一种Viterbi译码的快速搜寻路径方法与流程
本发明涉及数字信息传输技术领域,具体涉及一种viterbi译码的快速搜寻路径方法。
背景技术:
信道编码是数字信息传输技术中的一个重要的研究领域,其中卷积码因其优良的抗噪声特性、灵活编译码方法及时延小等特点受到了广泛的研究和应用。卷积码的译码方式也有很多,而比较常见的方法就是viterbi译码方法。
viterbi译码方法既可以用于硬判决译码,也可以用于软判决译码。viterbi硬判决译码是根据接收的硬判决比特序列在码的篱笆图上找到一条与之积累的汉明距离最小的编码比特序列的一种算法。设(n0,k0,m)卷积码信息序列段数为l,其中m为卷积码的编码存储,则卷积码编码器有2^(k0m)个状态、l+m+1个时间单位节点,以0至l+m予以标号。所以篱笆图中可能有的全部路径也有2^(k0l)条,但viterbi译码方法并不是比较可能的所有路径,而是接收一段,计算比较一段,选择一段最可能的分支,从而达到整个码字序列是一个最大似然函数的序列。译码器从某个状态,例如从状态s0出发,每次向右延伸一个分支,并与接收序列相应分支进行比较,计算它们之间的距离,然后将计算所得距离加到被延伸路径的累积距离值中。对到达每个状态的各条路径(有2^k0条)的距离累积值进行比较,保留距离值最小的一条路径,称为幸存路径,当有两条以上取最小值时,可任取其中之一。最后将篱笆图回归到全0状态,从而剩下一条幸存路径,即为所求路径,路径回溯对应的信息比特就是译码输出序列。
viterbi译码算法虽然是一种性能高的算法,但在路径搜寻过程中的复杂度是比较大的。对于(n0,k0,m)卷积码,对每一时刻要做2^(k0m)次“加-比-存”操作,每一个操作包括2^k0次加法和2^k0-1次比较,同时要保留2^(k0m)条幸存路径。可见算法的复杂度与信道质量无关,其计算量和存储量都随编码存储m和信息元分组k0呈指数增长,故如果m和k0较大,viterbi译码并不适用。在信道条件比较好的前提下,为了进一步降低viterbi译码算法的计算复杂度及存储量,我们将充分信道信息,寻求改进的viterbi译码算法中的路径搜寻方法。
技术实现要素:
为了克服现有技术存在的缺点与不足,本发明提供一种viterbi译码的快速搜寻路径方法。
该方法针对卷积码viterbi译码过程中路径选择问题,在较好信道前提条件下,加入确定性高的路径选择方案,使得路径搜寻的计算复杂度和储存量大大降低,具有较高的实用意义。
本发明提出的viterbi译码的路径搜寻方法即从状态s0出发,每次向右延伸一个分支,首先直接选择输出子组与当前时间节点接收序列相同的分支也就是满足汉明距离为0作为本段路径,若找不到与接收序列相同的分支,则保留从本状态到次状态的所有分支,然后再从所有次状态向右延伸的分支中继续搜寻输出子组与对应接收序列相同的分支,在只存在随机错而且条件较好的信道中,一般不会连续出现2个错,所以在本次的分支选择中可以找到输出子组与对应接收序列相同的分支,作为次段路径,接着删除之前保留的其他路径,如此进行搜寻路径,直到将篱笆图回归到全0状态,得到的路径即为本算法的最佳路径。若出现连续两个以上错误,则连续错误部分的路径搜寻按照传统方法,寻找编码输出序列与接收序列汉明距离最小的中间路径。
