一种公共安全知识图谱构建的方法与流程
本发明涉及公共安全领域以及语义网络领域,尤其涉及公共安全知识图谱构建方法。
背景技术:
随着大数据与人工智能的发展,知识图谱作为人工智能技术的重要组成部分,因其强大的语义处理、互联组织、信息检索以及知识推理能力,已经被广泛应用于智能搜索、人机问答、个性化推荐等方向,为医疗、金融等多个领域的知识化组织与智能化应用提供了技术基础。本质上,知识图谱是一张巨大的语义网络图,通过节点表示实体或者概念、边表示关系来描述真实世界中存在的各种实体或者概念以及其关系。
公共安全领域随着大数据技术的深度应用,开启了新的纪元。通过有效地整合各类数据、构建多维分析模型等方式,提升了情报洞察、分析研判、侦查打击以及指挥管理的能力。但是随着数据融合的不断深入,业务建模的不断整合,公共安全大数据对更加深入地关联挖掘能力、更加智能化的预警预测能力以及更加全方位的分析研判能力的需求变得愈加迫切。
由上可知,将知识图谱应用于公共安全领域,借助知识图谱强大的互联以及推理能力,进行关系深度挖掘、案情智能推理以及事件主动预测,是符合公共安全行业的发展趋势的。同时,公共安全大数据对海量数据的收集、整理以及归类,也为公共安全知识图谱的构建奠定了基础。但由于当前知识图谱作为全新的技术领域,其在公共安全领域的应用几乎还处于空白阶段,且其构建技术多数还停留在常规的主体以及简单的关系,缺乏广泛性。
技术实现要素:
本发明的目的在于提供一种公共安全知识图谱构建的方法,有效构建公共安全知识图谱。
实现上述目的的技术方案是:
一种公共安全知识图谱构建的方法,包括:
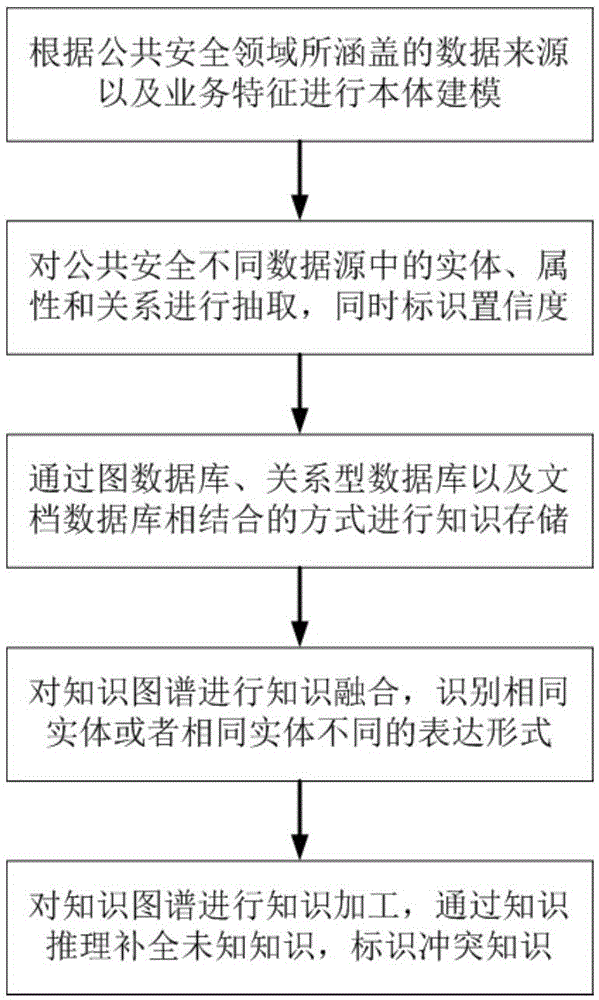
步骤一,根据公共安全领域所涵盖的数据来源以及业务特征进行本体建模;
步骤二,从当前公共安全数据源进行知识抽取;
步骤三,通过图数据库、关系型数据库以及文档数据库相结合的方式对抽取的知识进行存储;
步骤四,将从各数据源采集的知识进行知识融合;
步骤五,对完成知识融合的知识图谱进行知识加工。
优选的,所述的步骤一中,本体建模采用自顶向下与自底向上相结合的构建方式,包括:
步骤s11,采用自顶向下的构建方式进行类以及类层次的构建:采用公共安全“人、事、物、点、组织”基本要素作为基础类,再根据数据源特征以及实际业务,从基础类开始,以多叉树的结构进行展开,构建类之间的层级关系,直到最小粒度;类以及类层次关系构建完毕后,进一步的构建类的交叉关系,包括互斥、交集、并集、补集以及继承关系;
步骤s12,采用自顶向下与自底向上相结合的方式进行关系以及关系关联的构建:首先通过自顶向下的方式对基础的抽象关系进行构建,包括从属关系、互斥关系、等价关系以及冲突关系;再采用自底向上的方式,对于关系型数据源抽取其关联外键构建实例关系,非关系型数据源采用语义依存构建实例关系,且每一种实例关系至少对应一种抽象关系;
步骤s13,采用自底向上的方式进行实体与属性构建:对于关系型数据源直接从数据表字段中抽取实体与属性,而对于非关系型数据源则通过语义依存分析进行聚类分析抽取实体与属性,且每个属性至少对应一个实体,每个实体至少属于一个类。
优选的,所述步骤二中,知识抽取的数据源包括关系型数据以及非关系型数据;知识抽取的内容包含:实体、属性和关系;
其中,关系型数据源的知识抽取采用数据治理以及资源描述框架技术,非关系型数据源知识抽取采用文本语义分析提取技术;对于抽取实体、关系以及属性,根据不同的数据来源以及抽取方式标识置信度。
