或眼睛的变化信息确定否为“真人”。
如图1所示,在步骤S13中,如果人脸检测结果为检测到人脸,则判断图像中的人脸是否为二次翻拍,得到二次翻拍结果。
这一步骤需要对已检测到人脸的图像进一步验证其“活体”特性,即判断是否是有人恶意利用翻拍的视频或图像进行检测。
图3示出步骤S13中判断图像中的人脸是否为二次翻拍,得到二次翻拍结果的流程图。
如图3所示,在步骤S31中,从检测到人脸的图像中截取得到人脸图像。例如可以用以矩形框对图像中的人脸进行标记,假设检测出的人脸图像的宽、高分别为W、H,则截取的图像左上角位于人脸框的左上角,宽WN=(W/16)*16,高HN=(H/16)*16,“/”表示整除运算。
如图3所示,在步骤S32中,对人脸图像进行同态滤波,得到同态滤波后的人脸图像。通过对人脸图像进行同态滤波,可以压缩人脸图像的亮度范围,同时增强图像对比度,从而降低外界环境的干扰,步骤S32的流程在后续图4中进一步示出。
如图3所示,在步骤S33中,对同态滤波后的人脸图像进行划分和特征处理,得到特征向量。
在本发明一实施例中,首先,对滤波后的人脸图像进行划分,得到多个数据块。
图5示出对人脸图像进行划分处理的示意图。如图5所示,每个数据块的大小为16*16,在对这些数据块按照3*3的矩阵单元进行划分,共包含(16-3+1)*(16-3+1)=196个3*3的矩阵单元,以一行或者一列像素为间隔进行单元提取,按照从左到右、从上到下的原则依次进行滑动,并且将每一个3*3的矩阵单元转化成一维向量Y,用八方向Sobel梯度算子X依次与Y进行卷积计算。
图6示出八方向Sobel梯度算子模板的示意图。参见图6所示,所谓的八方向其实就是将360均分后的八个方向,即0°、45°、90°、135°、180°、225°、270°和315°。这样,对于每一个方向,将计算得到的196个卷积值中的最大值作为该方向的统计量。
基于上述,每一个矩阵单元都包含了8个方向的统计量,不同的矩阵单元8个方向的统计量也各不相同,可以作为每一个矩阵单元的特征。因此步骤S32同态滤波后得到的整张人脸图像包含(WN/16)*(HN/16)*8个特征集合,设为特征向量F。
如图3所示,在步骤S34中,对特征向量进行归一化处理,得到归一化特征向量,归一化特征向量FN=F/((WN/16)*(HN/16)*196.0)。
如图3所示,在步骤S35中,根据归一化特征向量计算人脸图像对应的抗翻拍特征值。抗翻拍特征值的计算公式为α=(std(FN)/mean(FN)),其中std(FN)表示向量FN的标准差,mean(FN)表示向量FN的均值。
如图3所示,在步骤S36中,如果抗翻拍特征值大于第一阈值,则二次翻拍结果为否,也就是人脸图像中是真实人脸;如果抗翻拍特征值不大于第一阈值,则二次翻拍结果为是,也就是人脸图像时二次翻拍得到的,并不是真实人脸。
这一步骤的第一阈值可以为0.53,即当α>0.53时人脸图像中是真实人脸,否则人脸图像中不是真实人脸。
图4示出步骤S32中对人脸图像进行同态滤波的流程图。
如图4所示,在步骤S41中,基于人脸图像获取得人脸图像的宽度和高度,假设人脸图像的宽度用FACE_W表示,高度用FACE_H表示。
如图4所示,在步骤S42中,根据对人脸图像进行同态滤波构建高斯高通滤波器,高斯高通滤波器的宽度为人脸图像的宽度,高斯高通滤波器的高度为人脸图像的宽度,步骤S42中生成高斯高通滤波器的流程在后续图7中进一步示出。
如图4所示,在步骤S43中,将人脸图像从RGB模型或转换为HSV模型,并获取H分量、S分量、V分量。
如图4所示,在步骤S44中,基于V分量从时域变换到频域,具体为对V分量取自然对数,然后进行DCT离散余弦变换,即logV=ln(V),dctV=dct(logV),实现V分量从时域空间转换到频域空间。
如图4所示,在步骤S45中,对频域的V分量和高斯高通滤波器进行卷积,具体为将DCT离散余弦变换后的V分量和高斯高通滤波器进行卷积,即ghfV=dctV*GHF。
