一种译码方法及装置与流程
本发明涉及无线通信
技术领域:
,尤其涉及一种译码方法及装置。
背景技术:
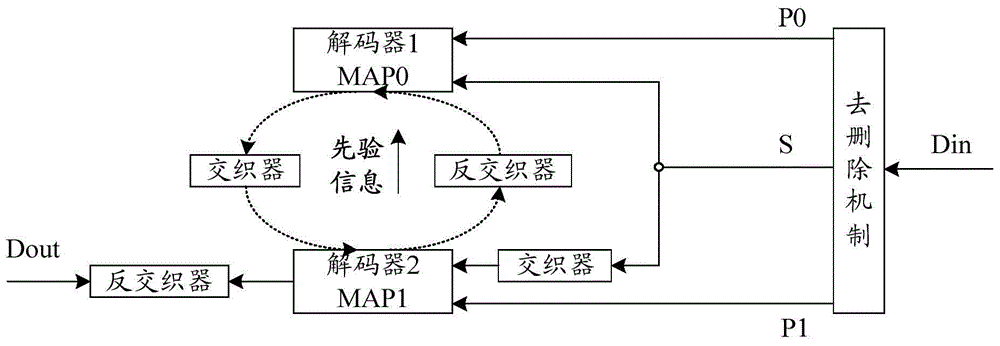
:无线通信中,2G制式、3G制式、与4G制式,乃至将来的5G制式将长期共存,用于满足不同用户的不同需求;因此,无线通信设备的多模化是无线通信设备发展的必然趋势。Turbo作为一种信道编码技术,广泛应用与3G制式和4G制式的无线通信系统;Turbo编码器的编码原理示意图,如图1所示,Turbo编码器将两个简单分量编码器通过伪随机交织器并行级联来构造具有伪随机特性的长码,以最大限度地提高数据的随机性和单位比特的信息量,使其容量更接近于香农理论的极限,在信噪比较低的高噪声环境下性能更优越,并且具有更强的抗衰落和抗干扰能力。Turbo译码器通过在两个软入/软出译码器之间进行多次迭代实现伪随机译码;Turbo译码器的译码原理示意图,如图2所示,两个译码器MAP0和MAP1组成一个循环迭代结构,在外部信息的作用下,一定信噪比的误比特率将随着循环次数的增加而降低,置信度也逐步增加;同时,由于外部信息的相关性也随着译码次数的增加而逐渐增加,从而外部信息所提供的纠错能力也随之减弱,在一定的循环次数之后,Turbo译码器的译码性能将不再提高。Turbo译码器不仅采用迭代循环过程,而且采用的算法不仅要能够对每比特进行译码,还要伴随着译码给出每比特译出的先验信息;因此,Turbo译码器具有实现复杂的缺点;这里,MAP1为进行交织处理的解码器,MAP0为进行非交织处理的解码器。3G制式和4G制式采用的Turbo算法唯一的不同就在于交织器,交织器的实现通常通过控制访问数据的地址来完成;3G制式采用的多级(MIL)交织器,通过构造RxC矩阵、进行行内置换和行间置换等多级步骤来实现,其地址毫无规律性,并行操作的可能性小;而4G制式采用基于二次多项式置换(QPP)交织器,地址的规律性强,可以实现无冲突访问,并且操作简便。同时,由于3G制式和4G制式采用的关键技术不同,导致其干扰类型和干扰抵消的目标有所不同;3G制式为保证可靠性,通常采用硬比特干扰抵消算法,不需要输出软符号;而4G制式为了获取更大的增益,通常采用软符号干扰抵消算法,这样在Turbo译码的过程中需要缓存软符号信息,以便输出到外部模块做干扰抵消。为提高系统吞吐率,3G制式和4G制式通常采用基4的Turbo译码算法,即每时刻译码产生4比特的数据;但由于3G制式和4G制式在采用的交织器算法方面的差异,直接影响到其译码实现所采用的方式以及存储空间的开销;译码实现方式,如图3所示:对于4G制式,由于交织的规律性,Turbo译码器可以方便的分并行处理单元(PU)并行、分串行处理单元(WIN)串行;而对于3G制式,由于交织的无规律性,MAP1仅能分WIN串行。传统MAP流水线,如图4所示,对于MP0,由于后半窗需要读写LE,故存在读写LE冲突;而对于MAP1,除读写LE冲突外,3G制式由于交织地址的冲突性,还存在4比特的读冲突和写冲突;因此,现有技术中多模Turbo译码器的实现架构,如图5所示:通过前窗缓存、后窗使用的方式来解决后半窗的读写LE冲突;通过4份拷贝的方式来解决3G支持的4比特读冲突和写冲突;但是,该方法由于不能充分共享4G制式软符号的存储资源,从而导致存储资源开销比较大。同时,Turbo译码器为提高译码性能,通常采用一定大小的重叠窗(overlap),通过固定默认初始值的方法来训练序列,从而提高译码的精度和正确性;采用固定默认初始值,重叠窗至少需要16才能满足译码的一般性能需求。这极大地增加了资源的无用开销。由此可见,传统的Turbo译码器由于交织器的差异,4G并行和3G串行, 存储资源受限于3G,逻辑资源受限于4G,资源共享不充分,从而导致资源利用率低,整体硬件开销和功耗都大。