优化译码器存储极化码译码性能的方法与流程
本发明涉及通信系统中信道编解码领域,具体地涉及polar码(极化码)的译码算法和译码器实现方法。
背景技术:
极化码(polarcodes)是一种结构性与迭代性极强的信道编码,而且能够被严格证明它的渐进性能够达到香农极限容量,是信道编码领域中唯一被严格证明能够达到香农极限容量的编码技术,是在二进制离散无记忆信道下达到香农容量的信道编码方式,同时,它具有较低的编解码复杂度。因此极化码近来成为一种最受欢迎的可以达到香农容量的信道编码方式,同时它具有较低的编解码复杂度。然而,由于传统的连续消除译码器是串行译码,所以实际应用中所需要的大码长会造成很高的译码延迟。极化码代表一类新兴的纠错码,它的功率接近一个离散无记忆信道的容量。由于极化码产生时间不长,其在中短码长下实用的编译码方案的性能显得不具有竞争力,提出极化码的arikan在除了二进制删除信道(bec)外,没有给出其它信道中极化码的低复杂度的编码方案,在译码方面极化码的传统sc译码的性能也不是很好,这限制了极化码的实用。为了提高极化码的有限码长的性能,现有技术提出了几种可选择的译码算法,例如连续消除译码算法(successivecancellation,sc)、sc译码过程和升级算法和列表译码算法。连续消除译码算法sc是针对极化码的一种低复杂度译码算法,在码长趋于无限长时具有很好的性能,但是中短码长下性能并不理想。polar码的sc译码算法,可设置不同信噪比,不同码长,可改为scl算法和ca_scl算法。核心部分采用c程序编写,主要框架采用matlab编写。sc译码过程合同阶段代码树可以使用称为合同阶段编码树的统一框架来形容sc译码过程和升级算法,例如scl/scs译码过程。在这个代码树中,除了叶子节点和冻结节点,每个节点都有两个子孩子,对应的分叉分别标着0和1。包括从根节点到其中一个叶子节点的分支序列的译码路径和相应的可靠性可以用app来测量。每个节点相邻的数字提供了从根节点到该节点的译码路径的app度量标准。极化码的sc译码过程与合同级代码树相比,被称为渴望搜索算法。在与确定级的信息位结合的这两种分支中,概率被用来进一步处理。不论何时一个位被错误地确定,在以后的译码过程中纠正错误将成为不可能。
为了提高译码器的纠错性能,在sc译码算法的基础上,不断有改进的译码算法被提出来。其中,可以极大的提高译码性能的基于列表的连续消除(scl)译码算法,scl通过引入候选码字列表,被称作是广度优先算法,在与信息位有关的每一级中,scl算法通过在每个候选路径上附加位0或1使候选路径的数量加倍。通过最佳度量标准挑选出了l条最佳候选路径并将它们存储在列表中。scl译码器通过级搜索到了代码树,与sc译码器具有相同的方式。但是不像sc译码器,经过每一级的处理后仅有一种路径被保留,并且允许最大l个候选路径进一步探索。与传统sc译码相比,scl译码器在译码过程中会保留消息比特的两种可能取值,即0和1都会作为备选可能存储起来,并计算当前路径的可靠程度。当所保留的路径数目超过某个门限值l的时候,便对路径进行修剪,只保留最可靠的l条路径,并继续后续的译码直到到达最后的第n个比特位置。由于scl译码器没有立即做硬判决而是保留了两种可能的取值,因此会减少硬判决带来错误的可能性,从而提升最终的译码性能,列表译码改进了串行抵消算法的贪心深度优先搜索方式,是一种性能优异的译码算法。它的关键部分排序模块最为耗时,成为列表译码算法实用化的瓶颈。仿真结果表明,scl算法与sc算法相比,性能得到了显著提升。但是和传统的turbo码和低密度奇偶校验(ldpc)码相比还是有一定差距。