基于YOLOv3多伯努利视频多目标检测跟踪方法与流程
本发明涉及基于yolov3多伯努利视频多目标检测跟踪方法,属于机器视觉、智能信息处理领域。
背景技术:
复杂环境下视频多目标跟踪应用领域中,除了存在光照变化、目标形变、目标被遮挡等问题,还存在目标数目未知、新生目标不确定、目标交叉或紧邻运动、目标消失及杂波干扰等复杂情况,一直是多目标跟踪领域中研究的难点和具有挑战性的问题。
针对视频多目标跟踪问题,早期主要采用基于数据关联的目标检测跟踪方法,先采用目标检测器对视频序列进行多目标检测,然后借助数据关联等技术完成对视频多目标跟踪。典型的数据关联如:多假设跟踪、联合概率数据关联、图分解、动态规划等,虽然这些方法在视频多目标跟踪中取得了一定的效果,但由于复杂的数据关联运算,一定程度上降低了算法的运算效率,此外,对数目未知且变化的多目标跟踪,存在目标数目及状态估计不准确的问题。
近年来,随机有限集(randomfiniteset,rfs)理论在对数目未知且变化的多目标跟踪中取得了一定优势,分别对目标状态和观测进行随机集建模,可避免复杂的数据关联运算。自mahler教授提出概率假设密度(probabilityhypothesisdensity,phd)和多伯努利(member)滤波器之后,随机有限集理论在目标跟踪领域得到了广泛地应用。概括来说,基于随机有限集理论的多目标跟踪算法主要包含两大类:基于概率假设密度(phd)/势概率假设密度(cphd)的多目标跟踪算法和基于多伯努利(member)/势均衡多伯努利(cbmember)的多目标跟踪算法。典型的闭合解有:粒子滤波phd/cphd、高斯混合phd/cphd、粒子滤波cbmember和高斯混合cbmember等。尤其是粒子多伯努利滤波(particlefiltermultiplebernoulli,pfmb)技术,借助多目标贝叶斯估计理论递推近似多目标状态集的后验概率密度,可提高对数目变化多目标的跟踪精度。但pfmb方法难以检测新生目标,且当多目标之间出现相互遮挡和干扰时,跟踪精度下降,甚至出现目标被漏估计的问题。
技术实现要素:
为了解决目前存在的现有目标跟踪方法无法检测新生目标以及当多目标之间出现相互遮挡和干扰时,跟踪精度下降,甚至出现目标被漏估计的问题,本发明提供了一种基于yolov3多伯努利视频多目标检测跟踪方法,所述方法检测跟踪过程中,采用yolov3技术检测视频的第k和k+1帧视频序列;记k时刻检测框个数为n,检测框状态集为
对于视频的初始帧,k=0,将已匹配的检测框作为初始的新生目标加入目标模板集和目标轨迹集中;对于视频的中间帧,k>0,利用检测框、目标轨迹信息和目标模板信息实现新生目标判定、丢失目标重识别和存活目标优化跟踪;其中,存活目标优化跟踪是在多伯努利滤波框架下,利用当前帧置信度大于给定置信度阈值tb的检测框信息,优化对应目标的跟踪过程。
可选的,所述对于视频的初始帧,k=0,将已匹配的检测框作为新生目标加入目标模板集和目标轨迹集中,包括:采用抗干扰的卷积特征表示第k帧和第k+1帧的检测框,分别记为
其中,
可选的,由于视频各帧中目标连续变化,假定同一个目标在相邻两帧不会出现特别大的位移变化,因此,在量测似然匹配的基础上,加入目标框的交并比iou作为限制:若两个检测框的交并比iou大于交并比阈值ti,则可判定两个检测框匹配;
从量测似然矩阵λ的每一行选择量测似然值最大、且大于似然阈值tl,同时交并比iou大于交并比阈值ti的两个检测框作为匹配结果,将最终匹配的检测框对作为初始的新生目标,并分配标签
可选的,所述对于视频的中间帧,k>0,利用检测框、目标轨迹信息和目标模板信息来实现新生目标判定、丢失目标重识别和存活目标优化跟踪,包括:对相邻的检测框进行匹配,确定新生目标与重识别目标的判定条件,再根据相邻帧的检测框、目标模板和存在目标轨迹来判定目标是否为新生目标、重识别目标或存在目标。