对于3G制式,由于没有充分利用逻辑资源,导致系统吞吐率也低。技术实现要素:有鉴于此,本发明实施例期望提供一种译码方法及装置,能够提高资源利用率和吞吐率,降低系统开销和功耗。本发明实施例的技术方案是这样实现的:本发明实施例提供了一种译码方法,所述方法包括:在译码的前半窗阶段读取译码的输入数据,并对读取的输入数据进行处理,得到处理结果;在译码的后半窗阶段将所述处理结果进行译码,得到译码结果;根据所述译码结果确认译码结束时,封装并输出译码结果。上述方案中,所述确认接收的外部数据为前半窗数据之前,所述方法还包括:接收译码参数包,根据所述译码参数包获取译码参数;接收译码的输入数据,根据由所述译码参数计算得到的补零个数PadNum对所述输入数据进行处理,并存储处理后的数据。上述方案中,所述读取译码的输入数据,包括:对于3G制式,在对所述译码的输入数据进行交织处理阶段的第一个窗,先读取两组译码的输入数据,在前半窗阶段,再读取两组译码的输入数据,获取四组译码的输入数据;或,对于3G制式,在对所述译码的输入数据进行非交织处理阶段直接读取四组译码的输入数据;或对于4G制式,在对所述译码的输入数据进行非交织处理阶段及在对所述译码的输入数据进行交织处理阶段,均直接读取四组译码的输入数据。上述方案中,所述对读取的输入数据进行处理,得到译码结果,包括:对读取的输入数据进行gamma计算,得到gamma值。上述方案中,所述将所述处理结果进行译码,包括:对所述gamma值进行前后向碰撞计算,得到硬比特信息、先验信息、及软符号信息。本发明实施例还提供了一种译码装置,所述装置包括:第一处理模块、译码模块、和输出模块;其中,所述第一处理模块,用于在译码的前半窗阶段读取译码的输入数据,并对读取的输入数据进行处理,得到处理结果;所述译码模块,用于在译码的后半窗阶段将所述处理结果进行译码,得到译码结果;所述输出模块,用于根据所述译码结果确认译码结束时,封装并输出译码结果。上述方案中,所述装置还包括:第二处理模块,用于接收译码参数包,根据所述译码参数包获取译码参数;接收译码的输入数据,根据由所述译码参数计算得到的补零个数PadNum对所述输入数据进行处理,并存储处理后的数据。上述方案中,所述第一处理模块,具体用于对于3G制式,在对所述译码的输入数据进行交织处理阶段的第一个窗,先读取两组译码的输入数据,在前半窗阶段,再读取两组译码的输入数据,获取四组译码的输入数据;或,对于3G制式,在对所述译码的输入数据进行非交织处理阶段直接读取四组译码的输入数据;或对于4G制式,在对所述译码的输入数据进行非交织处理阶段及在对所述译码的输入数据进行交织处理阶段,均直接读取四组译码的输入数据。上述方案中,所述第一处理模块,具体用于对读取的输入数据进行gamma计算,得到gamma值。上述方案中,所述译码模块,具体用于对所述gamma值进行前后向碰撞计算,得到硬比特信息、先验信息、及软符号信息。本发明实施例所提供的译码方法及装置,在译码的前半窗阶段,读取译码的输入数据,并对读取的输入数据进行处理,得到处理结果;在译码的后半窗阶段,将所述处理结果进行译码,得到译码结果;根据所述译码结果确认译码结束时,封装并输出译码结果;如此,可通过前半窗阶段的读数据与后半窗阶段的写数据分离,解决了读写冲突的问题,降低了资源的功耗;同时通过对译码的输入数据进行数据对齐,将3GMAP0、4GMAP0和4GMAP1合并为无冲突通道,统一并行处理,3GMAP1为冲突通道,单独进行串行处理,提高了吞吐率。附图说明图1为现有技术Turbo编码器的编码原理示意图;图2为现有技术Turbo译码器的译码原理示意图;图3为现有技术Turbo译码器的译码实现方式示意图;图4为现有技术MAP流水线示意图;图5为现有技术多模Turbo译码器的实现架构示意图;图6为本发明实施例译码方法的基本处理流程示意图;图7为本发明实施例alpha继承历史值初始化的原理示意图;图8为本发明实施例beta继承历史值初始化的原理示意图;图9为本发明实施例读写数据的示意图;图10为本发明实施例译码方法的详细处理流程示意图;图11为本发明实施例译码装置的组成结构示意图;图12为本发明实施例译码装置的实现示意图。