scl算法采用软判决方式,通过对数似然比llr判决来进行译码,虽然性能获得了很大的改善,但是算法复杂度随着列表长度或路径宽度值的增加而增加。ldpc编码的优化也是一个非常耗时的过程。变量和检查程度分布只能由计算机优化搜索,并且主要方法生成奇偶校验矩阵图(或因子图)的ldpc码也是一个计算机辅助施工过程。循环冗余校验(cyclicredundancycheck,crc)辅助的scl译码通过先对信息序列进行crc校验,再对crc校验的信息序列进行极化编码,在进行scl译码后,译码器选择能够通过crc校验的度量最大的路径作为输出,可以进一步优化性能。仿真表明在相同码长码率条件下,crc-scl译码算法可以获得优于ldpc码的误码块性能。但是传统的crc-scl译码器在整个译码树上通过scl算法搜索得到l个最可靠的候选码字,然后通过crc校验,选择通过校验或者路径度量最小的候选码字作为最终输出,因此需要保存整个译码树内部llr值的l个备份。在有限码长条件下,crc-scl译码算法的性能随列表大小l的增大而逐渐提升,当l等于1时回退到sc译码算法。但当l增大时,由于要在更多路径中做选择和剪裁,以及存储更多的中间变量,译码算法的时间复杂度和空间复杂度也会大大增加。尤其是空间存储资源的消耗,严重限制了其在高性能和低功耗条件下的应用。
这些众所周知的算法对于中长代码实际应用过于复杂,所以他们只是被视为参考其它极性码的解码算法的性能比较。目前的研究主要集中在优化性能和提升译码速度方面,存储资源优化方面的研究比较少,还没有能够显著减少的实现方法。
现有技术sc的衍生堆栈译码方案,其原理与scl译码方案实际上是一样的,都是区别与sc针对于当前的局部最优化条件,同时存储了很多备用码字,以减少译码过程中将最优译码方案提前舍弃的概率,相较于scl算法的优点在于其译码时延更小一些,但是在eb/n0较小时它的存储需求大于scl算法,在eb/n0较大一些时其存储需求会减小,并且会小于scl的存储需求,后者的存储需求不随eb/n0变化。现阶段极化码的码长没办法做得很长,而在短码情况下,极化码的译码性能是极化码通向实用之路的一个瓶颈。
技术实现要素:
本发明的目的是针对上述现有技术存在的不足之处,提供一种能够在不影响译码性能的情况下,显著降低存储资源占用的优化译码器存储极化码译码性能的方法。
本发明的目的可以通过如下技术方案实现:一种优化译码器存储极化码译码性能的方法,其特征在于包括如下步骤:在crc-scl译码器基础上,将译码树分为由p个子译码树构成的底部译码树和顶部译码树,并将长度为n的polar码划分为p个polar码子块连接构成的底层模块和顶层模块,p个不同的数据分块共用同一个crc-scl译码器进行译码,为了进一步提高分块后译码器的性能,在不同分块消息比特中添加循环冗余校验crc比特长度进行优选,采用仿真筛选的方法得到前i-1个分块都译码正确的情况下,第i个分块添加不同长度crc比特时,根据polar码子块的错误概率fer,选择fer性能最好的crc长度作为第i个分块需要添加的crc比特长度;译码器采用crc-scl译码算法先后对p个polar码子块进行译码,在译码树上对译码器候选码字进行搜索,搜索估计每个数据分块在子译码树上的候选码字,得到l个候选码字后对候选码字进行crc校验,并在p个polar码子块之间采用sc译码算法,得到最终的译码结果。
本发明相比于现有技术具有如下有益效果。
