一种turbo码译码系统及译码方法与流程
本发明实施例涉及turbo码译码技术,尤其涉及一种turbo码译码系统及译码方法。
背景技术:
turbo(特博)码是一种有效且常用的信道编码方法,turbo码具有接近香农(shannon)理论极限的性能。在深空通信、卫星通信、多媒体通信以及无线移动通信系统中的应用越来越广泛。
图1为现有技术中turbo码译码系统的结构示意图,如图1所示,输入数据包括系统信息x和两个校验信息y1,y2。现有技术的方法通过两个软输入软输出(softinputsoftoutput,siso)译码器对输入数据进行交织迭代完成译码过程。
以四路并行正向反向递推处理为例,传统的输入数据存储方式,会把输入数据分成4段并分别顺序存储,从每一段中分别取数据,完成4路并行处理。由于正向递推反向递推同时进行,需要使用双口随机存取存储器(randomaccessmemory,ram)存储输入数据;另外两次siso译码计算需要分别存储系统信息x交织前和交织后的数据,译码实现过程中所需存储空间较大。
技术实现要素:
本发明提供一种turbo码译码系统及译码方法,以减小译码过程中所需存储空间。
第一方面,本发明实施例提供了一种turbo码译码系统,所述系统包括:输入数据存储器、第一译码器、第二译码器和交织迭代模块;其中,
所述输入数据存储器用于存储待译码系统数据;其中,所述系统数据平分为n段,各段对应位置的数据构成一个分组,所述系统数据以分组为单位存储于所述输入数据存储器的n个子存储器中,所述系统数据的前半部分顺序间隔存储于前n/2个子存储器中,所述系统数据的后半部分倒序间隔存储于后n/2个子存储器中,n为大于等于2的偶数;
所述第一译码器用于获取所述n个子存储器中相应位置的分组数据,并根据第一校验信息和获取的所述分组数据计算第一外信息;
所述第二译码器用于按第一交织地址读取所述输入数据存储器中的系统数据,并根据第二校验信息和读取的所述系统数据计算第二外信息,其中,所述第一交织地址对应于所述系统数据的n个位于不同子存储器的分组;
所述交织迭代模块用于对所述第一外信息和第二外信息进行交织迭代,完成对所述系统数据的译码。
第二方面,本发明实施例还提供了一种turbo码译码方法,所述方法包括:
存储模块将待译码系统数据存储于输入数据存储器中;其中,所述系统数据平分为n段,各段对应位置的数据构成一个分组,所述系统数据以分组为单位存储于所述输入数据存储器的n个子存储器中,所述系统数据的前半部分顺序间隔存储于前n/2个子存储器中,所述系统数据的后半部分倒序间隔存储于后n/2个子存储器中,n为大于等于2的偶数;
第一译码器获取所述n个子存储器中相应位置的分组数据,并根据第一校验信息和获取的所述分组数据计算第一外信息;
第二译码器按第一交织地址读取所述输入数据存储器中的系统数据,并根据第二校验信息和读取的所述系统数据计算第二外信息,其中,所述第一交织地址对应于所述系统数据的n个位于不同子存储器的分组;
交织迭代模块对所述第一外信息和第二外信息进行交织迭代,完成对所述系统数据的译码。
本发明实施例提供了一种turbo码译码系统,所述的译码系统包括输入数据存储器、第一译码器、第二译码器和交织迭代模块,通过所述输入数据存储器按照预设的存储格式存储系统数据,使得采用单口ram即可完成正反向递推,同过所述第二译码器按照第一交织地址读取系统数据,使得无需预先存储系统数据交织后的数据,从而减小了译码过程中所需的存储空间。
附图说明
图1为现有技术中turbo码译码系统的结构示意图;
图2是本发明实施例一提供的一种turbo码译码系统的结构图;
图3a是现有技术中的第一段系统数据存储格式示意图;
图3b是现有技术中的第二段系统数据存储格式示意图;
图3c是现有技术中的第三段系统数据存储格式示意图;
图3d是现有技术中的第四段系统数据存储格式示意图;
图4a-图4b是本发明实施例一提供的正向递推系统数据存储格式示意图;
图4c-图4d是本发明实施例一提供的反向递推系统数据存储格式示意图;
图5是本发明实施例二提供的一种turbo码译码系统的结构图;