具体实施方式本发明实施例一种译码方法的基本处理流程,如图6所示,包括以下步骤:步骤101,在译码的前半窗阶段,读取译码的输入数据,并对读取的输入数据进行处理,得到处理结果;具体地,译码装置的第一处理模块在译码的前半窗阶段读取译码的输入数据;1)对于3G制式,在对所述译码的输入数据进行交织处理MAP1阶段的第一个窗前,先从缓存中读取两组译码的输入数据,在前半窗阶段,再从缓存中读取两组译码的输入数据,获取四组译码的输入数据;每次MAP1迭代前均有半个窗的预读阶段,后半窗作为后一个窗的预读阶段;这里,所述每组译码的输入数据包括:先验值LE、系统数据S、和校验值P1;如此,通过提前半窗读的方式,即在3GMAP1的每次迭代前增加一级提前预读流水,从4比特的数据中任取2比特的数据进行提前预读并缓存,其余2比特在正常流程的前半窗读取,并与提前预读的2比特组成完整的数据;由于3GMAP1采用拷贝的方式来解决冲突,读写不会同时存在于同一存储资源空间,因此从根本上就不会发生读写冲突,提前预读流水可以和其它窗的后半窗重合。这样,通过增加少量的开销,即可实现从同时读4个数据降低到同时读2个数据,从而使相应的拷贝数也从4份降低为2份,存储资源可以完全共享4G软符号的存储资源,达到降低存储资源开销和提高共享资源利用率的目的;2)对于3G制式,在对所述译码的输入数据进行非交织处理MAP0阶段直接读取四组译码的输入数据;这里,所述每组译码的输入数据包括:LE、S、和P0;3)对于4G制式,在对所述译码的输入数据进行非交织处理阶段及在对所述译码的输入数据进行交织处理阶段,均直接读取四组译码的输入数据;这里,所述每组译码的输入数据包括:LE、S、和P0,或LE、S、和P1。对读取的输入数据进行处理是指将输入的数据进行gamma计算,得到gamma值,并将所述gamma值缓存至gamma_ram;具体地,gamma计算采用(1,0)的方案;由Turbo算法从理论上推到出的gamma计算的方程式,为:其中,(χ2ks,χ2k+1s,χ2kp,χ2k+1p)={0000,0001,......,1111};]]>表示从状态S2k到S2k+2的gamma值;表示编码系统比特SYS,表示编码校验比特P0或P1;表示接收的软系统符号,表示接收的软校验符号;La(χ2k),La(χ2k+1)表示先验软信息Le。硬比特符号x在通信意义上仅有+1,-1之分,而0表示无信号,±1可以增大两个不同信号之间的区分度;因此,通常gamma的计算采用(1,-1)方案;gamma计算方案比较值,如表1所示:表1由表1可以看出,gamma(1,-1)和gamma(1,0)两种算法的概率差相差一个整数倍数,这是由于采用gamma简化算法带来的结果;如果采用浮点算法,两种译码算法的结果一样;但是如果采用定点算法,由于定点精度问题,gamma(1,-1)算法在精度上会有损失;同时,从实现角度而言,gamma(1,0)算法也相对简化;因此,采用gamma(1,0)算法不仅能降低逻辑资源的开销,提高译码性能,而且由于前半窗需要缓存,也能降低缓存存储资源的开销;而且,由于gamma值在随后的无论是用于求硬比特符号,还是用于求先验信息,抑或用于求软符号信息,均采用的是不同组合的概率差值,因此,gamma采用(1,0)方案计算,并不会造成任何性能损失。