如图4所示,在步骤S46中,对卷积后的V分量进行频域到时域的反变换,得到新V分量。具体为将卷积后的V分量进行DCT离散余弦反变换,然后对结果取反自然对数得到新的V分量VN,即idctV=idct(ghfV),VN=exp(idctV),VN表示新V分量。
如图4所示,在步骤S47中,根据H分量、S分量、新V分量VN还原成RGB模型,得到同态滤波后的人脸图像。步骤S43和步骤S47中RGB模型和HSV模型之间的转换谓本领域技术人员所公知,此处不再赘述。
根据图4所示,通过步骤S41~S47,利用广义叠加原理对同态系统进行滤波。同态滤波是把频率过滤和灰度变换结合起来的一种图像处理方法,它依靠图像的照度/反射率模型作为频域处理的基础,利用压缩亮度范围和增强对比度来改善图像的质量。使用这种方法可以使图像处理符合人眼对于亮度响应的非线性特性,避免了直接对图像进行傅立叶变换处理的失真。
根据上述步骤S42,图7示出生成高斯高通滤波器的流程图。
如图7所示,在步骤S71中,假设高斯高通滤波器的宽度为GHF_W,高度为GHF_H。
如图7所示在,在步骤S72中,gammaH=1.5,gammaL=0.7,C=1.5。
如图7所示在,在步骤S73中,d0=(GHF_H/2)*(GHF_H/2)+(GHF_W/2)*(GHF_W/2),定义参数i=0,j=0。
如图7所示在,在步骤S74中,判断i是否小于GHF_H,如果是,则继续步骤S75;如果否,则直接转至步骤S79;
如图7所示在,在步骤S75中,判断j是否小于GHF_W,如果是,则继续步骤S76;如果否,则直接转至步骤S79;
如图7所示在,在步骤S76中,d2=i2+j2,GHF[i][j]=(gammaH-gammaL)*(1-exp(-C*d2/(d0+0.0)))+gammaL;
如图7所示在,在步骤S77中,j=j+1;
如图7所示在,在步骤S78中,i=i+1,j=0;
如图7所示在,在步骤S79中,GHF[0][0]=0.95,得到的GHF为生成的高斯高通滤波器。
根据图7所示步骤流程得到的高斯高通滤波器应用于步骤S52,进行同态滤波处理。
如图1所示,在步骤S14中,如果二次翻拍结果为否,则向用户发出一动作指示,并获取用户完成动作指示过程中的反馈视频。
在发明一实施例中,动作指示包括命令用户完成眨眼、张嘴以及朗读一段随机文本中至少一种动作的指示,动作指示以文本和/或语音的形式发出。因此可以向用户发送语音或文本通知用户完成张嘴或眨眼的动作,或者通知用户朗读一段随机文本。并在发出动作指示后获取用户完成这一项或多项动作指示过程中的反馈视频,反馈视频中包括体现用户对动作指示完成情况的信息,例如,反馈视频中的语音部分用于体现用户完成朗读一段随机文本等发声动作的情况,反馈视频中的图像部分用于体现用户完成眨眼、张嘴等无声动作的情况。在这些指示动作中,眨眼、张嘴均为单一信息来源的动作,而朗读一段随机文本为多维信息来源的动作,即既包含张嘴的动作,又包含发出的声音。
如图1所示,在步骤S15中,基于反馈视频进行语音和动作的识别,得到识别结果。
根据反馈视频的图像部分对用户的张嘴动作或眨眼动作进行检测,得到的识别结果为张嘴检测结果,或根据反馈视频的图像部分对用户的眨眼动作进行检测,得到的识别结果为眨眼检测结果。其中眨眼动作检测需要对人脸图像中眼睛的特征区域的变化进行检测,而张嘴动作检测需要对人脸图像中嘴的特征区域的变化进行检测。需要说明的是,通常,眨眼动作检测仅用于单一动作的检测,而张嘴动作检测除了用于单一动作的检测,还可以用于朗读一段随机文本的动作的检测。
在发明一实施例中,图8示出步骤S15当动作指示为朗读一段随机文本的动作时,基于反馈视频进行语音和动作的识别的流程图。
如图8所示,在步骤S81中,根据反馈视频的图像部分对用户的张嘴动作进行检测,得到的识别结果为张嘴检测结果。具体的流程在后续图9中进一步示出。