优选的,知识抽取的数据源中,关系型数据来自于数据仓库以及各业务系统数据库,非关系型数据来自文案、新闻;置信度的计算中,数据仓库的数据源可以基本视为完全信任,置信度为100,各业务系统数据库的置信度根据实际的数据完善度进行计算;而非关系型数据源,依据具体的知识抽取结果的质量评估进行计算。
优选的,所述步骤三中,数据存储模式采用雪花型存储模式,以图数据库为中心,进行类以及类层级、实体以及实体的唯一标识、关系的存储;关系型数据库以及文档数据库作为外围数据存储,关系型数据库存储属性以及属性的层级关系,文档数据库存储文本以及文本关键词;关系型数据库、文档数据库通过实体的唯一标识与图数据库进行关联。
优选的,所述步骤四中,知识融合指:通过实体链接标识相似实体,关联相同实体的不同表达形式;并对相同实体的不同属性或者相同实体相同属性不同的属性值进行合并,同时去掉重复的实体、属性以及关系;具体包括:
步骤s41,对于全部共同唯一性属性值完全相同的两个实体,判断其共同非唯一性属性的值,当非唯一性属性值相同率达到某一阈值后,标识为相同实体;
步骤s42,对于部分共同唯一性属性值完全相同的两个实体,标识为实体冲突关系;
步骤s43,对于共同唯一性属性值完全不同,但非唯一性属性值相同率达到某一阈值的两个实体,标识为相似实体;
步骤s44,对于所述步骤s41中相同的实体,判断当前实体与目标实体是否都存在某一属性,若存在,则将属性的值进行合并后去重,若不存在,则将当前实体的属性以及属性值添加到目标实体;
步骤s45,对于所述步骤s41中相同的实体,判断当前实体与目标实体是否存在关联到某实体的相同关系,若不存在,则将目标实体与某实体关联此关系;对于当前实体与目标实体与某实体关联关系存在冲突的,将当前实体与目标实体取消相同实体标识,标识为冲突实体;
步骤s46,对于所述步骤s45中完成关系合并的当前实体,删除其重复实体、属性以及关系。
优选的,所述的步骤五中,通过知识推理技术进行知识补全以及冲突检测;知识补全包括对实体属性、属性未知属性值以及实体间未知关系进行补全;知识补全通过知识推理技术实现,且补全的知识仅针对知识推理结果为真且置信度为100的结果;冲突检测中,对存在冲突的知识进行甄别,对于存在冲突的知识,标识信度较低的知识为逻辑非。
优选的,所述步骤五,包括:
步骤s51,通过属性继承通过父类实体补全子类实体属性以及属性值,对于多继承的子类,继承其所有父类的属性以及属性值,对于同一属性父类属性值不唯一的,对属性值进行合并;
步骤s52,通过逻辑归纳补全实体属性以及属性值,对于同类实体均包含的属性进行补全,对于同类实体同一属相的值均相同进行补全,但同类实体同一属相的值不同的仅补全属性;
步骤s53,通过关系传递补全实体间关系,首先对连接两个直接关系为空的实体间的所有关系链进行抽象关系传递,针对传递结果为真的关系链,通过构建的实例关系进行推理,若推理结果依旧存在于实例关系中,则将此实例关系补全为实体间关系;
步骤s54,冲突检测内容包括属性值冲突以及关系冲突;其中,属性值冲突包括:父类子类属性以及属性值不一致、同类公共属性值不一致、互斥类互斥属性值相同;关系冲突包括:关系链推理结果为非,以及相同关系链不同实体间结果不一致;