本发明针对传统的极化码基于列表的连续消除译码算法存储器资源占用过多的缺陷,在crc-scl算法基础上对数据进行分块,将译码树分为由p个子译码树构成的底部和顶部译码树,并将长度为n的polar码划分为p个polar码子块连接构成的底层模块和顶层模块,p个不同的数据分块共用同一个crc-scl译码器进行译码,且每个子块大小一致,即都为n/p,但是并不对此作严格限制,只是在这种情况下每个子块译码器存储和计算单元能够得到最大限度的共用,不会造成任何浪费。对于列表大小为2极化码译码器,分块数p为2时,译码器存储资源占用只有原来的61%,如果把列表大小和分块数都提高到4则性能优于原译码器,存储资源占用为原来的73%。
本发明在crc-scl译码器基础上进行优化,译码器在译码树上对候选码字进行搜索时,将译码树分为两个部分,即译码树的顶部和底部。底部由p个子译码树构成,每个数据分块在子译码树上进行候选码字的搜索估计,得到l个候选码字后对候选码字进行crc校验,如果有一个候选码字通过crc校验则把它传递给译码树的顶层;如果没有候选码字通过校验或者有多个候选码字通过校验,则选择置信度最高的候选码字传递给译码树的顶层。p个不同的数据分块可以共用同一个crc-scl译码器进行译码,而在译码树的顶层执行sc译码算法,得到最终的码字。为了进一步提高分块后译码器的性能,对不同分块消息比特中添加的crc比特长度进行优选,采用仿真筛选的方法,得到前i-1个分块都译码正确的情况下第i个分块添加不同长度crc比特的码块错误概率(frameerrorrate,fer),从而选择fer性能最好的crc长度作为第i个分块需要添加的crc比特长度。在对消息比特进行分块时,对每个分块添加的crc校验比特长度进行优选。采用fer性能仿真筛选的方法,在分块数为p时,对于每个分块,仿真得到前i-1个分块都译码正确的情况下第i个分块添加不同长度crc比特的fer性能,从而选择fer性能最好的crc长度。仿真表明码长1024,码率0.5,列表大小8,分块数4的情况下,优选出的4个分块添加的crc长度分别为2、4、7和4,此时与同等条件下4个分块添加crc长度都为8的情况相比,fer性能优化0.25db。
本发明采用在译码树上对译码器候选码字进行搜索,搜索估计每个数据分块在子译码树上的候选码字,得到l个候选码字后对候选码字进行crc校验,在译码树的顶层执行sc译码算法,选择路径度量值最小的候选码字作为最终输出;省去了在译码树顶层对候选路径进行排序裁剪的过程,相比于传统的译码器,译码时延会略有降低。
本发明采用在第i-1个polar码子块译码结束之后输出第i-1个译码分段,在剩余译码树上的p个polar码子块之间采用sc译码算法,通过计算单元计算第i个polar码子块译码所需的初始llr值,重复上述操作,直到p个译码分段都计算结束,得到最终的码字。可以使用共同的存储空间进行多个分块的计算,不需要保存整个译码树内部llr值的l个备份,而只需要保存每个分块的内部llr值的l个备份,由于译码器所需存储的内部llr值随着译码树大小的减小成指数倍降低,这样极大的减小了译码过程中对数似然比值(log-likelihoodratio,llr)的存储空间。克服了传统crc-scl译码器在整个译码树上通过scl算法搜索得到l个最可靠的候选码字,选择通过校验或者路径度量最小的候选码字作为最终输出,需要保存整个译码树内部llr值的l个备份的缺陷。
附图说明
下面结合附图和具体实施进一步说明本发明,但并不因此将本发明限制在所述的实例范围之中。
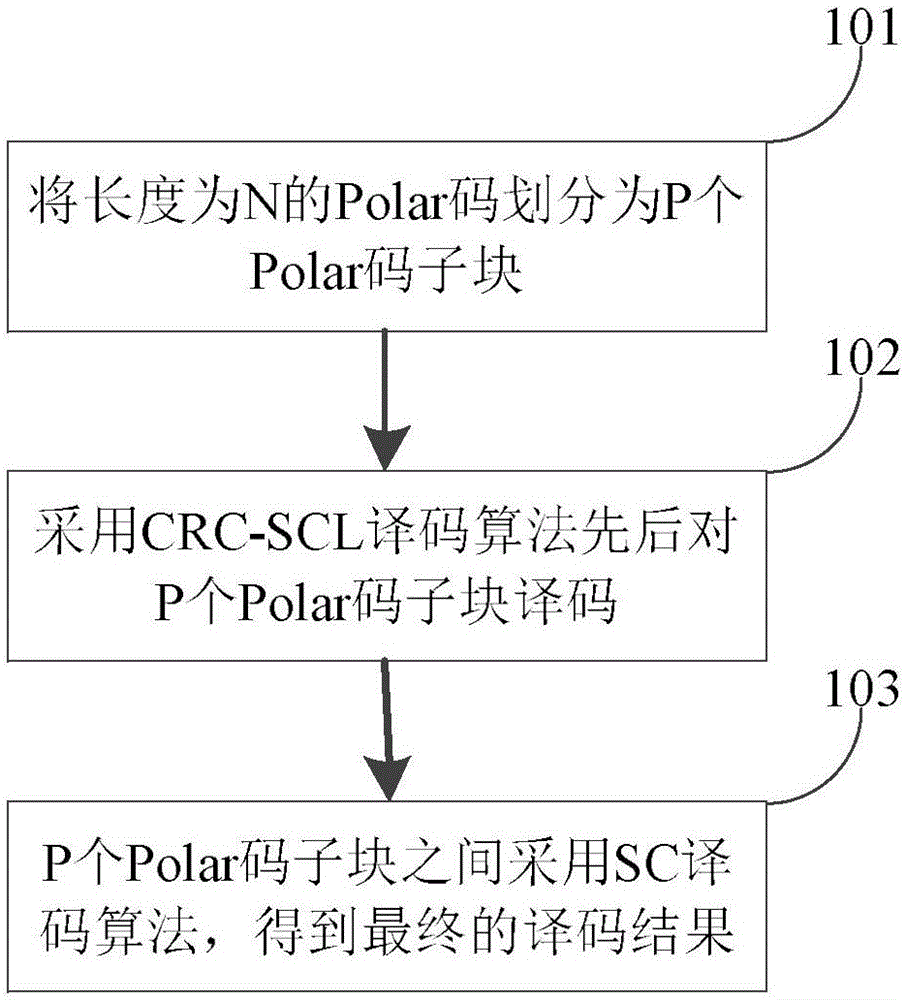
图1是本发明优化译码器存储极化码译码性能的基本流程图。