如图8所示,在步骤S82中,根据反馈视频的语音部分进行语音识别,得到的识别结果为语音文本检测结果。具体的流程在后续图10中进一步示出。
图9示出步骤S81根据反馈视频的图像部分对用户的张嘴动作进行检测的流程图。
如图9所示,在步骤S91中,对反馈视频的多帧图像中进行人脸检测,得到检测到人脸的连续图像。
如图9所示,在步骤S92中,从连续图像的前一帧图像中定位出嘴巴所在的特征区域为第一区域,从连续图像的当前帧图像中定位出嘴巴所在的特征区域为第二区域。
假设前一帧图像定位出的嘴巴所在的第一区域为prev_Rec,当前帧图像中定位出嘴巴所在的第二区域为Rec。在本实施例中,第一区域和第二区域均为矩形,在本发明其他实施例中第一区域和第二区域的形状还可以为矩形之外的其他形状。
如图9所示,在步骤S93中,计算第一区域的高度为第一高度,第二区域的高度为第二高度,具体为计算矩形prev_Rec的高度为prevMouthH,矩形Rec的高度为MouthH。
如图9所示,在步骤S94中,根据第一高度和第二高度计算得到张嘴特征值,计算公式为:
β=abs(MouthH-prevMouthH)/(min(prevMouthH,MouthH)+0.01)
其中β为张嘴特征值,MouthH为第二高度,prevMouthH为第一高度,abs(value)表示value的绝对值,min(value1,value2)表示value1和value2两者之间的最小值。
如图9所示,在步骤S95中,如果张嘴特征值大于第二阈值,则张嘴检测结果为通过;如果张嘴特征值不大于第二阈值,则张嘴检测结果为不通过。
这一步骤的第二阈值可以为0.23,即当α>0.23时,检测到张嘴动作,否则就是没有检测到张嘴动作。
图10示出步骤S82根据反馈视频的语音部分进行语音识别的流程图。
如图10所示,在步骤S101中,采用语音识别技术从语音部分中提取得到识别文本。其中语音识别技术为本领域技术人员公知的,在此不再赘述。
如图10所示,在步骤S102中,将识别文本与随机文本进行对比,如果识别文本与随机文本相同,则语音文本检测结果为通过;如果识别文本与随机文本不相同,则语音文本检测结果为不通过。
需要说明的是,当指示动作为朗读一段随机文本时,需要张嘴检测结果和语音文本检测结果两项都通过时才算识别通过,即识别结果为是,如果其中任一项检测结果为不通过,则识别都是不通过,即识别结果为否。
如图1所示,在步骤S16中,根据人脸检测结果、二次翻拍结果、识别结果中的至少一项,得到活体检测结果。
如果视频的多帧图像的人脸检测结果均为未检测到人脸、二次翻拍结果为是、张嘴检测结果为不通过以及语音文本检测结果为不通过中至少一项成立,则活体检测结果为检测失败。即决定活体检测结果的几项结果中只要有一项不通过,活体检测结果就是检测失败。
如果视频的至少一帧图像的人脸检测结果均为检测到人脸、二次翻拍结果为否、张嘴检测结果为通过以及语音文本检测结果为通过中全部成立,则活体检测结果为检测成功。即决定活体检测结果的几项结果中必须全部通过时,活体检测结果就是检测成功。
下面结合图11和一个具体实施例对该活体检测方法的技术内容进行详细具体的说明。
图11示出本发明一实施例提供的一种活体检测方法的步骤流程图。
如图11所示,在步骤S111中,输入一段包含人脸的视频,按照帧率将视频截成图像序列。
如图11所示,在步骤S112中,假设图像序列包含的图像帧数为FRM_NUM,对图像序列的多帧图像按照帧序号从0到FRM_NUM-1的顺序进行编号。假设视频帧率为15帧/秒,视频分辨率为640x480。相应的检测的图像帧数FRM_NUM=15,帧序号为从0到14,初始化帧序号idx=0。
设置活体检测结果R=False,设置朗读变量bRead=True。对图像序列从帧序号idx=0开始,依次遍历图像序列的每一帧图像。