可选的,所述对相邻的检测框进行匹配,包括:
计算第k和k+1帧视频序列中检测框之间的量测似然矩阵λ,从量测似然矩阵λ的每一行选择量测似然值最大且大于似然阈值tl的两个检测框,若两个检测框的交并比iou大于交并比阈值ti,则可判定两个检测框匹配,假设第k帧中的第i个检测框与第k+1帧中的第j个检测框匹配,则为第k+1帧中匹配目标的标签赋值,即:
当存在目标轨迹集中没有与检测框匹配的目标,将检测框与目标模板进行匹配,判断是否为重新识别目标,如匹配上,则为重识别目标,否则为新生目标。若当前检测框在下一帧图像中不存在与之匹配的检测框,且目标模板与存在目标轨迹集中也不存在与之匹配的目标,则可判定该检测框为误检。
可选的,所述确定新生目标与重识别目标的判定条件包括:
假设条件:
(a)目标在第k-1帧没有被检测到,在第k和k+1帧被检测到;
(b)检测到的目标不在目标跟踪轨迹集中;
(c)检测到的目标也不在目标模板中;
若检测框目标满足条件(a)和(b),且不满足条件(c),则该目标为重识别目标;
若当前检测框目标同时满足(a)(b)(c),则判定该目标为新生目标。
可选的,若判断该目标为重识别目标,则将其重新加入到存在目标轨迹集中,继续跟踪;若判断该目标为新生目标,则分配标签
可选的,假设目标运动模型为随机游走模型,若当yolov3检测器检测到该目标,且其检测框置信度大于阈值tb,则:
否则:
其中,
可选的,在k-1时刻,采用多伯努利参数集
其中,
多目标概率密度预仍为多伯努利参数集,表示为:
其中,等式右边两项表示k时刻存活目标和新生目标的多伯努利参数集,
新生目标利用检测器的检测信息、存活目标信息和目标模板信息判断得出,新生目标的粒子根据新生目标参数直接采样获得;
存活目标多伯努利参数
其中
ps,k为k时刻目标存活概率。
可选的,检测跟踪过程中,当相邻两个目标框的交并比iou大于阈值ti时,判定这两个目标出现紧邻,且部分遮挡;
此时,(1)当目标没有被完全遮挡时,检测器检测出两个目标,采用更新机制对目标进行跟踪和模板更新;
(2)当只有一个目标能被检测器检测出来时,可判定另一个目标为被遮挡目标,提出对被遮挡目标,停止模板更新,采用该目标前两帧的位移差估计目标实时速度v与运动方向θ,对目标进行预测估计,目标框的大小保持不变;
(3)当两个目标都无法通过检测器检测出来时,依据目标与模板的量测似然判断被遮挡目标,与第(2)种情况中采用同样的方式处理被遮挡的目标;若目标在跟踪过程中消失或者跟丢,在目标分离或者重新出现时,根据检测结果与目标模板的匹配对目标进行重识别。
本发明有益效果是:
通过引入yolov3技术对视频序列中的多目标进行检测,并将其作为新生目标,考虑到检测中存在目标过检测或漏检测、以及检测结果不精确的问题,采用抗干扰的卷积特征对目标细节进行深度描述,并借助自适应pfmb方法进行目标状态精确估计,本发明中尤其是将检测结果与跟踪结果进行交互融合,以提高多目标状态的估计精度。本发明还针对yolov3在对复杂环境的视频多目标检测,同样会存在检测错误和检测结果不准确的问题,本申请在pfmb滤波框架下融入yolov3检测方法,既解决了pfmb方法中未知新生目标的估计问题、目标身份的识别问题,同时将检测置信度和滤波似然进行融合建模,也可以有效提高对复杂环境下数目变化的视频多目标跟踪精度。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
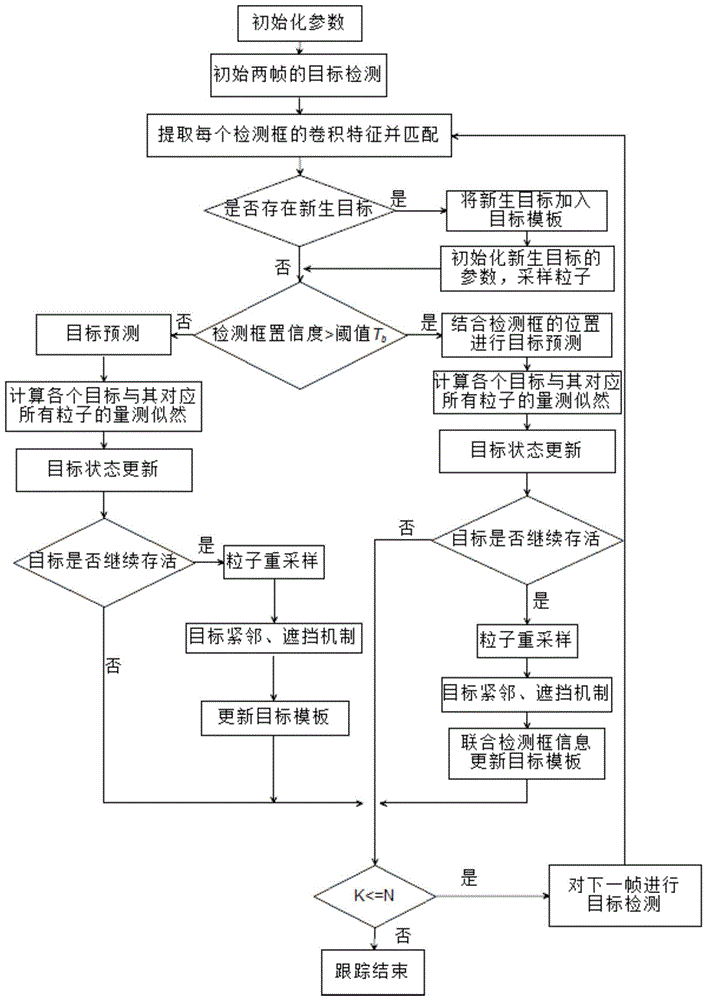
图1是本发明方法的整体流程图。
图2是yolov3工作原理示意图。