本发明实施例中,若不是3G制式下的MAP1阶段的第一个窗,在执行本步骤之前,则需初始化alpha或beta;若是3G制式下的MAP1阶段的第一个窗,则在缓存中读取两组译码的输入数据后,再初始化alpha或beta;这里,如果为首次对输入的数据进行译码,即首次迭代,则采用固定的默认值初始化alpha或beta;否则,采用缓存的历史值初始化alpha或beta;其 中,缓存的历史值为上一次译码产生并缓存的值;具体地,由于Turbo碰撞译码算法通过采用增加overlap训练窗大小的方法来提高译码性能,因此,用于训练所选择的初始值不仅决定训练窗WIN的大小,而且决定其译码性能;训练窗从理论上来说是无用的,仅仅是为了训练,而不会产生有效的译码输出;因此,本申请通过采用继承历史值来初始化alpha或beta,在保证译码性能的前提下,能有效地减小训练窗WIN的大小,从而降低无用开销;而无用开销的减少,也必然会提高系统吞吐率和降低动态功耗。alpha继承历史值初始化的原理,如图7所示:由于alpha采用前向计算,各窗间可以平滑过渡,除第一个窗外的其它窗无需重叠训练,后窗可以直接采用前窗的计算结果做为训练结果继续处理,因此alpha仅各PU的第一个窗需要初始化。在第一次迭代的时候,采用传统的默认固定值初始化,并保存距离各PU末尾重叠窗WIN长度点的alpha中间计算值,用于下次迭代的初始化;除第一次迭代外的其他迭代,均采用上次迭代保存的中间值作为alpha的初始值,并保存本次计算的中间值以供下次迭代使用。beta继承历史值初始化的原理,如图8所示:由于beta由于采用反向计算,各窗间在数据上无连贯性,因此,各个窗均需要独立初始化。在第一次迭代的时候,各窗采用传统的默认固定值初始化,并保存距离各窗头部重叠窗WIN长度点的beta中间计算值,用于下次迭代的初始化;除第一次迭代外的其他迭代均采用上次迭代保存的中间值作为beta的初始值,并保存本次计算的中间值以供下次迭代使用。本发明实施例中,在执行步骤101之前,还包括:步骤100a,接收译码参数包,根据所述译码参数包获取译码参数;具体地,译码装置中的第二处理模块接收外部发送的译码参数包,并解析所述译码参数包;如果解析所述译码参数包为3G制式,根据补零个数计算公式计算PadNum;对于3G制式,由于MAP0采用顺序地址,地址间无冲突,因此,MAP0可采用并行操作;但是,由于3G制式下交织器的无规律性,MAP1读写数据 时的交织地址容易产生冲突,因此MAP1无法并行操作;对于4G制式,交织器采用无冲突的二次置换多项式(QuadraticPolynomialPermutation,QPP),因此,4G制式下的MAP0和MAP1均能并行操作。因此,把3GMAP0、4GMAP0和4GMAP1合并为无冲突通道,统一并行处理;而3GMAP1为冲突通道,采用固定窗长的原则单独进行串行处理。这样,既能最大限度的共享其逻辑资源,达到资源利用率的最大化;同时,由于并行处理3GMAP0,也能极大提高3G系统的吞吐率。4G协议规定的Turbo码块大小K为在[40,6144]区间的188种可能取值,且每种取值在各自的区间均为N(N=8,16,32,64)的整数倍,因此能容易的均分为PUxWIN等份,利于并行处理;而3G协议中规定的Turbo码块大小K可以是[40,5114]的任意值,并不完全是PUxWIN的整数倍,为兼容4G的多PU并行处理,需要对3G的输入数据进行末尾补零对齐到与4G最接近的码块大小K;具体的补零个数计算公式如下:PadNum=(8-k%8)%8,k∈[40,512](2)(16-k%16)%16,k∈(512,1024](32-k%32)%32,k∈(1024,2048](64-k%64)%64,k∈(2048,5114];再根据解码快大小k和PadNum分别计算出MAP0和MAP1运算所需要的并行处理单元数量(PuNum)、串行处理单元数量(WinNum)和串行处理单元大小(WinSize),K’、PuNum、WinNum和WinSize的关系,如表2所示:K’=k