图2是码长为8的极化码polar码译码器示例的译码蝶形示意图。
具体实施方式
参阅图1。根据本发明,在crc-scl译码器基础上,将译码树分为由p个子译码树构成的底部和顶部译码树,并将长度为n的polar码划分为p个polar码子块,p个不同的数据分块共用同一个crc-scl译码器进行译码,为了进一步提高分块后译码器的性能,在不同分块消息比特中添加循环冗余校验crc比特长度进行优选,采用仿真筛选的方法得到前i-1个分块都译码正确的情况下,第i个分块添加不同长度crc比特时该码块的错误概率fer,选择fer性能最好的crc长度作为第i个分块需要添加的crc比特长度;译码器采用crc-scl译码算法依次对p个polar码子块进行译码,在译码树上对译码器候选码字进行搜索,搜索估计每个数据分块在子译码树上的候选码字,得到l个候选码字后对候选码字进行crc校验,并在p个polar码子块之间采用sc译码算法,得到最终的译码结果。如果有一个候选码字通过crc校验,则把它传递给译码树的顶层模块;如果没有候选码字通过校验或者有多个候选码字通过校验,则选择置信度最高的候选码字传递给译码树的顶层模块,在译码树的顶层执行sc译码算法,选择路径度量值最小的候选码字作为最终输出;在第i-1个polar码子块译码结束之后输出第i-1个译码分段,在剩余译码树上的p个polar码子块之间采用sc译码算法,通过计算单元计算第i个polar码子块译码所需的初始llr值,重复上述操作,直到p个译码分段都计算结束,得到最终的码字。
在分块数为p时,对于每个分块,仿真得到前i-1个分块都译码正确的情况下第i个分块添加不同长度crc比特的fer性能,从而选择fer性能最好的crc长度。为了进一步提高分块后译码器的性能,需要对不同分块消息比特中添加的crc比特长度进行优选,优化存储的极化码译码器按以下步骤实施:
步骤101,根据极化码在sc译码下各个比特判决之间的依赖关系,能够构造一颗码树。从根节点到每一个深度的节点的路径,均对应了一种可能的取值。定义连接着深度和节点的边所构成的集合为层边。根节点到任何一个节点所形成的路径,均对应一个路径度量值(pm)。极化码译码码树实质是一个满二叉树,因此译码过程也就是在满二叉树上寻找合适的路径。对于译码长度为n的polar码,译码树共有log2n层,译码过程中第i层需要存储2(i-1)个内部llr值。本发明将译码长度为n,列表大小为l的polar码划分为p个子块,一般情况下p为2的整数次幂,分块crc-scl译码器把译码树划分为多个分块,在每个分块上执行scl运算,每个分块选出一个通过crc校验的候选码字,然后送往下一个分块,因此不需要保存整个译码树内部llr值的l个备份,而只需要保存每个分块的内部llr值的l个备份,多个分块的计算可以使用共同的存储空间。假设crc-scl译码器和分块crc-scl译码器需要的存储空间大小分别用m1和m2表示,则其计算公式如下所示:
m1=(n+(n-1)l)qα+lqpm+(n-1)l(1)
式中,qα为llr值的量化比特数,qpm为路径度量值量化比特数,n为polar码长度,p为分块crc-scl译码器中分块数,l为译码树llr值的备份个数即列表大小。实际测试表明码长2048,码率0.5的polar码,添加32比特crc校验位,列表大小l为2的条件下,分块大小为2的crc-scl译码器和传统crc-scl译码器性能相一致,而存储资源占用只有原来的61%。
译码器分块的划分和编码前信息序列分块添加crc的方式相一致,待编码的原始k比特的信息序列s首先被分为p个子序列s1,s2,l,sp,每个子序列的长度为ki,其中0<i≤p,即