图3是yolov3的网络结构图。
图4是enterexitcrossingpaths1cor序列实验结果。
图5是enterexitcrossingpaths1cor序列实验目标数目估计对比图。
图6是enterexitcrossingpaths1cor序列实验ospa距离估计对比图。
图7是jogging序列的实验结果。
图8是jogging序列实验目标数目估计对比图。
图9是jogging列实验ospa距离估计对比图。
图10是subway序列实验结果。
图11是subway序列实验目标数目估计对比图。
图12是subway序列实验ospa距离估计对比图。
图13是human4序列实验结果。
图14是human4序列实验目标数目估计对比图。
图15是human4序列实验ospa距离估计对比图。
图16是suv序列实验结果。
图17是suv序列实验目标数目估计对比图。
图18是suv序列实验ospa距离估计对比图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
首先对本申请涉及的相关内容进行介绍如下:
1、多伯努利滤波原理
多伯努利滤波基于随机有限集(rfs)框架,在空间χ上,多伯努利随机有限集x可表示为
假设采用参数集
1.1预测
假设在k-1时刻,多目标的后验概率密度可表示为:
则预测后的多目标概率密度可表示为:
其中
<a,b>表示变量a和b的点积,fk|k-1(x|·)和ps,k分别表示单目标状态转移概率密度函数和目标存活概率。假设k时刻新生目标的多伯努利参数集为
1.2更新
k时刻,设多目标随机有限集的预测概率密度可表示为:
则更新后的后验多目标概率密度可表示为:
其中
ψk,z=gk(z|x)pd,k(x)
其中,gk(z|x)表示量测似然,pd,k(x)表示检测概率,zk表示量测集合,κk(z)表示杂波密度函数。
2、yolov3目标检测
yolov3的工作原理如图2所示。
yolov3采用darknet-53作为特征提取的网络,该网络结构如图3所示,由连续的3×3和1×1卷积层组成,融合残差网络(residualneuralnetwork,resnet)的残差块(residualblock),将整个网络分为多个子段逐阶段训练,采用shortcut的连接方式对每个子段的残差进行训练,从而达到总体残差最小。yolov3在三个不同尺度上预测边界框,每个尺度预测3个边界框,尺度内进行局部特征交互,在基础网络之后,添加一系列卷积层得到特征图(featuremap),在此基础上,进行位置回归与分类,此过程为最小尺度预测;将上一尺度中的卷积层上采样与最后一个16×16大小的特征图连接,再次通过多个卷积后输出预测信息;同理,将中间尺度的卷积层上采样与最后一个32×32大小的特征图连接,经过一系列卷积得到最大尺度上的边界框预测。
yolov3采用fasterr-cnn中锚框(anchorbox)的思想,通过k-means聚类的方法生成9个边界框的先验,每个尺寸各预测3个边界框。yolov3将图像划分为g×g个网格,则每个尺度预测的张量为g×g×[3*(4+1+80)],其中数字3表示3个预测边界框,数字4表示每个预测边界框包含4个偏移值(tx,ty,tw,th),(tx,ty,tw,th)为预测边界框中心坐标偏移值和宽、高的偏移值,数字1表示边界框的置信度(confidencescore),数字80表示预测边界框属于80类物体条件类别概率pr(classi/object)。根据网格与图像左上角坐标的偏移值(px,py)和边界框先验的宽pw、高ph得到边界框中心坐标(bx,by)和宽bw、高bh的预测值,即:
bx=δ(tx)+cx
by=δ(ty)+cy