图6是本发明实施例三提供的一种turbo码译码系统的结构图;
图7是本发明实施例四提供的一种turbo码译码方法的流程图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
实施例一
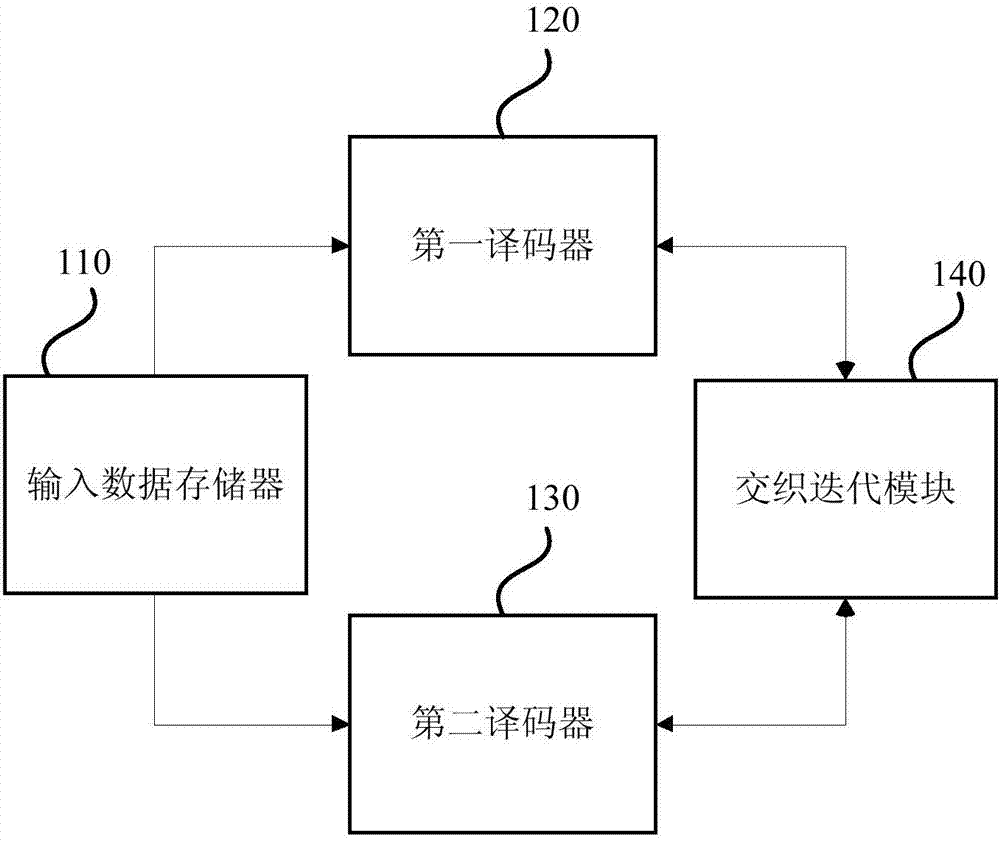
图2是本发明实施例一提供的一种turbo码译码系统的结构图,如图2所示,所述turbo码译码系统具体可以包括:输入数据存储器110、第一译码器120、第二译码器130和交织迭代模块140;其中,
输入数据存储器110用于存储待译码系统数据;其中,所述系统数据平分为n段,各段对应位置的数据构成一个分组,所述系统数据以分组为单位存储于输入数据存储器110的n个子存储器中,所述系统数据的前半部分顺序间隔存储于前n/2个子存储器中,所述系统数据的后半部分倒序间隔存储于后n/2个子存储器中,n为大于等于2的偶数;
第一译码器120用于获取所述n个子存储器中相应位置的分组数据,并根据第一校验信息和获取的所述分组数据计算第一外信息;
第二译码器130用于按第一交织地址读取输入数据存储器110中的系统数据,并根据第二校验信息和读取的所述系统数据计算第二外信息,其中,所述 第一交织地址对应于所述系统数据的n个位于不同子存储器的分组;
交织迭代模块140用于对所述第一外信息和第二外信息进行交织迭代,完成对所述系统数据的译码。
其中,第一译码器120和第二译码器130可以为siso译码器。示例性的,以对系统数据x1-x6144进行四路并行正向反向递推处理为例,现有技术中将x1-x6144平分为x1-x1536、x1537-x3072、x3073-x4608和x4609-x6144四段,每一段数据分别顺序存储于一个子存储器中,第一段数据到第四段数据在4个子存储器中的存储格式见图3a到图3d。具体的,正向递推过程对每一数据段从前向后取数,反向递推过程对每一数据段从后向前取数。在正向递推过程中,分别从每一子存储器相应的位置读取一个数,如x1、x1537、x3073和x4609,完成四路并行正向递推。在反向递推过程中,分别每一子存储器相应的位置读取一个数,如x1536、x3072、x4608和x6144,完成四路并行反向递推。由于正向递推和反向递推需要同时进行,现有技术的数据存储格式必须采用双口ram对系统数据进行存储。
本实施例提供了一种新的系统数据存储格式,将所述四段数据每段对应位置的数据,如x1、x1537、x3073和x4609分为一个分组,以分组为单位将系统数据存储于输入数据存储器110的4个子存储器中,每一段数据的前半部分即x1-x768、x1537-x2304、x3073-x3840和x4609-x5376顺序间隔存储于前2个子存储器中,每一段数据的后半部分倒序间隔存储于后2个子存储器中。具体存储方式参见图4a到图4d,每一个图对应一个子存储器。其中,图4a和图4b对应的两个子存储器中存数的数据用于正向递推,图4c和图4d对应的两个子存储器存储的数据用于反向递推。依次获取所述4个子存储器中相应位置 的分组数据即可同时完成正向递推和反向递推。采用本实施例所述的系统数据存储结构,在进行四路并行正反向递推时,输入数据存储器110采用单口ram即可实现正反向递推数据的读取,节省了存储资源。
另外,现有技术在第二译码器130进行译码计算时,需要预先存储系统数据交织后的数据,然后第二译码器130读取交织后的数据完成译码,系统数据以及交织后系统数据的存储需要8块12*768的双口ram。本实施例中第二译码器130在译码计算时按第一交织地址直接读取输入数据存储器110中的系统数据,无需存储交织后的系统数据,只需4块24*384的单口ram即可,节省了一半的存储空间。
