一种基于IntelCPU的并行Turbo译码方法与流程
本发明涉及数据传输领域,且特别是有关于一种基于Intel CPU的并行Turbo译码方法。
背景技术:
在通信系统中,为了使信道容量逼近香农极限,很多情况下会采用Turbo编译码技术。Turbo编码步骤较为简单,而译码则相对复杂。为了满足通信系统要求的高速率,需要尽可能提高Turbo译码的吞吐量。
以往移动通信的Turbo译码往往是在特定的DSP平台上进行。随着Intel CPU单指令多数据流的发展,其计算能力越来越强,基于Intel CPU的Turbo译码也开始出现并不断改进。当前的Turbo译码器实现方案中以github上的srsLTE项目较为完善、性能较好,此方案使用AVX指令集,128位高级矢量寄存器,16位定点化,单码块译码,顺序计算α、β的方法,并未实现在单指令多数据流指令下的并行译码。
技术实现要素:
为解决上述问题,本发明提出一种基于Intel CPU的并行Turbo译码方法,吞吐量高,而误码率性能损失有限。
为达上述目的,本发明提出一种基于Intel CPU的并行Turbo译码方法,包括下列步骤:
(1)在单指令多数据流指令中,每个码块分配128位,设定并行码块个数为CPU支持的单指令多数据流指令位宽除以128;设置迭代指示器index=0;
(2)对每个原始码块分别进行解剪裁,每个码块得到两串系统信息Lsys0,Lsys1和两串校验信息Lp0,Lp1,所述系统信息Lsys1由系统信息Lsys0交织得到,所述Lsys0、Lp0由系统中的分量译码器0处理,所述Lsys1、Lp1由系统中的分量译码器1处理;
(3)以对数似然比形式计算分量译码器0各个码块中每个时序对应的分支度量值γ11、γ10,即γ11=0.5(Lsys+Lp+La),γ10=0.5(Lsys-Lp+La),其中La为先验信息,Lsys为Lsys0和Lsys1的通用符号,Lp为Lp0和Lp1的通用符号;
(4)分量译码器0中,在时序k,构建θk+1,具体为:根据各个码块的卷积码生成矩阵列出分支状态度量值γ11k、γ10k的对应序列,将γ11k、γ10k按所述对应序列构建矢量γk;
使用单指令多数据流指令进行矢量运算,即θk+=θk+γk,θk-=θk-γk,然后根据卷积码生成矩阵对应状态位变化对θk+,θk-内部数据进行重新排列;求θk+和θk-对应数据的最大值作为下一时序的矢量θk+1,然后进行归一化处理;
其中,θk由上一时序产生,θk中包含并行码块的八个前向状态度量值αjk和八个反向状态度量值βjm,j为状态序号,N为系统码长,当k=0时,θ0内部数据为:α00=-127,β0N-1=-127,αj≠00=0,βj≠0N-1=0;θk+、θk-为状态分别为正、负的中间矢量,m=N-k-1;
(5)分量译码器0中,当时序k小于N的一半时,令k=k+1,并返回步骤(4),否则载入矢量θm,将其内部的αjm和βjk调换位置,根据下式计算Lk+和Lk-:
Lk+=θm+θk+,Lk-=θm+θk-,
其中Lk+和Lk-分别为状态为正负的输出对数似然比中间矢量;所述Lk+和Lk-每个矢量内部分别有并行码块的八个k时序的输出对数似然比中间值和八个m时序的输出对数似然比中间值;