边界框在训练时采用平方误差损失的总和。边界框的置信度由边界框包含目标的可能性pr(object)和边界框的准确度
若边界框中不包含物体,pr(object)的值为0,置信度为0,否则pr(object)的值为1,置信度为预测框与真实框之间的交并比。条件类别概率pr(classi/object)表示在边界框包含目标的前提下,它属于某个类别的概率。yolov3联合条件类别概率和边框置信度,得出边界框类别置信度(classspecificconfidencescores,c)来表示边界框包含目标归类于每个类别的可能性和边界框与目标匹配的好坏,边框类别置信度可表示为:
实施例一:
本实施例提供一种基于yolov3多伯努利视频多目标检测跟踪方法,参见图1,所述方法包括:
步骤一:初始化
1.1参数初始化,初始时刻k=0,视频总帧数为n,初始化采样粒子最大数目为lmax,粒子最小数目为lmin,初始目标存在概率ps=0.99。
1.2目标检测,
采用yolov3技术检测第k和k+1帧视频序列,记k时刻检测框个数为n,检测框状态集为
1.3初始帧目标框匹配
k=0时,采用抗干扰的卷积特征表示第k帧和第k+1帧的检测框,分别记为
其中,
步骤二:目标新生与重识别
当k>0时,根据相邻帧的检测框、目标模板和存在目标轨迹来判定目标是否为新生目标、重识别目标或存在目标。
2.1检测框匹配
计算第k和k+1帧视频序列中检测框之间的量测似然矩阵λ,从量测似然矩阵λ的每一行选择量测似然值最大且大于似然阈值tl的两个检测框,若两个检测框的交并比iou大于交并比阈值ti,则可判定两个检测框匹配,假设第k帧中的第i个检测框与第k+1帧中的第j个检测框匹配,则为第k+1帧中匹配目标的标签赋值,即:
当存在目标轨迹集中没有与检测框匹配的目标,将检测框与目标模板进行匹配,判断是否为重新识别目标,如匹配上,则为重识别目标,否则为新生目标。若当前检测框在下一帧图像中不存在与之匹配的检测框,且目标模板与存在目标轨迹集中也不存在与之匹配的目标,则可判定该检测框为误检。
2.2新生目标与重识别目标判断
条件假设:
(a)目标在第k-1帧没有被检测到,在第k和k+1帧被检测到;
(b)检测到的目标不在目标跟踪轨迹集中;
(c)检测到的目标也不在目标模板中;
若检测框目标满足条件(a)和(b),且不满足条件(c),则该目标为重识别目标,并将其重新加入到存在目标轨迹集中,继续跟踪。
若当前检测框目标同时满足(a)(b)(c),则判定该目标为新生目标,分配标签
步骤三:目标预测
3.1目标运动模型
假设目标运动模型为随机游走模型,若当yolov3检测器检测到该目标,且检测框置信度大于阈值tb,则:
否则:
其中,
3.2目标预测
在k-1时刻,采用多伯努利参数集
其中,
多目标概率密度预仍为多伯努利参数集,表示为:
其中,等式右边两项表示k时刻存活目标和新生目标的多伯努利参数集,
新生目标利用检测器的检测信息、存活目标信息和目标模板信息判断得出,新生目标的粒子根据新生目标参数直接采样获得。存活目标多伯努利参数
其中
ps,k为k时刻目标存活概率。
步骤四:量测似然计算
4.1目标卷积特征提取
将目标框的尺寸规范化为n×n,并转化为灰度图像,记为i,使用大小为w×w的滑动窗口,以步长为δ对目标图像进行卷积操作,得到目标图像块集合y={y1,y2,...,yl},其中yi∈rw×w,l=(n-w+δ)×(n-w+δ),将每块减去自身均值并二范数归一化处理,采用k-means算法选出d个子块
目标模板建立时,在目标附近随机平移目标框来采集m个背景样本,要求平移值大于目标框宽和高的1/4,与目标特征采集时使用同样预处理操作,使用k-means算法选取d个特征小块,第i个背景样本的特征子块集合为