+PuNumPuNumWinNumWinSize[40,376]11K’%2(376,752]21K’%4(752,1504]41K’%8(1504,3072]81K’%16(3072,6144]82K’%32表2步骤100b,接收译码的输入数据,根据PadNum对所述输入数据进行处理,并存储处理后的数据;具体地,译码装置的第二处理模块接收外部的译码输入数据,解析所述输入数据中的p0、p1和S,根据所述PadNum的大小在所接收的数据尾部补零对齐后存储至缓存;同时,所述第二处理模块根据k产生交织地址,并将产生的交织地址缓存至addr_ram,所述交织地址用于MAP1阶段读写数据使用;在执行该步骤后,执行初始化alpha或beta的操作。步骤102,在译码的后半窗阶段将所述处理结果进行译码,得到译码结果;具体地,译码装置中的译码模块对步骤101中计算得到的所述gamma值基于基4碰撞MAP算法进行前后向碰撞计算,得到译码结果,并将所述译码结果进行缓存;其中,所述译码结果包括:硬比特信息、LE、及软符号信息;相应的,所述硬比特信息存储至hd_ram,所述4G校验比特p1软符号存储至p1_le_ram,4G校验比特p0软符号存储至p0_le_ram,4G系统比特软符号存储至llrs_scpy_ram,LE存储至le_ram;对于非冲突通道,则将四组译码结果并行写入le_ram,如果是冲突通道,在写入译码结果的过程中若遇到地址冲突,则将有冲突的地址和数据先缓存起至delay_ram,在没有地址冲突的时候,将已经缓存的有冲突的地址和数据同其他译码结果一同写入le_ram。本发明实施例中,为解决4比特数据的写冲突,采用延迟写法,由于MAP的译码结果数据仅发生在后半窗,通过延迟可以扩展写到前半窗,相当于每一时刻只写2比特数据,而在无地址冲突的时候,可以同时写入多比特数据,从而,在根本上消除写冲突的问题。同时,在本发明实施例中,如图9所示,在前半窗从共享存储资源读取本 窗所有需要的数据信,并对所述数据进行gamma计算后缓存,在后半窗仅从该缓存中读取相应的gamma值进行译码,并将译码结果回写到共享存储资源;如此,实现了共享存储资源的读/写完全分开,解决了读写冲突;同时,由于不需要从较大的共享存储资源二次重复读取数据和进行gamma值的二次计算,而仅从较小的缓存中直接获取gamma值降低了大RAM的读写概率和逻辑资源的翻转率,有效地降低了动态功耗。步骤103,根据所述译码结果确认译码结束时,封装并输出译码结果;具体地,译码装置中的输出模块对所述译码结果中的硬比特信息进行循环冗余校验(CyclicRedundancyCheck,CRC),或将本次译码结果中的硬比特信息与上次迭代结果中的硬比特信息进行比较,依据迭代提前停止准则及CRC结果或比较结果确定迭代是否结束;如果迭代未结束,则重复执行步骤101至步骤103;如果迭代结束,则将译码得到的硬比特信息或软比特信息封装、输出至外部;需要说明的是,本发明实施例中所述迭代是指对输入的译码数据进行多次译码。本发明实施例一种译码方法的详细处理流程,如图10所示,包括以下步骤:步骤201,接收译码参数包,根据所述译码参数包获取译码参数;具体地,译码装置中的第二处理模块接收外部发送的译码参数包,并解析所述译码参数包;如果解析所述译码参数包为3G制式,根据补零个数计算公式计算PadNum;对于3G制式,由于MAP0采用顺序地址,地址间无冲突,因此,MAP0可采用并行操作;但是,由于3G制式下交织器的无规律性,MAP1读写数据时的交织地址容易产生冲突,因此MAP1无法并行操作;对于4G制式,交织器采用无冲突的QPP,因此,4G制式下的MAP0和MAP1均能并行操作。因此,把3GMAP0、4GMAP0和4GMAP1合并为无冲突通道,统一并行处理;而3GMAP1为冲突通道,采用固定窗长的原则单独进行串行处理。