分别求出Lk+中k时序和m时序的输出对数似然比中间值的最大值lk+和lm+,Lk-中k时序和m时序的输出对数似然比中间值的最大值lk-和lm-,然后计算出lk+-lk-即是k时刻的输出对数似然比信息Lok,lm+-lm-即是m时刻的输出对数似然比信息Lom;若k=N-1,则进入步骤(6),否则令k=k+1,并返回步骤(4);
(6)按照所述步骤(3)至(5)中分量译码器0的处理方法和流程,在分量译码器1中进行分量译码,得到输出对数似然比信息Lo,然后由公式Le=Lo-Lsys-La得到外部信息Le,当前译码器为译码器0时,将Le0交织得到译码器1的先验信息La1,当前译码器为译码器1时,将Le1解交织得到译码器0的先验信息La0,其中Le0、La0为译码器0的外部信息和先验信息,Le1、La1为译码器1的外部信息和先验信息,Le是Le0、Le1的通用符号,La是La0、La1的通用符号;
(7)迭代指示器index累加一次,如index<6,则返回步骤(3),当index=6时,译码结束。
进一步,所述步骤(1)中CPU指令集位宽为256位;设置并行码块个数为2,所述步骤(3)至(6)中的运算使用AVX2指令集处理。
进一步,所述步骤(1)中CPU指令集位宽为512位,设置并行码块个数为4,所述步骤(3)至(6)中的运算使用AVX512指令集处理。
进一步,所述步骤(4)中和(5)中使用单指令多数据流指令实现前向状态度量值和反向状态度量值的并行计算。
进一步,所述步骤(4)中的归一化处理为:θk+1内部8个状态的αk+1、βm-1都减去该度量值的0状态值α0k+1、β0m-1。
综上所述,本发明与现有技术相比具有如下有益效果:
(1)当CPU支持的单指令多数据流指令集为AVX2、AVX512或更新的指令集时,本发明的译码方法相应增加并行码块个数并在译码过程中使用对应的指令以充分利用指令集支持的位宽;现有的srsLTE中并没有针对AVX2或更新的指令集的方法,无法充分发挥处理器性能;由于AVX、AVX2和AVX512的指令周期是相同的,但是处理的数据量一次翻倍,则使用AVX2和AVX512实现的并行译码和使用AVX单码块译码所需时间相同,当指令集为AVX2时,本方法对应的矢量运算吞吐量是srsLTE中矢量运算吞吐量的两倍,当指令集为AVX512时,本方法对应的矢量运算吞吐量是srsLTE中矢量运算吞吐量的四倍;
(2)本发明使用的并行计算α、β的方法是用8位表示定点数,在128位中排列8个状态的α和8个状态的β,而srsLTE中用16位表示定点数,128位中只能排列8个16位定点数,因此相同指令周期中,本发明的译码方法可以并行计算α、β,而srsLTE中的方法只能串行计算α、β;另外在计算输出对数似然比时,由于α、β的并行排列,每次可以计算出两个输出对数似然比信息,而srsLTE中的方法只能计算一个;使用8位定点和16位定点相比增加的误码率在0.2dB以内。
附图说明
图1是本发明基于Intel CPU的并行Turbo译码方法的原理图。
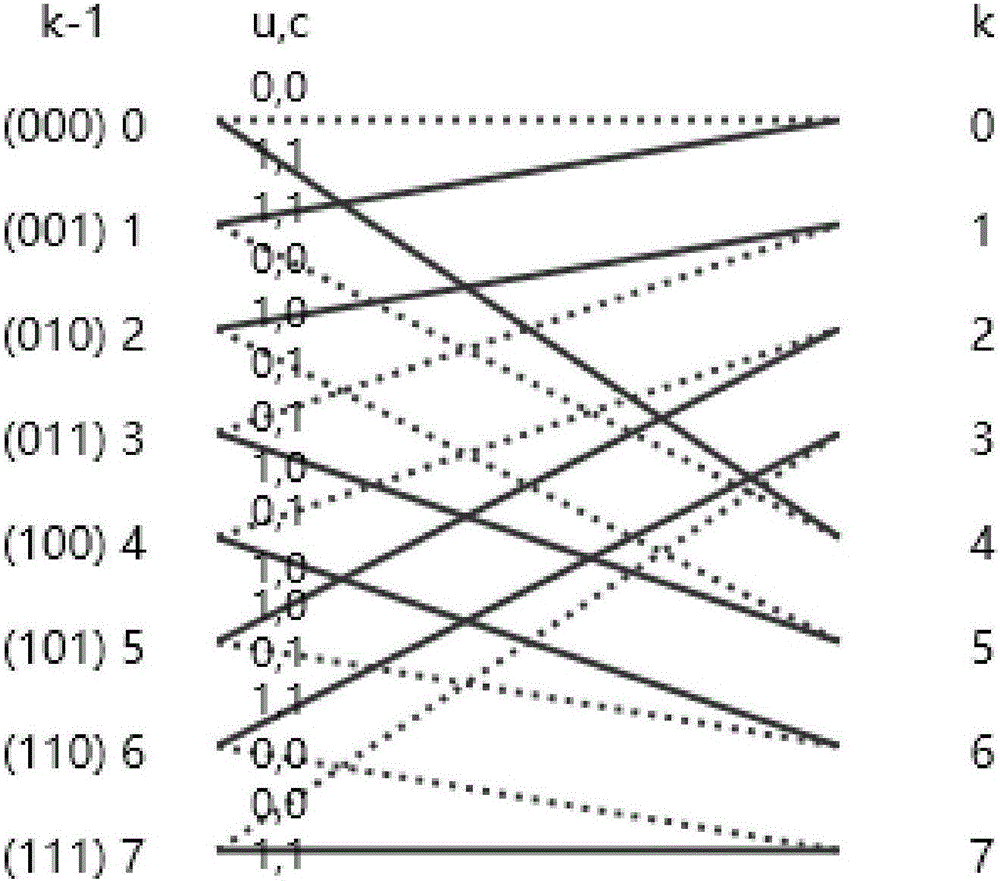
图2是生成矩阵[1 0 1 1;1 1 0 1]对应状态位变化图。
图3是α、β矢量计算流程图。
图4是输出对数似然比矢量计算流程图。
具体实施方式
为了更了解本发明的技术内容,特举具体实施例并配合所附图式说明如下。