将其与图像i做卷积操作,得到背景在图像上的特征图:
用目标特征图
将d个特征图按行展开,成为d个一维向量,并按顺序拼接,最终得到目标的卷积特征
4.2特征的稀疏表示
将特征图集s看作三维的张量c∈r(n-w+1)×(n-w+1),对张量进行稀疏化表示凸显目标的特征,利用稀疏向量f去逼近vec(c),使以下目标函数最小化:
其中,vec(c)是通过串联c中所有元素的列向量,
其中,λ是张量c的中位数。
4.3计算量测似然
两个目标框的量测似然计算公式为:
其中f1,f2为对应的目标框卷积特征,在计算粒子与目标的量测似然时,利用目标对应的目标特征图集和背景特征图集来计算粒子对应的卷积特征:
其中il为粒子表示的候选框的规范化之后的图像。将si按行展开,得到d个一维向量,顺序连接为最终粒子对应候选框的特征fl。
步骤五:目标状态更新
5.1状态更新
k时刻,假设视频多目标随机有限集的预测概率密度可表示为:
则更新后的多目标后验概率密度可表示为:
其中,
其中
5.2粒子重采样
为了防止粒子出现退化,本发明采用随机重采样方式对采样粒子集进行重采样,利用采样粒子更新之后的权值,对采样粒子加权求和来估计当前时刻的目标状态集sk。
步骤六:目标紧邻和遮挡处理机制
当相邻两个目标框的交并比iou大于阈值ti时,可判定这两个目标出现紧邻,且部分遮挡,此时,检测器可能出现三种情况:
1)当目标没有被完全遮挡时,检测器可能检测出两个目标,本发明方法中提出采用更新机制对目标进行跟踪和模板更新;
2)只有一个目标能被检测器检测出来时,可判定另一个目标为被遮挡目标,提出对被遮挡目标,停止模板更新,采用该目标前两帧的位移差估计目标实时速度v与运动方向θ,对目标进行预测估计,目标框的大小保持不变;
3)两个目标都无法通过检测器检测出来时,依据目标与模板的量测似然判断被遮挡目标,与第二种情况中采用同样的方式处理被遮挡的目标。若目标在跟踪过程中消失或者跟丢,在目标分离或者重新出现时,可根据检测结果与目标模板的匹配对目标进行重识别。
步骤七:目标模板更新
目标运动过程中,周围环境及自身状态会不断发生变化,如背景变化、自身扭曲、旋转及尺度变化等,因此,需要对目标模板进行实时更新,本发明综合考虑采用存在目标轨迹、目标模板和目标检测结果进行融合更新目标模板,即:
其中,ρ为模板的学习速率,fk和fk-1分别为k和k-1时刻的目标模板,
为验证本申请提出的上述基于yolov3多伯努利视频多目标检测跟踪方法的效果,特实验如下:
1、实验条件及参数
本发明采用的视频序列数据为visualtrackerbenchmarktb50中的序列huamn4,visualtrackerbenchmarktb100中的序列jogging、subway、suv,以及cavuar数据集中的序列enterexitcrossingpaths1cor,这5组典型视频序列分别来源于不同场景,且包含动态背景、目标紧邻、目标形变、图片模糊、目标尺寸变化、目标遮挡等干扰情况。实验中采用的评价指标为多目标跟踪正确度(multipleobjecttrackingaccuracy,mota)、多目标跟踪精度(multipleobjecttrackingprecision,motp)、轨迹完整目标数目(mostlytracked,mt)、标签跳变数(identityswitch,ids),分别定义如下:
1)多目标跟踪正确度(mota)
其中,mt为第t帧中被跟丢的目标数量,fpt为第t帧误检的目标数,mmet为第t帧中跟踪轨迹中目标标签发生跳变的数目,gt表示第t帧中目标的实际个数。
2)多目标跟踪精度(motp)
其中,
3)轨迹完整目标数目(mt),表示目标跟踪轨迹占真实轨迹长度80%以上的目标轨迹数目,刻画了轨迹的完整程度。