如图11所示,在步骤S113中,设置当前图像帧序号为idx,如果idx>FRM_NUM-1,转到步骤S1110;否则,采用人脸识别技术在当前帧图像中进行人脸检测,如果人脸检测结果为检测到人脸,则进一步在人脸图像中定位出嘴巴所在的特征矩形区域;如果当前帧图像中人脸检测结果为未检测到人脸,转到步骤S119。
图12示出采用人脸识别技术在当前帧图像中检测到人脸并定位出嘴巴所在的特征区域的一个实例示意图,如图12所示,人脸区域以及面部主要器官所在的区域以及嘴巴所在的特征区域分别用方形框、方形框以及矩形框标注出来。比如嘴巴所在的特征矩形区域的坐标为(91,25,255,205),其中(91,25)表示矩形框左上角点的坐标值,(255,205)表示矩形框右下角点的坐标值,矩形框的宽W、高H分别为164、180。
如图11所示,在步骤S114中,检测一帧图像中的人脸是否是二次翻拍人脸。如果检测成功,转到步骤S119。
其中检测图像中的人脸是否是二次翻拍人脸具体为:
结合图3,按照步骤S31,截取步骤S113中检测出的人脸框图像,得到新的图像宽WN=(w/16)*16=(164/16)*16=160、高HN=(H/16)*16=(180/16)*16=176;按照步骤S32,对新的人脸图像进行同态滤波;按照步骤S33,对滤波后的图像进行划分,每个块大小为16*16,共有(WN/16)*(HN/16)=(160/16)*(176/16)=10*11个块,计算每个小块8个方向的统计量作为其特征,整张人脸包含了(WN/16)*(HN/16)*8=10*11*8=880个特征集合,设为特征向量F,维数为880;按照步骤S34,对特征向量F进行归一化,得到新的归一化特征向量FN=F/((WN/16)*(HN/16)*196.0)=F/(10*11*196);按照步骤S35,计算人脸图像对应的抗翻拍特征值α,按照本实例计算得到α=0.572;按照步骤S36,比较抗翻拍特征值α与第一阈值的大小,比如计算得到α=0.572>0.53(第一阈值),因此图12所示的图像包含真实人脸。
图13示出二次翻拍检测的实例示意图。
如图11所示,在步骤S115中,如果bRead=True,指示用户朗读一句随机文本,设置bRead=False。
图14示出步骤S115处理的实例示意图,如图14所示,当前图像中显示随机文本“朝辞白帝彩云间”。
如图11所示,在步骤S116中,检测用户的张嘴动作。如果检测失败,即没有检测到张嘴动作,转到步骤S119。
其中检测用户的张嘴动作具体为:
结合图9所示,按照步骤S92,假设步骤S113中前一帧图像定位出的嘴巴所在的矩形为prev_Rec=(90,185,141,210),其中(90,185)表示矩形框左上角点的坐标值,(141,210)表示矩形框右下角点的坐标值;当前图像中定位出的嘴巴所在矩形为Rec=(94,178,143,210),其中(94,178)表示矩形框左上角点的坐标值,(143,210)表示矩形框右下角点的坐标值;按照步骤S93,计算前一帧图像中矩形框的宽prevMouthW、高prevMouthH分别为51、25当前帧图像中矩形框的宽度MouthW、高度MouthH分别为49、32;按照步骤S94,计算张嘴特征值β=abs(MouthH-prevMouthH)/(min(prevMouthH,MouthH)+0.01)=(32-25)/(25+0.01)=0.269;按照步骤S95,比较张嘴特征值β与第二阈值的大小,β=0.269>0.23,表示检测到张嘴动作。
图15示出张嘴动作检测的实例示意图。
如图11所示,在步骤S117中,采用语音识别技术得到语音对应的文本,将其与步骤S115中的随机文本进行比对,比如通过语音识别得到的文本为“朝辞白帝彩云间”,与步骤S115中的随机文本“朝辞白帝彩云间”进行比对。
如图11所示,在步骤S118中,如果步骤S117比对成功,即识别得到语音对应的文本与随机文本一致,则设置活体检测结果R=True,转到步骤S1110。根据步骤S117的比对结果为成功,活体检测结果R=True。