本发明采用如下技术方案:
一种viterbi译码的快速搜寻路径方法,包括如下步骤:
s1对(n0,k0,m)卷积码,从单位时间节点j=0开始,即从状态s0出发,向右延伸一个分支,从分支中找到输出子组与现时间节点的接收序列相同的分支作为本段译码路径,若找不不到满足条件的分支,则进入s2,否则j=j+1进入s4;
s2保留从上个状态到达次状态的所有分支,接着对所有次状态向右延伸一个分支,然后j=j+1,从向右延伸的分支中选择输出子组与现在时间节点的接收序列相同的分支作为次段译码路径,进入s3;
s3保留与次段译码路径相连的到达次状态的分支作为前段译码路径,其他到达次状态的分支删除,进入s4;
s4若j<l+m,则返回s1,否则停止,译码器得到具有前提条件的最大似然路径,所述l为卷积码中信息序列段数,m为卷积码的编码存储。
若接收序列中出现连续两个以上错误,则连续错误部分的路径搜寻按照传统方法,寻找编码输出序列与接收序列汉明距离最小的中间路径。
所述的(n0,k0,m)卷积码有2^(k0m)个状态,为保证使得篱笆图最终回到全0状态,其将有l+m+1个时间单位节点,以0至l+m予以标号。
所述输出子组与现时间节点的接收序列相同是指输出子组与现时间节点的接收序列之间的汉明距离为0。
本发明的有益效果:
(1)该viterbi译码的快速搜寻路径方法适用于实际中应用较多的条件较好的信道,与传统的viterbi译码路径搜寻方法有同样的最佳效果。
(2)该发明相比于传统的译码路径搜寻方法具有更低的计算复杂度和更少的路径存储量,只需要存储一条最佳路径,从而路径搜寻速度也得到极大的提升。
附图说明
图1是本发明的工作流程图;
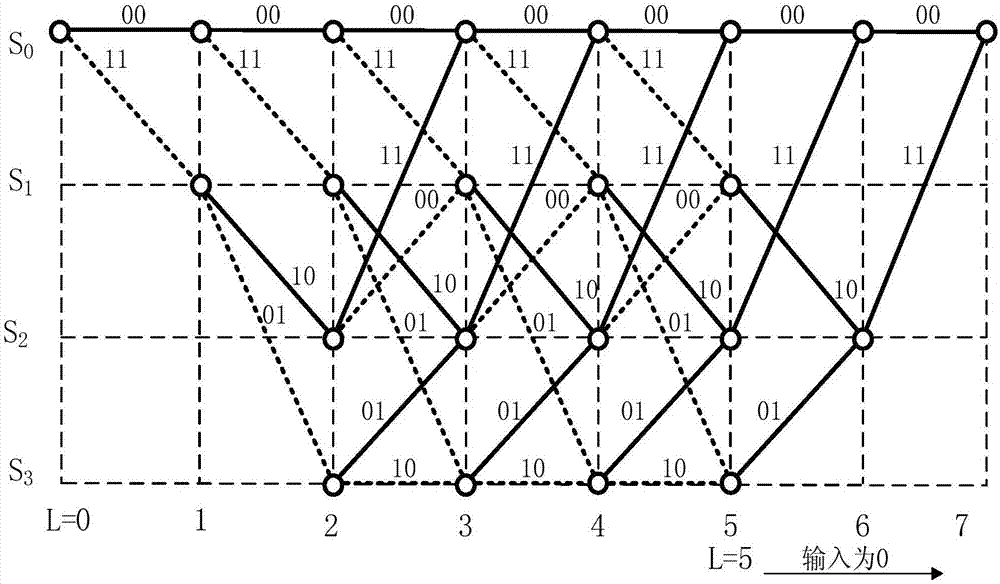
图2是本发明实施例中(2,1,2)卷积码g(d)=(1+d+d2,1+d2)的篱笆图表示法;
图3是本发明实施例中(2,1,2)卷积码viterbi译码的快速搜寻路径方法执行过程示意图。
具体实施方式
下面结合实施例及附图,对本发明作进一步地详细说明,但本发明的实施方式不限于此。
实施例
如图1-图3所示,一种viterbi译码的快速搜寻路径方法,适用于接收序列没有出现两个连续错误,实施例中我们采用简单的(2,1,2)卷积码,即该卷积码的信息元分组长度为1,输出子组码元长度为2,编码存储为2。该卷积码的生成多项式为g(d)=(1+d+d2,1+d2),如图2为该卷积码的篱笆图表示。在图2的篱笆图中,每一个状态有两个输入和两个输出分支,在某一个单位时间节点j,离开每一状态的虚线分支即下面分支表示输入编码器中的信息子组mi=1;而实线分支即上面分支表示此时刻输入至编码器的信息子组mi=0;每一个分支上的2个数字表示第j时刻编码器输出的子组,因而篱笆图中每一条路径都对应于不同输入的信息序列。我们同时假设编码信息序列为m=(1011100),接收到的码字为r=(10,10,01,01,10,01,11,00….),r中第一序列段和第三序列段的第二个比特均发生了错误,即原来正确的码字是c=(11,10,00,01,10,01,11,00…)。