步骤s55,对于存在冲突的知识,计算其置信度;多个冲突知识中:若某条知识置信度为100,则标记为真,其余知识标记为假;若不存在置信度为100的知识,则将置信度高于预设阈值的知识标记为真,低于预设阈值的知识标记为假,其余标记为未知。
本发明的有益效果是:本发明通过有效准确的方法实现知识图谱的构建,在数据源足够支撑的情况下,使得覆盖公共安全领域的知识更加全面;同时,本发明具有很强的公共安全领域特色,对领域的描述更加深刻,与实际业务结合更加紧密;本发明具备较强的知识推理能力,以及较高的一致性和准确性,并且知识存储方式能够适应不同的数据规模。
附图说明
图1为本发明的公共安全知识图谱构建方法的流程图;
图2为本发明实施例提供的本体构建中类以及类层级的示意图;
图3为本发明实施例提供的本体构建中属性以及属性层级的示意图;
图4为本发明实施例提供的公共安全知识抽取的流程图;
图5为本发明实施例提供的公共安全知识图谱子图谱的示意图;
图6为本发明实施例提供的公共安全知识图谱存储架构的示意图;
图7为本发明实施例提供的公共安全知识图谱知识融合的流程图;
图8为本发明实施例提供的公共安全知识图谱知识加工的流程图。
具体实施方式
下面将结合附图对本发明作进一步说明。
请参阅图1,本发明的公共安全知识图谱构建的方法,包括:
步骤一,根据公共安全领域所涵盖的数据来源以及业务特征进行本体建模。建模内容包括:类以及类层次构建、关系以及关系关联构建、属性以及属性与类关联关系的构建。构建方式采用自顶向下与自底向上相结合的方式。包括:
步骤s11,采用自顶向下的构建方式进行类以及类层次的构建:采用公共安全“人、事、物、点、组织”基本要素作为基础类,再根据数据源特征以及实际业务,从基础类开始,以多叉树的结构进行展开,构建类之间的层级关系,直到最小粒度;类以及类层次关系构建完毕后,进一步的构建类的交叉关系,包括互斥、交集、并集、补集以及继承关系。如图2所示,本体构建中类以及类层级的构建方式,如下:
针对公共安全领域“人”这一要素进行类以及类层级构建。“人”这一类作为基础类。根据实际的公安业务,对“人”这一类继续进行展开,分为“重点人员”与“常住人口”,显然,“重点人员”与“常住人口”仅是“人”这一基础类下的子类的部分示例。对“重点人员”以及“常住人口”继续进行展开,“重点人员”划分为“涉毒人员”以及“在逃人员”,“常住人口”划分为“户籍人口”与“流动人口”。
步骤s12,采用自顶向下与自底向上相结合的方式进行关系以及关系关联的构建:首先通过自顶向下的方式对基础的抽象关系进行构建,包括从属关系、互斥关系、等价关系以及冲突关系;再采用自底向上的方式,对于关系型数据源抽取其关联外键构建实例关系,非关系型数据源采用语义依存构建实例关系,且每一种实例关系至少对应一种抽象关系。如图2中,进行类关系的构建。其中“人”基础类与“重点人员”以及“常住人口”为父类与子类,即关系为“所属”关系。其中,“户籍人口”为“常住人口”中拥有本地户籍的人口,“流动人口”为“常住人口”中外地户籍的人口,故“户籍人口”与“流动人口”相互不包含,即是“互斥”关系。
步骤s13,采用自底向上的方式进行实体与属性构建:对于关系型数据源直接从数据表字段中抽取实体与属性,而对于非关系型数据源则通过语义依存分析进行聚类分析抽取实体与属性,且每个属性至少对应一个实体,每个实体至少属于一个类。如图3所示,本体构建中属性以及属性层级的构建方式:
每个类均包含一套本类的属性以及属性层级,且子类可以继承父类的属性以及属性层级。所述类的属性划分为“唯一属性”与“非唯一属性”,所述“唯一属性”为属性值为唯一值的属性。其中“唯一属性”与“非唯一属性”又根据实际公共安全业务的需要,划分为“基础属性”、“社会属性”,“物品属性”等。示例中,“唯一属性”中“基础属性”又继续划分为“身份证号”以及“护照号”等。
步骤二,从当前公共安全数据源进行知识抽取。知识抽取的数据源包括关系型数据以及非关系型数据;由于关系型数据源具有很强的格式性和逻辑性,且准确度相对比较高。特别是数据仓库中,经过数据治理的关系型数据源,涵盖的数据范围广,数据分类明确且精确性高。所以关系型数据源作为公共安全知识图谱构建的主要数据源。
知识抽取的内容包含:实体、属性和关系。关系型数据源来自于各业务应用系统数据库,同时,围绕关系型数据源包含大量非关系型数据,如笔录、案情描述以及新闻舆情等。
其中,关系型数据源的知识抽取采用数据治理以及资源描述框架技术,非关系型数据源知识抽取采用文本语义分析提取技术;对于抽取实体、关系以及属性,根据不同的数据来源以及抽取方式标识置信度。
具体地,如图4所示,本发明实施例提供的一种知识抽取的流程图。针对进行知识抽取的数据源判断其属于关系型数据源以及非关系型数据源。由于,公共安全数据源中,笔录、案情描述等文档内容,部分存储在关系型数据库字段中,而部分人员、关系、轨迹等信息按照关系型数据库的导入格式存储在csv、excel文档中,故关系型数据源与非关系型数据源的界定不能以具体数据存储介质的类型进行界定,而需要根据实际的内容以及映射关系进行界定。置信度的计算中,数据仓库的数据源可以基本视为完全信任,置信度为100,各业务系统数据库的置信度根据实际的数据完善度进行计算;而非关系型数据源,依据具体的知识抽取结果的质量评估进行计算。
关系型数据源的知识抽取包括:信息映射、表主键抽取、表字段抽取以及表外键关联抽取。信息映射构建关系型数据源到知识图谱的映射关系,包括数据库地址、登陆信息的映射、数据表字段的映射、数据表关系的映射。由于关系型数据源存储中,主键通常为实体的唯一标识,所以通过所述表主键抽取进行实体的抽取。而且其他字段的内容,大部分是针对该条数据的描述,故通过所述表字段抽取获取实体属性。而各表数据的关系通常通过外键进行关联,故通过所述表外键关联抽取获取实体关系。
针对非关系型数据源的知识抽取,采用自动以及半自动的文本挖掘以及语义分析算法进行实体、属性以及关系的抽取。抽取步骤包括:实体识别、语义分析、属性抽取以及关系抽取。
实体识别中,由于公共安全数据源的特殊性,关系型数据源中包括了大量且可信性高的实体。故非关系型数据源的实体识别优先采用基于规则以及词典的方法,通过文本分词结果与关系型数据源实体名称的快速比对,进行实体的识别。同时,非关系型数据源中也包含了开放域的实体,需要通过基于统计机器学习的算法进行抽取,算法不限于tf-idf、lda等算法。
语义抽取在已抽取完成的实体的基础上,通过对中文语言结构的分析和识别,进一步提取实体的上下位关系以及语义依存关系,形成不同形式的依存句法,包括:主谓宾关系、动宾关系以及介宾关系等。通过不同的依存语法,确定其语义结构是实体属性或者是实体间关联关系。针对所述语义结构为实体属性的,进行属性抽取,针对所述语义结构为实体关系的,进行关系抽取。