如图11所示,在步骤S119中,设置idx=idx+1,处理下一帧图像,转到步骤S113。
如图11所示,在步骤S1110中,获取活体检测结果R。R=True表示活体检测成功,判定视频中存在“真实”人脸。
根据上述步骤S111~S1110,依次经过人脸检测、二次翻拍检测以及动作指示检测,判断出活体检测结果为检测到“真实”人脸
根据图11所示步骤,对一段图像的逐帧对其进行人脸检测、判断其是否为二次翻拍以及张嘴动作检测和文本对比,最终得到活体检测结果。
综上所述,本发明实施例提供的活体检测方法,一方面,通过对视频中的图像进行人脸检测、抗二次翻拍以及图像中的人对于动作指示的反馈情况确定活体检测的结果,与仅仅依靠抗二次翻拍以及仅仅依靠眨眼、张嘴等指令式的动作交互方式进行活体检测的技术方案相比,检测的准确率更高。本实施例针对作为独立活体检测技术方案的张嘴、眨眼等指令式交互方式和抗二次翻拍的单张图像检测方式以及语音识别检测方式都存在漏检、误检的缺陷,通过将这些性能相对较弱的检测模块有效级联成一个整体,就能产生一个性能增强的活体检测器,在不显著增加算法复杂度的前提下,能够大大提高活体检测的正确率。另一方面,该方法对设备要求不是很高,无需使用红外摄像头或3Ds摄像头等高成本的硬件设备,因此可以降低设备成本,也更加便于广泛的应用。
图16示出本发明实施例提供的一种活体检测系统的示意图,用于解决现有技术中通过活体检测进行身份验证存在的漏检、误检的问题。
如图16所示,该装置1600中包括:视频分割单元1610、人脸检测单元1620、二次翻拍检测单元1630、动作指示单元1640、反馈识别单元1650和检测结果单元1660。
视频分割单元1610配置为对一段视频进行分割,得到多帧图像;人脸检测单元1620配置为对图像进行人脸检测,得到人脸检测结果;二次翻拍检测单元1630配置为如果人脸检测结果为检测到人脸,则判断图像中的人脸是否为二次翻拍,得到二次翻拍结果;动作指示单元1640配置为如果二次翻拍结果为否,则向用户发出一动作指示,并获取用户完成动作指示过程中的反馈视频;反馈识别单元1650配置为基于反馈视频进行语音和动作的识别,得到识别结果;检测结果单元1660配置为根据人脸检测结果、二次翻拍结果、识别结果中的至少一项,得到活体检测结果。
另外,图16所示系统中各个模块的功能参见上述方法实施例中的相关描述,此处不再赘述。
本实施提供的活体检测系统能够实现与上述活体检测方法相同的技术效果,此处不再赘述。
根据本发明实施例的第三方面,提供一种电子设备,包括:存储器;处理器及存储在该存储器上并可在该处理器上运行的计算机程序,该程序被该处理器执行时实现上述的方法步骤。
另一方面,本发明还提供了一种电子设备,包括处理器和存储器,存储器存储用于上述处理器控制以下方法的操作指令:
对一段视频进行分割,得到多帧图像;
对所述图像进行人脸检测,得到人脸检测结果;
如果所述人脸检测结果为检测到人脸,则判断所述图像中的人脸是否为二次翻拍,得到二次翻拍结果;
如果所述二次翻拍结果为否,则向用户发出一动作指示,并获取所述用户完成所述动作指示过程中的反馈视频;
基于所述反馈视频进行语音和动作的识别,得到识别结果;
根据所述人脸检测结果、所述二次翻拍结果、所述识别结果中的至少一项,得到活体检测结果。
下面参考图17,其示出了适于用来实现本发明实施例的电子设备的计算机系统1700的结构示意图。图17示出的电子设备仅仅是一个示例,不应对本申请实施例的功能和使用范围带来任何限制。
如图17所示,计算机系统1700包括中央处理单元(CPU)1701,其可以根据存储在只读存储器(ROM)1702中的程序或者从存储部分1707加载到随机访问存储器(RAM)1703中的程序而执行各种适当的动作和处理。在RAM 1703中,还存储有系统1700操作所需的各种程序和数据。CPU 1701、ROM 1702以及RAM 1703通过总线1704彼此相连。输入/输出(I/O)接口1705也连接至总线1704。