这样,既能最大限度的共享其逻辑资源,达到资源利用率的最大化;同时,由于并行处 理3GMAP0,也能极大提高3G系统的吞吐率。4G协议规定的Turbo码块大小K为在[40,6144]区间的188种可能取值,且每种取值在各自的区间均为N(N=8,16,32,64)的整数倍,因此能容易的均分为PUxWIN等份,利于并行处理;而3G协议中规定的Turbo码块大小K可以是[40,5114]的任意值,并不完全是PUxWIN的整数倍,为兼容4G的多PU并行处理,需要对3G的输入数据进行末尾补零对齐到与4G最接近的码块大小K;具体的补零个数计算公式如下:PadNum=(8-k%8)%8,k∈[40,512](2)(16-k%16)%16,k∈(512,1024](32-k%32)%32,k∈(1024,2048](64-k%64)%64,k∈(2048,5114];再根据解码快大小k和PadNum分别计算出MAP0和MAP1运算所需要的并行处理单元数量(PuNum)、串行处理单元数量(WinNum)和串行处理单元大小(WinSize),K’、PuNum、WinNum和WinSize的关系,如表2所示:K’=k+PuNumPuNumWinNumWinSize[40,376]11K’%2(376,752]21K’%4(752,1504]41K’%8(1504,3072]821K’%16(3072,6144]812K’%32表2步骤202,接收译码的输入数据,根据PadNum对所述输入数据进行处理,并存储处理后的数据;具体地,译码装置的第二处理模块接收外部的译码输入数据,解析所述输入数据中的p0、p1和S,根据所述PadNum的大小在所接收的数据尾部补零对 齐后存储至缓存;同时,所述第二处理模块根据k产生交织地址,并将产生的交织地址缓存至addr_ram,所述交织地址用于MAP1阶段读写数据使用。步骤203,判断是否需要进入提前预读阶段,在判断结果为是时,执行步骤204,在判断结果为否时,执行步骤205;具体地,译码装置的第一处理模块判断为3G制式,且在对所述译码的输入数据进行交织处理MAP1阶段的第一个窗时,确认需要进入提前预读阶段,否则,不需要进入提前预读阶段。步骤204,提前预读数据;具体地,先从缓存中读取两组待译码的输入数据;这里,所述每组译码的输入数据包括:先验值LE、系统数据S、和校验值P1;如此,通过提前半窗读的方式,即在3GMAP1的每次迭代前增加一级提前预读流水,从4比特的数据中任取2比特的数据进行提前预读并缓存,其余2比特在正常流程的前半窗读取,并与提前预读的2比特组成完整的数据;由于3GMAP1采用拷贝的方式来解决冲突,读写不会同时存在于同一存储资源空间,因此从根本上就不会发生读写冲突,提前预读流水可以和其它窗的后半窗重合。这样,通过增加少量的开销,即可实现从同时读4个数据降低到同时读2个数据,从而使相应的拷贝数也从4份降低为2份,存储资源可以完全共享4G软符号的存储资源,达到降低存储资源开销和提高共享资源利用率的目的。步骤205,在译码的前半窗阶段,读取译码的输入数据,并对读取的输入数据进行处理,得到处理结果;具体地,译码装置的第一处理模块在译码的前半窗阶段读取译码的输入数据;1)对于3G制式,在对所述译码的输入数据进行交织处理MAP1阶段的第一个窗,在前半窗阶段,从缓存中读取两组译码的输入数据,与步骤204中提前预读的两组数据共同组成四组译码的输入数据;这里,所述每组译码的输入数据包括:LE、S、和P1;每次MAP1迭代前均有半个窗的预读阶段,后半窗作为后一个窗的预读阶段;2)对于3G制式,在对所述译码的输入数据进行非交织处理MAP0阶段直接读取四组译码的输入数据;这里,所述每组译码的输入数据包括:LE、S、和P0;3)对于4G制式,在对所述译码的输入数据进行非交织处理阶段及在对所述译码的输入数据进行交织处理阶段,均直接读取四组译码的输入数据;这里,所述每组译码的输入数据包括:LE、S、和P0,或LE、S、和P1。