由于关系型数据源与非关系型数据源的界定不能以具体数据存储介质的类型进行界定,且在存储层存在相互包含的关系。举例来说,在审讯笔录关系型数据表中,既包括笔录的具体内容,属于非关系型数据源,同时又包括了审讯开始/结束时间、审讯地点、审讯干警等信息,属于关系型数据源。故在完成知识抽取后,还需要通过信息关联,将非关系型数据源与关系型数据源的内容进行关联。在信息关联的同时,同时进行所述置信度的标注。
经所述知识抽取,获取一种公共安全知识图谱。如图5所示,本发明实施例提供的一种知识图谱子图谱的示意图。
通过对关系型数据源的抽取,获取了三个实体,“xx派出所”、“张xx”和“xx案件”,以及“xx派出所”的“名称”、“行政区划代码”、“地址”、“经度”,“纬度”等属性,“张xx”警官的“姓名”、“身份证”、“警官号”、“性别”、“职务”等属性,其中“身份证号”为唯一属性。同时,获取了“xx警官”侦办“xx案件”以及“xx案件”的“案发时间”、“案发地点”等信息。通过对非关系型数据源的抽取,通过对“xx案件”审讯笔录进行知识抽取,获取了“xx案件”中“涉案人员”、“涉案物品”等属性。
步骤三,通过图数据库、关系型数据库以及文档数据库相结合的方式对抽取的知识进行存储。由于公共安全数据量大、维度多的特点,仅靠图数据库是无法满足本实施例中所构建的知识图谱的存储要求的。故本实施例在公共安全知识图谱存储方面构建雪花型的存储模式,即以图数据库为中心,关系型数据库以及文档数据库作为外围数据存储的存储模式。
如图6所示,本发明实施例提供的一种公共安全知识图谱存储架构的示意图。其中以图数据库为中心,进行类以及类层级、实体、实体主要属性、关系、关系主要描述的存储;关系型数据库作为外围数据库,对实体的详细属性以及关系的详细描述进行存储;文档数据库由于适合文本的大批量存储以及快速的检索,用于对文本的关键词、概要以及文本原文进行存储。
上述的知识图谱存储的架构,不仅利用了图数据库对图快速、多层级的检索和表达能力,同时针对当前图数据库存储能力有限的特征进行了改进,将不影响图检索的实体详细属性和关系详细描述存储于关系型数据库中,将文档的关键词、概要以及原文存储与文档数据库中。
当进行知识挖掘时,首先通过图数据库进行相关实体、关系的检索,然后通过实体的唯一标识,从关系型数据库中获取实体的相信信息以及关系的详细描述。若设计到文本的,支持通过唯一标识、关键词等从文档数据库中快速检索文本内容,最后将检索结果合并返回,确保了数据查询的效率和整个知识图谱的响应速度。
步骤四,将从各数据源采集的知识进行知识融合。
通常情况下,由知识抽取构建的知识图谱,由于所涉及的公共安全数据源数据量大小不一、数据质量参差不齐以及同一信息可能在多个数据源中,使得所构建的知识图谱中存在大量冗余的实体、属性以及关系,同时,相同实体的不同表达信息可能被表达为不同实体。故需要通过知识融合步骤,对相同实体、相同实体的不同表达形式、相同实体不同属性、相同属性不同的值以及相同实体的不同关联关系进行融合。
如图7所示,公共安全知识图谱知识融合的流程图。知识融合指:通过实体链接标识相似实体,关联相同实体的不同表达形式;并对相同实体的不同属性或者相同实体相同属性不同的属性值进行合并,同时去掉重复的实体、属性以及关系;具体包括:
步骤s41,首先判断需要进行知识融合判断的实体是否属于同一大类,或者是否属于互斥类,显然,不属于同一大类的实体不可能为同一实体,互斥类相互不包含,也不可能存在一个实体同时属于两个互斥的类。