4)标签跳变数(ids),表示跟踪过程中目标标签发生变化的次数。
2、实验及结果分析
本申请方法采用matlab2016a实现,在处理器为intelcorei7-8700、3.2ghz,12核,内存为16gb,显卡为nvidiageforcegtx1080ti的工作站上运行,并与传统的粒子多伯努利滤波(pfmb)方法和2017年erikbochinski等在发表论文《high-speedtracking-by-detectionwithoutusingimageinformati》中提出的iou-tracker方法进行性能比较与分析。由于传统pfmb方法中,缺少对新生目标检测机制,本实验中也采用yolov3进行检测,并将判定为新生目标的检测结果作为pfmb的新生目标,然后进行跟踪。
具体实验从四个方面对发明方法进行性能评估,即:目标重识别、目标紧邻与遮挡、图像模糊与目标形变、目标大位移等,实验结果如下。
实验一:目标重识别
本实验采用的视频序列为cavuar数据集中enterexitcrossingpaths1cor序列,该序列包含383帧图像,存在目标紧邻和较长时间的目标遮挡问题,同时伴随目标逐渐出现导致形变较大的情况。由于较长时间遮挡,很容易导致目标跟丢,本发明融合检测器结果、存在目标轨迹和目标模板能够实现对目标的重识别,将目标重新加入到跟踪轨迹中。
图4给出了enterexitcrossingpaths1cor序列实验结果,其中,图4(a)为yolov3算法检测结果,图4(b)为传统pfmb方法跟踪结果,图4(c)为iou-tracker方法跟踪结果,图4(d)为本发明方法的跟踪结果。可以看出,当目标被遮挡时,检测器可能无法检测出被遮挡目标,大幅度降低检测效果,如图4(a)中第93帧,采用传统的pfmb方法,存在遮挡时,目标被跟丢;由于iou-tracker完全抛弃使用图像信息,只利用目标检测结果进行跟踪处理,所以该方法也无法继续跟踪漏检目标,当目标再次被检测到时,将会被定义为新目标,难以与历史目标关联;而本发明方法,较长时间被遮挡的目标,由于存在概率逐渐降低导致目标消失,但当目标再次出现时,能有效地进行重识别,重新加入到目标跟踪轨迹中。
图5为enterexitcrossingpaths1cor序列实验目标数目估计对比图,图6为enterexitcrossingpaths1cor序列实验ospa距离估计对比图,可以看出,传统的pfmb方法缺少目标遮挡处理机制,在目标被遮挡后,容易出现误跟和漏跟情况,导致跟踪框偏离较大,ospa值上升;iou-tracker方法受检测器性能影响,目标被遮挡过程中,目标数目减少,ospa值急剧上升,本发明方法处理长时间被遮挡目标时,也可能出现目标丢失的情况,当目标脱离遮挡后,能有效地对丢失目标进行重识别,整体跟踪性能优于传统pfmb方法和iou-tracker方法。尤其从表1所示的mota、motp、mt、ids四个评价指标可以看出。
表1为50次蒙特卡洛仿真结果,可以看出,传统pfmb方法的指标mota、motp、mt的值最低,ids为1,是因为该方法缺少目标重识别过程,导致目标被跟丢后,再重新出现时将无法与之前的轨迹关联上,从而会出现标签跳变情况。iou-tracker方法在目标紧邻或遮挡时,目标标签将会出现频繁跳变,导致ids的值最高。而本发明方法能有效地对目标进行重识别,减少目标标签跳变的问题,有效减少轨迹碎片。
表1目标重识别跟踪性能评价(表中↑表示值越大越好,↓表示值越小越好)
实验二:目标紧邻与遮挡
采用视频序列为visualtrackerbenchmarktb100数据集中的jogging序列、subway序列。jogging序列为相机移动的路口场景,包含3个运动目标,存在目标被遮挡的情况。subway序列包含8个目标,存在多个目标紧邻和频繁被遮挡等问题。