以下部件连接至I/O接口1705:包括键盘、鼠标等的输入部分1706;包括诸如阴极射线管(CRT)、液晶显示器(LCD)等以及扬声器等的输出部分1707;包括硬盘等的存储部分1708;以及包括诸如LAN卡、调制解调器等的网络接口卡的通信部分1709。通信部分1709经由诸如因特网的网络执行通信处理。驱动器1710也根据需要连接至I/O接口1705。可拆卸介质1711,诸如磁盘、光盘、磁光盘、半导体存储器等等,根据需要安装在驱动器1710上,以便于从其上读出的计算机程序根据需要被安装入存储部分1708。
特别地,根据本发明的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本发明的实施例包括一种计算机程序产品,其包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分1709从网络上被下载和安装,和/或从可拆卸介质1711被安装。在该计算机程序被中央处理单元(CPU)1701执行时,执行本申请的系统中限定的上述功能。
需要说明的是,本申请所示的计算机可读介质可以是计算机可读信号介质或者计算机可读介质或者是上述两者的任意组合。计算机可读介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑磁盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本申请中,计算机可读介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本申请中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、RF等等,或者上述的任意合适的组合。
附图中的流程图和框图,图示了按照本申请各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,上述模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图或流程图中的每个方框、以及框图或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
描述于本申请实施例中所涉及到的单元可以通过软件的方式实现,也可以通过硬件的方式来实现。所描述的单元也可以设置在处理器中,例如,可以描述为:一种处理器包括发送单元、获取单元、确定单元和第一处理单元。其中,这些单元的名称在某种情况下并不构成对该单元本身的限定,例如,发送单元还可以被描述为“向所连接的服务端发送图像获取请求的单元”。
另一方面,本发明实施例还提供了一种计算机可读介质,该计算机可读介质可以是上述实施例中描述的设备中所包含的;也可以是单独存在,而未装配入该设备中。上述计算机可读介质承载有一个或者多个程序,当上述一个或者多个程序被一个该设备执行时,使得该设备包括以下方法步骤:
对一段视频进行分割,得到多帧图像;
对所述图像进行人脸检测,得到人脸检测结果;
如果所述人脸检测结果为检测到人脸,则判断所述图像中的人脸是否为二次翻拍,得到二次翻拍结果;
如果所述二次翻拍结果为否,则向用户发出一动作指示,并获取所述用户完成所述动作指示过程中的反馈视频;
基于所述反馈视频进行语音和动作的识别,得到识别结果;
根据所述人脸检测结果、所述二次翻拍结果、所述识别结果中的至少一项,得到活体检测结果。
应清楚地理解,本发明实施例描述了如何形成和使用特定示例,但本发明实施例的原理不限于这些示例的任何细节。相反,基于本发明实施例公开的内容的教导,这些原理能够应用于许多其它实施方式。
以上具体地示出和描述了本发明的示例性实施方式。应可理解的是,本发明实施例不限于这里描述的详细结构、设置方式或实现方法;相反,本发明实施例意图涵盖包含在所附权利要求的精神和范围内的各种修改和等效设置。
- 还没有人留言评论。精彩留言会获得点赞!