为了得到更优的译码器性能,每个分块序列si添加的crc校验比特长度ri要进行优化,在码长和分块大小确定后,依次对p个分块添加的crc校验长度进行筛选,对于第i个分块,仿真得到前i-1个分块都译码正确的情况下第i个分块添加不同长度crc比特的fer性能,从而选择使得fer性能最好的crc长度。p个分块的crc校验比特长度ri确定之后,再将信息序列划分到不同的分块中,尽量保证每个分块的大小为n/p。
步骤102,译码器采用crc-scl译码算法依次对码字长度为n的polar码的p个polar码子块进行译码,则每个分块的长度为n/p。译码器在译码树上对候选码字进行搜索,计算每条路径的度量值,得到度量值最小的l个子路径,当该分块的polar码子块所有比特都译码出来之后,即得到了ki个信息比特和ri个校验比特,则送crc校验模块,对列表中保存的l个候选码字依次进行crc校验。如果只有一个候选码字通过crc校验,则输出该码字给顶层模块;如果所有候选码字都未通过校验或者有多个候选码字通过校验,则选择路径度量值最小的候选码字作为最终输出,送给顶层模块。同时,选择输出的候选码字参与下一个polar码子块初始llr值的计算。
译码树由log2n层满二叉树组成,译码过程中第i层需要存储2(i-1)个内部llr值,这样完整的一条搜索路径需要存储n-1个llr值,l条路径就需要存储(n-1)l个llr值;p个polar码子块的译码顺序进行,因此可以共用同一个crc-scl译码模块。码长为n的p个polar码子块译码器共用同一个crc-scl译码模块,将码长为n的polar码拆分之后,polar码子块译码器存储码长为n/p的子码,根据译码树上l个搜索路径获得(n/p-1)l个llr值。存储空间的消耗会随p的增大而成倍下降。
步骤103,p个polar码子块之间采用sc译码算法,即polar码子块之间只有单条译码路径的扩展。改进连续消除sc译码算法为串行抵消列表(序列连续消除scl)译码算法,根据scl译码算法,在增加每一层路径搜索后允许保留的候选路径数量,最大允许选择最好的条路径进行下一步扩展,从码树根节点开始,逐层依次向叶子节点层进行路径搜索每一层扩展后,尽可能多地保留后继路径,完成一层的路径扩展后,选择路径度量值(pathmetrics,pm)保存在一个列表中,等待进行下一层的扩展。每一条路径都拥有自己的一套llr值,每一条路径的pm都要根据各自路径上的llr值计算。将已经计算出的路径按照pm值从小到大排序,对各条路径进行剪枝操作:保留各条pm值最小的路径,并且删掉其余路径,选取pm最小的路径作为唯一路径,即为译码输出结果。crc-scl译码模块在第i-1个polar码子块译码结束之后输出第i-1个译码分段,在剩余译码树上执行sc译码算法,计算第i个polar码子块译码所需的初始llr值,然后进行第i个polar码子块的crc-scl译码并输出第i个译码分段,重复上述操作,直到p个译码分段都计算结束,把p个polar码子块译码输出的p个译码分段拼接到一起就得到最终的译码输出。
参阅图2,在码长为8的polar码译码蝶形图图中,最右边一列y1,y2,l,y8为信道接收信息,最左边一列候选码字
译码开始后首先计算模块203中4个f函数的llr值,然后在polar码子块连接第一顶层模块201中执行crc-scl译码运算,每条路径需要存储3个llr值,列表大小为l时需要存储3l个llr值;译码得到l个候选码字后从中选择通过crc校验或者置信度最高的候选码字
- 还没有人留言评论。精彩留言会获得点赞!