jogging序列的实验结果如图7所示,其中,图7(a)为yolov3算法检测结果,图7(b)为传统pfmb方法跟踪结果,图7(c)为iou-tracker方法跟踪结果,图7(d)为本发明方法的跟踪结果。可以看出,yolov3检测器难以正确检测出被遮挡目标,iou-tracker方法丢失漏检目标,当目标脱离遮挡状态时,iou-tracker方法将重新检测到的目标定义为新的目标,传统的pfmb方法即使没有丢失目标,但是跟踪框的偏离程度却增大,而本发明的方法能很好地融合目标的检测结果和跟踪结果,实现对跟踪框进行调整,可以获得比较准确的跟踪结果。
图8给出了jogging序列实验目标数目变化估计对比图,其中传统pfmb方法与本发明方法的目标数目变化一致,图9给出了jogging序列实验ospa距离估计对比图,可以看出,yolov3检测器存在漏检,导致iou-tracker方法目标数目估计不准确,出现漏估计减少,ospa值急剧上升较大,精度不高;传统pfmb方法在目标被遮挡后,跟踪框的偏离程度增加,导致ospa值上升增大,而本发明方法具有较好抗遮挡能力,跟踪性能明显优于传统pfmb方法与和iou-tracker方法。
subway序列的实验结果如图10所示,其中,图10(a)为yolov3算法检测结果,图10(b)为传统pfmb方法跟踪结果,图10(c)为iou-tracker方法跟踪结果,图10(d)为本发明方法的跟踪结果。可以看出,当多个目标邻近或相互遮挡的时候,检测器难以检测到被遮挡目标或者检测结果偏差较大,导致iou-tracker方法频繁丢失目标,传统的pfmb方法处理遮挡、紧邻问题时,也会出现较大的偏差,甚至跟丢,如图10(b)中第17、19帧,而本发明方法能够较好地对被遮挡目标进行跟踪。
图11给出subway序列目标数目估计对比图,图12给出了subway序列ospa距离估计对比图。可以看出,由于yolov3检测器难以检测到部分出现和被遮挡目标,所以iou-tracker方法目标数目变化大,ospa值较高,传统的pfmb方法在跟踪过程中丢失目标,ospa值突增,而本发明方法能够较好地处理目标遮挡问题,具有较高的跟踪精度。
进行50次蒙特卡洛仿真,jogging序列跟踪的量化统计结果如表2.1所示。可以看出,虽然传统pfmb方法与本发明方法的多目标跟踪正确度mota相当,但遮挡恢复后,传统pfmb方法的跟踪框会出现偏差,导致跟踪误差偏大,所以motp值比本发明方法要小。此外,由于检测器对被遮挡目标检测效果差,且该序列中两个目标一直处于紧邻状态,所以iou-tracker方法在对存在紧邻的序列jogging上跟踪精度较低,且目标标签出现频繁跳变。
subway序列的定量分析结果如表2.2所示,该序列中,多个目标也长期处于互相遮挡、紧邻状态,本发明方法在mota、motp、mt、ids上都明显要优于传统pfmb方法与iou-tracker方法。
表2.1jogging序列目标紧邻与遮挡
表2.2subway序列目标紧邻与遮挡
实验三:图像模糊与目标形变
采用视频序列visualtrackerbenchmarktb50数据集中的human4序列,该序列共包含667帧图像,为相机移动红绿灯路口场景,其中,包括三种类型17个目标,视频中存在由于相机运动或目标快速运动等造成的目标模糊情况,且存在许多目标频繁发生形变问题。
图13为human4序列实验结果,其中,图13(a)为yolov3算法检测结果,(b)为传统pfmb方法跟踪结果,(c)为iou-tracker方法跟踪结果,(d)为本发明方法的跟踪结果。可以看出,图片模糊可能导致检测器性能下降,部分目标被漏检,如图13(a)中第50帧、第74帧。目标形变对检测器的性能影响较小,虽然,传统pfmb方法能跟上目标,但部分目标的跟踪框会出现偏离,而本发明方法能够较好地处理这两种情况,具有较高的跟踪精度。