对读取的输入数据进行处理是指将输入的数据进行gamma计算,得到gamma值,并将所述gamma值缓存至gamma_ram;具体地,gamma计算采用(1,0)的方案;由Turbo算法从理论上推到出的gamma计算的方程式,为:其中,(χ2ks,χ2k+1s,χ2kp,χ2k+1p)={0000,0001,......,1111};]]>表示从状态S2k到S2k+2的gamma值;表示编码系统比特SYS,表示编码校验比特P0或P1;表示接收的软系统符号,表示接收的软校验符号;La(χ2k),La(χ2k+1)表示先验软信息Le。本发明实施例中采用gamma(1,0)算法进行gamma计算。本发明实施例中,若不是3G制式下的MAP1阶段的第一个窗,在执行本步骤之前,则需初始化alpha或beta;若是3G制式下的MAP1阶段的第一个床,则在缓存中读取两组译码的输入数据后,再初始化alpha或beta;这里,如果为首次对输入的数据进行译码,即首次迭代,则采用固定的默认值初始化alpha或beta;否则,采用缓存的历史值初始化alpha或beta;其中,缓存的历史值为上一次译码产生并缓存的值;alpha继承历史值初始化的原理,如图7所示,beta继承历史值初始化的原理,如图8所示,在前述均有描述,这里不在赘述。步骤206,在译码的后半窗阶段将所述处理结果进行译码,得到译码结果;具体地,译码装置中的译码模块对步骤203中计算得到的所述gamma值基于基4碰撞MAP算法进行前后向碰撞计算,得到译码结果,并将所述译码结果进行缓存;其中,所述译码结果包括:硬比特信息、LE、及软符号信息;相应的,所述硬比特信息存储至hd_ram,所述4G校验比特p1软符号存储至p1_le_ram,4G校验比特p0软符号存储至p0_le_ram,4G系统比特软符号存储至llrs_scpy_ram,LE存储至le_ram;对于非冲突通道,则将四组译码结果并行写入le_ram,如果是冲突通道,在写入译码结果的过程中若遇到地址冲突,则将有冲突的地址和数据先缓存起至delay_ram,在没有地址冲突的时候,将已经缓存的有冲突的地址和数据同其他译码结果一同写入le_ram。本发明实施例中,为解决4比特数据的写冲突,采用延迟写法,由于MAP的译码结果数据仅发生在后半窗,通过延迟可以扩展写到前半窗,相当于每一时刻只写2比特数据,而在无地址冲突的时候,可以同时写入多比特数据,从而,在根本上消除写冲突的问题。步骤207,判断是否所有窗均处理完毕,判断结果为是时,执行步骤208,判断结果为否时,执行步骤205步骤208,根据所述译码结果判断译码是否结束,判断结果为是时,执行步骤209,判断结果为否时,执行步骤203;具体地,译码装置中的输出模块对所述译码结果中的硬比特信息进行循环冗余校验(CyclicRedundancyCheck,CRC),或将本次译码结果中的硬比特信息与上次迭代结果中的硬比特信息进行比较,依据迭代提前停止准则及CRC结果或比较结果确定迭代是否结束。步骤209,封装并输出译码结果;译码装置中的输出模块将译码得到的硬比特信息或软比特信息封装、输出至外部;需要说明的是,本发明实施例中所述迭代是指对输入的译码数据进行多次 译码。为实现上述译码方法,本发明实施例提供一种译码装置,所述装置的组成结构,如图11所示,包括:第一处理模块10、译码模块20、和输出模块30;其中,所述第一处理模块10,用于在译码的前半窗阶段读取译码的输入数据,并对读取的输入数据进行处理,得到处理结果;所述译码模块20,用于在译码的后半窗阶段将所述处理结果进行译码,得到译码结果;所述输出模块30,用于根据所述译码结果确认译码结束时,封装并输出译码结果。