对于全部共同唯一性属性值完全相同的两个实体,判断其共同非唯一性属性的值,当非唯一性属性值相同率达到某一阈值后,标识为相同实体。
步骤s42,对于部分共同唯一性属性值完全相同的两个实体,标识为实体冲突关系。
步骤s43,对于共同唯一性属性值完全不同,但非唯一性属性值相同率达到某一阈值的两个实体,标识为相似实体。
步骤s44,对于步骤s41中相同的实体,判断当前实体与目标实体是否都存在某一属性,若存在,则将属性的值进行合并后去重,若不存在,则将当前实体的属性以及属性值添加到目标实体。
步骤s45,对于步骤s41中相同的实体,判断当前实体与目标实体是否存在关联到某实体的相同关系,若不存在,则将目标实体与某实体关联此关系;对于当前实体与目标实体与某实体关联关系存在冲突的,将当前实体与目标实体取消相同实体标识,标识为冲突实体。
步骤s46,对于步骤s45中完成关系合并的当前实体,删除其重复实体、属性以及关系。
通过上述融合,公共安全知识图谱已经初步具备了知识表达以及知识推理的能力,但是知识表达以及知识推理的能力还不够完善。因为,首先,部分可以通过已知知识推理出的确定的知识还未进行表达,同时,由于所述数据源类型繁多,质量参差不齐,可能存在知识冲突。而在公共安全领域,冲突的知识也许隐藏了案件侦破重要的线索,所以,对于冲突的知识,只能进行标识,不能删除。
步骤五,对完成知识融合的知识图谱进行知识加工。如图8所示,公共安全知识图谱知识加工的流程图,通过知识推理技术进行知识补全以及冲突检测。知识补全包括对实体属性、属性未知属性值以及实体间未知关系进行补全;知识补全通过知识推理技术实现,且补全的知识仅针对知识推理结果为真且置信度为100的结果。冲突检测中,对存在冲突的知识进行甄别,对于存在冲突的知识,标识信度较低的知识为逻辑非。包括:
步骤s51,通过属性继承通过父类实体补全子类实体属性以及属性值,对于多继承的子类,继承其所有父类的属性以及属性值,对于同一属性父类属性值不唯一的,对属性值进行合并。
步骤s52,通过逻辑归纳补全实体属性以及属性值,对于同类实体均包含的属性进行补全,对于同类实体同一属相的值均相同进行补全,但同类实体同一属相的值不同的仅补全属性;
步骤s53,通过关系传递补全实体间关系,首先对连接两个直接关系为空的实体间的所有关系链进行抽象关系传递,针对传递结果为真的关系链,通过构建的实例关系进行推理,若推理结果依旧存在于实例关系中,则将此实例关系补全为实体间关系。
步骤s54,冲突检测,内容包括属性值冲突以及关系冲突;其中,属性值冲突包括:父类子类属性以及属性值不一致、同类公共属性值不一致、互斥类互斥属性值相同等。关系冲突包括:关系链推理结果为非,以及相同关系链不同实体间结果不一致等。
步骤s55,冲突标识,对于存在冲突的知识,计算其置信度;多个冲突知识中:若某条知识置信度为100,则标记为真,其余知识标记为假;若不存在置信度为100的知识,则将置信度高于预设阈值的知识标记为真,低于预设阈值的知识标记为假,其余标记为未知。
以上实施例仅供说明本发明之用,而非对本发明的限制,有关技术领域的技术人员,在不脱离本发明的精神和范围的情况下,还可以作出各种变换或变型,因此所有等同的技术方案也应该属于本发明的范畴,应由各权利要求所限定。
- 还没有人留言评论。精彩留言会获得点赞!