图13给出human4序列目标数目估计对比图,图14给出了human4序列ospa距离估计对比图。可以看出,本发明方法能较好的处理图像模糊与目标形变问题,跟踪性能优于传统的pfmb方法和iou-tracker方法。
进行50次蒙特卡洛仿真,定量分析结果如表3所示。可以看出,由于频繁的目标形变、图像模糊而导致传统pfmb方法中出现目标漏跟或仅跟踪到目标的部分区域,导致mota、motp、mt的值都比较低;iou-tracker方法能较好地利用检测器的检测结果,所以,motp值与本发明方法相当,而目标尺寸变化和图像模糊导致检测器性能下降,存在部分目标被漏检,使得mota值偏小,ids值最大,即存在大量目标标签跳变,航迹估计不准确。本发明方法能较好地对检测框进行关联,有效减少目标标签的跳变,在ids上明显优于iou-tracker。
表3目标模糊与形变跟踪性能评价
实验四:目标大位移
实验中采用视频序列visualtrackerbenchmarktb100数据集中的suv序列,该序列共包含400帧图像,为相机移动动态背景的公路场景,包含6个目标,存在快速运动导致的大位移情况。
图16给出了suv序列实验结果,其中,图16(a)为yolov3算法检测结果,图16(b)为传统pfmb方法跟踪结果,图16(c)为iou-tracker方法跟踪结果,图16(d)为本发明方法的跟踪结果。可以看出,目标的大位移对检测器没有影响,iou-tracker方法表现良好,而传统pfmb方法会出现目标跟丢的情况,本发明方法由于利用检测器的结果去调整跟踪过程,对于较大位移的目标跟踪结果也明显要优于另外两种方法。
图17为suv序列目标数目估计对比图,图18为suv序列ospa距离估计对比图。可以看出,传统的pfmb方法由于缺少对目标大位移的处理机制,所以,当目标位移较大时,可能出现目标丢失或跟踪框偏离较大的情况,导致ospa值较大,而iou-tracker方法与本发明方法能利用检测器结果提高对目标大位移的处理能力,具有较好的跟踪精度。
进行50次蒙特卡洛仿真,定量分析结果如表4所示。对大位移目标进行跟踪,传统的pfmb方法容易出现漏跟、位置偏移过大的情况因此,四个评价指标结果都比较差;由于视频序列也还存在目标遮挡和紧邻等情况,导致iou-tracker方法跟踪结果中,目标标签也出现频繁的跳变情况,所以mota值偏低,ids值偏高。而本发明方法能融合检测结果有效地处理目标大位移情况,在各项指标上都明显优于传统pfmb方法,在mota,mt,ids上也明显优于iou-tracker方法。
表4目标模糊与形变跟踪性能评价
通过上述实验可知,本申请提供的基于yolov3多伯努利视频多目标检测跟踪方法,通过将检测结果与跟踪结果进行交互融合,在目标重识别过程中,对于较长时间被遮挡的目标,当其再次出现时,能有效地进行重识别;而对于存在多个目标紧邻和频繁被遮挡情况时,本申请提出的方法能够融合目标的检测结果和跟踪结果,实现对跟踪框进行调整,获得比较准确的跟踪结果;而对于存在图像模糊与目标形变情况时,本申请提出的方法能够较好地对检测框进行关联,有效减少目标标签的跳变;而对于存在目标大位移情况时,本申请提出的方法能够利用检测器的结果去调整跟踪过程,从而防止出现目标跟丢的情况发生。
本发明实施例中的部分步骤,可以利用软件实现,相应的软件程序可以存储在可读取的存储介质中,如光盘或硬盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!