图1是本发明基于Intel CPU的并行Turbo译码方法的原理图。本实施例中硬件平台采用Intel CPU Core i7-4790,支持AVX2指令集,配有16个256位高级矢量寄存器,主频3.6GHz;Turbo码生成矩阵为[1 0 1 1;1 1 0 1],数据采用8位定点表示。双码块并行译码时码块1在低128位,码块2在高128位,码块之间并没有交互,如图1所示。Turbo码携带信息为系统信息Lsys0,校验信息Lp0和Lp1,Lsys1由Lsys0经过交织得到。译码过程中时序从0开始逐一累加,其最大值等于码长数减一,即所有时序个数等于码长。每一时序中使用单指令多数据流指令处理该时序所有并行码块的数据。以下说明其中一个码块的译码过程:
(1)对码块进行解剪裁,得到两串系统信息Lsys0,Lsys1和两串校验信息Lp0,Lp1,所述系统信息Lsys1由系统信息Lsys0交织得到,所述Lsys0、Lp0由系统中的分量译码器0处理,所述Lsys1、Lp1由系统中的分量译码器1处理;
(3)以对数似然比形式计算分量译码器0各个码块中每个时序对应的分支度量值γ11、γ10;
根据分支状态度量计算公式:
Lsys,Lp,La,Le分别为系统信息,校验信息,先验信息和外部信息;uk,pk分别表示系统码和校验码;sik表示k步第i个状态位;
得到γ11=0.5(Lsys+Lp+La),γ10=0.5(Lsys-Lp+La),其中La为先验信息,Lsys为Lsys0和Lsys1的通用符号,Lp为Lp0和Lp1的通用符号;
(4)分量译码器0中,在时序k,构建θk+1,具体为:根据码块的卷积码生成矩阵列出分支度量值γ11k、γ10k的对应序列,如图2所示,将γ11k、γ10k按所述对应序列构建矢量γk;矢量θk内部的定点数排列是β7m,β6m,β5m,β4m,β3m,β2m,β1m,β0m,α7k,α6k,α5k,α4k,α3k,α2k,α1k,α0k,因此本例中从高位到低位对应的γ排列为γ11m,γ10m,γ10m,γ11m,γ11m,γ10m,γ10m,γ11m,γ11k,γ11k,γ10k,γ10k,γ10k,γ10k,γ11k,γ11k,m为k的反向时序,m=N-k-1,N为系统码长度;
根据前向状态度量计算公式计算α:
集合F包含了k步中与sj(k+1)有关的2个状态位,α0={0,-∞,-∞,-∞,-∞,-∞,-∞,-∞};
根据后向状态度量计算公式计算β:
集合B包含与状态sj(k-1)有关的k步的状态位,βN-1={0,-∞,-∞,-∞,-∞,-∞,-∞,-∞};
使用单指令多数据流指令进行矢量运算,如图3所示,即θk+=θk+γk,θk-=θk-γk,然后根据卷积码生成矩阵对应状态位变化对θk+,θk-内部数据进行重新排列;求θk+和θk-对应数据的最大值作为下一时序的矢量θk+1;使用单指令多数据流指令进行计算时,由于8位定点的限制,得到θk+1后要进行归一化处理,即内部8个状态的αk+1、βm-1都减去该度量值的0状态值α0k+1、β0m-1,即归一化后内部排列为β7m-1-β0m-1,β6m-1-β0m-1,β5m-1-β0m-1,β4m-1-β0m-1,β3m-1-β0m-1,β2m-1-β0m-1,β1m-1-β0m-1,0,α7k+1-α0k+1,α6k+1-α0k+1,α5k+1-α0k+1,α4k+1-α0k+1,α3k+1-α0k+1,α2k+1-α0k+1,α1k+1-α0k+1,0;