具体的,以采用基四算法为例,每一次译码分别从每一个子存储器中读出4路并行的4个系统数据,其中第一译码器120分别从4个子存储器相应的位置读出一组分组数据,即4*4=16个数据。第二译码器130则需要按照交织后的顺序读出16个数据,即按照第一交织地址读出16个数据。本实施例中的所述第一交织地址对应于所述系统数据的4个位于不同子存储器的分组,这样可以保证,交织后的数据还保持在输入数据存储器110中的分组,即原来属于同一分组的四路并行的数据在交织后仍然按照原来的次序并行,仍属于同一分组,;并且所述第一交织地址保证交织后4组数分别位于4个子存储器中。这样,第二译码器130可以直接按照所述第一交织地址由输入数据存储器110中读取系统数据,完成交织过程,无需预先存储交织之后的数据,节省了译码过程所需的存储空间。
本实施例的提供了一种turbo码译码系统,所述的译码系统包括输入数据存储器、第一译码器、第二译码器和交织迭代模块,通过所述输入数据存储器按 照预设的存储格式存储系统数据,使得采用单口ram即可完成正反向递推,同过所述第二译码器按照第一交织地址读取系统数据,使得无需预先存储系统数据交织后的数据,从而减小了译码过程中所需的存储空间。
实施例二
本实施例以上述实施例为基础,提供了一种turbo码译码系统。图5是本发明实施例二提供的一种turbo码译码系统的结构图,如图5所示,所述的译码系统的第二译码器130包括:第一交织地址发生器210、交织地址存储器220和译码单元230;其中,
第一交织地址发生器210用于在正向递推过程中,计算正向交织地址,并根据所述正向交织地址读取所述系统数据;在反向递推过程中,读取交织地址存储器220中存储的部分反向交织地址,并根据所述部分反向交织地址读取所述系统数据;译码单元230用于根据所述第二校验信息和读取的所述系统数据获得第二外信息。
可选的,第一交织地址发生器210还用于:根据所述部分反向交织地址计算剩余部分的反向交织地址,并存储到交织地址存储器220中。
其中,传统的turbo译码系统因为需要正向和反向递推,需要存储完整的交织地址,若具有6144个系统数据,则存储交织地址所需存储空间为13*6144。具体的,在正向递推的过程中,第一交织地址发生器210按照交织地址计算方法,实时计算正向交织地址,并按照所述正向交织地址读取输入数据存储器110中的系统数据完成数据交织过程。在反向递推计算过程中,需要按反向交织地址读取所述系统数据,为了减少交织地址存储资源,反向交织地址可以采取实 时计算和部分存储相结合的方式,即交织地址存储器220可以采用乒乓结构。示例性的,可以提前在交织地址存储器220的一块ram中存储m个反向交织地址,供反向递推使用;在使用这m个反向交织地址的同时,第一交织地址发生器210通过正向递推公式计算后m个反向交织地址,存储在交织地址存储器220的另一块ram中,反向递推和交织地址计算交替进行,其中m的数值可以根据第一交织地址发生器210的计算速度设定,只需满足在使用完交织地址存储器220中存储的m个反向交织地址时,后m个交织地址能够计算完成即可,示例性的m可以取104。本实施例的方案仅需13*m*2的存储空间来存储交织地址,大大节省了译码过程中所需要的存储空间。
本实施例的提供了一种turbo码译码系统,所述的译码系统的第二译码器包括第一交织地址发生器、交织地址存储器和译码单元,通过交织地址存储器存储部分反向交织地址,并通过第一交织地址发生器实时计算剩余部分的反向交织地址,减小了译码过程中所需的存储空间。
实施例三
本实施例以上述实施例为基础,提供了一种turbo码译码系统。图6是本发明实施例三提供的一种turbo码译码系统的结构图,如图6所示,所述译码系统的交织迭代模块140可以包括:第二交织地址发生器310,用于计算第二交织地址;外信息存储器320,用于存储所述第一外信息和第二外信息。
其中,第二交织地址发生器310按照顺序或按第二交织地址将所述第一外信息和第二外信息存储于外信息存储器320中,或由外信息存储器320中读出所述第一外信息和第二外信息。
具体的,第二交织地址发生器310具体用于:将所述第一外信息顺序写入外信息存储器320;按照第二交织地址,从外信息存储器320中读出所述第一外信息,并输入第二译码器130;按照第二交织地址,将所述第二外信息写入外信息存储器320;从外信息存储器320中顺序读出所述第二外信息,并输入第一译码器120。