根据我们选取的简单的卷积码为例,如图3为本实施例中卷积码viterbi译码的快速搜寻路径方法执行过程示意图。下面对viterbi译码的快速搜寻路径方法的具体实施方式进行说明:
s1:对(2,1,2)卷积码,从单位时间节点j=0开始,即从状态s0出发,向右延伸一个分支,从分支中找到输出子组与现时间节点的接收序列(10)相同的分支作为本段译码路径,发现找不到满足条件的分支,进入步骤2;
s2:保留状态s0到达次状态即s0和s1的所有分支,如图3中的两个分支①,接着对所有次状态向右延伸一个分支,j增加1,从分支中选择输出子组与现时间节点的接收序列(10)相同的分支,如图3中的分支②,作为次段译码路径,进入步骤3;
步骤3:保留与次段译码路径相连的到达次状态的分支作为前段译码路径,如图3中的与分支②相连的分支①,删除其它到达次状态的分支,如图3中的未与分支②相连的另一分支①,进入步骤4;
步骤4:若j<7,则返回步骤1,否则停止,译码器得到了具有前提条件下的最大似然路径,如图3中的路径①→②→③→④→⑤→⑥→⑦。按照此路径回溯得到的信息序列与编码器信息序列m=(1011100)是一致的,说明译码成功。
所述的(2,1,2)卷积码中信息序列段数为5,其中卷积码的编码存储为2。
所述的(2,1,2)卷积码中有4个状态,分别为s0、s1、s2、s3,为保证使得篱笆图最终回到全0状态,其将有8个时间单位节点,以0至7予以标号。
在只存在随机错而且条件较好的信道中,一般不会连续出现2个错,在这种信道前提下,按照以上方法进行viterbi译码的搜寻路径,即在搜寻路径过程中直接寻找输出子组与接收序列相同的分支,即直接寻找输出子组与接收序列汉明距离为0的分支,得到的路径是一条最大似然路径,是一种有前提条件下的最佳译码路径。
若出现连续两个以上错误,则连续错误部分的路径搜寻按照传统方法,寻找编码输出序列与接收序列汉明距离最小的中间路径。
对于(n0,k0,m)卷积码,n0表示码元长度,k0表示信息元长度,运用传统的译码路径搜寻方法时,对每一时刻要做2^(k0m)次“加-比-存”操作,每一个操作包括2^k0次加法和2^k0-1次比较,同时要保留2^(k0m)条幸存路径。从实施例中我们可以看到,该方法相比于传统的译码路径搜寻方法具有更低的计算复杂度和更少的路径存储量,每一个时刻一般情况下只要做2^k0次的匹配比较操作,不需要存储临时路径。最坏情况下只需要存储2^k0条临时路径,需要做2^(2k0)次的匹配比较操作。而总体上只需要存储一条最佳路径,从而路径搜寻速度也得到极大的提升。同时,本方法与传统的viterbi译码路径搜寻方法有同样的最佳效果。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!