其中,当k=0时,θ0部数据为:α00=-127,β0N-1=-127,αj≠00=0,βj≠0N-1=0;θk+、θk-为状态分别为正、负的中间矢量,θk由上一时序产生,θk中包含并行码块的八个前向状态度量值αjk和八个反向状态度量值βjm,j为状态序号;
此步骤所涉及的矢量计算中,每个码块占用矢量内部的128位,所涉及的矢量计算中,低64位计算前向状态度量值α,高64位计算反向状态度量值β,高64位和低64位之间不会有数据交换;
(5)分量译码器0中,当时序k小于N的一半时,令k=k+1,并返回步骤(4),否则根据以下公式计算输出对数似然比Lo:
集合U1和U-1包含了当uk分别为1和-1时的状态位;
如图4所示,载入矢量θm,将其内部的αjm和βjk调换位置,根据下式计算Lk+和Lk-:
Lk+=θm+θk+,Lk-=θm+θk-,其中Lk+和Lk-分别为状态为正负的输出对数似然比中间矢量;所述Lk+和Lk-每个矢量内部分别有并行码块的八个k时序的输出对数似然比中间值和八个m时序的输出对数似然比中间值;
分别求出Lk+中k时序和m时序的输出对数似然比中间值的最大值lk+和lm+,Lk-中k时序和m时序的输出对数似然比中间值的最大值lk-和lm-,然后计算出lk+-lk-即是k时刻的输出对数似然比信息Lok,lm+-lm-即是m时刻的输出对数似然比信息Lom,为视图简洁,图中lk+、lk-用l表示,而lm+、lm-用x表示,状态标注在框图右侧;若k=N-1,执行下一步操作,否则令k=k+1,并返回步骤(4);
此步骤所涉及的矢量计算中,每个码块占用矢量内部的128位,低64位计算当前时序k的输出对数似然比,高64位计算时序N-k-1的输出对数似然比,除了将矢量θN-k-1内部的αjN-k-1和βjk调换位置时高64位数据和低64位数据互换外,其余矢量计算中高64位和低64位之间不会有数据交换;
(6)按照所述步骤(3)至(5)中分量译码器0的处理方法和流程,在分量译码器1中进行分量译码,得到输出对数似然比信息,然后由公式Le=Lo-Lsys-La得到外部信息Le,当前译码器为译码器0时,将Le0交织得到译码器1的先验信息La1,当前译码器为译码器1时,将Le1解交织得到译码器0的先验信息La0,其中Le0、La0为译码器0的外部信息和先验信息,Le1、La1为译码器1的外部信息和先验信息,Le是Le0、Le1的通用符号,La是La0、La1的通用符号;
(7)迭代指示器index累加一次,如index<6,则返回步骤(3),当index=6时,译码结束。
本实施例的结果如表格1所示,对照组为srsLTE中的顺序计算α、β的Turbo单码块译码方案。误码率损失的比较对象是MATLAB下使用双精度浮点数进行Turbo译码的误码率。
表格1单码块和双码块并行Turbo译码性能比较
有上述表格可以看出,本发明的基于Intel CPU的并行Turbo译码方法主要优点在于吞吐量高,而误码率性能损失有限。
上述实施例仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和等同替换,这些对本发明权利要求进行改进和等同替换后的技术方案,均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!