其中,因为所述第一外信息和第二外信息同时是第一译码器和第二译码器的输入数据或输出数据,现有技术中会分别存储第一外信息和第二外信息。对于6144个系统数据,第一外信息和第二外信息所需的存储空间为6*6144*2。本实施例提供的译码系统,可以对外信息存储器320的读和写同时进行。具体的,第一外信息作为第一译码器120的输出,在交织迭代过程中为第二译码器130的输入;第二外信息作为第二译码器130的输出,交织迭代过程中为第一译码器120的输入。在交织迭代时,第二交织地址发生器310按照第一译码器120的数据输出顺序,顺序的将第一外信息存储到外信息存储器320中;按照第二交织地址的读出所述第一外信息,并输入第二译码器130进行译码;第二译码器130通过计算输出所述第二外信息;第二交织地址发生器310按照所述第二交织地址将所述第二外信息写入外信息存储器320;在第一译码器120进行译码时,第二交织地址发生器顺序的读出所述第二外信息,并输入第一译码器120。按照这种方法,外信息存储器320只需要存储一组外信息,每一组外信息在存储时,只需覆盖外信息存储器320中的原始数据即可,因此外信息的存储空间节省了一半,即6*6144。
本实施例提供了一种turbo码译码系统,所述的译码系统的交织迭代模块包括第二交织地址发生器和外信息存储器,所述第二交织地址发生器通过控制所 述第一外信息和第二外信息读出或写入所述外信息存储器的顺序,减小了外信息存储器的数据存储量,从而减小了译码过程中所需的存储空间。
实施例四
图7为本发明实施例四提供的一种turbo码译码方法的流程图,如图7所示,所述方法具体可以包括如下步骤:
步骤410、存储模块将待译码系统数据存储于输入数据存储器中;其中,所述系统数据平分为n段,各段对应位置的数据构成一个分组,所述系统数据以分组为单位存储于所述输入数据存储器的n个子存储器中,所述系统数据的前半部分顺序间隔存储于前n/2个子存储器中,所述系统数据的后半部分倒序间隔存储于后n/2个子存储器中,n为大于等于2的偶数。
步骤420、第一译码器获取所述n个子存储器中相应位置的分组数据,并根据第一校验信息和获取的所述分组数据计算第一外信息。
步骤430、第二译码器按第一交织地址读取所述输入数据存储器中的系统数据,并根据第二校验信息和读取的所述系统数据计算第二外信息,其中,所述第一交织地址对应于所述系统数据的n个位于不同子存储器的分组。
步骤440、交织迭代模块对所述第一外信息和第二外信息进行交织迭代,完成对所述系统数据的译码。
进一步的,第二译码器按第一交织地址读取所述输入数据存储器的系统数据包括:
在正向递推过程中,第一交织地址发生器计算正向交织地址,并根据所述正向交织地址读取所述系统数据;
在反向递推过程中,第一交织地址发生器读取交织地址存储器中存储的部分反向交织地址,并根据所述部分反向交织地址读取所述系统数据。
进一步的,所述的方法还包括:
所述第一交织地址发生器根据所述部分反向交织地址计算剩余部分的反向交织地址,并存储到所述交织地址存储器中。
进一步的,交织迭代模块对所述第一外信息和第二外信息进行交织迭代包括:第二交织地址发生器计算第二交织地址。
进一步的,交织迭代模块对所述第一外信息和第二外信息进行交织迭代包括:
第二交织地址发生器将所述第一外信息顺序写入外信息存储器;
第二交织地址发生器按照第二交织地址,从所述外信息存储器中读出所述第一外信息,并输入第二译码器;
第二交织地址发生器按照第二交织地址,将所述第二外信息写入所述外信息存储器;
第二交织地址发生器从所述外信息存储器中顺序读出所述第二外信息,并输入第一译码器。
本实施例提供的turbo码译码方法,与本发明任意实施例所提供的turbo码译码系统属于同一发明构思,具有相应的有益效果。未在本实施例中详尽描述的技术细节,可参见本发明任意实施例提供的turbo码译码系统。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进 行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!