本发明实施例中,所述装置还包括:第二处理模块40,用于接收译码参数包,根据所述译码参数包获取译码参数;接收译码的输入数据,根据所述译码参数中的PadNum对所述输入数据进行处理,并存储处理后的数据。本发明实施例中,所述第一处理模块10,具体用于对于3G制式,在对所述译码的输入数据进行交织处理阶段的第一个窗,先读取两组译码的输入数据,在前半窗阶段,再读取两组译码的输入数据,获取四组译码的输入数据;或,对于3G制式,在对所述译码的输入数据进行非交织处理阶段直接读取四组译码的输入数据;或对于4G制式,在对所述译码的输入数据进行非交织处理阶段及在对所述译码的输入数据进行交织处理阶段,均直接读取四组译码的输入数据。本发明实施例中,所述第一处理模块10,具体用于对读取的输入数据进行gamma计算,得到gamma值。本发明实施例中,所述译码模块30,具体用于对所述gamma值进行前后向碰撞计算,得到硬比特信息、LE、及软符号信息。本发明实施例中,若不是3G制式下的MAP1阶段的第一个窗,在执行本步骤之前,则需初始化alpha或beta;若是3G制式下的MAP1阶段的第一个床, 则在缓存中读取两组译码的输入数据后,再初始化alpha或beta;这里,如果为首次对输入的数据进行译码,即首次迭代,则采用固定的默认值初始化alpha或beta;否则,采用缓存的历史值初始化alpha或beta;其中,缓存的历史值为上一次译码产生并缓存的值。本发明实施例中,所述第二处理模块40具体用于接收外部的译码输入数据,解析所述输入数据中的p0、p1和S,根据所述PadNum的大小在所接收的数据尾部补零对齐后存储至缓存;同时,所述第二处理模块根据k产生交织地址,并将产生的交织地址缓存至addr_ram,所述交织地址用于MAP1阶段读写数据使用。本发明实施例中,所述译码模块30,具体用于对gamma值基于基4碰撞MAP算法进行前后向碰撞计算,得到译码结果,并将所述译码结果进行缓存;具体地,对于非冲突通道,则将四组译码结果并行写入le_ram,如果是冲突通道,在写入译码结果的过程中若遇到地址冲突,则将有冲突的地址和数据先缓存起至delay_ram,在没有地址冲突的时候,将已经缓存的有冲突的地址和数据同其他译码结果一同写入le_ram;其中,所述译码结果包括:硬比特信息、LE、及软符号信息;相应的,所述硬比特信息存储至hd_ram,所述4G校验比特p1软符号存储至p1_le_ram,4G校验比特p0软符号存储至p0_le_ram,4G系统比特软符号存储至llrs_scpy_ram,LE存储至le_ram;本发明实施例中译码装置的实现示意图,如图12所示。本发明实施例中,为解决4比特数据的写冲突,采用延迟写法,由于MAP的译码结果数据仅发生在后半窗,通过延迟可以扩展写到前半窗,相当于每一时刻只写2比特数据,而在无地址冲突的时候,可以同时写入多比特数据,从而,在根本上消除写冲突的问题。同时,在本发明实施例中,在前半窗从共享存储资源读取本窗所有需要的数据信,并对所述数据进行gamma计算后缓存,在后半窗仅从该缓存中读取相应的gamma值进行译码,并将译码结果回写到共享存储资源;如此,实现了共 享存储资源的读/写完全分开,解决了读写冲突;同时,由于不需要从较大的共享存储资源二次重复读取数据和进行gamma值的二次计算,而仅从较小的缓存中直接获取gamma值降低了大RAM的读写概率和逻辑资源的翻转率,有效地降低了动态功耗。需要说明的是,在实际应用中,所述第一处理模块10、译码模块20、和输出模块30和第二处理模块40执行的功能可由位于译码装置上的中央处理器(CPU)、或微处理器(MPU)、或数字信号处理器(DSP)、或可编程门阵列(FPGA)实现。以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1